
创建HNSW向量索引
在处理大型数据集或需要快速访问和检索数据的场景(数据库查询优化、机器学习和数据挖掘、图像和视频检索、空间数据查询等)中,创建向量索引是加速向量检索的有效方式,可以提高查询性能、加速数据分析和优化搜索任务,从而提高系统的效率和响应速度。
背景信息
云原生数据仓库AnalyticDB PostgreSQL版向量数据库中的FastANN向量检索引擎实现了主流的HNSW(Hierarchical Small World Graph)算法,它基于PostgreSQL中的段页式存储实现,并且在索引中只存储了指向表中向量列的指针,极大地减少了向量索引的存储空间。同时FastANN向量检索引擎也支持PQ(Product Quantization)量化功能,可以对高维向量进行降维。通过在索引中存储降维后的向量达到减少在向量插入和查询时的回表操作,从而提升了向量检索的性能。
语法
CREATE INDEX [INDEX_NAME]
ON [SCHEMA_NAME].[TABLE_NAME]
USING ANN(COLUMN_NAME)
WITH (DIM=<DIMENSION>,
DISTANCEMEASURE=<MEASURE>,
HNSW_M=<M>,
HNSW_EF_CONSTRUCTION=<EF_CONSTURCTION>,
PQ_ENABLE=<PQ_ENABLE>,
PQ_SEGMENTS=<PQ_SEGMENTS>,
PQ_CENTERS=<PQ_CENTERS>,
EXTERNAL_STORAGE=<EXTERNAL_STORAGE>);各字段说明:
INDEX_NAME:索引名。
SCHEMA_NAME:模式(命名空间)名。
TABLE_NAME:表名。
COLUMN_NAME:向量索引列名。
其他向量索引参数:
向量索引参数
是否必填
说明
默认值
取值范围
DIM
是
向量维度。该参数主要用于向量插入时的检查,当维度不匹配的时候,系统将提示相关错误信息。
0
[1, 8192]
DISTANCEMEASURE
否
支持的相似度距离度量算法:
L2:使用欧氏距离(平方)函数构建索引,通常适用于图片相似度检索场景。
计算公式:
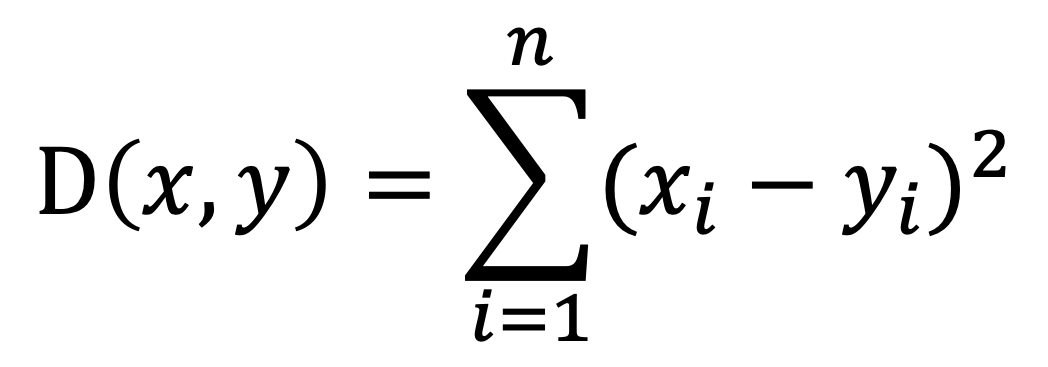
IP:使用反内积距离函数构建索引,通常适用于向量归一化之后替代余弦相似度。
计算公式:
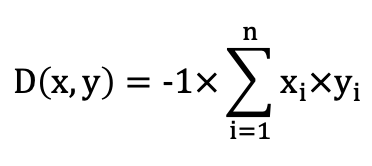
COSINE:使用余弦距离函数构建索引,通常适用于文本相似度检索场景。
计算公式:
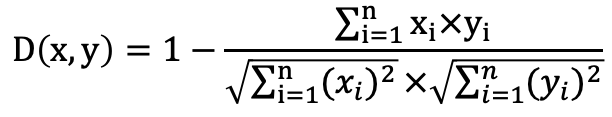
L2
(L2, IP, COSINE)
HNSW_M
否
HNSW算法中的最大邻居数。
32
[10, 1000]
HNSW_EF_CONSTRUCTION
否
HNSW算法构建索引时的候选集大小。
600
[40, 4000]
PQ_ENABLE
否
是否开启PQ向量降维的功能。PQ向量降维依赖于存量的向量样本数据进行训练,如果数据量小于50w时,不建议设置此参数。
0
[0, 1]
PQ_SEGMENTS
否
PQ_ENABLE为1时生效。用于指定PQ向量降维过程中使用的kmeans聚类算法中的分段数。
如果DIM能被8整除,则不需要填写,否则需要手动设置。
PQ_SEGMENTS必须大于0,且DIM必须能被PQ_SEGMENTS整除。
0
[1, 256]
PQ_CENTERS
否
PQ_ENABLE为1时生效。用于指定PQ向量降维过程中使用的kmeans聚类算法中的中心点数。
2048
[256, 8192]
EXTERNAL_STORAGE
否
是否使用mmap构建HNSW索引。
为0时,默认会采用段页式存储构建索引,这种模式可以使用PostgreSQL中的shared_buffer做缓存,支持删除和更新等操作。
为1时,该索引会采用mmap构建索引,从v6.6.2.3版本开始为索引支持了标记删除能力,可以支持数据表少量的删除和更新操作。
重要仅6.0版本支持参数external_storage。7.0版本暂不支持。
0
[0, 1]
示例
假设有一个文本知识库,将文章分割成chunk后,转换为embedding向量,最后存入数据库中,其中切割生成的chunks表包含以下字段:
字段 | 类型 | 说明 |
id | serial | 编号。 |
chunk | varchar(1024) | 文章切块后的文本chunk。 |
