
本文介绍PyTorch Profiler结合TensorBoard分析模型性能,分别从数据加载、数据传输、GPU计算、模型编译等优化思路去提升模型训练的性能。最后总结了一些会导致CPU和GPU同步的常见的PyTorch API,在使用这些API时需要考虑是否会带来性能影响。
PyTorch Profiler简介
什么是PyTorch Profiler?
PyTorch作为一款应用于深度学习领域的库,其影响力日益显著。PyTorch Profiler是PyTorch生态中的一个组件,用来帮助开发者分析大规模深度学习模型的性能。该组件不仅收集GPU硬件层面的数据,还同步整合PyTorch框架内的运行信息,通过这种深层次的数据关联,自动识别模型执行过程中的瓶颈问题,并提出具体的改进建议,所有收集到的信息经过整理后,均能在TensorBoard上直观展示。真正意义上做到了从数据收集、分析到可视化,为PyTorch用户提供了一站式解决方案。此外,新版本的PyTorch Profiler API已被直接内置到PyTorch框架中,您无需额外安装其他软件包,即可直接启动模型分析流程。
PyTorch Profiler的优势与局限性
优势 | 局限性 |
|
|
环境准备
本示例使用的GPU卡型为V100-SXM2-32GB,并使用PyTorch官方的Docker镜像(pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel)运行代码,需要注意一点是,启动Docker时,需为容器挂载Shm(docker run --shm-size=)和共享宿主机IPC(--ipc=host)。
创建具备GPU节点的集群。具体操作,请参见创建GPU集群。
ACK集群支持的GPU机型,请参见ACK支持的GPU实例规格族。
拉起PyTorch环境。
利用Arena拉起PyTorch环境
安装最新版Arena。具体操作,请参见配置Arena客户端。
执行以下命令,修改values.yaml文件。
vi ~/charts/pytorchjob/values.yaml打开文件后,将
shmSize和privileged的参数值修改为如下值:shmSize: 20Gi # 通过shmSize参数指定共享内存的大小。 privileged: true # 因为要使用pytorch Profiler,建议容器使用特权模式,即privileged=true。执行以下命令,拉起PyTorch环境。
使用Arena工具向ACK集群提交一个简单的PyTorch作业请求。作业本身并不执行任何实际的深度学习训练任务,而是通过执行
sleep 10d命令来模拟一个持续运行的进程,便于测试和验证作业提交流程。arena submit pytorch \ --name=workspace \ --gpus=1 \ --image=nvcr.io/nvidia/pytorch:24.03-py3 \ "sleep 10d"预期输出:
pytorchjob.kubeflow.org/workspace created INFO[0005] The Job workspace has been submitted successfully INFO[0005] You can run `arena get workspace --type pytorchjob -n default` to check the job status输出结果显示PyTorch作业已成功创建。
执行以下命令,查看作业是否已经处于
Running状态。arena get workspace当作业处于
Running状态后,执行以下命令进入PyTorch容器,即可进行Profiling。arena attach workspace预期输出:
Hello! Arena attach the container pytorch of instance workspace-master-0可在PyTorch容器中检查Nsight System是否安装。
nsys profile --help
利用kubectl拉起PyTorch环境
复制并粘贴以下内容到pytorch-workspace.yaml文件中,用于创建一个Deployment。
apiVersion: apps/v1 kind: Deployment metadata: name: pytorch-workspace spec: selector: matchLabels: app: pytorch-workspace replicas: 1 template: metadata: labels: app: pytorch-workspace spec: hostIPC: true hostPID: true containers: - name: pytorch-workspace image: nvcr.io/nvidia/pytorch:24.03-py3 command: - sleep - 10d resources: limits: nvidia.com/gpu: 1 securityContext: privileged: true volumeMounts: - mountPath: /dev/shm name: dshm volumes: - emptyDir: medium: Memory name: dshm执行以下命令,创建Deployment资源。
