
全文检索
全文检索(Full Text Search)指数据库将自然语言文本转换为可被查询数据的能力。云原生数据仓库AnalyticDB PostgreSQL版使用PostgreSQL内核,提供完善的全文检索功能。本文介绍AnalyticDB PostgreSQL版如何实现“一站式全文检索”业务。
背景信息
随着数字时代的发展,数据的来源和生成方式越来越广泛,其中也包含大量的文本数据。人们通常选择数据库或数据仓库存储文本数据,但是将文本数据中有价值的信息提取出来并进行高效分析,往往需要涉及多个数据处理系统配合来实现,用户的使用门槛通常较高、维护成本较大。
通常在使用数据仓库进行文本数据的加工和分析时,离不开数据仓库的数据实时写入、全文检索及任务调度等能力。如何使用一套数仓系统完成上述所有功能,往往面临以下几个挑战:
数据仓库内核的全文检索功能不够全面。部分数据仓库在全文检索功能上的的缺失,导致用户需要对文本数据做大量开发后才能将数据导入数据仓库。
任务调度依赖数据仓库内核的SQL标准支持能力,以及强大的外部工具支持。
全文检索涉及大量的文本数据,而数据仓库在处理文本数据时性能往往不如数字类型的数据。
不具备灵活的配置变更能力等。
AnalyticDB PostgreSQL版同时具备完善的全文检索和数据加工能力,能够较好地解决上述问题。
概述
在数据库存储的文本中找到特定的查询词并将它们按照出现的次数排序,就是一种典型的全文检索应用。
大部分数据库都提供对文本查询的基本功能。例如,在查询中使用LIKE等表达式查找搜索文本,但这些方法在现代数据库业务中缺少以下能力:
数据库常用的表达式查询方法无法处理派生词等语法。例如,英文单词
satisfy和它的第三人称形式satisfies。如果使用satisfy作为关键词查询,查询结果可能遗漏satisfies,这不是全文检索所期望的结果。当然也可以使用表达式OR去同时匹配satisfy和satisfies,但是这样操作效率非常低且容易出错(某些单词存在大量的派生词)。无法对匹配结果进行有效地排序。当查询结果较多时,筛选结果将变得非常低效。
查询性能慢,无法建立有效的索引,导致查询需要遍历完整的文本数据。
AnalyticDB PostgreSQL版的一站式全文检索业务同时具备上述所有能力。下图展示了AnalyticDB PostgreSQL版全文检索业务的流程。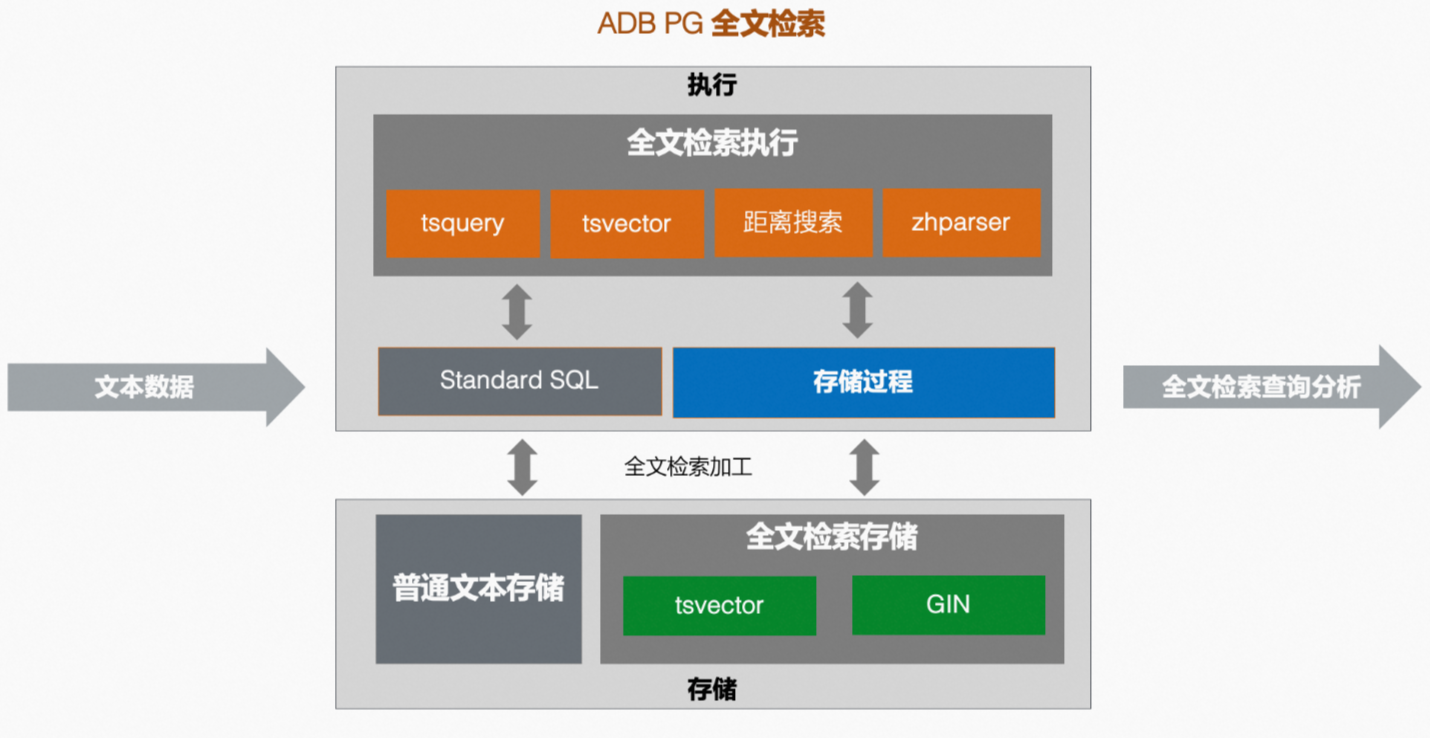
全文检索基本功能
AnalyticDB PostgreSQL版的全文检索功能,通过文本的预计算提供快速的查询性能。其中预计算主要包含以下几步:
将文本解析为符号。通过符号将文本词语分类为不同的类型,例如数字、形容词、副词等,不同类型的符号可以做不同的操作处理。PostgreSQL内核使用默认的解析器(parser)进行符号解析,并提供自定义解析器能力用于解析不同语言文本。
将符号转换为词语。相比较符号,词语经过了归一化(normalized)操作,将单词的不同形式进行合并(如
satisfy和satisfies),使得全文检索功能可以根据语义高效检索。PostgreSQL内核使用词典(dictionaries)进行符号转换为词语的操作,同样提供了自定义词典功能。优化词语存储,高效查询。例如,PostgreSQL内核提供
tsvector(text search vector)数据类型,将文本解析转换为带有词语信息的有序数据,并通过tsquery(text search query)语法对此类数据进行查询,实现高效的全文检索。
tsvector
tsvector用于存放一系列去重(distinct)的词语和词语顺序、位置等信息,使用PostgreSQL提供的to_tsvector方法可以自动完成文本至tsvector的转换。以英文语句'a fat cat jumped on a mat and ate two fat rats'为例:
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats');
to_tsvector
---------------------------------------------------------------
'ate':9 'cat':3 'fat':2,11 'jump':4 'mat':7 'rat':12 'two':10
(1 row)从查询结果可以看到tsvector的结果包含了一系列的词语,并按照词语的顺序进行了排序。同时每个词语后跟随了其在语句中的位置信息,如fat':2,11表示fat在语句的第2和第11个位置。此外tsvector结果省略了连接词(and,on等),并对部分单词进行了归一化的处理(jumped过去式归一化为jump)。
tsvector将文本完成预计算和转换。
tsquery
tsquery用于存放查询tsvector的词语,PostgreSQL同样提供to_tsquery方法将文本转换为tsquery,结合tsvector及全文检索操作符,就可以完成全文检索查询。
tsquery支持@@(包含)操作符和Boolean操作符&( AND)、|(OR) 和!(NOT),可以方便地构建组合条件的检索查询。
例如,使用@@查找tsvector中是否包含tsquery的词语。
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat');
?column?
