
基于AnalyticDB Spark快速构建开放湖仓分析
本文介绍如何通过云原生数据仓库 AnalyticDB MySQL 版Spark和OSS构建、开放湖仓,并为您演示部署资源、数据准备、数据导入、交互式分析以及任务调度的完整流程。
准备工作
部署资源
本教程将以OSS、MongoDB、RDS SQL Server和Azure Blob Storage四种数据源为例,详细介绍数据导入的流程。如果您仅希望体验某个特定资源的完整流程,您只需部署该资源即可,MongoDB、RDS SQL Server和Azure Blob Storage数据导入时,需要依赖相关Jar包,且Jar包需上传至OSS,因此还需部署OSS资源。
AnalyticDB for MySQL
AnalyticDB for MySQL集群的产品系列为企业版、基础版或湖仓版。
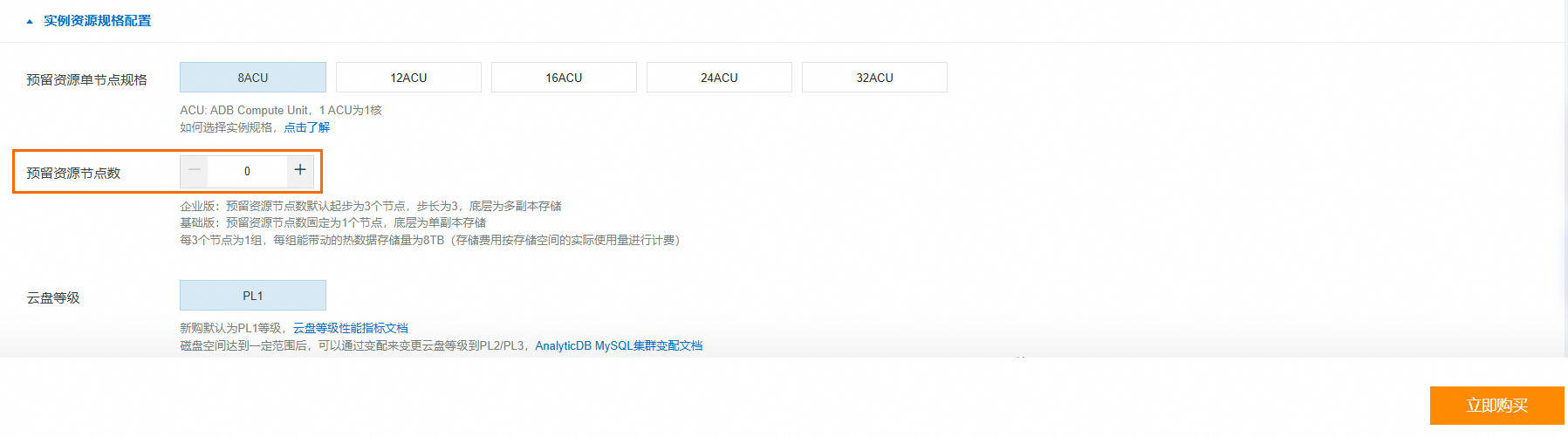
若您没有符合上述条件的集群,可以登录云原生数据仓库AnalyticDB MySQL控制台创建企业版或基础版集群。本教程仅涉及读取外表数据,因此创建集群时可将预留资源节点设置为0(如下图)。具体操作,请参见创建集群。
创建数据库账号。
如果是通过阿里云账号访问,只需创建高权限账号。
如果是通过RAM用户访问,需要创建高权限账号和普通账号、授予普通账号相应的库表权限并将RAM用户绑定到普通账号上。

创建Job型资源组和Spark引擎Interactive型资源组。

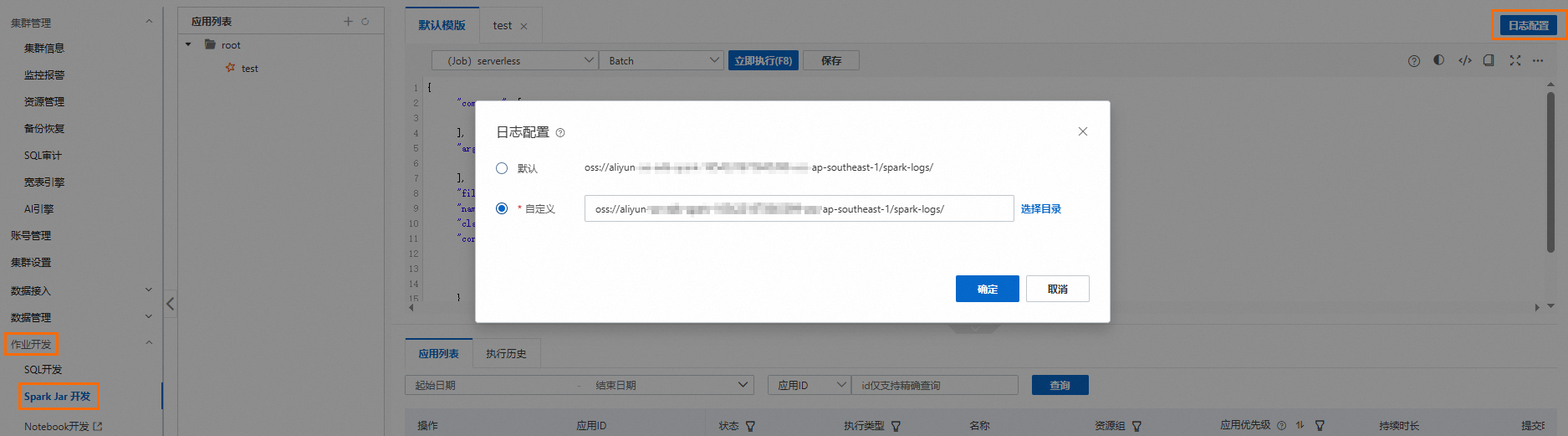
已配置Spark应用的日志存储地址。
登录云原生数据仓库AnalyticDB MySQL控制台,在页面,单击日志配置,选择默认路径或自定义存储路径。自定义存储路径时不能将日志保存在OSS的根目录下,请确保该路径中至少包含一层文件夹。
如果您需要使用RAM用户登录控制台进行Spark作业开发,需要完成为RAM用户授权。
使用Job型资源组或Spark Interactive型资源组,创建名为
test_db的数据库,并指定OSS路径,该数据库下的所有表的数据存储在该路径下。CREATE DATABASE IF NOT exists test_db COMMENT 'demo database for lakehouse' LOCATION 'oss://testBucketName/test';
OSS
MongoDB(可选)
创建MongoDB实例,且MongoDB实例与AnalyticDB for MySQL集群所属同一交换机。
将交换机IP添加到MongoDB实例的白名单中。
在云数据库MongoDB控制台的基本信息页面查看交换机ID。登录专有网络管理控制台,查看目标交换机的IP。
RDS SQL Server(可选)
创建RDS SQL Server实例,且RDS SQL Server实例与AnalyticDB for MySQL集群所属同一交换机。
将交换机IP添加到RDS SQL Server实例的白名单中。
在RDS SQL Server控制台的基本信息页面查看交换机ID。登录专有网络管理控制台,查看目标交换机的IP。
Azure Blob Storage(可选)
生成示例数据
OSS和Azure Blob Storage示例数据
使用如下代码批量生成1万条数据,数据格式为Parquet。数据生成后,并将其分别存储在OSS存储空间或者Azure Blob Storage容器中。
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
from faker import Faker
# 初始化Faker用于生成随机数据
fake = Faker()
# 生成100,000行数据
def generate_data(num_rows=100000):
data = {
'id': np.arange(1, num_rows + 1),
'name': [fake.name() for _ in range(num_rows)],
'age': [np.random.randint(18, 80) for _ in range(num_rows)]
}
return pd.DataFrame(data)
# 生成DataFrame
df = generate_data()
# 显式定义PyArrow Schema,限制整数长度
schema = pa.schema([
('id', pa.int32()), # 将id列限制为int32
('name', pa.string()),
('age', pa.int32()) # 将age列限制为int32
])
# 转换Pandas DataFrame为PyArrow Table,并应用显式Schema
table = pa.Table.from_pandas(df, schema=schema)
# 写入Parquet文件,指定Snappy压缩
output_file = "test_tbl.parquet"
pq.write_table(table, output_file, compression='snappy')
print(f"Parquet 文件已成功写入:{output_file}")
print(f"已生成 {output_file},共 {len(df)} 行数据,使用 Snappy 压缩。")MongoDB示例数据
该示例为某个电子银行交易场景的样例数据生成脚本,可以动态模拟交易并将数据写入MongoDB实例。
连接MongoDB实例,创建名为
test的数据库,并在该数据库中创建名为TransactionRecord的集合。使用如下代码在
TransactionRecord的集合中随机生成测试数据。from pymongo import MongoClient from datetime import datetime, timedelta import uuid import random import string import urllib.parse from faker import Faker fake = Faker() # Connect to MongoDB instance and create database/collection def connect_mongodb(uri,db_name,collection_name): try: # Connect to local MongoDB instance client = MongoClient(uri) # Create/Select database and collection db = client[db_name] # Check if collection exists and handle accordingly if collection_name not in db.list_collection_names(): # Collection doesn't exist, create it db.create_collection(collection_name) # Get the collection collection = db[collection_name] return client, db, collection except Exception as e: print(f"Connection failed: {e}") return None, None, None # Generate the username def generate_chinese_name(): surnames = ["李", "王", "张", "刘", "陈", "杨", "黄", "赵", "周", "吴", "徐", "孙", "马", "朱"] names = ["伟", "芳", "娜", "秀英", "敏", "静", "丽", "强", "磊", "军", "洋", "勇", "艳", "杰", "娟", "涛", "明", "超", "秀兰", "霞"] return random.choice(surnames) + random.choice(names) # Generate th bank account name def generate_bank_account(): return ''.join(random.choice(string.digits) for _ in range(16)) # 生成随机的交易数据 def insert_transaction(collection, count=1): transaction_ids = [] # 定义可能的值列表 financial_institutions = ["中国银行", "工商银行", "建设银行", "农业银行", "招商银行", "交通银行"] main_channels = ["APP", "Web", "ATM", "Branch", "Phone"] sub_channels = ["Bank Transfer", "Third-party Payment", "Cash", "Check", "Direct Debit"] operation_types = ["Deposit", "Withdrawal", "Transfer", "Payment", "Loan"] digital_wallet_types = ["Alipay", "WeChat Pay", "UnionPay", "Apple Pay", "Samsung Pay", "None"] source_operations = ["User ID", "System Auto", "Admin", "API"] offer_categories = ["Cash Back", "Bonus", "Discount", "Loan", "Investment"] item_types = ["Deposit", "Investment", "Loan", "Insurance", "Fund"] prefixes = ["TX", "PAY", "DEP", "WD", "TR"] for _ in range(count): # 生成姓名 local_name = generate_chinese_name() english_first_name = fake.first_name() english_last_name = fake.last_name() # 生成交易金额和余额变化 transaction_value = round(random.uniform(100, 10000), 2) pre_balance = round(random.uniform(1000, 100000), 2) post_balance = round(pre_balance + transaction_value, 2) # 生成信用额度变化 pre_credit = round(random.uniform(10000, 50000), 2) post_credit = round(pre_credit, 2) # 通常交易不会改变信用额度 # 生成交易明细金额 item1_value = round(transaction_value * 0.5, 2) item2_value = round(transaction_value * 0.3, 2) item3_value = round(transaction_value * 0.2, 2) # 生成钱包余额 wallet_item1 = round(random.uniform(1000, 5000), 2) wallet_item2 = round(random.uniform(1000, 5000), 2) wallet_item3 = round(random.uniform(1000, 5000), 2) # 生成未结算余额 unresolved_item1 = round(random.uniform(0, 1000), 2) unresolved_item2 = round(random.uniform(0, 1000), 2) unresolved_item3 = round(random.uniform(0, 1000), 2) # 生成唯一标识符 record_id = str(uuid.uuid4()) timestamp_creation = datetime.now() # 构建完整的交易记录 transaction_doc = { "record_id": record_id, "identifier_prefix": random.choice(prefixes), "user_id": f"user_{random.randint(10000, 99999)}", "transaction_value": transaction_value, "incentive_value": round(transaction_value * random.uniform(0.01, 0.2), 2), "financial_institution_name": random.choice(financial_institutions), "user_bank_account_number": generate_bank_account(), "account_reference": f"REF-{random.randint(100000, 999999)}", "account_group": random.randint(1, 5), "main_channel": random.choice(main_channels), "sub_channel": random.choice(sub_channels), "operation_type": random.choice(operation_types), "digital_wallet_type": random.choice(digital_wallet_types), "source_of_operation": random.choice(source_operations), "reference_id": f"ORD-{random.randint(100000, 999999)}", "pre_transaction_balance": pre_balance, "post_transaction_balance": post_balance, "pre_credit_limit": pre_credit, "post_credit_limit": post_credit, "product_reference": f"PROD-{random.randint(1000, 9999)}", "local_first_name": local_name[1:], "local_last_name": local_name[0], "english_first_name": english_first_name, "english_last_name": english_last_name, "campaign_id": f"CAM-{random.randint(1000, 9999)}", "offer_id": f"OFFER-{random.randint(10000, 99999)}", "offer_title": f"{random.choice(['Special', 'Premium', 'Standard', 'VIP'])} Offer", "offer_category": random.choice(offer_categories), "withdrawal_limit": round(random.uniform(5000, 20000), 2), "is_initial_transaction": random.random() < 0.1, # 10%概率是初始交易 "has_withdrawal_restrictions": random.random() < 0.2, # 20%概率有提款限制 "bonus_flag": random.random() < 0.3, # 30%概率是奖励交易 "transaction_note": fake.sentence(), "timestamp_creation": timestamp_creation, "timestamp_expiration": timestamp_creation + timedelta(days=random.randint(30, 365)), "recovery_data": str(uuid.uuid4()), "transaction_breakdown": { "item_1": item1_value, "item_2": item2_value, "item_3": item3_value, "max_operation_count": random.randint(5, 20), "max_operation_value": round(transaction_value * 2, 2), "item_1_type": random.choice(item_types), "item_2_type": random.choice(item_types) }, "virtual_wallet_balance": { "item_1": wallet_item1, "item_2": wallet_item2, "item_3": wallet_item3 }, "unresolved_balance": { "item_1": unresolved_item1, "item_2": unresolved_item2, "item_3": unresolved_item3 } } # 插入文档到集合 result = collection.insert_one(transaction_doc) print(f"已插入文档,ID: {record_id}") transaction_ids.append(record_id) return transaction_ids[0] if count == 1 else transaction_ids # Update document with partial field modifications def update_transaction(collection, doc_id): # 首先查询原始文档,获取交易金额以计算新的值 original_doc = collection.find_one({"record_id": doc_id}) if not