
为了帮助用户了解怎么配置实验,本文以召回实验,以及算法为例,介绍实验的创建及配置过程。
召回实验案例
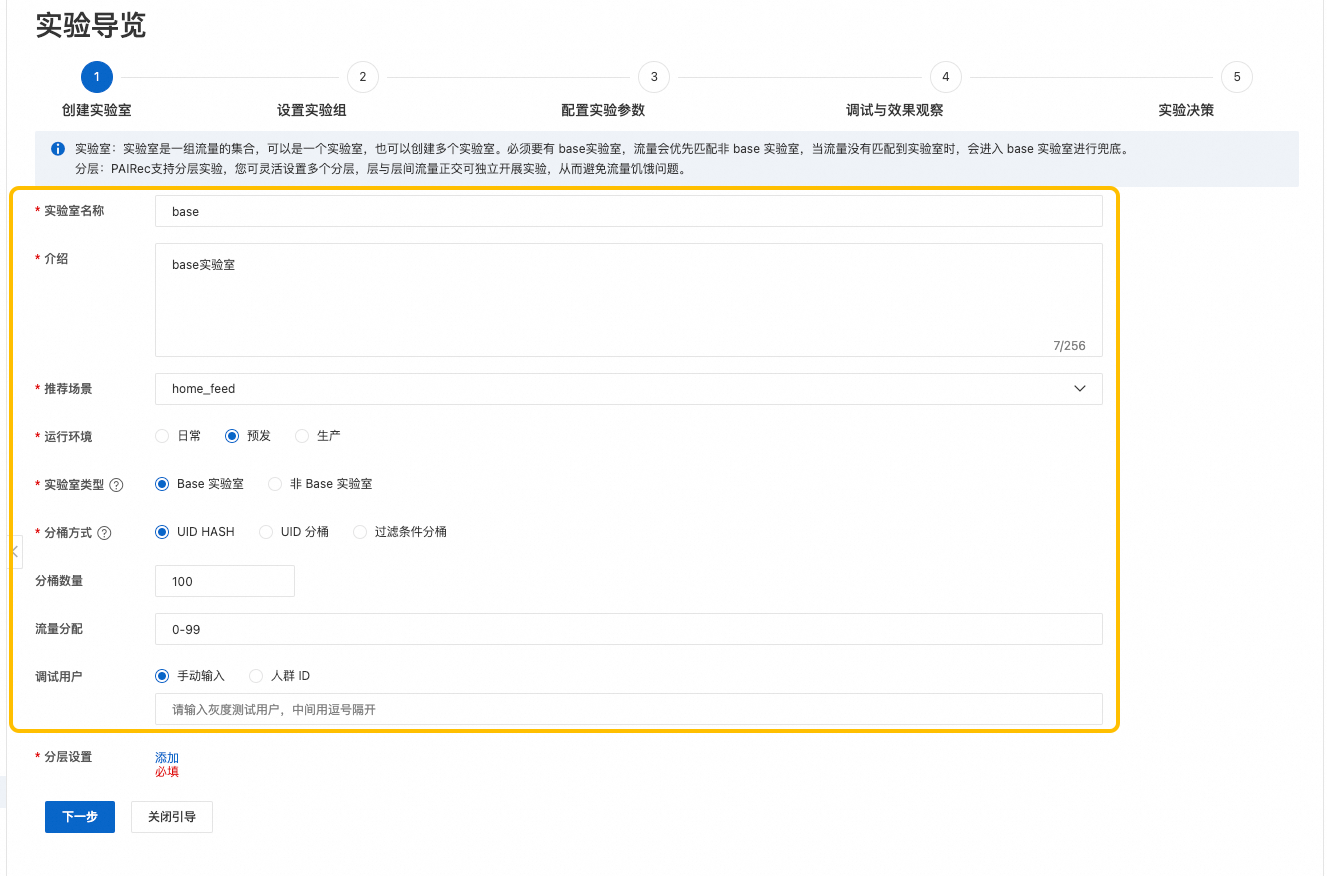
第一步:创建实验室
实验室是一组流量的集合,既可以只创建一个实验室,也可以创建多个实验室。当只有一个实验室的时候,这个实验室必须是Base实验室(作为兜底的实验室),并且Base实验室是必需的。流量会优先匹配非 Base 实验室,当推荐请求没有匹配到非Base实验室时会进入 Base实验室。因此,我们可以只创建一个兜底的实验室。
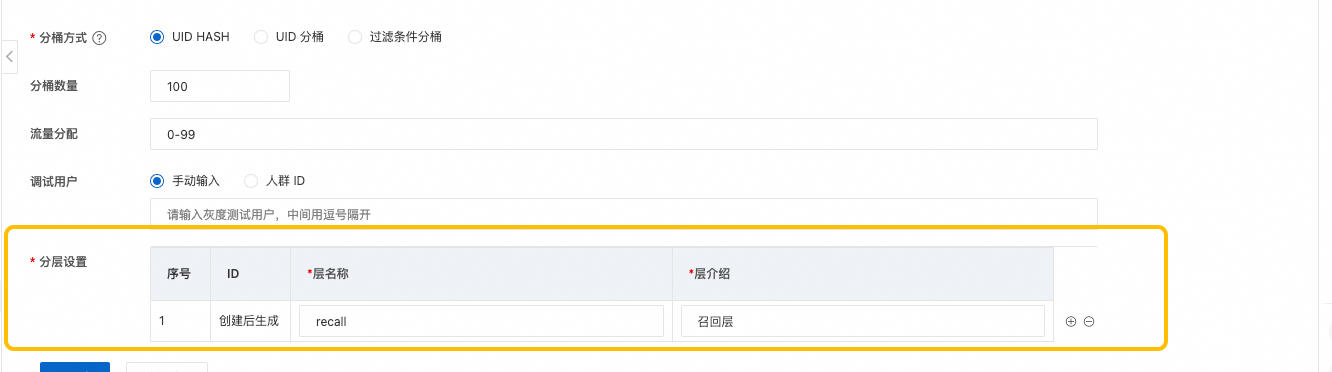
第二步:设置实验层
