
Loongkit 是阿里云推出的在基础软件视角下专门针对 AI 场景(比如文生图、文生视频、图生视频、智驾、具身智能等场景)的 Infra 维度深度优化的软硬协同加速的 OS 扩展组件。通过智能分析硬件资源、优化计算资源配置、监控训练过程、优化算子实现,该 OS 扩展组件能够显著提升模型训推效率,降低资源浪费,适用于 PyTorch/MMCV 等主流框架。
使用环境要求
-
Python版本: 3.10+
-
PyTorch版本: 2.4.0+
-
操作系统:Linux
安装方式
EGS、ACS 环境访问https://aiext-pypi.mirrors.aliyuncs.com/aiext-pro需提交工单申请白名单。
ACS PPU
ACS 环境访问https://aiext-pypi.mirrors.aliyuncs.com/aiext-pro 需要集群维度授权并修改容器YAML配置,详见ACS 环境配置 aiext-pro 源访问权限的步骤。pip install aiext-pypi-plugin -i http://mirrors.cloud.aliyuncs.com/aiext-pypi/aiext-pypi-plugin/simple --trusted-host mirrors.cloud.aliyuncs.com
pip install loongkit --extra-index-url=https://aiext-pypi.mirrors.aliyuncs.com/aiext-pro/pg1/simple/EGS
如使用uv,需在安装aiext-pypi-plugin后先执行一次pip install pip -i https://aiext-pypi.mirrors.aliyuncs.com/aiext-pro/simple/触发认证,之后 uv 即可正常使用 AIEXT-Pro 源。
pip install aiext-pypi-plugin -i http://mirrors.cloud.aliyuncs.com/aiext-pypi/aiext-pypi-plugin/simple --trusted-host mirrors.cloud.aliyuncs.com
pip install loongkit --extra-index-url=https://aiext-pypi.mirrors.aliyuncs.com/aiext-pro/simple/快速入门
Loongkit 提供环境变量、启动器和代码修改三种加载方式,任选其一即可。
环境变量
PYTHONPATH=/usr/local/lib/python3.10/site-packages/loongkit/prelude/:$PYTHONPATH LOONGKIT_ALL=1 <训练任务命令>-
在
PYTHONPATH环境变量中加入 loongkit/prelude 模块所在路径可使 loongkit 在 python 任务启动时自动加载,但默认不启用任何优化特性; -
通过
LOONGKIT_xxx系列环境变量控制各项优化特性的启闭与配置,其中LOONGKIT_ALL=1表示开启所有当前环境支持的优化特性。 -
loongkit/prelude 模块所在路径与基础镜像配置和虚拟环境配置有关,可通过在容器内执行
python3 -c "import site; print(site.getsitepackages()[0])"获得。如果不便获知该路径,可以考虑采用启动器或源代码修改形式加载Loongkit。
启动器
随Loongkit包附带的loongkit-run启动器可以自动检测 loongkit/prelude 模块所在路径并以修改后的PYTHONPATH执行训练任务:
LOONGKIT_ALL=1 loongkit-run <训练任务命令>各项优化特性的启闭与配置同样通过LOONGKIT_xxx系列环境变量进行控制。
代码修改
在训练任务脚本文件的开头加入下列语句也可以达到加载 Loongkit 的效果:
import loongkit.all各项优化特性的启闭与配置同样通过LOONGKIT_xxx系列环境变量进行控制。
高级配置
Loongkit的配置以环境变量为接口,可以通过在YAML、命令行等设置环境变量改变 Loongkit 的行为。
基本配置接口
