
数据注册
数据注册需要您已经开通MaxCompute、绑定项目,再注册MaxCompute表,该注册表是效果统计的中间表(实验报表来源表),即以user_id、exp_id、维度指标作为联合主键统计的数据表。表示某个用户在某个实验下的曝光、点击等指标,也可以增加国家维度作为“user_id+国家+exp_id”下的中间统计表。后面配置单维指标和衍生指标都依赖这个中间表。在具体讲实验报表来源表之前,我们回顾一下实验的整体架构,如下图:
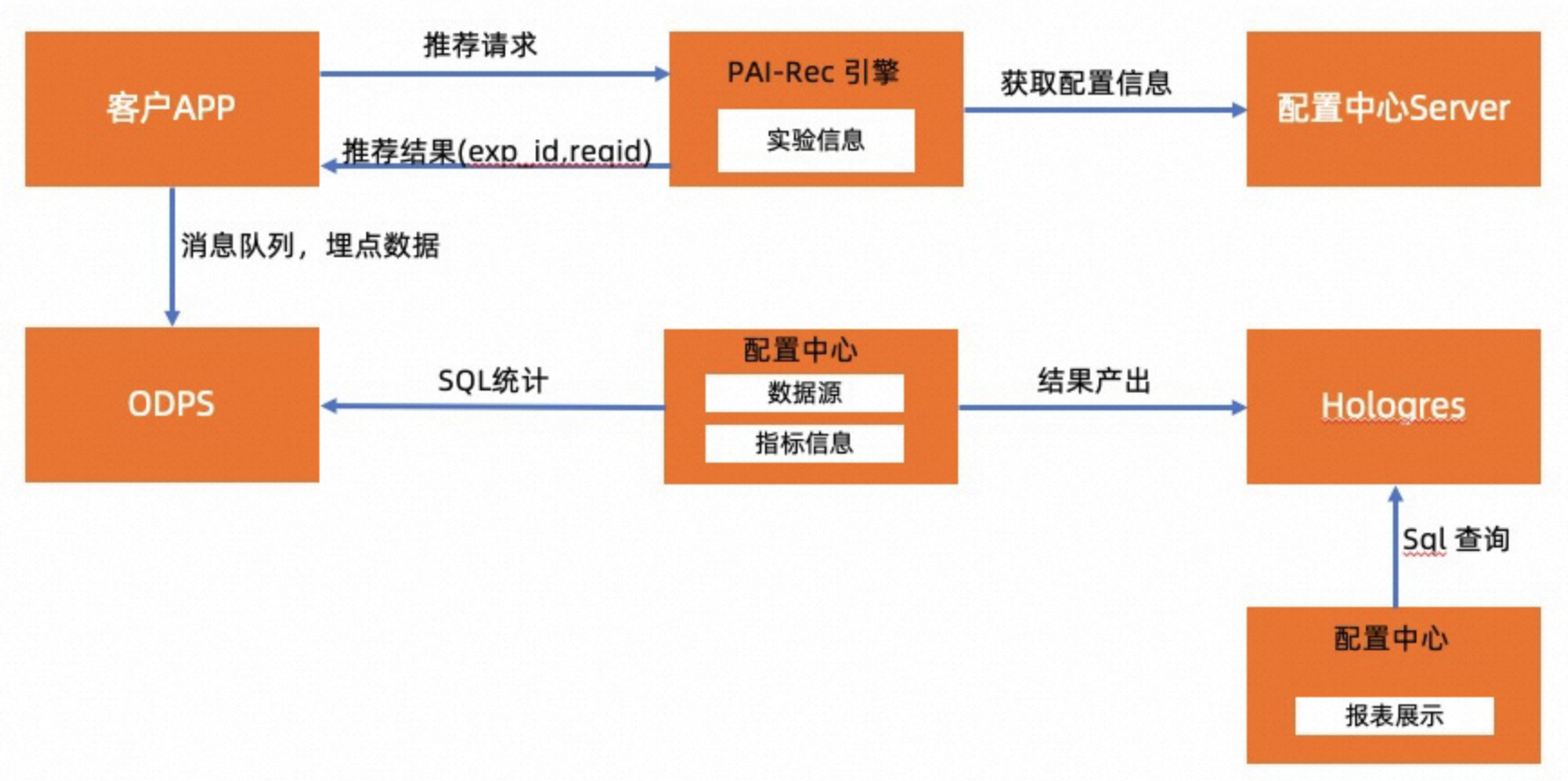
PAI-Rec 引擎是我们的推荐服务,里面集成了配置中心的 SDK,实验信息从配置中心获取到。在推荐服务返回接口中,会记录实验id(exp_id), 以及请求的标识(reqid)等。
当用户在App上操作产生行为时,行为日志会通过App上的前端埋点回流到 ODPS(即MaxCompute) 中。在“SQL统计”环节,产出“实验报表来源表”。在配置中心配置了若干个指标后,我们会动态组装 SQL, 然后对“实验报表来源表”进行计算、统计,并把结果存到 Hologres 中。在实验报表页面,可以查询到指标数据。
一、离线实验报表
生成离线“实验报表来源表”的代码
CREATE TABLE IF NOT EXISTS experiment_report (
user_id STRING COMMENT '用户ID',
exp_id STRING COMMENT '实验ID',
exposure_count BIGINT COMMENT '曝光次数',
click_count BIGINT COMMENT '点击次数',
like_comment_collect_count BIGINT COMMENT '点赞次数'
)
PARTITIONED by (dt STRING COMMENT '日期')
STORED AS ALIORC;
INSERT OVERWRITE TABLE experiment_report PARTITION (dt = '${bdp.system.bizdate}')
SELECT user_id
,exp_id
,SUM(IF(event == 'expose',1,0))
,SUM(IF(event == 'click',1,0))
,SUM(IF(event IN ('like','comment','collect'),1,0))
FROM rec_sln_demo_behavior_table_v1
WHERE ds = '${bdp.system.bizdate}'
GROUP BY user_id
,exp_id离线“实验报表来源表”的格式
字段名称 | 字段含义 | 是否必填 | 说明 |
user_id | 用户ID | 是 | 用户标识,可以是用户的 uid, 也可以是设备 devcie_id, imei 等 |
exp_id | 实验ID | 是 | ab 服务返回的实验id, 通过埋点回流。如果是用户的自己的推荐服务,设置自定义的标识即可。exp_id:ER1_L1#EG1#E1_L2#EG2#E2 |
