
Pod诊断功能使用于对 ACK/ACS 集群中部署的Pod进行诊断,目前主要覆盖内存相关的场景,包括内存全景分析、OOM诊断和Java应用内存诊断。本文介绍在 Alinux 控制台上进行Pod诊断的最佳实践,同时介绍了三个场景案例。
适用范围
支持除青岛外的中国内地地域的ACK/ACS实例,具体包含以下集群类型:
ACK 托管集群
ACK Serverless 集群
ACS 集群
同时需满足以下操作系统:
架构 | 操作系统 |
x86架构 |
|
ARM架构 | 暂不支持。 |
操作步骤
若使用RAM用户,请确保阿里云账号(主账号)已将系统策略AliyunECSReadOnlyAccess和AliyunSysomFullAccess为RAM用户授权。
在 Alinux 控制台进行诊断
选择需要诊断的集群、诊断类型、诊断项,以及要诊断的 Pod 的命名空间和Pod名称。
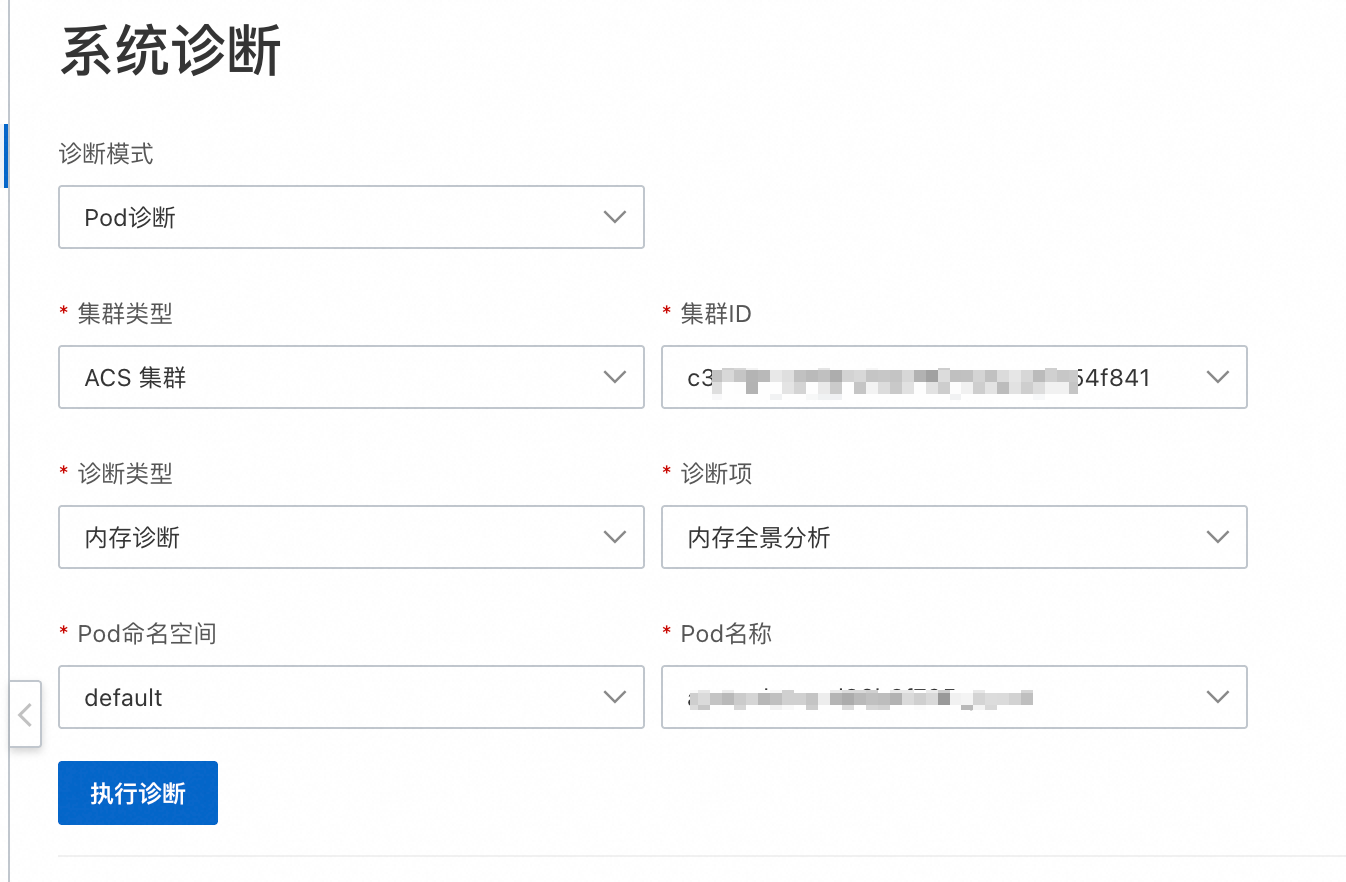
单击执行诊断后,可在诊断记录区域,单击查看报告。

通过 ACS 控制台访问诊断
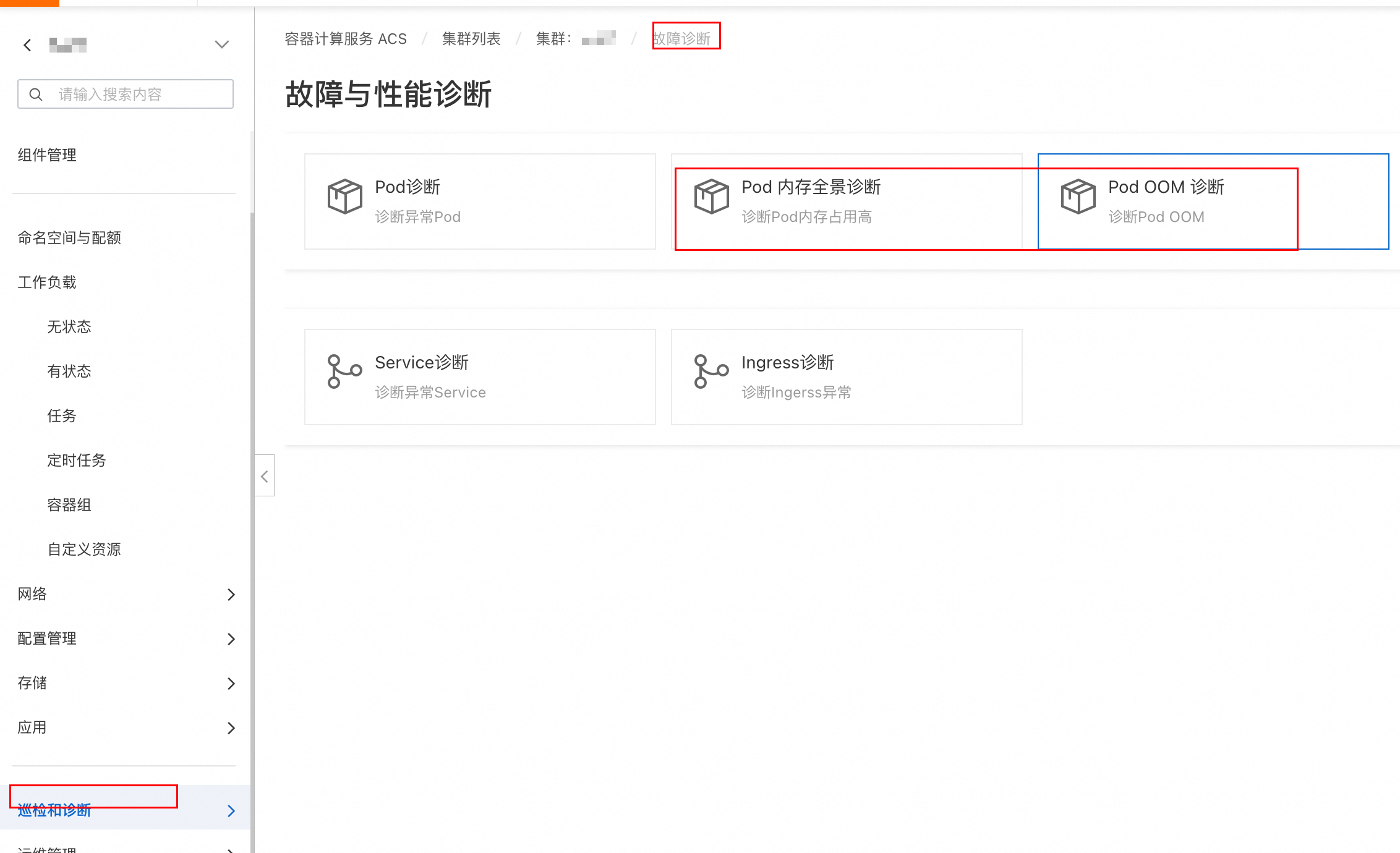
