
一、Contextual Bandit 算法的适用范围
Contextual Bandit 算法虽然可以用来解决冷启动问题,但如果在一些基础条件不满足时,算法可能不能很好地收敛。
注意:
探索流量是否足够。如果一个场景新品数量很大,每时每刻都有新品源源不断地加进来,并且能够用来做探索的流量并不是很多时(比如每次请求返回结果列表里只有一个位置可以展现新品,且总流量也不是很多),算法的效果可能不会很好。平均每个新品应该能够获得几十次曝光的机会,如果无法满足此要求,可以考虑建模时不要使用Item作为Arm。
建模时的考虑。一般情况下可以使用Item本身作为Contextual Bandit算法的Arm,但如果面临流量不够时,可以考虑使用主题、类目等粗粒度Item属性作为Arm,算法计算出每次应该展现的Arm(主题、类目等),然后再使用某种策略展现该Arm下面的Item(比如展现最新的)。
考虑是否一定要使用冷启动排序。当条件不成熟时,仅仅使用基于模型的冷启动召回(如DropoutNet模型)也能取得不错的效果。我们可以在冷启动召回模型的基础上加上一定探索机制,比如当我们需要展现N个新品时,使用向量K近邻算法匹配出 M(M>N)个新品,保留相似度最高(距离最近)的个新品作为候选,然后再根据相似度的Softmax概率采样N-K个新品添加到候选集。
按相似度分数的概率采样候选物品既能够保证一定的相关性,也加入了Exploration机制。
二、创建Hologres表
1. 创建特征表
BEGIN;
CREATE TABLE rec.contextual_bandit_features (
request_id text NOT NULL,
user_id bigint NOT NULL,
arm_id bigint NOT NULL,
recom_time timestamp with time zone NOT NULL,