original_doc: print("找不到要更新的文档") return # 生成随机的更新数据 # 更新交易分解 original_value = original_doc.get("transaction_value", 1000.0) new_item1_value = round(original_value * random.uniform(0.4, 0.6), 2) new_item2_value = round(original_value * random.uniform(0.2, 0.4), 2) new_item3_value = round(original_value - new_item1_value - new_item2_value, 2) # 更新钱包余额 new_wallet_item1 = round(random.uniform(2000, 8000), 2) new_wallet_item2 = round(random.uniform(1500, 6000), 2) new_wallet_item3 = round(random.uniform(1000, 5000), 2) # 更新未解决余额 new_unresolved_item1 = round(random.uniform(0, 500), 2) new_unresolved_item2 = round(random.uniform(0, 400), 2) new_unresolved_item3 = round(random.uniform(0, 300), 2) # 随机选择一些其他字段进行更新 random_fields_update = {} possible_updates = [ ("incentive_value", round(original_value * random.uniform(0.05, 0.25), 2)), ("withdrawal_limit", round(random.uniform(6000, 25000), 2)), ("transaction_note", fake.sentence()), ("has_withdrawal_restrictions", not original_doc.get("has_withdrawal_restrictions", False)), ("source_of_operation", random.choice(["User ID", "System Auto", "Admin", "API"])), ("bonus_flag", not original_doc.get("bonus_flag", False)), ] # 随机选择2-4个字段进行更新 for field, value in random.sample(possible_updates, random.randint(2, 4)): random_fields_update[field] = value # 构建更新数据 update_data = { "$set": { "transaction_breakdown": { "item_1": new_item1_value, "item_2": new_item2_value, "item_3": new_item3_value, "max_operation_count": random.randint(5, 20), "max_operation_value": round(original_value * 2, 2), "item_1_type": original_doc.get("transaction_breakdown", {}).get("item_1_type", "Deposit"), "item_2_type": original_doc.get("transaction_breakdown", {}).get("item_2_type", "Investment") }, "is_initial_transaction": False, "virtual_wallet_balance": { "item_1": new_wallet_item1, "item_2": new_wallet_item2, "item_3": new_wallet_item3 }, "unresolved_balance": { "item_1": new_unresolved_item1, "item_2": new_unresolved_item2, "item_3": new_unresolved_item3 }, "timestamp_update": datetime.now() } } for field, value in random_fields_update.items(): update_data["$set"][field] = value result = collection.update_one( {"record_id": doc_id}, update_data ) print(f"已修改 {result.modified_count} 条文档") def delete_transaction(collection, doc_id): result = collection.delete_one({"record_id": doc_id}) print(f"Deleted {result.deleted_count} document") def find_transaction(collection, doc_id): doc = collection.find_one({"record_id": doc_id}) if doc: print("Found document:") print(doc) else: print("Document not found") if __name__ == "__main__": # MongoDB实例的数据库名称 username = "root" # MongoDB实例数据库名称的密码 password = "****" encoded_username = urllib.parse.quote_plus(username) encoded_password = urllib.parse.quote_plus(password) # MongoDB实例的连接地址 uri = f'mongodb://root:****@dds-bp1dd******-pub.mongodb.rds.aliyuncs.com:3717' # MongoDB实例的数据库名称 db_name = 'test' # MongoDB实例的集合名称 collection_name = 'transaction_record' client, db, collection = connect_mongodb(uri,db_name,collection_name) if collection is None: exit(1) try: # Insert multiple documents transaction_count = 10 # 可以修改为需要的数量 print(f"准备插入{transaction_count}条交易记录...") transaction_ids = insert_transaction(collection, transaction_count) # 随机选择一个交易ID进行更新和查询 random_transaction_id = random.choice(transaction_ids) if isinstance(transaction_ids, list) else transaction_ids if random.uniform(0, 1) < 0.3: # 提高更新概率 # Update document print("更新一个交易记录...") update_transaction(collection, random_transaction_id) # Verify update print("查询更新后的交易记录...") find_transaction(collection, random_transaction_id) if random.uniform(0, 1) < 0.1: # 保持删除概率较低 print("删除一个交易记录...") delete_transaction(collection, random_transaction_id) # Verify deletion find_transaction(collection, random_transaction_id) finally: # Close connection if 'client' in locals(): client.close()
RDS SQL Server示例数据
连接RDS SQL Server实例,创建名为
demo的数据库。CREATE DATABASE demo;在
demo数据库中创建名为rdstest的表。CREATE TABLE rdstest ( id INT PRIMARY KEY, name VARCHAR(100), age INT );插入测试数据。