kubectl apply -f pytorch-workspace.yaml当Pod处于
Running状态后,使用以下命令进入PyTorch容器内部。kubectl exec -it pytorch-workspace-xxxxx -- /bin/sh
创建一个NodePort类型的Service资源,并为Service开启负载均衡,来暴露TensorBoard服务。
apiVersion: v1 kind: Service metadata: name: tensorboard-service spec: type: NodePort ports: - port: 6006 targetPort: 6006 nodePort: 30006 # 可以选择一个未使用的端口号 selector: app: pytorch-workspace然后您可以通过
<节点IP>:30006访问TensorBoard。
以下介绍如何利用PyTorch Profiler完成模型的性能分析与优化。
具体操作前,您可以通过阅读PyTorch Profiler官方文档,了解PyTorch Profiler的基本用法;以及通过阅读Quick Usage Instructions,了解TensorBoard各指标的含义。
步骤一:创建一个深度学习模型并进行训练
创建并拷贝以下内容到demo.py文件中,用于创建一个深度学习模型并进行训练。
为了演示模型性能分析与优化的思路和技巧,使用了TensorBoard-plugin tutorial 中的示例模型,完整代码如下。
# 导入所有必需的库。 import torch import torch.nn import torch.optim import torch.profiler import torch.utils.data import torchvision.datasets import torchvision.models import torchvision.transforms as T # 准备输入数据。本教程中,使用CIFAR10数据集,将其转换为所需格式,并使用DataLoader加载每个批次。 transform = T.Compose( [T.Resize(224), T.ToTensor(), T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True) # 创建ResNet模型、损失函数和优化器对象。为了在GPU上运行,将模型和损失转移到GPU设备上。 device = torch.device("cuda:0") model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device) criterion = torch.nn.CrossEntropyLoss().cuda(device) optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9) model.train() # 定义对每批输入数据的训练步骤。 def train(data): inputs, labels = data[0].to(device=device), data[1].to(device=device) outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() # 使用分析器记录执行事件。 with torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('./resnet18'), record_shapes=True, profile_memory=True, with_stack=True ) as prof: for step, batch_data in enumerate(train_loader): if step >= (1 + 4 + 3) * 1: break train(batch_data) prof.step() # 需要在每个步骤上调用此函数以通知分析器步骤边界。该代码涵盖了从数据准备、模型配置、训练流程设置到性能分析的整个机器学习模型训练过程。
进入PyTorch容器内部,运行demo.py文件。
python demo.py预期输出:
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /root/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth 100.0% [root@iZ2ze*******hZ ~]# ls data demo.py resnet18输出结果表明,当运行完代码以后,会在当前目录下产生一个目录resnet18,使用Tensorboard打开。
