
跨实例查询
云原生数据仓库 AnalyticDB PostgreSQL 版通过外部数据包装器FDW(foreign-data wrapper)帮助您轻松快速实现对同一账号中的不同实例进行联合查询,在保证数据实时性的同时,有效减少数据冗余。
功能介绍
目前,很多公司或组织同时运行了多个实例,分别用于各种业务和应用。在特殊情况下,需要跨这些实例进行查询,例如跨业务部门的联合分析需求。传统跨实例查询数据会采用如下方式:
在不同的实例中存储相同的数据副本,但可能会导致业务混乱以及数据冗余。
将数据放在一份共享存储中,例如存储在OSS上,但无法保证数据的实时性。
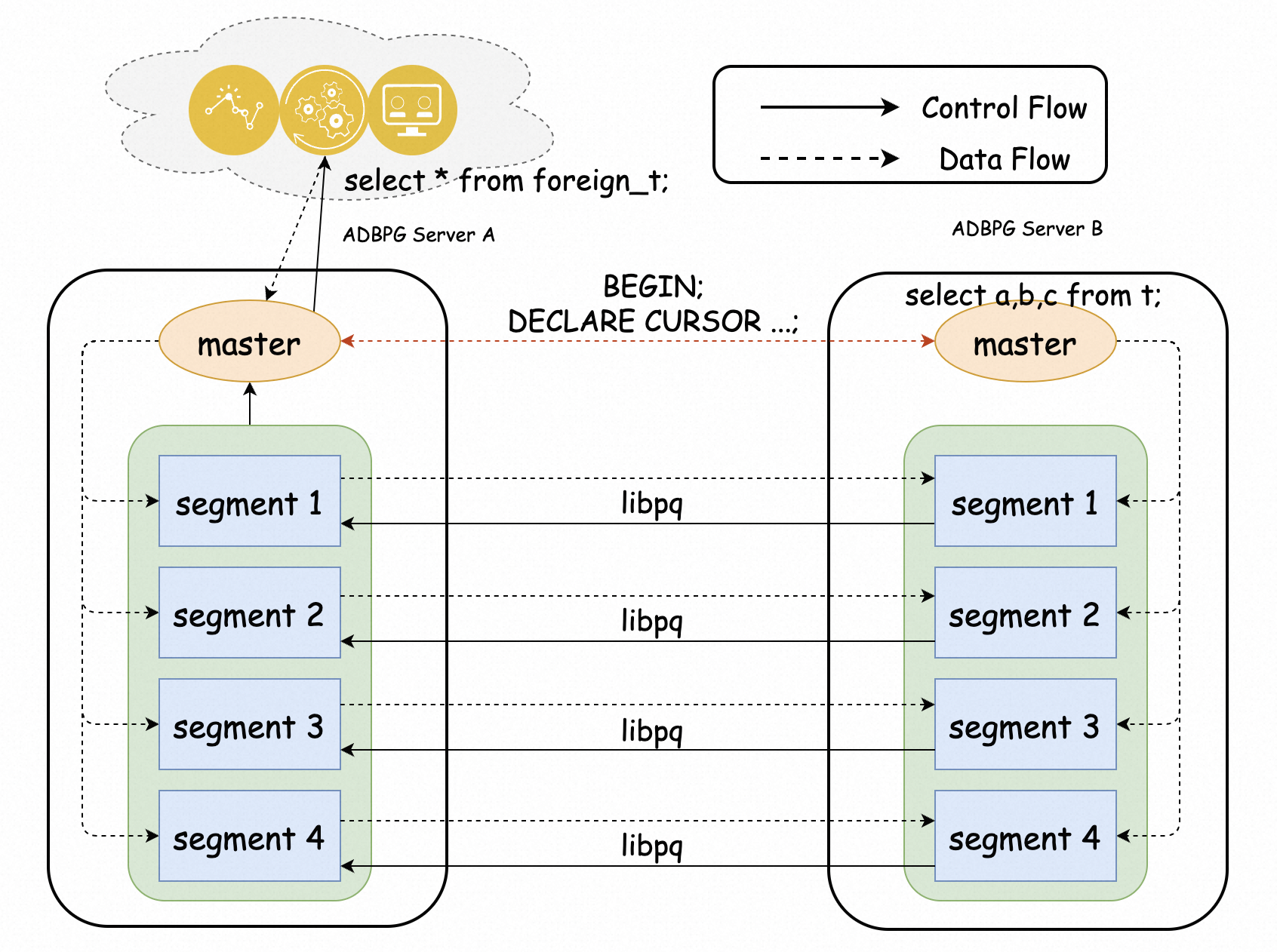
为解决上述问题,阿里云团队基于AnalyticDB PostgreSQL版的MPP架构,设计并实现了基于计算节点互联互通的FDW,充分利用计算节点的性能优势,实现数据在实例之间并行访问,提高数据访问效率的效果。性能相较于原生PostgreSQL的postgres_fdw有数倍的提升。
注意事项
源实例和目标实例需要属于同一个阿里云账号,且位于同一个地域,同一个VPC下。
若访问的源实例为Serverless模式实例,当源实例处于扩缩容状态时,扩缩容期间数据不可访问。
高速跨实例查询仅支持以下数据库内核版本:
存储弹性模式7.0版:V7.0.1.x及以上版本。
存储弹性模式6.0版:V6.3.11.2及以上版本。
Serverless模式:V1.0.6.x以及上版本。
由于AnalyticDB PostgreSQL 7.0版实例的密码验证方式发生变化,AnalyticDB PostgreSQL 6.0版实例和Serverless实例访问AnalyticDB PostgreSQL 7.0版实例需要提交工单联系技术处理。
FDW外表仅支持SELECT和INSERT操作,不支持UPDATE和DELETE操作。
仅存储弹性模式7.0版本支持JOIN下推和AGG下推功能。
仅存储弹性模式7.0版本的ORCA优化器支持对FDW外表生成执行计划,存储弹性模式6.0版本和Serverless模式的ORCA优化器无法处理外表,会使用原生优化器生成执行计划。
操作步骤
以下内容将为同一账号下的实例A和实例B(两个实例位于同一地域、同一可用区下)开通跨实例查询。开通后,您可以在实例A的db01库访问实例B的db02库中的表,并利用计算节点之间高速互联的特性,方便地和本地表进行联合查询。
使用psql连接实例,操作步骤,请参见客户端连接。
分别在实例A和实例B上创建数据库。
在实例A上创建db01库,并切换至db01库。