INSERT INTO rdstest (id, name, age) VALUES (1, 'Alice', 25), (2, 'Bob', 30), (3, 'Charlie', 28), (4, 'Diana', 22), (5, 'Edward', 35), (6, 'Fiona', 40), (7, 'George', 27), (8, 'Hannah', 33), (9, 'Ian', 29), (10, 'Judy', 31), (11, 'Kevin', 26), (12, 'Linda', 34), (13, 'Mark', 23), (14, 'Nina', 21), (15, 'Oliver', 32), (16, 'Paula', 36), (17, 'Quentin', 38), (18, 'Rachel', 24), (19, 'Steve', 39), (20, 'Tina', 28);
数据导入和ETL
本示例分别以OSS、MongoDB、Azure Blob Storage、RDS SQL Server和AnalyticDB for MySQL内表数据源为例,介绍导入数据的流程。
OSS数据:通过Spark SQL批量导入。
MongoDB数据:通过PySpark流式导入。
Azure Blob Storage数据、RDS SQL Server数据和AnalyticDB for MySQL内表数据:通过PySpark批量导入。
通过Spark SQL批量导入数据
在本教程中,默认使用DELTALAKE作为表格式。如果您希望创建格式为Iceberg的OSS表,可以在建表时指定类型为ICEBERG(即USING iceberg)。
进入SQL开发。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在左侧导航栏,单击。
在SQLConsole窗口,选择Spark引擎和Job型资源组。
在
test_db库中创建外表test_src_tbl。CREATE TABLE IF NOT exists test_db.test_src_tbl( id int, name string, age int ) USING parquet -- 数据准备章节中示例数据所在的OSS路径 LOCATION 'oss://testBucketName/test/test_tbl/' TBLPROPERTIES ('parquet.compress'='SNAPPY');查询
test_src_tbl表数据,验证数据是否成功读取。SELECT * FROM test_db.test_src_tbl LIMIT 10;创建Delta表,并将OSS表数据导入至Delta表中。
创建Delta表。
CREATE TABLE IF NOT EXISTS test_db.test_target_tbl ( id INT, name STRING, age INT ) USING DELTA;将外表数据导入至Delta表。
INSERT INTO test_db.test_target_tbl SELECT * FROM test_db.test_src_tbl;
查询数据是否导入成功。
SELECT * FROM test_db.test_target_tbl LIMIT 10;查看目标表
demo.test_target_tbl数据存储的OSS路径。DESCRIBE DETAIL test_db.test_target_tbl;ETL加工数据。
若您想要修改执行作业所使用的ACU时,可以在SQL语句前添加对应参数修改单个作业所使用的ACU,或在创建资源组时通过键值对形式添加对应参数修改该资源组内所有作业使用的ACU。
通过SET命令修改单个作业所使用的ACU
定义执行作业的Spark Executor节点个数为32,规格为medium(2核8 GB,使用ACU数量为2),此时该作业默认会被分配64ACU。
SET spark.executor.instances=32; SET spark.executor.resourceSpec = medium; -- 创建ETL目标表 CREATE TABLE IF NOT EXISTS test_db.etl_result_tbl ( id INT, name STRING, age INT, is_adult INT ) USING DELTA; -- 步骤 2: ETL(清洗+转换) INSERT INTO test_db.etl_result_tbl SELECT id, name, age, CASE WHEN age >= 18 THEN 1 ELSE 0 END AS is_adult FROM test_db.test_target_tbl WHERE name IS NOT NULL;通过资源组修改全局作业所使用的ACU
定义执行作业的Spark Executor节点个数为32,规格为medium(2核8 GB,使用ACU数量为2),此时该作业默认会被分配64ACU。
修改Job型资源组,以下两种方法任选一种即可。
在文本框配置中,以键值对形式配置:
spark.executor.instances 32 spark.executor.resourceSpec medium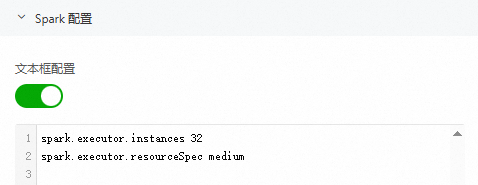
单击
 按钮,以prop-value形式配置:
按钮,以prop-value形式配置: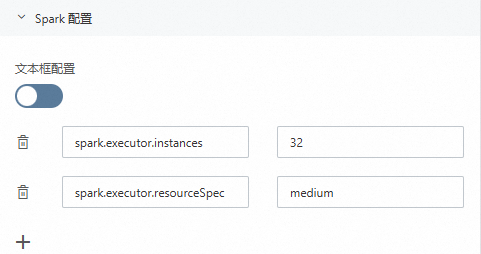
ETL加工数据。
-- 创建ETL目标表 CREATE TABLE IF NOT EXISTS test_db.etl_result_tbl ( id INT, name STRING, age INT, is_adult INT ) USING DELTA; -- ETL(清洗+转换) INSERT INTO test_db.etl_result_tbl SELECT id, name, age, CASE WHEN age >= 18 THEN 1 ELSE 0 END AS is_adult FROM test_db.test_target_tbl WHERE name IS NOT NULL;
通过PySpark流式导入数据
本章节基于DMS Notebook为您演示如何通过PySpark将MongoDB数据导入至AnalyticDB for MySQL并存储为Delta表。
下载AnalyticDB for MySQL Spark访问MongoDB依赖的Jar包,并将其上传至OSS中。
下载链接mongo-spark-connector_2.12-10.4.0.jar、mongodb-driver-sync-5.1.4.jar、bson-5.1.4.jar、bson-record-codec-5.1.4.jar和mongodb-driver-core-5.1.4.jar。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
单击。确保已完成如下准备工作,然后单击进入DMS Notebook。

创建Notebook文件,并导入数据。
创建Spark集群。
单击
 按钮,进入资源管理页面,单击计算集群。
按钮,进入资源管理页面,单击计算集群。选择Spark集群页签,单击创建集群,并配置如下参数:
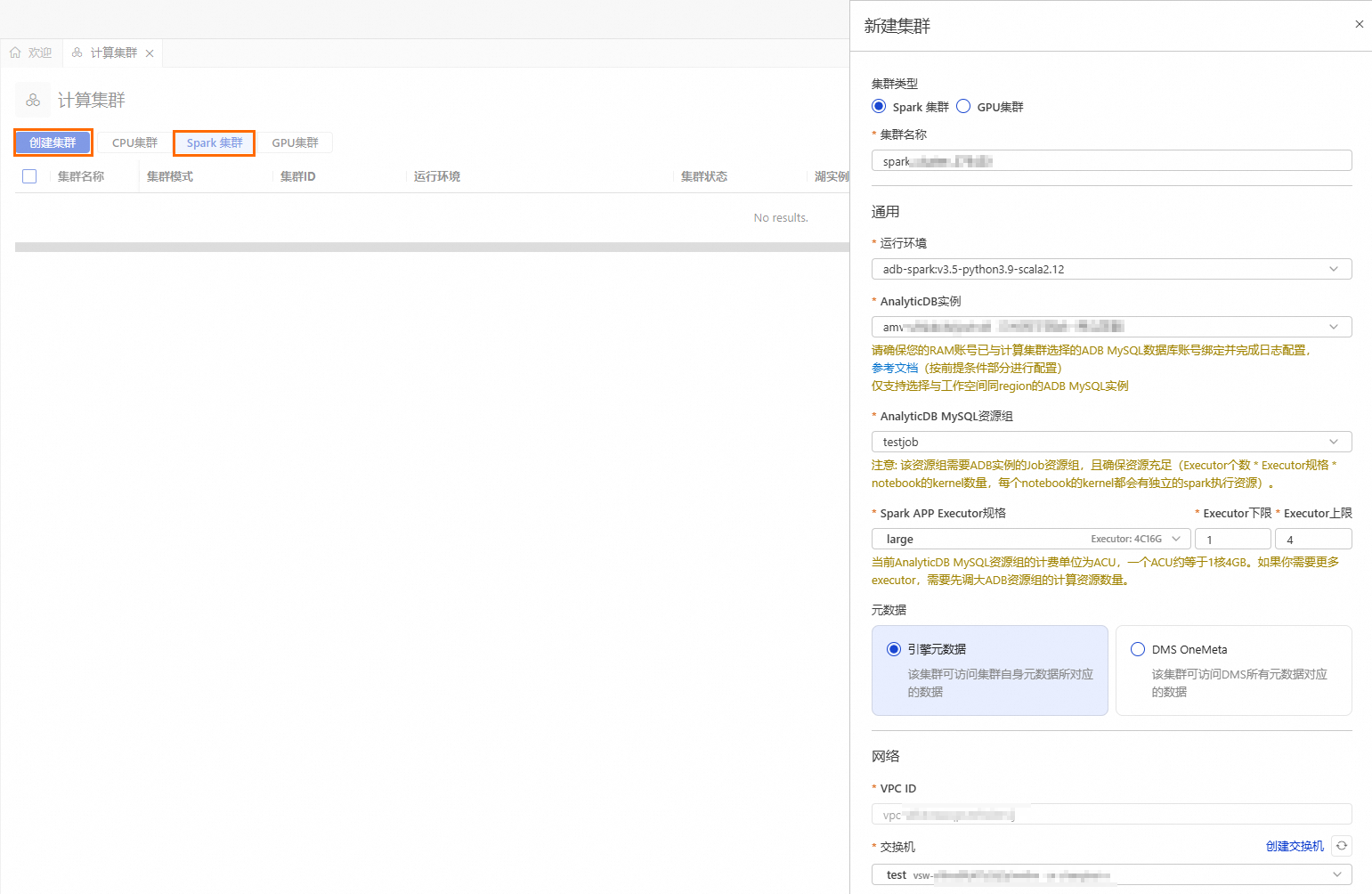
参数
说明
示例值
集群名称
输入便于识别使用场景的集群名称。
spark_test
运行环境
目前支持选择如下镜像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB实例
在下拉框中选择AnalyticDB for MySQL集群。
amv-uf6i4bi88****
AnalyticDB MySQL资源组
在下拉框中选择Job型资源组。
testjob
Spark APP Executor规格
选择Spark Executor的资源规格。
不同型号的取值对应不同的规格,详情请参见Spark应用配置参数说明的型号列。
large
交换机
选择当前VPC下的交换机。
vsw-uf6n9ipl6qgo****
依赖的Jars
Jar包的OSS存储路径。此处需要填写步骤1下载的Jar包所属的OSS路径。
如果您想在业务代码中指定JAR包的OSS地址,此处可以不填写。
oss://testBucketName/adb/mongo-spark-connector_2.12-10.4.0.jar oss://testBucketName/adb/mongodb-driver-sync-5.1.4.jar oss://testBucketName/adb/bson-5.1.4.jar oss://testBucketName/adb/bson-record-codec-5.1.4.jar oss://testBucketName/adb/mongodb-driver-core-5.1.4.jar
创建并启动Notebook会话时,首次启动需要等待大约5分钟。

参数
说明
示例值
所属集群
选择步骤b创建的Spark集群。
spark_test
会话名称
您可自定义会话名称。
new_session
镜像
选择镜像规格。
Spark3.5_Scala2.12_Python3.9:1.0.9
规格
kernel的资源规格。
4C16G