层和层之间的流量是正交的。我们可以把实验室看作一个容器,实验层可以看作是这种容器中的一层层网,每经过一层,会把流量重新打乱,进入下一层,所以这里我们可以认为,在较大的数据量下,每一层实验的效果是互不干扰的。
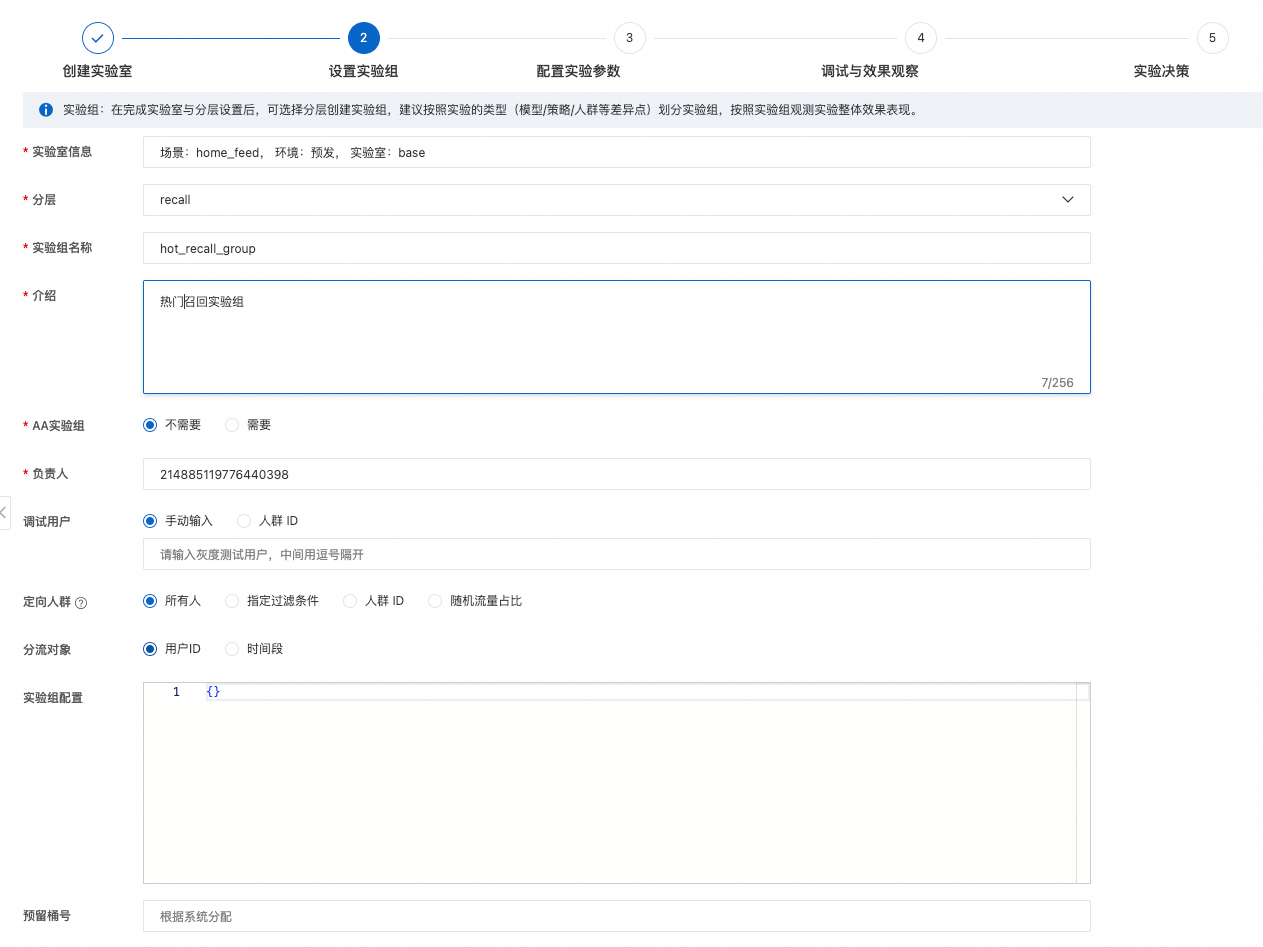
第三步:设置实验组
每个层上,可以有多个实验组,每个实验组可以划分层上的流量,这里我们只设置一个实验组作为举例。
第四步:设置实验
实验组下可以配置多个实验,多个实验之间互为对照,每一个实验要有一份不同的配置。
创建基准实验
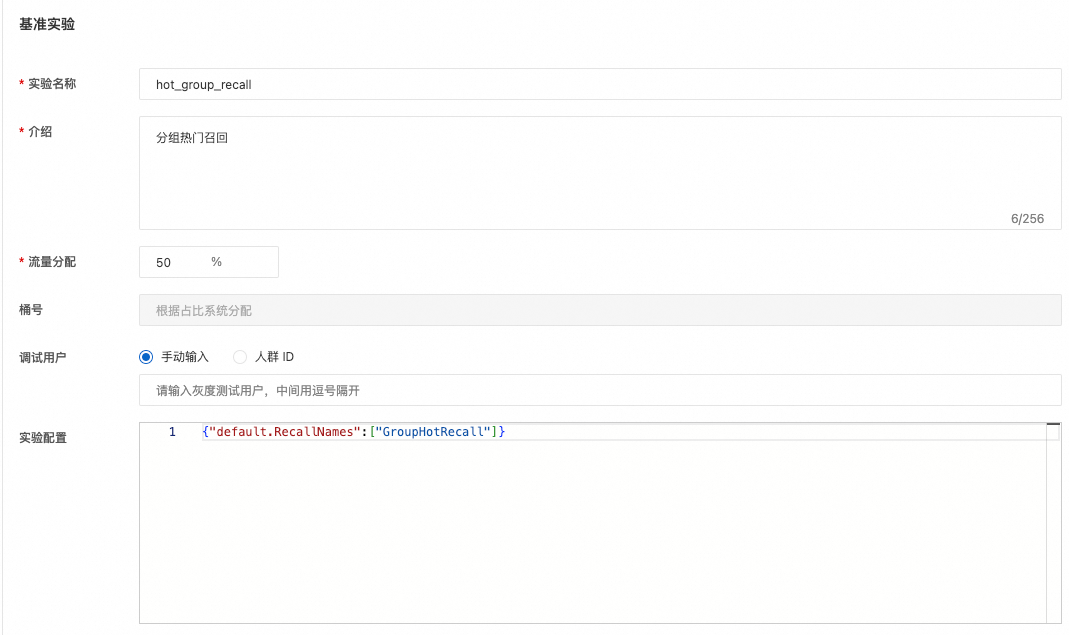
创建对比实验
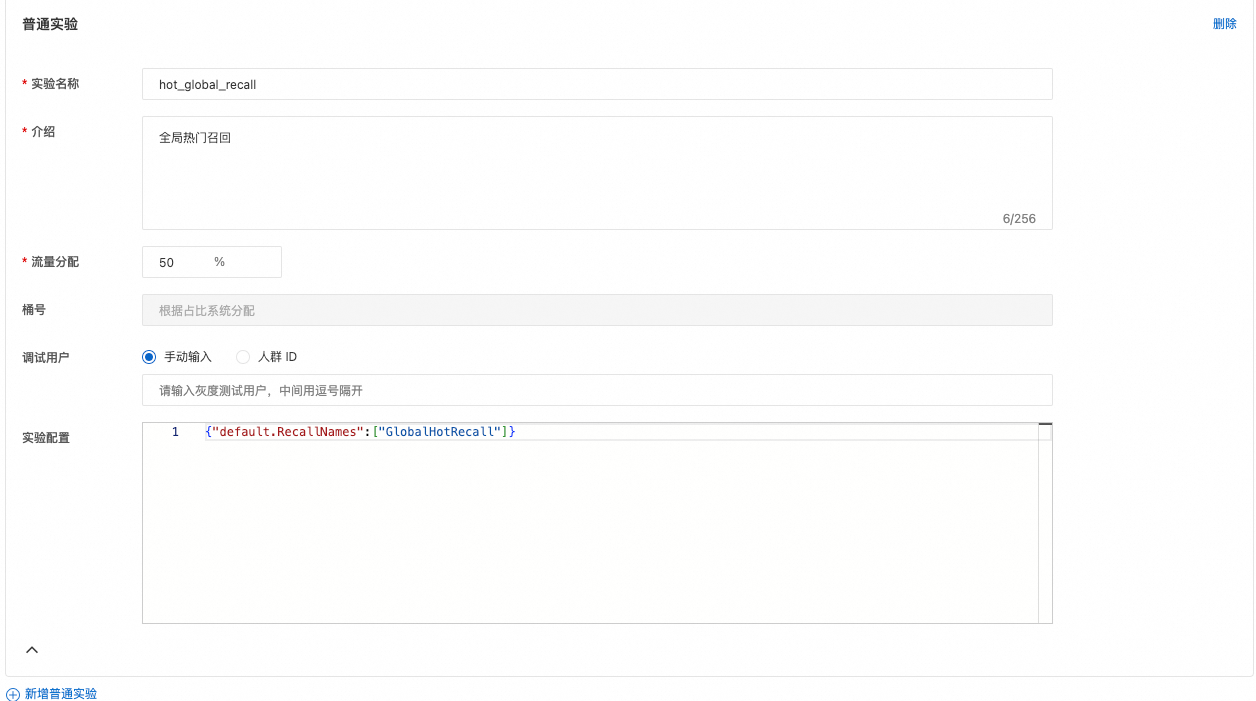
