背景介绍
在推荐系统的粗排和精排系统中,一般都需要在用户侧和物品侧设计大量的统计特征、序列特征、组合特征;基于统计特征还可以设计lookup、match特征等衍生特征。例如一个用户侧的偏好类目统计特征f1(KV类型特征),需要经历离线统计、组合为Lookup特征供离线训练;线上推理的时候需要把f1同步到在线系统中,推荐引擎通过PAI-FeatrureStore的SDK读取到内存,然后传递给PAI-EAS打分服务中使用。整个链路很长,因此我们把特征的生产、衍生、离线和在线使用都维护起来,避免手工一步步的去编程,大大降低工作量,也降低了出错的概率。
下面我们介绍一下从数据准备、注册,到各种特征设计的过程。在这个过程中,对产出的特征可以做增删改查,大大提高了对特征的精细控制过程。
数据准备
准备三张基础表。
行为日志表:行为日志表就是用户在什么时间,对什么商品,做了什么行为,以及其附属字段。例如:
uid_01,20240428112000,item_01,expr uid_01,20240428112005,item_01,click其中expr、click就是行为类型(表示曝光,点击)。进一步的行为类型,如加购、购买、点赞、评论等。附属字段例如:requestid、曝光位置、网络状况、操作系统、成交价格等。行为日志表每天一个分区,每个分区记录当天的行为日志。
用户表:用户信息表中用户ID不重复。要求可以和行为日志表可以通过用户唯一ID进行关联。应包含用户基础属性信息,如年龄、性别、所属城市、积分、注册时间、用户标签等。每天一个分区,记录所有用户信息。
物品表:商品信息表中商品ID不重复。要求可以和行为日志表可以通过商品唯一ID进行关联。应包含商品基础属性信息,如多级类目、价格、标题、颜色、规格、上架时间、作者ID、粉丝数量等
在准备过程中对于其中特殊字符需要经过处理,比如 : ; # chr(2) chr(3) chr(29) 等符号已经被推荐模板占用,应在数据准备阶段替换掉,还有一些如不能被utf-8解码的字符,在数据准备阶段需要被处理掉。
我们在MaxCompute的项目空间pai_online_project中准备了3张表(rec_sln_demo_user_table,rec_sln_demo_item_table,rec_sln_demo_behavior_table),采用如下SQL可以将数据克隆到自己项目中
