
摘要
当用户已有一个推荐/搜索/广告引擎服务,暂时不想迁移到PAI-REC,但是又想用PAI-REC的AB实验平台的时候,可参考本文完成AB test的系统接入,包括实验的配置、sdk调用、指标设置和计算等工作。我们提供了python和java两种语言方便用户把AB服务集成到自己的系统中。
1. 配置资源
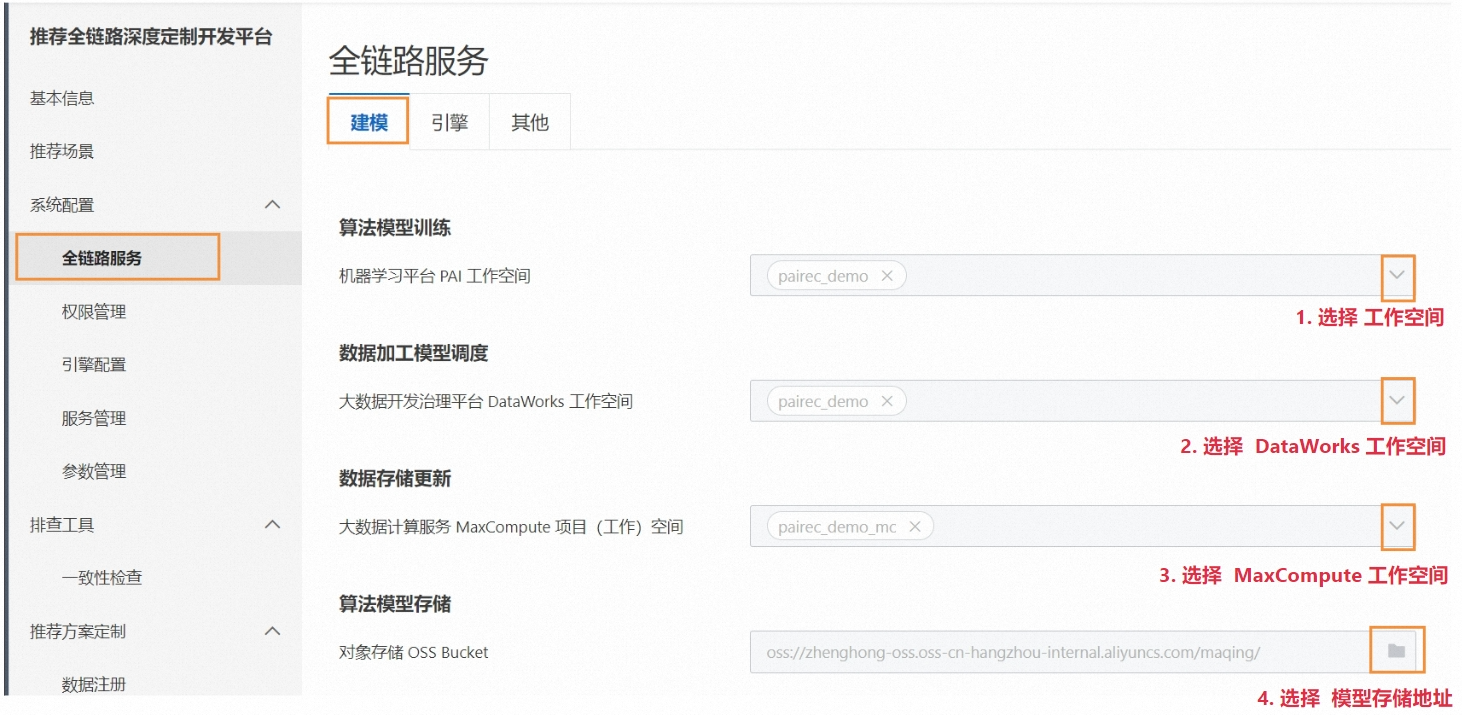
1.1. 进入 PAI-REC平台 首页
在 全链路服务 中,配置工作空间
配置说明:
PAI平台 & DataWorks平台 & MaxCompute工作空间的查询,可通过 阿里云官网的云服务进入对应的平台。
对象存储OSS Bucket: 进入OSS平台之后,可 先创建Bucket,再进行 PAI-REC平台的配置
1.2. 进入 MaxCompute 服务
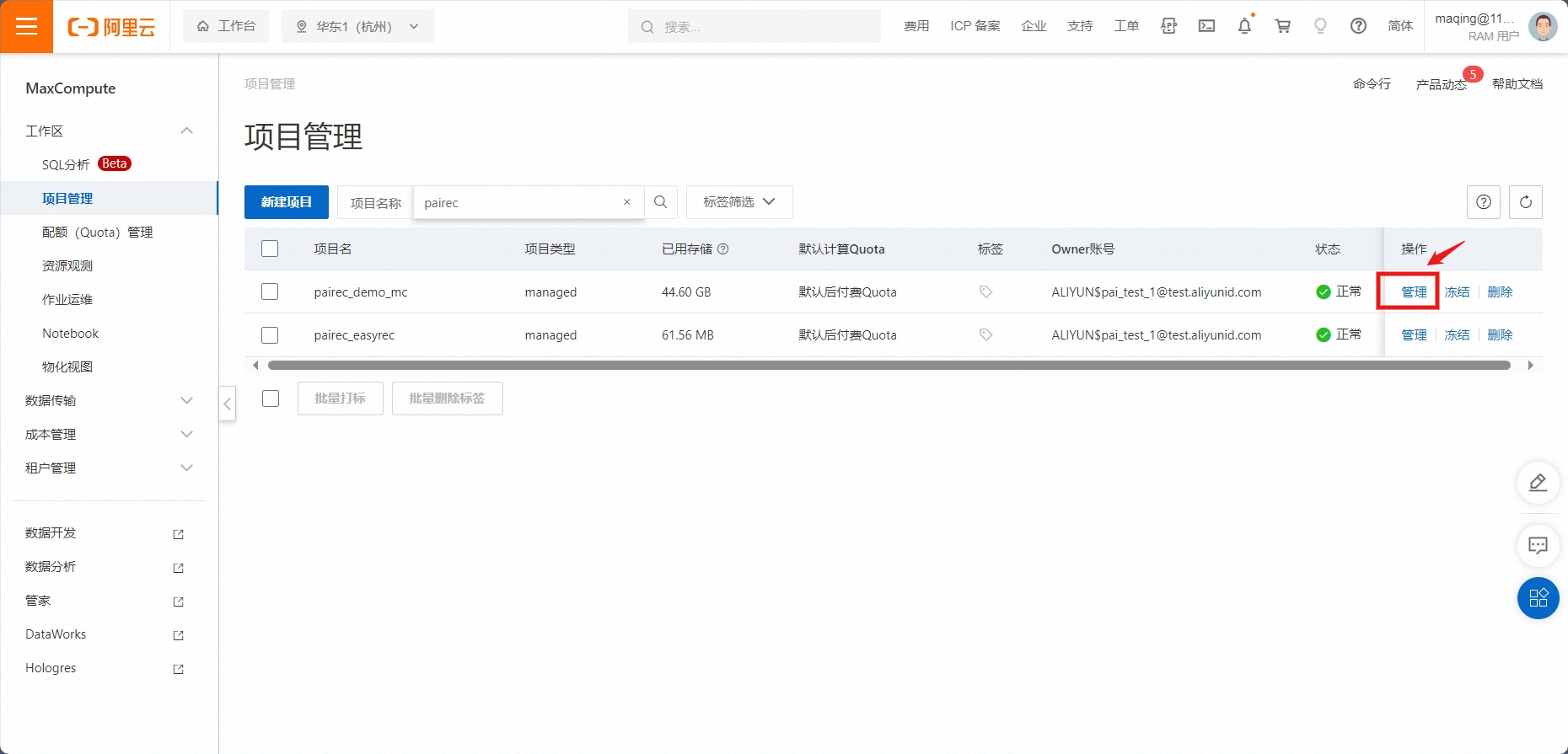
在 项目管理中, 搜索 需要使用的项目。
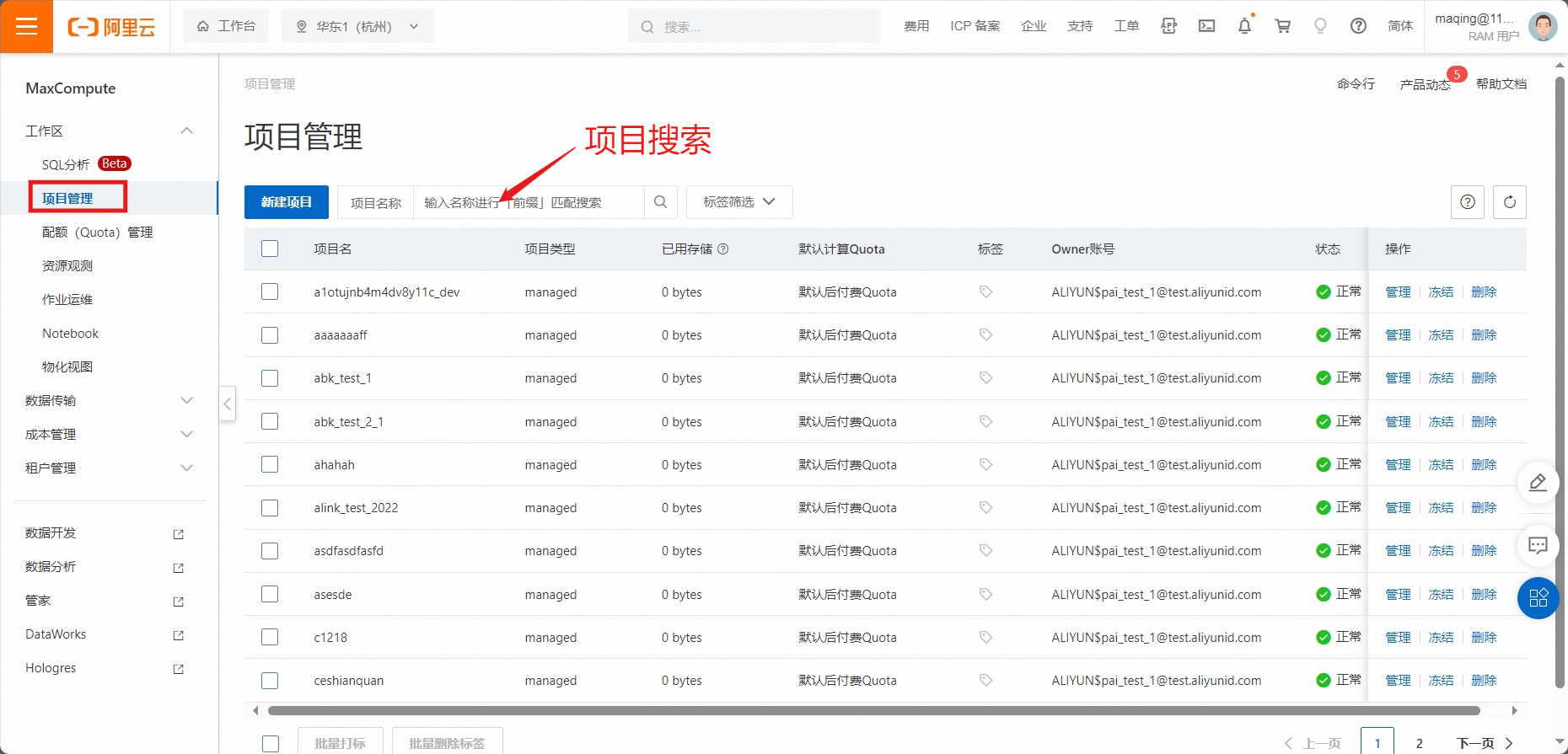
报错提示:如果没有搜索到项目,可尝试 切换到正确的地域,再进行操作。

点击管理项目,在相关的资源产品 MaxCompute 中,您需要给PAI-REC服务授予直接访问、写入这些资源的权限。
具体详情可参考:PAI-REC授权
2. 创建场景
2.1. 进入 推荐场景 模块
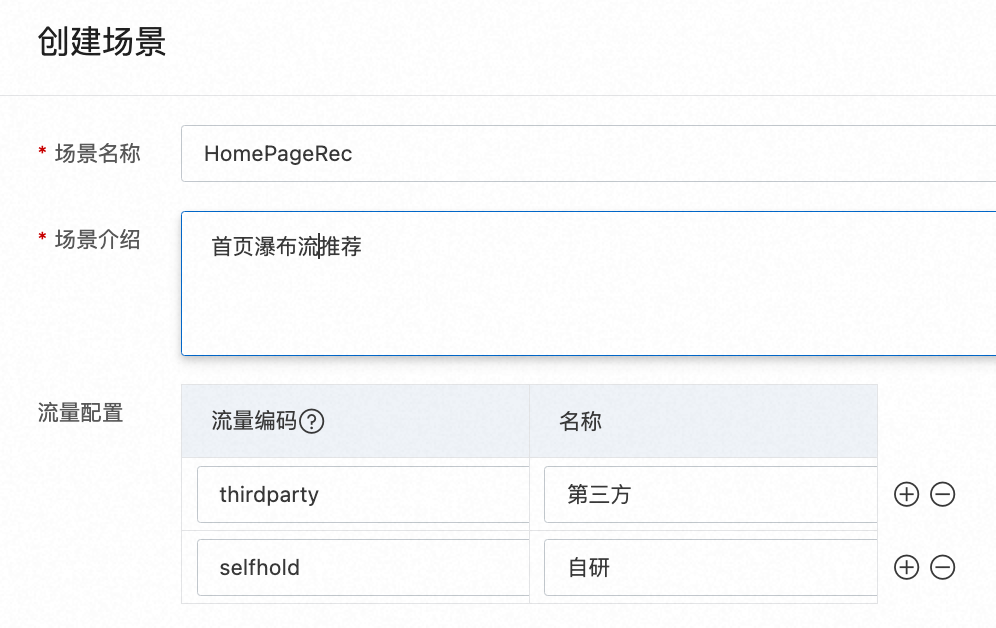
创建场景 ----> 自定义场景名称与场景介绍
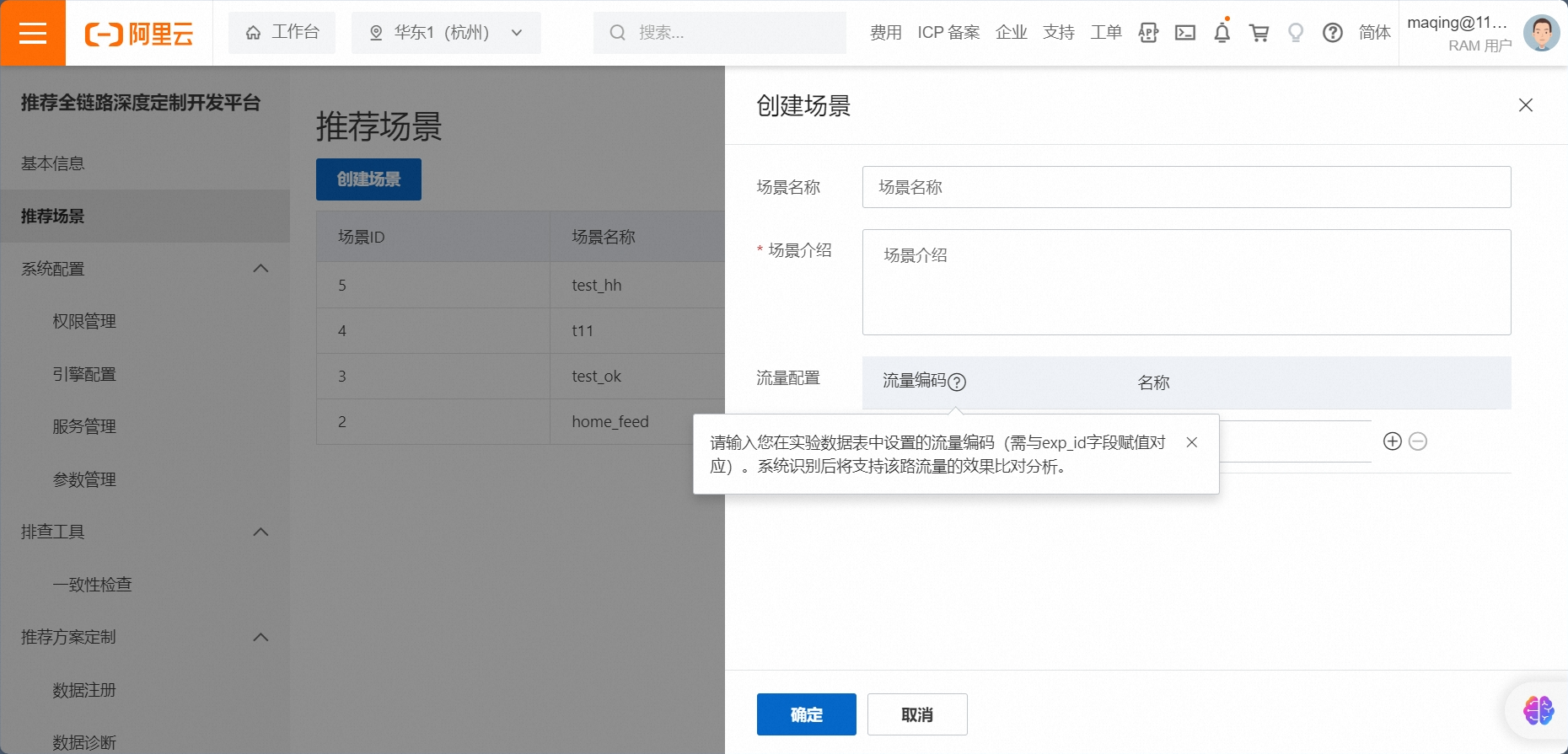
场景名称:推荐设置 能够说明推荐场景的位置的名称。
场景介绍:对场景名称进行补充解释。
流量配置说明:
适用用户:不完全使用 PAI-REC系统 推荐请求的用户。
使用场景:当用户自己已有推荐系统的时候,在刚开始会把这个场景从切10%到20%的推荐流量给PAI-REC系统。当PAI-REC的推荐效果达到预期之后再逐渐增加流量。
配置方式:
假设用户有自建的推荐流量 或 使用了第三方的推荐平台,可以自定义 流量编码 作为标识流量,后期与PAI-REC平台的实验效果进行对比。
用户需要在日志中埋点标记,建议记录到exp_id字段,与PAI-REC的埋点要求一致。
3. 配置实验
概述:根据业界常用a/b test方案设计了实验室、实验层、实验组、实验,实验室包含了实验层,实验层包含实验组,实验组中包含了实验。具体概念解释可参考文档:基本概念
注意:在开始进行实验之前,需要与相关的产品或者项目经理 确认实验要验证的改动点。
以下是实验配置参考。
3.1. 新建实验室
选择对应的环境,与推荐场景
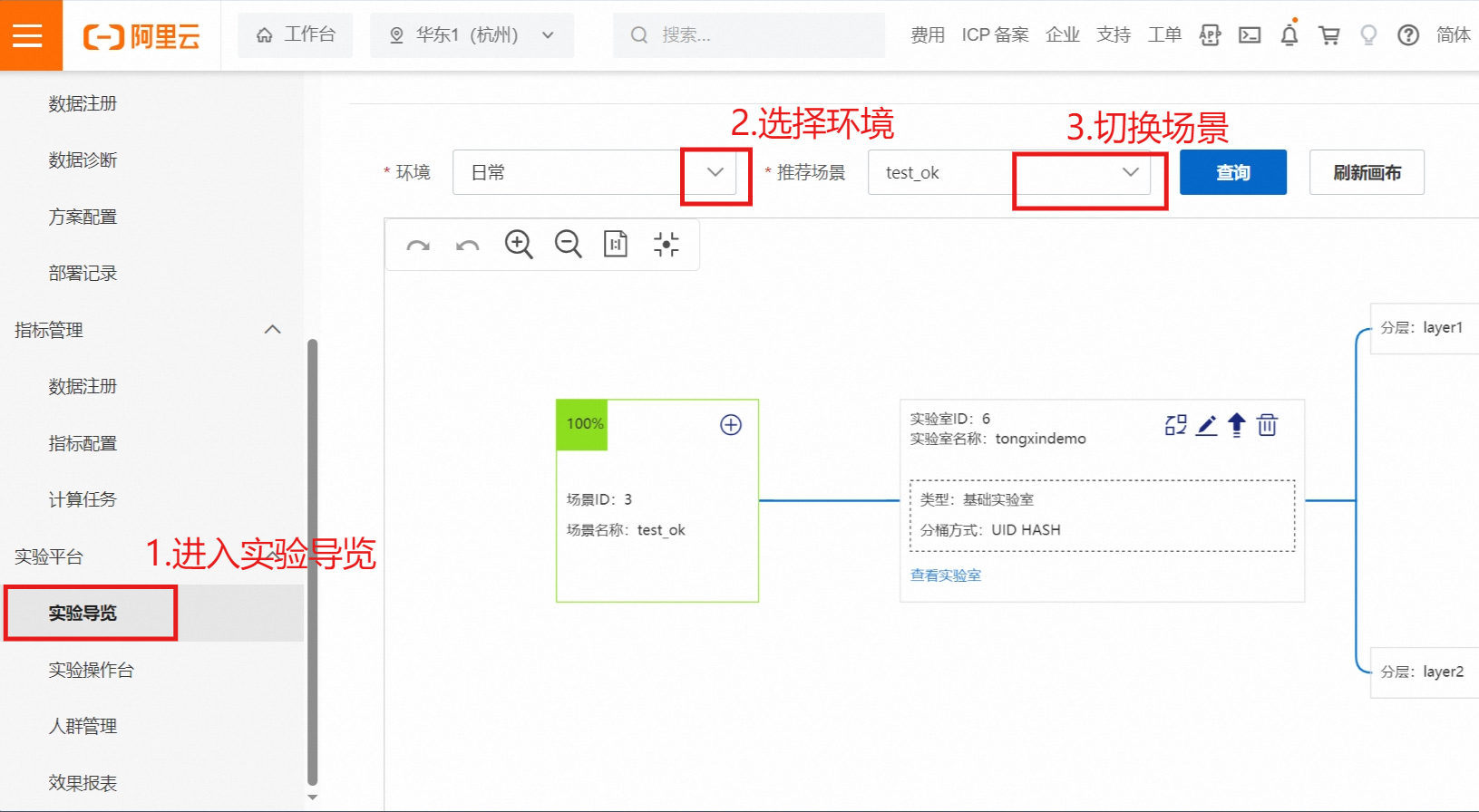
点击新建实验室
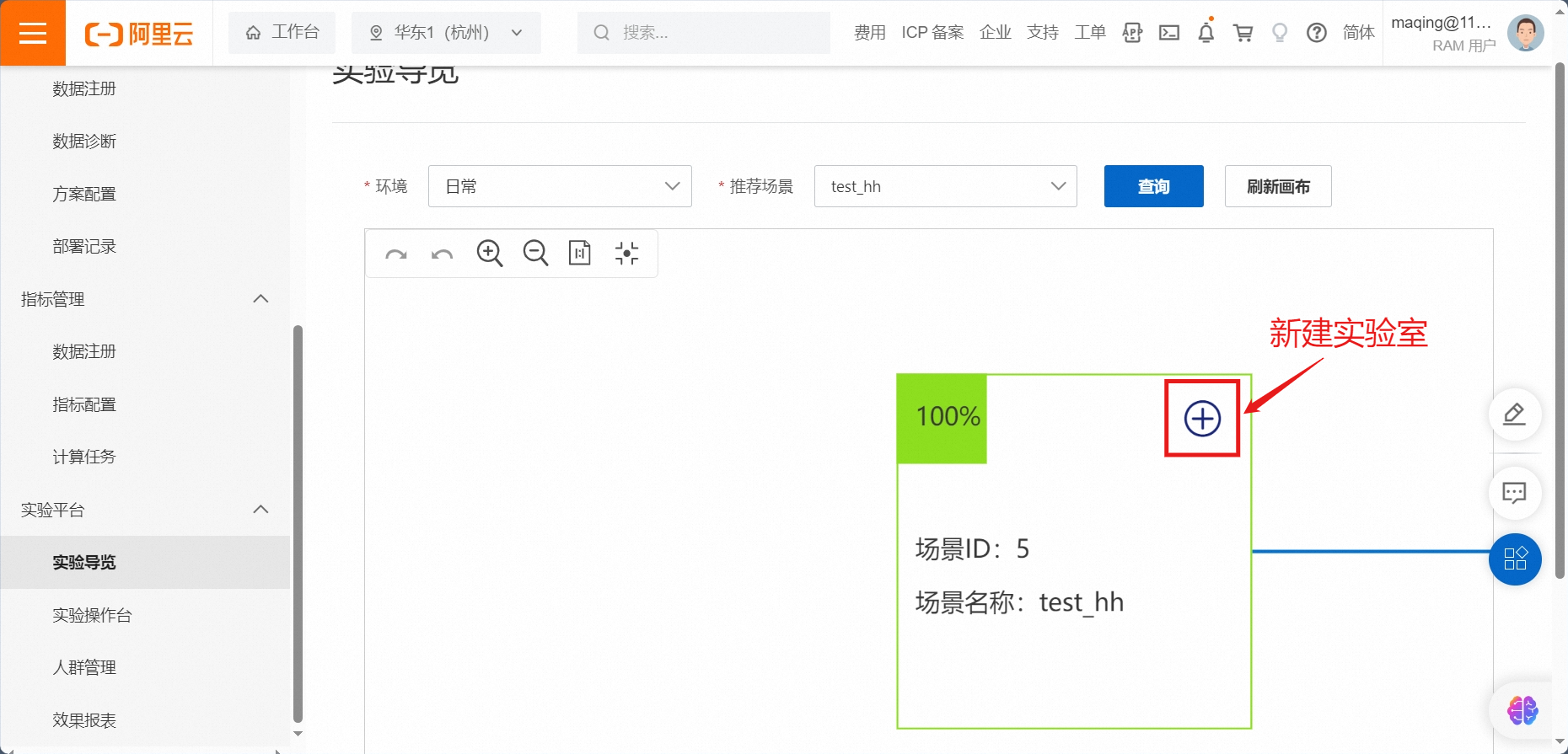
完成实验室配置 & 配置说明
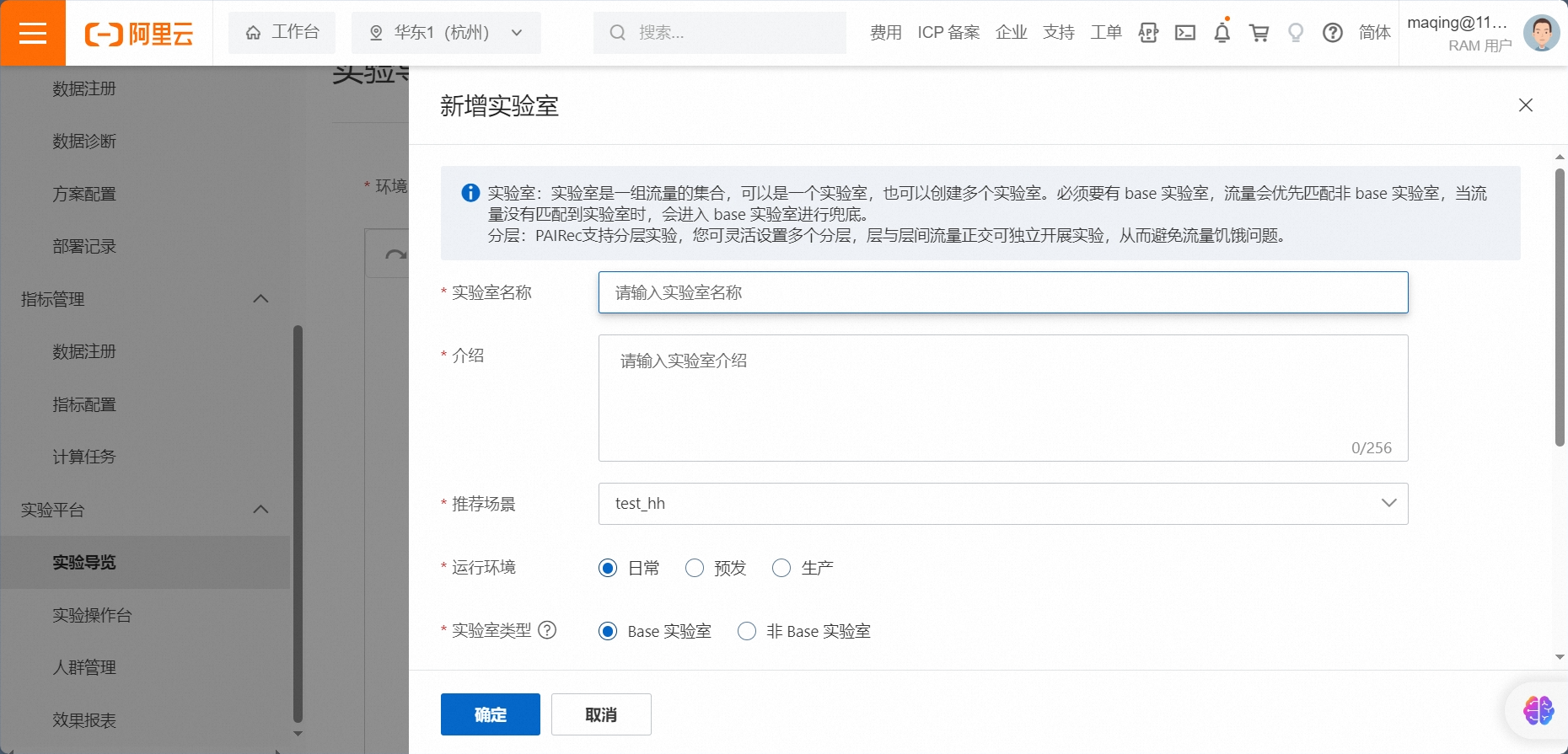
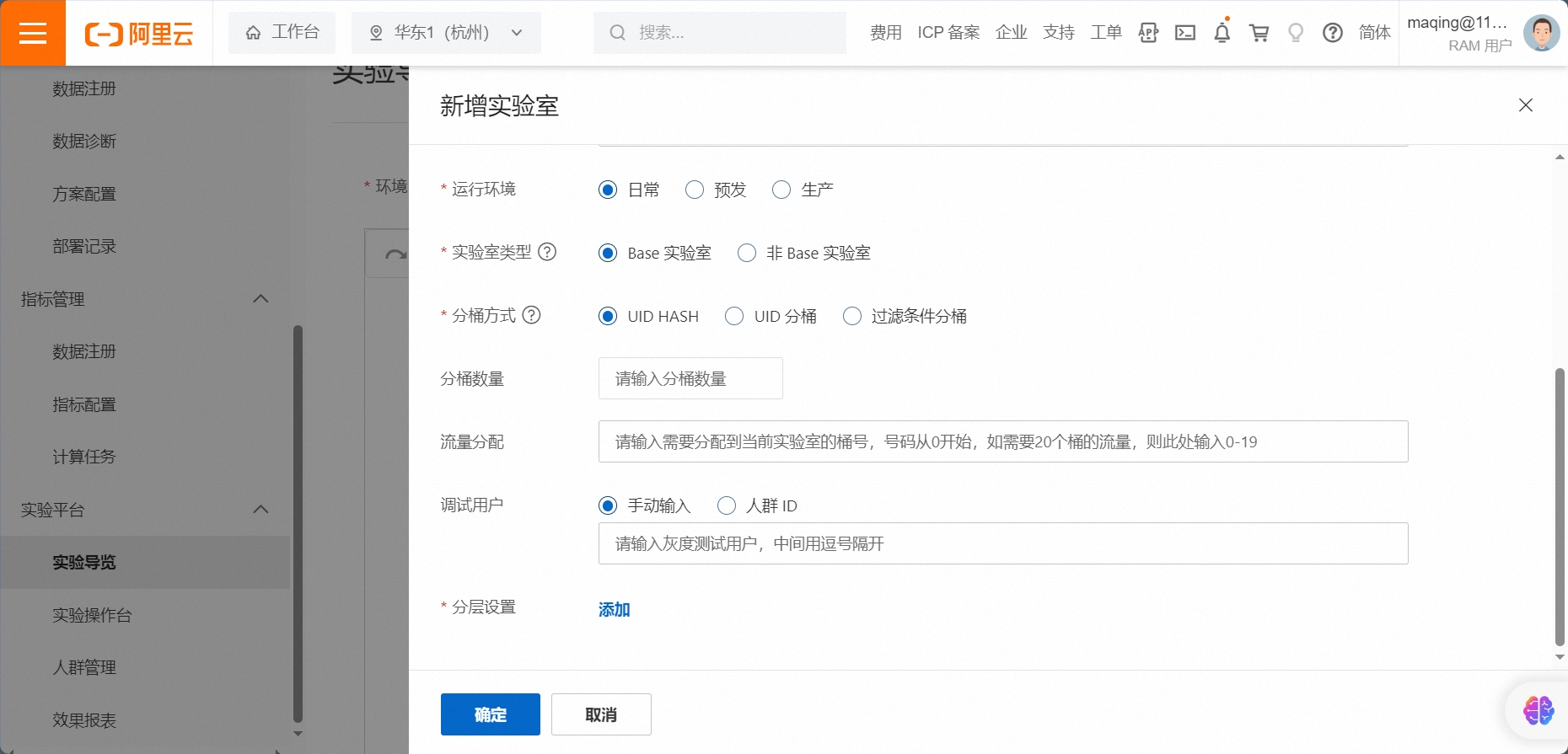
配置说明:
实验室类型
Base实验室:必须有一个base实验室,可以没有非base实验室。