|
环境变量 |
数据类型 |
默认值 |
说明 |
|
LOONGKIT_LOGLEVEL |
string |
warning |
限制输出日志的等级,仅等级不低于该等级的日志会被输出到日志文件。可选配置如下(不区分大小写):
如果该环境变量为其它取值,则仍然取默认等级 warning。 |
|
LOONGKIT_LOGDIR |
string |
无 |
指定输出日志的存放位置:
第一个可用目录将被用于存放日志文件。如果上述目录均不可用,日志将被输出到标准错误输出(stderr)。 |
优化特性说明
所有优化特性按照下列规则分类,可通过LOONGKIT_ALL=X(X取1、2或3)批量启用:
-
1(基础优化):在已知版本的主流框架基础上进行的等效优化,功能表现基本不变,默认配置下通常不会带来性能下降。
-
2(进阶优化):需要一定经验或结合其它工具才能在不同场景下正确配置的优化;如果参数或配置选择不当,可能会对性能产生负面影响。
-
3(深度优化):会改动一些常见模块的实现方式,属于更“底层/结构性”的调整;如果你的模型实现与开源版本差异较大,可能会出现功能不兼容或效果异常。
|
分类 |
环境变量 |
数据类型 |
默认值 |
优化等级 |
说明 |
版本要求 |
注意事项 |
|
/ |
LOONGKIT_ALL |
int |
0 |
/ |
启用特定优化等级及以下的所有优化特性。 |
参见各项特性的版本要求 |
/ |
|
数据预处理 |
LOONGKIT_DATA_CONTAINER |
bool |
0 |
1 |
启用 MMCV DataContainer 的pin_memory 支持 |
1.7.0 ≤ mmcv ≤ 1.8.0 |
自动使能 PyTorch DataLoader 的 pin_memory 功能。 |
|
LOONGKIT_DATA_PREFETCH |
bool |
0 |
1 |
启用数据预取,依赖DataContainer 的 pin_memory 支持。 |
1.7.0 ≤ mmcv ≤ 1.8.0 |
显存占用峰值增加,增加量相当于一次迭代所需数据量的大小 |
|
|
LOONGKIT_MMENGINE_DATA_PREFETCH |
bool |
0 |
1 |
启用适配 MMCV 2.x 的数据预取。 |
mmcv ≥ 2.0 且 mmengine ≥ 0.8.0 |
无 |
|
|
LOONGKIT_IMNORMALIZE |
bool |
0 |
3 |
优化数据预处理过程中图像归一化算子在 CPU 上执行的效率。 |
无 |
在数据进程第一次加载数据时引入即时编译,有一次性的编译时间开销。 |
|
|
LOONGKIT_DISTORTION |
bool |
0 |
3 |
优化数据预处理过程中图像随机畸变算子在 CPU 上执行的效率。 |
|||
|
LOONGKIT_PYTORCH |
bool |
0 |
1 |
优化数据预处理期间 PyTorch DataLoader 的内存管理效率。 |
无 |
||
|
LOONGKIT_PAGE_CACHE_LIMIT |
bool |
0 |
2 |
自动为当前容器的 root memcg 设置页面缓存上限,缓解内存碎片化带来的性能抖动问题。 |
|||
|
资源调控 |
LOONGKIT_NUMA_AFFINITY |
bool |
0 |
1 |
启用 loongkit 的主动 NUMA 亲和性设置,确保训练进程始终运行在与 GPU 相同的 NUMA 节点上。 |
无 |
|
|
LOONGKIT_SUBCGROUPS |
bool |
0 |
2 |
根据 NUMA 亲和性将训练和数据进程划分为不同子 cgroup,供其它资源调控工具进一步调整各类进程的可用资源。 |
该特性启用时将自动关闭主动的 NUMA 亲和性设置(即 |
||
|
LOONGKIT_CONFIG_GUARDS |
bool |
0 |
1 |
检查线程池大小、data worker 数、编译线程数等配置,在可能超出硬件资源承受范围时告警。 |
torch ≥ 2.1.0 |
见训练任务配置检查。 |
|
|
算子优化和模型编译 |
LOONGKIT_COMPILE_RESNET |
bool |
0 |
1 |
编译 ResNet 子网络。 |
