基于ADB Spark+DMS Airflow搭建湖仓工作流
本文主要介绍如何使用DMS托管的Airflow调度工具调度Notebook中运行的Spark任务。
方案架构
DMS Notebook作为Spark任务运行的容器,统一管理PySpark、SparkSQL、Python任务。
DMS Airflow作为调度器,将Notebook中的ipynb文件作为DAG定义中的一个Operator 节点。
AnalyticDB for MySQL作为Lakehouse,在提供Spark计算资源的同时,管理存储在OSS中的数据湖表(例如Delta Lake)。

准备工作
AnalyticDB for MySQL
AnalyticDB for MySQL集群的产品系列为企业版、基础版或湖仓版。
若您没有符合上述条件的集群,可以登录云原生数据仓库AnalyticDB MySQL控制台创建企业版或基础版集群。
已创建数据库账号。
如果是通过阿里云账号访问,只需创建高权限账号。
如果是通过RAM用户访问,需要创建高权限账号和普通账号并且将RAM用户绑定到普通账号上。
OSS
Notebook工作空间
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
单击。确保已完成如下准备工作,然后单击进入DMS Notebook。

创建Spark集群。
单击
 按钮,进入资源管理页面,单击计算集群。
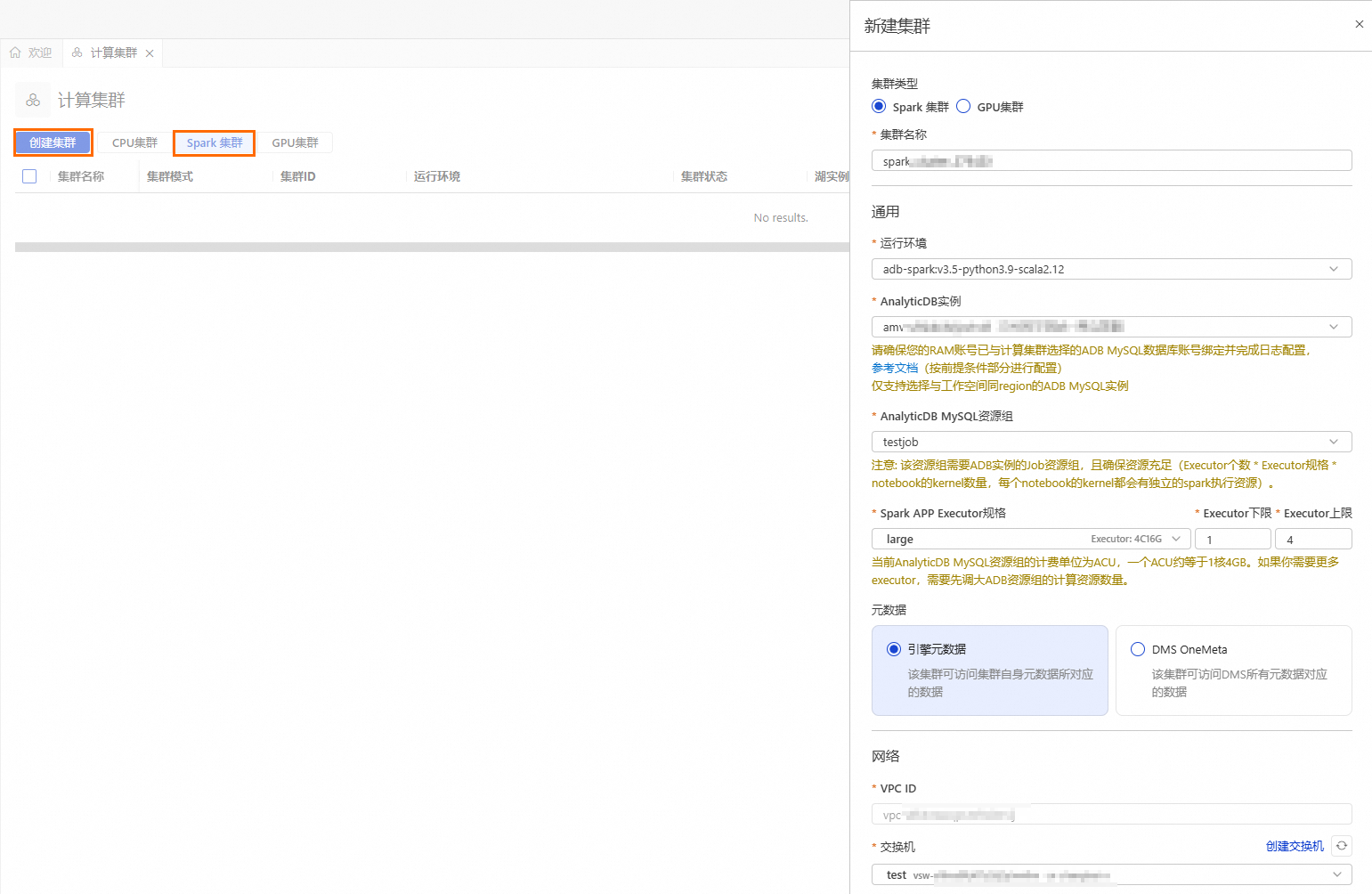
按钮,进入资源管理页面,单击计算集群。选择Spark集群页签,单击创建集群,并配置如下参数:
参数
说明
示例值
集群名称
输入便于识别使用场景的集群名称。
spark_test
运行环境
目前支持选择如下镜像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB实例
在下拉框中选择AnalyticDB for MySQL集群。
amv-uf6i4bi88****
AnalyticDB MySQL资源组
在下拉框中选择Job型资源组。
testjob
Spark APP Executor规格
选择Spark Executor的资源规格。
不同型号的取值对应不同的规格,详情请参见Spark应用配置参数说明的型号列。
large
交换机
选择当前VPC下的交换机。
vsw-uf6n9ipl6qgo****
创建并启动Notebook会话时,首次启动需要等待大约5分钟。
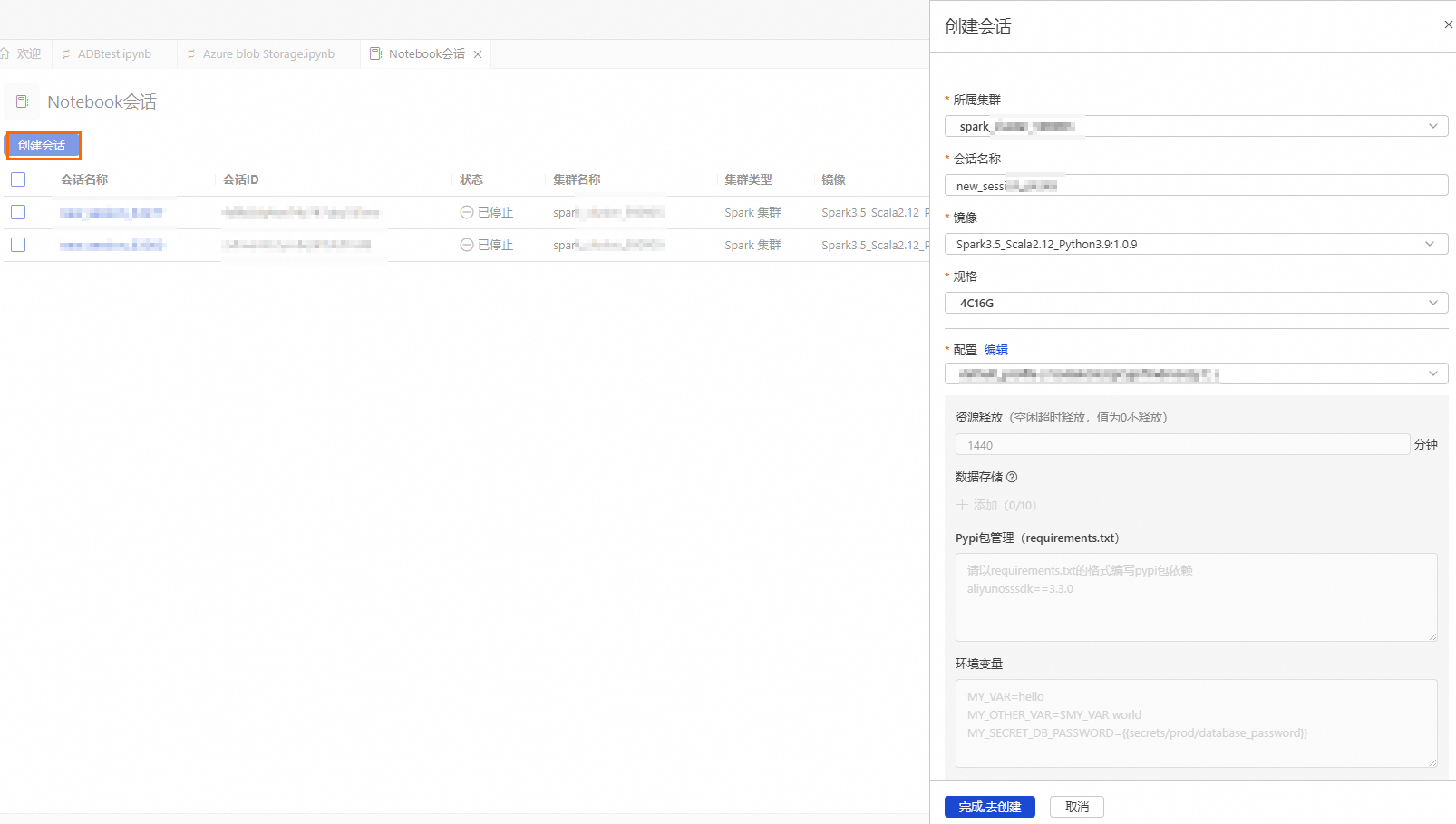
参数
说明
示例值
所属集群
选择步骤b创建的Spark集群。
spark_test
会话名称
您可自定义会话名称。
new_session
镜像
选择镜像规格。
Spark3.5_Scala2.12_Python3.9:1.0.9
