
EasyRec算法框架中包含数据字段、特征,还包含FG(Feature Generate)特征的概念。这三个概念很容易搞混,因此我们重点介绍一下这些概念和差异。
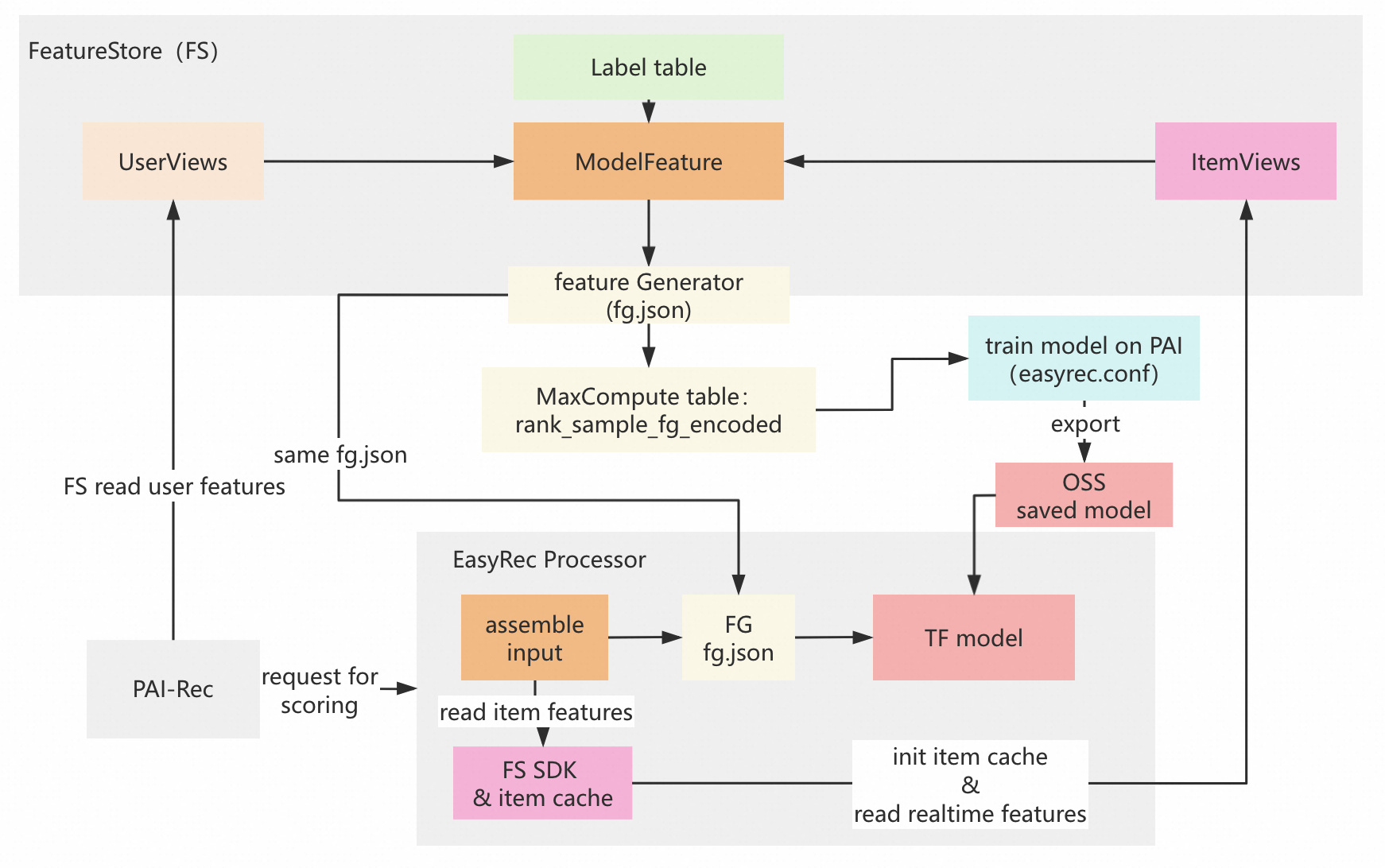
FG在PAI-Rec、PAI-FeatureStore、EasyRec Processor中的总览
名词解释
FeatureStore:PAI-FeatureStore是PAI平台下的特征平台管理工具,用于存储和管理离线和在线系统中的特征(详情见FeatureStore概述)。
FG:FG是Feature Generate(特征生成)的简称,FG是为了解决离线、在线特征处理的一致性问题的。具体的FG特征包括id_feature、raw_feature、combo_feature、lookup_feature、match_feature、sequence_feature、overlap_feature。我们用的比较多的是lookup_feature和sequence_feature,详情见RTP FG的特征配置说明。
用户特征(user features):以上案例描述推荐系统中的用户特征,包括从离线和在线系统中获取用户特征。在上图左下角 PAI-Rec推荐引擎是通过FeatureStore SDK(FS)读取用户特征。
物品特征(item features):在打分服务EasyRec Processor内部,通过FeatureStore SDK读取物品特征。
assemble input:根据请求里面的用户特征和缓存里面的物品特征,拼装成FG之前的特征。经过FG特征变换之后,喂给tensorflow模型打分。
EasyRec Processor:是指部署在PAI-EAS上的推荐、广告、搜索模型打分服务,主要是可以加载EasyRec相关的深度学习模型,并做了一系列性能优化工作。
easyrec.conf:即描述EasyRec深度学习模型用到的数据字段、特征类型,以及模型网络结构的文件。
链路解释
离线部分:在FS内部利用UserViews(指用户侧的多个特征视图),ItemViews(指物品侧的多个特征视图),Label Table(带有训练标签的MaxCompute表)构造得到ModelFeature(模型特征,即训练样本表),通过Feature Generator程序(即下文提到的mapreduce jar包:fg_on_odps-1.3.59-jar-with-dependencies.jar)以及特征变换文件fg.json,对ModelFeature表变换得到结果表rank_sample_fg_encoded,再根据easyrec.conf配置文件到PAI平台上做模型训练,把模型导出存储到OSS上,最终喂给Tensorflow模型打分。
在线部分:PAI-Rec推荐引擎中获取用户特征,内部获取需要打分的物品ID集合(图中忽略此部分逻辑),然后请求EasyRec Processor,在Processor内部组装特征,经过FG模块做在线特征变换,最终对物品ID打分并返回。
1. EasyRec配置文件中的数据字段和特征字段
1.1. 数据字段配置:data_config
data_config是EasyRec的配置文件(即上文提到的easyrec.conf)中说明数据的原始字段名称、类型、以及缺失值填充方式(参考EasyRec中的数据字段)。其中数据字段类型包括int、double、string等。数据可以存储为CSV文件、MaxCompute表、Kafka数据流等。
举例:key-value类型的数据
缺失值填充:默认值用一个KV值填充,即"-1024:0"
离线训练和在线预测逻辑:在Tensorflow模型中对缺失值做填充
input_fields: {
input_name: "prop_kv"
input_type: STRING
default_val:"-1024:0"
}1.2. 特征字段配置:feature_config
在data config中主要是数据和label的定义。而在feature_config中,说明了模型如何解析使用这些数据字段。例如一个字段x作为STRING类型的特征,但是在feature_config中可以按照IdFeature、TagFeature、SequenceFeature、TextCNN来解释。
举例:IdFeature特征
features {
input_names: "user_id"
feature_type: IdFeature
embedding_dim: 32