非Base实验室:优先匹配非 base 实验室。当base实验室的模型比较简单,而非base实验室的模型比较复杂的时候,可以设置两个实验室。base实验室也可以完全用一个热门随机兜底逻辑来实现。
分桶方式
UID HASH :根据 uid 的 hash 值分桶
UID分桶 :根据 uid 的末尾数字分桶
过滤条件分桶 :kv 表达式分桶,如 gender=man
分桶数量:此实验室分得的桶数,总数为100
流量分配
分得的桶的编号,可以设置为0-99
分层:实验层一般设置recall(召回)、filter(过滤)、coarse_rank(粗排)、rank(排序)等
调试用户:调试用户可以不经过匹配,直接进入此实验室
手动输入:可以输入多个,以逗号分隔
人群 ID:一组 uid 的集合,需要提前在【人群管理】中创建
3.2. 新建实验组
在每一个分层下,可以设置多个实验组。在每一个实验组里,也可以设置多个实验。
原因:当有多个 算法工程师做召回或者排序实验的时候,我们可以通过划分实验组,让他们互相不会干涉。
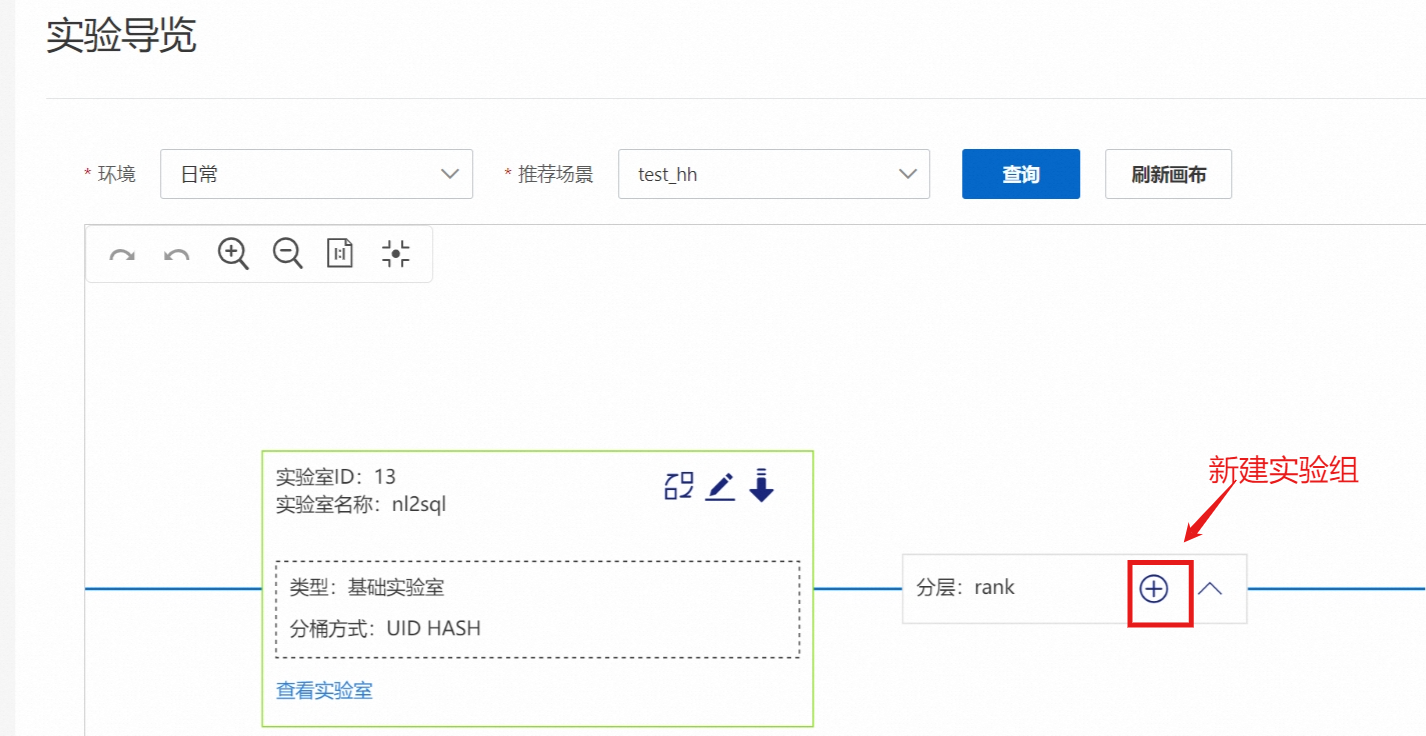
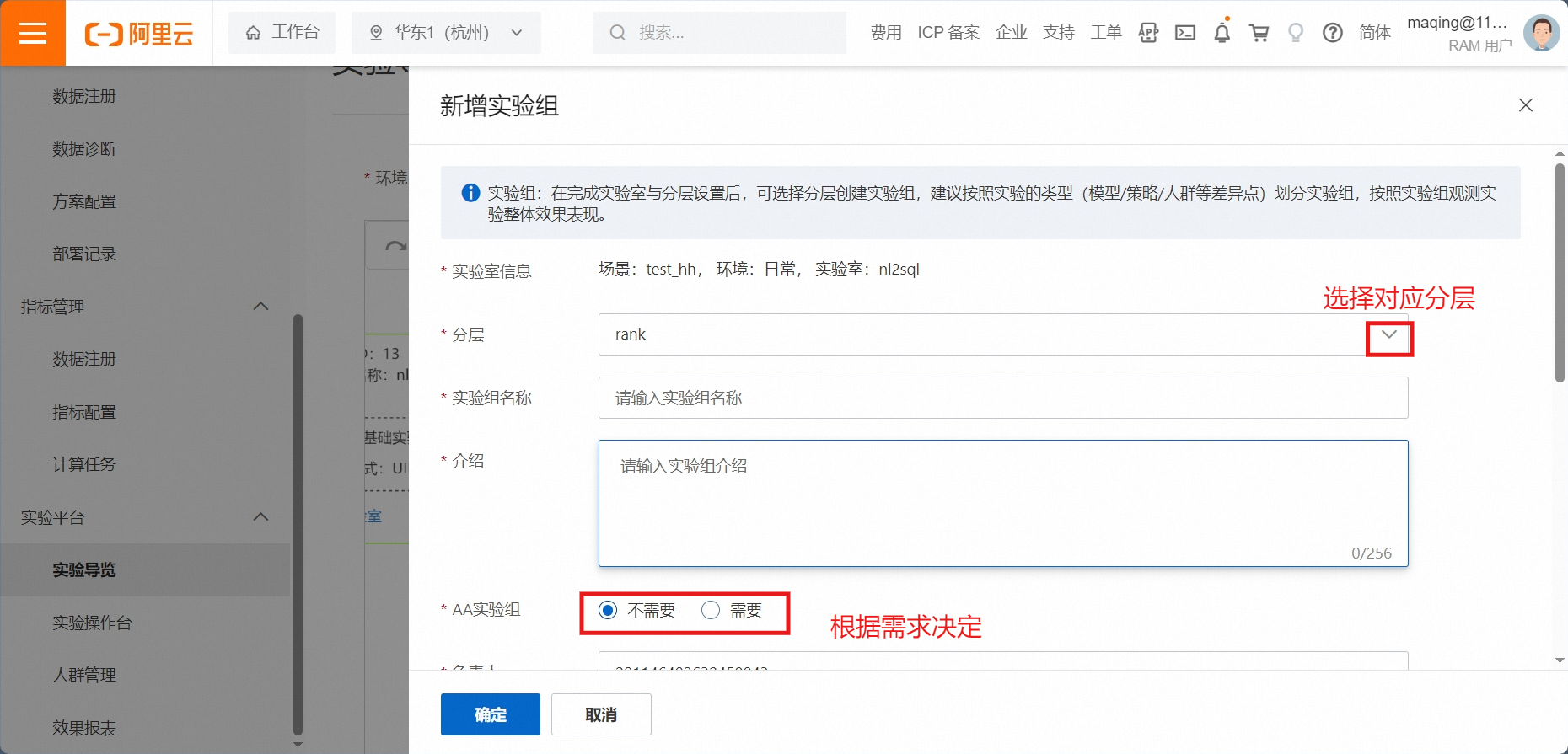
配置说明:
AA实验:
实际A/B实验中可能出现抽样不均的情况,结果可能会产生偏差,为了保证实验数据的变化仅仅是实验本身引起的,可以一次性抽取4,5组流量,选择任意两组不加策略空跑,监控核心指标数据,选取两组数据最接近的进行实验。用户可根据需求确定。
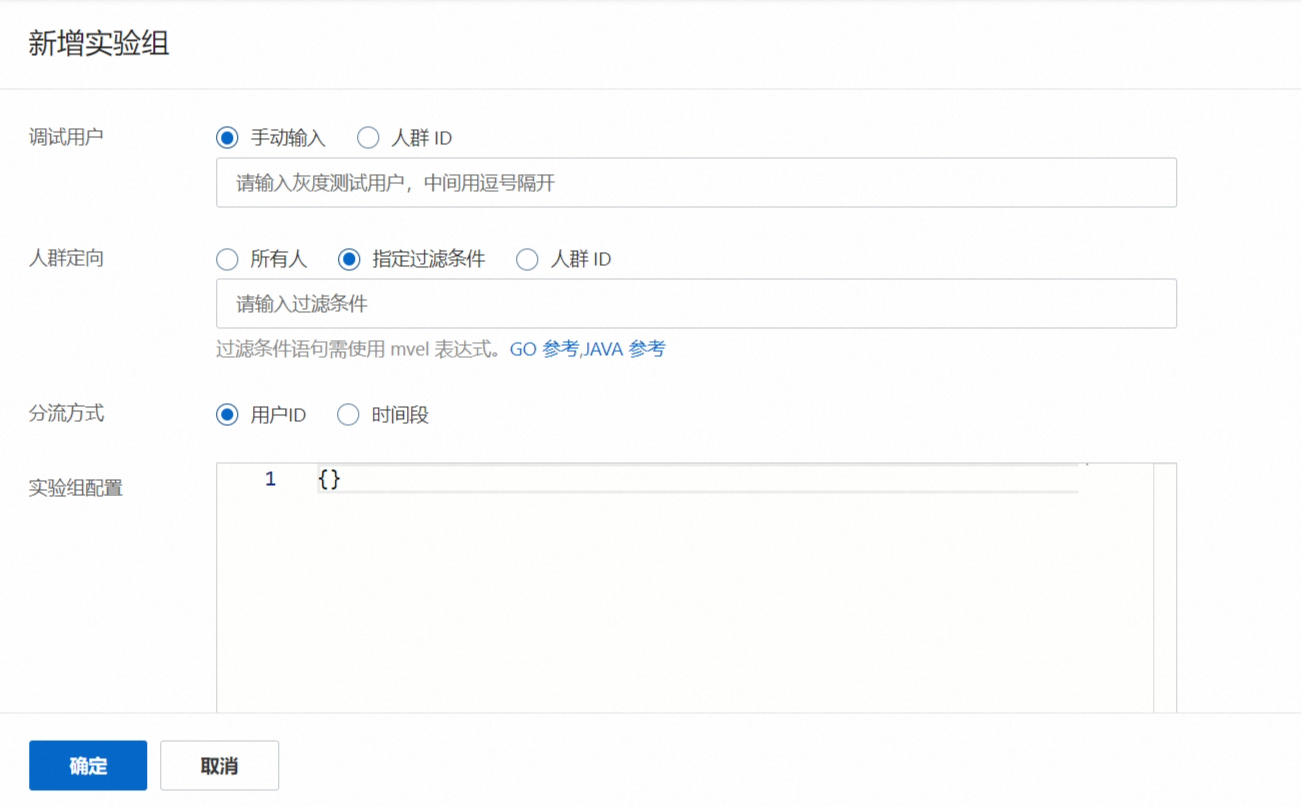
配置说明:
人群定向:在调试用户选定的基础下,再次对用户进行筛选。用户的选择需要具有代表性,可以使用新老用户交替来使用实验,才能反馈出较全面的结果。
调试用户
灰度测试用户:将本次实验首先给这部分灰度测试用户使用,通过这些测试用户的使用结果和反馈来修改完善实验。
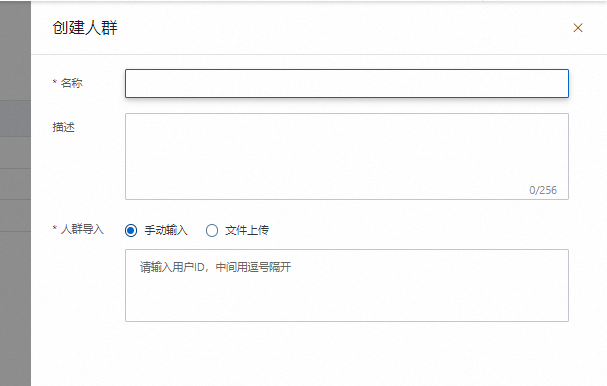
人群ID:您可以创建多个人群规则,分别用于不同的实验,让指定的人群可以进入到指定的实验流量当中,达成测试或观察效果的目的。
若显示无选项,在实验平台下的人群管理中,创建人群即可。
其中人群ID可选择手动输入或 Excel导入两种方式,创建完成后,再操作新增实验组选择人群ID。
3.3. 新建实验
配置说明:
流量分配:对于不同的情况,可以选择不同的分配流量策略。
不影响用户体验:例如UI实验,文案类实验等,一般可以均匀分配流量,可以快速得到实验结论。
不确定性较强的实验:例如新产品上线,新版本一般需要小流量实验,尽量减少用户体验影响,在允许的时间内得到结论
希望收益最大化的实验:例如运营活动等等,尽可以将效果最大化,一般需要大流量实验,留出小部分对照组用于评估ROI
根据以下提示,进入新建实验配置。
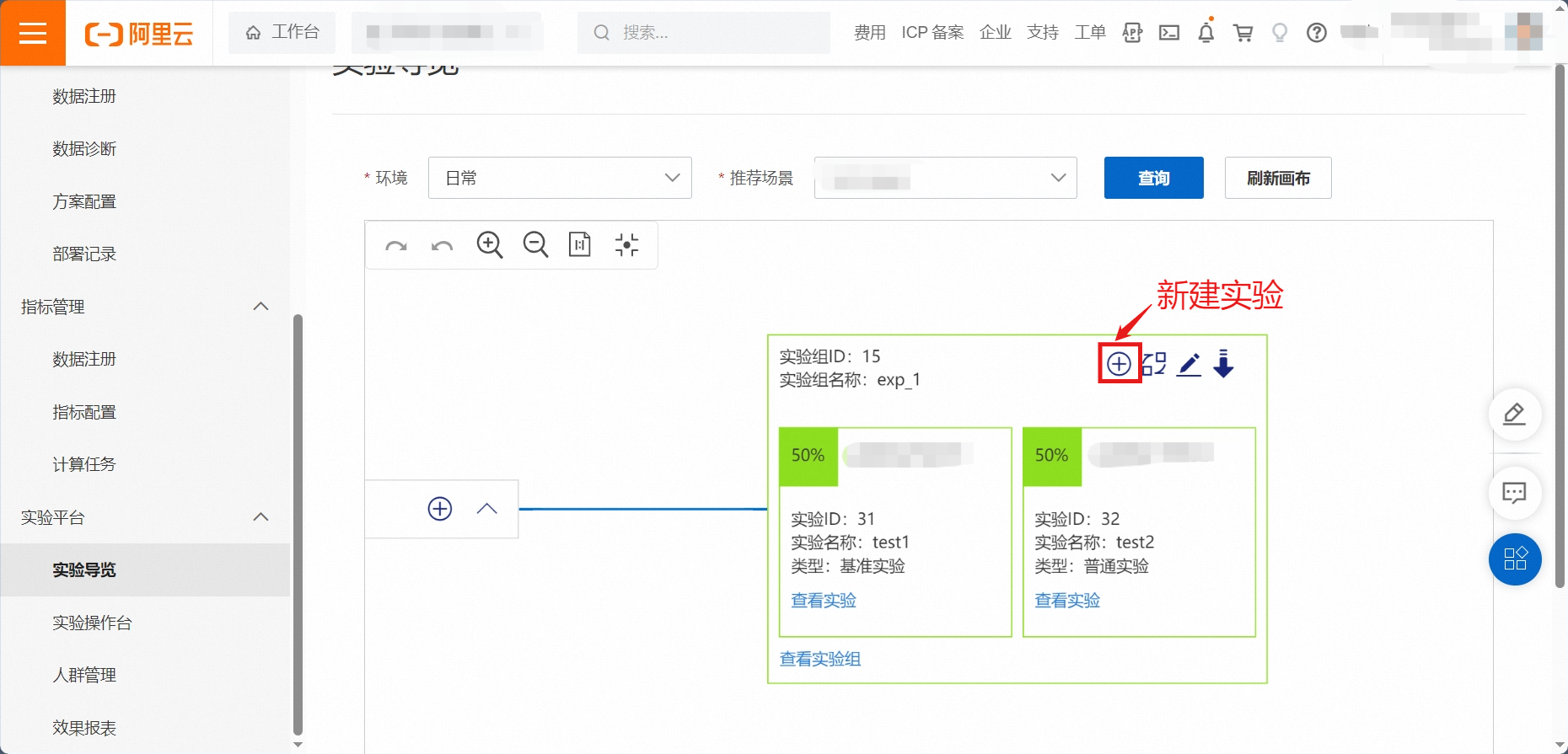

首先,首次新增实验 默认 基准实验。
基准实验:一组用户会被随机分到实验组或对照组,基准实验作为对照组。设置好之后,点击保存。
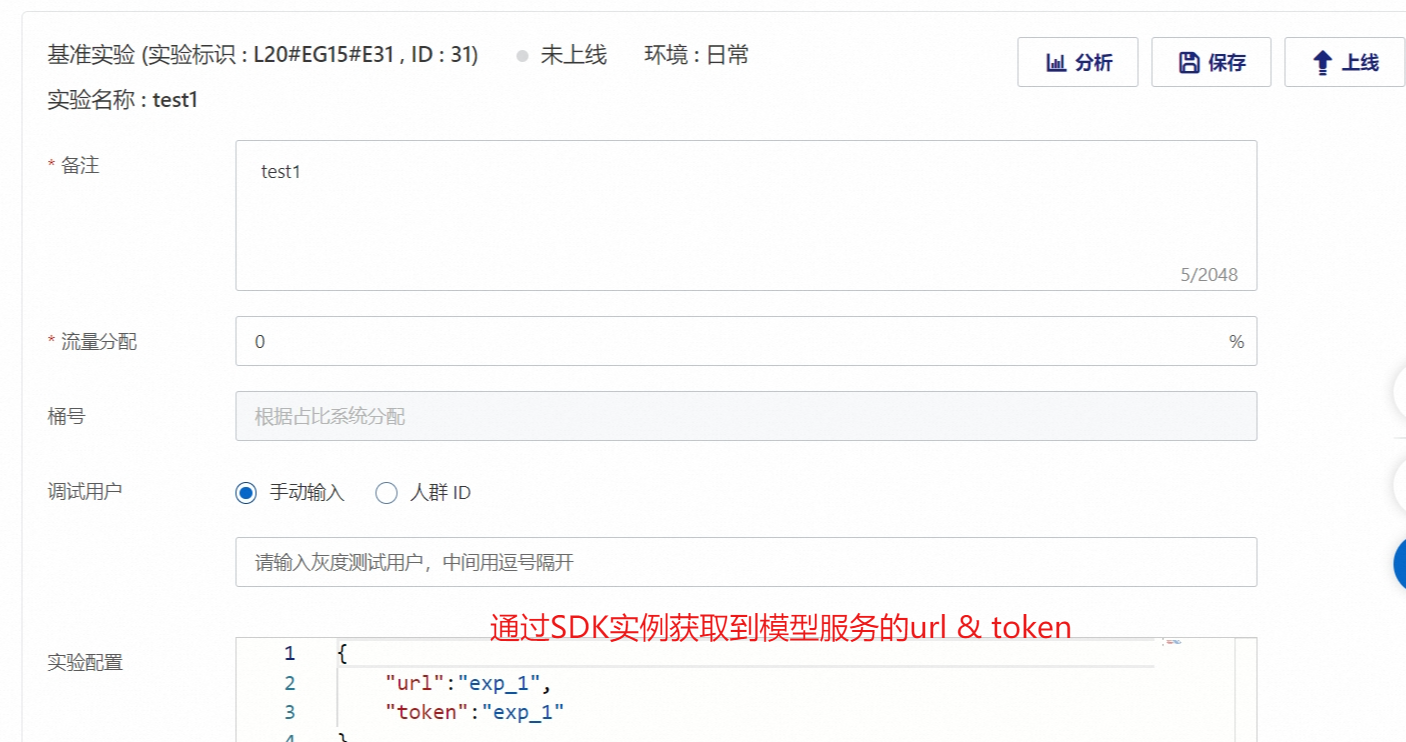
基本实验:一组用户会被随机分到实验组或对照组,基本实验作为对照组与基准实验配置一致,设置好之后,点击保存。