访问ACS控制台,从左侧侧边栏选择。
根据所需场景选择Pod 内存全景诊断或Pod OOM诊断。
案例一:Workingset高异常告警
场景说明:
在 Kubernetes 场景,容器内存实时使用量统计(Pod Memory),由 WorkingSet 工作内存(WSS)来表示,工作内存 WorkingSet 是 Kubernetes 的调度决策判断内存资源的指标,包括节点驱逐等,一般用户也会通过为 WSS 设置监控阈值来进行告警,但是部分场景下,WSS 告警会有一定程度的误报,也就是WSS提示用量高,但是大部分是Active的文件缓存,整体内存可用量(Available)其实是还有不少的,有大量的页缓存可以被回收使用。
问题描述:
客户首先通过ARMS设置的告警规则收到频繁的 WSS 用量超过80%告警,但是业务实际上并没有受到太大的影响,内存可以正常的申请和使用,而且并没有发OOM。
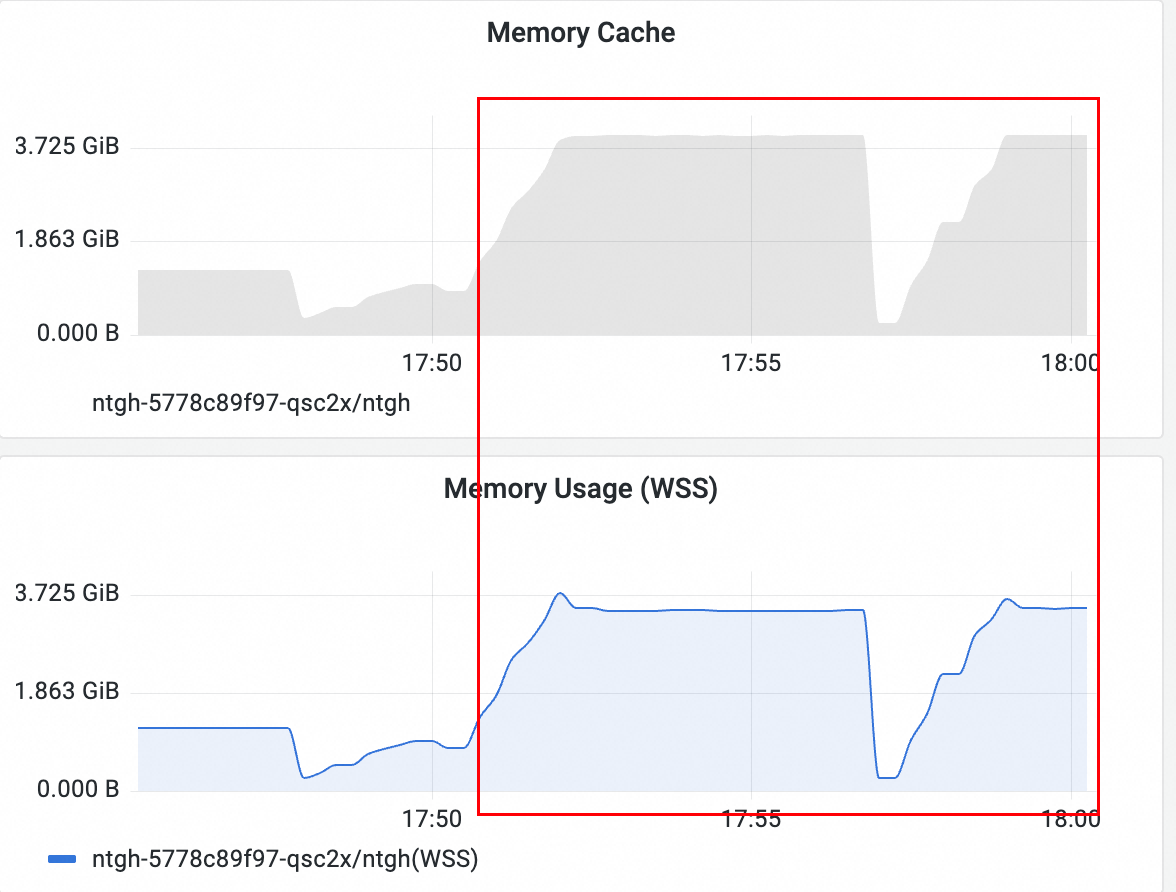
从内存监控上看,WSS 的增长贡献基本上是Cache贡献的,实际上,根据K8s官网的定义,WSS 是Pod 中容器的 WorkingSet 工作内存,是此容器对应的 cgroup memory usage,减去了 Inactive(file) 这部分的缓存。