----------
t
(1 row)
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cats');
?column?
----------
t
(1 row)
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat | dog');
?column?
----------
t
(1 row)
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat & dog');
?column?
----------
f
(1 row)从查询结果可以看到,对词语cat的查询结果为t,即true表明查询匹配。同时,由于cats是cat的复数,语义上也满足匹配,因此对词语cats的查询结果也为t。
距离搜索
仅AnalyticDB PostgreSQL 7.0版实例支持距离搜索,AnalyticDB PostgreSQL 6.0版实例不支持距离搜索。
全文检索不仅可以查找文本中是否包含某个词,还可以在短语、词组的基础上做进一步分析。PostgreSQL的全文检索tsquery方法,支持短语搜索符<N>,其中N为整数,表示指定词语之间的距离。例如,想要查找文本是否存在cat后跟随jump的短语,则可以使用<1>操作符查找。
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<1>jump');
?column?
----------
t
(1 row)查找特定的词语组合,也可以用距离搜索方法实现。
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<2>mat');
?column?
----------
f
(1 row)
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<4>mat');
?column?
----------
t
(1 row)AnalyticDB PostgreSQL版在PostgreSQL全文检索功能基础上,结合社区能力对全文检索进行了深度开发,进一步支持了全文检索范围距离搜索符<N,M>,M和N为整数,即指定词语之间距离在N至M之间的范围内。例如查找文本中是否包含cat和mat间距离小于等于5的短语,则可以使用<1,5>查询。
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<1,5>mat');
?column?
----------
t
(1 row)中文分词:Zhparser插件
在部分数据库业务中,通常会存放大量中文文本信息,例如用户的评价表单、地址信息等。对中文文本的分析同样需要全文检索功能来实现。但对于中文,词语是最小语素单位,书写时并不像英语会在词之间用空格分开,这就导致如果使用PostgreSQL的默认全文检索引擎,难以得到符合中文语义的分词结果。例如,使用PostgreSQL tsvector默认方法分词中文语句,得到的结果明显无法满足分词需求:
postgres=# SELECT to_tsvector('你好,这是一条中文测试文本');
to_tsvector
-----------------------------------
'你好':1 '这是一条中文测试文本':2
(1 row)SCWS(Simple Chinese Word Segmentation,简易中文分词系统),是一套基于词频词典的开源中文分词引擎,它能将一整段的中文文本基本正确地切分成词。SCWS使用C语言开发,可以直接作为动态链接库接入应用程序,结合PostgreSQL的代码扩展能力,可以在PostgreSQL数据库中使用SCWS实现中文分词功能。
Zhparser插件是一个基于SCWS能力开发的PostgreSQL中文分词插件,在兼容PostgreSQL已有全文检索能力的基础上,提供丰富的功能配置选项,同时也提供用户自定义词典功能。
在AnalyticDB PostgreSQL版中,Zhparser插件已完成默认安装,您可以根据中文分词需求自定义配置Zhparser。例如,创建一个名为zh_cn的中文分词解析器并配置分词策略:
--- 创建分词解析器。
CREATE TEXT SEARCH CONFIGURATION zh_cn (PARSER = zhparser);
--- 添加名词(n)、动词(v)、形容词(a)、成语(i)、叹词(e)和习用语(l)、自定义(x)分词策略。
ALTER TEXT SEARCH CONFIGURATION zh_cn ADD MAPPING FOR n,v,a,i,e,l,x WITH simple; 完成基本配置后,您可以使用中文分词能力开发中文检索业务。示例如下:
postgres=# SELECT to_tsvector('zh_cn','你好,这是一条中文测试文本');
to_tsvector
----------------------------------------------
'中文':3 '你好':1 '文本':5 '测试':4 '这是':2
(1 row)同样,您也可以使用tsquery结合Zhparser进行文本搜索。示例如下:
postgres=# SELECT to_tsvector('zh_cn','你好,这是一条中文测试文本') @@ to_tsquery('zh_cn','中文<1,3>文本');
?column?