4. 调用SDK 以及数据埋点
4.1. Python 调用
4.1.1. 环境准备
用户需要配置 Python 环境,安装 pycharm 软件工具。可参考以下文档:Pycharm及python安装详细教程
打开 cmd 命令提示窗口,安装所需的模块包,使用以下命令。
pip install https://aliyun-pairec-config-sdk.oss-cn-hangzhou.aliyuncs.com/python/aliyun_pairec_config_python_sdk-1.0.0-py2.py3-none-any.whl注意:
由于所需的模块包不是开源,所以在 pycharm 的安装模块的方式无法达到效果,可能会导致与正确的模块包冲突报错。
如果出现 pip 需要更新的情况,先更新,再安装模块。
出现 TimeOUT 超时报错,是由于网络不好的原因,重新运行命令。
4.1.2. 进入 pycharm
新建一个运行 python SDK 的 py 程序。
参考以下文档服务初始化,参考步骤获取到AccessKeyID 和AccessKeySecret
基于用户数据的保密性,推荐将 账号和密码添加到 系统变量中,使用 python 的 函数方法读取即可。
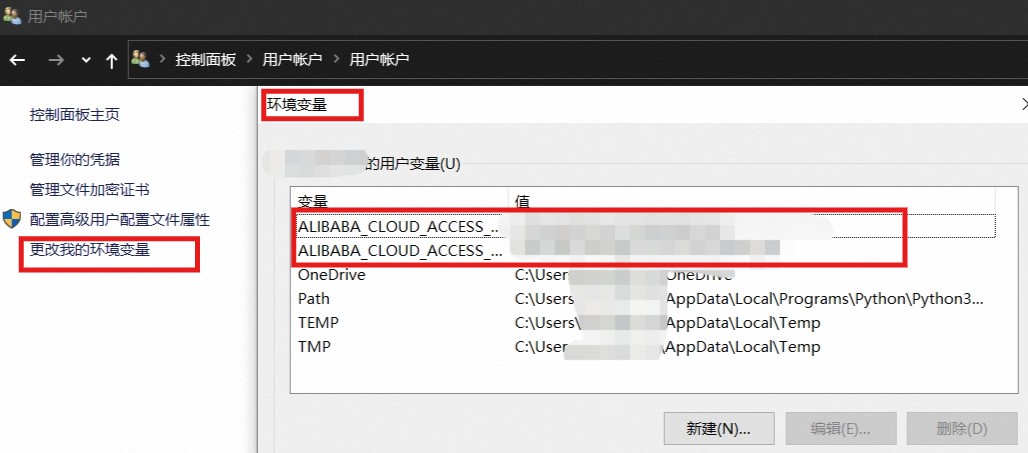
# 新建两个变量,用于存储ID和密码
ALIBABA_CLOUD_ACCESS_KEY_ID
ALIBABA_CLOUD_ACCESS_KEY_SECRET将以下代码,拷贝到 py 程序中 ,按照下一步提示进行内容替换。
from alibabacloud_tea_openapi.models import Config
from api.api_scene import SceneApiService
from api.api_experiment_room import ExperimentRoomApiService
from api.api_layer import api_layer
from api.api_experiment_group import ExperimentGroupApiService
from api.api_experiment import ExperimentApiService
from client.client import ExperimentClient
from model.experiment import ExperimentContext
from api.api_crowd import CrowdApiService
from alibabacloud_pairecservice20221213.client import Client
from common.constants import ENVIRONMENT_PRODUCT_CONFIG_CENTER
from common.constants import ENVIRONMENT_PREPUB_CONFIG_CENTER
from common.constants import ENVIRONMENT_DAILY_CONFIG_CENTER
import os