即若WSS大部分都是Cache的话,那说明 Active(file) 的占用较高,有文件被频繁读取。
诊断分析
针对上述场景,使用 Alibaba Cloud Linux 控制台 Pod诊断-内存全景分析诊断功能对目标 Pod 发起诊断,诊断结果如下图所示:
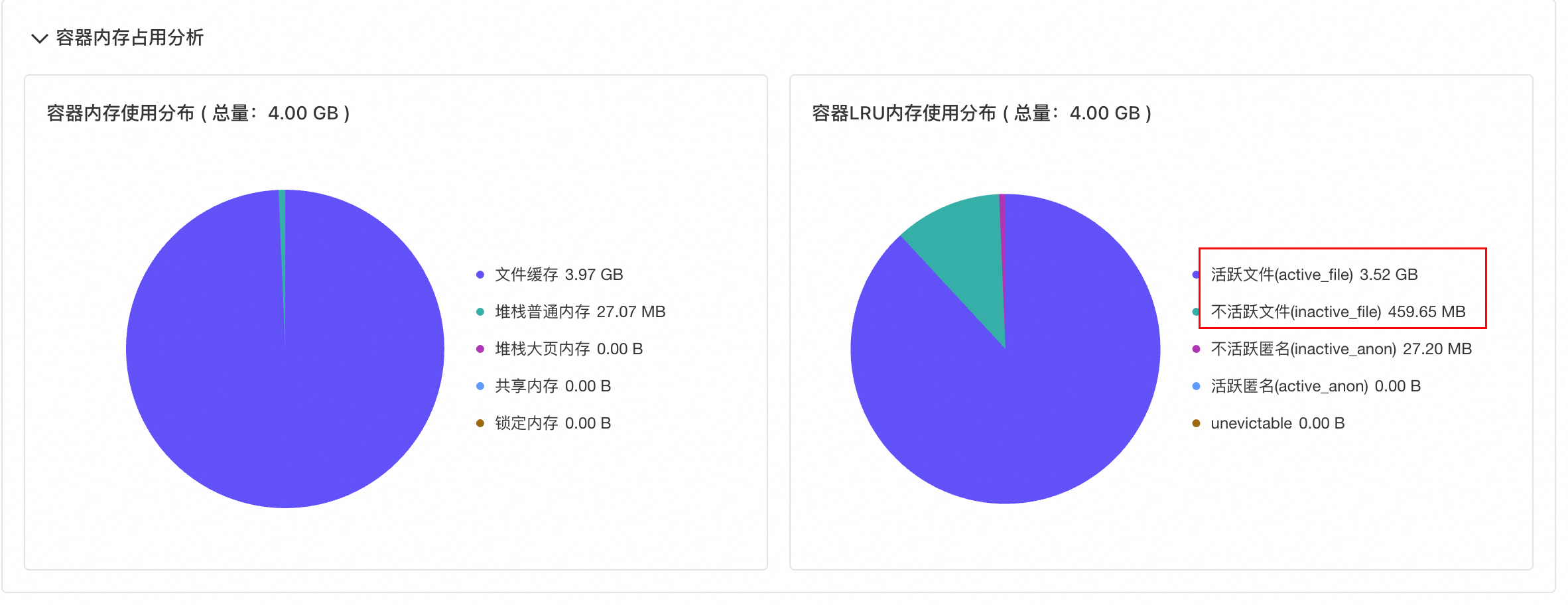
从内存分布结果可以看到,活跃内存占 3.52G,加上堆内存的使用,基本就和监控的 WSS 一致。
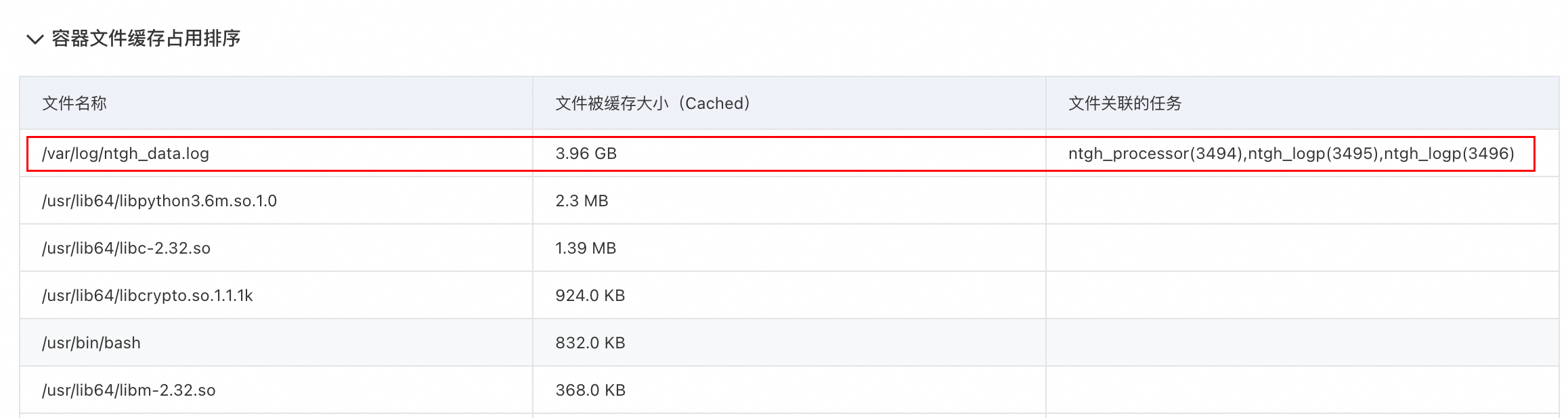
进一步查看文件缓存占用列表,发现容器缓存占用最大的是一个日志文件,同时这个日志文件有三个进程正在打开使用,其中有一个是产生日志的进程,另外两个进程则是读取日志文件进行解析。
Active文件缓存是被高频访问的部分,如果一个文件只被读取了一遍,对应产生的缓存会是 Inactive 的,如果文件的大部分缓存都是 Active的,极有可能是有多个进程对相同的文件内容进行多次重复读取导致的。