
为方便您快捷体验PAI-Rec产品,本文提供了一份公开数据集,您可以按照文档说明,按步骤体验PAI-Rec推荐算法定制的特征工程、召回、精排等关键功能的配置,生成代码并部署到DataWorks相应的业务流程中。
前提条件
在开始执行操作前,请确认您已完成以下准备工作:
已开通PAI,详情请参见开通PAI并创建默认工作空间。
已创建专有网络VPC和交换机,详情请参见搭建IPv4专有网络。
已开通PAI-FeatureStore(参考新建数据源的前提条件部分),注意数据源部分不用开通Hologres,数据源选择FeatureDB,参考新建在线数据源:FeatureDB。
已开通MaxCompute服务,并创建MaxCompute项目project_mc,详情请参见开通MaxCompute和创建MaxCompute项目。
创建OSS存储空间(Bucket),详情请参见创建存储空间。
开通DataWorks服务,并完成以下操作:
已创建DataWorks工作空间,操作详情请参见创建工作空间。
购买DataWorks的Serverless资源组,操作详情请参见使用Serverless资源组。资源组用于PAI-FeatureStore同步数据,以及执行eascmd的命令创建和更新PAI-EAS服务。
配置DataWorks数据源:
创建并绑定OSS数据源,详情请参见数据源管理。
创建并绑定MaxCompute数据源,详情请参见绑定MaxCompute计算资源。
创建FeatureStore项目和特征实体。如果是Serverless资源组则跳过本条目;如果是DataWorks独享资源组,在资源组上需要安装FeatureStore Python SDK,详情请参见二、创建并注册FeatureStore和安装FeatureStore Python SDK。
开通Flink,详情请参见开通实时计算Flink版。注意“存储类型”选择“OSS bucket”,不要选择“全托管存储”,并且保证Flink的OSS与PAI-Rec云产品配置中的OSS bucket一致。Flink用于记录实时用户行为数据,统计用户实时特征。
当您后续选择用EasyRec(TensorFlow框架)的时候,默认是在MaxCompute上训练。
当您后续选择TorchEasyRec(PyTorch框架)的时候,默认是在PAI-DLC上训练。PAI-DLC上下载MaxCompute数据需要开通数据传输服务(参考购买与使用独享数据传输服务资源组)。
1.创建PAI-Rec实例并初始化服务
登录全链路推荐系统开发平台首页,单击立即购买。
在PAI-Rec实例购买页面,配置以下关键参数,然后单击立即购买。
参数
说明
地域和可用区
您的云服务部署的地域。
服务类型
本方案选择高级版。
说明相较于标准版,高级版增加了数据诊断和推荐方案定制功能。
登录PAI-Rec管理控制台,在顶部菜单栏左上角处,选择地域。
在左侧导航栏选择实例列表,单击实例名称,进入实例详情页面。
