
本文介绍PAI-Rec系统中流量调控模块的使用流程。
背景介绍
1.什么是流量调控
流量调控业务就是通过算法/策略/系统的设计和优化,构建考虑平台意志和长期价值的流量分发系统。流量调控类似于国家的宏观经济调控,是一只“看得见的手”,是实现平台短期与长期收益平衡、促进平台生态健康发展的重要手段!

2.为什么要做流量调控
目的1:促进发布,增大内容池。 新内容获得的曝光越多,作者创作积极性越高。反映在发布渗透率、人均发布量。
目的2:挖掘优质内容。做探索,让每篇新内容都能获得足够曝光。 挖掘的能力反映在高热内容占比。
目的3:辅助商业化。以流量调控技术为手段,达到低成本撬动商家优质资源,实现平台、商家、用户三方共赢。广告变现
3.流量调控解决方案优势
扶持效果好:“流量调控”是基于PAI-Rec推荐系统架构而开发的流量干预功能,在不扰乱推荐系统整体推荐逻辑的基础上对所选物品池进行精准流量干预。
效果可量化:与传统的“加权”方式相比,“流量调控”功能以物品池的曝光次数、曝光次数占比等可量化的指标为调控的目标,更容易实现定量扶持;
易于管理:“流量调控”以任务为功能单元实现业务诉求,针对不同种类的流量干预需求可以建立不同的“流量调控”任务,这种方式便于灵活管理,您可以随时新建或结束一个任务。
操作简单:您只需要新建并配置任务目标等信息,系统将根据您的配置自动干预流量的分发,不需要您持续观察和监测;
创建流量调控任务
介绍如何创建流量调控任务,相关术语解释
准备工作
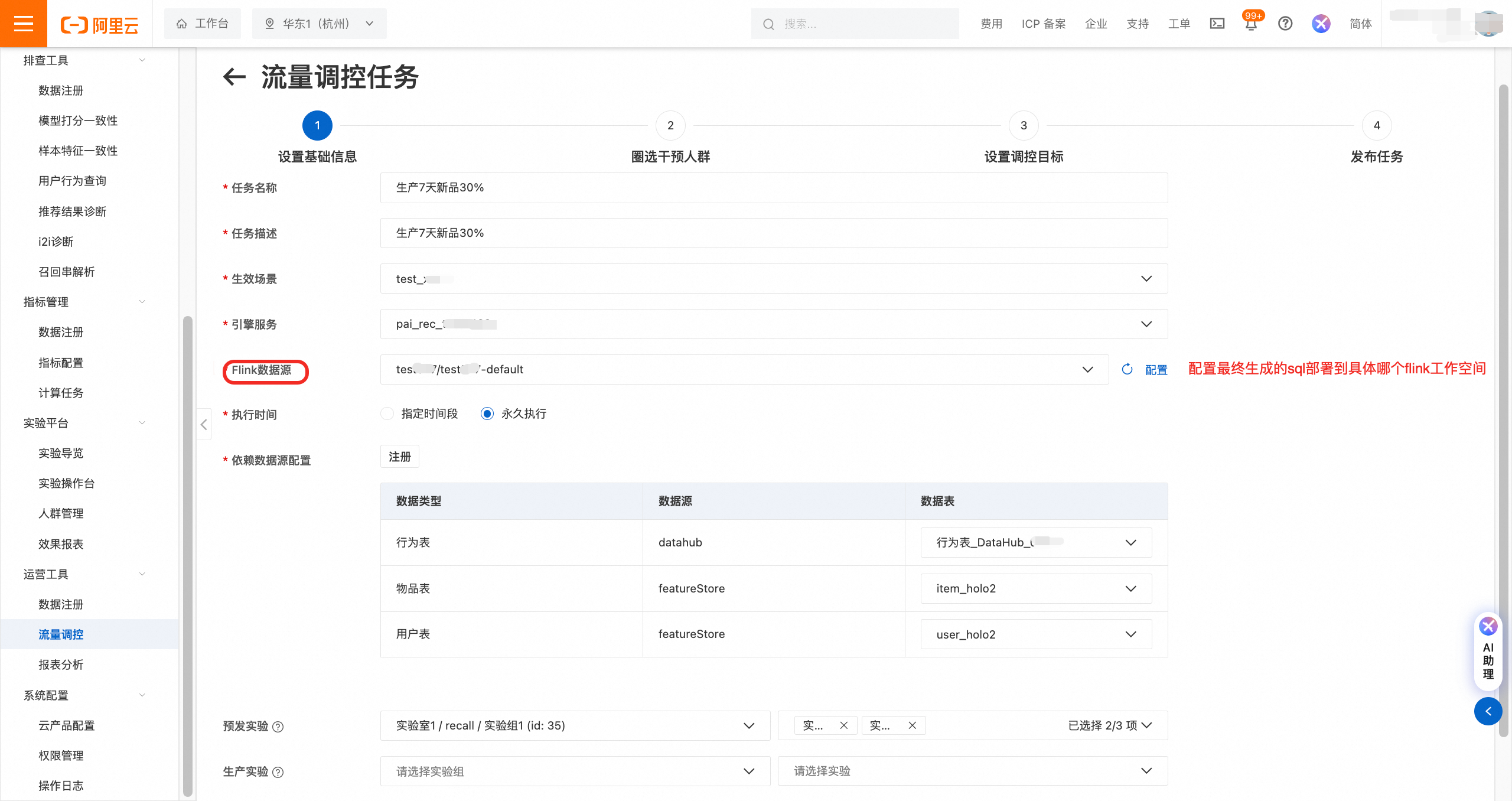