--用户信息表 CREATE TABLE IF NOT EXISTS rec_sln_demo_user_table( user_id BIGINT COMMENT '用户唯一ID', gender STRING COMMENT '性别', age BIGINT COMMENT '年龄', city STRING COMMENT '城市', item_cnt BIGINT COMMENT '创作内容数', follow_cnt BIGINT COMMENT '关注数', follower_cnt BIGINT COMMENT '粉丝数', register_time BIGINT COMMENT '注册时间', tags STRING COMMENT '用户标签' ) PARTITIONED BY (ds STRING) STORED AS ALIORC; INSERT OVERWRITE TABLE rec_sln_demo_user_table PARTITION(ds) SELECT * FROM pai_online_project.rec_sln_demo_user_table WHERE ds > "20221231" and ds < "20230217"; --商品信息表 CREATE TABLE IF NOT EXISTS rec_sln_demo_item_table( item_id BIGINT COMMENT '内容ID', duration DOUBLE COMMENT '视频时长', title STRING COMMENT '标题', category STRING COMMENT '一级标签', author BIGINT COMMENT '作者', click_count BIGINT COMMENT '累计点击数', praise_count BIGINT COMMENT '累计点赞数', pub_time BIGINT COMMENT '发布时间' ) PARTITIONED BY (ds STRING) STORED AS ALIORC; INSERT OVERWRITE TABLE rec_sln_demo_item_table PARTITION(ds) SELECT * FROM pai_online_project.rec_sln_demo_item_table WHERE ds > "20221231" and ds < "20230217"; --日志行为表 CREATE TABLE IF NOT EXISTS rec_sln_demo_behavior_table( request_id STRING COMMENT '埋点ID/请求ID', user_id STRING COMMENT '用户唯一ID', exp_id STRING COMMENT '实验ID', page STRING COMMENT '页面', net_type STRING COMMENT '网络型号', event_time BIGINT COMMENT '行为时间', item_id STRING COMMENT '内容ID', event STRING COMMENT '行为类型', playtime DOUBLE COMMENT '播放时长/阅读时长' ) PARTITIONED BY (ds STRING) STORED AS ALIORC; INSERT OVERWRITE TABLE rec_sln_demo_behavior_table PARTITION(ds) SELECT * FROM pai_online_project.rec_sln_demo_behavior_table WHERE ds > "20221231" and ds < "20230217";
数据注册
【推荐方案定制中】导航列表点击【数据注册】,点击【新增数据】

选择已经配置的MaxCompute的项目,也就是3张表所在的项目,MaxCompute表输入选择日志行为表rec_sln_demo_behavior_table,并在数据表名称输入相同的名称,点击开始导入。
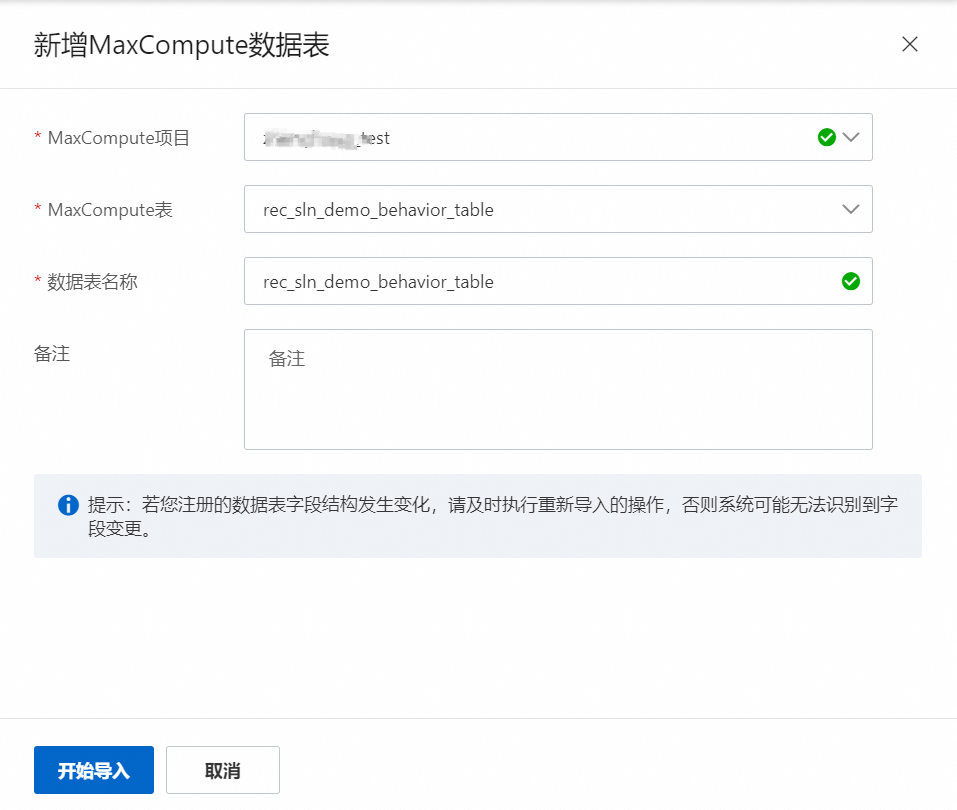
导入成功后,可以在新增好的表中点击查看字段,可以看到该表的字段明细
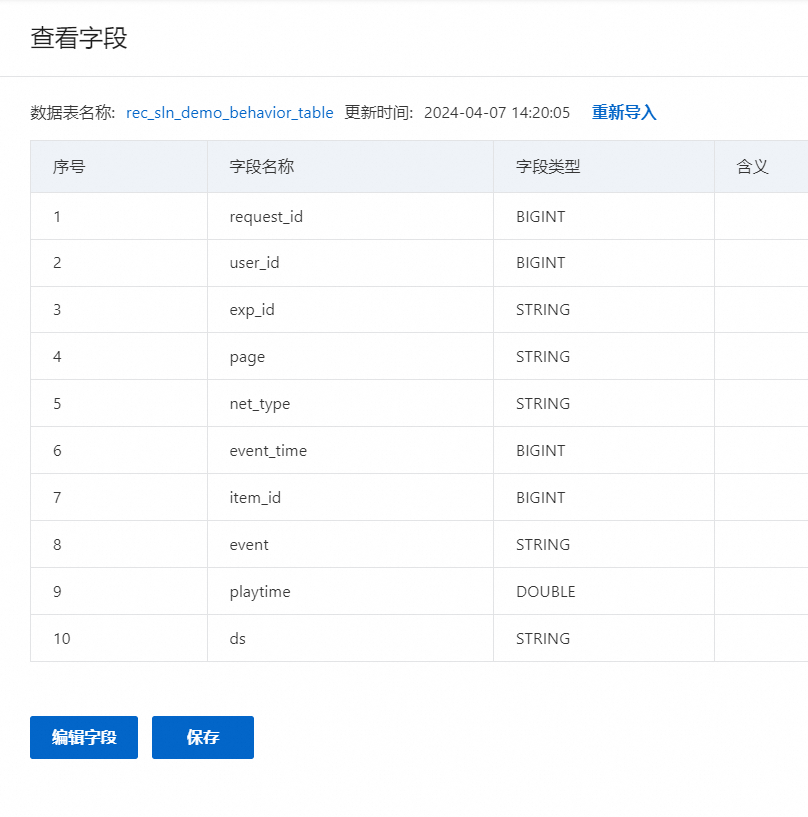
如上方式同样导入用户表和物品表
数据表配置
点击【推荐方案定制】下的【方案配置】,后创建推荐方案,如图
已经创建好的推荐方案,可以点击右侧的更新方案进行配置
1.添加行为表
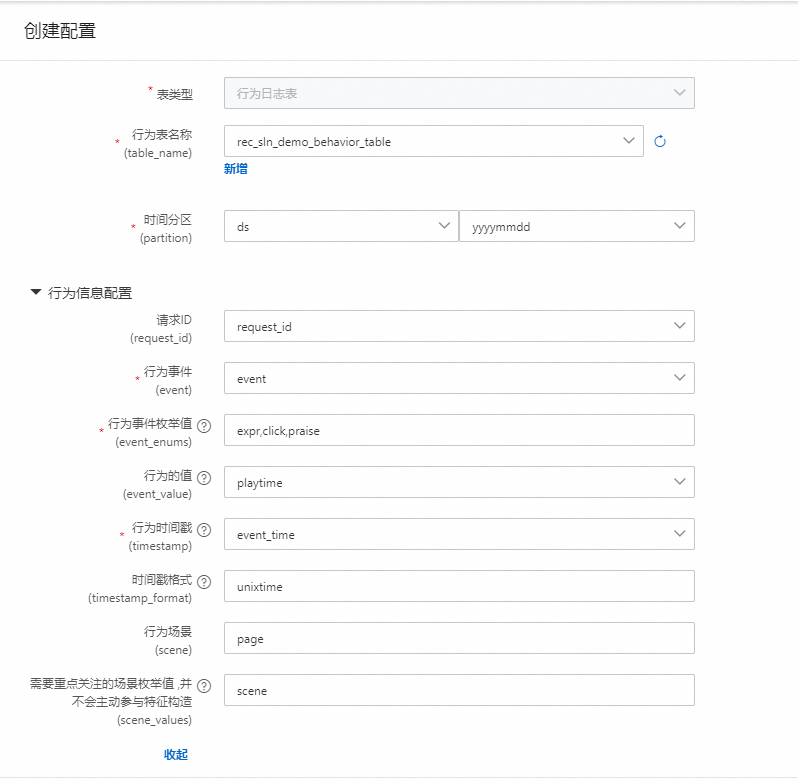
行为表中的行为信息配置
行为表名称:选取我们已经注册好的行为表
时间分区:行为表的分区字段
请求ID:行为日志的请求ID字段,有就填写,没有可以不填写,该字段会影响样本精准度和模拟的实时特征,实时序列特征的准确性。
行为事件:表示行为类型的字段
行为事件枚举值:也就是行为事件里面包含的枚举值,如曝光,点击,加购,购买等行为
行为的值:表示行为的深度,可以是成交价格,观看时长等字段。
行为时间戳:日志发生的时间,一般是10位时间戳,特殊需要指定格式,精准到秒
时间戳格式:和行为时间戳配合使用
行为场景:表示日志发生的场景字段,如首页,搜索页,或者是商品详情页
重点关注的场景:行为场景重要的值,在下游的特征配置中可以使用
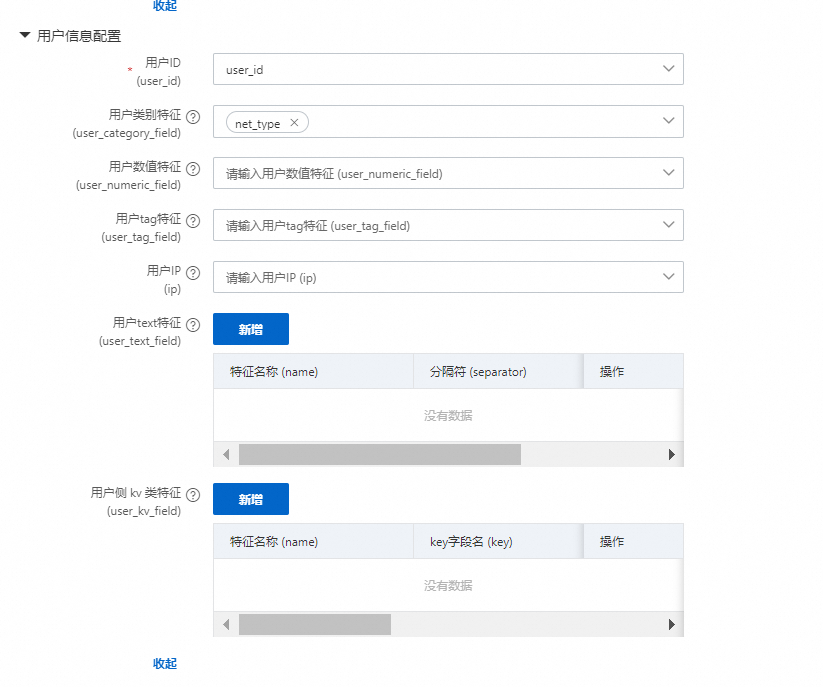
行为表属于用户侧的字段
用户ID:行为表中用户ID的标识