单击操作指引区域的初始化,跳转至系统配置>全链路服务页面,单击编辑,按照如下资源配置完成相应参数配置,然后单击完成。
在左侧导航栏选择系统配置>权限管理,按照界面提示,在访问服务页签检查各项云产品授权情况,确保对应云产品访问状态正常。
2. 克隆公开数据集
1.同步数据表
本方案的输入数据有两种方案:
从pai_online_project项目中克隆固定时间窗的数据,不支持任务例行调度执行。
提供Python脚本,通过代码产出数据,可以通过DataWorks执行任务产出指定时间段的数据。
如果需要调度每天产出数据和训练模型,建议使用第二种方案。您需要部署指定的Python代码以生成所需数据,详情请参见“通过代码产出数据”页签。
同步固定时间窗的数据
PAI-Rec在公开访问的项目pai_online_project中提前准备了推荐算法中常用的三张表:
用户表:pai_online_project.rec_sln_demo_user_table
物品表:pai_online_project.rec_sln_demo_item_table
行为表:pai_online_project.rec_sln_demo_behavior_table
本方案后续的操作均基于上述三张表,其数据均是随机生成的模拟数据,没有真实业务含义,因此训练得到的AUC等指标较低。您需要在DataWorks中执行SQL命令,从pai_online_project项目中将上述表数据同步到您的DataWorks项目(例如DataWorks_a)中。具体操作步骤如下:
登录DataWorks控制台,在顶部菜单栏左上角处,选择地域。
在左侧导航栏单击数据开发与运维>数据开发。
选择已创建的DataWorks工作空间后,单击进入数据开发。
鼠标悬停至新建,选择新建节点>MaxCompute>ODPS SQL,按照如下资源配置完成相应参数配置,然后单击确认。
在新建节点区域,复制并运行下面的代码,将用户表、物品表、行为表从pai_online_project项目同步到您已创建的MaxCompute项目(例如project_mc)中。执行代码需要设置变量,指定bizdate到bizdate日期之前100天的数据。一般把bizdate设置为当前的日期的前一天,设置调度参数如下:
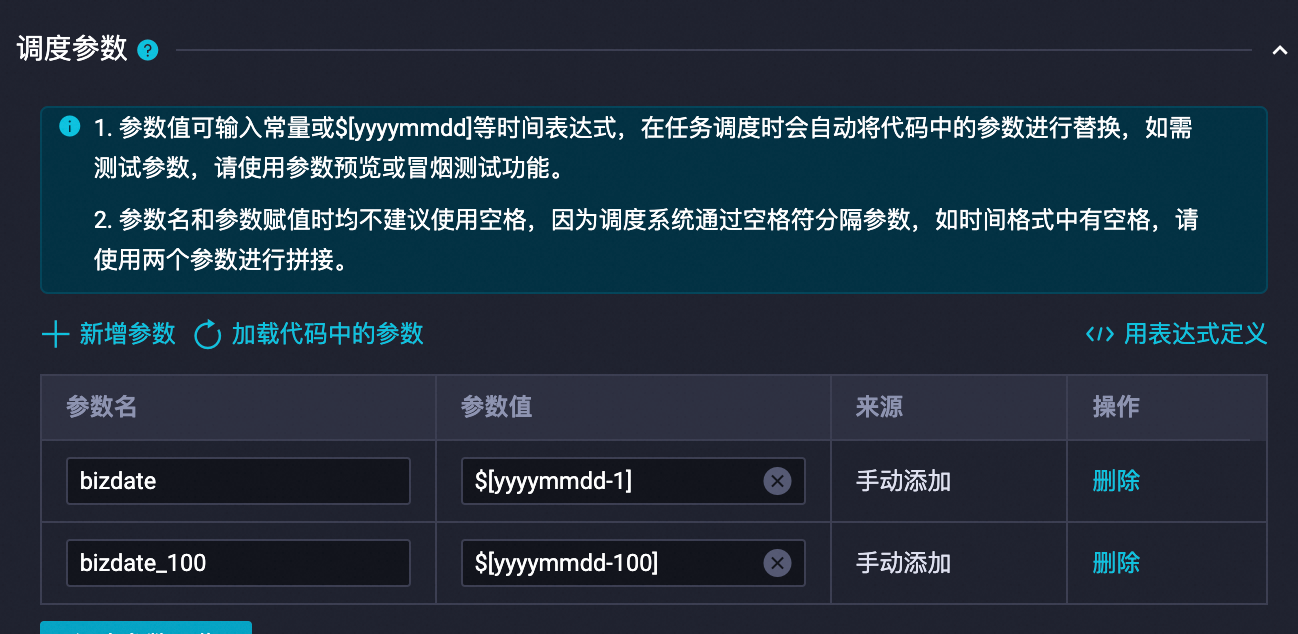 以下代码执行一次,即可将数据从公共的pai_online_project项目复制到用户的项目中:
以下代码执行一次,即可将数据从公共的pai_online_project项目复制到用户的项目中:
CREATE TABLE IF NOT EXISTS rec_sln_demo_user_table_v1(
user_id BIGINT COMMENT '用户唯一ID',
gender STRING COMMENT '性别',
age BIGINT COMMENT '年龄',
city STRING COMMENT '城市',