torch ≥ 2.6.0 且 1.0.0 ≤ mmdet ≤ 3.3.0 |
模型编译会引入额外的启动时编译时间和显存开销,其程度与所编译模型的复杂度有关。 |
|
LOONGKIT_FUSED_ADAMW |
bool |
0 |
1 |
采用融合算子后的 AdamW 优化器实现。 |
torch ≥ 2.4.0 |
||
|
LOONGKIT_OPENVLA |
bool |
0 |
1 |
编译 Llama2 模块。 |
torch ≥ 2.6.0 |
||
|
LOONGKIT_MMDET_MODULES |
bool |
0 |
1 |
编译部分注册到 mmdet.models.builder.MODELS 的算法模块。 |
torch ≥ 2.6.0 且 2.12.0 ≤ mmdet ≤ 2.28.3 |
默认编译 |
|
|
LOONGKIT_DICE_LOSS |
bool |
0 |
1 |
采用基于 GPU 的 DiceLoss 优化实现。 |
0.12.0 ≤ mmseg ≤ 1.0.0 |
无 |
|
|
LOONGKIT_DAG |
bool |
0 |
1 |
优化 Deformable Aggregation 算法模块。 |
无 |
无 |
|
|
LOONGKIT_VOXELIZATION |
bool |
0 |
3 |
优化 mmdet3d 库中体素化算子 |
无 |
||
|
LOONGKIT_BEVFORMER |
bool |
0 |
1 |
优化 BEVFormer 所引入的SpatialCrossAttention、TemporalSelfAttention 等算法模块。 |
适用于采用 BEVFormer 原生相关模块的模型。 |
||
|
LOONGKIT_UNIAD |
bool |
0 |
1 |
优化 UniAD 中使用到的部分算法模块。 |
无 |
||
|
LOONGKIT_BEVFUSION |
bool |
0 |
3 |
优化 BEVFusion 中使用到的部分算法模块。 |
适用于采用 BEVFusion 原生相关模块的模型。 |
||
|
LOONGKIT_HF_ACC_COMPILE |
bool |
0 |
3 |
支持 HuggingFace Accelerate 的 torch.compile 训练加速,自动启用 inductor 编译后端; |
torch = 2.10.x |
修复了 transformers 4.57.* 版本中 FA2 attention_interface 调用导致的编译崩溃问题 |
|
|
LOONGKIT_DYNAMIC_SHAPE_FIX |
bool |
0 |
1 |
修复 PyTorch 2.9.x 编译涉及动态维度的模型时崩溃的问题。 |
torch = 2.9.x |
无 |
|
|
LOONGKIT_COMPILE_PI0PYTORCH |
bool |
0 |
1 |
编译 pi0 的 PyTorch policy 模块。 |
torch ≥ 2.6.0 |
模型编译会引入额外的启动时编译时间和显存开销,其程度与所编译模型的复杂度有关。 |
|
|
LOONGKIT_DONATED_BUFFER_FIX |
bool |
0 |
1 |
修复 PyTorch 2.6–2.8 下 DDPOptimizer 导致权重被静默覆写的问题,自动禁用 donated_buffer。 |
torch 2.6.0 – torch 2.8.x |
上游 PyTorch 2.9.0 已修复此问题,该特性仅在受影响版本上自动生效。 |
|
|
精度控制 |
LOONGKIT_ALLOW_TF32 |
bool |
0 |
1 |
对于FP32精度的矩阵乘法和卷积,采用TF32精度进行计算 |
torch ≥ 2.0.0 |
TF32 与 FP32 的可表示范围一致,但尾数仅保留 FP32 的一半,需评估模型是否需要 FP32 的高精度。 |
bool类型的环境变量接受1、on、yes表示true,0、off、no表示false,其它值表示未定义,取默认值。
NUMA 亲和性的高级设置
CUDA_VISIBLE_DEVICES兼容性与LOONGKIT_NUMA_AFFINITY_ALLOW_INDEX