配置
profile资源。
您可编辑profile的名称、资源释放时长、数据存储位置、Pypi包管理和环境变量信息。
重要资源释放时长:当资源空闲时间超过设置的时长,则会自动释放。资源释放时长设置为0,表示资源永久不会自动释放。
deault_profile
新建Notebook文件。
单击
 按钮,然后单击。
按钮,然后单击。
将Cell的语言类型设置为Python,执行以下代码,将MongoDB实例中,
TransactionRecord集合的历史数据批量导入到AnalyticDB for MySQLtest库的mongo_load_table_test表中。from pyspark.sql import SparkSession spark = SparkSession.builder.appName("AppLoadMongoDB") \ # 填写步骤1下载的MongoDB依赖Jar包所存储的OSS路径 .config("spark.jars", "oss://testBucketName/mongodb/bson-5.1.4.jar,oss://testBucketName/mongodb/bson-record-codec-5.1.4.jar,oss://testBucketName/mongodb/mongo-spark-connector_2.12-10.4.0.jar,oss://testBucketName/mongodb/mongodb-driver-core-5.1.4.jar,oss://testBucketName/mongodb/mongodb-driver-sync-5.1.4.jar") \ .config("spark.driver.memory", "2g") \ .getOrCreate() # MongoDB实例的数据库名称 mongo_database_name = "test" # MongoDB实例的集合名称 mongo_collection_name = "TransactionRecord" # MongoDB实例的连接地址 url = "mongodb://root:******@dds-uf667b******.mongodb.rds.aliyuncs.com:3717" df = spark.read \ .format("mongodb") \ .option("spark.mongodb.connection.uri", url) \ .option("spark.mongodb.database", mongo_database_name) \ .option("spark.mongodb.collection", mongo_collection_name) \ .load() df.printSchema() df.show(truncate=False) df.write.format("delta").mode(saveMode="append").saveAsTable("test_db.mongo_load_table_test")将Cell的语言类型设置为Python,执行以下代码,将MongoDB实例中,
TransactionRecord集合的增量数据同步到AnalyticDB for MySQLtest库的mongo_load_table_test表中。from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType, BooleanType, TimestampType, ArrayType schema = StructType([ StructField("record_id", StringType(), True), StructField("identifier_prefix", StringType(), True), StructField("user_id", StringType(), True), StructField("transaction_value", DoubleType(), True), StructField("incentive_value", DoubleType(), True), StructField("financial_institution_name", StringType(), True), StructField("user_bank_account_number", StringType(), True), StructField("account_reference", StringType(), True), StructField("account_group", IntegerType(), True), StructField("main_channel", StringType(), True), StructField("sub_channel", StringType(), True), StructField("operation_type", StringType(), True), StructField("digital_wallet_type", StringType(), True), StructField("source_of_operation", StringType(), True), StructField("reference_id", StringType(), True), StructField("pre_transaction_balance", DoubleType(), True), StructField("post_transaction_balance", DoubleType(), True), StructField("pre_credit_limit", DoubleType(), True), StructField("post_credit_limit", DoubleType(), True), StructField("product_reference", StringType(), True), StructField("local_first_name", StringType(), True), StructField("local_last_name", StringType(), True), StructField("english_first_name", StringType(), True), StructField("english_last_name", StringType(), True), StructField("campaign_id", StringType(), True), StructField("offer_id", StringType(), True), StructField("offer_title", StringType(), True), StructField("offer_category", StringType(), True), StructField("withdrawal_limit", DoubleType(), True), StructField("is_initial_transaction", BooleanType(), True), StructField("has_withdrawal_restrictions", BooleanType(), True), StructField("bonus_flag", BooleanType(), True), StructField("transaction_note", StringType(), True), StructField("timestamp_creation", TimestampType(), True), StructField("timestamp_expiration", TimestampType(), True), StructField("recovery_data", StringType(), True), StructField("transaction_breakdown", StructType([ StructField("item_1", DoubleType(), True), StructField("item_2", DoubleType(), True), StructField("item_3", DoubleType(), True), StructField("max_operation_count", IntegerType(), True), StructField("max_operation_value", DoubleType(), True), StructField("item_1_type", StringType(), True), StructField("item_2_type", StringType(), True) ]), True), StructField("virtual_wallet_balance", StructType([ StructField("item_1", DoubleType(), True), StructField("item_2", DoubleType(), True), StructField("item_3", DoubleType(), True) ]), True), StructField("unresolved_balance", StructType([ StructField("item_1", DoubleType(), True), StructField("item_2", DoubleType(), True), StructField("item_3", DoubleType(), True) ]), True) ]) # MongoDB实例的数据库名称 mongo_database_name = "test" # MongoDB实例的集合 mongo_collection_name = "TransactionRecord!" # MongoDB实例的连接地址 uri = "mongodb://root:******@dds-uf667b******.mongodb.rds.aliyuncs.com:3717" df = (spark.readStream \ .format("mongodb") \ .option("database", mongo_database_name) \ .option("collection", mongo_collection_name) \ .option("spark.mongodb.connection.uri",uri)\ .option("change.stream.publish.full.document.only", "true")\ .schema(schema) .load()) display(df) checkpoint_oss_location = "oss://testBucketNam/mongodb_checkpoint_v1/" query = df.writeStream \ .trigger(availableNow=True) \ .format(source="delta") \ .outputMode("append") \ .option("checkpointLocation", checkpoint_oss_location) \ .option("mergeSchema", "true") \ .toTable("test_db.mongo_load_table_test") query.awaitTermination()将Cell的语言类型设置为SQL,执行以下代码,查看MongoDB实例数据是否成功写入
mongo_load_table_test表。DESCRIBE test_db.mongo_load_table_test; DESCRIBE HISTORY test_db.mongo_load_table_test;将Cell的语言类型设置为SQL,执行以下代码合并目标表中的小文件,并根据timestamp_creation列进行排序,以优化查询性能。
OPTIMIZE test_db.mongo_load_table_test ZORDER BY (timestamp_creation);
通过PySpark批量导入数据
本章节基于DMS Notebook为您演示如何通过PySpark将Azure Blob Storge数据、RDS SQL Server数据和AnalyticDB for MySQL仓表数据导入至AnalyticDB for MySQL并存储为Delta表。
Azure Blob Storage数据导入
下载AnalyticDB for MySQL Spark访问Azure Blob Storage依赖的Jar包,并将其上传至OSS中。
下载链接jetty-util-ajax-9.4.51.v20230217.jar、jetty-server-9.4.51.v20230217.jar、jetty-io-9.4.51.v20230217.jar、jetty-util-9.4.51.v20230217.jar、azure-storage-8.6.0.jar、hadoop-azure-3.3.0.jar和hadoop-azure-datalake-3.3.0.jar。
配置Spark公网环境。
公网NAT网关需要与AnalyticDB for MySQL实例为同一个地域。
- 重要
为保证成功读取并导入Azure Blob Storage数据,创建SNAT条目时指定的交换机需要跟后续创建Spark集群的交换机一致。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
单击。确保已完成如下准备工作,然后单击进入DMS Notebook。
创建Notebook文件,并导入数据。
创建Spark集群。
单击
按钮,进入资源管理页面,单击计算集群。选择Spark集群页签,单击创建集群,并配置如下参数:
参数
说明
示例值
集群名称
输入便于识别使用场景的集群名称。
spark_test
运行环境
目前支持选择如下镜像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB实例
在下拉框中选择AnalyticDB for MySQL集群。
amv-uf6i4bi88****
AnalyticDB MySQL资源组
在下拉框中选择Job型资源组。
testjob
Spark APP Executor规格
选择Spark Executor的资源规格。
不同型号的取值对应不同的规格,详情请参见Spark应用配置参数说明的型号列。
large
交换机
选择当前VPC下的交换机。
vsw-uf6n9ipl6qgo****
依赖的Jars
Jar包的OSS存储路径。此处需要填写步骤1下载的Jar包所属的OSS路径。
如果您想在业务代码中指定JAR包的OSS地址,此处可以不填写。
oss://testBucketName/jar_file/jetty-util-ajax-9.4.51.v20230217.jar, oss://testBucketName/jar_file/jetty-server-9.4.51.v20230217.jar, oss://testBucketName/jar_file/jetty-io-9.4.51.v20230217.jar, oss://testBucketName/jar_file/jetty-util-9.4.51.v20230217.jar, oss://testBucketName/jar_file/azure-storage-8.6.0.jar, oss://testBucketName/jar_file/hadoop-azure-3.3.0.jar, oss://testBucketName/jar_file/hadoop-azure-datalake-3.3.0.jar")
创建并启动Notebook会话时,首次启动需要等待大约5分钟。
参数
说明
示例值
所属集群
选择步骤b创建的Spark集群。
spark_test
会话名称
您可自定义会话名称。
new_session
镜像
选择镜像规格。
Spark3.5_Scala2.12_Python3.9:1.0.9
规格
kernel的资源规格。
4C16G
配置
profile资源。
您可编辑profile的名称、资源释放时长、数据存储位置、Pypi包管理和环境变量信息。
重要资源释放时长:当资源空闲时间超过设置的时长,则会自动释放。资源释放时长设置为0,表示资源永久不会自动释放。
deault_profile
新建Notebook文件。
单击
按钮,然后单击。将Cell的语言类型设置为Python,执行如下代码,加载python依赖。
!pip install azure-storage-blob>=12.14.0 !pip install azure-identity将Cell的语言类型设置为Python,执行如下代码,测试是否可以正常读取Azure Blob Storage中的数据。
from azure.storage.blob import BlobServiceClient import azure.storage.blob # Azure Blob Storage的账户名称 storage_account_name = 'storage****' # Azure Blob Storage账户的密钥 azure_account_key = 'NPNe9B6DmxQpmA****' # Azure Blob Storage的容器名称 container = 'azurename****' blob_service = BlobServiceClient( account_url=f"https://{storage_account_name}.blob.core.windows.net", credential=azure_account_key ) try: container_client = blob_service.get_container_client(container) if container_client.exists(): print(f"Azure Container {container} is accessible!") print(azure.storage.blob.__version__) blobs = container_client.list_blobs() #if azure.storage.blob.__version__ >= "12.14.0": # blobs = container_client.list_blobs(max_results=10) #else: # blobs = container_client.list_blobs() print("\nAzure Objects count: %s"%len(blobs)) else: print(f"Azure Container {container} access failed!") except Exception as e: print(f"Connection failed: {str(e)}")将Cell的语言类型设置为Python,执行如下代码,创建Spark会话。