# 设置相关信息
instance_id = "实例ID" #填写:实例ID
region = "地域" #填写:地域
access_id = os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID']
access_key = os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET']
if __name__ == '__main__':
# environment 为枚举值:ENVIRONMENT_PRODUCT_CONFIG_CENTER(生产),ENVIRONMENT_PREPUB_CONFIG_CENTER(预发),ENVIRONMENT_DAILY_CONFIG_CENTER(日常)
experiment = ExperimentClient(instance_id=instance_id, region=region,access_key_id=access_id,access_key_secret=access_key,environment=ENVIRONMENT_PRODUCT_CONFIG_CENTER)
# 构造请求上下文,其中 filter_params 可为空
experiment_context = ExperimentContext(request_id="请求ID",uid="用户ID",filter_params={})
# 获取实验的匹配结果,需传入场景名和上下文
experiment_result = experiment.match_experiment("场景名称", experiment_context)
# 打印匹配结果的信息
print('info', experiment_result.info())
# 打印匹配到的 exp_id
print('exp_id', experiment_result.get_exp_id())
# 这里可以获取实验中配置的参数
print(experiment_result.get_experiment_params())
print(experiment_result.get_experiment_params().get('url', 'not exist'))
print(experiment_result.get_experiment_params().get('token', 'not exist'))配置环境变量报错:
如果访问的环境变量不存在,将会报错,引发一个 KeyError, 解决方法:在运行实例的代码空白处可右击,查看运行配置中系统变量是否加载进去了,如果没有,重启py项目即可
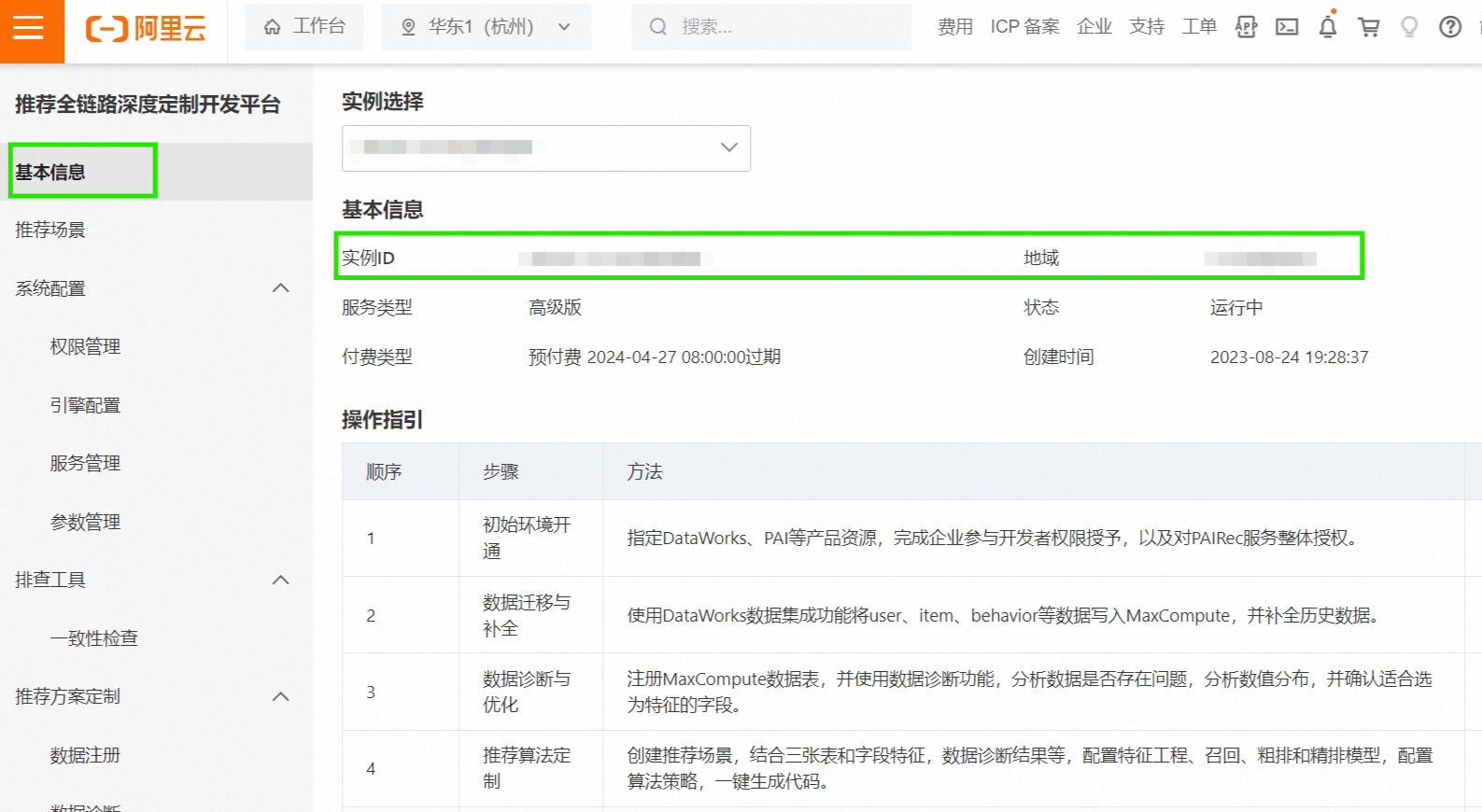
替换以下用户信息。(代码中有提示需要注释)
在 AI-REC平台中的基本信息中,可以查看到配置信息:实例ID,地域
request_id & uid: request_id 表示请求 id, 用户通过自定义逻辑,例如:自增加ID,UUID等逻辑,生成请求ID
在推荐场景栏中,可查看到需要使用的场景名称。
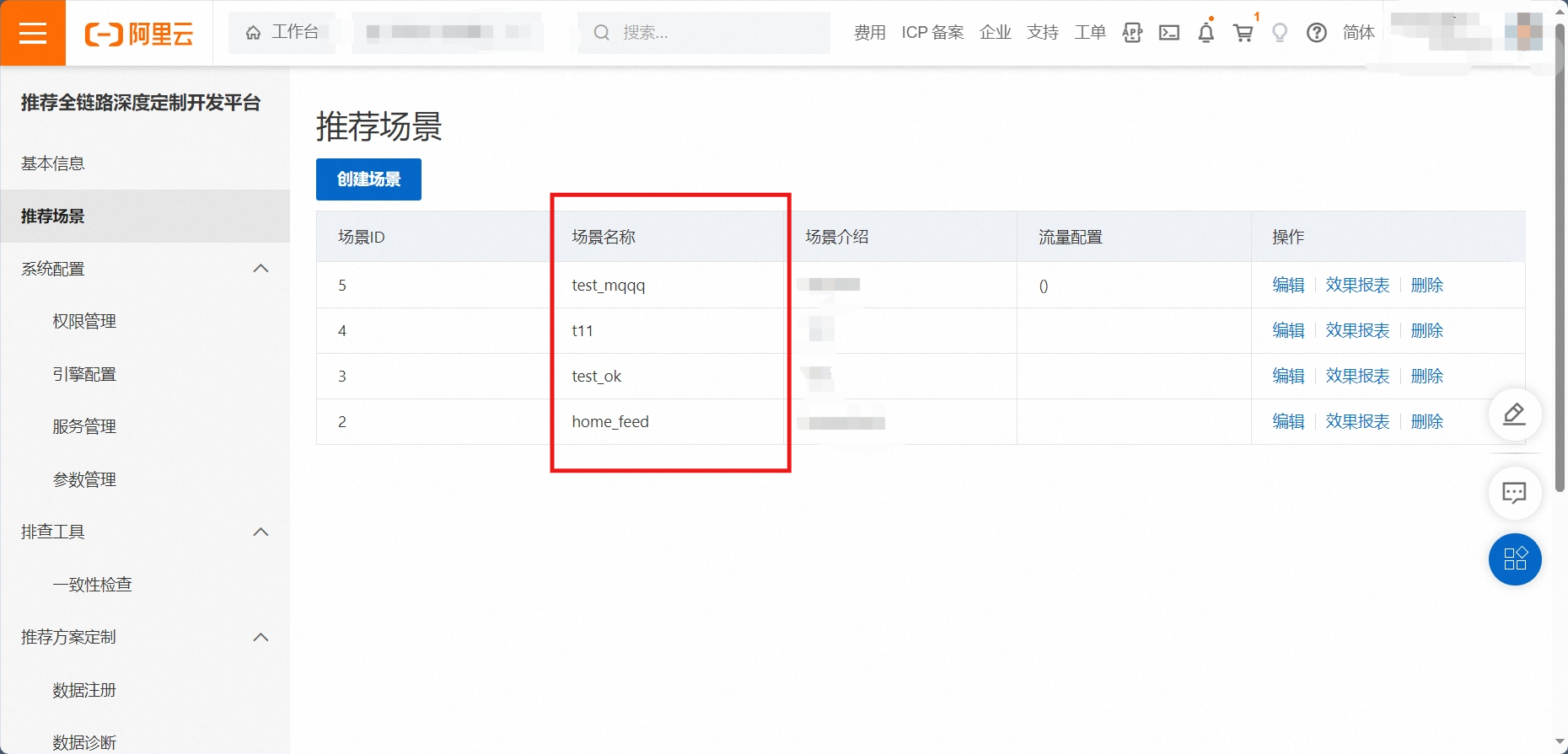
运行替换后的 py 程序,可获取到 url 与 token.