基准实验和对比实验配置中的 GroupHotRecall 和 GlobalHotRecall 需要预先在引擎配置的RecallConfs中定义好。
第五步:调试与观察
这一步,我们可以把实验室、实验组、实验都上线,然后对推荐引擎打请求,观察引擎返回结果中的exp_id是否有值。
如果exp_id的值一直为空,则需要检查实验室、实验组、实验是否是已上线状态,在实验导览页面,已上线的状态是绿色,未上线是灰色。
如果exp_id的值为ER1_L1#EG1#E1,则表示本次请求,经过了1号实验,会采用1号实验的配置,后面再配置相关指标,我们就可以观察实验的效果啦。
算法配置实验
算法配置的相关实验和召回类似,为了防止实验的相互作用,我们可以创建一个算法层,如 rank。其他实验组、实验的配置基本相同,我们只需要更改实验的配置即可。
如基准实验的配置可以为:
{
"rankconf": {
"RankAlgoList": [
"dbmtl_v1"
],
"RankScore": "${dbmtl_v1_prob}",
"BatchCount":100,
"Processor": "EasyRec"
}
}对比实验的配置可以为
{
"rankconf": {
"RankAlgoList": [
"dbmtl_v2"
],
"RankScore": "${dbmtl_v2_prob}",
"BatchCount":100,
"Processor": "EasyRec"
}
}dbmtl_v1 和 dbmtl_v2 为不同的打分模型,需要预先在引擎配置的AlgoConfs中定义好。