创建的流量调控任务会生成实时统计被调控目标数量的flink sql,该sql在任务发布时会部署到flink平台。所以这里需要区分下您创建的Flink资源:

OSS Bucket类型:无需额外操作
全托管存储:需要手动上传jar包。
当您的Flink资源为全托管存储类型时,需要做以下准备工作(该配置做一次即可):
下载Jar包基础Jar包,若使用了FeatureStore则还需要下载FeatureStore Jar 包
进入对应工作空间的flink控制台,点击 ETL => 函数 => 点击+号,这里注册的udf的JAR就是我们下载的基础Jar包,这里规定UDF名称为traffic-ctrl,点击确定
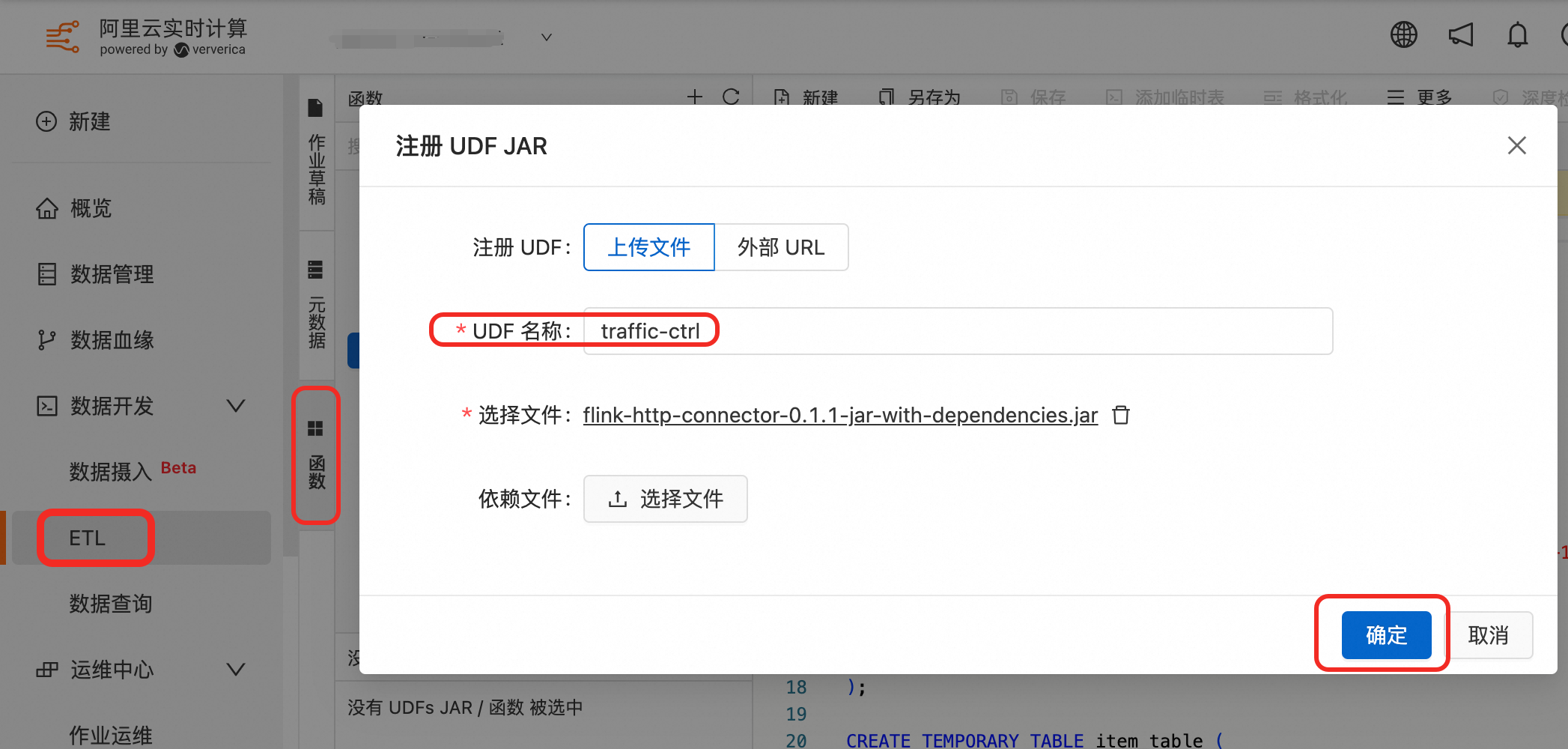 这里需要改下函数的名称,ConditionMatch改为is_expr_match,如图配置=>点击创建函数
这里需要改下函数的名称,ConditionMatch改为is_expr_match,如图配置=>点击创建函数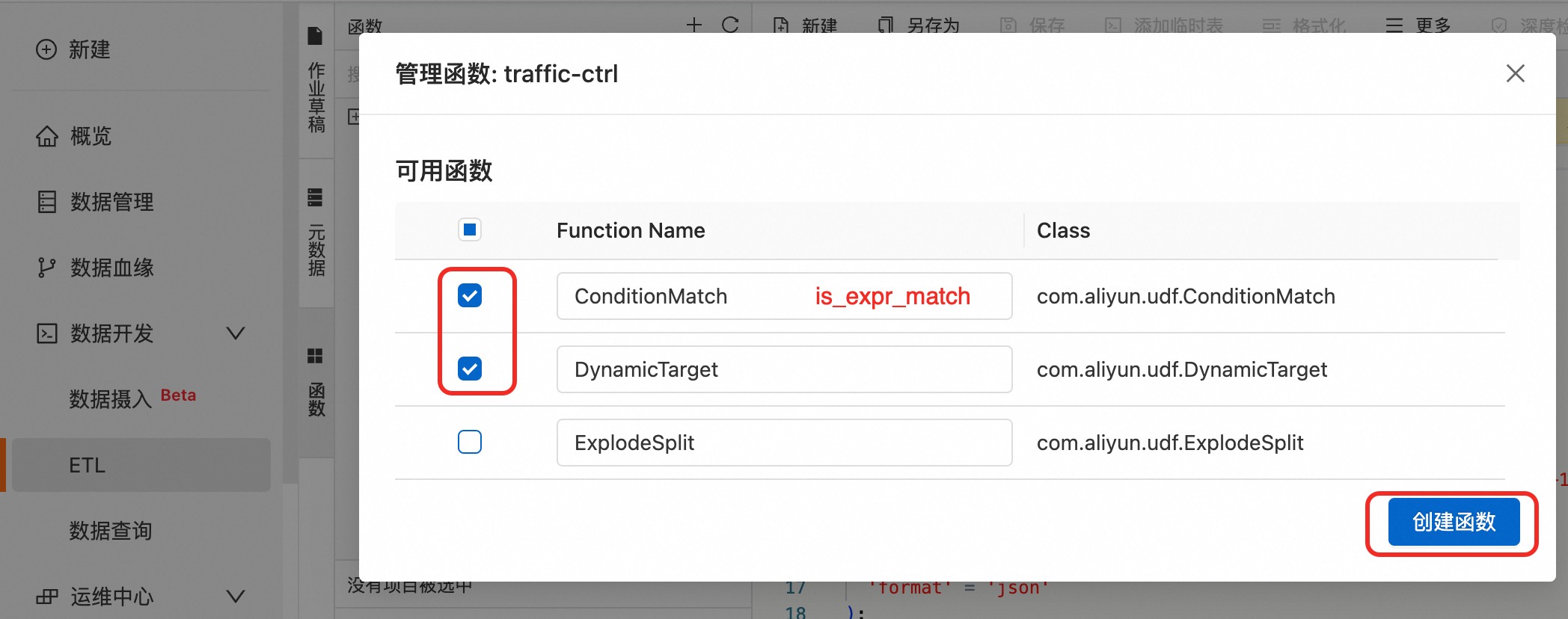
业务所需,需要上传自定义连接器。点击连接器 => 创建自定义连接器,如图点击下一步
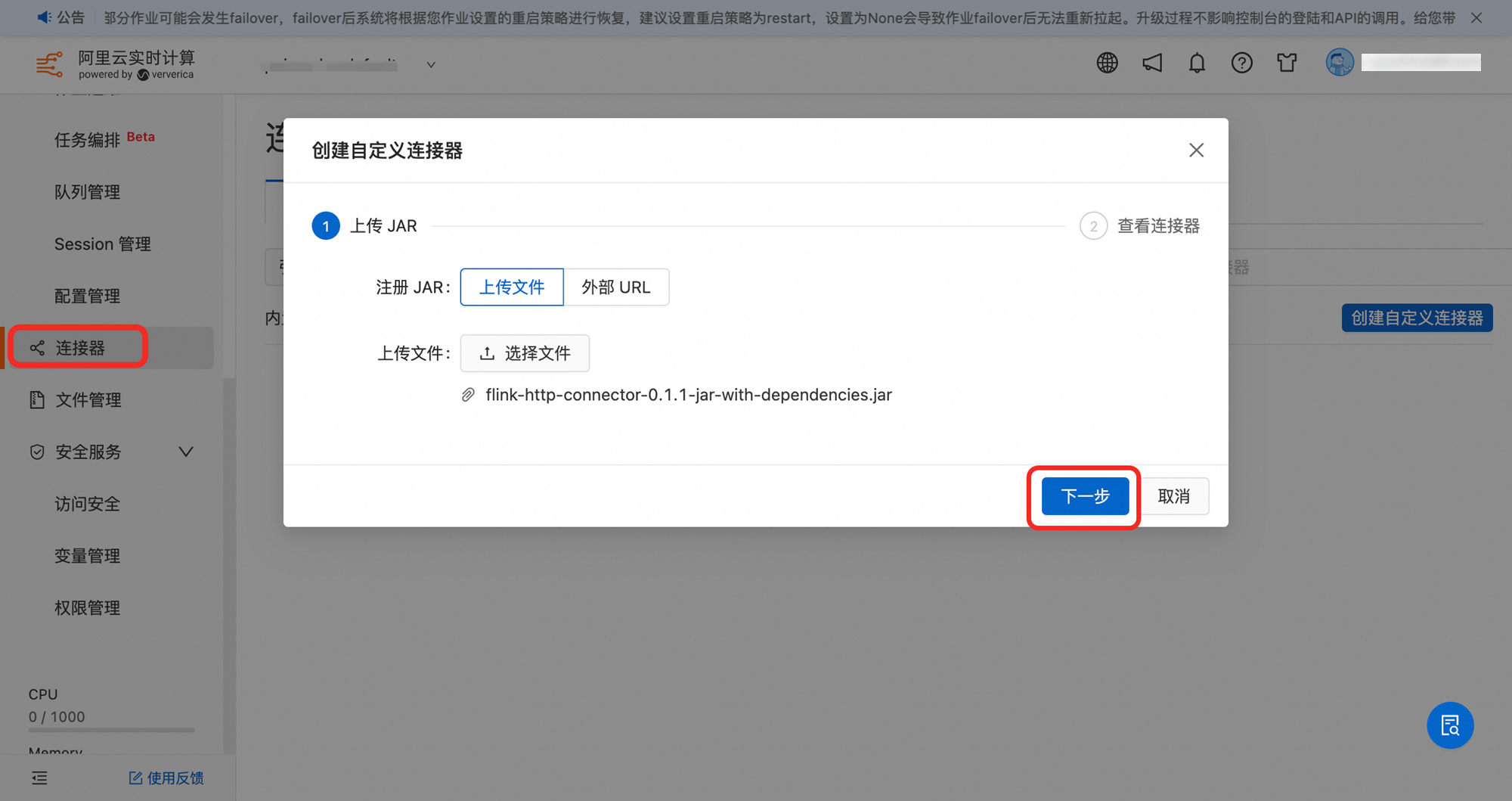 这里注册的Connector不止一个,需要全部注册。
这里注册的Connector不止一个,需要全部注册。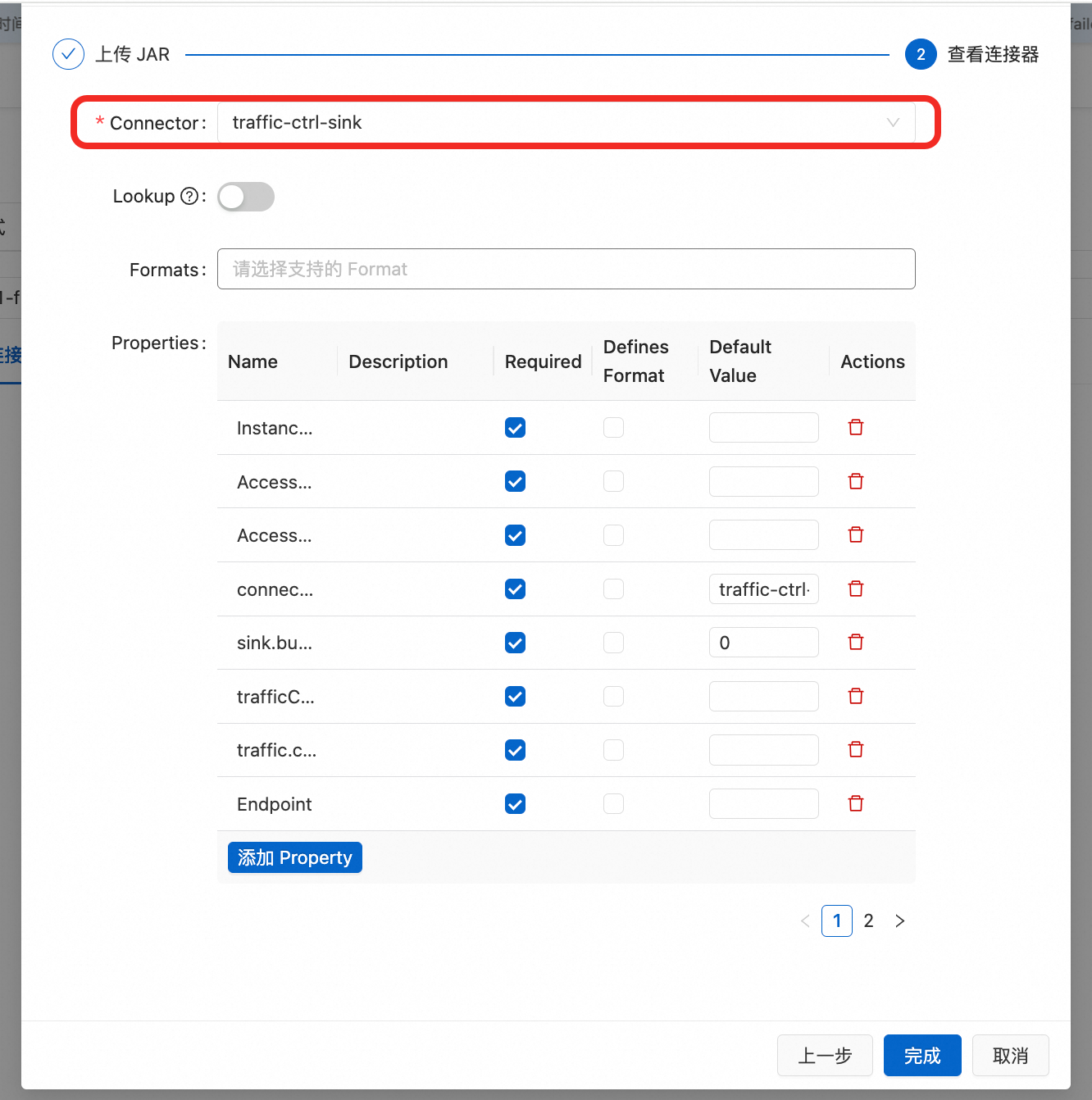 示例的这五个需要都注册:
示例的这五个需要都注册: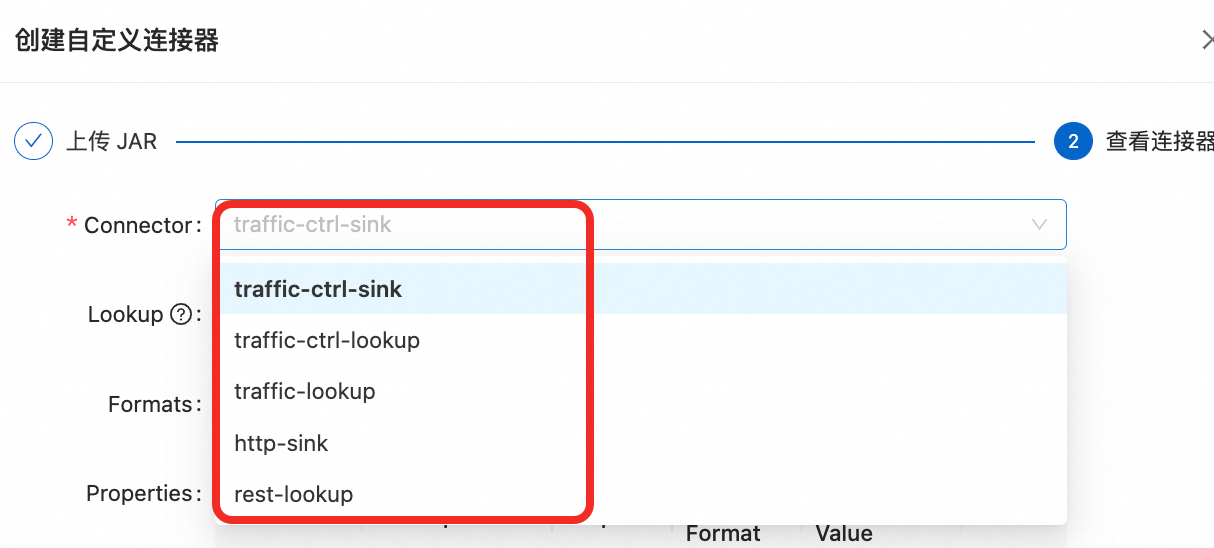 如果涉及到FeatureStore的部分,就需要上传前面提到的FeatureStore Jar 包,勾选上Lookup开关。详细可以参考下FeatureStore的设置Flink Connector文档。
如果涉及到FeatureStore的部分,就需要上传前面提到的FeatureStore Jar 包,勾选上Lookup开关。详细可以参考下FeatureStore的设置Flink Connector文档。
1. 新建流量调控任务
1.1 设置基础信息
1.2 圈选干预人群
干预人群是流量调控任务的作用范围,如不选择则默认对整个场景的流量都做干涉。

行为统计条件配置用户实时行为的过滤条件,只对符合条件的流量进行统计。

圈人条件与行为统计条件都可以配置多个子项,系统保证各个子项的条件都必须满足。
如果需要配置更加复杂的条件,比如“或”关系的条件,可以输入自定义表达式。
自定义表达式支持多种运算符,包含数学运算符、逻辑运算符、比较运算符及集合运算符等。
数学运算符包括加(
+)、减(-)、乘(*)、除(/)和取模(%)。逻辑运算符包括逻辑与(
&&)、逻辑或(||)和逻辑非(!)。比较运算符有相等(
==)、不等(!=)、小于(<)、小于等于(<=)、大于(>)和大于等于(>=)。操作集合的运算符,如
in用于检查元素是否在集合中。