feature text NOT NULL
,PRIMARY KEY (user_id, arm_id)
);
CALL set_table_property('rec.contextual_bandit_features', 'orientation', 'row');
CALL set_table_property('rec.contextual_bandit_features', 'clustering_key', 'user_id:asc,arm_id:asc');
CALL set_table_property('rec.contextual_bandit_features', 'time_to_live_in_seconds', '259200');
CALL set_table_property('rec.contextual_bandit_features', 'distribution_key', 'user_id,arm_id');
CALL set_table_property('rec.contextual_bandit_features', 'storage_format', 'sst');
COMMENT ON TABLE rec.contextual_bandit_features IS '冷启动算法特征表';
COMMENT ON COLUMN rec.contextual_bandit_features.request_id IS '每次请求唯一的ID';
COMMENT ON COLUMN rec.contextual_bandit_features.user_id IS '用户ID';
COMMENT ON COLUMN rec.contextual_bandit_features.arm_id IS '在大多数场景下指item_id';
COMMENT ON COLUMN rec.contextual_bandit_features.recom_time IS '请求时间';
COMMENT ON COLUMN rec.contextual_bandit_features.feature IS '序列化的特征向量';
END;2. 创建模型表
BEGIN;
CREATE TABLE rec.contextual_bandit_models (
arm_id bigint NOT NULL,
version bigint NOT NULL,
invert_matrix_a integer[] NOT NULL,
vector_b integer[] NOT NULL,
matrix_b integer[]
,PRIMARY KEY (arm_id)
);
CALL set_table_property('rec.contextual_bandit_models', 'orientation', 'column');
CALL set_table_property('rec.contextual_bandit_models', 'clustering_key', 'arm_id:asc');
CALL set_table_property('rec.contextual_bandit_models', 'bitmap_columns', 'arm_id');
CALL set_table_property('rec.contextual_bandit_models', 'time_to_live_in_seconds', '259200');
CALL set_table_property('rec.contextual_bandit_models', 'storage_format', 'orc');