4.2. java 调用
package com.aliyun.openservices.pairec;
import com.aliyun.openservices.pairec.api.ApiClient;
import com.aliyun.openservices.pairec.api.Configuration;
import com.aliyun.openservices.pairec.common.Constants;
import com.aliyun.openservices.pairec.model.ExperimentContext;
import com.aliyun.openservices.pairec.model.ExperimentResult;
public class ExperimentTest {
static ExperimentClient experimentClient;
public static void main(String[] args) throws Exception {
String regionId = "地域";
String instanceId = System.getenv("实例ID"); // pai-rec instance id
String accessId = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"); // aliyun accessKeyId
String accessKey = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET"); // aliyun accessKeySecret
Configuration configuration = new Configuration(regionId, accessId, accessKey, instanceId);
// set experiment environment
configuration.setEnvironment(Constants.Environment_Product_Desc);
ApiClient apiClient = new ApiClient(configuration);
experimentClient = new ExperimentClient(apiClient);
// init client
experimentClient.init();
// set expeirment context
ExperimentContext experimentContext = new ExperimentContext();
experimentContext.setUid("用户ID");
experimentContext.setRequestId("请求ID");
// match experiment, use scence and experimentContext
ExperimentResult experimentResult = experimentClient.matchExperiment("场景名称", experimentContext);
// exp id
System.out.println(experimentResult.getExpId());
// exp log info
System.out.println(experimentResult.info());
// get experiment param value
System.out.println(experimentResult.getExperimentParams().getString("rank_version", "not exist"));
System.out.println(experimentResult.getExperimentParams().getString("version", "not exist"));
System.out.println(experimentResult.getExperimentParams().getString("recall", "not exist"));
System.out.println(experimentResult.getExperimentParams().getDouble("recall_d", 0.0));
// get experiment param value by pecific layer name
//通过 特定层的名称 获取到实验参数值
System.out.println(experimentResult.getLayerParams("recall").getString("rank_version", "not exist"));