结合这个场景可以知道,容器内部产生了一个日志文件,同时有两个进程对这个日志文件进行了重复的读取解析导致这个日志文件的Cache都是 Active的。又由于 WSS 计算的时候会包含活跃文件缓存,因此造成容器工作内存使用率高产生告警,但是业务无明显异常的问题。
案例二:突发内存申请导致OOM,监控看内存没有用满
场景说明:
在部分业务场景下,Pod内部在业务流量有突增时对内存有突发需求,如果突发的内存申请比较激进,快速达到了 Pod 的 limit 限制,则容易触发OOM,并且触发OOM时刻从监控大概率发现内存并没有用满,通常来说监控数据是每15、30或者60秒采样一次,突发的内存申请可能会被忽略。
问题描述:
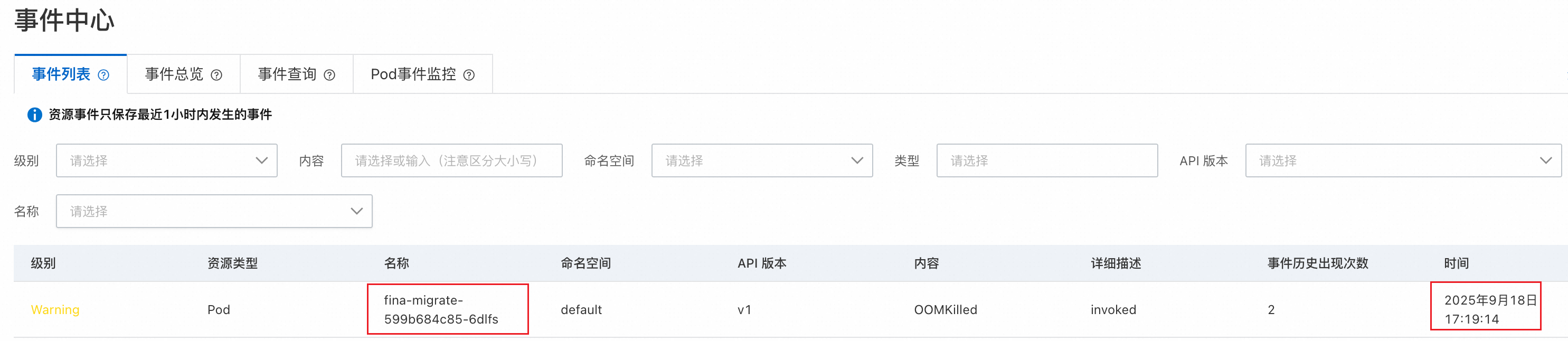
客户首先通过ACS的事件中心观测到有Pod发生了 OOMKilled 事件,表示该 Pod 存在内存使用超过限制的情况,触发了系统的 oom-killer 机制,将目标Pod中的高内存占用进程杀掉了,为了观测事发时刻内存的实际用量,客户接着继续查看集群的 Pod 监控。
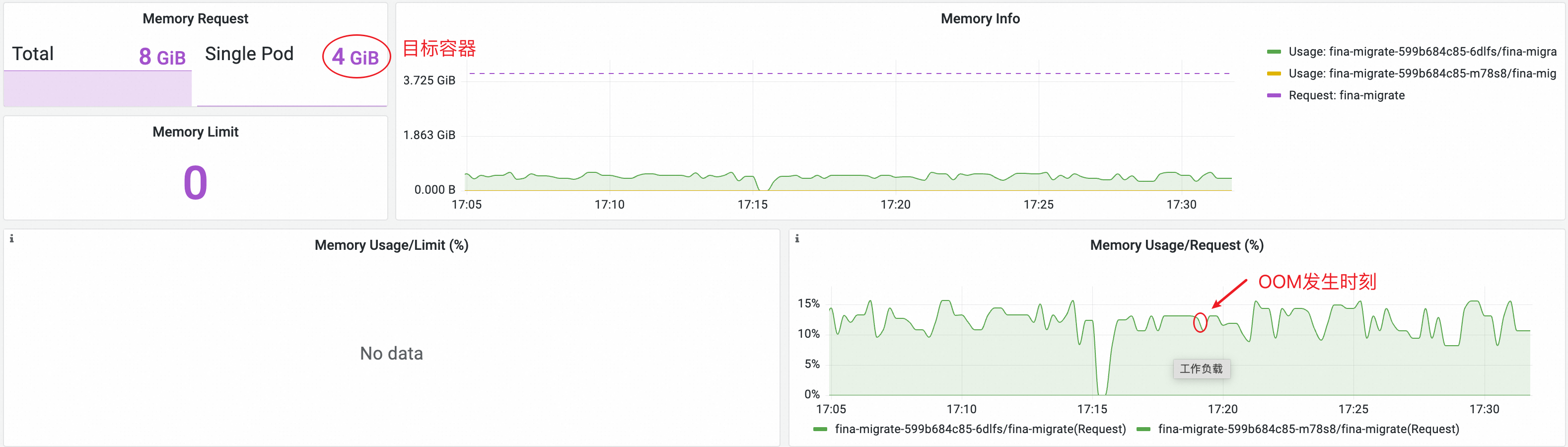