CALL set_table_property('rec.contextual_bandit_models', 'distribution_key', 'arm_id');
CALL set_table_property('rec.contextual_bandit_models', 'segment_key', 'version');
COMMENT ON TABLE rec.contextual_bandit_models IS '冷启动模型参数表';
COMMENT ON COLUMN rec.contextual_bandit_models.arm_id IS 'arm id';
COMMENT ON COLUMN rec.contextual_bandit_models.version IS '算法版本号:时间戳';
COMMENT ON COLUMN rec.contextual_bandit_models.invert_matrix_a IS 'linucb算法参数:矩阵A的逆矩阵';
COMMENT ON COLUMN rec.contextual_bandit_models.vector_b IS 'linucb算法参数:向量b';
COMMENT ON COLUMN rec.contextual_bandit_models.matrix_b IS 'linucb算法参数:矩阵B';
END;三、部署模型训练任务
下载Flink训练任务的Jar包ContextualBanditFlink-1.0-SNAPSHOT-jar-with-dependencies.jar 。
进入阿里云实时计算控制台——资源上传页面,上传刚刚下载的Jar包
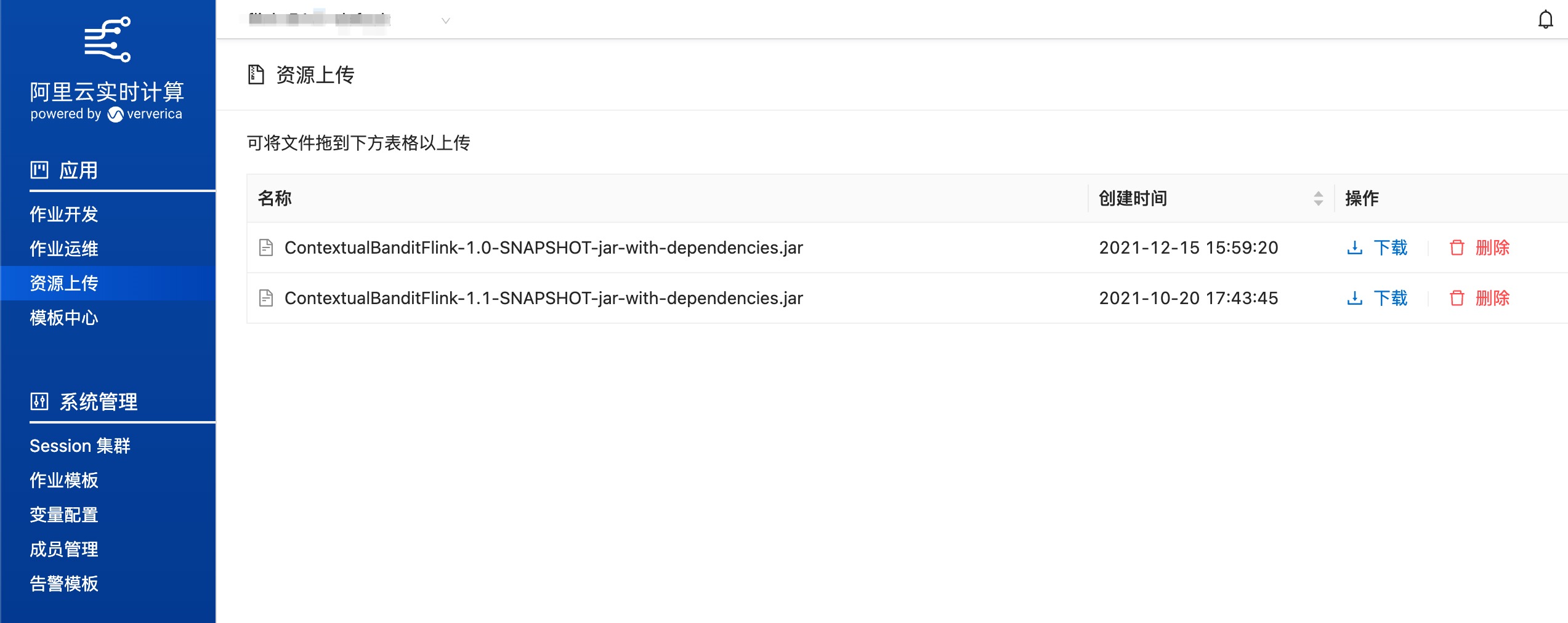