自定义表达式的语法在下文中保持不变。
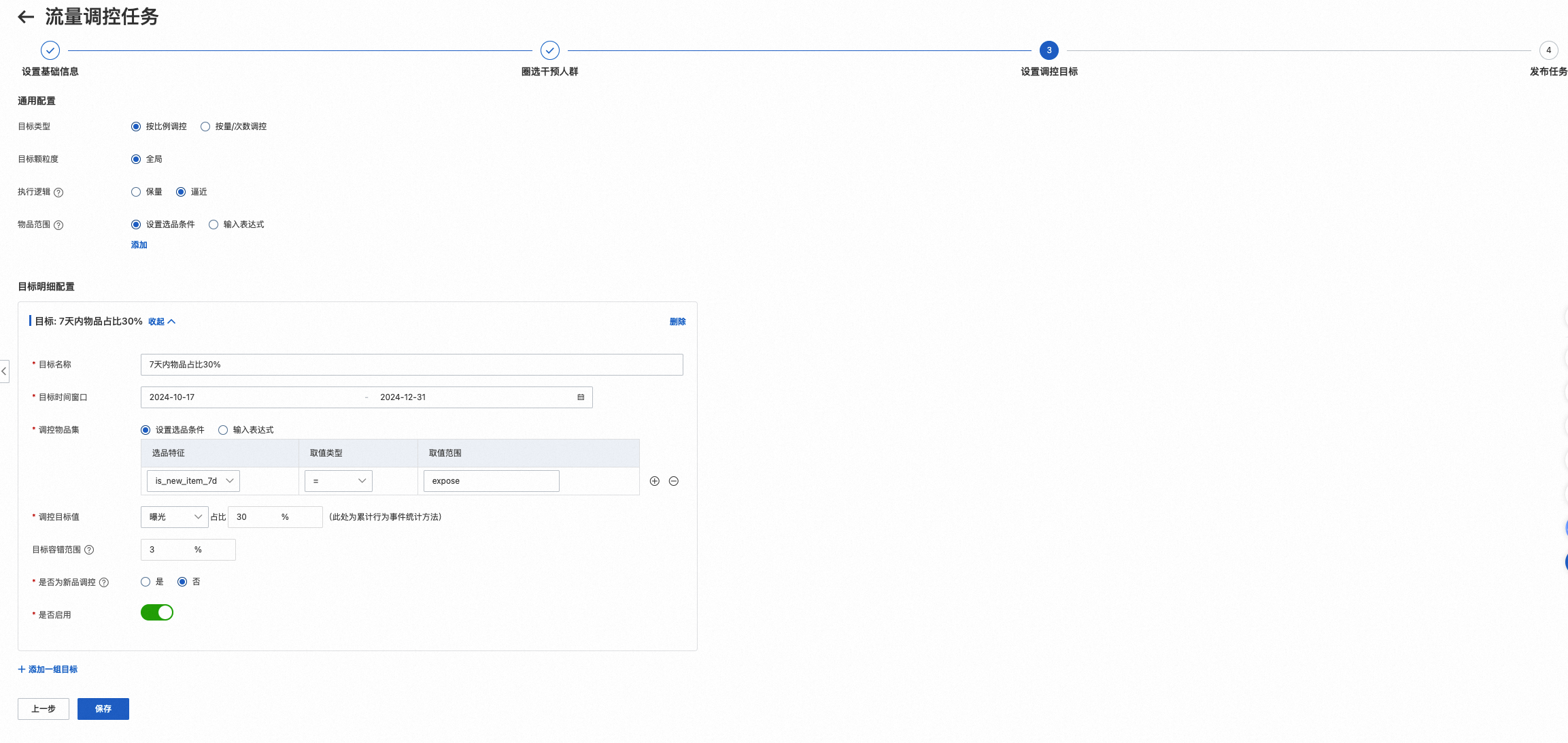
1.3 设置调控目标
术语解释:
执行逻辑
保量:调控任务致力于让目标物品集获得大于等于设定目标值的流量
逼近:调控任务致力于让目标物品集获得约等于设定目标值的流量,; 注意,当多个“逼近”类型的调控任务关联了相同的物品子集时可能会存在因目标冲突而无法达成目标的情况
目标类型
按比例调控:控制目标的流量在整个任务的流量中的比例;整个任务的流量定义为与任务关联的物品集的总流量,若没有配置任务的关联物品集则为当前调控场景的总流量
按量/次数调控:控制目标物品集的能够获得的绝对流量多少
目标颗粒度
全局:设定的流量目标为物品集合需要达成的总流量
单品:设定的流量目标为物品集合中每个物品需要达成的流量
物品范围
一般为在线所有生效的物品集合,您当前设置为比例型调控任务时,物品范围圈定的物品集合的流量将作为分母,核算调控比例。
目标容错范围
记为
,如果当前任务的流量落在 区间,暂停该目标的调控任务直到流量值不满足该区间的约束范围为止。 是设定的流量目标值, 的值可正可负。 针对按比例调控的“逼近”型任务,设定容错范围的好处是当发生超调时不用做反向调控,有助于减轻对大盘指标的干扰。
新品调控
新品调控属于冷启动场景,新品无法从已有召回链路中产出,需新建一路单独的召回。
每个调控任务可以关联多个调控目标。根据需求选择目标类型
1.3.1 按比例调控
1.3.2 按量或按次数调控

1.4 发布任务