System.out.println(experimentResult.getLayerParams("rank").getString("version", "not exist"));
}
}5. 设计实验指标
由 数据分析师 设计实验中所需要观测的一些核心指标,例如:点击率 或者转化率等等
5.1. 进入指标管理,数据注册模块
将maxcompute表 与a/b test实例关联,其中数据表名称为自定义名称,可以起个与业务相关的表名。
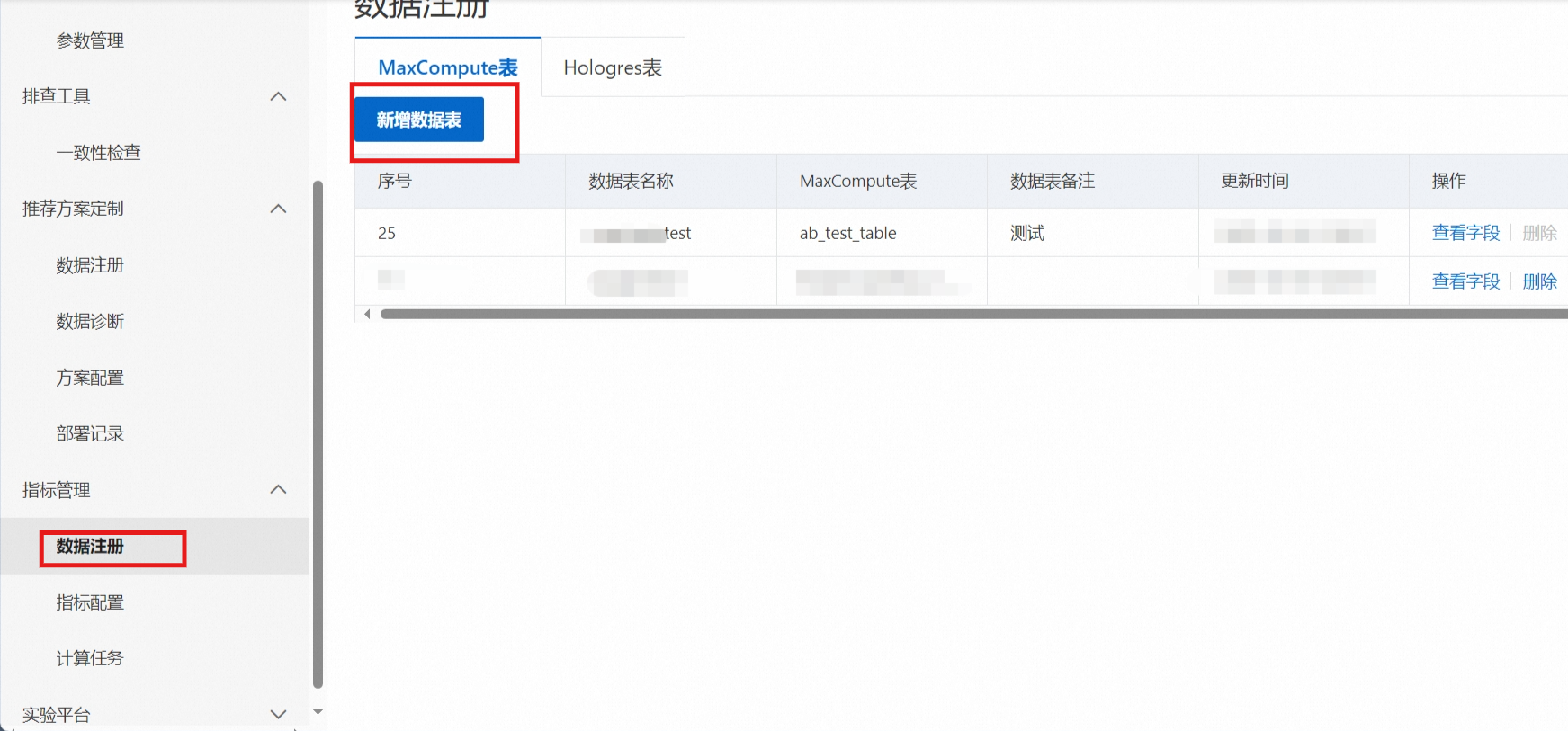
选择包含必填字段的数据表,详细格式请参考文档:数据注册与字段配置
若用户没有包含所有必填字段的 MaxCompute 数据表,则需要新建,以下提供新建步骤参考:
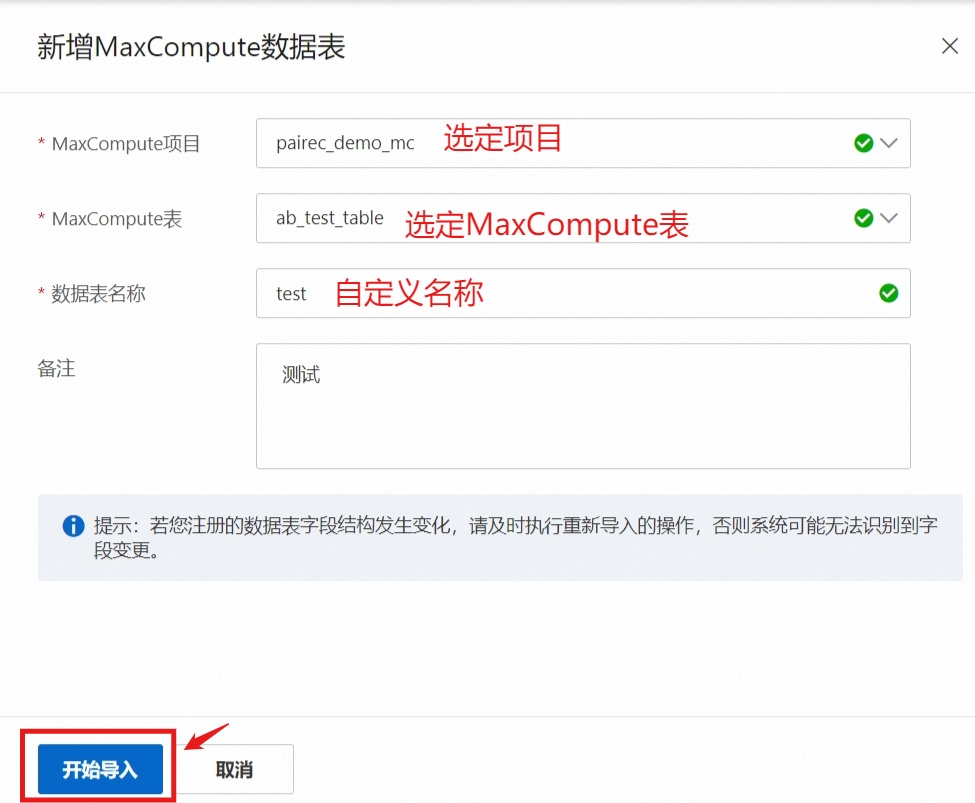
注册好的数据表会自动出现在列表中,您可以点击查看字段按钮查看数据表中的字段,对字段和相关信息进行核对或编辑。
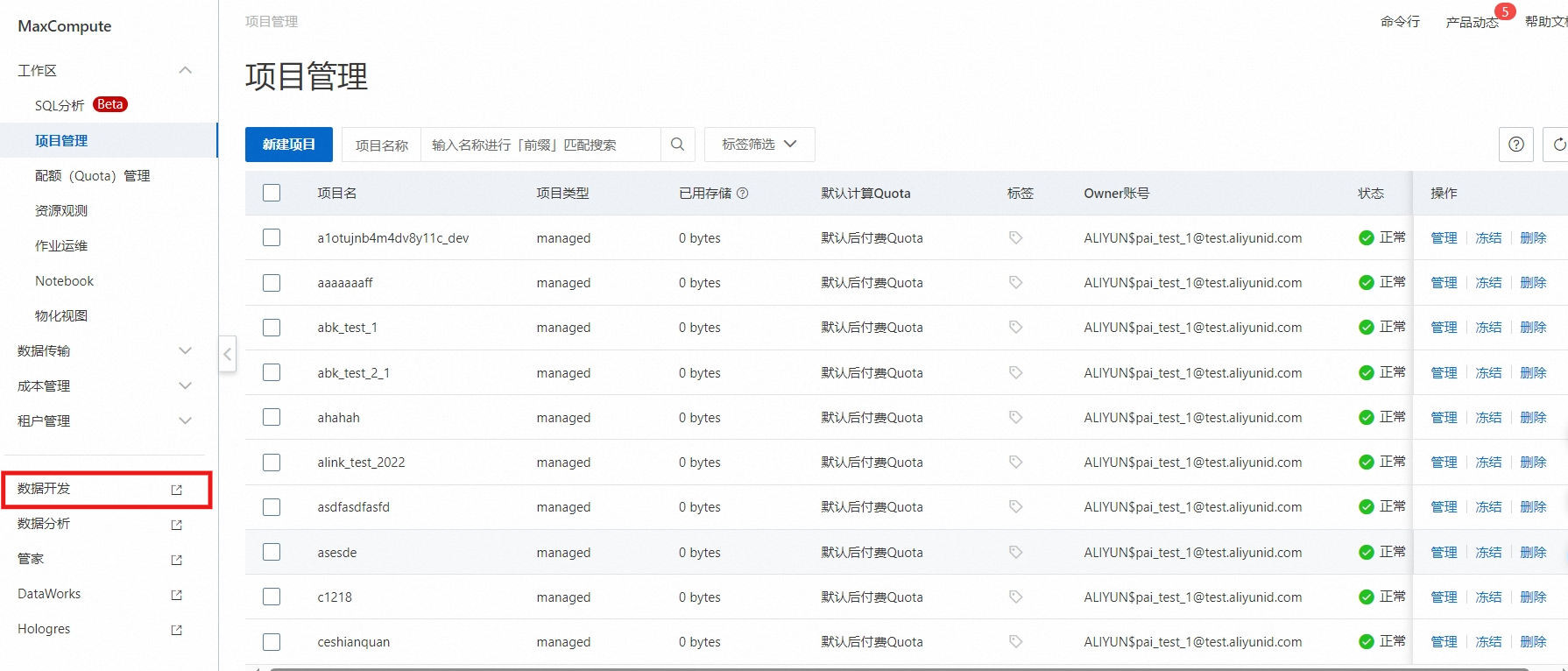
5.1.1. MaxCompute 表中没有必填字段的情况
需要进入 MaxCompute控制台,新建符合要求的数据表。
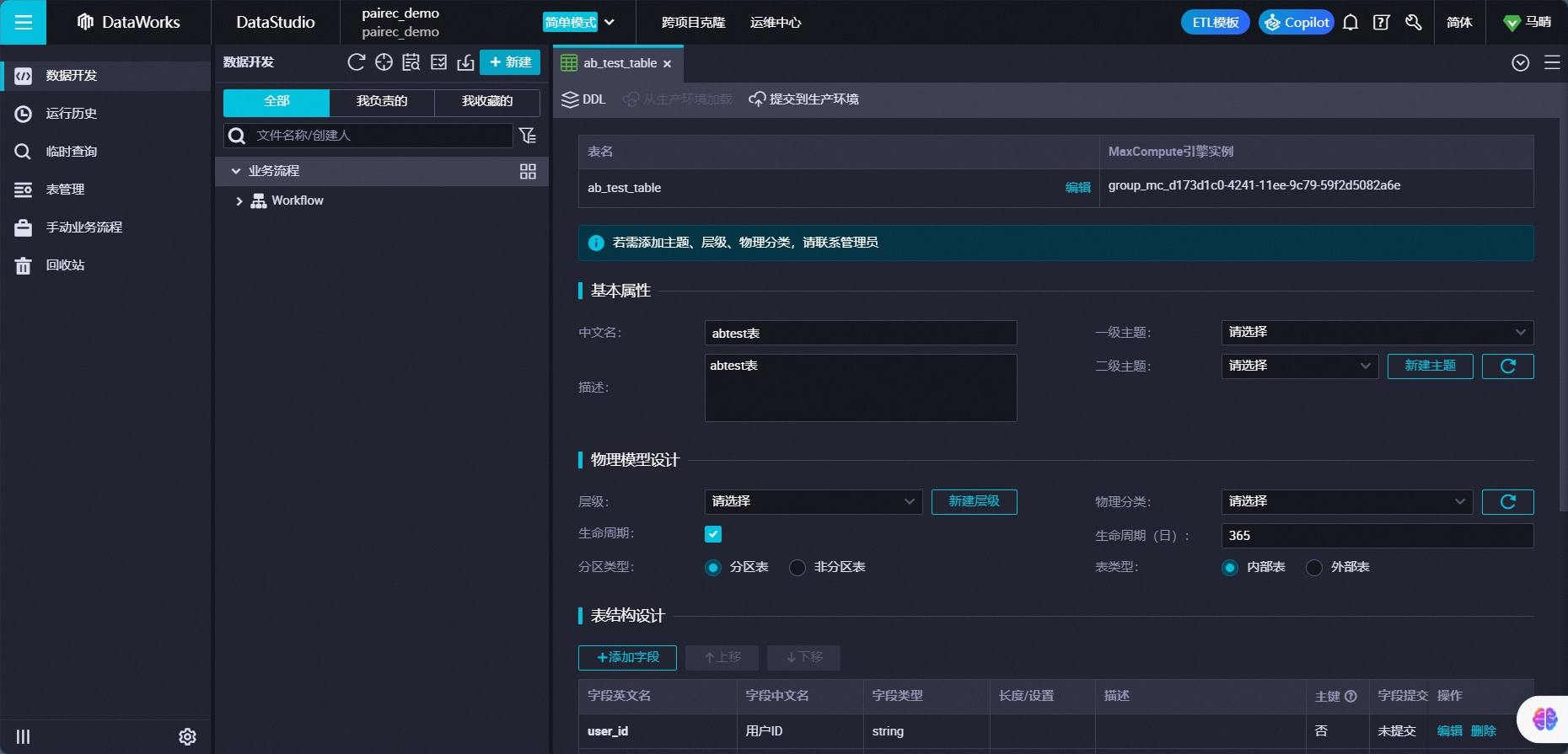
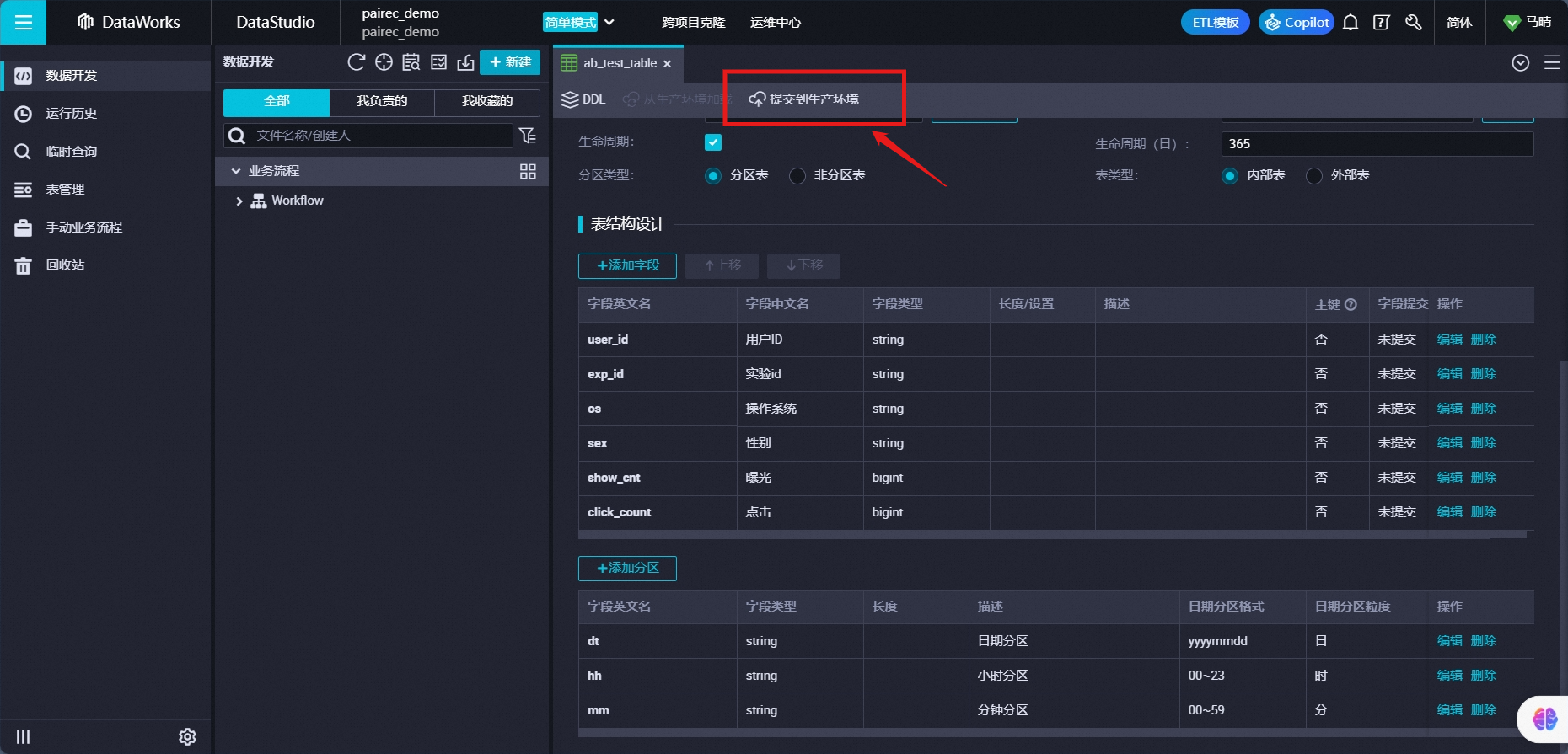
通过 DataWorks ,创建 MaxCompute 实验报表来源表。
5.2. 配置实验指标
在 AB 测试过程中,通过实验指标来度量实验效果。
实验指标可分为 2 类:
比例型实验指标 / 人均值实验指标
比例型实验指标(点击转化率、次日留存率、CTR-点击率、CVR-转化率)
人均值实验指标 (人均点击次数、人均下单金额)
核心指标 / 必看指标
核心指标(决策胜出的直接指标)
必看指标(每一个 测试需要观察的指标,虽然测试功能对这个必看指标没有直接的因果关系,但是不能对必看指标有显著负向的影响。)
除了以上类型和用途指标之外,偶尔会对比一些绝对值指标。(只有在进入测试组的用户数相同的情况下,对比这些绝对值指标才是有意义的)
绝对值指标
总点击用户数
总下单金额
5.2.1. 指标项
首先,进入指标配置模块,选择指标项配置,选定应用的推荐场景与指标时效。