进入阿里云实时计算控制台——作业开发页面,创建作业——流作业/Jar
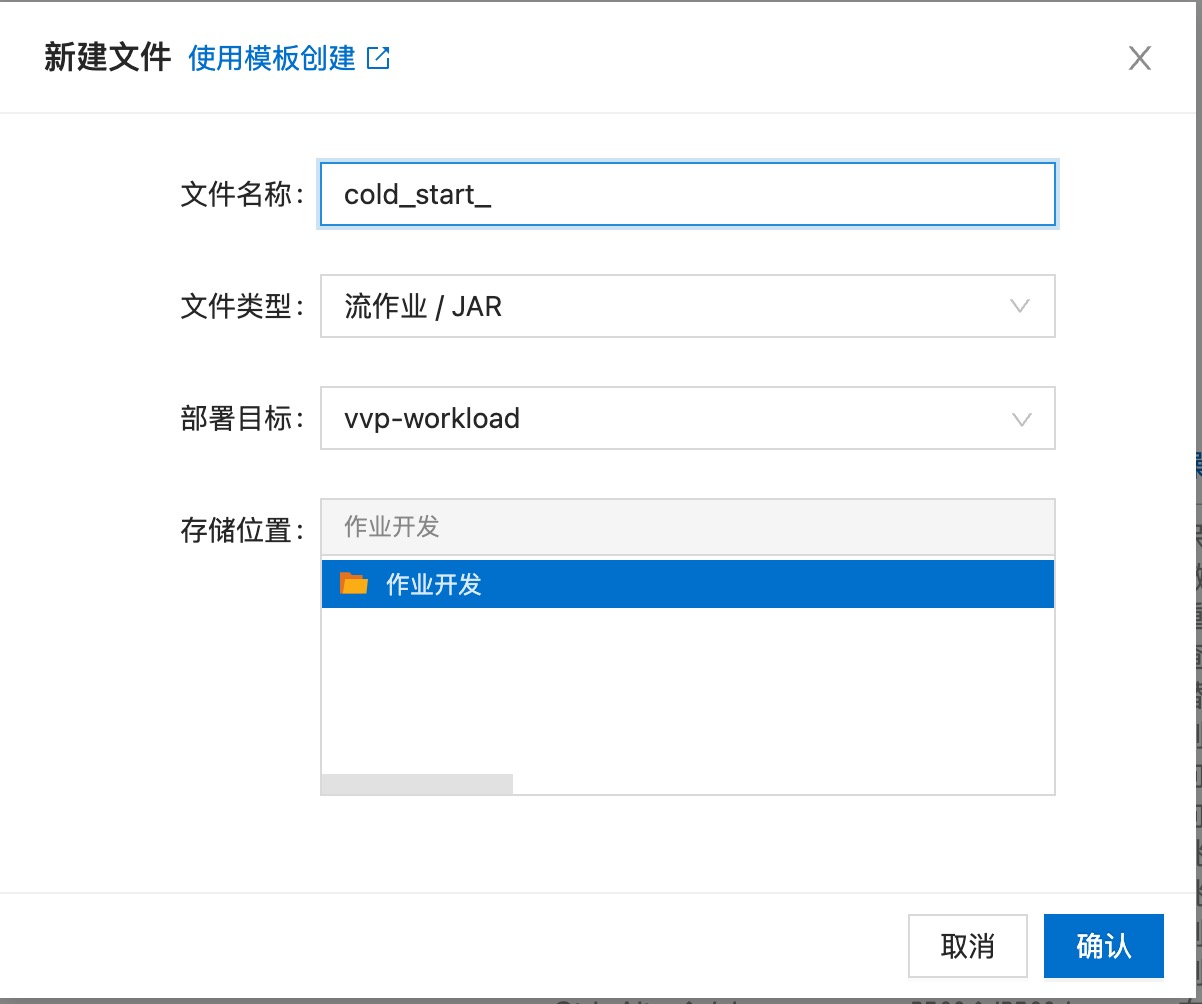
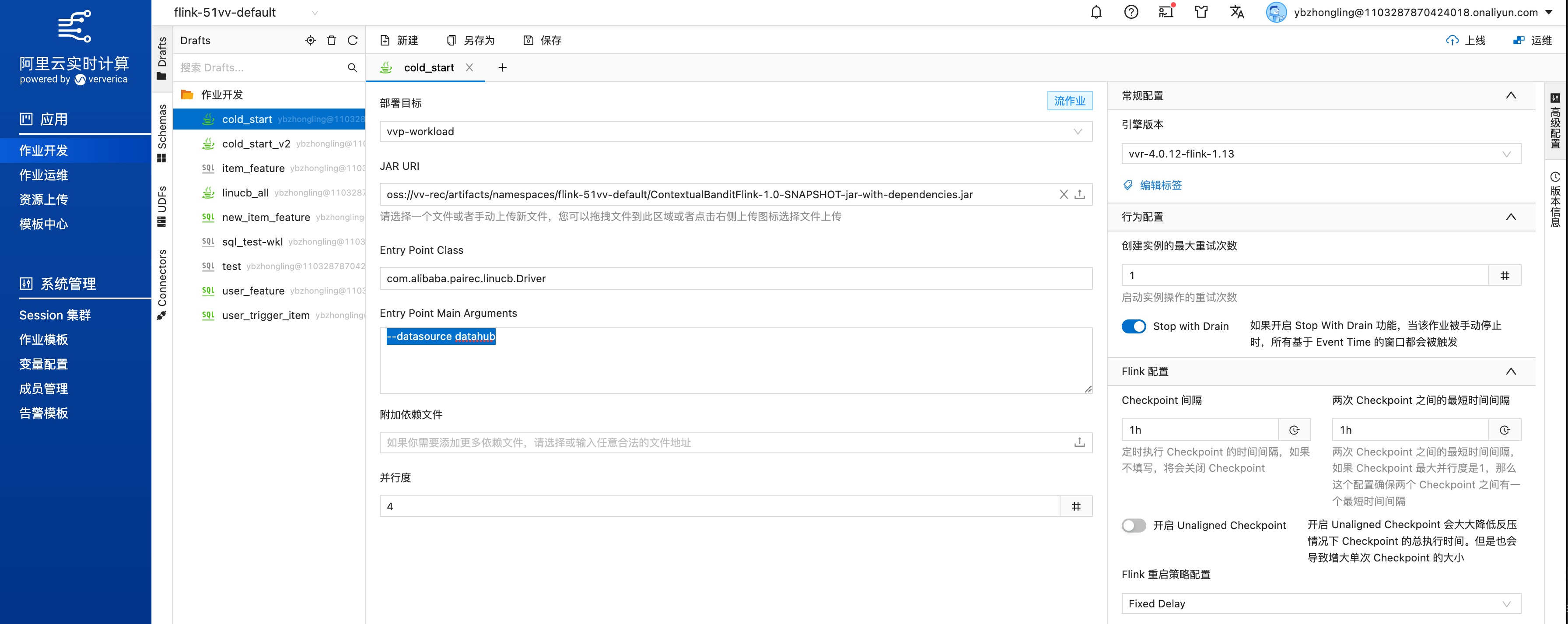
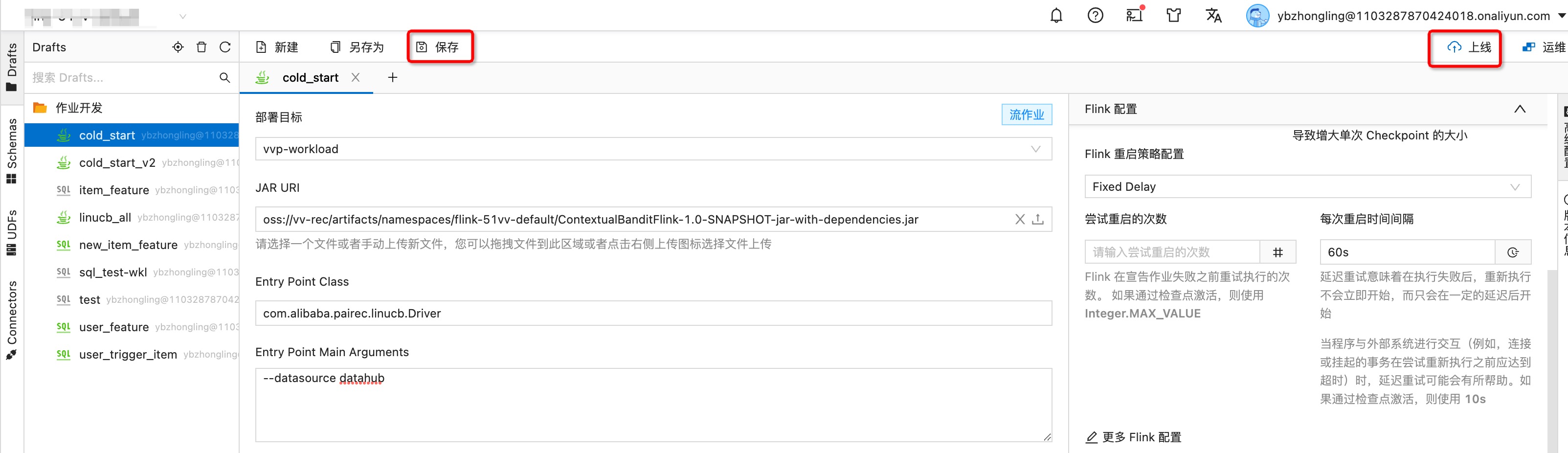
配置作业信息,
Jar URI选择刚上传的Jar;Entry Point Class文本框输入com.alibaba.pairec.linucb.Driver;Entry Point Main Arguments文本框输入--datasource datahub(如果数据来源为datahub)或者--datasource kafka(如果数据来源为kafka)
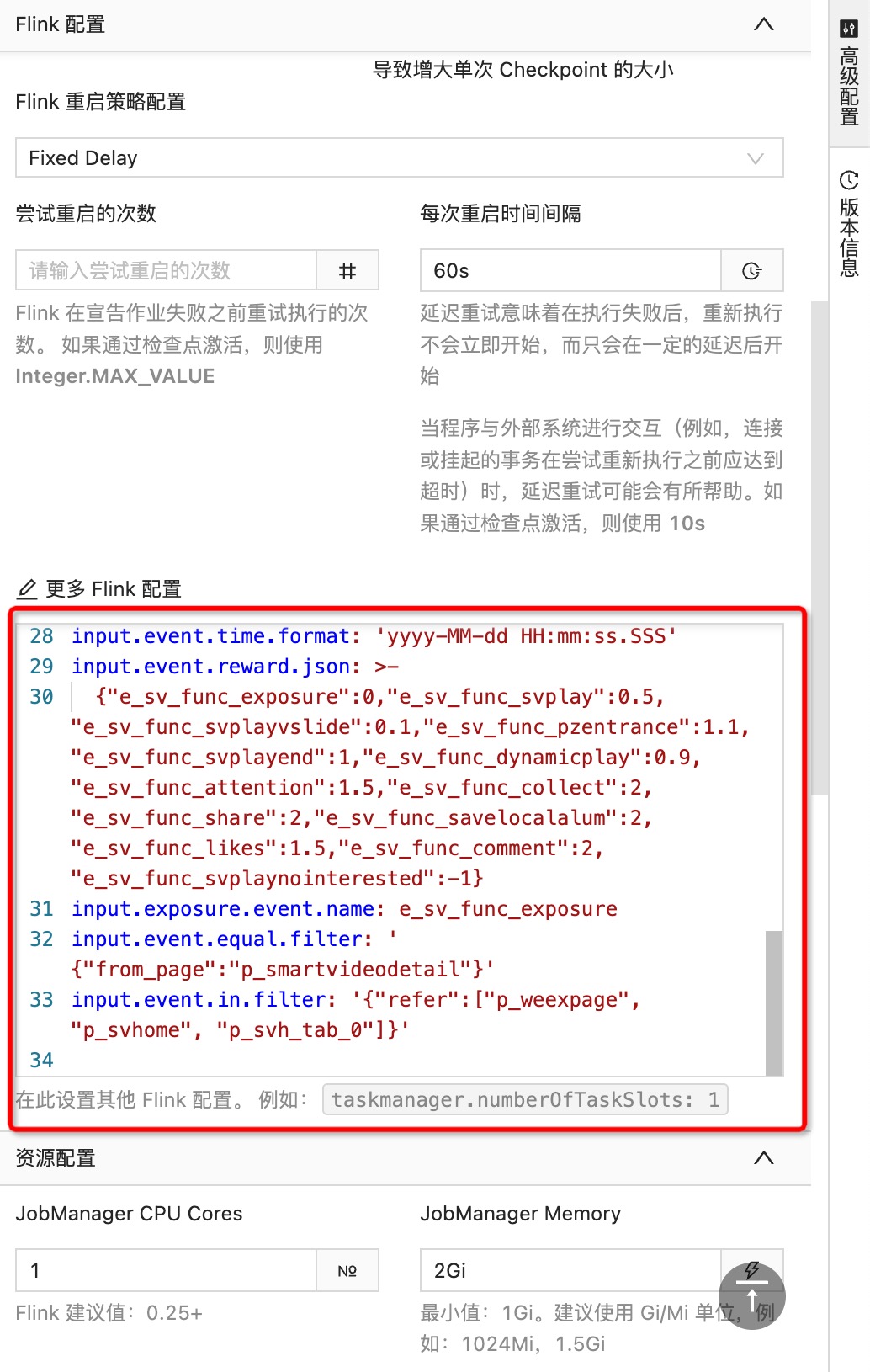
配置训练任务信息,在作业页面右侧高级配置浮窗的
更多Flink配置文本框中输入算法训练相关的配置
配置完毕后,点击左上方"保存"按钮,右上方"上线"按钮,发布任务。
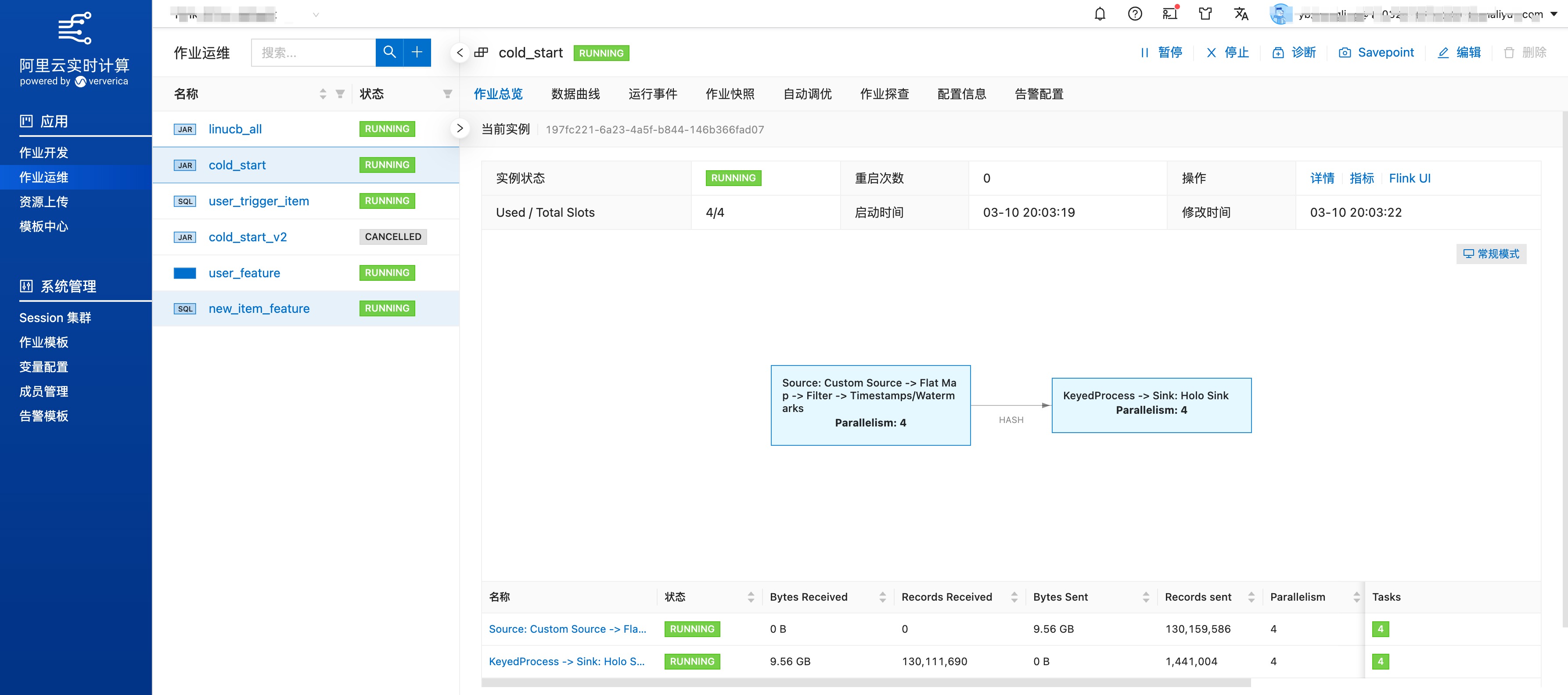
进入"作业运维"页面,启动任务; 并查看任务运行情况
四、部署模型打分服务
创建好模型打分服务需要的配置文档,并上传到OSS,获取对应的OSS公开可访问的路径。
准备好EAS服务的配置文件,假设文件名为eas_config.json, 示例如下:
{
"name": "cold_start",
"containers": [
{
"image": "mybigpai-registry.cn-beijing.cr.aliyuncs.com/mybigpai/eas-contextual-bandit:0.0.1-efa1d85",
"env": [
{
"name": "GIN_MODE",