intime | timestamp | 文章的入库时间。 |
url | varchar(1024) | 文本chunk所属文章的链接。 |
feature | real[] | 文本chunk embedding向量。 |
创建存储向量的数据库表。
CREATE TABLE chunks ( id SERIAL PRIMARY KEY, chunk VARCHAR(1024), intime TIMESTAMP, url VARCHAR(1024), feature REAL[] ) DISTRIBUTED BY (id);将向量列的存储模式设置为PLAIN,以降低数据行扫描成本,获得更好的性能。
ALTER TABLE chunks ALTER COLUMN feature SET STORAGE PLAIN;对向量列建立向量索引。
-- 创建欧氏距离度量的向量索引。 CREATE INDEX idx_chunks_feature_l2 ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=l2, hnsw_m=64, pq_enable=1); -- 创建内积距离度量的向量索引。 CREATE INDEX idx_chunks_feature_ip ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=ip, hnsw_m=64, pq_enable=1); -- 创建余弦相似度度量的向量索引。 CREATE INDEX idx_chunks_feature_cosine ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);说明目前一个向量表可以创建多个向量列,每个向量列又可以创建多个向量索引,具体根据实际需要创建对应的向量索引,避免创建无效的索引。
向量查询的方式必须与向量索引的距离度量对应。例如,向量查询中的符号
<->对应欧氏距离度量的向量索引,<#>对应内积距离度量的向量索引,<=>对应余弦相似度度量的向量索引。如果没有对应的向量索引,则向量查询会退化为精确搜索(即暴力搜索)。请使用FastANN向量检索插件提供的
ANN访问方法,当实例开启向量检索引擎优化功能时,会自动在该实例中创建FastANN向量检索插件。若报错
You must specify an operator class or define a default operator class for the data type,表示该实例未开启向量检索引擎优化功能,请开启后重试,具体操作请参见开启或关闭向量检索引擎优化。
为常用的结构化列建立索引,提升融合查询速度。
CREATE INDEX ON chunks(intime);
向量索引的构建方式
向量索引主要分为两种构建方式:
流式构建。
即先创建一个空表,并在空表上建立向量索引,那么在进行向量数据导入时,就会进行流式实时的索引构建。此方式适用于实时向量检索场景,但是会导致数据导入速度过慢。
异步构建。
即在创建一个空表后,在不建向量索引的情况下,先将数据导入,然后再对存量的向量数据构建向量索引。此方式适用于大规模向量数据导入的场景。
云原生数据仓库AnalyticDB PostgreSQL版对于异步向量索引构建模式提供了并发构建能力,可以通过GUC参数fastann.build_parallel_processes来设置并行构建索引的并发度。
例如,在DMS上异步构建索引可以采用如下方式:
-- 假设在8C32GB的实例规格上进行操作。
-- 设置statement_timeout和idle_in_transaction_session_timeout都为0,确保不触发超时中断。
-- 设置fastann.build_parallel_processes为8,确保计算节点的CPU可以用满,这里需要根据segment的不同的规格需要设置不同的值,如4C16GB的规格设置为4,8C32GB的规格设置为8,16C64GB规格设置为16。
-- 在DMS上,参数设置必须和索引创建的SQL在同一行,否则不能生效。
SET statement_timeout = 0;SET idle_in_transaction_session_timeout = 0;SET fastann.build_parallel_processes = 8;CREATE INDEX ON chunks USING ann(feature)
WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);使用psql进行异步构建索引时可以采用如下方式:
-- 假定和上面DMS操作的实例一样,也是8C32GB的实例上进行操作。
-- 第一步:将以下内容放到文件create_index.sql中。
SET statement_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET fastann.build_parallel_processes = 8;
CREATE INDEX ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);
-- 第二步:执行如下命令开始并行构建索引。
psql -h gp-xxxx-master.gpdb.rds.aliyuncs.com -p 5432 -d dbname -U username -f create_index.sql如果当前实例有业务正在使用,不能将索引构建的并行进程数调到和实例规格一致,否则会影响正在运行的业务。
相关参考
函数作用 | 向量函数 | 返回值类型 | 含义 | 支持数据类型 |
计算 | l2_distance | double precision | 欧氏距离(开方值),用于衡量两个向量的大小,表示两个向量的距离。普遍应用于检索图片相似度。 重要 l2_distance在V6.3.10.17及以下版本中为欧氏距离(平方值),在V6.3.10.18及以上版本中为欧式距离(开方值)。 | smallint[]、float2[]、float4[]、real[] |
inner_product_distance | double precision | 内积距离,在向量归一化之后等于余弦相似度,通常用于在向量归一化之后替代余弦相似度。 计算公式: | smallint[]、float2[]、float4[]、real[] | |
cosine_similarity | double precision | 余弦相似度,取值范围:[-1, 1],通常用于衡量两个向量在方向上的相似性,而不关心两个向量的实际长度。 计算公式: | smallint[]、float2[]、float4[]、real[] | |
dp_distance | double precision | 点积距离,和内积距离完全一致。 计算公式: | smallint[]、float2[]、float4[]、real[] | |
hm_distance | integer | 汉明距离。 计算公式:位运算 | int[] | |
vector_add | smallint[], float2[] 或 float4[] | 计算两个向量数组的加法。 | smallint[]、float2[]、float4[]、real[] | |
vector_sub | smallint[], float2[] 或 float4[] | 计算两个向量数组的减法。 | smallint[]、float2[]、float4[]、real[] | |
vector_mul | smallint[], float2[] 或 float4[] | 计算两个向量数组的乘法。 | smallint[]、float2[]、float4[]、real[] | |
vector_div | smallint[], float2[] 或 float4[] | 计算两个向量数组的除法。 | smallint[]、float2[]、float4[]、real[] | |
vector_sum | int 或 double precision | 计算一个向量数组中所有元素的累加值。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_min | int 或 double precision | 统计一个向量数组中所有元素的最小值。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_max | int 或 double precision | 统计一个向量数组中所有元素的最大值。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_avg | int 或 double precision | 计算一个向量数组中所有元素的平均值。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_norm | double precision | 计算一个向量数组的模长。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_angle | double precision | 计算两个向量数组的夹角。 | smallint[]、float2[]、float4[]、real[] | |
