
在PAI-Rec中所有的服务和实验都需要关联一个推荐的场景,例如“首页瀑布流推荐”,“购物车猜你喜欢”,“详情页相关推荐”等等。下面我们介绍创建的细节。
推荐场景
我们先创建一个推荐场景(建议场景的名称可以说明推荐场景的页面位置),下面“首页瀑布流推荐”中的“首页”说明了场景的位置,“瀑布流”说明场景是可以不断下滑浏览的。
流量编码是为不走PAI-Rec系统的推荐请求预留的。这种情况非常常见:当用户自己已有推荐系统的时候,在刚开始会把这个场景从切10%到20%的推荐流量给PAI-Rec系统。当PAI-Rec的推荐效果达到预期之后再逐渐增加流量。HomePageRec的默认流量是走PAI-Rec的,而selfhold表示用户自持的流量,thirdparty是第三方流量。
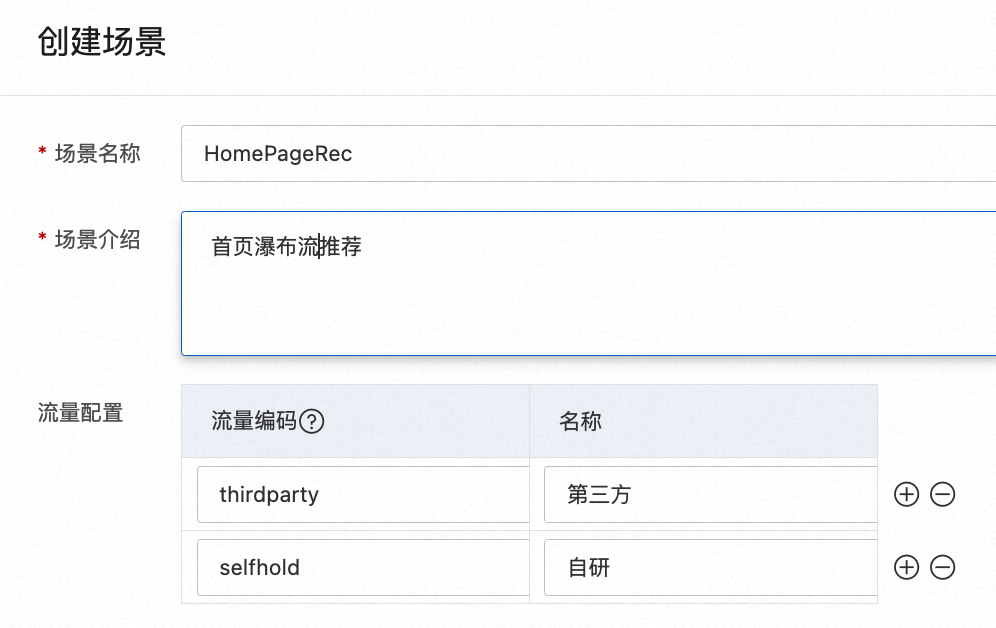
如下图中有6个用户,根据系统的分桶逻辑(由客户实现),两个用户通过selfhold(客户自持流量)得到推荐结果;两个用户通过PAI-Rec得到推荐结果;两个用户通过thirdparty(第三方)得到推荐结果;
实验室和实验层
当用户的推荐请求路由到PAI-Rec的内部之后,我们对这些推荐请求做了进一步的流量分桶。我们根据业界常用a/b test方案设计了实验室、实验层、实验组、实验,实验室包含了实验层,实验层包含实验组,实验组中包含了实验。
首先,实验室是一组流量的集合,既可以只创建一个实验室,也可以创建多个实验室。当只有一个实验室的时候,这个实验室必须是Base实验室(作为兜底的实验室),并且Base实验室是必须的。流量会优先匹配非 Base 实验室,当推荐请求没有匹配到非base实验室时会进入 Base实验室。因此,我们可以只创建一个兜底的实验室。
