
本文适用于已安装共享GPU基础版的集群。本文介绍如何解决共享GPU专业版集群升级后共享GPU调度失效的问题。
问题描述
升级ACK中的共享GPU专有版集群后,kube-scheduler组件中关于ack-cgpu应用的extender配置会丢失,导致集群的GPU共享调度无法正常工作。
问题原因
ACK中的共享GPU专有版集群升级时,现有配置将被默认配置覆盖,导致extender配置丢失。
解决方案
请参考下列步骤进行处理。
步骤一:检查extender配置
依次登录所有Master节点。
依次检查Master节点中的文档
/etc/kubernetes/manifests/kube-scheduler.yaml,查看是否存在类似下图中与scheduler-extender-config.json相关的配置。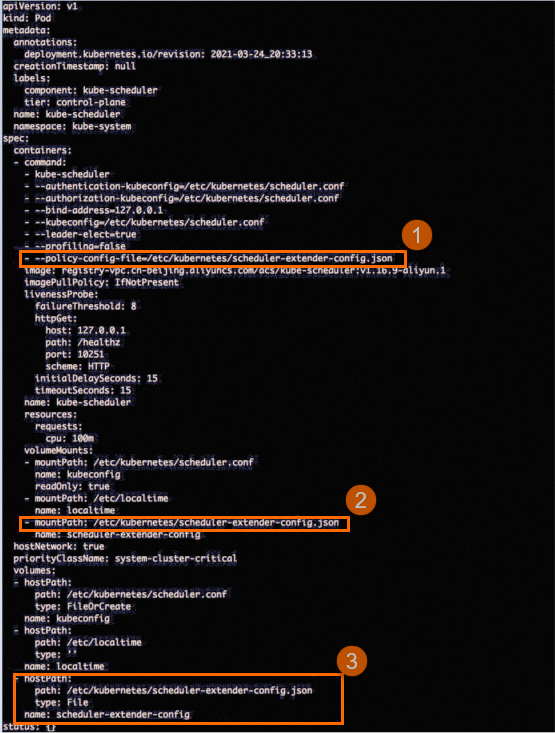
如果不存在上图中相关的配置,请执行步骤二进行修复。如果存在,则说明extender配置未丢失,无需进行修复,请加入钉群(钉群号:30421250),联系产品技术专家进行咨询。
步骤二:运行修复程序
登录任意一个Master节点。
在Master节点上执行以下命令,下载修复工具。
sudo wget http://aliacs-k8s-cn-beijing.oss-cn-beijing.aliyuncs.com/gpushare/extender-config-update-linux -O /usr/local/bin/extender-config-update执行以下命令,为修复工具添加可执行权限。
sudo chmod +x /usr/local/bin/extender-config-update执行以下命令,运行修复工具。
sudo extender-config-update执行以下命令,检查kube-scheduler的运行状态,确认其已重启,并且当前状态为运行(Running)状态。
kubectl get po -n kube-system -l component=kube-scheduler系统显示类似如下,其中AGE为14s,表示组件刚刚重启,说明修复工具已生效。
NAME READY STATUS RESTARTS AGE kube-scheduler-cn-beijing.192.168.8.37 1/1 Running 0 14s kube-scheduler-cn-beijing.192.168.8.38 1/1 Running 0 14s kube-scheduler-cn-beijing.192.168.8.39 1/1 Running 0 14s参考步骤一:检查extender配置,确认
kube-scheduler.yaml文件中extender相关配置已经复原,然后执行步骤三。
步骤三:结果验证
登录到任意一个Master节点。
创建文件/tmp/cgpu-test.yaml用于测试。
将以下内容写入
/tmp/cgpu-test.yaml文件。apiVersion: batch/v1 kind: Job metadata: name: tensorflow-mnist spec: parallelism: 1 template: metadata: labels: app: tensorflow-mnist spec: containers: - name: tensorflow-mnist image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - python - tensorflow-sample-code/tfjob/docker/mnist/main.py - --max_steps=100000 - --data_dir=tensorflow-sample-code/data resources: limits: aliyun.com/gpu-mem: 3 # 总共申请3GiB显存 workingDir: /root restartPolicy: Never执行以下命令,创建任务。
kubectl create -f /tmp/cgpu-test.yaml执行以下命令,确认Pod处于运行状态。
kubectl get po -l app=tensorflow-mnist系统显示如下。
NAME READY STATUS RESTARTS AGE tensorflow-mnist-5htxh 1/1 Running 0 4m32s执行以下命令,检查上述Pod实际被分配的显存,确认其与/tmp/cgpu-test.yaml文件中指定的显存一致。
kubectl logs tensorflow-mnist-5htxh | grep "totalMemory"系统显示如下。
totalMemory: 3.15GiB freeMemory: 2.85GiB执行以下命令,检查上述Pod实际被分配的显存,确认其与/tmp/cgpu-test.yaml文件中指定的显存一致。
kubectl exec -ti tensorflow-mnist-5htxh -- nvidia-smi系统显示如下,该Pod实际被分配3226 MiB显存,符合预期,说明GPU共享调度恢复正常。如果GPU共享调度未生效,容器被分配的显存等于宿主机的GPU显存容量。
Mon Apr 13 11:52:25 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 33C P0 56W / 300W | 629MiB / 3226MiB | 1% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+