用户类别特征:行为表中存在的用户类别特征,如网络,操作平台,性别等
用户数值特征:行为表中存在的用户数值特征,如粉丝数量,作品数
用户Tag特征:行为表中存在的用户多值的类目特征,如兴趣爱好等
用户IP: 行为日志可能存在的IP,如果有,则下游会对IP解析成国家,省份,城市等类目特征
用户Text特征:行为表中可能存在的属于user侧的文本特征
用户KV特征:行为表中可能存在,并且属于user侧的多值类目,并带有权重的特征
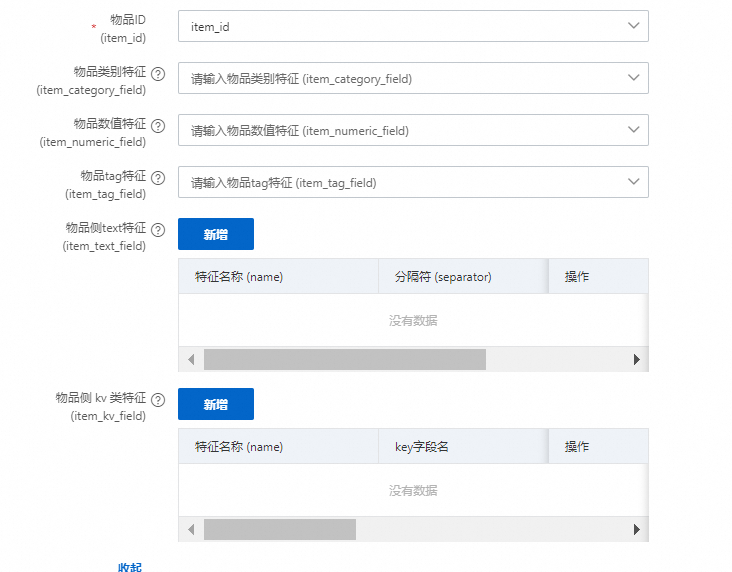
行为表输入物品侧的字段
物品ID:行为表中物品ID的标识
物品类别特征:行为表中存在的物品类别特征,如类目等
物品数值特征:行为表中存在的物品数值特征,如观看人数等
物品Tag特征:行为表中存在的物品多值的类目特征,如尺码等
物品Text特征:行为表中可能存在的属于item侧的文本特征,如标题等
物品KV特征:行为表中可能存在,并且属于item侧的多值类目,并带有权重的特征

行为表的其他字段
tag特征的分隔符号,如果存在user的tag或者item的tag,则正确填写其多值特征的分割符号
表生命周期:如果填写,则行为表会保存对应的周期,如果不填写,则生成的表将和其上游表同周期
datawroks节点名称:如果填写则依赖的就是填写节点的名称,如果不填写则依赖节点的名称和行为表名称一样
2.添加用户表
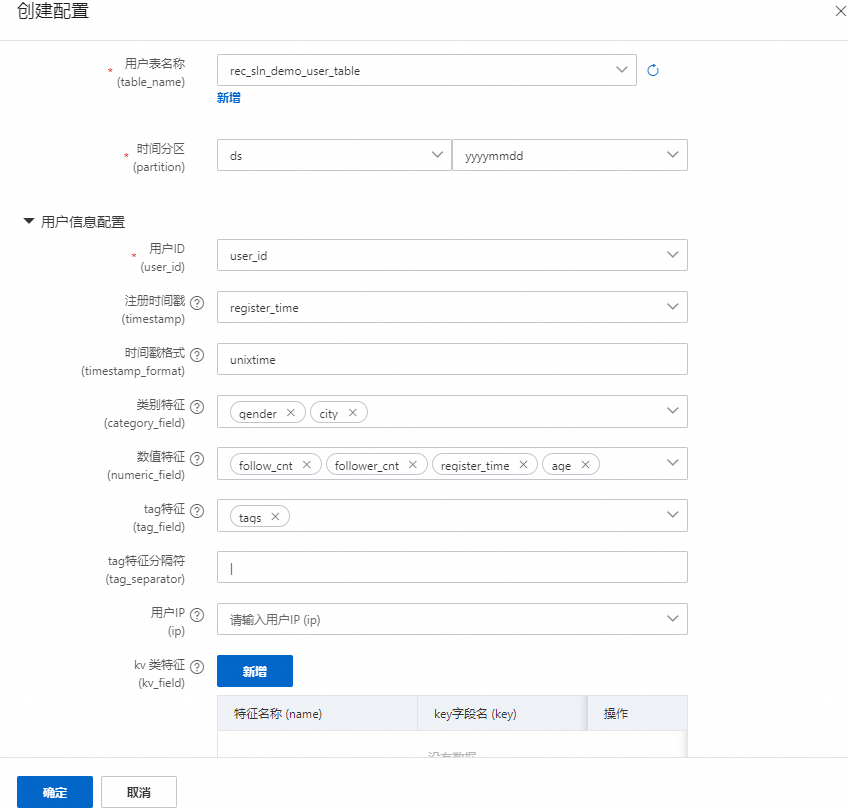
用户表名称:选取我们已经注册好的用户表
时间分区:用户表的时间分区字段
用户ID:用户表中的用户ID字段
注册时间戳:该用户注册的时间,一般是10位时间戳,特殊需要指定格式,精准到秒
时间戳格式:和注册时间配置配合使用
类别特征:用户表的类别字段,如性别,年龄段,所属城市等。
数值特征:用户表的数值字段,如作品数,积分
tag特征:多值类别字段,使用tag分割符号分割
用户IP:用户表中可能存在的IP字段,下游会自动解析省份,城市等信息
kv类特征:用户多值特征并带有分割符号
embedding特征:用户侧带有的embedding特征
3.添加物品表
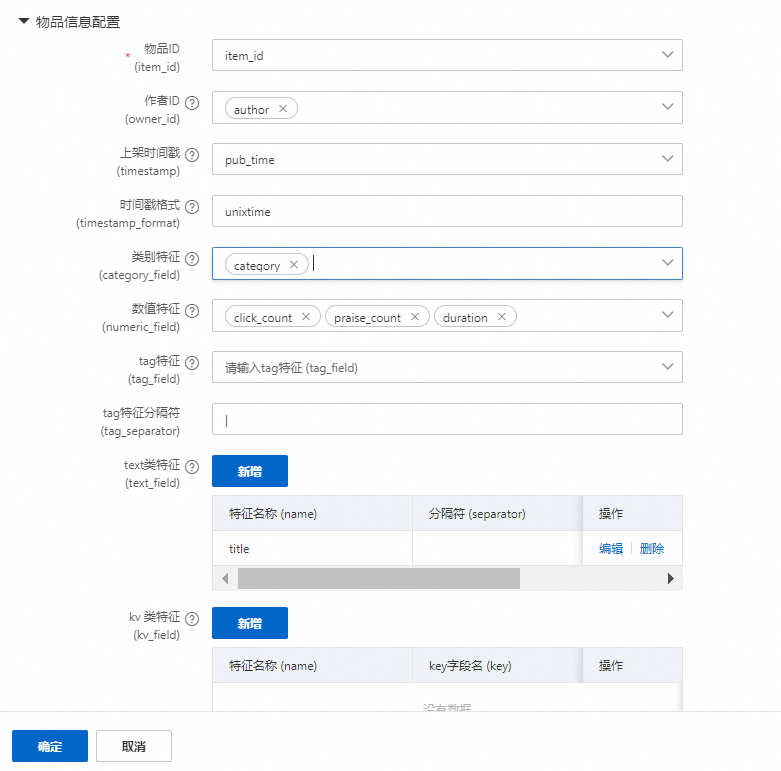
物品表名称:选取我们已经注册好的物品表。
时间分区:物品表的时间分区字段。
物品ID:物品表中的物品ID字段。
作者ID:商品所属的作者。
注册时间戳:该物品注册的时间,一般是10位时间戳,特殊需要指定格式,精准到秒。
时间戳格式:和注册时间配置配合使用。
类别特征:物品表的类别字段,如类目。
数值特征:物品表的数值字段,如作价格,累计销量,点赞量。