item_cnt BIGINT COMMENT '创作内容数',
follow_cnt BIGINT COMMENT '关注数',
follower_cnt BIGINT COMMENT '粉丝数',
register_time BIGINT COMMENT '注册时间',
tags STRING COMMENT '用户标签'
) PARTITIONED BY (ds STRING) STORED AS ALIORC;
INSERT OVERWRITE TABLE rec_sln_demo_user_table_v1 PARTITION(ds)
SELECT *
FROM pai_online_project.rec_sln_demo_user_table
WHERE ds >= "${bizdate_100}" and ds <= "${bizdate}";
CREATE TABLE IF NOT EXISTS rec_sln_demo_item_table_v1(
item_id BIGINT COMMENT '内容ID',
duration DOUBLE COMMENT '视频时长',
title STRING COMMENT '标题',
category STRING COMMENT '一级标签',
author BIGINT COMMENT '作者',
click_count BIGINT COMMENT '累计点击数',
praise_count BIGINT COMMENT '累计点赞数',
pub_time BIGINT COMMENT '发布时间'
) PARTITIONED BY (ds STRING) STORED AS ALIORC;
INSERT OVERWRITE TABLE rec_sln_demo_item_table_v1 PARTITION(ds)
SELECT *
FROM pai_online_project.rec_sln_demo_item_table
WHERE ds >= "${bizdate_100}" and ds <= "${bizdate}";
CREATE TABLE IF NOT EXISTS rec_sln_demo_behavior_table_v1(
request_id STRING COMMENT '埋点ID/请求ID',
user_id STRING COMMENT '用户唯一ID',
exp_id STRING COMMENT '实验ID',
page STRING COMMENT '页面',
net_type STRING COMMENT '网络型号',
event_time BIGINT COMMENT '行为时间',
item_id STRING COMMENT '内容ID',
event STRING COMMENT '行为类型',
playtime DOUBLE COMMENT '播放时长/阅读时长'