tensorboard --logdir=resnet18效果如下:
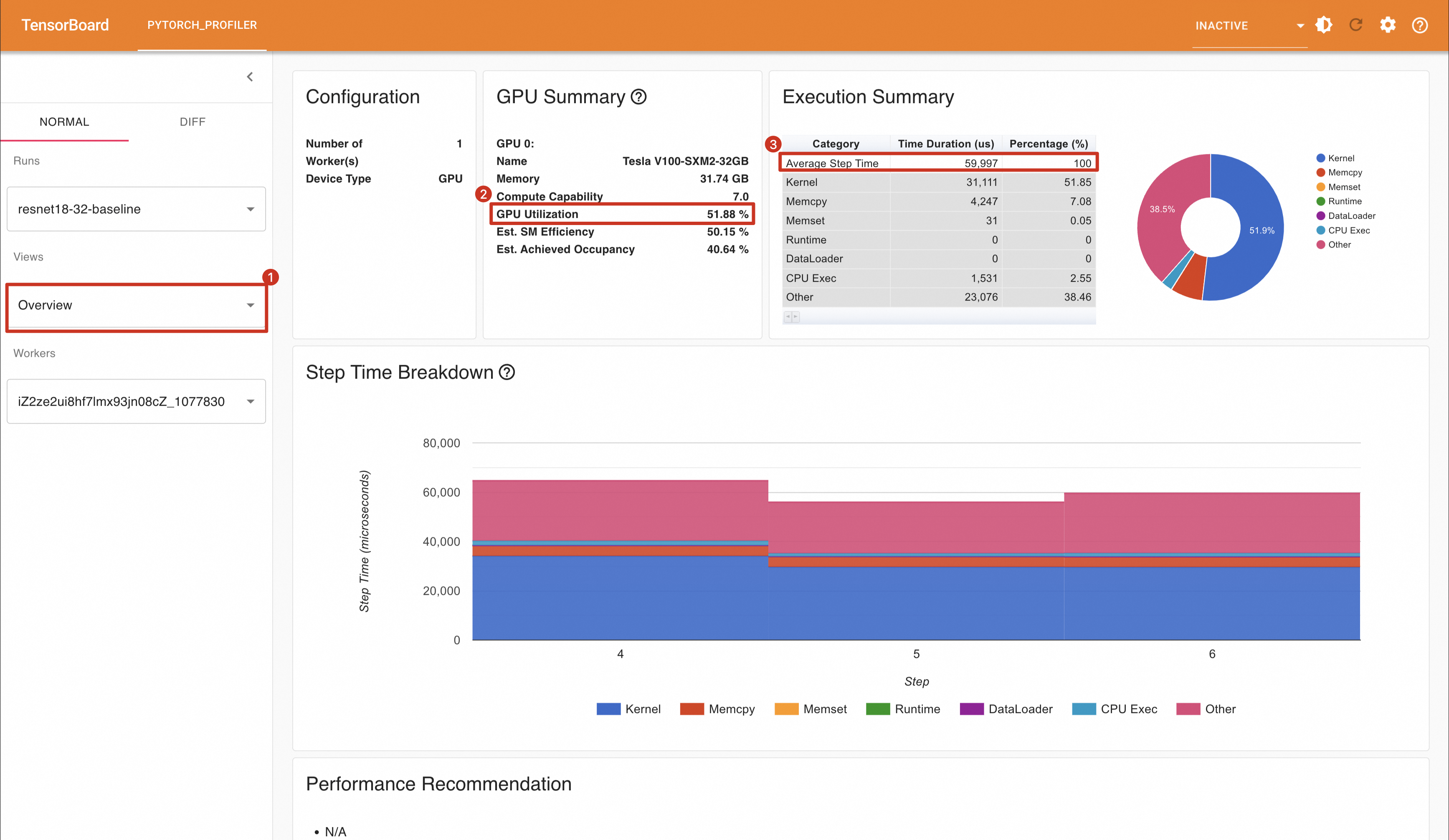
从上图中,可以看到:
GPU的利用率为51.88%
平均每一个Step(PyTorch Profiler将一个Mini Batch称为一个Step)时间为59.997ms。
每秒处理样本数为:32 / (59.997 / 1000) = 533.36 samples/s。
步骤二:优化模型
对于一个单机的深度学习训练任务,可优化的方向有如下几个:
数据加载(Data Loading):通常情况下,把数据从Disk(或者其他网络存储系统)加载到主机内存,并对数据做预处理操作(例如,去除噪声值),笼统地称为数据加载阶段。
数据传输(Data Transmission):将数据从主机内存传输到GPU内存。
训练(Training):GPU计算单元(CUDA Core、Tensor Core)利用这些数据做训练操作。

一般考虑的方向是上面前面三部分,下面将对每部分作一些案例介绍。
优化方向1:加速数据加载
在训练任务中,缩短数据加载时间对提升整体效率至关重要。理想情况下,希望数据加载耗时能够低于GPU的实际计算时间,以避免因数据准备滞后而导致的GPU空置(等待数据加载)现象,从而确保GPU资源得到充分利用。
优化前:
PyTorch的DataLoader支持多个Worker(Multi-process)同时工作,能够同时处理单个Mini Batch的数据加载任务。
未优化前,仅使用1个Worker加载数据。从TensorBoard中可以看到,整个Step的耗时为55.875ms,但是Data Loading阶段却花费了29.528ms,存在优化的空间。
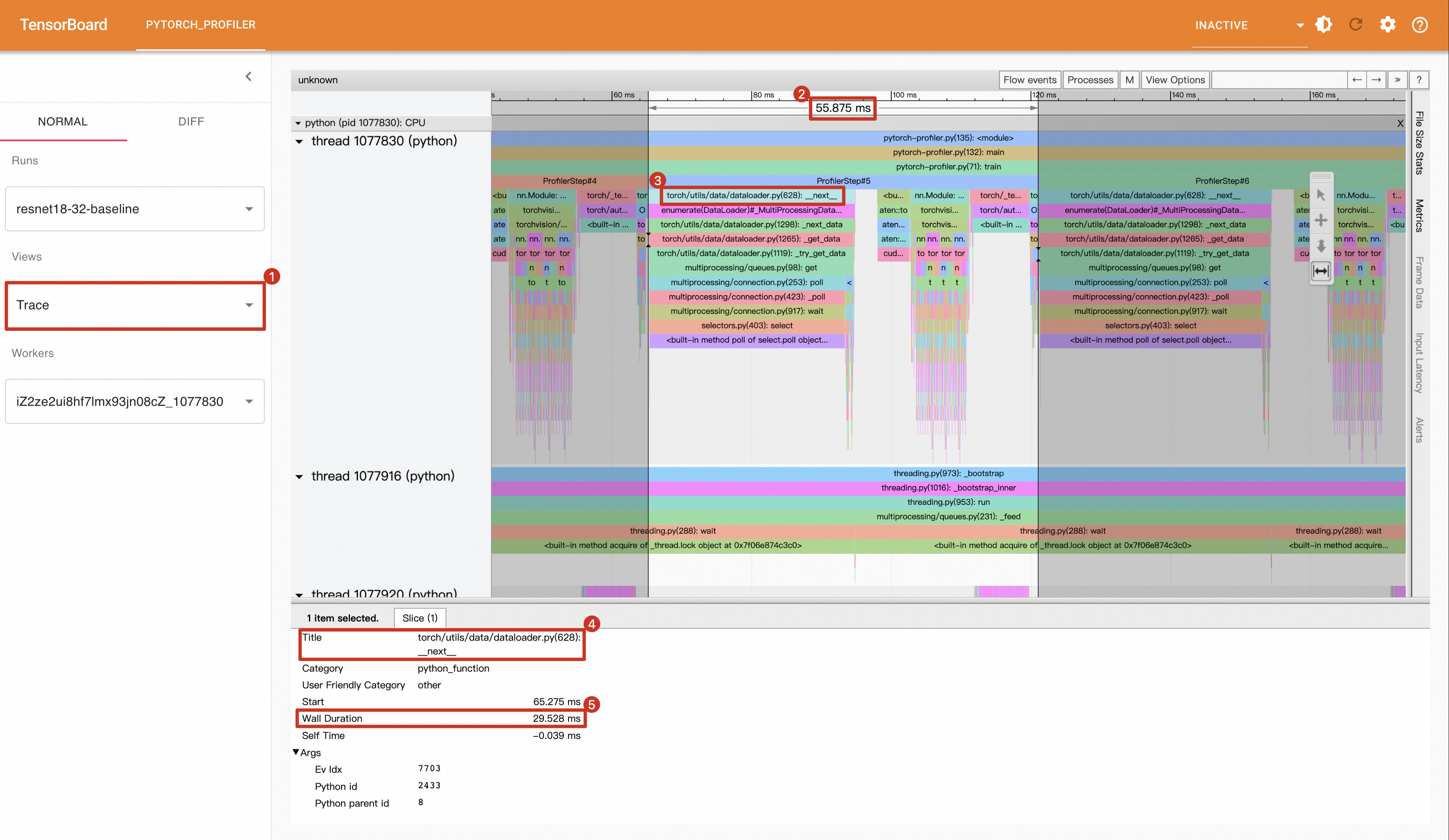
优化后:
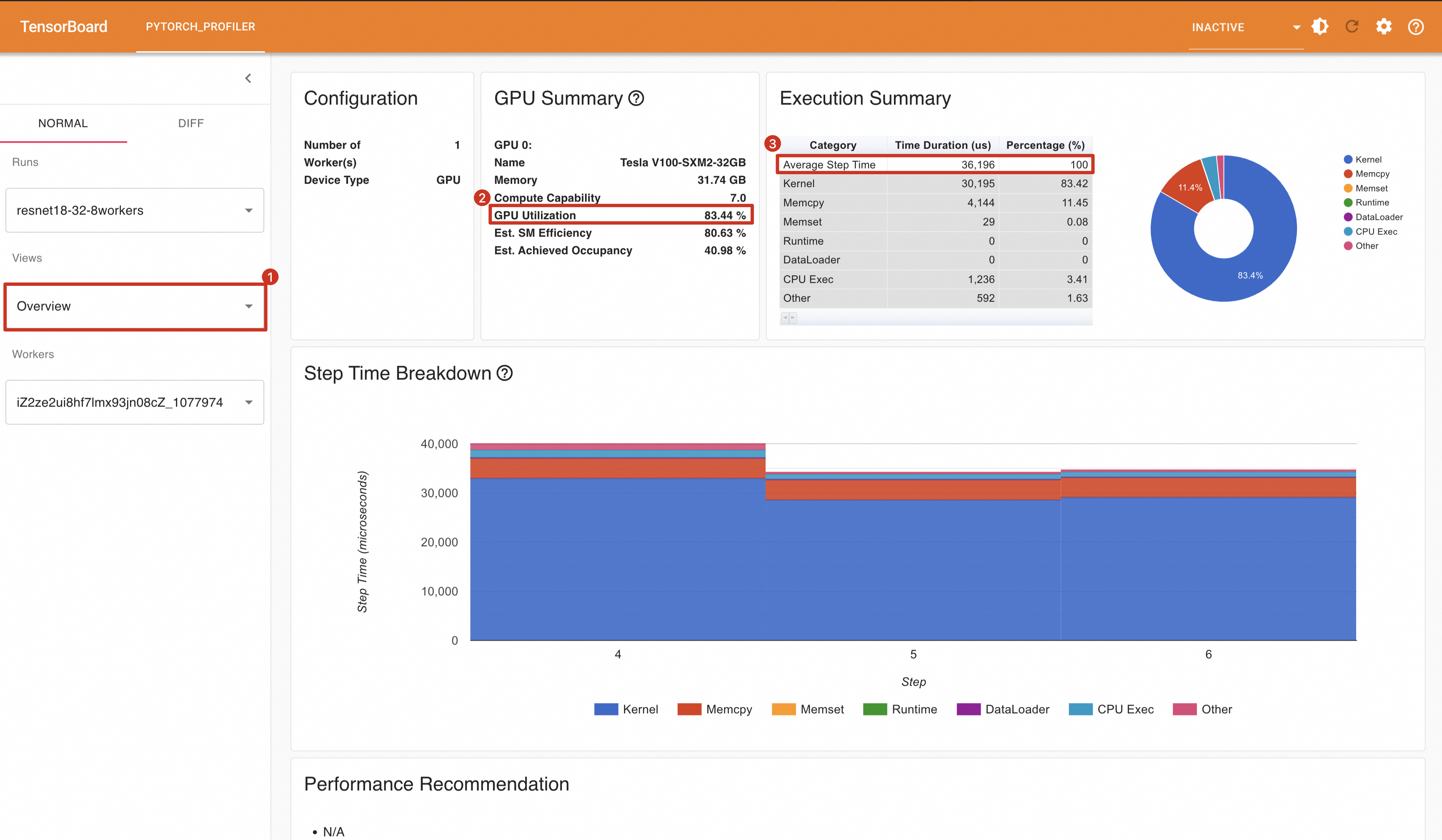
尝试将DataLoader的Worker数由1变成8:
train_loader = torch.utils.data.DataLoader(train_set,num_workers=8, batch_size=32, shuffle=True)重新运行代码,将Profling结果导入Tensorboard中,可以看到GPU利用率变成了83.44%,平均每一个Step消耗时间为36.196ms。
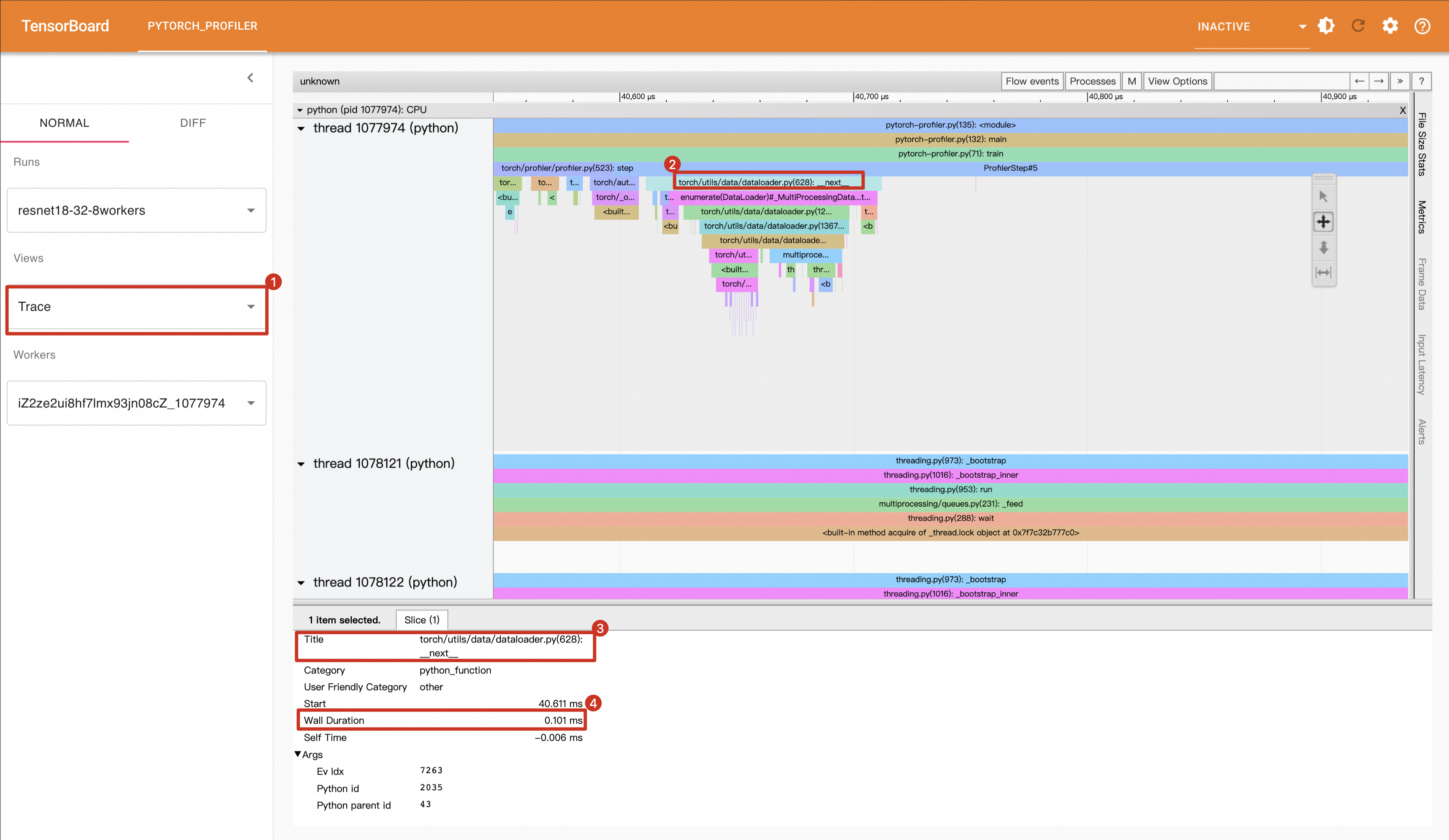
在Trace视图中,查看Data Loading时间为0.101ms。
总结
缩短数据加载时间后,将相关指标与Baseline做一下对比:
对比项 | 优化前(1 Worker) | 优化后(Enable 8 Workers) |
GPU利用率 | 51.88% | 83.44% |
Step平均耗时 | 59.997ms | 36.196ms |
Data Loading耗时(以Step5为例) | 29.528ms | 0.101ms |
平均每秒处理样本数(samples/s) | 533.360 | 884.076 |
可以看到,仅仅将Worker数由1变成8,模型性能就有很大的提升。
优化方向2:提升数据传输效率
在处理每个Batch时,需要先将数据从Host端内存传输到GPU内存中。对于较小的Batch Size,这种数据传输可能不会显著影响整体处理时间;然而,当Batch Size较大时,减少数据传输时间能够显著提高模型的运行效率。
为了缩短数据传输时间,可以将预处理后的数据直接存储在固定内存(Pin Memory)中。在创建DataLoader时,通过设置pin_memory=True选项,能够有效加速数据从CPU到GPU的传输过程,从而提升整体性能。此外,在数据传输过程中,使用non_blocking=True参数可以使数据传输异步进行,进一步提高效率。
开启Pin Memory
在创建DataLoader时,指定pin_memory=True选项。
train_loader = torch.utils.data.DataLoader(train_set,num_workers=8,pin_memory=True, batch_size=32, shuffle=True)同时,在传输数据时,使数据传输异步进行,设置non_blocking=True。
inputs, labels = data[0].to(device=device,non_blocking=True), data[1].to(device=device,non_blocking=True)重新运行代码,将Profiling结果导入TensorBoard中。
开启Pin Memory后,观察到GPU利用率显著提升至91.86%,同时每个步骤的耗时减少到26.734毫秒。
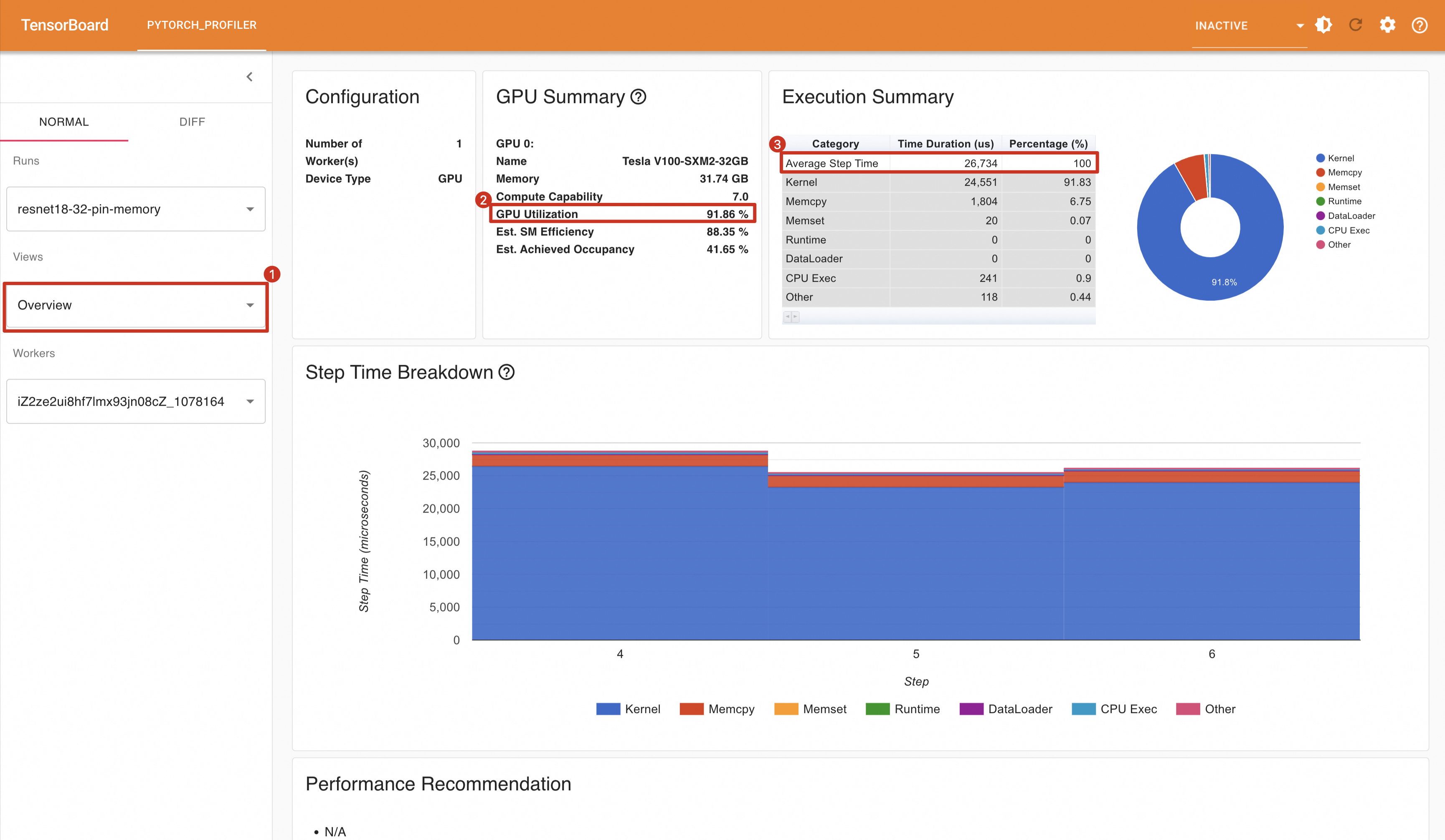
为什么使用异步传输?