tag特征:多值类别字段,使用tag分割符号分割。
text特征:物品的文本特征,如标题,描述等。
kv类特征:物品多值特征并带有分割符号。
embedding特征:物品侧带有的embedding特征。
特征配置
1.常用周期行为类型配置
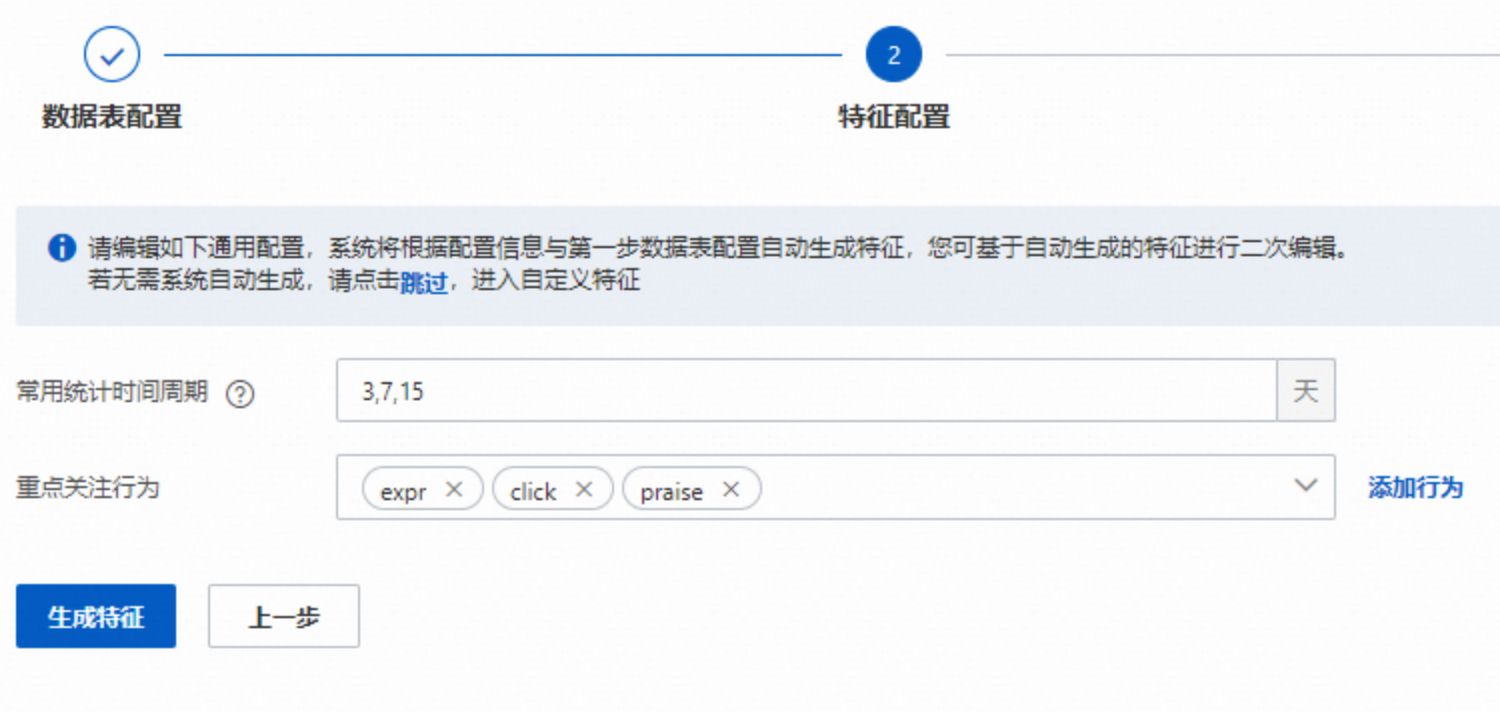
常用周期:可以自定义配置,一般我们配置短,中,长周期,不可过多,过多可能引起过多的特征(如在一个周期我们统计200个特征,通常3个周期就有600特征,如果是6个周期就会有1200个特征)。
重点关注行为:即行为表填写的行为枚举值,不可过多(和行为周期一样,太多会引起过多的特征)。如果有过多的行为类型,可以在上游准备表的时候合并一些不重要的,或者含义一样的行为类型。注意此处一般按照行为发生的先后次序,如次序应该是"曝光、点击、购买"这种顺序,次序混乱会影响下面比率特征的生成,会给下游更改造成一些手动工作。
此处会根据统计周期以及行为类型,还有上游3张表提供的类目,数值,tag等类型的基础特征,点击【生成特征】,会自动在用户和物品侧衍生出多种统计特征。
2.基础衍生特征
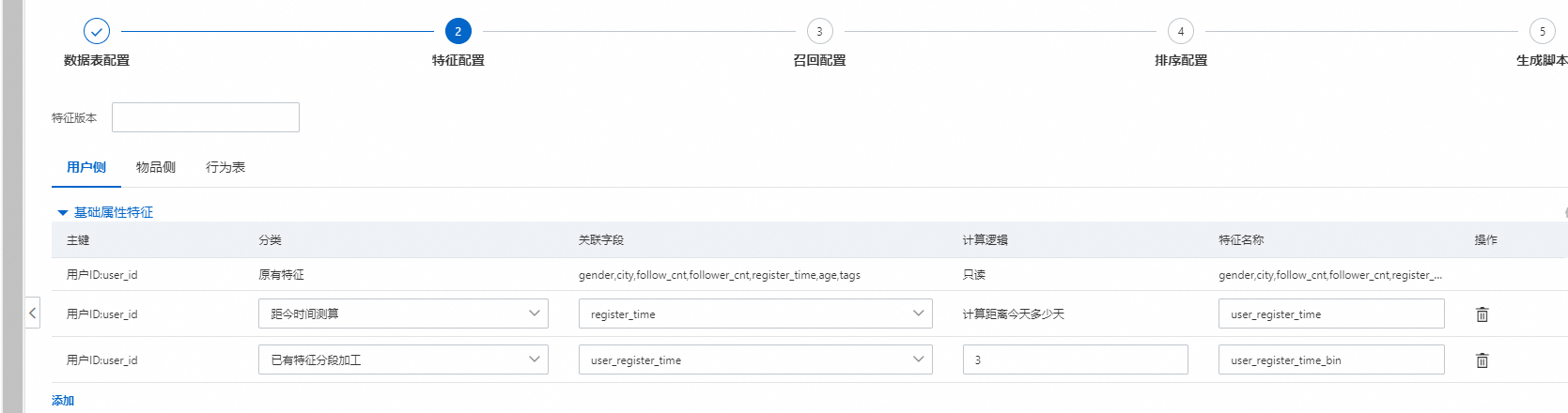
一般根据上游对3张表的配置,下游对应的基础属性特征已经有一些自动的衍生特征,不过此处我们还可以点击添加,继续增加基础衍生特征。注意用户侧,物品侧,和行为侧都有基础属性特征的衍生。
IP衍生:配置IP衍生,只能上游对应表配置的IP字段才可以衍生,我们可以根据配置,解析到IP的省份,城市,国家3种信息。
距今时间测算:根据用户或者商品的注册时间,会计算距今多少天。
已有特征分段加工:只能数值字段,根据填写的分割点进行分割,分割后则是类目特征。
特征组合:表示多种类目字段的组合,可以类目和类目,类目和tag,tag和tag字段组合,此种组合要求属于当前表,且要么都属于user侧,要么都属于item侧。
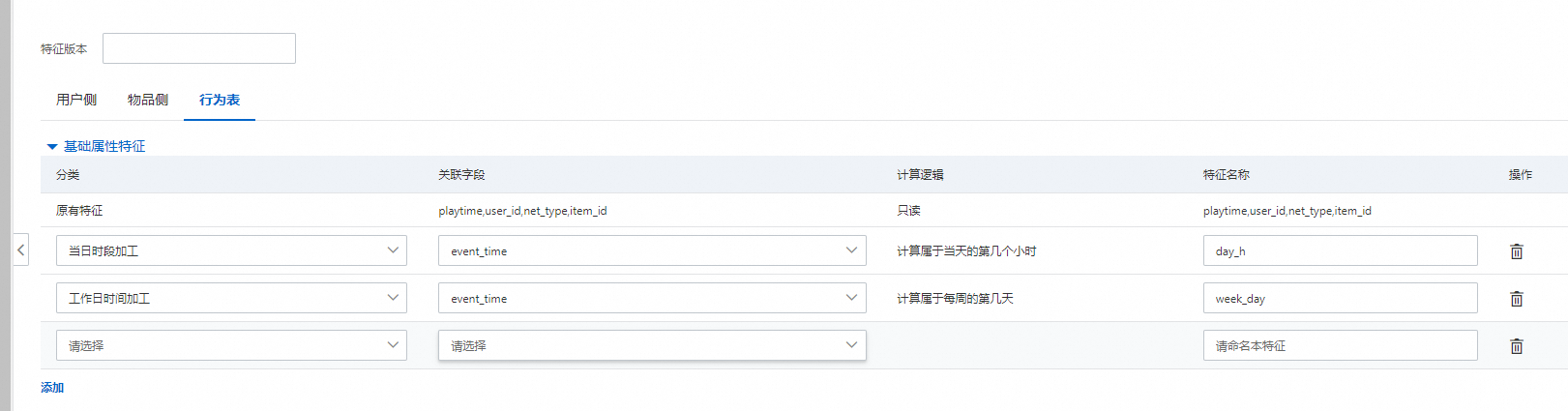
点击行为表,还有其余的2种基本衍生
当日时段加工:根据行为日志会衍生出属于日志发生于当天第几个小时
工作日时段加工:根据行为日志解析出日志发生于每周的第几天
如果手动增加完基础的衍生特征,需要点击右上角的保存,手动增加的基础衍生特征才会生效
3.行为偏好统计
如下图所示,我们已经自动衍生了多种统计特征,用户侧和物品侧都有对应的统计特征,其中自动以用户ID和物品ID作为聚合主键。目前有以下6种类型的统计:
行为统计计数
转化率统计
Top偏好属性类特征的行为计数
Top偏好属性类特征的行为占比