from datetime import datetime from datetime import date from pyspark.sql import SparkSession # Azure Blob Storage的账户名称 storage_account_name = 'storage****' # Azure Blob Storage的容器名称 container = 'azurename****' # Azure Blob Storage账户的密钥 azure_account_key = 'NPNe9B6DmxQpmA****' spark = SparkSession.builder \ .appName("AzureBlobToOSS") \ .config("spark.jars", \ #步骤1下载的Azure Blob Storage依赖的Jar包所在的OSS路径 "oss://testBucketName/jar_file/jetty-util-ajax-9.4.51.v20230217.jar,\ oss://testBucketName/jar_file/jetty-server-9.4.51.v20230217.jar,\ oss://testBucketName/jar_file/jetty-io-9.4.51.v20230217.jar,\ oss://testBucketName/jar_file/jetty-util-9.4.51.v20230217.jar,\ oss://testBucketName/jar_file/azure-storage-8.6.0.jar,\ oss://testBucketName/jar_file/hadoop-azure-3.3.0.jar,\ oss://testBucketName/jar_file/hadoop-azure-datalake-3.3.0.jar")\ .config("spark.hadoop.fs.azure", "org.apache.hadoop.fs.azure.NativeAzureFileSystem") \ .config("spark.hadoop.fs.azure.account.key.%s.blob.core.windows.net"%storage_account_name, azure_account_key) \ .getOrCreate() print("Spark Session has been created successfully!")将Cell的语言类型设置为Python,执行如下代码,将Azure Blob Storage中的Parquet数导入到AnalyticDB for MySQL
test_db库的azure_load_table表中。from pyspark.sql import SparkSession from py4j.java_gateway import java_import import time from datetime import datetime # 请将test_tbl_2.parquet替换为Parquet示例数据实际存储路径 parquet_path = f"wasbs://{container}@{storage_account_name}.blob.core.windows.net/test_tbl_2.parquet" df = spark.read.parquet(parquet_path) # 将数据导入azure_load_table表 df.write.format("delta").mode("overwrite").saveAsTable('test_db.azure_load_table')在AnalyticDB for MySQL集群中查询数据是否导入成功。
SELECT * FROM test_db.azure_load_table LIMIT 10;
RDS SQL Server数据导入
下载AnalyticDB for MySQL Spark访问RDS SQL Server依赖的Jar包。
解压下载的驱动程序压缩包,将jars文件里后缀为jre8.jar的Jar包简单上传。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
单击。确保已完成如下准备工作,然后单击进入DMS Notebook。
创建Notebook文件,并导入数据。
创建Spark集群。
单击
按钮,进入资源管理页面,单击计算集群。选择Spark集群页签,单击创建集群,并配置如下参数:
参数
说明
示例值
集群名称
输入便于识别使用场景的集群名称。
spark_test
运行环境
目前支持选择如下镜像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB实例
在下拉框中选择AnalyticDB for MySQL集群。
amv-uf6i4bi88****
AnalyticDB MySQL资源组
在下拉框中选择Job型资源组。
testjob
Spark APP Executor规格
选择Spark Executor的资源规格。
不同型号的取值对应不同的规格,详情请参见Spark应用配置参数说明的型号列。
large
交换机
选择当前VPC下的交换机。
vsw-uf6n9ipl6qgo****
依赖的Jars
Jar包的OSS存储路径。此处需要填写步骤1下载的Jar包所属的OSS路径。
如果您想在业务代码中指定JAR包的OSS地址,此处可以不填写。
oss://testBucketName/jar_file/mssql-jdbc-12.8.1.jre8.jar
创建并启动Notebook会话时,首次启动需要等待大约5分钟。
参数
说明
示例值
所属集群
选择步骤b创建的Spark集群。
spark_test
会话名称
您可自定义会话名称。
new_session
镜像
选择镜像规格。
Spark3.5_Scala2.12_Python3.9:1.0.9
规格
kernel的资源规格。
4C16G
配置
profile资源。
您可编辑profile的名称、资源释放时长、数据存储位置、Pypi包管理和环境变量信息。
重要资源释放时长:当资源空闲时间超过设置的时长,则会自动释放。资源释放时长设置为0,表示资源永久不会自动释放。
deault_profile
新建Notebook文件。
单击
按钮,然后单击。将Cell的语言类型设置为Python,执行如下代码,读取RDS SQL Server数据。
from pyspark.sql import SparkSession # 初始化 SparkSession spark = SparkSession.builder.appName("AppLoadSQLServer") \ .config("spark.jars", "oss://testBucketName/sqlserver/mssql-jdbc-12.8.1.jre8.jar") \ # 步骤1下载的Jar所在的OSS路径 .config("spark.driver.memory", "2g") \ .getOrCreate() # RDS SQL Server数据库名称 database = "demo" # RDS SQL Server表名称 table = "rdstest" # RDS SQL Server连接地址 sqlserver_url = "jdbc:sqlserver://rm-uf68v****.sqlserver.rds.aliyuncs.com:1433" # RDS SQL Server数据库账号 user = 'user' # RDS SQL Server数据库账号的密码 password = 'pass****' df = spark.read \ .format("jdbc") \ .option("url", f"{sqlserver_url};databaseName={database};trustServerCertificate=true;encrypt=true;") \ .option("dbtable", table) \ .option("user", user) \ .option("password", password) \ .load() # 打印 Schema 和示例数据 df.printSchema() df.show(truncate=False) # 保存为 Delta表 df.write.format("delta").mode(saveMode="append").saveAsTable("test_db.rds_delta_test")