如果没有指定
non_blocking=True,数据传输会是一个同步过程。这意味着程序会在数据完全传输到GPU之前暂停执行后续指令。具体来说,当执行如下代码时:inputs, labels = data[0].to(device=device), data[1].to(device=device)如果未设置
non_blocking=True,那么CPU会在数据(即data[0]和data[1])从主机端传输至GPU内存的过程中停止运行,直到整个数据传输完成为止。在TensorBoard中可以看到,aten::_to_copy函数会调用两个CUDA API:一个是用于实际数据传输的cudaMemcpyAsync;另一个是cudaStreamSynchronize,它用来确保数据传输完成后才继续执行。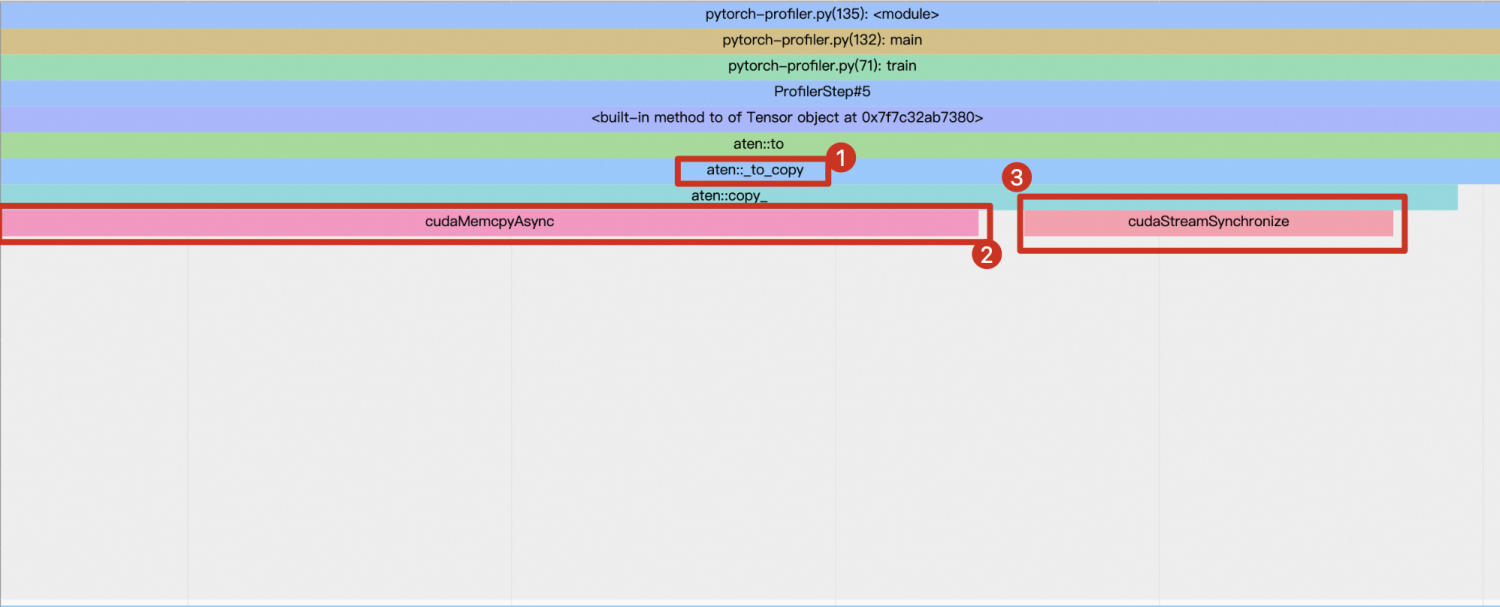
当设置non_blocking=True后,数据传输将变成一个异步行为。此时,
aten::_to_copy不会调用cudaStreamSynchronize来等待数据传输结束。相反,一旦开始执行下面的第一行代码后,函数就会立即返回控制权给CPU,允许其继续执行下一条语句,即使此时数据可能还在从主机向GPU传输的过程中。inputs, labels = data[0].to(device=device,non_blocking=True), data[1].to(device=device,non_blocking=True) outputs = model(inputs) loss = criterion(outputs, labels)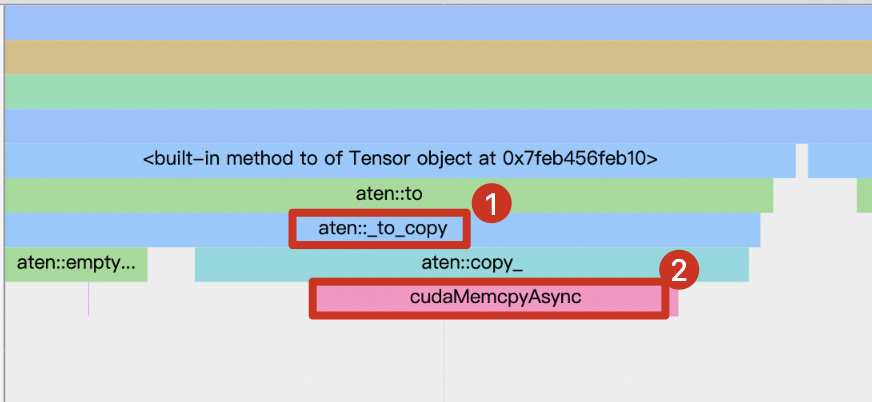
总结
在开启8个worker的基础上,开启Pin Memory后性能有所提升,如下所示。
对比项 | 优化前(Enable 8 Workers) | 优化后(Enable Pin Memory) |
GPU利用率 | 83.44% | 91.86% |
Step平均耗时 | 36.196ms | 26.734ms |
平均每秒处理样本数(samples/s) | 884.076 | 1196.978 |
优化方向3:启用自动混合精度
在开启Pin Memory的基础上,继续寻找优化模型的机会。
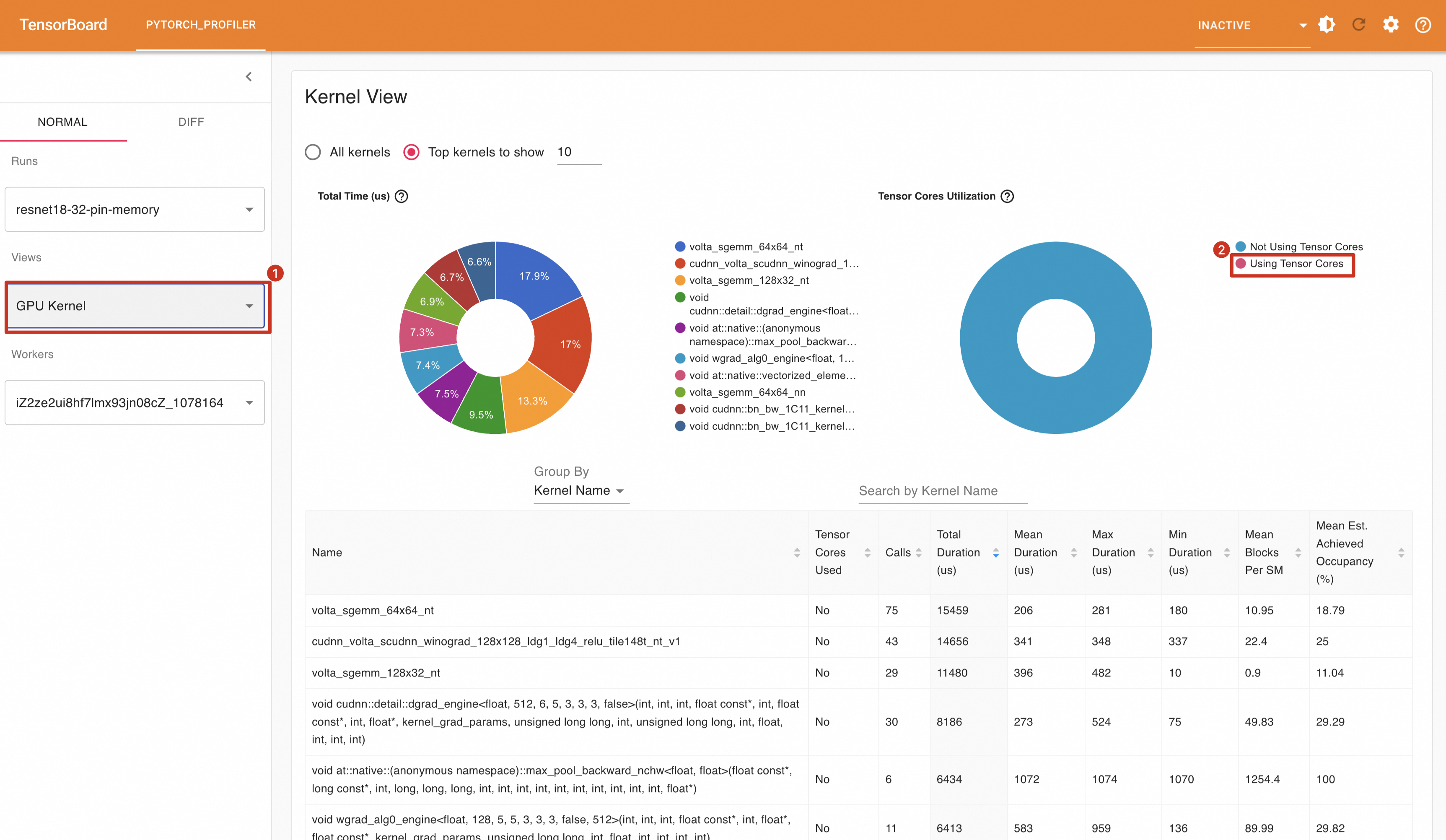