排序 | l2_squared_distance | double precision | 欧氏距离(平方值),由于比欧氏距离(开方值)少了开方的计算,因此主要用于对欧氏距离(开方值)的排序逻辑,以减少计算量。 计算公式: | smallint[]、float2[]、float4[]、real[] |
negative_inner_product_distance | double precision | 反内积距离,为内积距离取反后的结果,主要用于对内积距离的排序逻辑,以保证排序结果按内积距离从大到小排序。 计算公式: | smallint[]、float2[]、float4[]、real[] | |
cosine_distance | double precision | 余弦距离,取值范围:[0, 2],主要用于对余弦相似度的排序逻辑,以保证排序结果按余弦相似度从大到小排序。 计算公式: | smallint[]、 float2[]、float4[]、real[] |
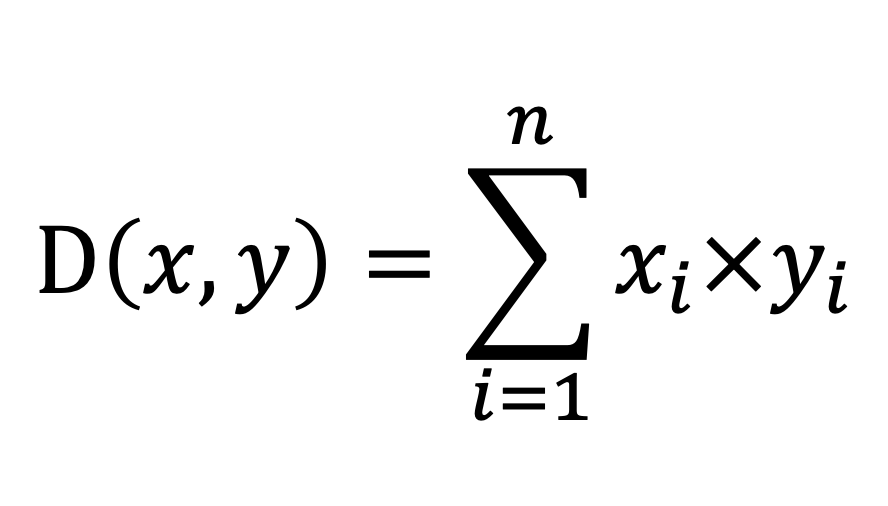
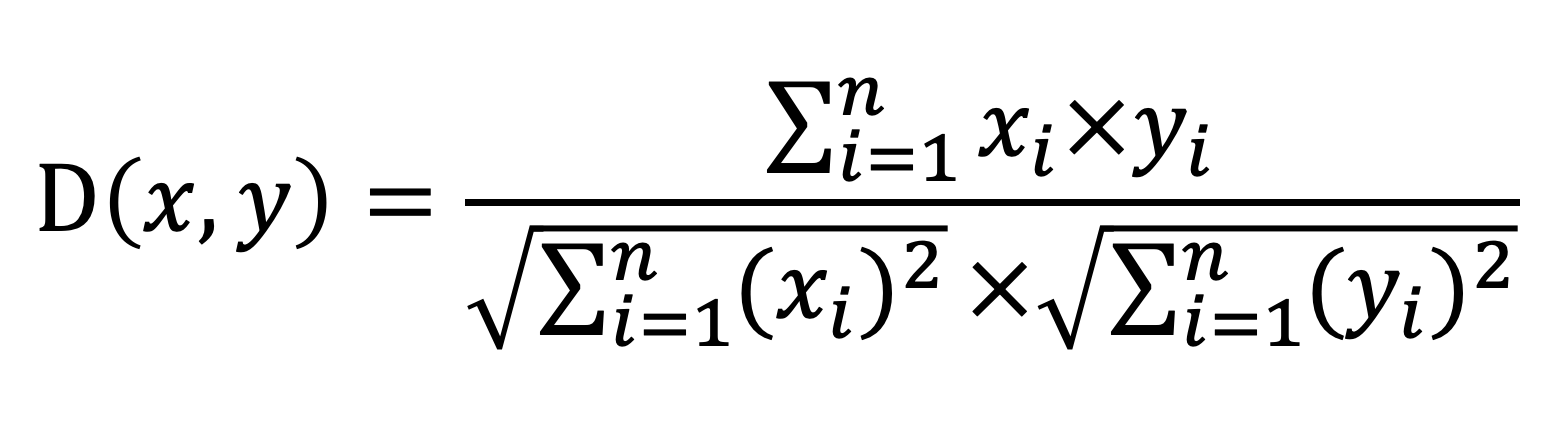
vector_add、vector_sub、vector_mul、vector_div、vector_sum、vector_min、vector_max、vector_avg、vector_norm和vector_angle向量函数仅v6.6.1.0及以上版本支持。如何查看实例版本,请参见查看内核小版本。
向量函数的使用示例:
-- 欧氏距离
SELECT l2_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 内积距离
SELECT inner_product_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 余弦相似度
SELECT cosine_similarity(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 点积距离
SELECT dp_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 汉明距离
SELECT hm_distance(array[1,0,1,0]::int[], array[0,1,0,1]::int[]);
-- 向量数组加法
SELECT vector_add(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 向量数组减法
SELECT vector_sub(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 向量数组乘法
SELECT vector_mul(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 向量数组除法
SELECT vector_div(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 向量数组累加值
SELECT vector_sum(array[1,1,1,1]::real[]);
-- 向量数组最小值
SELECT vector_min(array[1,1,1,1]::real[]);
-- 向量数组最大值
SELECT vector_max(array[1,1,1,1]::real[]);
-- 向量数组平均值
SELECT vector_avg(array[1,1,1,1]::real[]);
-- 向量数组模长
SELECT vector_norm(array[1,1,1,1]::real[]);
-- 两个向量的夹角
SELECT vector_angle(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);