Fluid是一个开源的Kubernetes原生的分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用,例如大数据应用、AI应用等。JindoRuntime来源于阿里云EMR团队JindoFS,是基于C++实现的支撑Dataset数据管理和缓存的执行引擎,支持OSS对象存储。Fluid通过管理和调度JindoRuntime实现数据集的可见性、弹性伸缩和数据迁移。本文介绍如何在注册集群中使用Fluid加速OSS文件访问。
实现原理
通过Fluid加速OSS文件访问的实现原理如下图所示。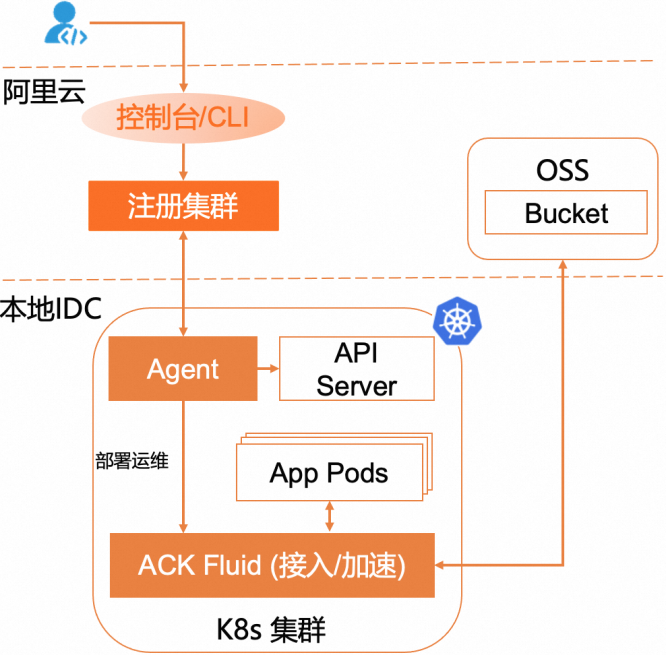
前提条件
已通过容器服务Kubernetes版接入一个注册的Kubernetes集群。具体操作,请参见创建注册集群。
已通过kubectl连接注册集群。具体操作,请参见获取集群KubeConfig并通过kubectl工具连接集群。
步骤一:安装ack-fluid组件
通过onectl安装
在本地安装配置onectl。具体操作,请参见通过onectl管理注册集群。
执行以下命令,安装ack-fluid组件。
onectl addon install ack-fluid --set pullImageByVPCNetwork=falsepullImageByVPCNetwork:为可选参数,设置是否使用VPC网络拉取组件镜像。预期输出:
Addon ack-fluid, version **** installed.
通过控制台安装
登录容器服务管理控制台,在左侧导航栏选择。
在应用目录页面,搜索并选中ack-fluid。
在页面右上角,单击一键部署。
在创建面板中,选择集群,命名空间和发布名称可保持系统默认,然后单击下一步。
选择Chart 版本为当前最新版本,设置组件相关参数,然后单击确定。
步骤二:准备OSS Bucket数据
步骤三:为本地集群节点打上标签
执行以下命令,为本地IDC集群中的所有节点打上demo-oss=true的标签,该标签用于设置JindoRuntime的Master和Worker组件的节点调度约束条件。
kubectl label node **** demo-oss=true步骤四:创建Dataset和JindoRuntime
使用以下内容,创建mySecret.yaml文件。
该文件用于保存OSS的fs.oss.accessKeyId和fs.oss.accessKeySecret,需要在创建Dataset之前创建。
apiVersion: v1 kind: Secret metadata: name: mysecret stringData: fs.oss.accessKeyId: **** fs.oss.accessKeySecret: ****执行以下命令,部署mySecret文件生成Secret。
kubectl create -f mySecret.yamlKubernetes会对已创建的Secret使用加密编码,避免将其明文暴露。
使用以下内容,创建resource.yaml文件。该YAML文件包含Dataset和JindoRuntime两部分内容。
Dataset:用于描述远端存储数据集和UFS的信息。
JindoRuntime:用于启动一个JindoFS的集群来提供缓存服务。
apiVersion: data.fluid.io/v1alpha1 kind: Dataset metadata: name: hadoop spec: mounts: - mountPoint: oss://<oss_bucket>/<bucket_dir> options: fs.oss.endpoint: <oss_endpoint> name: hadoop path: "/" encryptOptions: - name: fs.oss.accessKeyId valueFrom: secretKeyRef: name: mysecret key: fs.oss.accessKeyId - name: fs.oss.accessKeySecret valueFrom: secretKeyRef: name: mysecret key: fs.oss.accessKeySecret --- apiVersion: data.fluid.io/v1alpha1 kind: JindoRuntime metadata: name: hadoop spec: # 保证缓存运行时只运行在本地集群的节点中。 master: nodeSelector: demo-oss: "true" worker: nodeSelector: demo-oss: "true" fuse: nodeSelector: demo-oss: "true" replicas: 2 tieredstore: levels: - mediumtype: HDD path: /mnt/disk1 quota: 100G high: "0.99" low: "0.8"类别
参数
说明
Dataset
mountPoint
oss://<oss_bucket>/<bucket_dir>为挂载UFS的路径,路径中不需要包含Endpoint信息。fs.oss.endpoint