flink任务的目的是实时统计被调控目标的数量。
重置datahub/kafka的行为数据的点位到当天的0点(图例为Datahub)
发布任务时如果遇到以下弹窗,请按照界面文档提示完成Datahub配置及Debug配置。

2. 生成的统计sql在运行时需要用到ak信息,首次创建流控任务需要点击创建flink项目变量,然后在发布任务前需要前往flink平台配置下您的ak信息。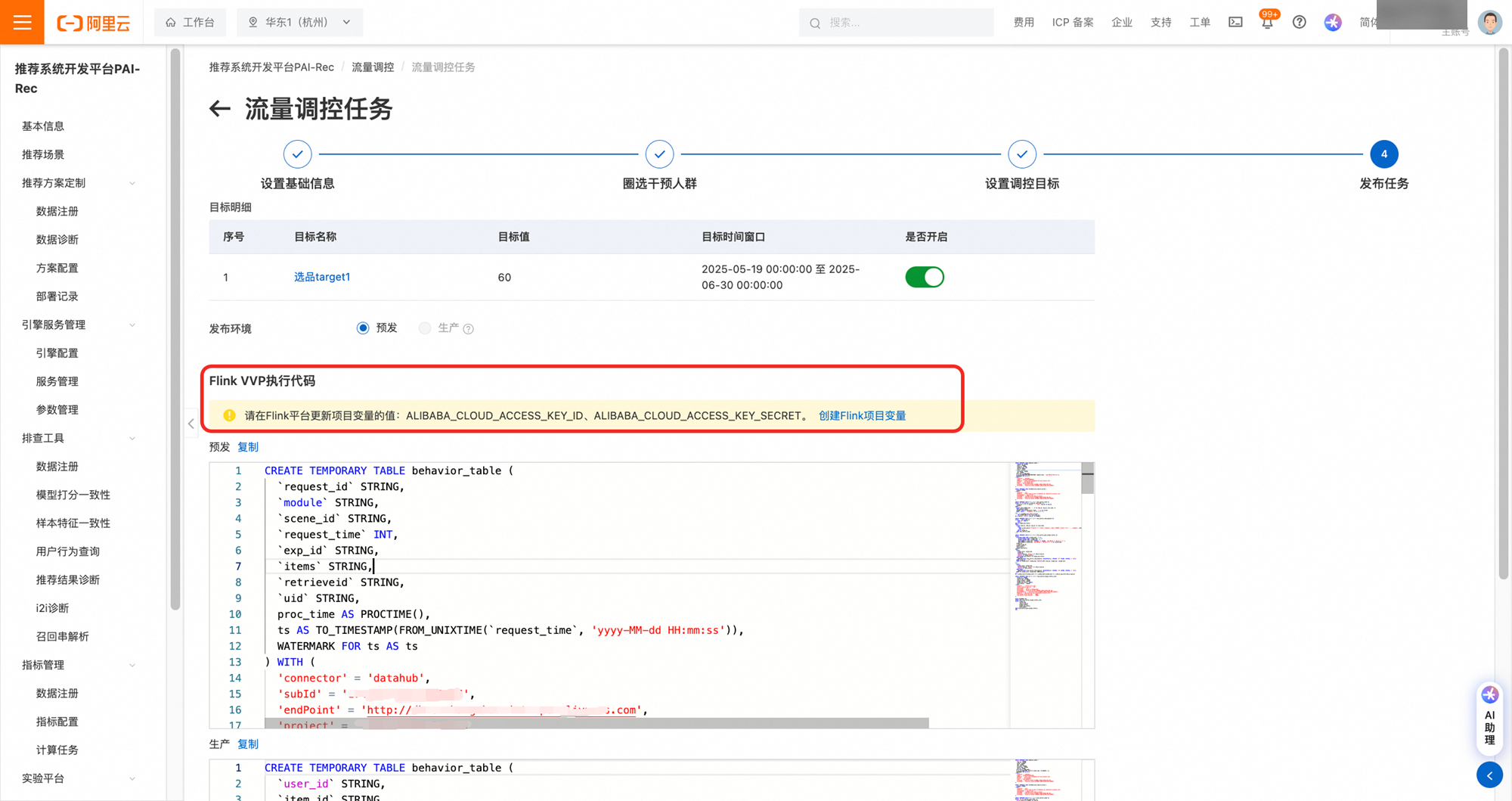
提示创建变量成功之后,在Flink控制台变量管理会新增以下两个变量,请设置下您的ak信息。
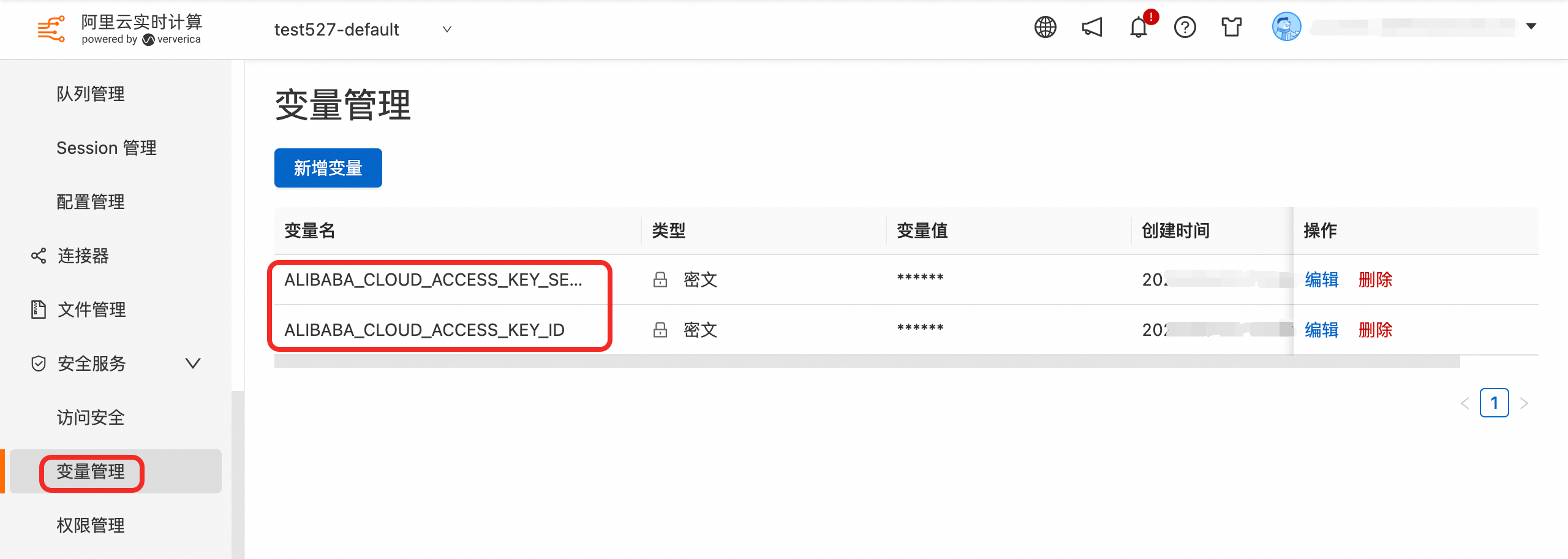
以上做完后点击发布即可(预发环境发布完成,生产环境方可发布)。 发布需要等待一段时间,提示发布成功之后,在flink平台ETL=>作业草稿可以看到对应的sql草稿(后缀为任务ID)以及作业运维中当前作业运行情况(启动中=>运行中)。
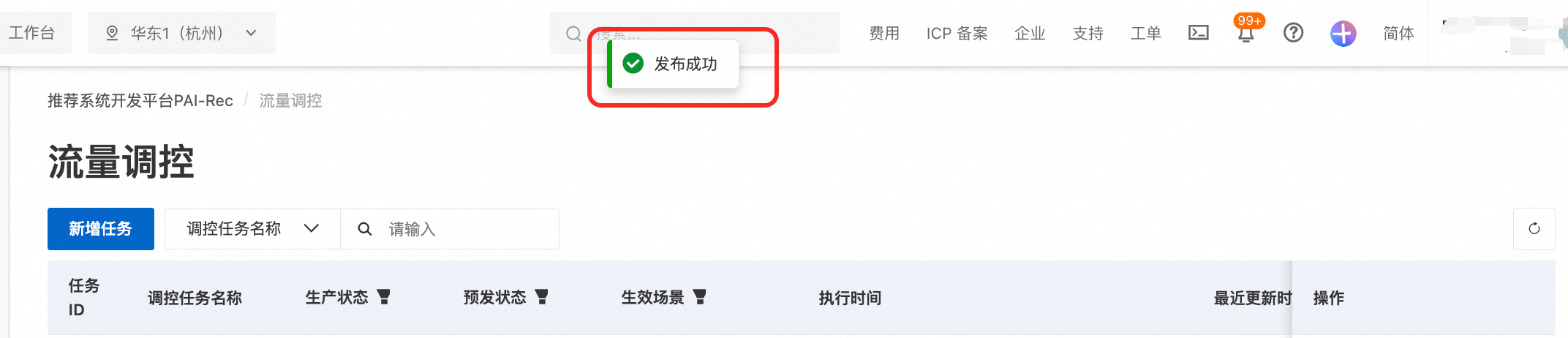


发布操作,可能会出现以下err,即生成的flink sql脚本在部署或启动过程中出现问题,需要您去flink平台详细排查下原因,再返回PAI-Rec重新发布。

2. 启动任务
启动预发流量调控任务,查看流量调控报表,预发任务达到目标后,再开启生产环境任务。

添加PAI-Rec引擎
在原来的引擎配置上,根据业务情况,添加下面的配置。
任务启动后,flink任务需要跑一段时间,建议第二天再配置引擎