从Pod监控可以看到目标容器的 Request 是 4G,17:05 ~ 17:30 期间通过监控观测到容器的内存利用率基本都在15%以下,并没有观测到内存有较高占用。
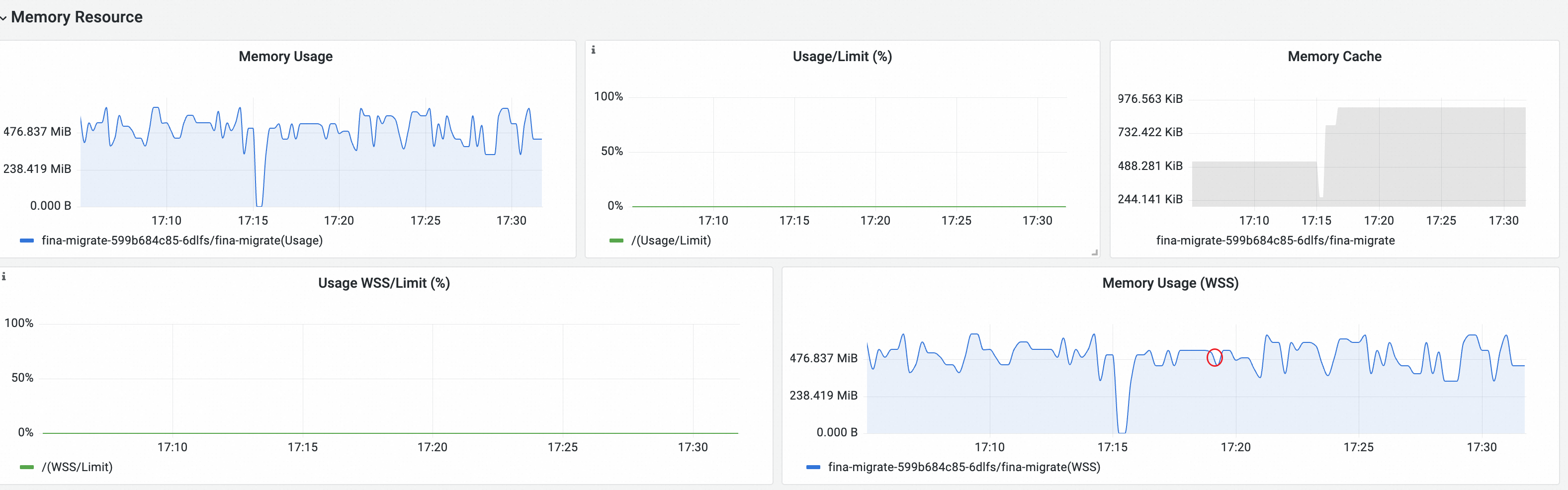
同时观察到的 Workingset 用量也维持在低位,期间缓存也没有增长。此时就出现了 OOM 发生时,监控并没有观测到内存耗尽的现象,和直观不符合。通常这个情况是由于进程存在短时间的突发内存申请,从开始突发申请内存到耗尽内存发生OOM的时间短于监控的采样周期导致的。那该如何知道OOM现场的情况,是由于哪个进程内存用超导致的呢。
诊断分析
针对上述场景,使用 Alibaba Cloud Linux 控制台 Pod诊断-OOM诊断功能对目标 Pod 发起诊断,诊断结果如下图所示:
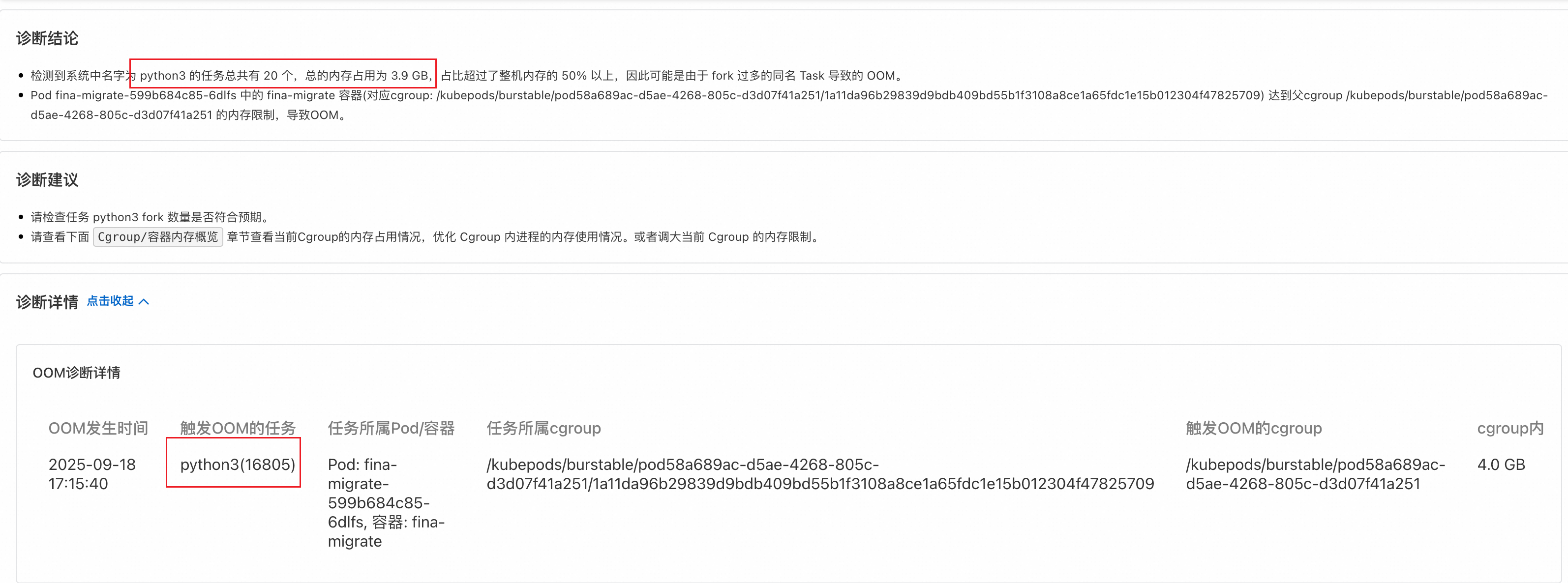
从诊断结果可以知道目标Pod确实在 17:15 左右发生了一次OOM(OOMKilled事件产生会有一定延时,在实际发生OOM几分钟后 OOMKilled 事件才会生成),并且触发 OOM 的进程是一个 python 业务,同时观测到发生OOM时刻,容器内部存在20个python进程,总的内存占用为3.9G,接近容器的 memory limit。