Loongkit 的 NUMA 亲和性设置默认对 PyTorch 2.5.0 版本及以上,且 GPU 均匀分布在各 NUMA 节点的条件下生效,此时可以自动适应CUDA_VISIBLE_DEVICES的配置。
对于 PyTorch 2.4.0 及更低版本,可以通过设置LOONGKIT_NUMA_AFFINITY_ALLOW_INDEX=1启用 NUMA 亲和性设置,此时用户应避免配置CUDA_VISIBLE_DEVICES,否则训练进程的 NUMA 亲和性设置可能发生错位,影响训练效率。
AMD/海光 CPU 的进一步调优
AMD、海光 CPU 等的微架构采用分离的 L3 缓存,不同物理核访问不同 L3 缓存的延迟也不相同,因此可以设置LOONGKIT_NUMA_AFFINITY_PARTITION_PER_LLC=1将不同训练进程绑定到 L3 缓存不同的物理核上可以进一步提高性能。该设置仅在同一 NUMA 节点内的不同L3缓存可均匀分配到该节点上的训练进程时生效。
在 L20N 机型上,当训练任务整体 CPU 利用率不超过 50% 时,可以设置 LOONGKIT_NUMA_AFFINITY_SEPARATE_BY_ROLES=1隔离训练和数据进程所使用的 L3 缓存,进一步降低数据进程对训练的干扰。
非对称架构上的进一步调优
在 GPU 未均匀分布在各 NUMA 节点的平台上进行 NUMA 亲和性设置需要综合考虑训练任务的CPU和内存需求和硬件拓扑,因此Loongkit仅在显式设置LOONGKIT_NUMA_AFFINITY_ALLOW_ASYMMETRIC=1时才会启用NUMA亲和性设置,此时亲和性策略支持下列配置项:
-
LOONGKIT_NUMA_AFFINITY_TRAIN_ON_GPULESS:允许训练进程使用无 GPU 连接的NUMA节点; -
LOONGKIT_NUMA_AFFINITY_DATA_WORKER_ON_GPULESS:允许数据进程使用无 GPU 连接的NUMA节点; -
LOONGKIT_NUMA_AFFINITY_DATA_WORKER_GPULESS_ONLY:数据进程仅运行在无 GPU 连接的NUMA节点上。
例:假设硬件拓扑结构如下图所示,以 GPU 2 上的训练和数据进程为例,上述配置项的不同组合的效果见下表。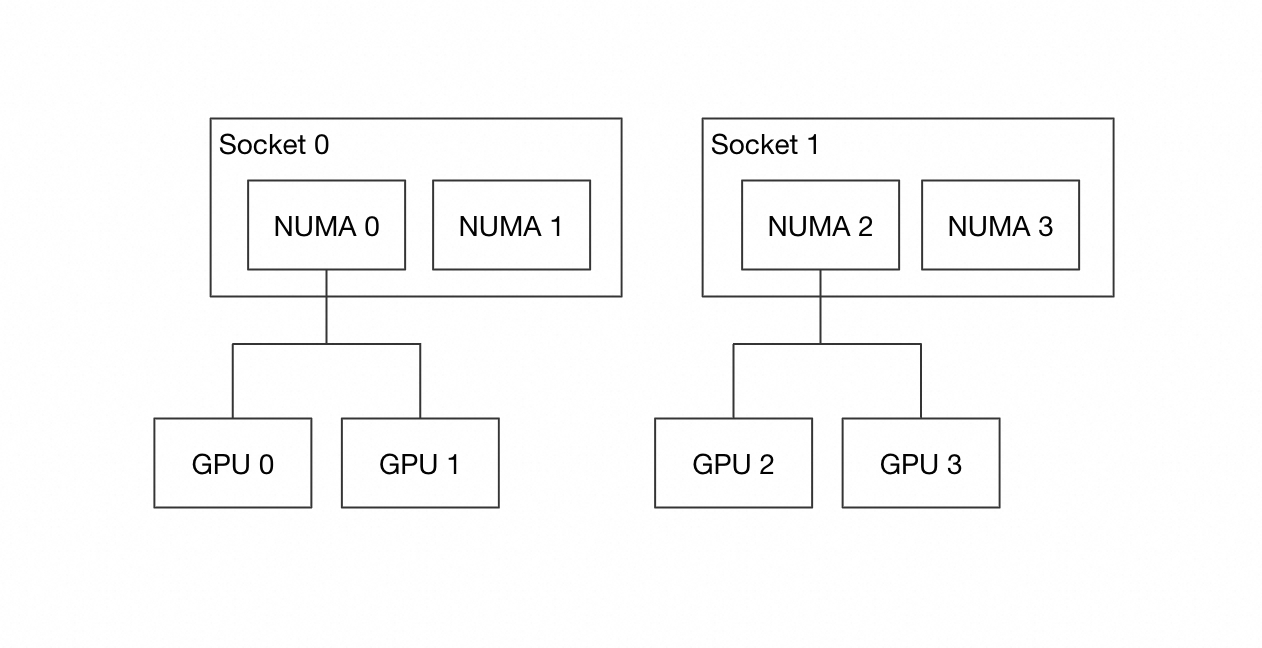
|
|
|
|
训练进程亲和性设置 |
数据进程亲和性设置 |
|
0 |
0 |
忽略 |
NUMA 2 |
NUMA 2 |
|
0 |
1 |
0 |
NUMA 2 |
NUMA 2,3 |
|
0 |
1 |
1 |
NUMA 2 |
NUMA 3 |
|
1 |
0 |
忽略 |
NUMA 2,3 |
NUMA 2 |
|
1 |
1 |
0 |
NUMA 2,3 |
NUMA 2,3 |
|
1 |
1 |
1 |
NUMA 2,3 |
NUMA 3 |
如需要确定特定硬件拓扑和训练负载上的最优配置,请提交工单联系进行联合评估。
训练任务配置检查
在启用LOONGKIT_CONFIG_GUARDS对训练任务的配置进行检查时,配置异常会以WARNING级别输出到Loongkit日志(日志路径可通过LOONGKIT_LOGDIR配置)。
Loongkit同时提供自动优化相关配置,降低训练任务过载风险的功能,可通过额外设置LOONGKIT_CONFIG_GUARDS_APPLY_FIX=1启用。
配置页面缓存限制
在启用LOONGKIT_PAGE_CACHE_LIMIT后,可以通过以下环境变量进一步配置页面缓存限制的行为:
|
环境变量 |
数据类型 |
默认值 |
说明 |
|
LOONGKIT_PAGE_CACHE_LIMIT_SIZE |
string |
50% |
当前容器的 Page Cache 使用量上限,支持以下三种格式:十进制数字(表示字节数,如 10737418240);带单位的字节数(如 8G、512M、1024K,大小写不敏感);百分比(如 50%,表示当前容器可用内存的比例)。 |
|
LOONGKIT_PAGE_CACHE_LIMIT_SYNC |
bool |
0 |
当前 memcg 的 Page Cache 使用量超出限制后,采用异步回收还是同步回收。 |
硬件感知的默认优化策略
Loongkit 针对不同硬件提供了相适应的默认优化策略,在启用对应优化等级时自动应用,具体策略如下表所示。