CREATE DATABASE db01; \c db01在实例B上创建db02库,并切换至db02库。
CREATE DATABASE db02; \c db02在实例A的db01库和实例B的db02库创建跨库查询插件greenplum_fdw和gp_parallel_retrieve_cursor。具体操作,请参见安装、升级与卸载插件。
获取实例A的内网IP地址,并IP地址添加到实例B的白名单中。如何设置白名单,请参见设置白名单。
在实例A上执行以下SQL获取内网IP地址。
SELECT dbid, address FROM gp_segment_configuration;在实例B的db02库准备测试数据。
CREATE SCHEMA s01; CREATE TABLE s01.t1(a int, b int, c text); CREATE TABLE s01.t2(a int, b int, c text); CREATE TABLE s01.t3(a int, b int, c text); INSERT INTO s01.t1 VALUES(generate_series(1,10),generate_series(11,20),'t1'); INSERT INTO s01.t2 VALUES(generate_series(11,20),generate_series(11,20),'t2'); INSERT INTO s01.t3 VALUES(generate_series(21,30),generate_series(11,20),'t3')在实例A的db01库中创建SERVER和USER MAPPING。
创建SERVER。
CREATE SERVER remote_adbpg FOREIGN DATA WRAPPER greenplum_fdw OPTIONS (host 'gp-xxxxxxxx-master.gpdb.zhangbei.rds.aliyuncs.com', port '5432', dbname 'db02');参数说明。
参数
说明
host
实例B的内网地址。
您可以登录云原生数据仓库AnalyticDB PostgreSQL版控制台,在实例B基本信息页面的数据库连接信息区域,获取内网地址。
port
实例B内网地址的端口号,默认为
5432。dbname
源库的数据库名称,此处示例为
db02。创建USER MAPPING,更多关于USER MAPPING的介绍,请参见CREATE USER MAPPING。