维度字段 | 用于更细粒度的统计效果报表 | 否 | 可以根据此维度字段统计、展示对应的指标。 例如设置一个省(province)字段,按照不同的省来统计,分析产品在不同省的效果。 最多设置两个字段如province和city,当设置第三个字段的时候组合太多,导致计算非常慢。 常见的维度字段还可以是召回ID(recall_id),即分析不同的召回源的效果。需要先设置PAI-Rec引擎的后端日志,参考其他配置中的pairec_debug_log。 |
计算字段 | 计算字段可以是多个, 如曝光次数:show_count; 点击次数:click_count | 是 | 计算字段是用户填写的数值类型,比如曝光数,点击数,观看时长等 |
dt | 日期分区 | 是 | 格式:yyyyMMdd |
hh | 小时分区 | 否 | 24小时制, 00 ~ 23 |
mm | 分钟分区 | 否 | 00 ~ 59 |
来源表可以离线按天产出,也可以小时级报表产出(例如DataWorks中每小时调度一次,统计前一个小时的曝光、点击、购买日志数据),主要看客户的业务需求。如果是离线产出, user_id, exp_id, dt 是必须的。 如果是小时级报表,user_id,exp_id,dt,hh 是必须的,mm 分区不是必须的。
指标分为离线和实时(对应小时级报表)。如果是实时产出的数据源,离线、实时指标可以共用一个数据源。如果是离线产出的数据源,只能创建离线指标,无法创建实时指标。
上面的维度字段也不是必需的,加上维度字段可以对指标进行维度分析。比如常见的维度字段有性别、操作系统(IOS, 安卓)等。这样报表的数据可以分 男女,ios 和 安卓进行查看。
二、实时实验报表来源表
生成“实验报表来源表”的代码
CREATE TABLE IF NOT EXISTS experiment_report_real (
user_id STRING COMMENT '用户ID',
exp_id STRING COMMENT '实验ID',
exposure_count BIGINT COMMENT '曝光次数',
click_count BIGINT COMMENT '点击次数',
like_comment_collect_count BIGINT COMMENT '点赞次数'
)
PARTITIONED by (
dt string
,hh string
)
STORED AS ALIORC;
INSERT OVERWRITE TABLE experiment_report_real PARTITION (dt = '${bdp.system.bizdate}',hh = '${hour}')
SELECT user_id
,exp_id
,SUM(IF(event == 'expose',1,0))
,SUM(IF(event == 'click',1,0))