偏好数值类特征
Top类目与数值组合特征计算
如果觉得那些特征不需要,可以点击右侧的删除按钮,或者点击编辑对某个属性进行删除。如果需要添加特征可以点击右下角的【添加】按钮,继续添加多种类型的统计特征。以下是几种统计特征的介绍

行为统计计数
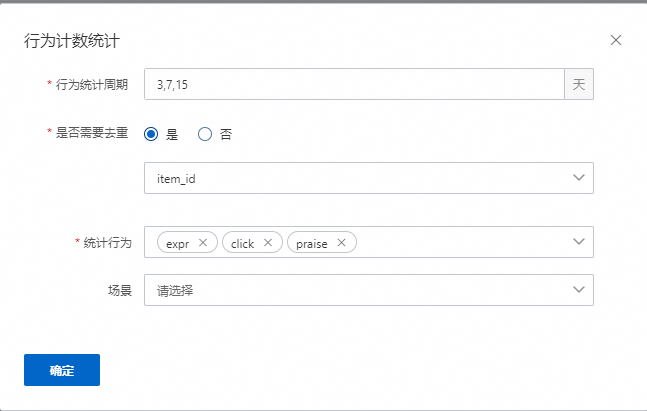
表示会统计用户在对应的周期,如3,7,15天中,统计对应的行为,如expr、click、praise发生的次数,如果带有去重ID,则表示依照ID去重之后的次数,如果有配置场景,则表示这些特征会统计发生在某个场景的行为。该示例配置会产生9个特征,统计周期数量*统计行为数量。
转化率统计
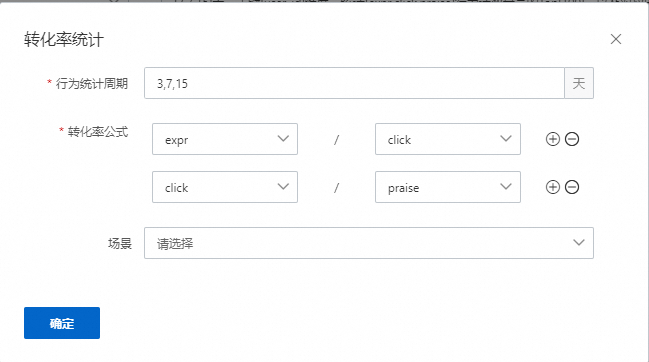
为统计行为次数相除,表示会统计用户,在对应的周期,如3,7,15天中,统计对应的行为相除,如click的次数除以expr的次数,praise的次数除以click的次数,如果不符合要求还可以继续修改或者增加,删除等。如果有配置场景,则表示这些特征会统计发生在某个场景的数据下。该示例配置产生6个特征,统计周期数量*转化率公式数量。
Top偏好属性类特征的行为计数
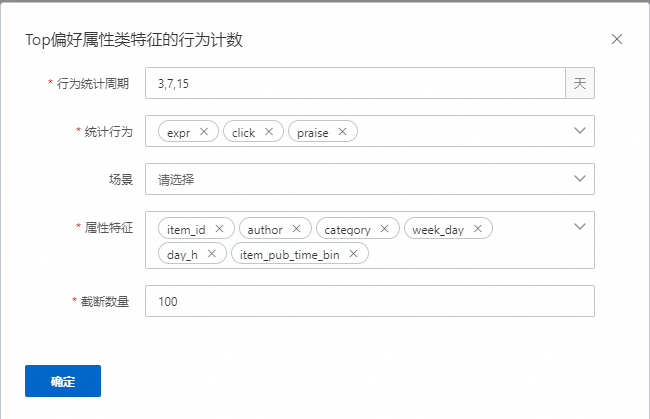
表示会统计用户在对应的周期,如3,7,15天中,对属性特征类目或者多值类目,统计对应的行为,如expr,click,praise。每种属性值发生的次数,最终生成kv特征。如以类目day_h,行为是点击举例,生成特征"12:27.0,8:26.0,1:1.0"表示该用户在当前周期内,在12点的点击发生27次,8点的点击发生26次,1点的点击发生1次。如果有配置场景,则表示这些特征会统计发生在某个场景的数据下,如果key的数量过多,默认截断100个。该示例配置生成54个特征,数量=统计周期数量*统计行为数量*属性特征数量
Top偏好属性类特征的行为占比
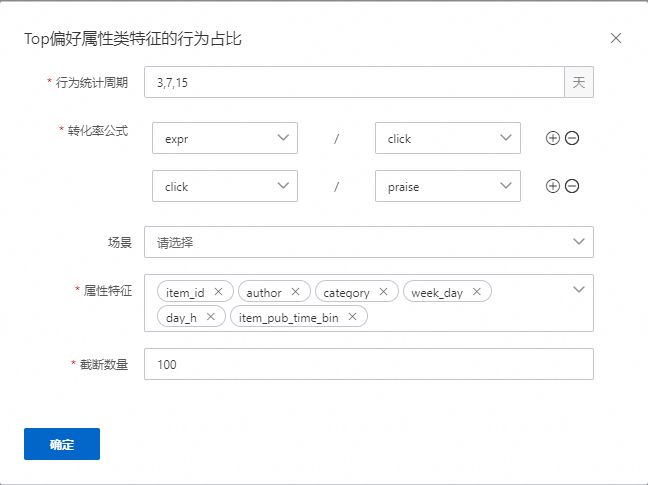
表示会统计用户在对应的周期,如3,7,15天中,对属性特征类目或者多值类目,统计对应的行为比率,如click/expr (ctr),praise/click(cvr)比率特征。最终生成kv特征。如以类目cate为列,公式是click/expr,生成特征"12:0.27,8:0.26"表示该用户在当前周期内,在12类目的点击率是0.27,在类目8的点击率0.26。如果有配置场景,则表示这些特征会统计发生在某个场景的数据下,如果key的数量过多,默认截断100个。该示例配置生成36个特征,数量=统计周期数量*转化率公式数量*属性特征数量