|
CPU 架构 |
优化策略 |
|
Intel |
|
|
AMD / 海光 |
|
|
GPU 架构 |
优化策略 |
|
NVIDIA GPU |
不启用 |
|
平头哥 PPU |
启用 |
启用特性小结
启用 Loongkit 后,在训练任务结束时会在标准输出和日志中输出启用特性小结,列出通过环境变量启用的特性,同时标注训练过程中的实际使用情况,其形式如下所示:
============================ Loongkit Feature Summary ============================
Enabled Features Configurations
----------------------------------------------------------------------------------
data_container * None
data_prefetch * None
allow_tf32 * None
fused_adam None
fused_adamw * None
numa_affinity {'allow_assymetric': False, 'allow_index': False}
==================================================================================其中:
-
第一列显示了所有通过环境变量启用的特性;
-
第二列显示了每项特性的高级配置参数;
-
星号(
*)表示该特性在训练期间实际生效。
常见问题
Loongkit自身的运行时开销时多少?
在不启用任何特性的情况下,Loongkit 自身的加载时间(除导入 PyTorch 的时间以外)不超过50ms,系统内存占用不超过10MB。
优化特性的运行时开销参见优化特性说明。
如果不希望改变训练命令,是否有其它启用Loongkit的方式?
除了使用loongkit-run以外,还可以通过在训练代码的入口文件开头加入import loongkit.all的方式加载 Loongkit ,特性配置以import loongkit.all执行时为准,可以通过yaml或在该代码行之前调整os.environ字典的方式,修改 Loongkit 相关的环境变量。
ACS 环境配置 aiext-pro 源访问权限的步骤
在 ACS 产品中授权访问 aiext-pro 源
-
ACS(PPU实例)的 aiext-pro 访问是按照集群维度授权的,您可以在ACS产品控制台,通过“集群列表”找到需要使用PIP服务的集群,在面板中单击PIP免密授权。
-
请务必生成授权URL,并且新开浏览器页面进行后续的授权操作。
-
需要您记录ACS集群的Service Account名称,接续的配置步骤会引用该名称。
-
集群开通PIP免密授权之后,在这个集群中使用“DinD Pod”、“Buildah Pod”、“普通PPU Pod”都已经具备了访问 aiext-pro 的基本条件。可以根据您的具体使用场景选取并执行后续步骤。
在普通PPU容器内一次性安装PIP软件
-
改造创建 PPU Pod 的 YAML 文件,添加
spec.serviceAccountName字段。*** securityContext: privileged:true #添加前序步骤创建的ServiceAccount名称 serviceAccountName: pip-default volumes: *** -
在普通PPU容器内进行必要的环境设置,使用PIP服务。
# 1. 首先安装免密插件aiext-pypi-plugin pip install aiext-pypi-plugin -i http://mirrors.cloud.aliyuncs.com/aiext-pypi/aiext-pypi-plugin/simple --trusted-host mirrors.cloud.aliyuncs.com # 2. 然后就可以正常安装相关pip wheel包,比如: pip install loongkit --extra-index-url=https://aiext-pypi.mirrors.aliyuncs.com/aiext-pro/pg1/simple/