hash_bucket_size: 100000
}说明:user_id特征,通过哈希映射到100000个桶,每个桶号再通过模型训练映射到32维向量。
离线训练和在线预测的处理逻辑:在Tensorflow模型中把user_id变换为32维向量。
举例:RawFeature特征
features {
input_names: "ctr"
feature_type: RawFeature
boundaries: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
embedding_dim: 8
}预处理:通过PAI的离散化算法binning得到一组分隔点(boundaries),配置到feature_config的features中。
离线训练和在线预测的处理逻辑:上面的ctr特征,通过分隔点集合boundaries分桶得到桶号,然后根据桶号得到向量。
举例:TagFeature特征
features : {
input_names: 'tags'
feature_type: TagFeature
separator: '|'
hash_bucket_size: 100000
embedding_dim: 24
}如文章标签特征tags的值可能是“娱乐|搞笑|热门”,其中|为分隔符。
离线训练和在线预测的处理逻辑:在tf模型中把标签特征分别hash embedding,然后再做average pooling转化为embedding。
2. FG中的lookup_feature变换介绍
FG包含了多种特征组合和变换方式,以下用lookup特征变换为例:
{
"map": "user:map_brand_click_kv",
"key":"item:brand",
"feature_name": "map_brand_click_count",
"feature_type":"lookup_feature",
"needDiscrete":false,
}离线数据处理:需要jar包fg_on_odps-1.3.59-jar-with-dependencies.jar,把物品侧特征brand作为查询key,使用物品的品牌去用户侧特征map_brand_click_kv(表示用户在不同品牌下的点击次数统计)查询得到value值,把value作为新特征map_brand_click_count的值(即用户在该物品品牌下的点击次数)。
在线预测处理:在EasyRec Processor(推荐打分服务)中,先通过FG模块计算得到map_brand_click_count,然后喂给Tensorflow模型做预测。
3. 常见问题
3.1.离散化分隔点从哪里获取以及含义是什么?
在下面的EasyRec配置文件中,ctr特征包含了boundaries参数。具体如下:
feature_configs: {
input_names: "CTR"
feature_type: RawFeature
boundaries: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
embedding_dim: 8
}其中的分隔点集合boundaries,是使用阿里云PAI的binning组件分箱得到的。
在Tensorflow模型中,对上面CTR特征做离散化处理时,实际上是把分隔点集合boundaries看做一系列的离散化区间:(-inf, 0.1), [0.1, 0.2), [0.2, 0.3), [0.3, 0.4),[0.4, 0.5), [0.5, 0.6), [0.6, 0.7), [0.7, 0.8), [0.8, 0.9), [0.9, 1.0)。在配置了参数boundaries之后,需要再配置embedding_dim,即把区间编号变换为一个向量。
3.2. FG特征变换在线上系统怎么执行?怎么保证离线和在线的一致性?
FG特征变换依赖fg.json来描述特征变换过程。线上和离线系统都是用同一套代码来保证特征变换逻辑的一致性。线上系统是通过特征变换模块来执行特征变换。
3.3. 如何对特征做缺失值填充?特征填充在哪里执行?
在配置easyrec.config文件时,通过给data_config每一个特征字段设置default_value参数来进行缺失值的填充。在训练的时候,是读数据的时候根据default_value来填充缺失值;在线上模型推理的时候,需要先填充缺失值再推理。
在使用FG的情况下,缺失值填充在fg.json中描述,离线和在线都在FG模块中填充缺失值。