) PARTITIONED BY (ds STRING) STORED AS ALIORC;
INSERT OVERWRITE TABLE rec_sln_demo_behavior_table_v1 PARTITION(ds)
SELECT *
FROM pai_online_project.rec_sln_demo_behavior_table
WHERE ds >= "${bizdate_100}" and ds <= "${bizdate}";通过代码产出数据
使用固定时间窗的数据,不支持任务例行调度执行。如果有执行需求,您需要部署特定的Python代码以生成所需数据。具体操作步骤如下:
在DataWorks控制台创建PyODPS 3节点,详情请参见创建并管理MaxCompute节点。
单击并下载create_data.py,将文件内容粘贴到PyODPS 3节点中。
单击右侧的调度配置,并配置以下参数,然后单击右上角的保存
 和提交
和提交 。
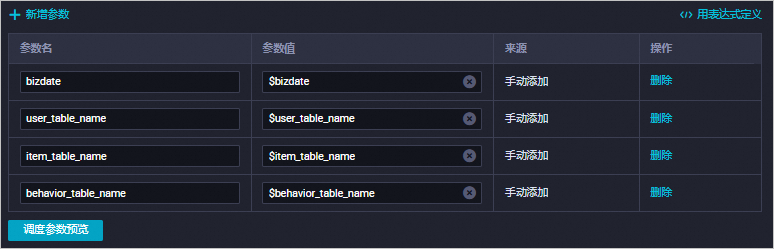
。配置调度参数:
注意替换变量:
$user_table_name可以替换为rec_sln_demo_user_table
$item_table_name可以替换为rec_sln_demo_item_table
$behavior_table_name可以替换为rec_sln_demo_behavior_table
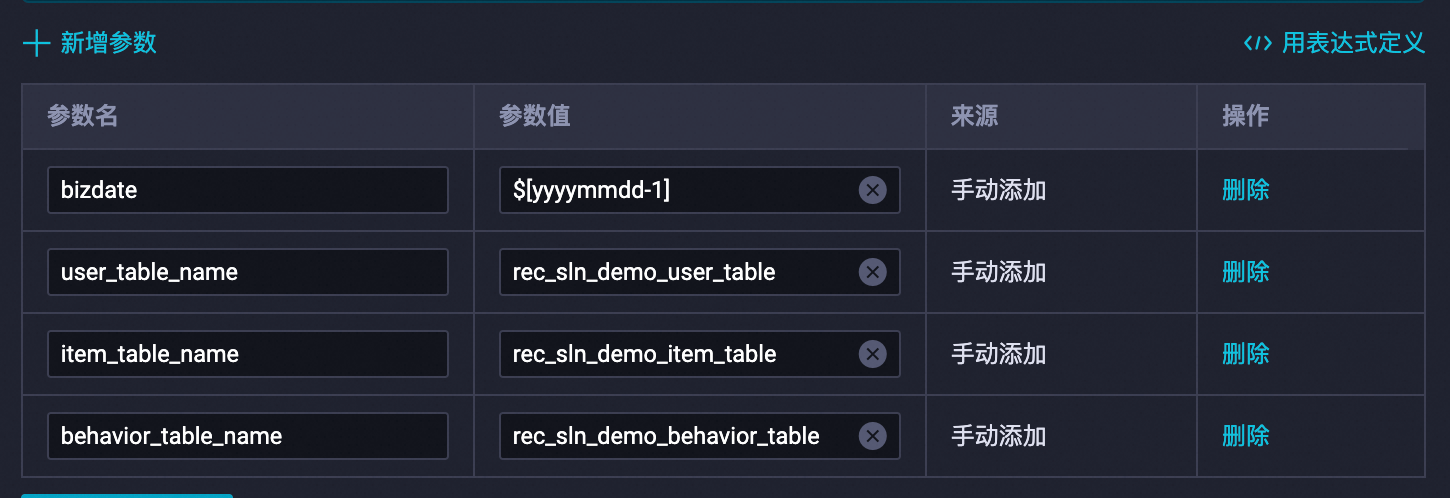
替换后:
配置调度依赖。
单击运维中心,并选择。
单击目标任务操作列下的。
在补数据配置面板中,设置业务日期,并单击提交并跳转。
较好的补数据时间范围为60天,建议您将业务日期设置为
任务定时调度日期-60,以确保数据的完整性。
2.配置依赖节点
为了确保后续代码生成与部署的顺利进行,请预先在您的DataWorks项目中添加三个SQL代码节点。请将这些节点的调度依赖配置为工作空间的根节点,完成所有设置后再发布节点。具体操作步骤如下:
鼠标悬停至新建,选择新建节点>通用>虚拟节点,按照如下资源配置分别创建3个虚拟节点,然后单击确认。
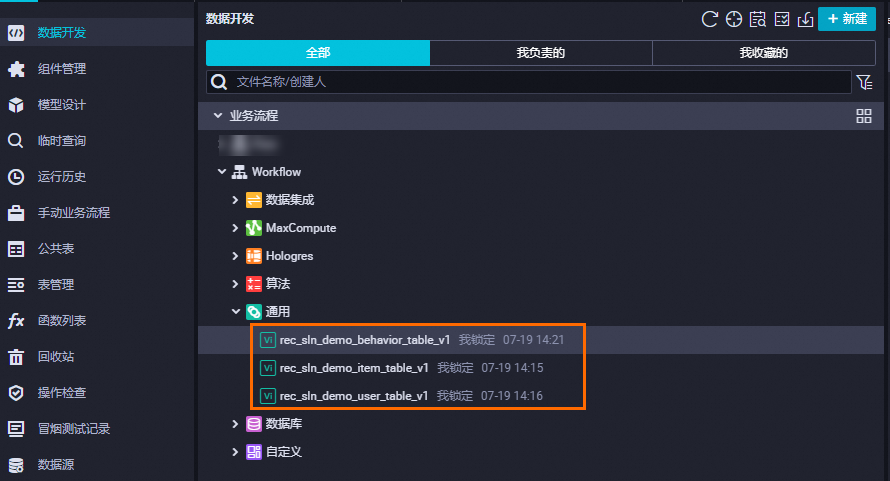
选中节点,分别将代码节点内容设置为
select 1;,然后单击右侧的调度配置,完成以下配置:在时间属性区域,设置重跑属性为运行成功或失败后节点重跑。
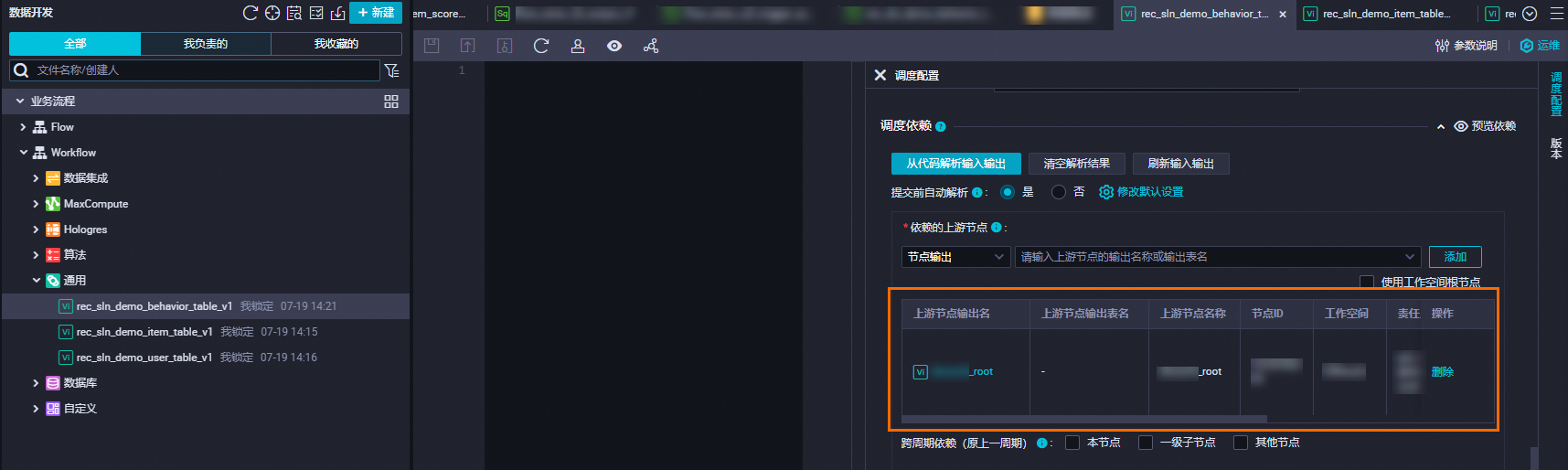
在调度依赖>依赖的上游节点区域,输入DataWorks工作空间名称,选择带有_root后缀的节点,单击添加。
3个虚拟节点均需配置。
单击虚拟节点前的
 ,提交该节点。
,提交该节点。
3.注册数据
为了后续在推荐方案定制功能中配置特征工程、召回、排序算法,您需要先注册同步到DataWorks项目中的三张表,具体操作步骤如下:
登录PAI-Rec管理控制台,在顶部菜单栏左上角处选择地域。