,SUM(IF(event IN ('like','comment','collect'),1,0))
FROM rec_sln_demo_behavior_table_v1
WHERE ds = '${bdp.system.bizdate}'
AND hh = hour(now()) -1
GROUP BY user_id
,exp_id;实时“实验报表来源表”的格式
字段名称 | 字段含义 | 是否必填 | 说明 |
user_id | 用户id | 是 | 用户标识,可以是用户的 uid, 也可以是设备 devcie_id, imei 等 |
exp_id | 实验id | 是 | ab 服务返回的实验id, 通过埋点回流。如果是用户的自己的推荐服务,设置自定义的标识即可。exp_id:ER1_L1#EG1#E1_L2#EG2#E2 |
维度字段 | 比如操作系统 os | 否 | 可以根据此维度字段过滤对应的指标 |
计算字段 | 计算字段可以是多个, 如曝光:show_count;点击:click_count | 是 | 计算字段是用户填写的数值类型,比如曝光数,点击数,观看时长等 |
dt | 日期分区 | 是 | 格式:yyyyMMdd |
hh | 小时分区 | 是 | 24小时制, 00 ~ 23 |
mm | 分钟分区 | 否 | 00 ~ 59 |
结果表字段基本都是固定的,只有维度字段是可变的。维度字段的定义与来源表中的定义保持一致即可。
离线指标和实时指标不能混用一个结果表。离线指标结果表只需要有 dt 日期字段即可。实时指标至少要有 hh 小时字段 。
有了“实验报表来源表”之后,打开控制台“指标管理-数据注册”页面,即可选择新增MaxCompute数据表。
建议用户直接使用系统默认的Hologres表(不占用用户资源)用于指标计算结果的回写,系统会自动为您建表、存储相关指标数据。当然客户也可以使用自己的Hologres实例表,而不用默认的Hologres表。
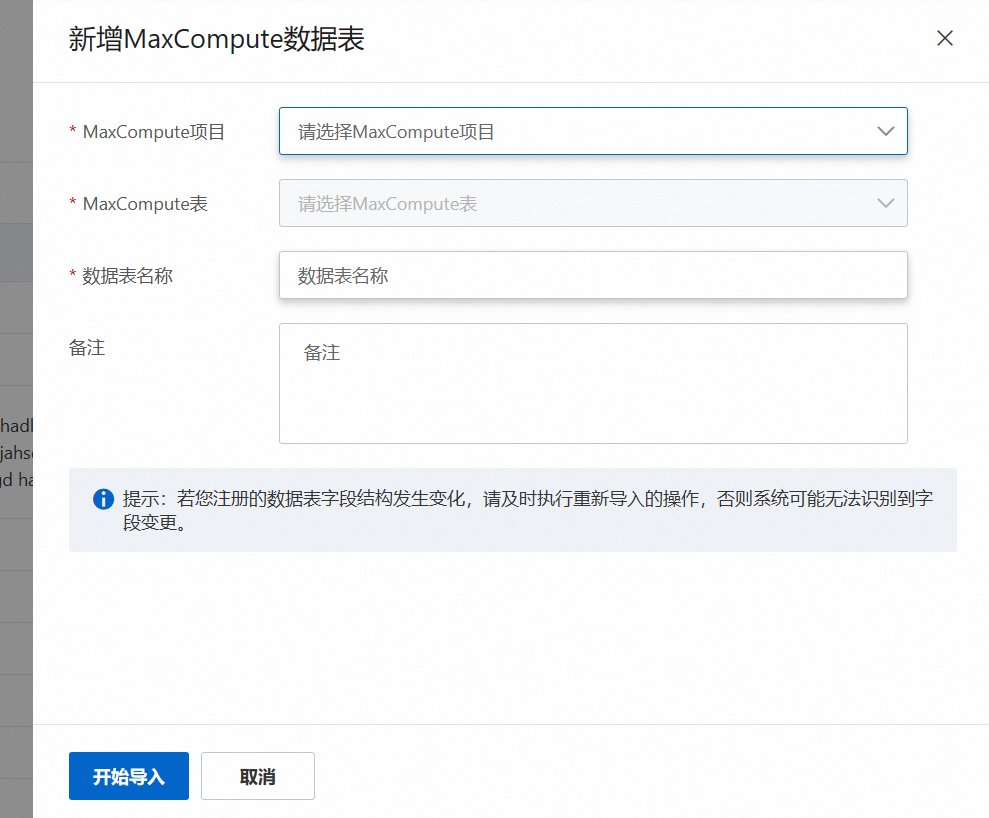
三、新增注册MaxCompute表
单击新增数据表,需要选择绑定好的MaxCompute项目空间,并选择要新增的MaxCompute当中的数据表,并自定义一个名称,点击开始导入即可导入表中数据。
若您注册的数据表字段结构发生变化,请及时执行重新导入的操作,否则系统可能无法识别到字段变更。
字段配置
注册好的数据表会自动出现在列表中,您可以点击查看字段按钮查看数据表中的字段,对字段和相关信息进行核对或编辑。其中user_id 、exp_id 、dt字段是必须要有的字段,表示某个用户(user_id)在某天(dt)在一组实验(exp_id)中的曝光、点击、点赞等行为的次数总和。自定义指标就是基于这个表来定义和计算。

维度字段
在上面的表中可以增加1到2个维度字段,例如设置一个city字段作为维度,则在实验报表中可以查看不同city维度下的实验对比效果。如果设置city和gender两个维度字段,则是这两个字段组合的实验对比结果。