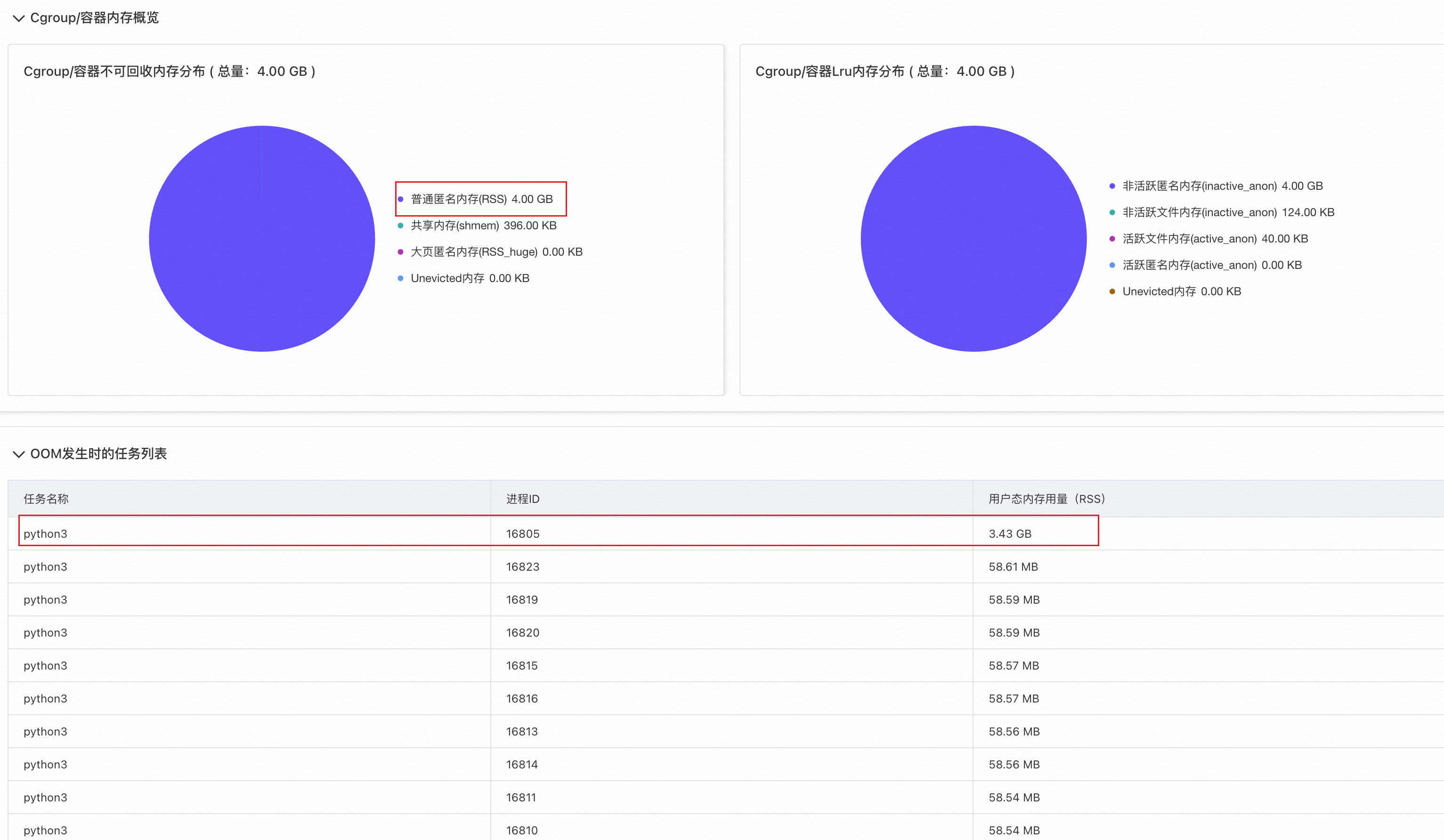
进一步观察报告详情可以看到,发生OOM时刻,主要的内存占用为普通匿名内存,基本是业务进程的堆内存,同时从OOM发生时的任务列表可以看到,排名第一的 python 进程申请了3.43G左右的内存,而其它 python 进程的内存占用基本在五六十M左右。
综合上述报告分析可以知道,目标Pod内确实存在业务python进程突发内存申请导致了OOM。
案例三:容器持续OOM,每次OOM之后内存没有完全恢复
场景说明:
在 Kubernetes 场景中,共享内存(Shared Memory)的使用通常涉及需要高效跨容器通信或数据共享的场景,以 ACS 为例,可以根据挂载EmptyDir的方式来使用共享内存。这部分内存独立于进程,所以如果进程发生OOM被kill,并不会释放这部分内存,如果没有合适的清理就会导致共享内存的泄露。
问题描述

客户首先,从 ACS 的事件中心观测到 Pod 发生了 OOMKilled 事件,为了进一步分析,先去查看Pod 的监控。
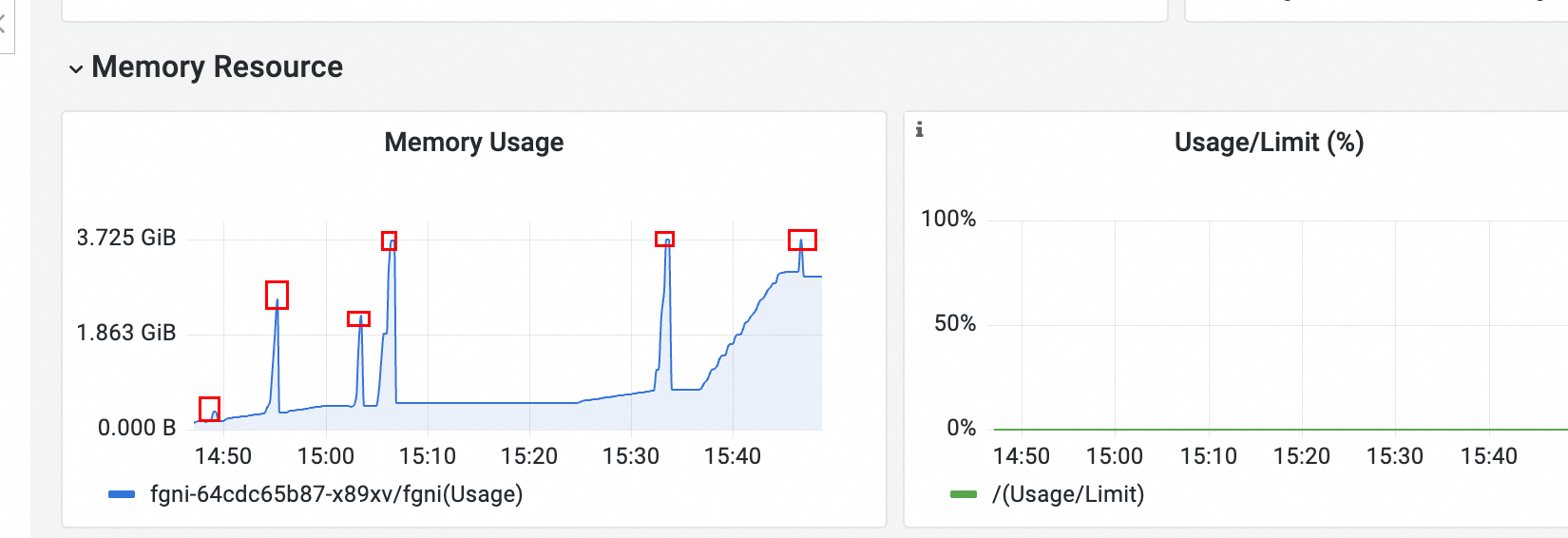