在左侧导航栏选择实例列表,单击实例名称,进入实例详情页面。
在左侧导航栏选择推荐方案定制>数据注册,在MaxCompute表页签单击新增数据表,按照如下资源配置分别新增1个用户表、1个物品表和1个行为表,然后单击开始导入。
参数
说明
方案默认示例
MaxCompute项目
选择已创建的MaxCompute项目。
project_mc
MaxCompute表
选择已同步到DataWorks工作空间的数据表。
用户表:rec_sln_demo_user_table_v1
物品表:rec_sln_demo_item_table_v1
行为表:rec_sln_demo_behavior_table_v1
数据表名称
自定义填写。
用户表
物品表
行为表
4.创建推荐场景
在配置推荐任务之前需要先创建一个推荐场景。推荐场景的基本概念、流量编码含义参考基本概念。
在左侧导航栏选择推荐场景,单击创建场景,按照如下资源配置创建1个推荐场景,然后单击确定。
5.创建并配置算法方案
如果您需要完整配置一个真实场景,建议配置的召回和精排如下。
全局热门召回:日志数据中,全面热门数据的统计排名取Top k。
全局热门兜底召回:使用Redis作为兜底,防止推荐接口下发数据为空。
分组热门召回:按照城市、性别区间等指标来分类召回,这对提高热门物品的准确性有帮助。
etrec u2i召回:基于etrec协同过滤算法。
swing u2i召回(可选):基于Swing算法。
冷启动召回(可选):dropoutnet算法的冷启动召回。
精排:单目标可以选择MultiTower排序;多目标可选择DBMTL排序。
一般当召回比较全面之后再开启向量召回或者PDN召回等算法。向量召回需要配合向量召回引擎,因为FeatureDB不支持向量召回,因此我们在本案例中不配置向量召回。
本文旨在体验配置与部署流程,因此在召回配置环节只配置了全局热门召回及RECommender(eTREC,一种协同过滤的实现)的u2i召回策略。在排序配置上,选择了精细化排名以优化体验。具体操作步骤如下:
在左侧导航栏选择推荐方案定制>方案配置,选择已创建的场景,并单击创建推荐方案,按照如下资源配置创建1个方案,然后单击保存并进入算法方案配置。
未说明的参数保持默认即可,详情请参见数据表配置。
在数据表配置节点,单击目标数据表右侧的添加,按照如下资源配置分别设置行为日志表、用户表和物品表,并设置相应的分区、事件、特征、时间戳等字段,然后单击下一步。
未说明的参数保持默认即可,详情请参见数据表配置。
在特征配置节点,按照如下资源配置完成相应参数配置,单击生成特征,设置特征版本,然后单击下一步。
单击生成特征后,会在用户和物品侧衍生出多种统计特征,本方案不对衍生特征进行二次编辑,保持默认即可。您可以根据自身业务需求,对衍生特征进行编辑,详情请参见特征配置。
在召回配置节点,单击目标分类右侧的添加,完成相应参数配置,单击确认,然后单击下一步。
以下内容包含了多种召回配置方法,为了带您快速体验部署流程,您可以只配置全局热门召回和etrec u2i召回。其他向量召回、协同度量召回等仅供参考。