偏好数值类特征
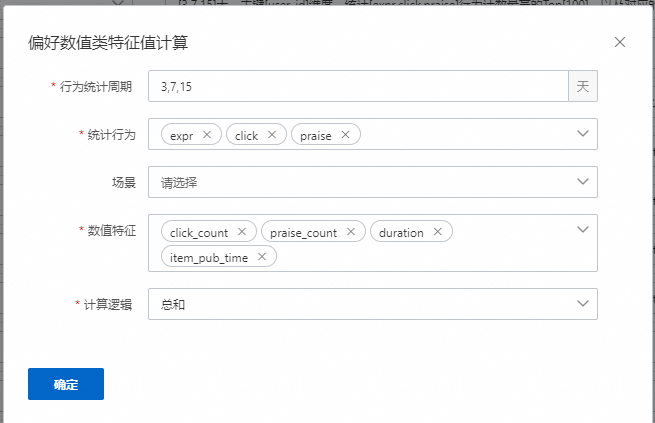
表示会统计用户在对应的周期,如3,7,15天中;在对应的行为中,如expr,click,praise;对选择的数值属性,根据计算逻辑进行统计。计算逻辑可以是总和,最大值,最小值,均值等。如果有配置场景,则表示这些特征会统计发生在某个场景的数据下。该示例配置生成36个特征,数量=统计周期数量*行为数量*数值特征数量。
Top类目与数值组合特征计算
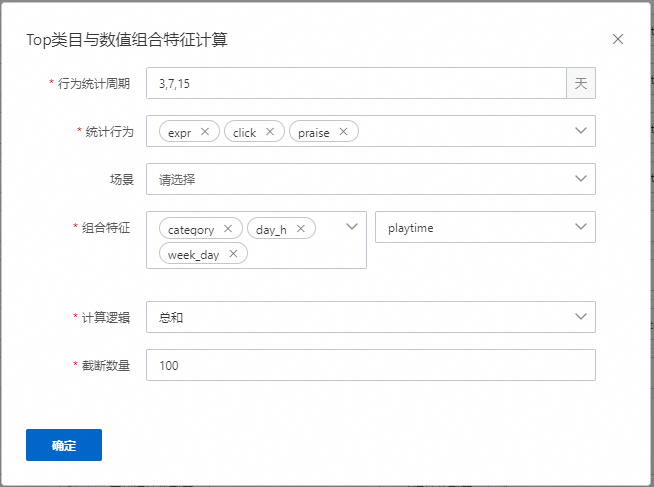
表示会统计用户在对应的周期,如3,7,15天中;在对应的行为中,如expr、click、praise;根据计算逻辑,如总和,最大值,最小值,均值等;计算用户在对应类目特征下对某数值的偏好。如果有配置场景,则表示这些特征会统计发生在某个场景的数据下。该示例配置生成27个特征,数量=统计周期数量*行为数量*组合特征的类目特征数量。
4.序列特征
序列特征只会发生在用户侧。序列特征刚开始我们都是依靠现有的数据模拟实时序列特征,节省线上落下序列特征的时间,加速上线。其中模拟事件一般都是曝光事件;防穿越时间是指最近几秒的行为不会算入当前行为序列(因为推理的时候,日志回流链路原因会导致部分数据有延迟,如果模拟的过于实时,会导致训练有穿越);序列特征分割符号,是指构造序列的时候,序列之间的分割符号;子特征分割符号,是指在一个序列中,子特征之间的分割符号。

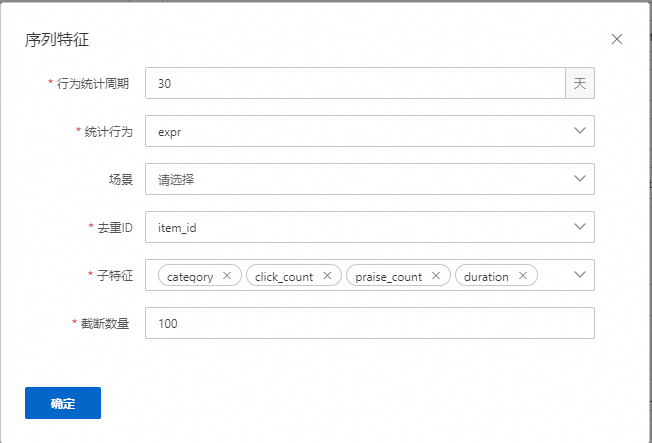
行为周期:表示统计最近多少天内的行为,如果有多组序列,则最大的周期起作用。
统计行为:表示要统计的行为类型。
场景:表示发生在某单个场景下。
去重ID:表示在序列中会依据该子特征去重,保留当前时刻最后一次该行为发生。
子特征:表示序列特征子特征,一般都是属于商品侧的非统计特征,类目,多值类目,以及数值特征。
阶段数量:表示序列特征最大保留的序列数量。
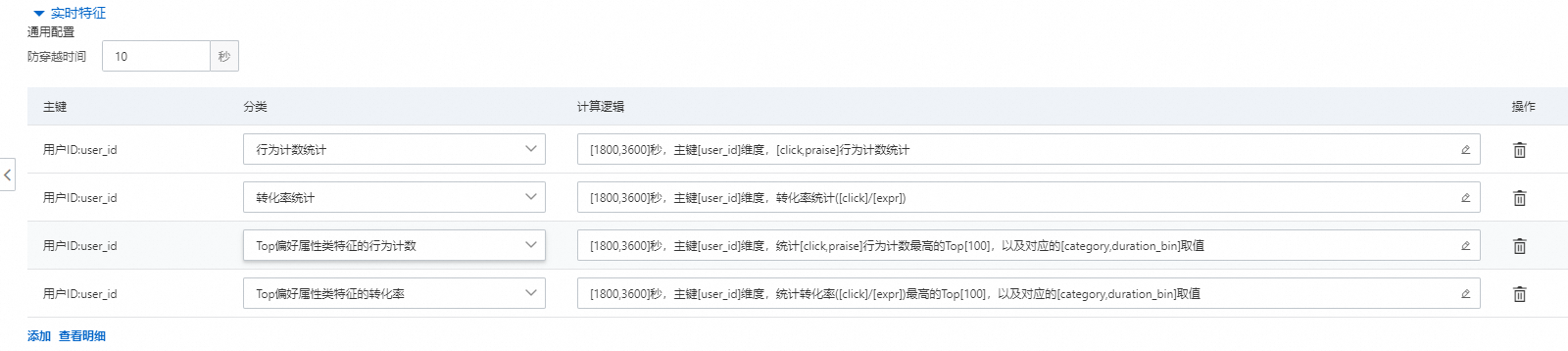
5.实时特征
以用户ID和物品ID为主键都可以创建实时特征,其中防穿越时间和序列特征的防穿越时间的功能一样,表示在目标行为的最近多少秒内的行为不会进入计数统计(因为行为日志从客户端传输到消息中间件,再统计写入到在线存储服务会有一段时间差;如果不设置防穿越时间,会导致线上统计不到理想的数据)。其中实时特征统计周期单位是秒。统计类型包含以下四种类型:
行为统计计数
转化率统计
Top偏好属性类特征的行为计数
Top偏好属性类特征的行为占比