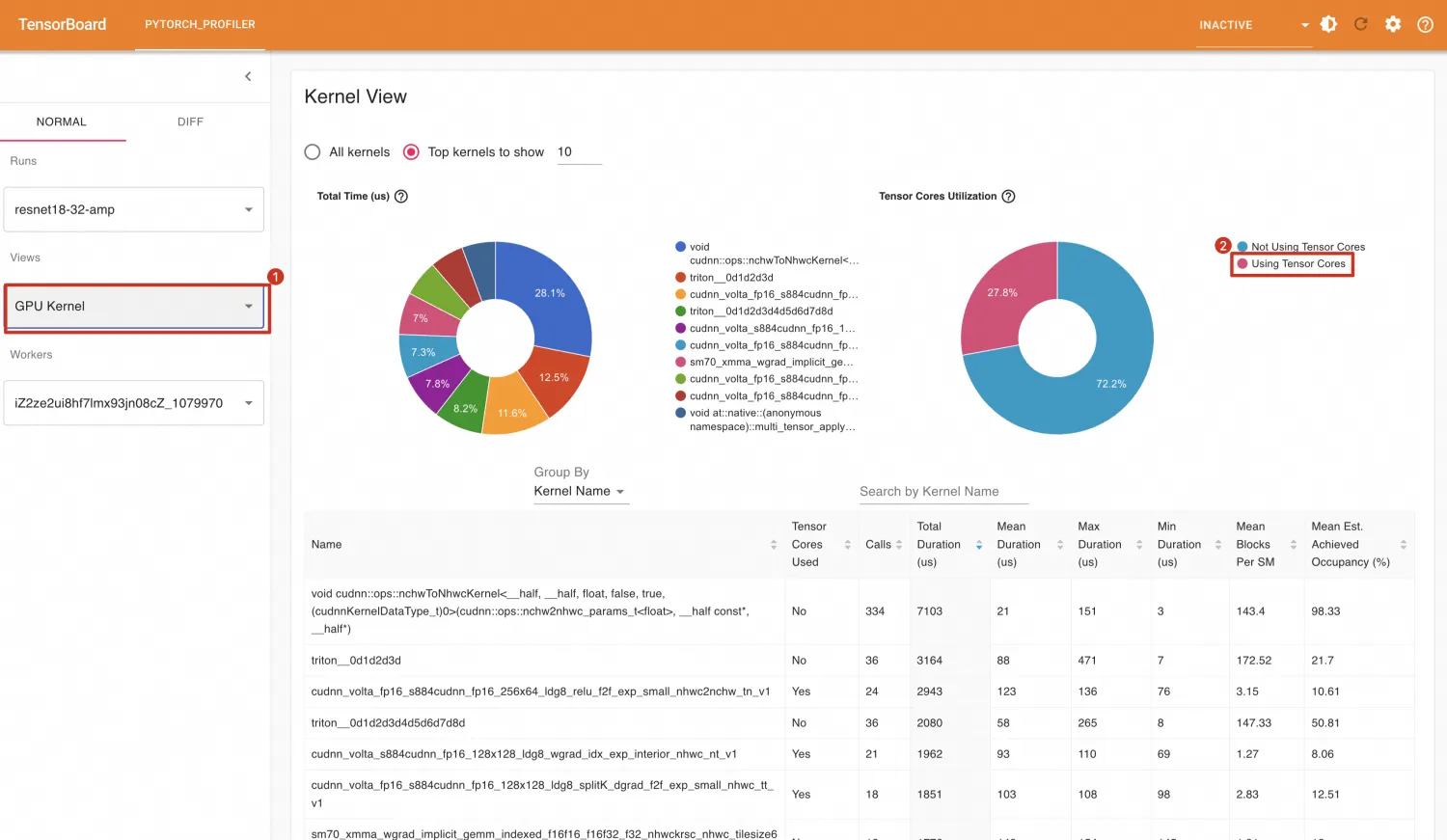
GPU内核(Kernel)视图提供了Kernel的执行时间,这为提升GPU利用率提供一定参考。如下所示,从GPU内核视图中可以观察到Tensor的利用率为0,这可能是一个提升GPU利用率的方向。
利用Tensor Core可以进行混合精度计算,PyTorch支持在训练的时候开启混合精度计算( Automatic Mixed Precision (AMP)),在AMP模式下,GPU上部分Tensor自动转换为低精度的16位浮点数,并在GPU张量核心上运行。
AMP的完整实现可能需要梯度缩放,本文的演示中没有包括这一点。在生产环境中,请正确使用AMP。
修改以下代码开启AMP模式。
# train step
def train(data):
inputs, labels = data[0].to(device=device,non_blocking=True), data[1].to(device=device,non_blocking=True)
# 开启amp
with torch.autocast(device_type='cuda', dtype=torch.float16):
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()重新运行,在TensorBoard中各指标展示如下。使用AMP后比不使用的效果还差,GPU利用率由91.86%变为48.66%,每个Step耗时由26.734ms增加到29.611ms。
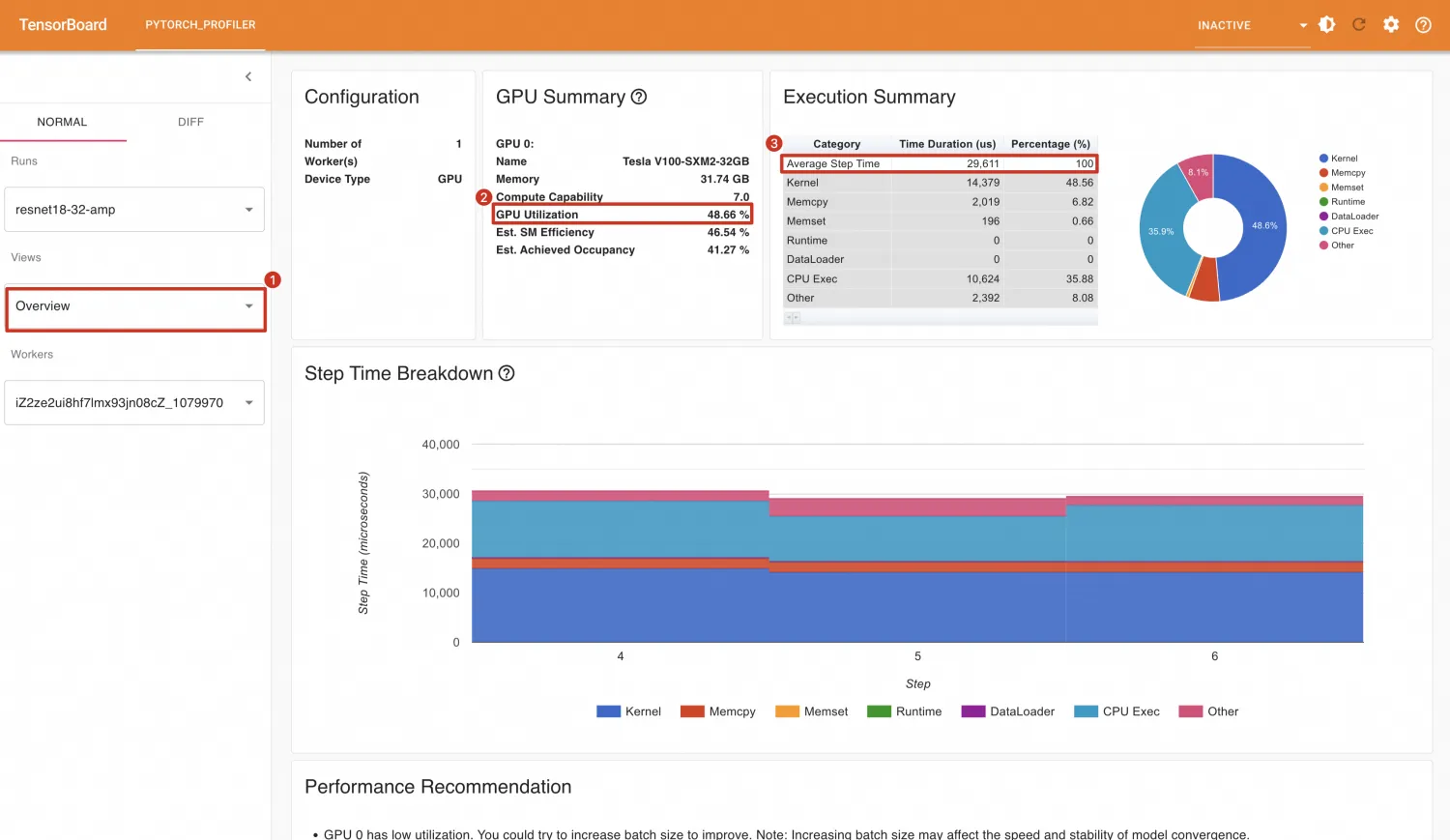
不过在GPU内核视图中,可以看到Tensor Core的使用占比由0上升至27.8%。
为什么使用AMP后效果更差了?原因可能是精度转换本身是有开销,如果Batch Size比较小(或者模型比较简单),那么精度转换本身消耗的时间比较数据计算时间还长,导致无法从AMP获取更多的收益。
为了验证猜想的正确性,尝试将当前Batch Size(32)增加到128,然后比较在Batch Size为128的情况下,开启AMP与不开启AMP的效果对比。
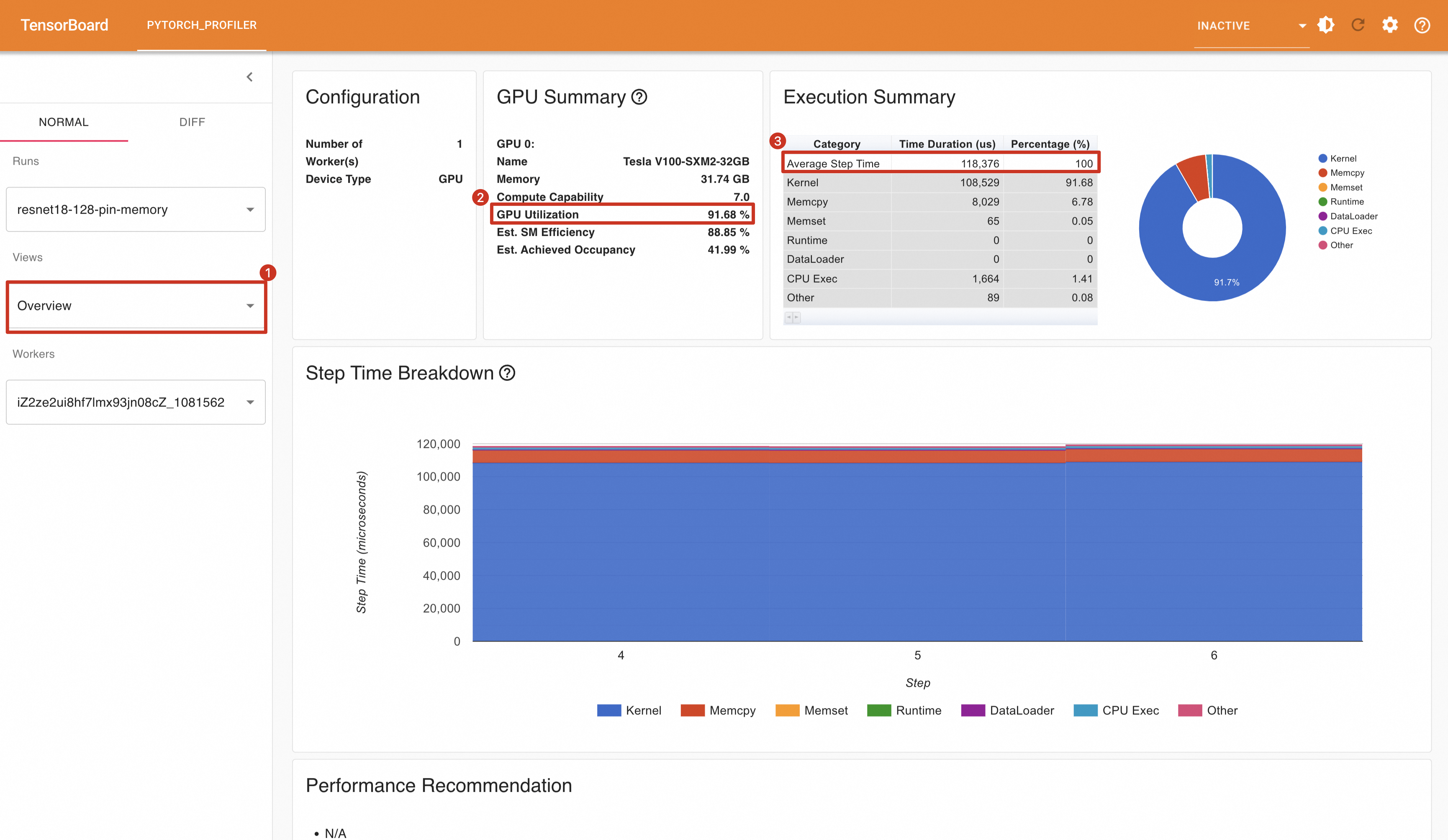