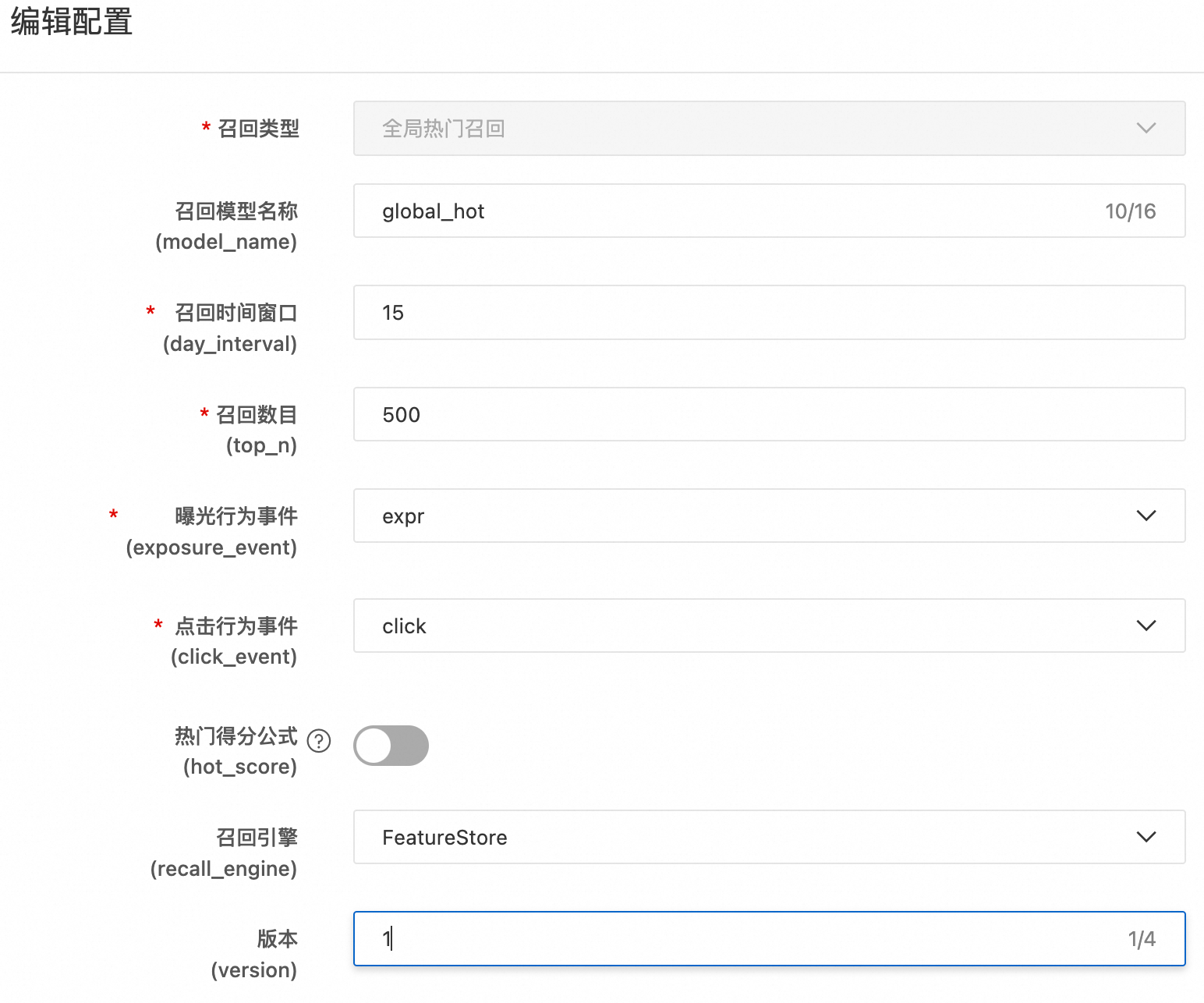
全局热门召回
全局热门召回是根据点击事件统计得到热门的物品排行榜(top_n表示排行榜个数)。如果要修改热门的得分公式或者访问事件,您可在生成相关代码后,将其部署到DataWorks平台再进行修改。
打分公式为
click_uv*click_uv/(expr+adj_factor)*exp(-item_publish_days/fresh_decay_denom),其中click_uv:相同点击率(CTR)时,点击量越多,则越热门。
click_uv/(expr+adj_factor):平滑后的点击率(CTR),其中click_uv表示点击用户数量,expr表示曝光数量。增加调节因子adj_factor,一方面是为了防止分母为0,另一方面是当曝光数量很少的时候,CTR会接近于1,加上adj_factor之后CTR会远离1,从而使得CTR更加趋近于真实的CTR。
exp(-item_publish_days/fresh_decay_denom):惩罚发布早的商品。其中item_publish_days表示从发布时间到当前的天数。
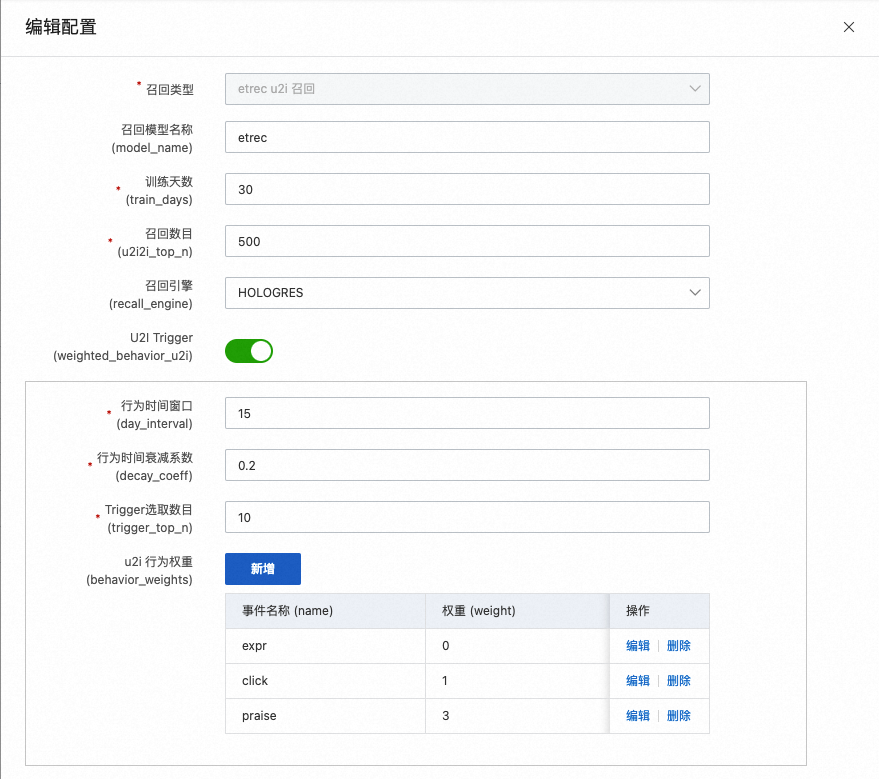
etrec u2i召回
etrec是基于item的协同过滤算法,详情请参见协同过滤etrec。
参数
描述
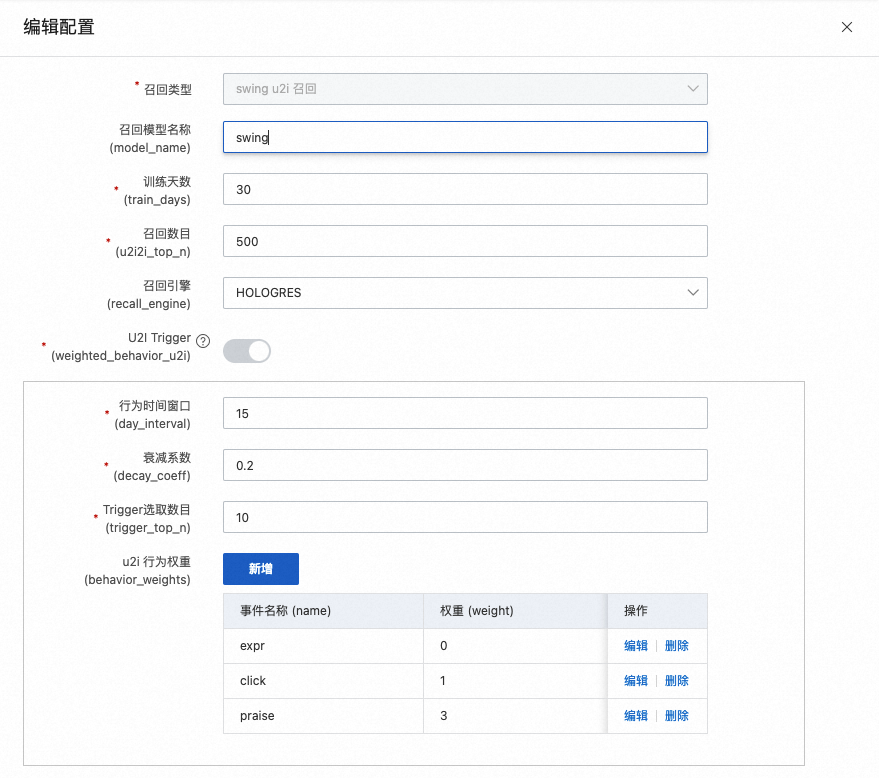
训练天数
表示使用多少天的行为日志来训练。默认为30天,您可以根据日志量来增减。
召回数目
表示最终离线产出的用户到物品的数量。
U2ITrigger
表示用户有交互行为的物品。例如用户点击、收藏或购买的物品,一般不包含曝光物品。
行为时间窗口
表示收集多少天内的行为数据,默认为15,表示最近15天。
行为时间衰减系数
一般介于0-1之间,值越大表示过去的行为距离今天衰减越厉害,在构造trigger_item中其占比权重越小。
Trigger选取数目
指每个用户取多少个物品ID去与etrec产出的i2i数据做笛卡尔积。建议取值在10到50之间。如果Trigger的数目太大会造成召回的候选物品数量太多。
u2i行为权重
其中注意曝光事件要么不设置,要么设置为权重0。建议不设置曝光事件,即跳过用户曝光数据。
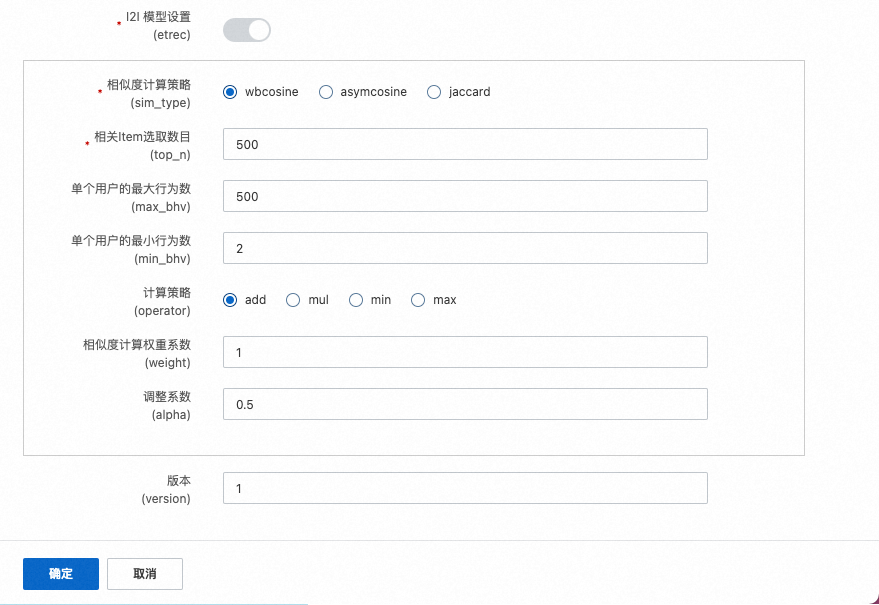
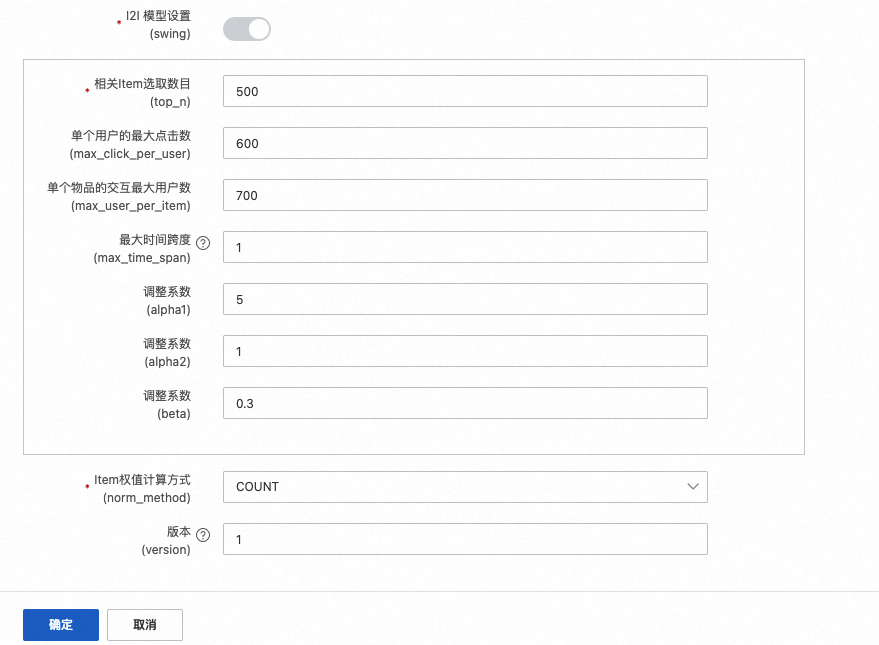
I2I模型设置
etrec的参数设置,详情请参见协同过滤etrec。其中相关Item选取数目建议不要太多。
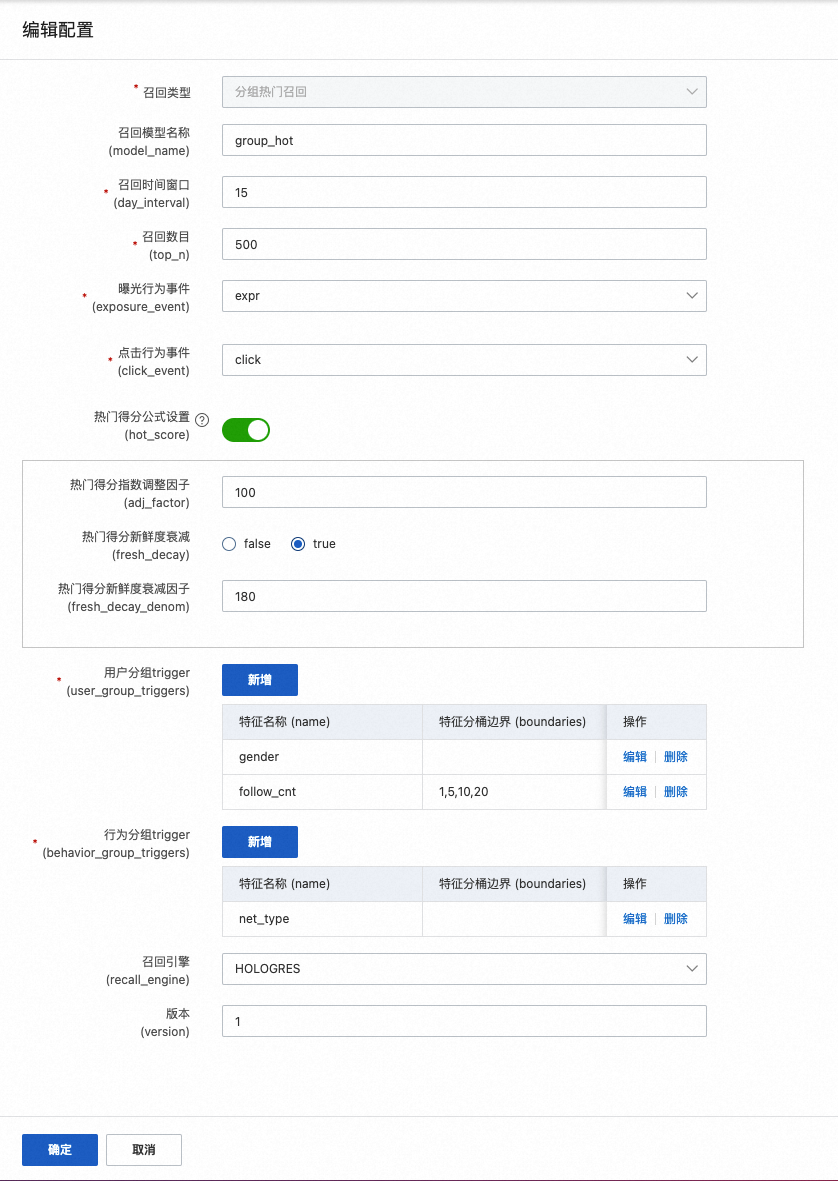
分组热门召回
即可设置按照城市、性别等属性来统计排行榜,能提供初步个性化的召回。如下示例中,使用性别和数值的分桶号组合作为分组。