我们可以创建一个召回和排序逻辑都相对简单的实验室作为兜底实验室,而通常用的复杂的召回和排序逻辑放在非Base实验室。这样,当流量突然太大时,我们可以把部分流量切换到base实验室,以防止整个推荐系统被拖垮。
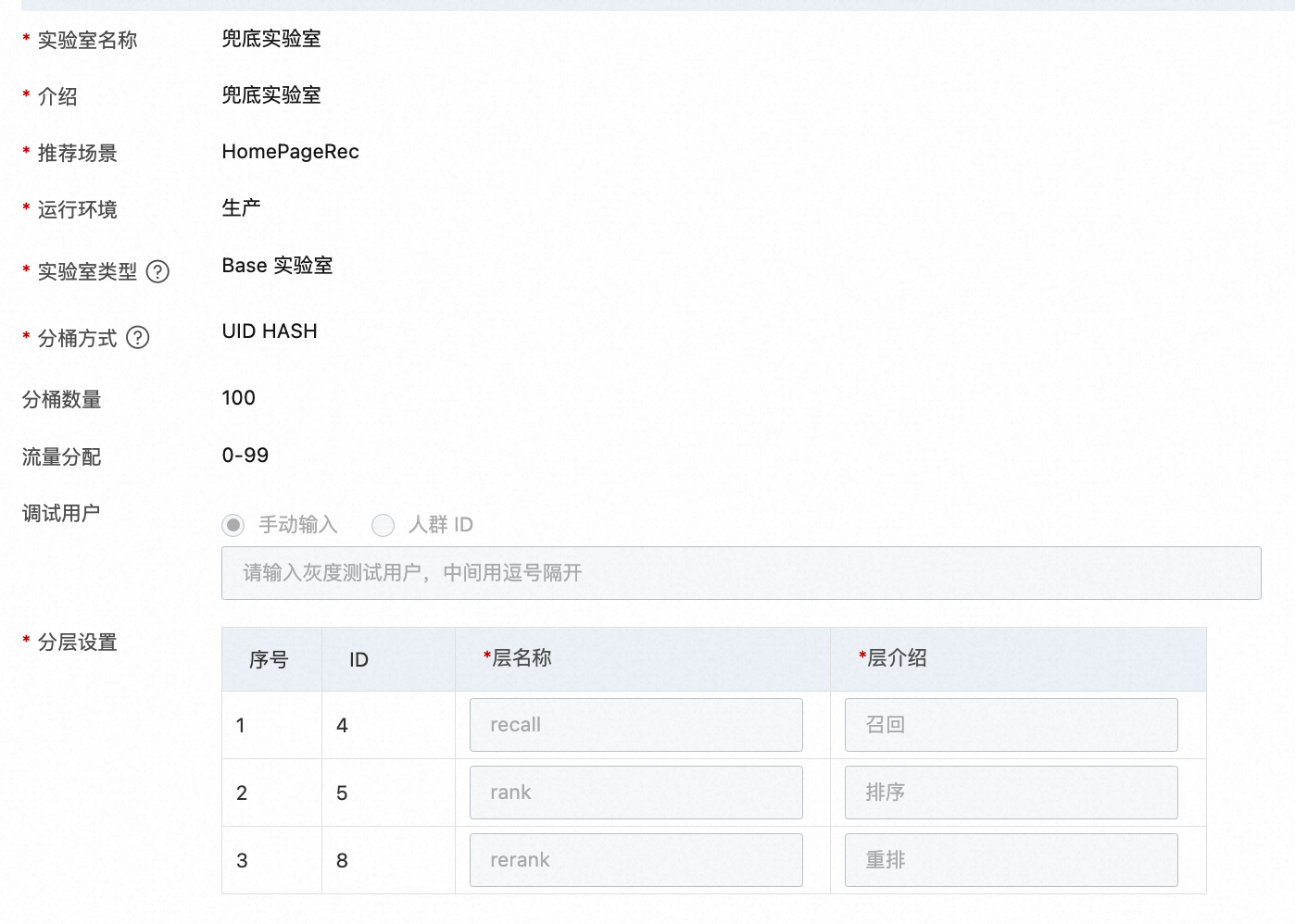
上面是Base实验室的案例,对上图表格中的名称解释如下:
实验室名称:自定义实验室名称
介绍:实验室的详细描述
实验室类型:
base 实验室:必须有一个base实验室,可以没有非base实验室。
非 base 实验室:优先匹配非 base 实验室。当base实验室的模型比较简单,而非base实验室的模型比较复杂的时候,可以设置两个实验室。base实验室也可以完全用一个热门随机兜底逻辑来实现。
运行环境:对应引擎的运行环境,日常(daily), 预发(prepub),生产(product)
实验室桶类型:
UID分桶:根据 uid 的末尾数字分桶
UID HASH:根据 uid 的 hash 值分桶
过滤条件分桶:kv 表达式分桶,如 gender=man
分桶数量:此实验室分得的桶数,总数为100
流量分配:分得的桶的编号,可以设置为0-99
分层:实验层一般设置recall(召回)、filter(过滤)、coarse_rank(粗排)、rank(排序)等
调试用户:调试用户可以不经过匹配,直接进入此实验室
手动输入:可以输入多个,以逗号分隔
人群 ID:一组 uid 的集合,需要提前在【人群管理】中创建
实验组和实验室
在每一层可以设置多个实验组,每一个组里面可以设置多个实验。为什么要设置多个实验组呢?当有多个算法工程师做召回或者排序实验的时候,我们可以通过划分实验组,可以让他们相互自己不干涉。
每个实验组中,一般都会有多个实验。例如下面我们配置了swing、etrec两个实验,而dssm还在测试中,因此流量占比设置为“0%”,但是处于上线状态。DSSM处于上线状态是方便我们通过白名单来观察推荐效果。