从 Pod 监控可以看到有明显的六处内存突刺,应该和OOM相关。

进一步查看容器内部的 dmesg 日志可以看到期间发生了7次OOM(时区问题,容器内部的时间+8为对应的真实时间)。
从上述信息中可以看到如下现象:
不是每次OOM都达到内存上限,并且有一次OOM没有在内存监控盘中看到突刺,说明此时有突发内存申请。
每次发生OOM之后,内存会有回落,但是整体呈上升趋势,看起来内存并没有完全释放,有泄漏。
诊断分析
诊断最新一次OOM
针对上述场景,首先使用 Alibaba Cloud Linux 控制台 Pod诊断-OOM诊断功能对目标 Pod 发起OOM诊断,诊断结果如下图所示:
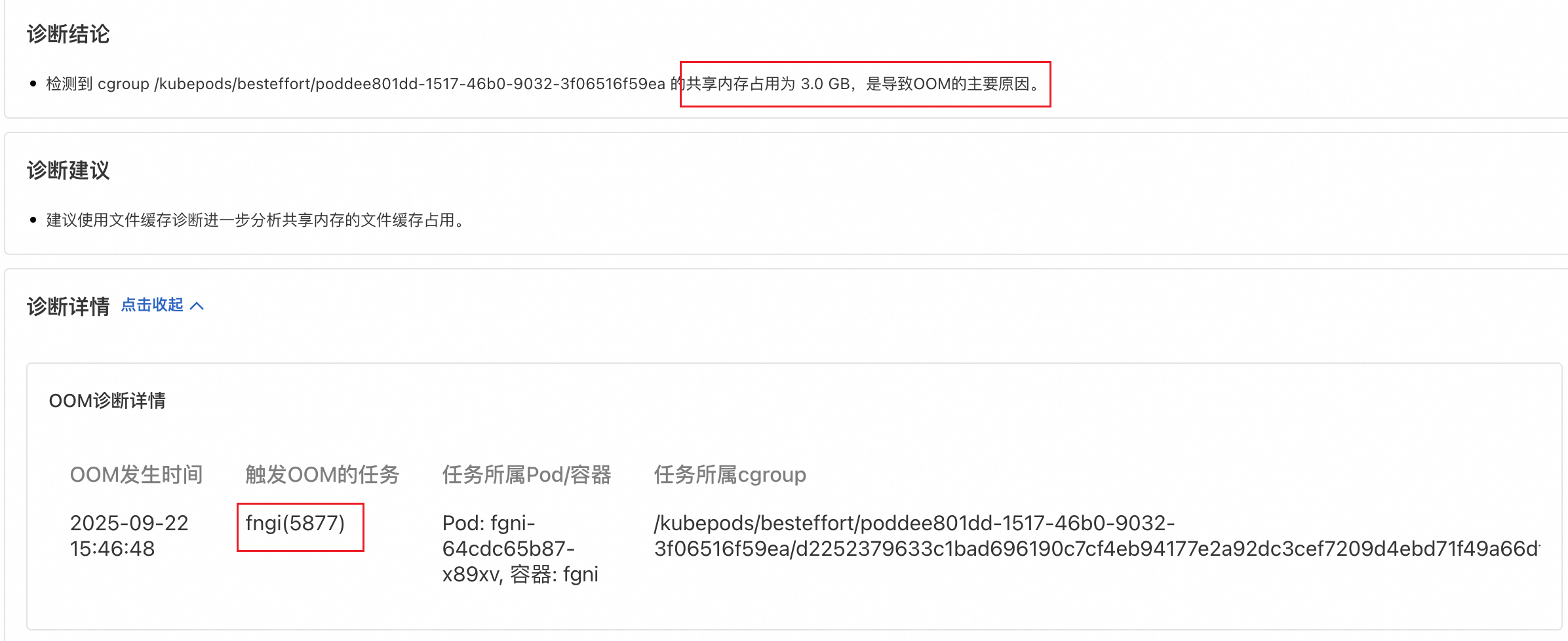

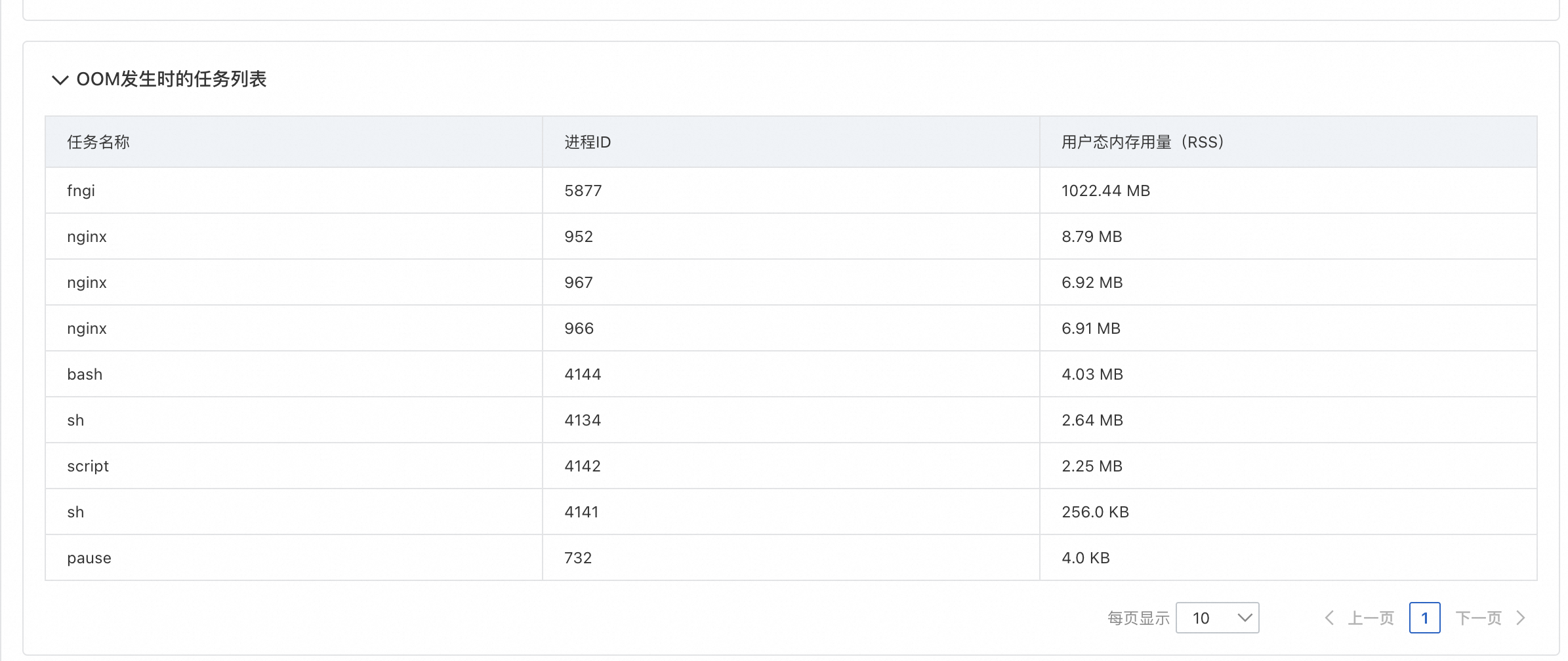
从诊断结果可以知道目标Pod最新一次发生OOM的原因是共享内存占了3G,业务应用占了1G,达到 limit 限制导致OOM。
诊断历史OOM
由于 OOM 发生多次,最新一次的OOM是由于共享内存占用过多,同时应用内存也占了1G导致的,为了更好的分析OOM的原因,可以在发起诊断的时候对历史的OOM进行诊断。