"value": "release"
},
{
"name": "ALGO_CONFIG",
"value": "https://${bucket}.oss-cn-beijing-internal.aliyuncs.com/cold_start.json?OSSAccessKeyId=xxxxx&Expires=1001639368243&Signature=XXXX"
}
],
"port": 8000,
"command": "/linucb-server -l /log"
}
],
"metadata": {
"cpu": 15,
"instance": 2,
"memory": 22000
}
}其中,containers 参数的说明如下:
"image": "mybigpai-registry.cn-beijing.cr.aliyuncs.com/mybigpai/eas-contextual-bandit:0.0.1-efa1d85",是模型打分服务的镜像仓库地址,固定不变。
ALGO_CONFIG: value表示模型打分服务的配置文件,需要为公开可访问的地址。
通过eascmd命令行工具创建或更新EAS服务:
# 创建服务
#eval "${eascmd} create ../conf/eas_config.json"
# 更新服务
eval "${eascmd} modify cold_start -s ../conf/eas_config.json"
# 查看服务
eval "${eascmd} desc cold_start"五、在推荐服务中配置冷启动Pipeline
参考推荐引擎PaiRec的配置文档自定义 Pipeline 流程 ,配置单独冷启动推荐链路。
配置如下:
{
"PipelineConfs": {