swing u2i召回
Swing是一种item相关性计算方法,基于User-Item-User原理衡量Item的相似性。
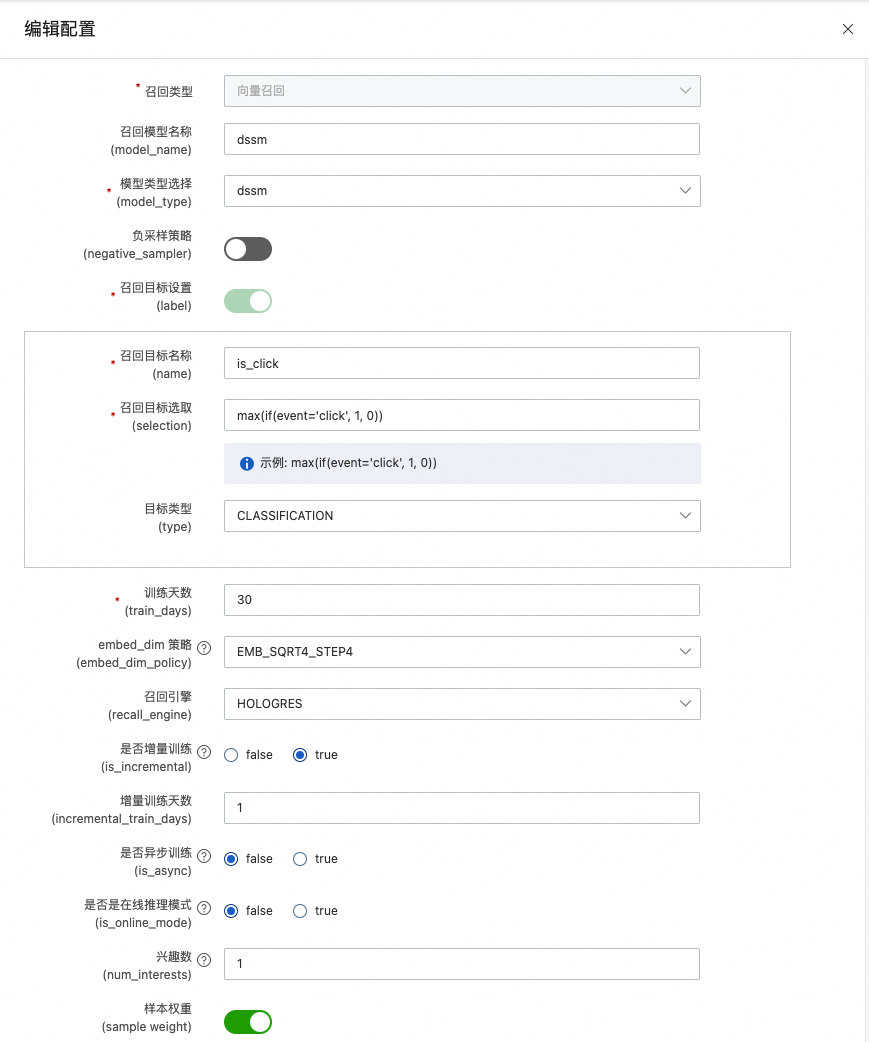
向量召回
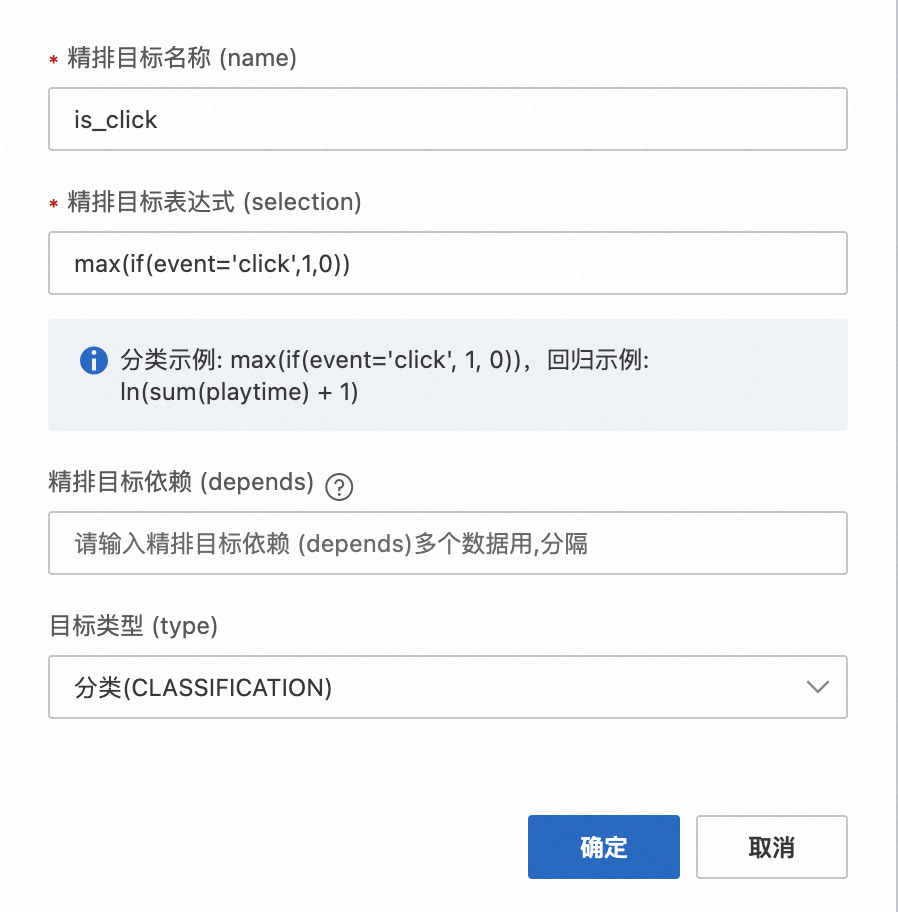
召回目标名称:一般指是否点击,设置为is_click。
召回目标选取: 设置为
max(if(event='click', 1, 0))。该部分在执行的时候可以参考如下代码:
select max(if(event='click',1,0)) is_click ,... from ${behavior_table} where between dt=${bizdate_start} and dt=${bizdate_end} group by req_id,user_id,item其中:
${behavior_table}:表示行为表。
${bizdate_start}:是行为时间窗的开始日期。
event:是${behavior_table}表里面事件字段,需根据具体字段选择。
is_click:即目标名称。
其中维度计算的公式如下:
EMB_SQRT4_STEP8: (8 + Pow(count, 0.25)) / 8) * 8 EMB_SQRT4_STEP4: (4 + Pow(count, 0.25)) / 4) * 4 EMB_LN_STEP8: (8 + Log(count + 1)) / 8) * 8 EMB_LN_STEP4: (4 + Log(count + 1)) / 4) * 4其中count表示特征枚举值个数。当特征取值个数较多时,使用Log函数。

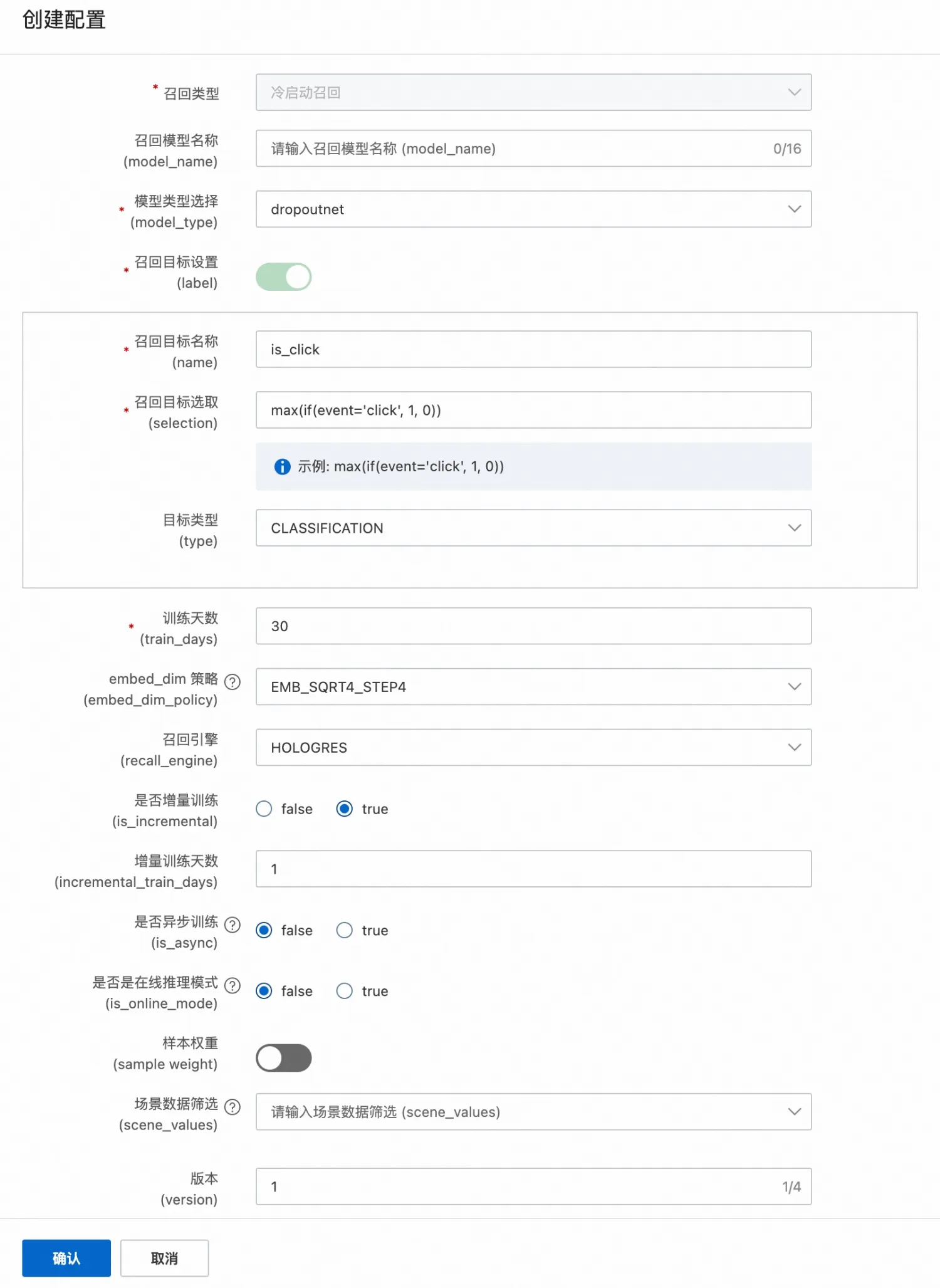
冷启动召回
类似于DSSM的双塔召回模型,分为user塔和item塔。DropoutNet是一种既适用于头部用户和物品,也适用于中长尾,甚至全新的用户和物品的召回模型。
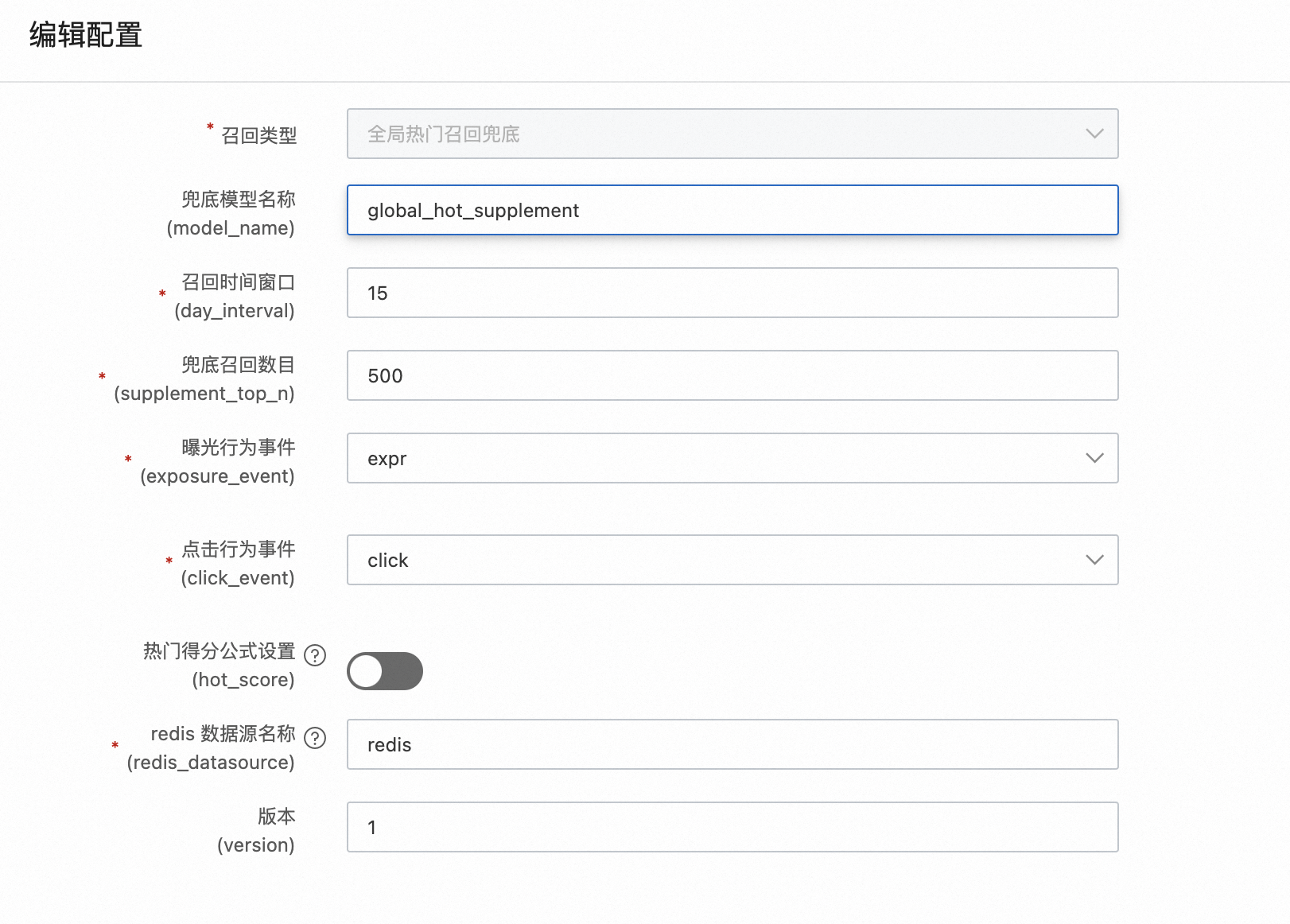
全局热门召回兜底
全局热门召回兜底和全局热门召回基本一致,主要是为了防止全局热门召回引擎失败情况下能够召回足够多的候选集,因此将其存放在Redis存储中,该产出只有一行数据。
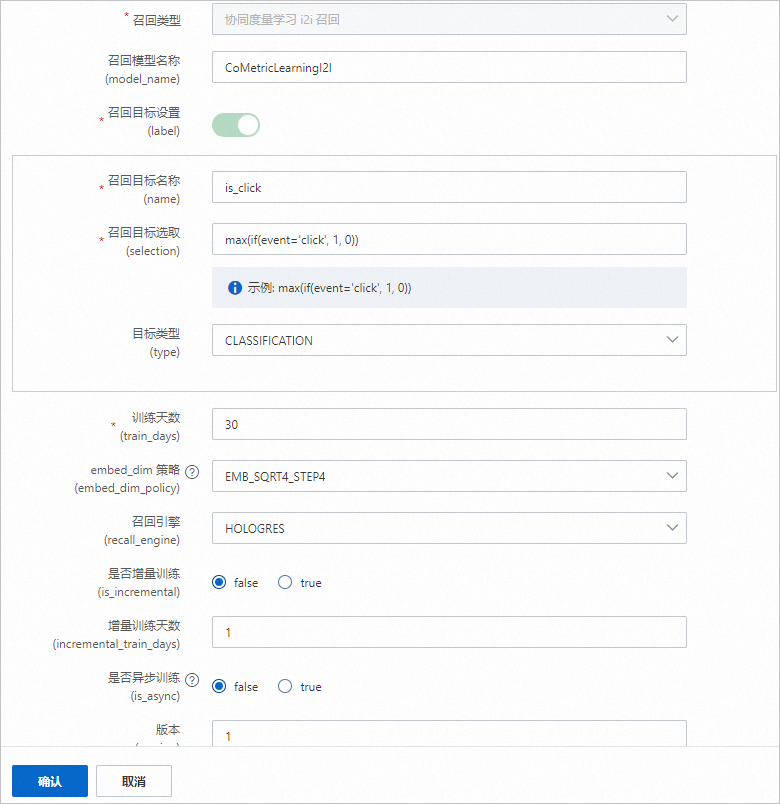
协同度量学习i2i召回
协同度量学习i2i召回,又称Collaborative Metric Learning I2I召回模型,基于session点击数据计算item与item的相似度。
在排序配置节点,单击精排右侧的添加,按照如下资源配置完成相应参数配置,单击确认,然后单击下一步。
本平台提供多种排序模型,具体可参考排序模型。下面是按照多目标排序模型DBMTL来设置相关的排序参数。
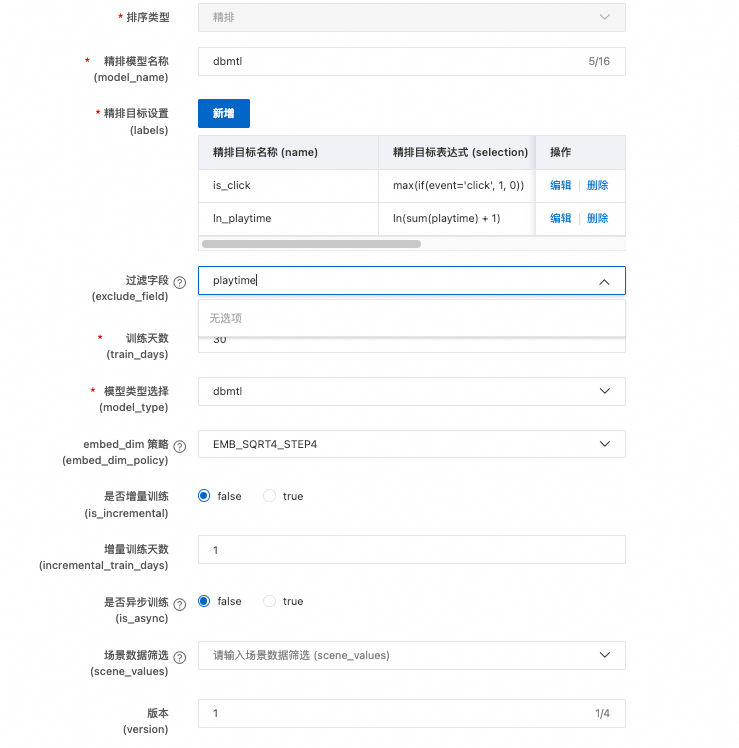