AnalyticDB for MySQL仓表数据导入
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
单击。确保已完成如下准备工作,然后单击进入DMS Notebook。
创建Notebook文件,并导入数据。
创建Spark集群。
单击
按钮,进入资源管理页面,单击计算集群。选择Spark集群页签,单击创建集群,并配置如下参数:
参数
说明
示例值
集群名称
输入便于识别使用场景的集群名称。
spark_test
运行环境
目前支持选择如下镜像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB实例
在下拉框中选择AnalyticDB for MySQL集群。
amv-uf6i4bi88****
AnalyticDB MySQL资源组
在下拉框中选择Job型资源组。
testjob
Spark APP Executor规格
选择Spark Executor的资源规格。
不同型号的取值对应不同的规格,详情请参见Spark应用配置参数说明的型号列。
large
交换机
选择当前VPC下的交换机。
vsw-uf6n9ipl6qgo****
依赖的Jars
Jar包的OSS存储路径。此处需要填写步骤1下载的Jar包所属的OSS路径。
如果您想在业务代码中指定JAR包的OSS地址,此处可以不填写。
oss://testBucketName/jar_file/mssql-jdbc-12.8.1.jre8.jar
创建并启动Notebook会话时,首次启动需要等待大约5分钟。
参数
说明
示例值
所属集群
选择步骤b创建的Spark集群。
spark_test
会话名称
您可自定义会话名称。
new_session
镜像
选择镜像规格。
Spark3.5_Scala2.12_Python3.9:1.0.9
规格
kernel的资源规格。
4C16G
配置
profile资源。
您可编辑profile的名称、资源释放时长、数据存储位置、Pypi包管理和环境变量信息。
重要资源释放时长:当资源空闲时间超过设置的时长,则会自动释放。资源释放时长设置为0,表示资源永久不会自动释放。
deault_profile
新建Notebook文件。
单击
按钮,然后单击。将Cell的语言类型设置为Python,执行如下代码,读取AnalyticDB for MySQL仓表数据。
from pyspark.sql import SparkSession # 初始化 SparkSession spark = SparkSession.builder.appName("AppLoadADBMSQL") \ .config("spark.driver.memory", "2g") \ .getOrCreate() # AnalyticDB for MySQL数据库名称 database = "demo" # AnalyticDB for MySQL表名称 table = "test" # AnalyticDB for MySQL连接地址 url = "jdbc:mysql://amv-uf6i4b****.ads.aliyuncs.com:3306" # AnalyticDB for MySQL数据库账号 user = 'user' # AnalyticDB for MySQL数据库账号的密码 password = 'pass****' # 批量读取 AnalyticDB for MySQL 数据 df = spark.read \ .format("jdbc") \ .option("url", f"{url}/{database}") \ .option("dbtable", table) \ .option("user", user) \ .option("password", password) \ .load() # 打印 Schema 和示例数据 df.printSchema() df.show(truncate=False) # 保存为 Delta表 df.write.format("delta").mode(saveMode="append").saveAsTable("test_db.adb_delta_test")
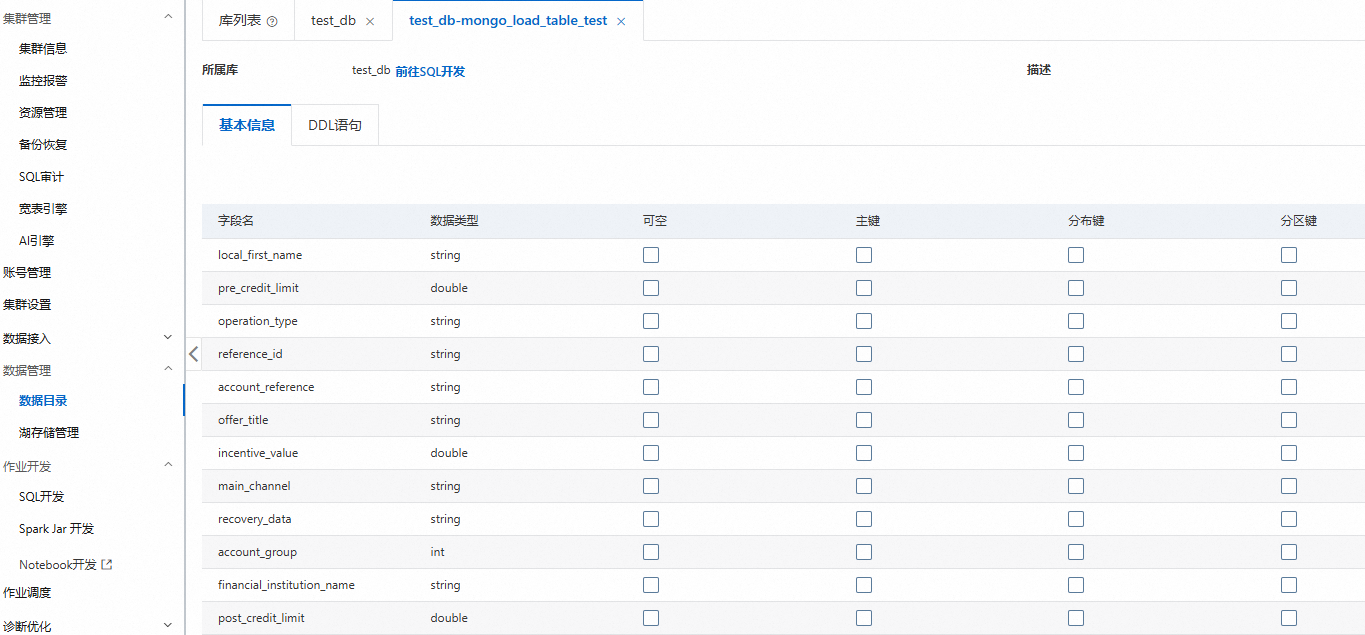
预览数据目录
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在左侧导航栏,单击。
单击目标数据库和表,查看表的详细信息,例如:表类型、表存储数据量、列名等。
交互式分析
如果您需要以交互式方式执行Spark SQL,并且对查询性能有要求,可以使用Spark Interactive型资源组作为执行查询的资源组。此外每个Spark Interactive型资源组默认都有本地缓存机制,当重复读取OSS数据时,可以提升查询性能。
通过控制台进行交互式查询
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在左侧导航栏,单击。
在SQLConsole窗口,选择Spark引擎和Interactive型资源组。
执行以下语句,进行交互式查询:
SELECT COUNT(*) FROM test_db.etl_result_tbl;
通过应用程序进行交互式查询
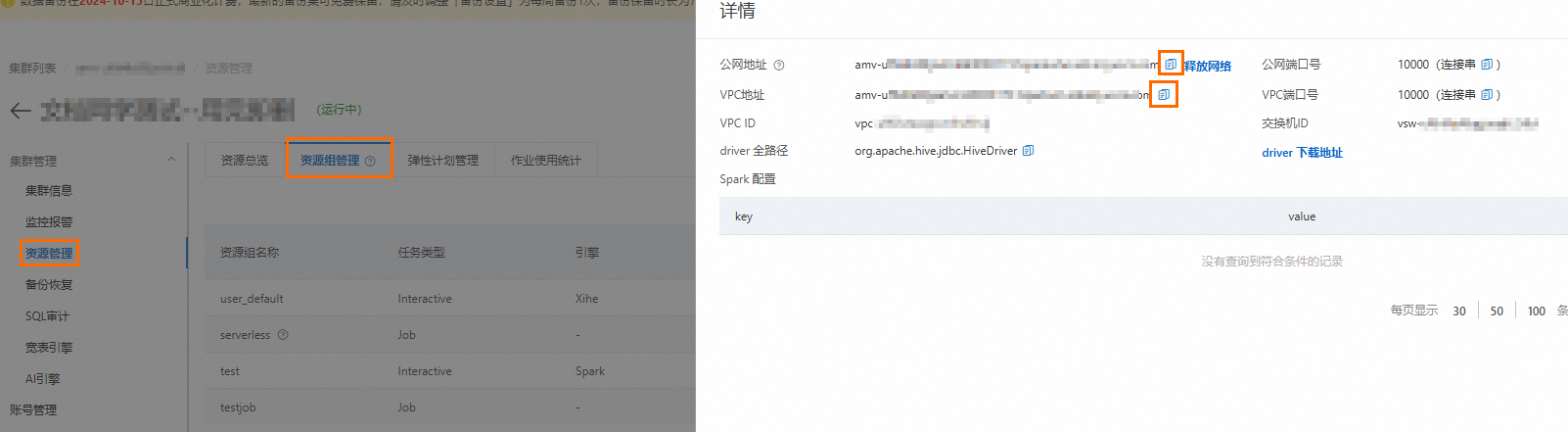
获取Spark Interactive型资源组的连接地址。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,在企业版、基础版或湖仓版页签下,单击目标集群ID。
在左侧导航栏,单击,单击资源组管理页签。
单击对应资源组操作列的详情,查看内网连接地址和公网连接地址。您可单击
 按钮,复制连接地址。
按钮,复制连接地址。以下两种情况,您需要单击公网地址后的申请网络,手动申请公网连接地址。
提交Spark SQL作业的客户端工具部署在本地或外部服务器。
提交Spark SQL作业的客户端工具部署在ECS上,且ECS与AnalyticDB for MySQL不属于同一VPC。
安装Python依赖。
Python版本为3.11及以上,使用如下命令安装依赖:
pip install pyhive[hive_pure_sasl]>=0.7.0Python版本为3.11以下,使用如下命令安装依赖:
pip install pyhive[hive]>=0.7.0
执行如下代码:
from pyhive import hive from TCLIService.ttypes import TOperationState cursor = hive.connect( # Spark Interactive型资源组连接地址 host='amv-uf6i4b****sparkwho.ads.aliyuncs.com', # Spark Interactive型资源组的端口号,固定为10000 port=10000, # AnalyticDB for MySQL的资源组名称和数据库账号 username='testjob/user', # AnalyticDB for MySQL数据库账号的密码 password='password****', auth='CUSTOM' ).cursor() # Spark SQL作业的业务代码 cursor.execute('select count(*) from test_db.etl_result_tbl;') status = cursor.poll().operationState while status in (TOperationState.INITIALIZED_STATE, TOperationState.RUNNING_STATE): logs = cursor.fetch_logs() for message in logs: print(message) # If needed, an asynchronous query can be cancelled at any time with: # cursor.cancel() status = cursor.poll().operationState print(cursor.fetchall())
调度Spark SQL作业
Airflow开源调度工具,可以实现各类工作负载的DAG编排与调度。如果您希望使用Airflow调度Spark SQL作业,可以参考调度Spark SQL作业文档通过Spark Airflow Operator、Spark-Submit命令行工具来调度Spark SQL任务。
DataWorks提供全链路大数据开发治理能力,且DataWorks数据开发(DataStudio)模块支持工作流可视化开发和托管调度运维,能够按照时间和依赖关系轻松实现任务的全面托管调度。如果您希望使用DataWorks调度Spark SQL作业,可以参考DataWorks调度Spark SQL作业文档通过AnalyticDB Spark SQL节点调度Spark SQL任务。
除上述工具以外,若您希望使用其他调度工具(如DMS、DolphinScheduler或者Azkaban),请参考Spark调度文档调度Spark SQL作业。