"video_feed": [ // 场景名称,场景,可以配置多个 pipeline
{
"Name": "coldstart", // 自定义 pipeline 名称,全局唯一,不同场景也要唯一
"RecallNames": [], // 召回列表, RecallConfs 里定义
"FilterNames": [], // 过滤列表, FilterConfs 里定义
"GeneralRankConf": { // 粗排定义, 可以参考粗排的配置
"FeatureLoadConfs":[],
"RankConf":{},
"ActionConfs": [
{
"ActionType": "filter",
"ActionName": ""
}
]
},
"FeatureLoadConfs":[],
"RankConf":{
"RankAlgoList":[],
"RankScore":"",
"Processor":"",
"BatchCount": 100
},
"ColdStartRankConf": {
"AlgoName":"",
"OnlyEmbeddingFeature": true
},
"SortNames":[] // 排序处理,SortConfs 里定义
}
]
}
}冷启动Pipeline的结果会与常规主流程的推荐结果融合在一起。
六、新品冷启动效果评估
新品冷启动是作用在物品侧的算法,因此,不能再使用流量划分的A/B测试方法来评估效果。
在做算法效果度量时,需要以物品集的划分为实验对比的对象,比如:
基准桶:针对item id(或hash值)为奇数的新物品集合,不使用冷启动算法。比如,常规推荐,或随机展现新品。
实验桶:针对item id(或hash值)为偶数的新物品集合,使用冷启动算法,如LinUcb算法。
统计指标需根据业务特点确定,比如曝光量、点击率、留存率、播放时长等。