1.流量调控配置
该配置在预发环境和预发环境上都要配置
DefaultKp, DefaultKi, DefaultKd 为 PID 算法的三个默认参数值:Kp,Ki,Kd,可通过A/B实验配置覆盖
DiversityRuleSort 为多样性重排(DiversityRuleSort)
"SortConfs": [
{
"Name": "TrafficControlSort",
"SortType": "TrafficControlSort",
"Debug": true,
"PIDConf": {
"SyncPIDStatus": false,
"AllocateExperimentWise": false,
"DefaultKp": 5,
"DefaultKi": 1,
"DefaultKd": 1
}
},
{
"Name": "TrafficDiversityRuleSort",
"SortType": "DiversityRuleSort",
"DiversitySize": 20,
"DiversityRules": [
{
"Dimensions": [
"__traffic_control_id__"
],
"WindowSize": 10,
"FrequencySize": 5
}
]
}
],
"SortNames": {
"home_feed": [
"TrafficControlSort",
"TrafficDiversityRuleSort"
]
},2.其他配置
2.1 按比例调控
无额外配置
2.2 按量\次数调控
该配置在预发环境和预发环境上都要配置,配置完流量调控后,还需添加下面的配置。直接召回所有的被调控物品会给排序造成很大压力,所以需要自定义一个PipelineConfs,每次请求从召回表里取RetainNum:300个物品,进行排序,然后合并到主pipeline里,配置详情参考自定义 Pipeline 流程
"PipelineConfs": {
"home_feed": [
{
"Name": "newitem",
"FilterNames": [
"UniqueFilter",
"UserExposureFilter15Min",
"UserExposureFilterReal",
"adjust_count_filter"
],
"RecallNames": [
"new_item_1500_recall"
],
"RankConf": {
"RankAlgoList": [
"fs_dbmtl_v4"
],
"RankScore": "${fs_dbmtl_v4_probs_is_click}+${fs_dbmtl_v4_probs_is_collect_like_comment}",
"BatchCount": 400,
"Processor": "EasyRec"
},
FeatureLoadConfs": [
{
"FeatureDaoConf": {
"AdapterType": "hologres",
"HologresName": "holo_info",
"ItemFeatureKeyName": "item_id",
"FeatureKey": "item:id",
"HologresTableName": "xxx_home_feed_new_item_1500_v2_online",
"ItemSelectFields": "item_id,is_1500_new_item",
"FeatureStore": "item"
},
"Features": []
}
]
}
]
},
"RecallConfs": [
{
"Name": "new_item_1500_recall",
"RecallType": "ColdStartRecall",
"RecallCount": 1500,
"ColdStartDaoConf": {
"AdapterType": "hologres",
"HologresName": "holo_info",
"HologresTableName": "xxx_home_feed_new_item_1500_v2_online",
"WhereClause": "is_complated='1'",
"PrimaryKey": "\"item_id\""
}
}
],
"FilterConfs": [
{
"Name": "adjust_count_filter",
"FilterType": "AdjustCountFilter",
"ShuffleItem": true,
"RetainNum": 300
}
]