该四种类型和行为偏好统计的4中含义一样,只是周期不同。
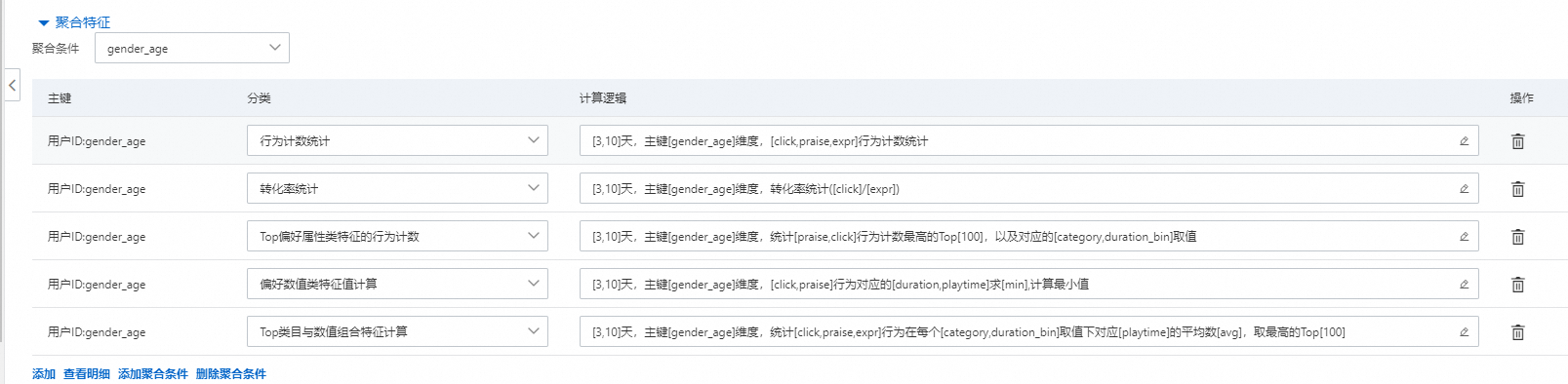
6.聚合特征
聚合特征在用户侧和物品侧都可以发生。需要选择聚合条件,只能选择类目特征作为聚合条件,可以配置多组。
会根据当前的聚合条件统计对应的特征。可以统计的类型和行为偏好的统计类型一样,含义也一样
精排配置
在排序配置中我们选择添加精排
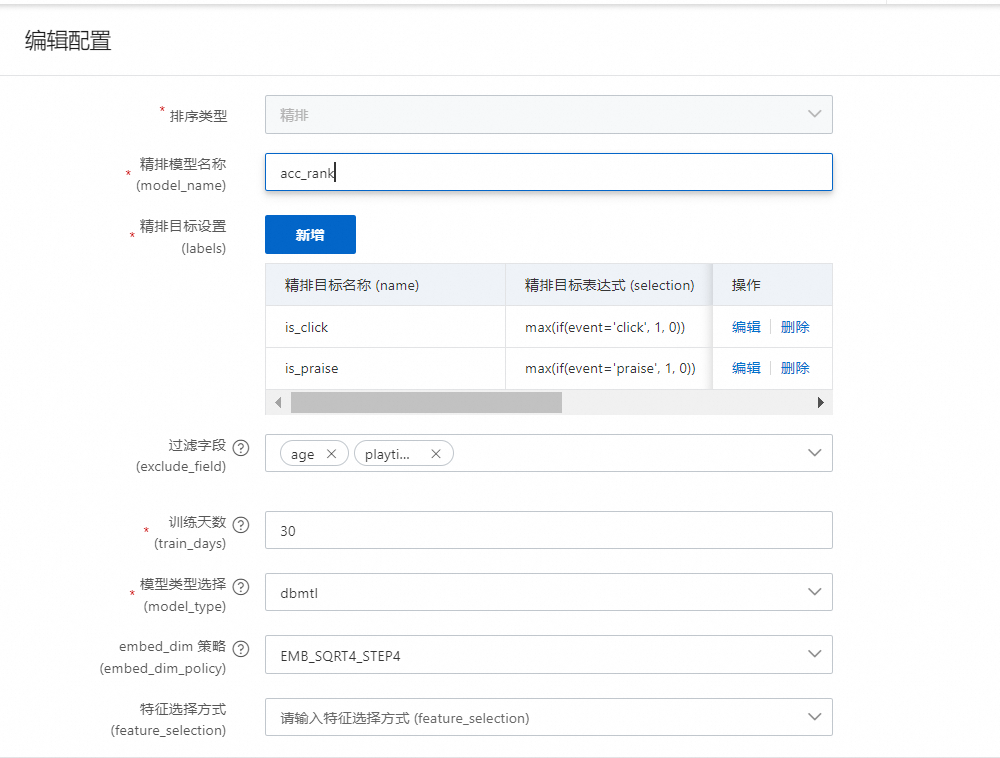
精排模型名称:字母加下划线,推荐用:${场景名称}_${模型名称}_rank
精排目标设置:精排目标可以设置多个目标,包含分类和回归目标,详情如下:
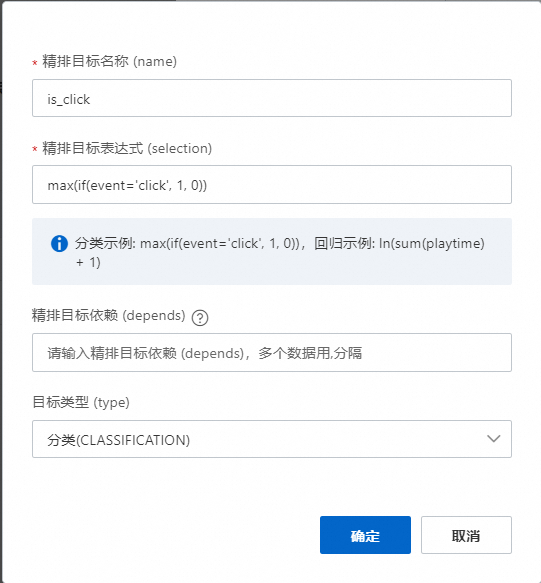
分类目标
精排目标名称自定义;精排目标表达式,一般我们是二分类目标,根据聚合条件做对应的聚合;目标类型分类就是classfication,如下图:
回归目标
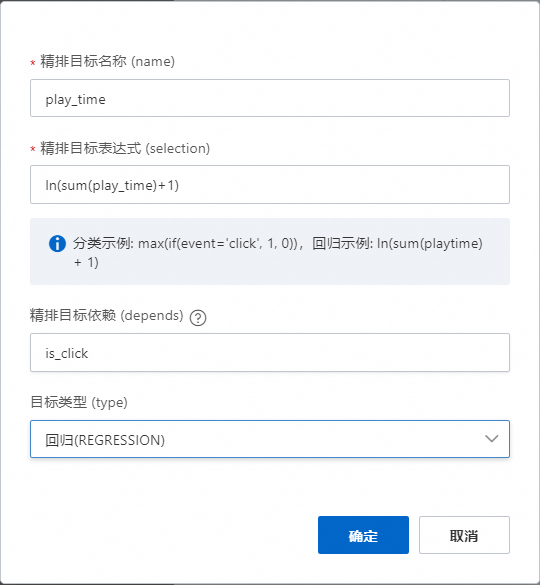
精排目标名称可自定义;
精排目标表达式:对于回归目标,我们需要对行为表目标数值做sum聚合加和,然后取log变换;
目标类型:选择回归目标regression;
精排目标依赖:如果某目标(x)需要依赖另外一个目标(y),可以在目标依赖处填写。例如:在视频中我们只有点击之后才会播放,播放的观看时长是play_time,那么play_time目标可以依赖点击目标(注意这里选择的是上面注册的分类任务名称is_click)。同理,别的分类任务也适用。如下图:
过滤字段:可以选择我们不需要参加训练的特征,或者不能在曝光之前获取到的特征,如play_time。
训练天数:表示我们用多少天的数据集进行训练精排模型。
模型选择:如果是单任务则结合EasyRec选择单任务的模型,是多任务的选择多任务的模型,此处我们是多任务,选择DBMTL。
特征选择方式,特征选择的目标列:特征选择方式如果有配置,将对所有的特征可以进行筛选,选择重要的特征进行训练,目标列则配合其选择方式,选择重要的特征。
是否增量训练:true则表示增量训练,我们后一天的训练会在前一天训练好的模型上继续训练。
是否异步训练:在分布式训练中是否异步训练。
样本权重:如果配置,则会对不同样本根据表达式获得权重,进而影响模型训练精度,一般不用。
场景数据筛选:是否用某特定场景下的数据进行训练。
使用特征平台:是否会使用配置好的FeatureStore,如果在推荐方案的环境配置中有配置FeatureStore,则会启用FeatureStore。
自动特征工程:是则会根据现有的特征,根据算法挖掘更有用的特征来进行训练。