CREATE USER MAPPING FOR PUBLIC SERVER remote_adbpg OPTIONS (user 'report', password '******');参数说明。
参数
说明
user
实例B的数据库账号。
该账号需要拥有db02库的读权限(如需执行INSERT操作,则还需要写权限),如何创建账号,请参见创建数据库账号。
password
以上账号的密码。
在实例A的db01库实现跨实例查询。
实现跨实例查询有如下两种方式:
为源表创建外表。
CREATE SCHEMA s01; CREATE FOREIGN TABLE s01.t1(a int, b int) server remote_adbpg options(schema_name 's01', table_name 't1');上述方式的优缺点如下:
优点:可以灵活定制外表的DDL。例如db02库中t1有三个字段a,b,c,但目标库只需要a,b两个字段,因此可以在创建外表的时候指定字段。
缺点:需要知道每一个表的DDL,一次性导入多个外表较为繁琐。
导入源库下Schema中的所有表。
CREATE SCHEMA s01; IMPORT FOREIGN SCHEMA s01 LIMIT TO (t1, t2, t3) FROM SERVER remote_adbpg INTO s01;上述方式的优缺点如下:
优点:可以快速导入外表,而且不需要知道每一个表的DDL。
缺点:不够灵活,每个表的名称和源库一致,字段也一致。
更多介绍,请参见IMPORT FOREIGN SCHEMA。
在实例A的db01库查询实例B的db02数据。
SELECT * FROM s01.t1;返回示例如下。
a | b | c ----+----+---- 2 | 12 | t1 3 | 13 | t1 4 | 14 | t1 7 | 17 | t1 8 | 18 | t1 1 | 11 | t1 5 | 15 | t1 6 | 16 | t1 9 | 19 | t1 10 | 20 | t1 (10 rows)
性能测试
以下内容为跨实例查询的TPC-H性能测试,测试数据量为1 TB,并分别在数据库本地和目标端数据库中执行查询。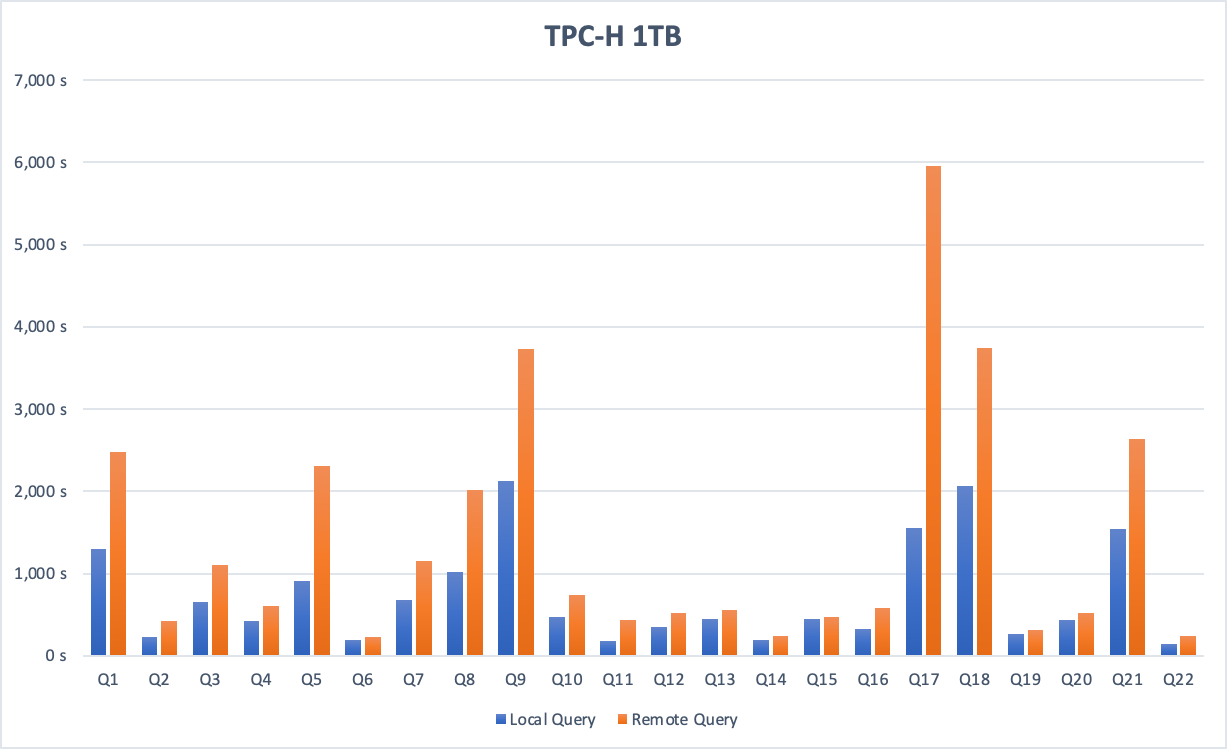
大数据场景(例如TPC-H 1 TB数据)下,跨实例查询数据性能约为本地查询数据性能的50%。
跨实例查询数据需要跨网络传输数据,为了减少网络IO,请尽量增加外表的WHERE过滤条件。
相关文档
AnalyticDB PostgreSQL版也支持跨库查询,详情请参见跨库查询。