OSS Bucket的Endpoint信息,公网或私网地址皆可。
JindoRuntime
replicas
创建JindoFS集群的Worker数量。
mediumtype
缓存类型。定义创建JindoRuntime模板样例时,JindoFS暂时仅支持HDD、SSD、MEM的其中一种缓存类型。
path
存储路径。暂时只支持单个路径。当选择MEM做缓存时,需指定一个本地路径用于存储Log等文件。
quota
缓存最大容量,单位为GB。
high
存储容量上限大小。
low
存储容量下限大小。
执行以下命令,创建JindoRuntime和Dataset。
kubectl create -f resource.yaml执行以下命令,查看Dataset的部署情况。
kubectl get dataset hadoop预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE hadoop 210MiB 0.00B 100.00GiB 0.0% Bound 1h执行以下命令,查看JindoRuntime的部署情况。
kubectl get jindoruntime hadoop预期输出:
NAME MASTER PHASE WORKER PHASE FUSE PHASE AGE hadoop Ready Ready Ready 4m45s执行以下命令,查看PV和PVC状态。
kubectl get pv,pvc预期输出:
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE persistentvolume/hadoop 100Gi RWX Retain Bound default/hadoop 52m NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE persistentvolumeclaim/hadoop Bound hadoop 100Gi RWX 52m预期输出表明,Dataset和JindoRuntime已创建成功。
步骤五:创建容器应用体验加速效果
您可以通过创建容器应用来使用JindoFS加速服务,或者提交机器学习作业来体验相关功能。本文以创建一个容器应用多次访问同一数据,并通过对比访问时间为例展示JindoRuntime的加速效果。
使用以下内容,创建app.yaml文件。
apiVersion: v1 kind: Pod metadata: name: demo-app spec: containers: - name: demo image: fluidcloudnative/serving volumeMounts: - mountPath: /data name: hadoop volumes: - name: hadoop persistentVolumeClaim: claimName: hadoop执行以下命令,创建容器应用。
kubectl create -f app.yaml执行以下命令,查看文件大小。
kubectl exec -it demo-app -- bash du -sh /data/spark-3.0.1-bin-hadoop2.7.tgz预期输出:
209.7M /data/spark-3.0.1-bin-hadoop2.7.tgz执行如下命令,查看文件的拷贝时间。
time cp /data/spark-3.0.1-bin-hadoop2.7.tgz /test预期输出:
real 1m2.374s user 0m0.000s sys 0m0.256s预期输出表明,文件拷贝时间消耗了62s。
执行以下命令,查看此时Dataset的缓存情况。
kubectl get dataset hadoop预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE hadoop 209.74MiB 209.74MiB 100.00GiB 100.0% Bound 1h预期输出表明,209.7 MiB的数据已经缓存到了本地。
执行以下命令,删除之前的容器应用,新建相同的容器应用。
说明此操作是为了避免其他因素(例如Page Cache)对结果造成影响。
kubectl delete -f app.yaml && kubectl create -f app.yaml执行如下命令,查看文件拷贝时间。
kubectl exec -it demo-app -- bash time cp /data/spark-3.0.1-bin-hadoop2.7.tgz /test预期输出:
real 0m3.454s user 0m0.000s sys 0m0.268s预期输出表明,文件的拷贝时间为3s,拷贝时间缩短至原来的十八分之一。主要原因是由于文件已经被JindoFS缓存,所以第二次访问所需时间远小于第一次。
(可选)步骤六:清理环境
当不再使用数据加速功能时,您需要执行以下命令清理环境。
执行以下命令,删除JindoRuntime和应用容器。
kubectl delete jindoruntime hadoop执行以下命令,删除Dataset。
kubectl delete dataset hadoop