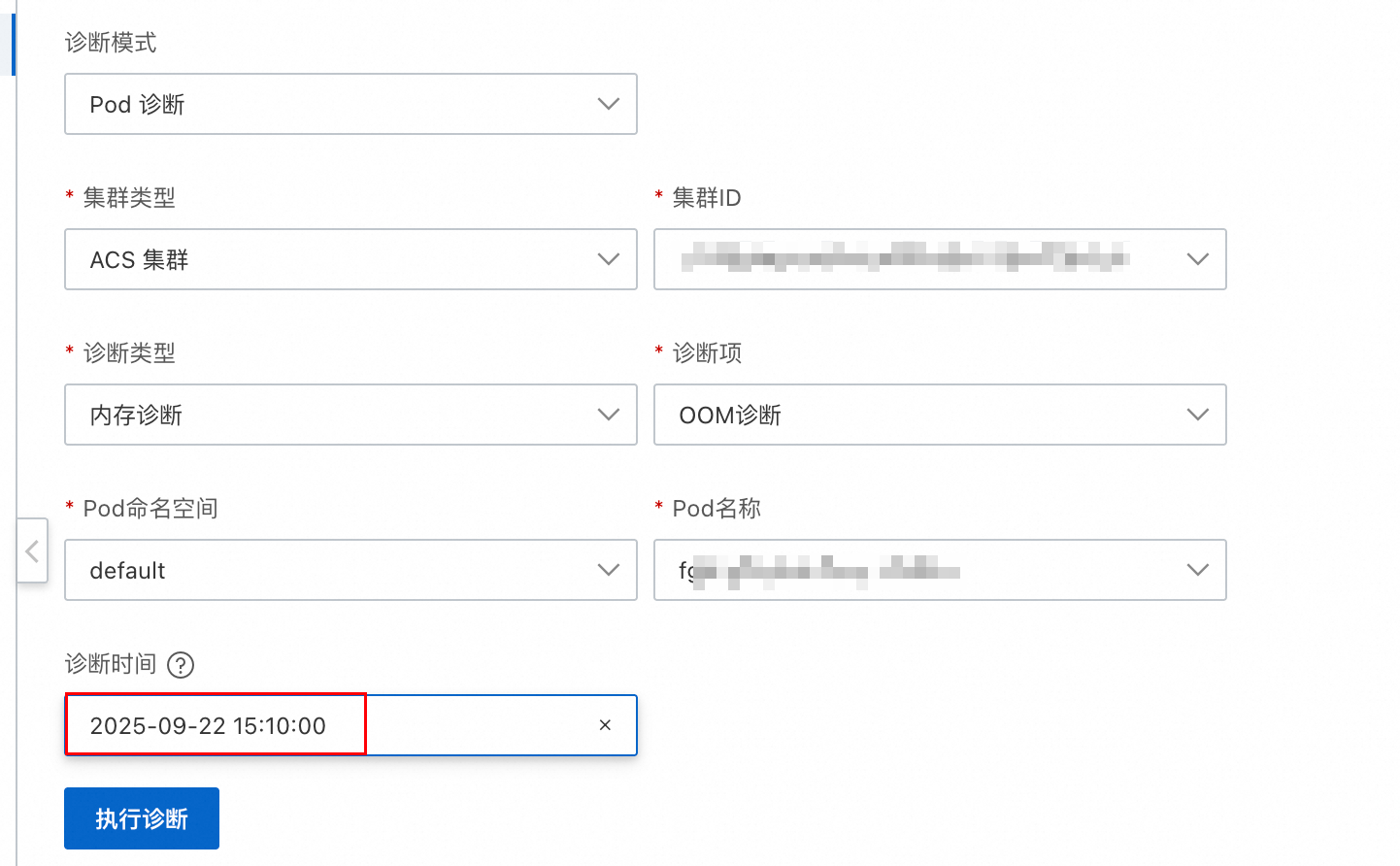
如图在发起OOM诊断时,指定时间即可对历史OOM发起诊断,诊断工具会对离目标时间最近的一次OOM事件进行分析,诊断结果如下:
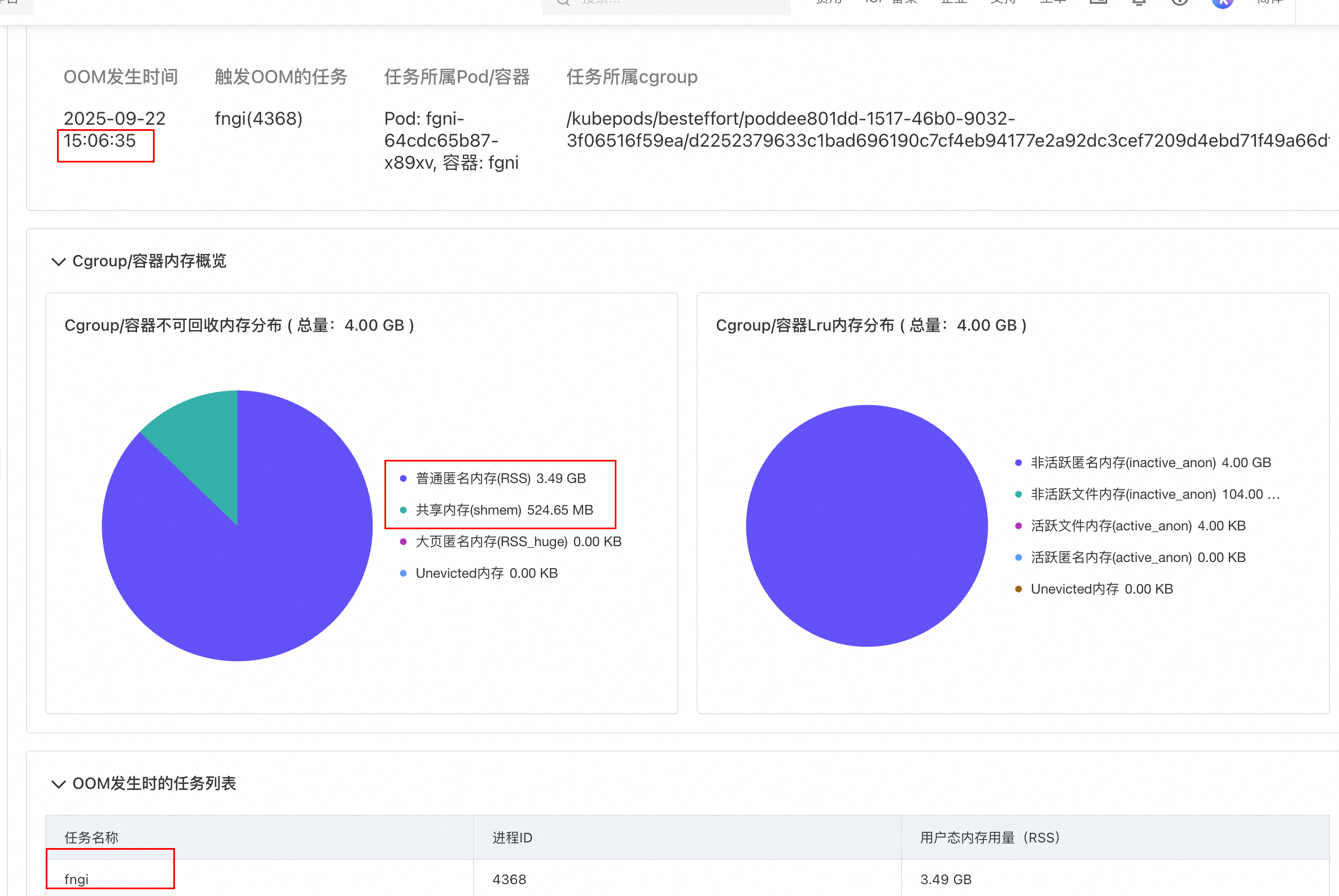
从诊断结果可以看出,15:06发生的OOM,主要的原因是业务应用占用内存太多,此时共享内存还没有用到很多。
通过内存全景分析,查看共享内存
从前两个诊断结果可以看出首先业务进程有突发内存申请,导致周期性OOM,同时共享内存存在泄露,每次OOM之后内存没有完全释放,接着可以使用内存全景分析,分析一下共享内存的占用情况。
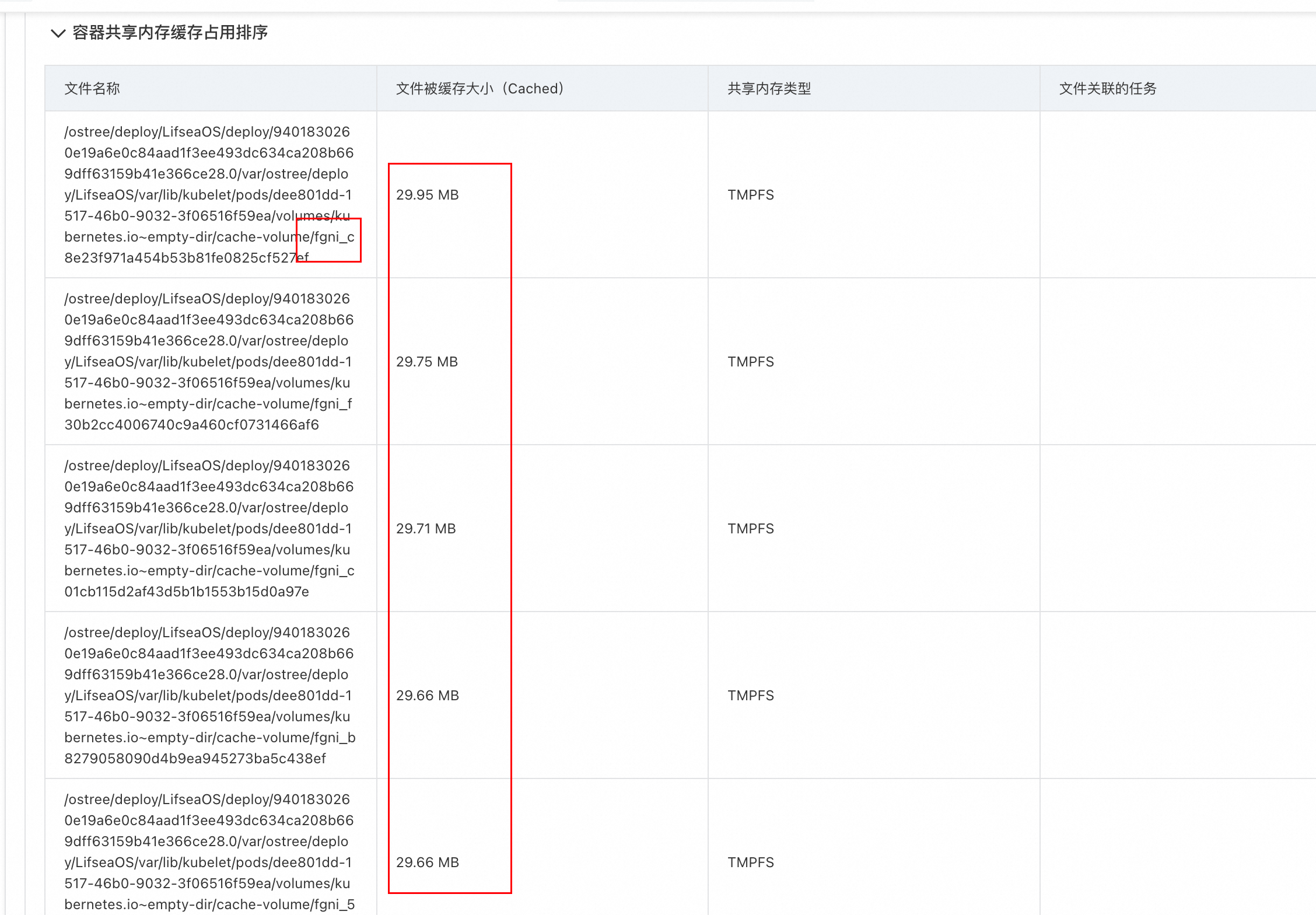
内存全景分析结果显示,容器内存和业务相关的大量共享内存文件,并且基本都是小文件。手动删除泄漏的文件之后,监控观察到内存得以释放。
综合上述报告分析可以知道,目标Pod存在业务进程突发内存申请导致了OOM,同时伴随着业务进程的OOM,有大量共享内存文件小文件泄漏,手动删除泄漏的共享内存文件,内存才得到释放。