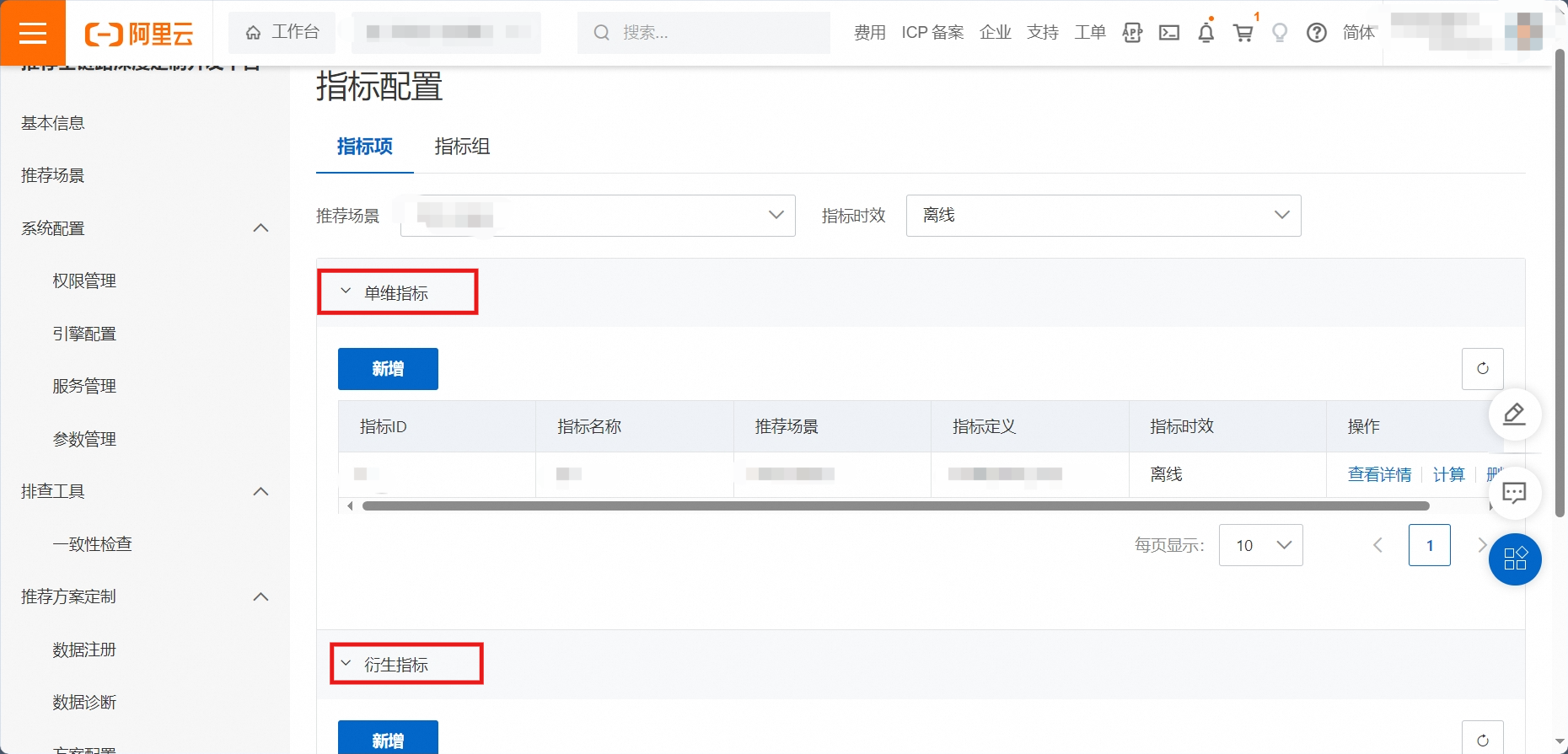
5.2.1.1. 单维指标
根据一些聚合逻辑(计数,去重计数,加和,取平均数等),生成的基础指标,例如用户打开 app 的次数。
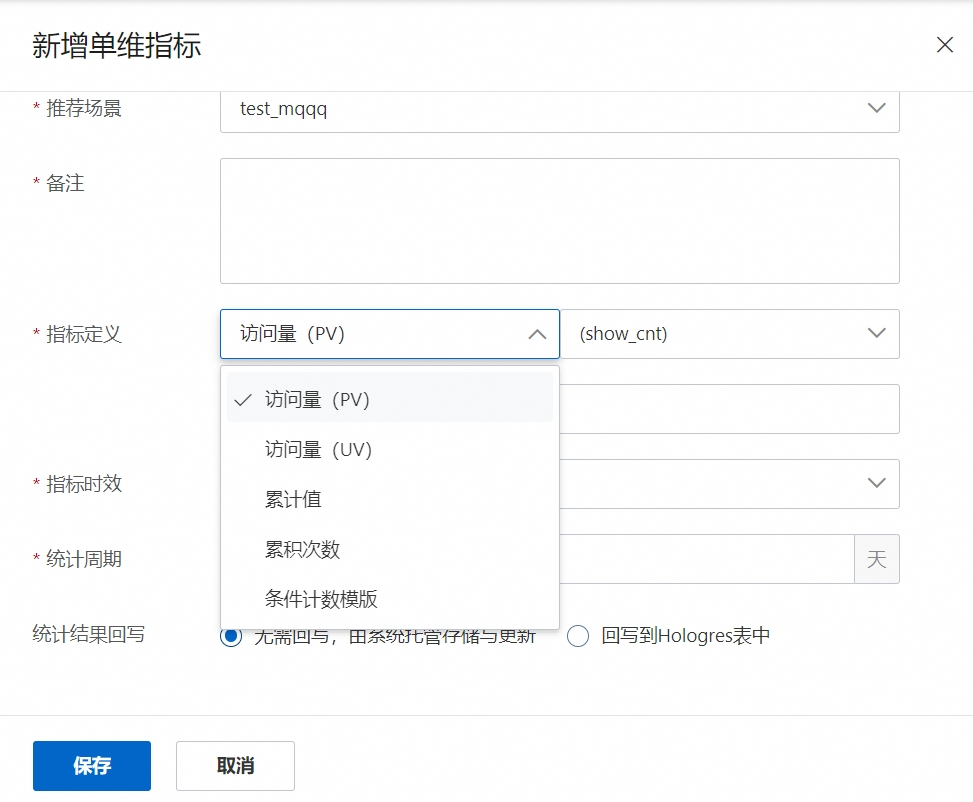
例如:我们最终结果需要得到某个网站的点击率。
点击率 = 每日点击数 / 每日访问量 ,则应当在单维指标中新增每日点击数和每日访问量,最终通过在衍生指标进行计算,得到结果。
配置说明:
指标定义中, PV 表示某个网页的页面访问量,UV 表示某个页面的用户访问数(只在用户首次进入时记录次数)。
选择字段后,会生成对应的计算字段命令。
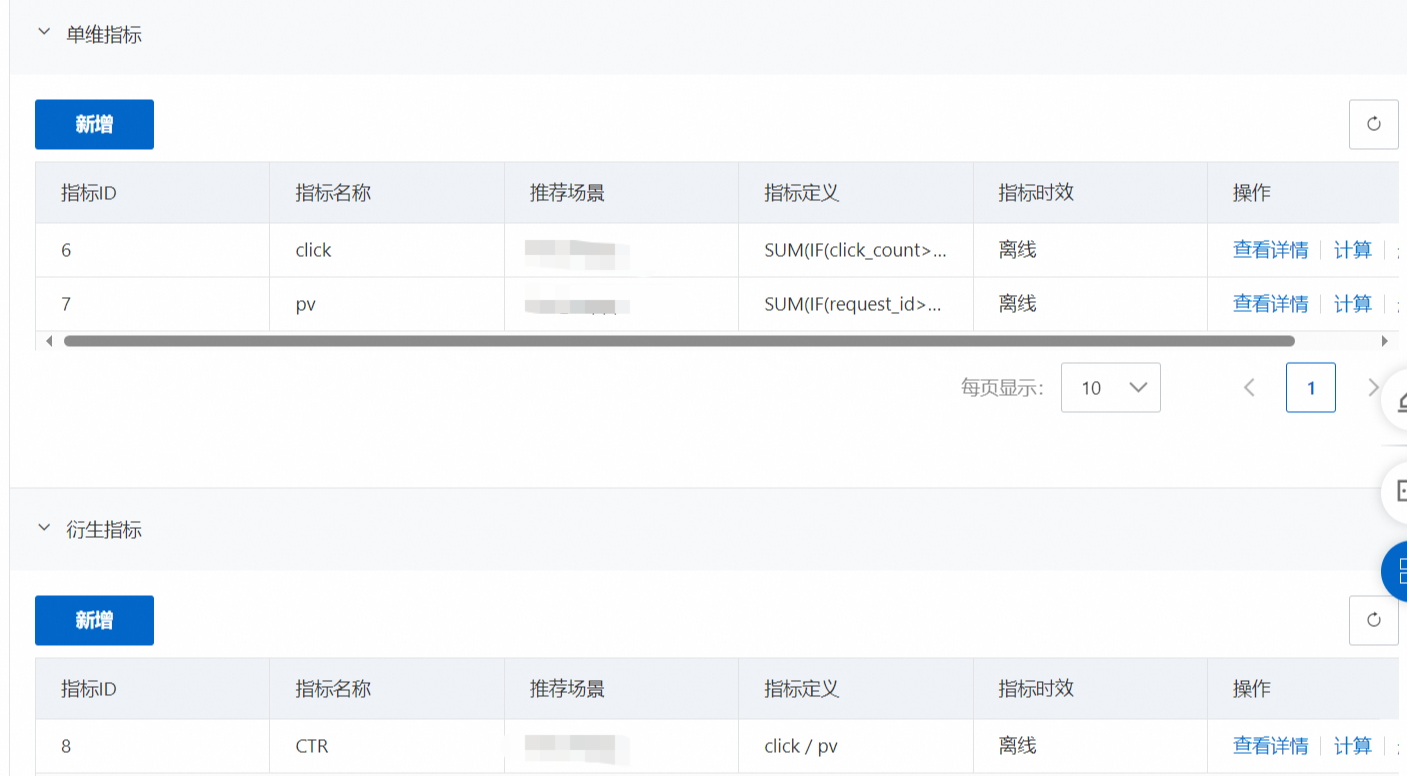
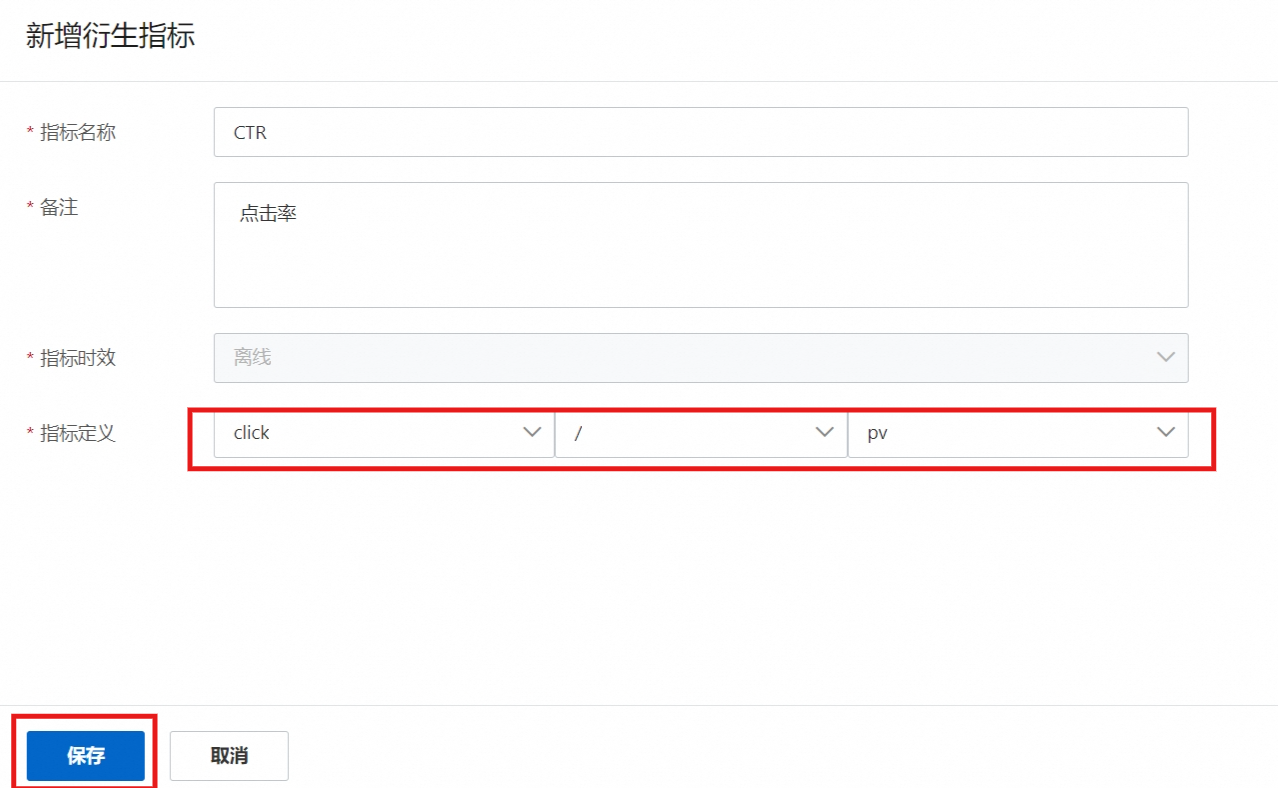
5.2.1.2. 衍生指标
对多个单维指标进行比例等类型的计算。
5.2.2. 指标组
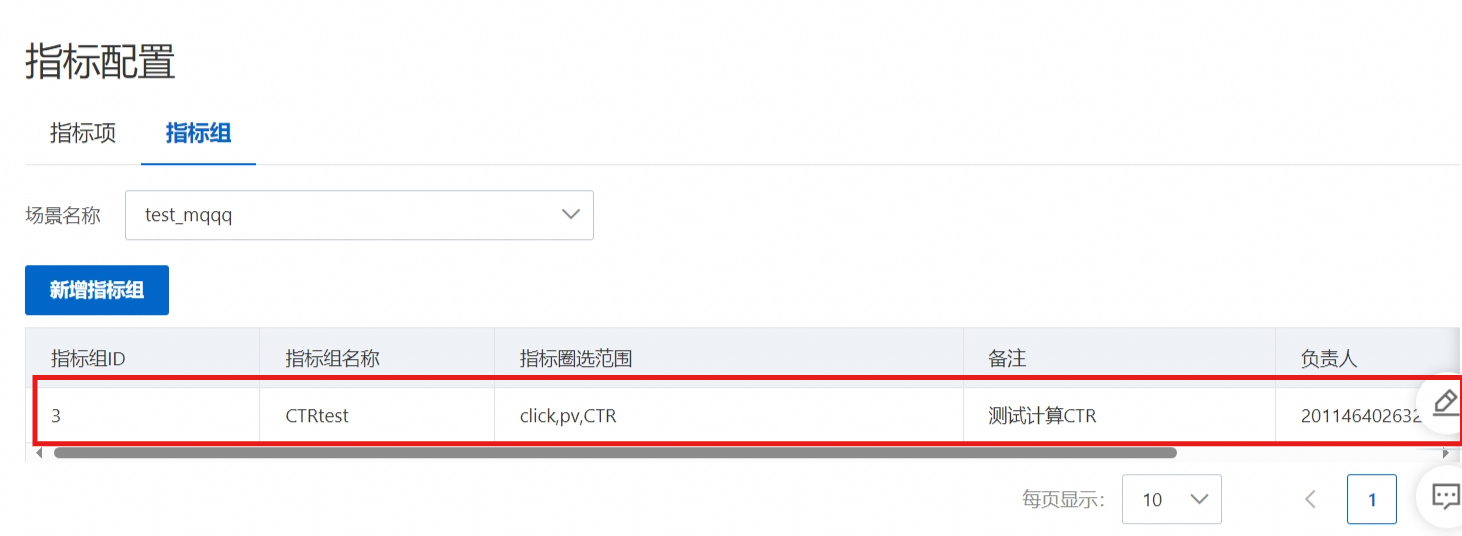
您可以圈选选定场景下的多个指标,作为一个指标组,以指标组为单位进行指标计算等任务。
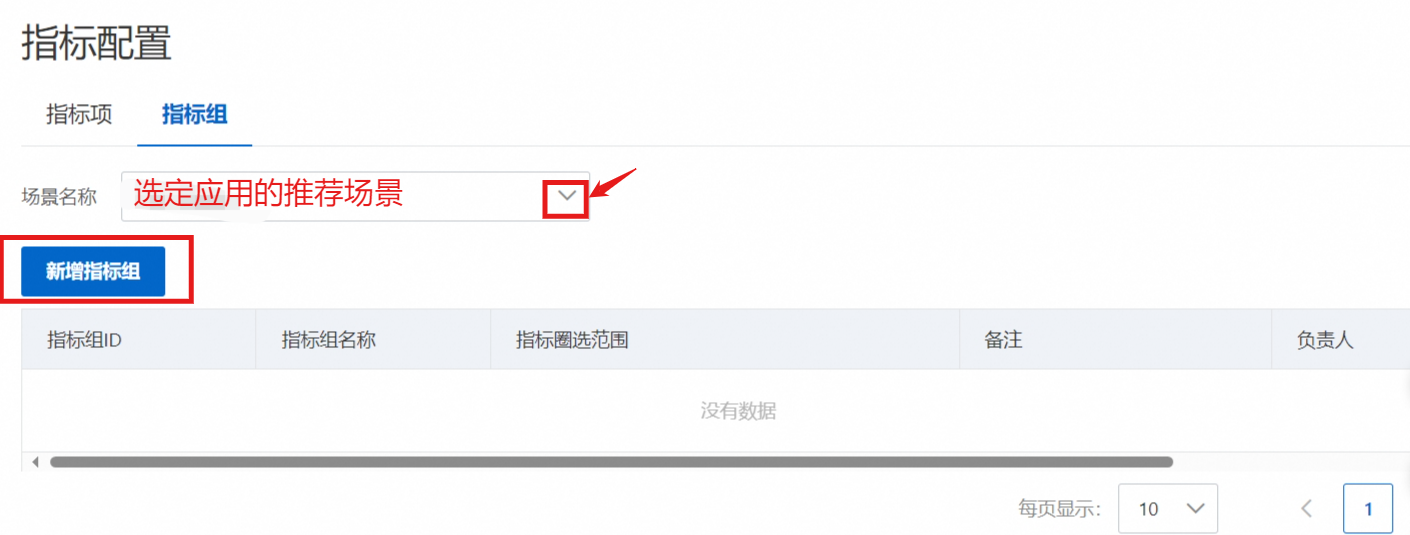
配置指标组,设定指标圈选范围。
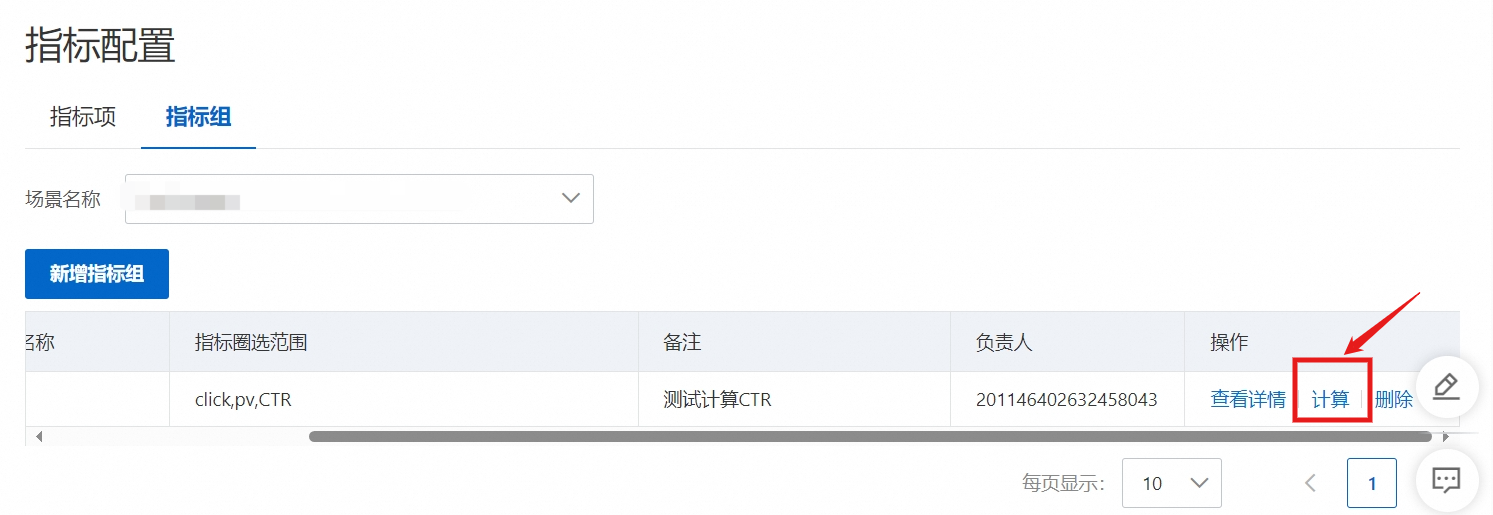
点击计算。
6. 计算指标以及生产报表
6.1. 计算指标
在指标配置中,在指标组中点击计算后,选择指标。
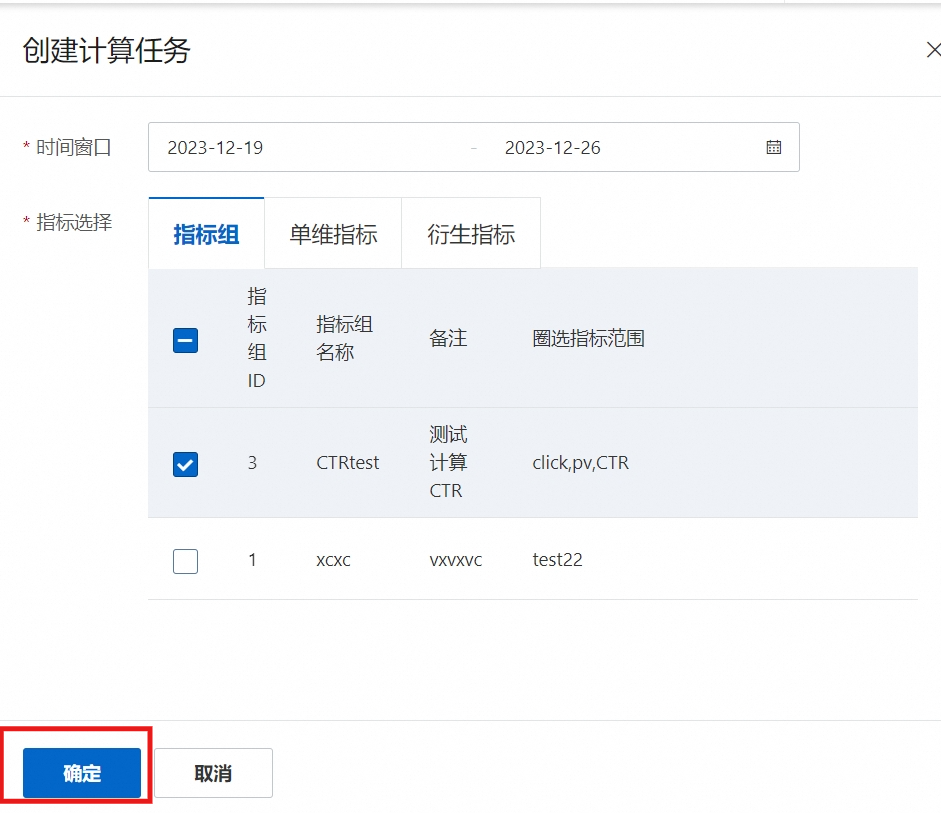
创建计算任务完成后,可在计算任务模块中,查看具体进度。
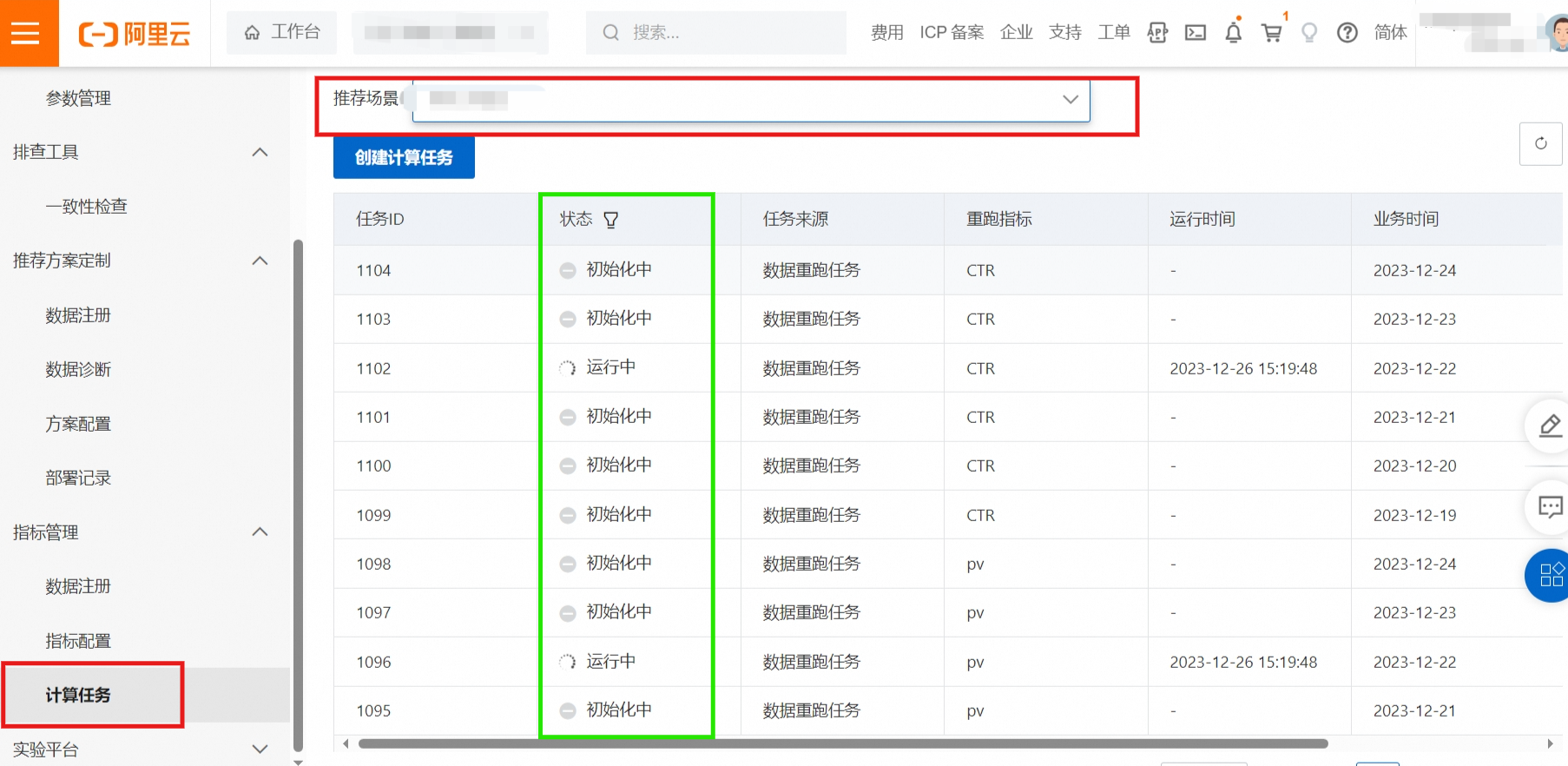
当所有的计算任务跑完之后,状态显示为成功。
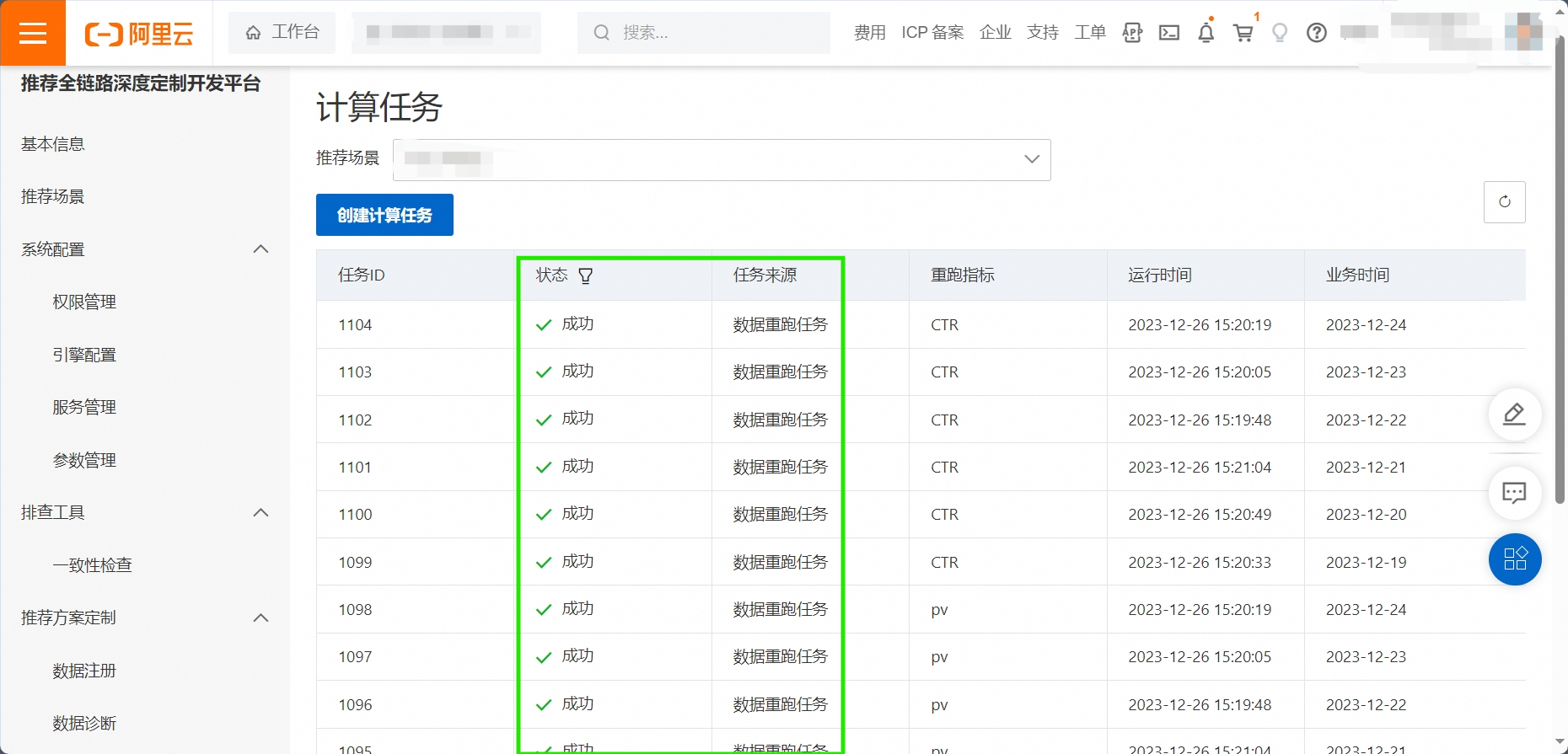
6.2. 生产报表
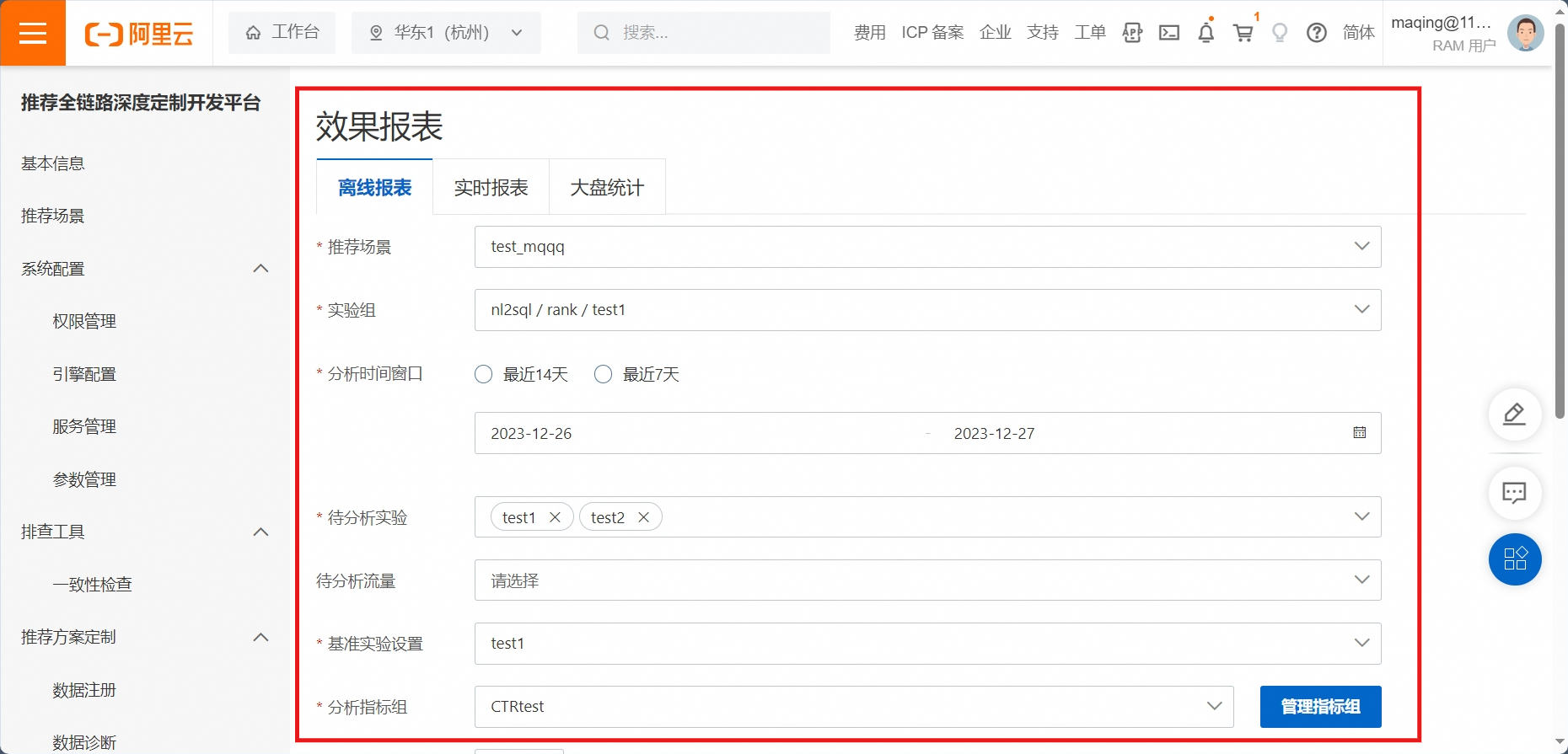
进入到实验平台中的效果报表模块,配置参数后,点击开始分析。
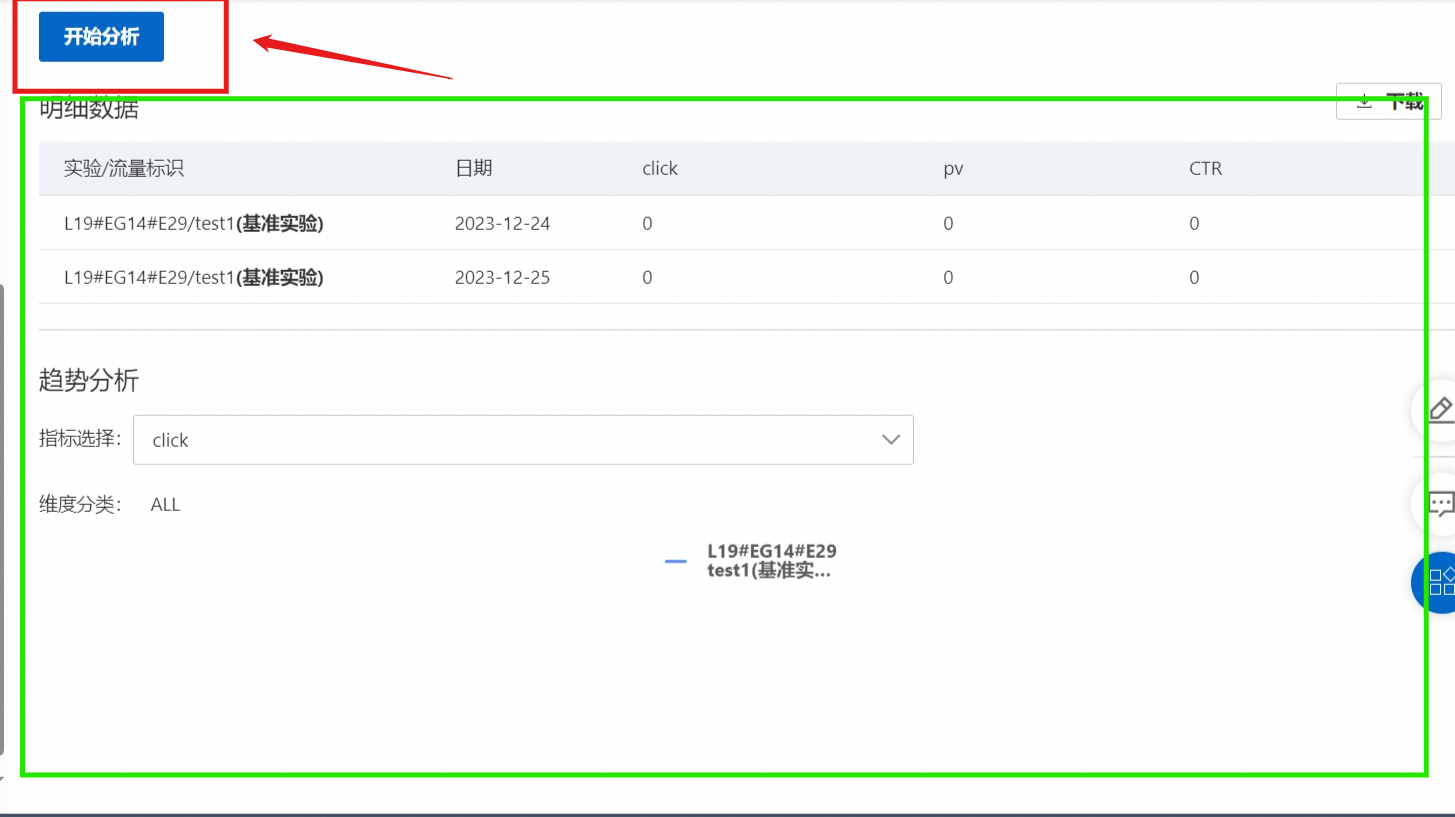
用户可以在明细数据中,查看对比基准实验与普通实验的指标差异;在趋势分析中,可切换不同的实验指标查看实验效果。