单击精排目标设置(labels)后的新增,新增如下两个label:
目标1
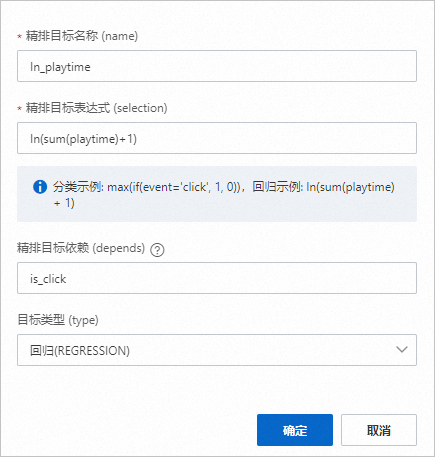
目标2(注意ln中的l是L的小写)
在生成脚本节点,单击生成部署脚本。
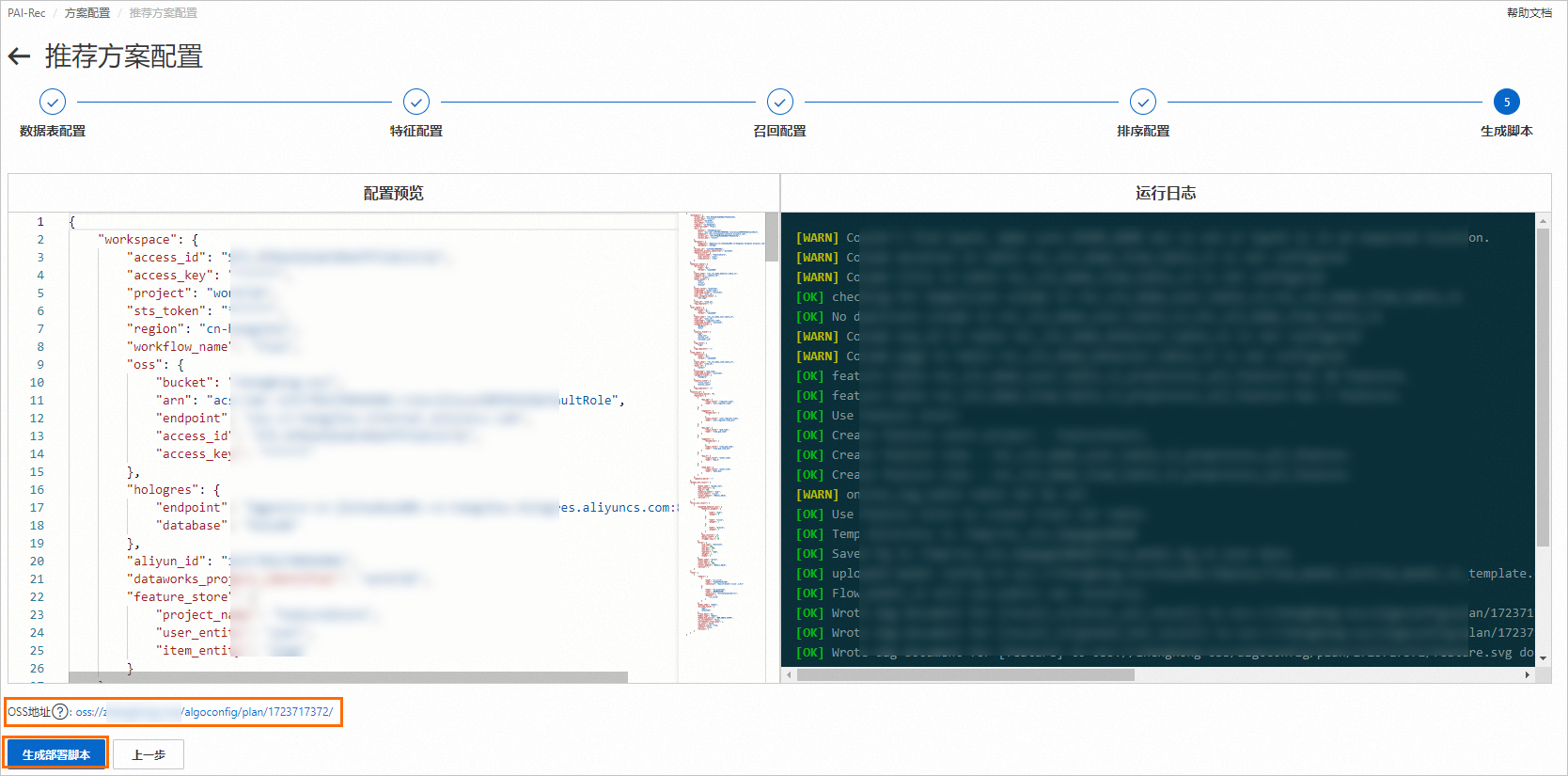 重要
重要脚本生成成功后,系统将生成一个如上图所示的OSS地址,该OSS路径存储了待部署的所有文件。您可以将该地址保存到本地,方便后续使用手动方式部署脚本。
脚本生成完成后,在弹窗中单击确定,跳转至推荐方案定制>部署记录页面。
如果生成失败,请查看运行日志,分析并解决具体报错问题,然后重新生成脚本。
6.部署推荐方案
脚本生成完成后,您可以通过以下两种方式,将该脚本部署至DataWorks。
方式一:通过推荐全链路深度定制开发平台部署
单击目标方案右侧的前往部署。

在部署预览页面的文件diff区域,选择要部署的文件。本方案为首次部署,单击全选,然后单击部署到DataWorks。
页面自动返回到部署记录页面,显示脚本部署运行中。

等待一段时间后,单击
 刷新列表,查看部署状态。
刷新列表,查看部署状态。如果部署失败,请单击操作列下的查看日志,分析并解决具体报错问题,然后重新生成脚本并部署。
当部署状态变为成功,代表脚本已成功部署。您可以前往该方案配置的DataWorks工作空间下的数据开发页面,查看部署好的代码,详情请参见数据开发:开发者。
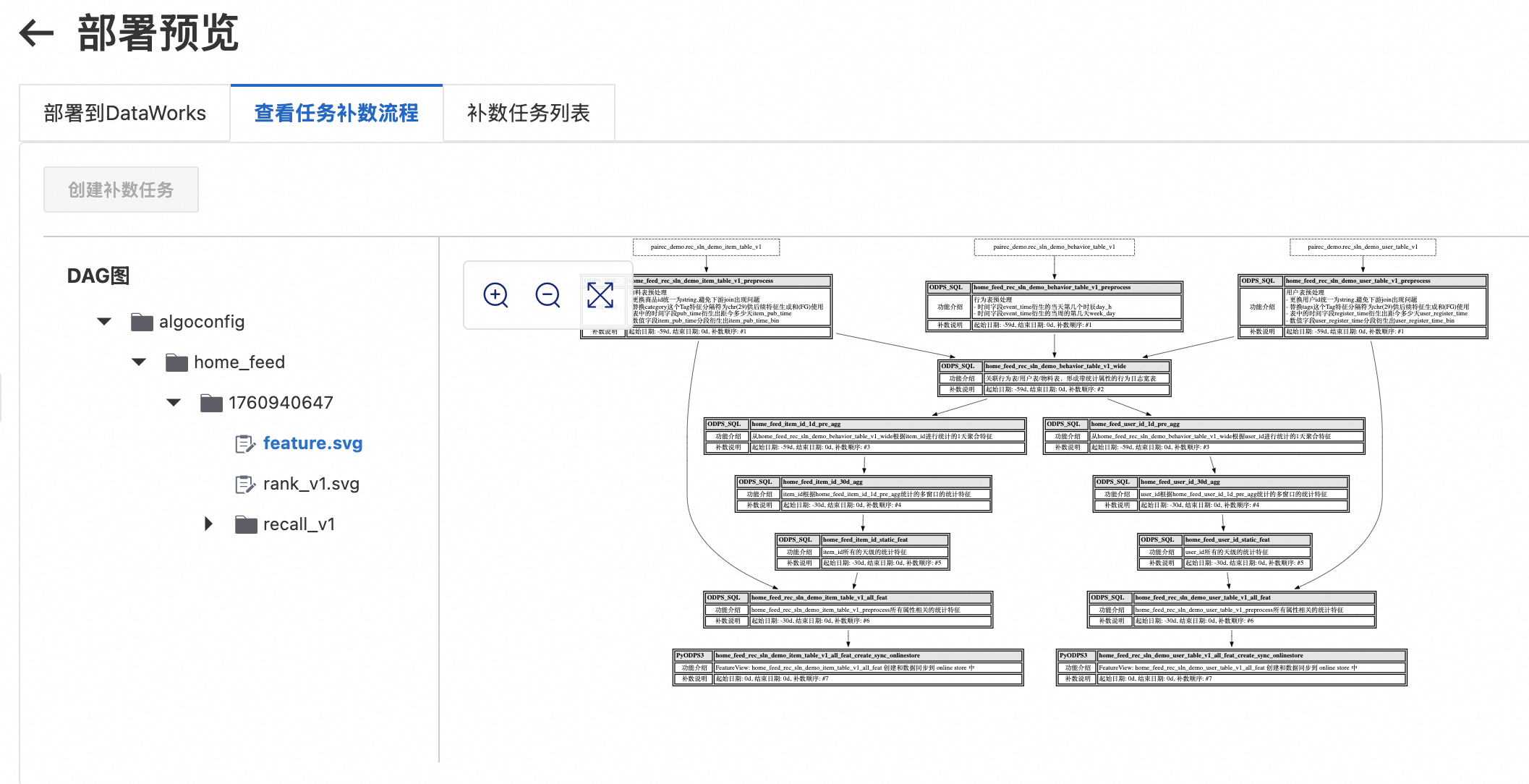
查看任务补数据流程。
在页面,单击已部署成功的推荐方案操作列下的详情。
在部署预览页面,单击查看任务补数据流程,了解补数据流程和相关说明,确保数据的完整性。
保证用户表、物品表、用户行为表分区都有最近n天(n的值可以是:训练时间窗加上最大特征时间窗的数值)的数据。如果是使用本文的demo数据,注意同步最新的数据分区。如果使用Python脚本产出数据,则在DataWorks运维中心补数产出最新的数据分区。
点击创建部署任务,在补数任务列表下面点击依次启动任务。保证任务都成功运行。某个任务如果运行失败,可以点击详情来查看日志信息,分析并解决相应的错误,然后重跑即可。重跑成功后需要点击页面左上角的续跑,直至任务全部成功。
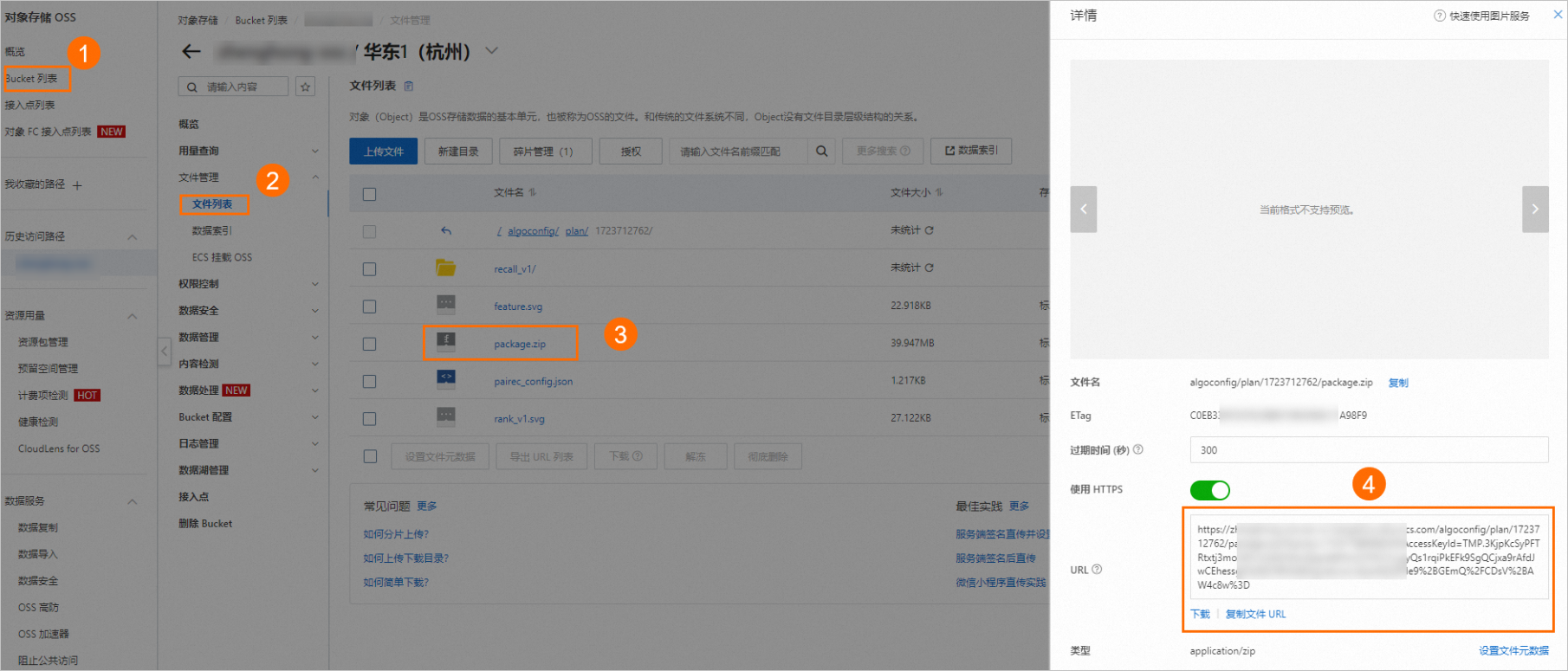
方式二:通过迁移助手部署
脚本生成成功后,您也可以前往DataWorks控制台,通过迁移助手功能手动部署脚本,其中关键参数说明如下,其他操作详情,请参见创建和查看DataWorks导入任务。
7.冻结节点
此文档是Demo数据,当一键补数已经完成,需要冻结运维中心里面的任务(步骤2.2中三个节点),防止任务每天调度执行。
进入DataWorks的运维中心,鼠标选择周期任务运维>周期任务,搜索刚才创建节点名称(如rec_sln_demo_user_table_v1),选中目标节点(工作空间.节点名),选择暂停(冻结)即可。