----------
t
(1 row)更多关于Zhparser插件的使用方法,请参见使用Zhparser支持中文分词。
自定义词库
Zhparser提供中文自定义词库功能,如果默认的词库满足不了分词的结果需求,可以更新自定义词库并实时优化查询结果。Zhparser的系统表zhparser.zhprs_custom_word是一个面向用户的自定义词典表,您只需要更新该系统表即可实现自定义词库。zhparser.zhprs_custom_word的表结构如下:
Table "zhparser.zhprs_custom_word"
Column | Type | Collation | Nullable | Default
--------+------------------+-----------+----------+-----------------------
word | text | | not null |
tf | double precision | | | '1'::double precision
idf | double precision | | | '1'::double precision
attr | character(1) | | | '@'::bpchar
Indexes:
"zhprs_custom_word_pkey" PRIMARY KEY, btree (word)
Check constraints:
"zhprs_custom_word_attr_check" CHECK (attr = '@'::bpchar OR attr = '!'::bpchar)其中word列为自定义词语。tf、idf列用于设置自定义词语权重,参见TF-IDF(term frequency–inverse document frequency,词频-逆文本频率指数)。attr列为自定义词语的分词、停止词属性。
在AnalyticDB PostgreSQL版中自定义词库是数据库级别的,存放于每个数据节点对应数据库的数据目录下。通过以下示例为您展示如何AnalyticDB PostgreSQL版中使用自定义词库功能。
示例一:将
你好,这是一条中文测试文本中测试和文本不拆分为两个词语,而是以测试文本作为一个单独的分词,只需要在zhparser.zhprs_custom_word系统表中插入对应分词,重载后即可生效。postgres=# INSERT INTO zhparser.zhprs_custom_word values('测试文本'); INSERT 0 1 postgres=# SELECT sync_zhprs_custom_word(); --加载自定义分词。 sync_zhprs_custom_word ------------------------ (1 row) postgres=# \q --重新建立连接。 postgres=# SELECT to_tsvector('zh_cn','你好,这是一条中文测试文本'); to_tsvector ----------------------------------------- '中文':3 '你好':1 '测试文本':4 '这是':2 (1 row)示例二:自定义词库也支持停止词功能。例如,当不希望将
你好,这是一条中文测试文本中这是单独作为一个分词时,同样可以在自定义词库中插入对应的词语和控制符停止特定分词。postgres=# INSERT INTO zhparser.zhprs_custom_word(word, attr) values('这是','!'); INSERT 0 1 postgres=# SELECT sync_zhprs_custom_word(); sync_zhprs_custom_word ------------------------ (1 row) postgres=# \q --重新建立连接。 postgres=# SELECT to_tsvector('zh_cn','你好,这是一条中文测试文本'); to_tsvector --------------------------------------- '中文':3 '你好':1 '是':2 '测试文本':4 (1 row)
全文检索索引
全文检索查询业务可能涉及到大量的文本数据,合理使用索引可以有效提升查询性能。倒排索引是一种存放了数据和位置关系的数据结构,在数据系统中通常被用于处理大量文本的检索问题。本文通过以下示例,展示倒排索引如何提升文本的检索性能。
现有一张数据表Document,存放了一系列的文本Text,同时每条文本都有一个对应的编号ID,该表的结构如下:
Document | |
ID | Text |
1 | 这是一条中文测试文本 |
2 | 中文分词插件的使用 |
3 | 数据库全文检索 |
4 | 基于中文的全文检索 |
当您想查找出所有包含中文词语的文本,在这个数据结构下需要逐条检索Text的全部内容。当数据量大时,查询代价将很大。而通过建立倒排索引可以解决此问题,其索引结构包含每条文本中的词语及词语对应出现的文本位置。一个可能的倒排索引数据结构如下:
Term | ID |
中文 | 1,2,4 |
全文 | 3,4 |
数据库 | 3 |
文本 | 1 |
... | ... |
通过这个数据结构,在查找所有包含中文文本时将非常简单,可根据索引信息直接定位文本ID,避免了大量的文本数据扫描。
在AnalyticDB PostgreSQL版中,提供GIN(Generalized Inverted Index,通用倒排索引)功能,可以有效提升tsvector类型的查询性能。
CREATE INDEX text_idx ON document USING GIN (to_tsvector('zh_cn',text));