train_loader = torch.utils.data.DataLoader(train_set,num_workers=8,pin_memory=True, batch_size=128, shuffle=True)在没有开启AMP情况下,GPU利用率为91.68%,平均每个Step消耗时间为118.376ms,每秒处理样本数为:128 / (118.376 / 1000) = 1081.300。
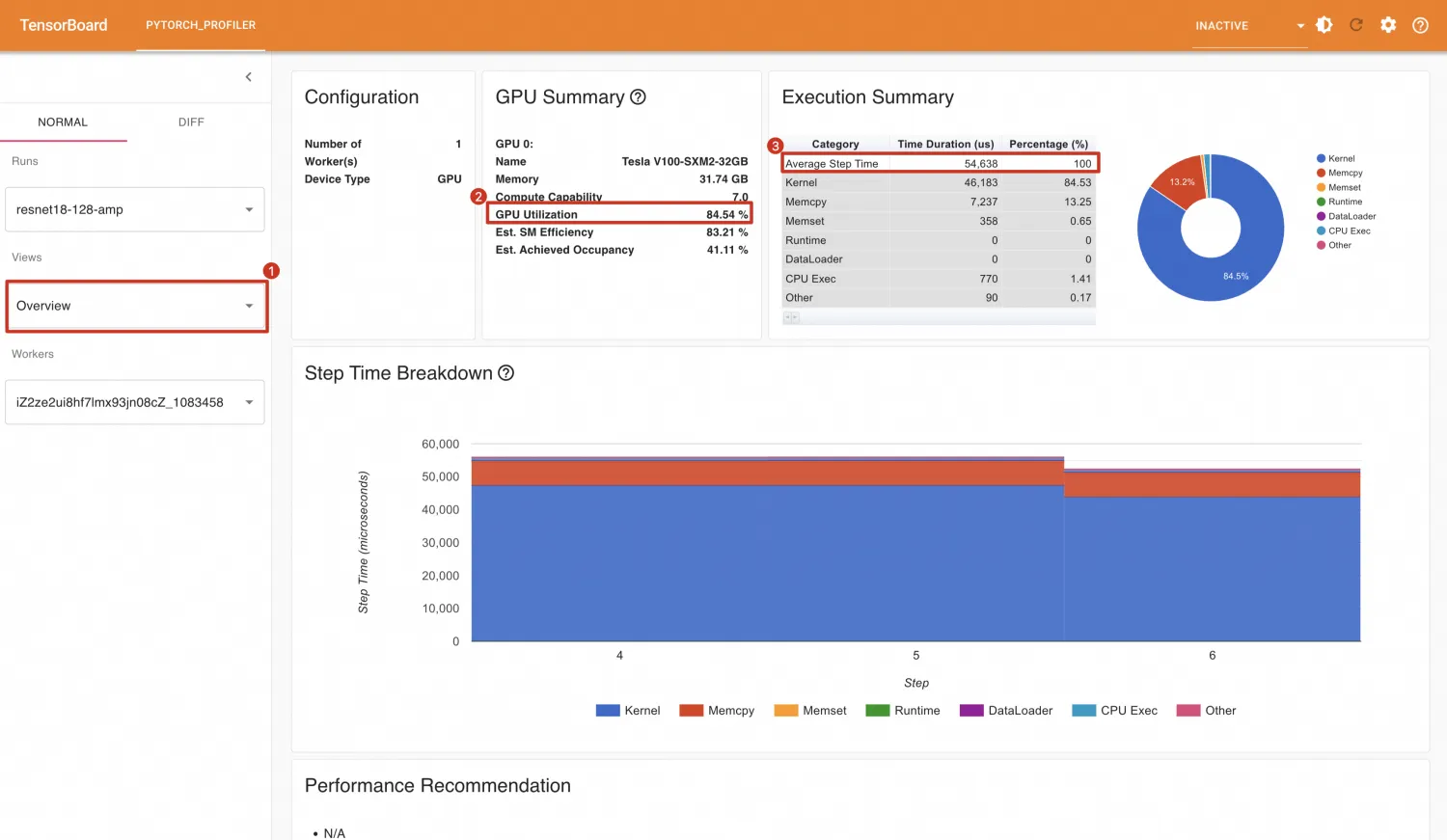
开启AMP后,GPU利用率为84.54%,平均每个Step消耗时间为54.638ms,平均每秒处理样本数为:128 / (54.638 / 1000) = 2342.692。
总结
可以看到,开启AMP情况下的平均每个Step消耗时间缩短到不开启AMP的情况下的一半。开启AMP后GPU利用率这个指标值虽然有所降低,但这并影响。因为GPU利用率高并不一定说明是高效使用GPU(但是GPU利用率低一定说明GPU并未充分利用)。
优化方向4:实施模型编译优化
默认情况下,PyTorch采用的是即时编译,您可以借助PyTorch的编译API将模型编译成图模式(Graph Mode)。
模型编译需要修改如下代码:
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
model = torch.compile(model)为了更好地演示模型编译效果,本小节选择Batch Size为1024(因为较小的Batch Size效果不明显),同时,需要具备如下条件:
Data Loader Workers数为8
开启Pin Memory
开启AMP
首先展示模型不编译的效果,GPU利用率为87.22%,平均每个Step耗时为422.462ms,平均每秒处理样本数为:1024 / (422.462 / 1000) = 2423.887。
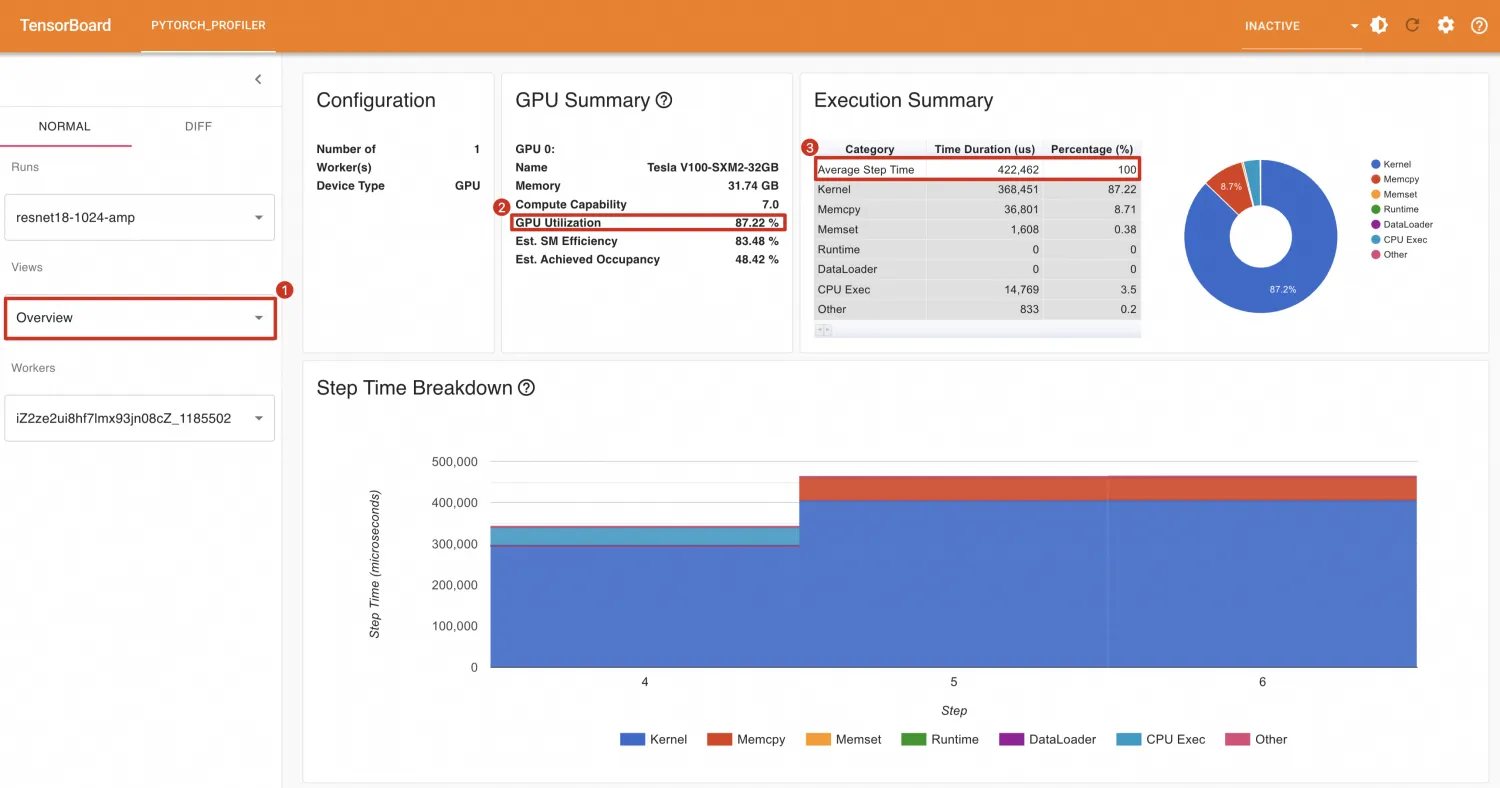
模型编译后,GPU利用率为84.07%,平均每个Step耗时为375.715ms,平均每秒处理样本数为:1024 / (375.715 / 1000) = 2725.470。
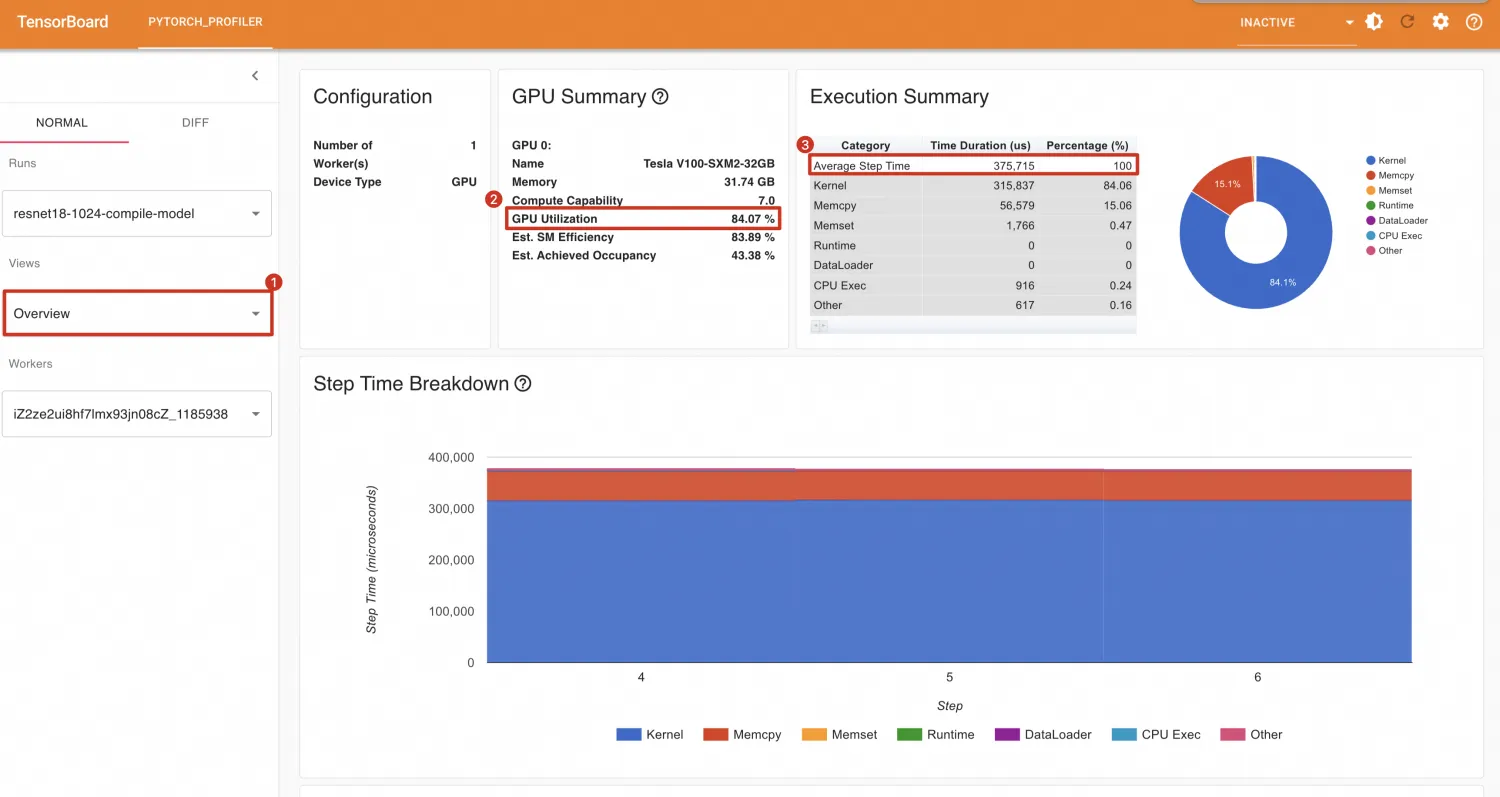
总结
以上结果表明,通过编译优化,不仅提高了处理速度,还增强了整体效率。
优化方向5:精简一些数据传输与同步的操作
在PyTorch中存在一些CPU和GPU之间同步的操作。如果不注意,这些同步操作可能会极大的降低训练任务的速度。
本小节仍然基于Baseline做修改,配置如下:
Batch Size设置为512
Data Loader Worker数设置为8
完整代码如下。
import torch
import torch.nn
import torch.optim
import torch.profiler
import torch.utils.data
import torchvision.datasets
import torchvision.models
import torchvision.transforms as T
transform = T.Compose(
[T.Resize(224),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=512, # batch size 设置为512
num_workers=8, # worker数设置为8
shuffle=True,
)
device = torch.device("cuda:0")
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
criterion = torch.nn.CrossEntropyLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
# train step
def train(data):
inputs, labels = data[0].to(device=device), data[1].to(device=device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# training loop wrapped with profiler object
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./resnet18'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, batch_data in enumerate(train_loader):
if step >= (1 + 4 + 3) * 1:
break
train(batch_data)
prof.step() # Need to call this at the end of each step运行代码,将结果导入TensorBoard中,可以看到GPU利用率84.64%,平均每个Step消耗时间为488.871ms,平均每秒处理的样本数为512 / (488.871 / 1000) = 1047.31。
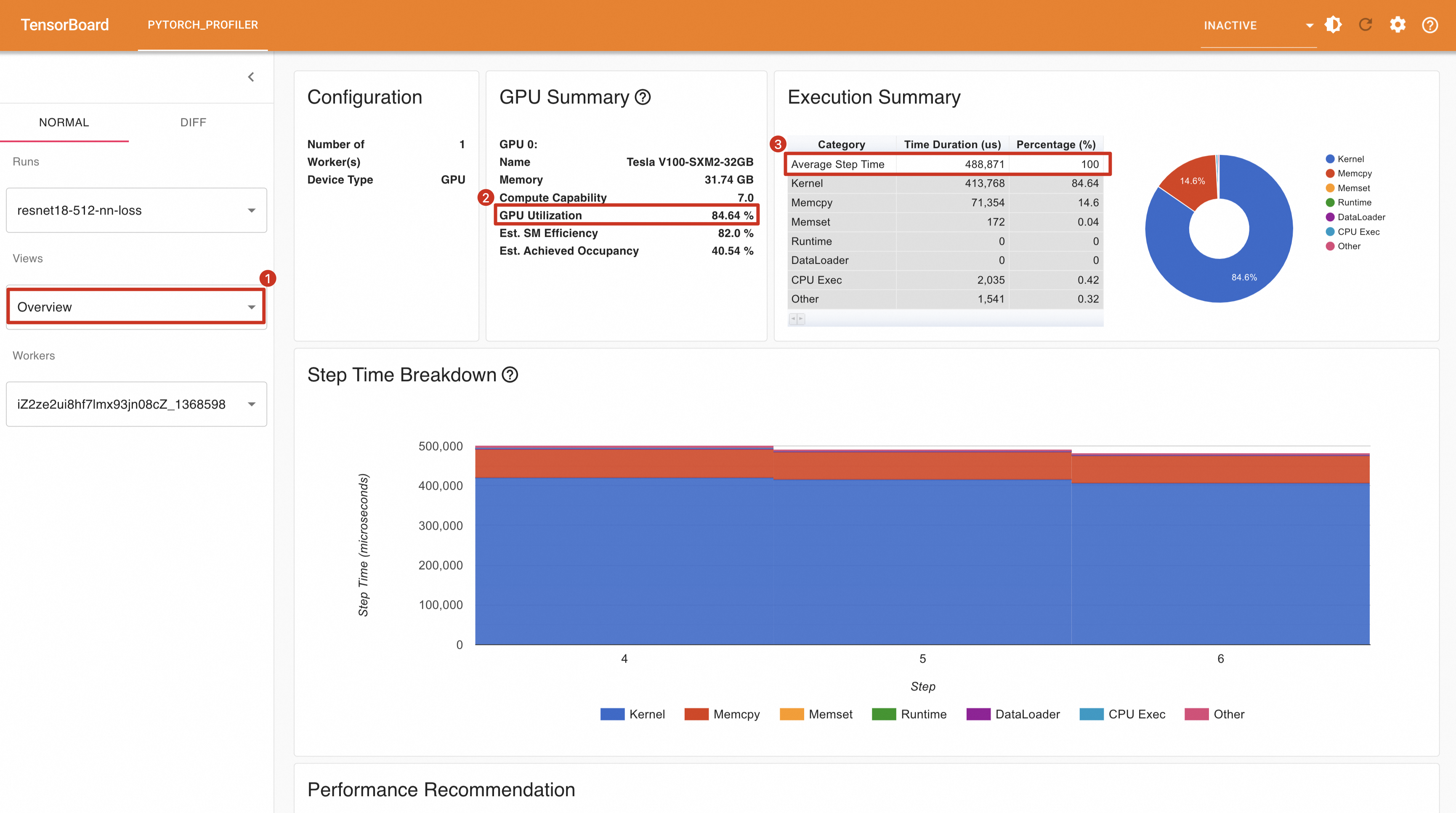
然后修改train函数,用一个全局变量保存每次batch计算的loss值。
# 全局变量,保存每次计算的loss值
total_losses = []
# train step
def train(data):
inputs, labels = data[0].to(device=device), data[1].to(device=device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 将当前loss值添加到total_losses中
total_losses.append(loss.item())重新运行代码,结果如下所示。在调用loss.item()后,GPU利用率降为77.02%,平均每个Step消耗时间为538.954ms,平均每秒处理的样本数为512 / (538.954 / 1000) = 949.99。

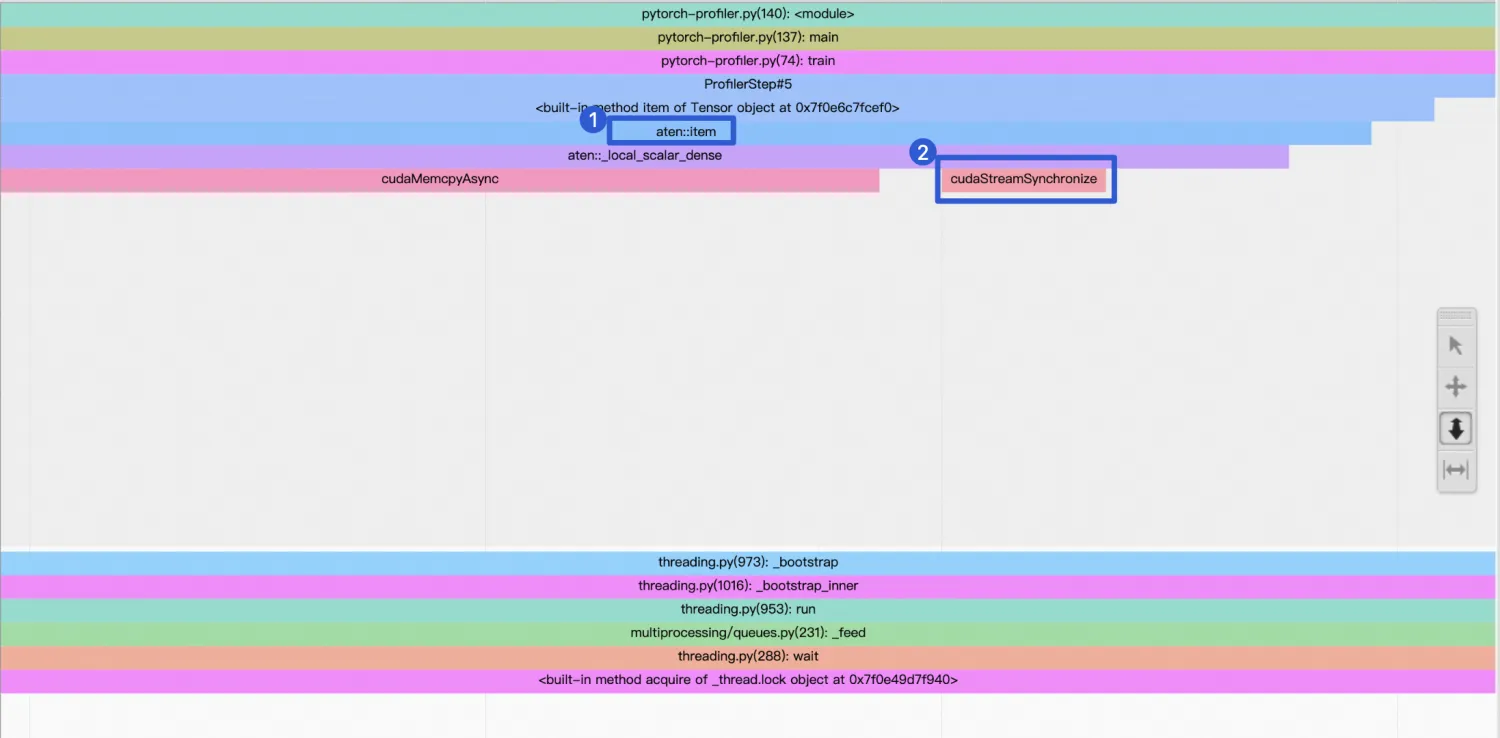
仅添加了一行代码,调用了loss.item(),就导致性能出现极大的损失。进入Trace视图发现:tensor.item()操作(382.469ms)占据了整个Step(530.101ms)的大部分时间。
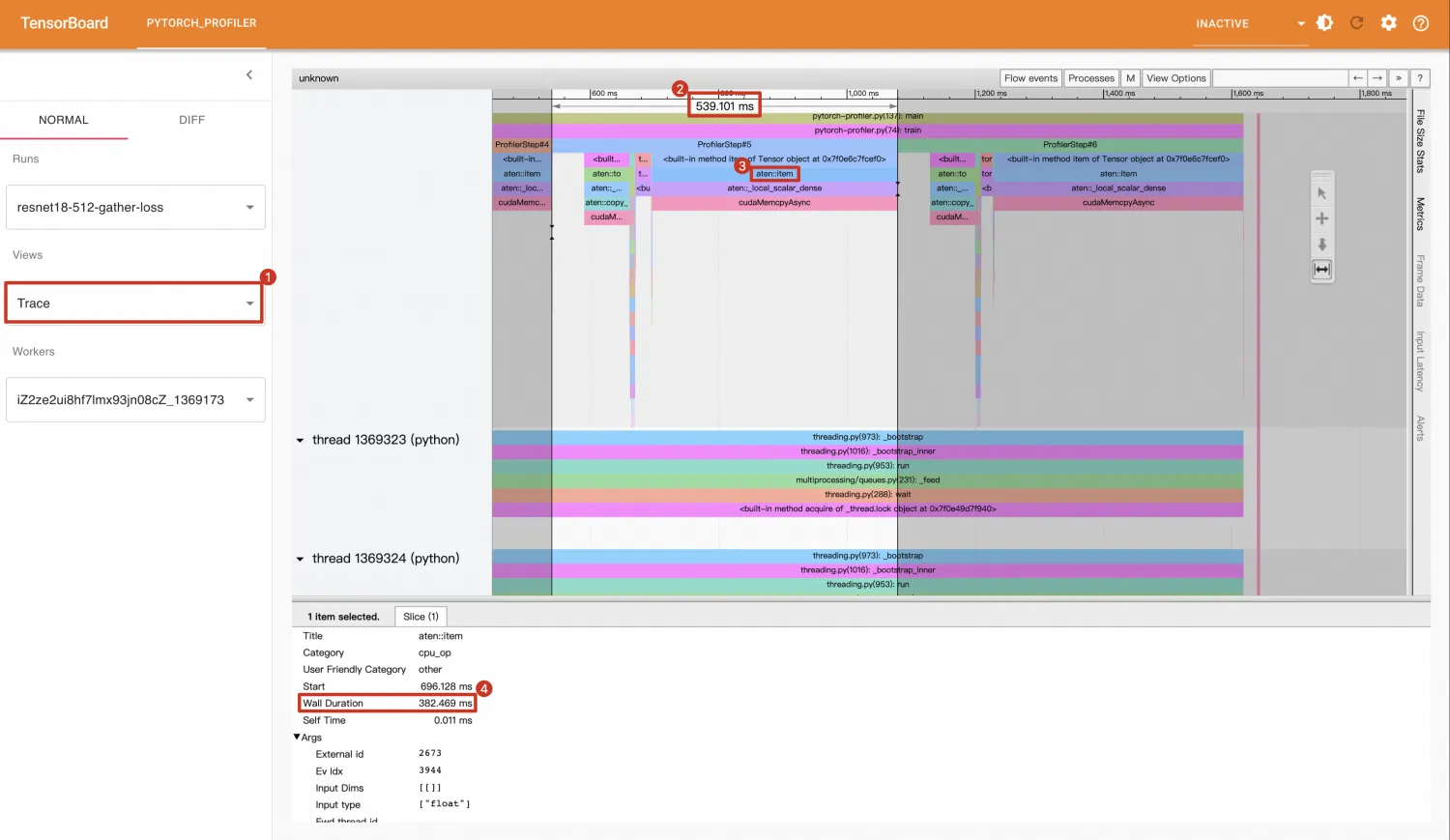
同时,放大Trace视图,可以看到tensor.item()会调用cudaStreamSynchronize(),这是一个同步CPU和GPU的操作,执行到这个函数时,进程会被阻塞,直到CUDA Stream中的当前时间点之前的操作执行完成后,cudaStreamSynchronize()才会返回,进程才可以执行其他代码。
总结
通过上述分析,在生产环境中应谨慎使用 tensor.item(),如果确实需要使用,则必须评估其对性能的潜在影响。此外,还有几个与 tensor.item() 行为相似的PyTorch API也会导致CPU与GPU之间的同步操作,从而可能引起性能下降。这些API包括torch.nonzero和torch.unique。在使用这些函数时,同样需要仔细考量它们是否会对系统的整体性能造成不利影响。