Spark3.3_Scala2.12_Python3.9:1.0.9
Spark3.5_Scala2.12_Python3.9:1.0.9
规格
kernel的资源规格。
1核4 GB
2核8 GB
4核16 GB
8核32 GB
16核64 GB
4C16G
配置
profile资源。
您可编辑profile的名称、资源释放时长、数据存储位置、Pypi包管理和环境变量信息。
重要资源释放时长:当资源空闲时间超过设置的时长,则会自动释放。资源释放时长设置为0,表示资源永久不会自动释放。
deault_profile
步骤一:创建Airflow实例
进入DMS Notebook,单击左侧导航栏
 按钮,进入资源管理页面。
按钮,进入资源管理页面。单击工作流实例,然后单击左上角创建实例。
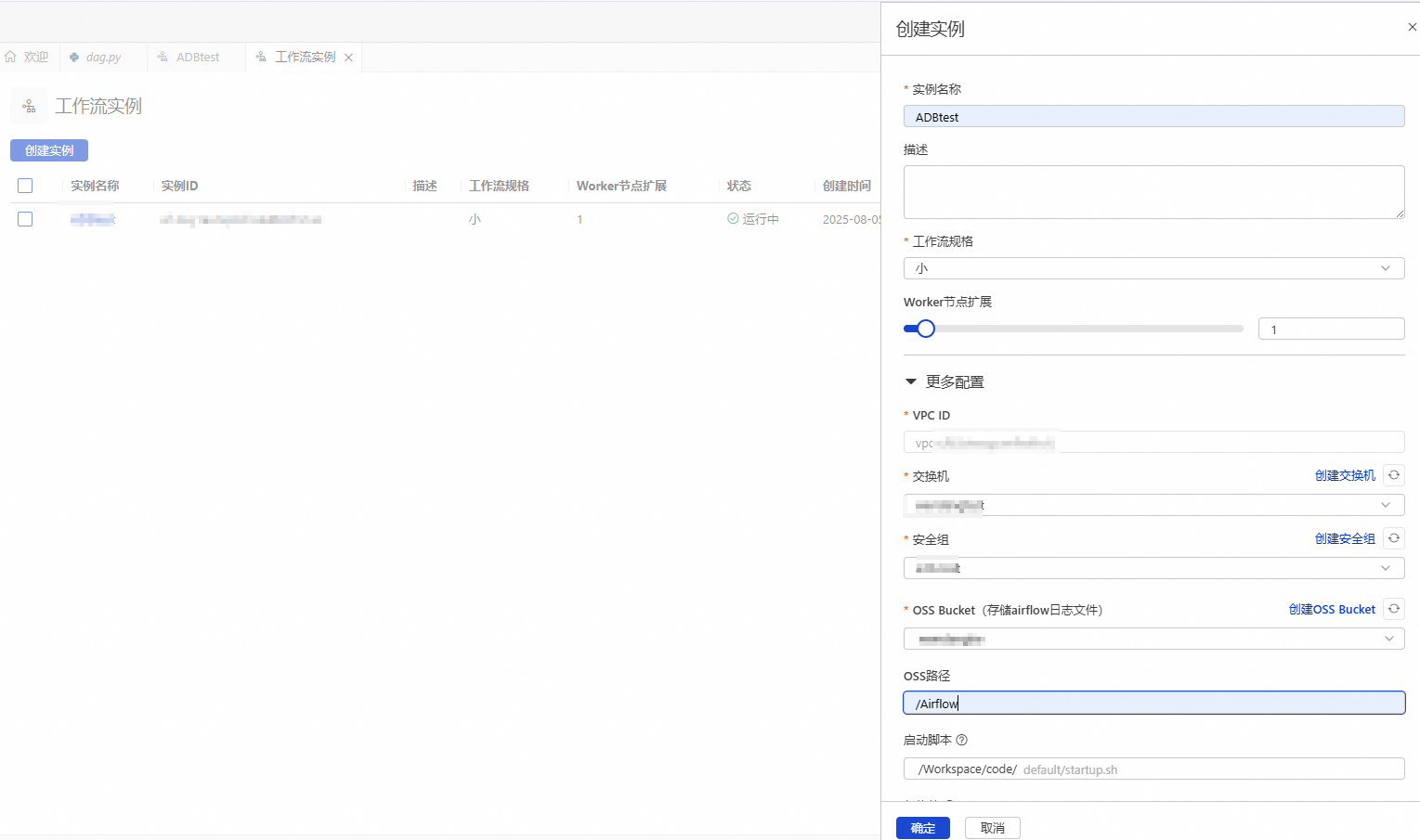
在创建实例面板,配置实例信息。
参数
说明
示例值
实例名称
输入便于识别使用场景的实例名称。
Airflow_test
工作流规格
请根据工作流规模和复杂程度合理选择规格。目前支持如下三种规格:
小(scheduler:1,webserver:1,worker:1)
中(scheduler:2,webserver:1,worker:3)
大(scheduler:2,webserver:2,worker:6)
小
Worker节点扩展
Airflow会根据任务负载情况自动调整使用节点数。Worker节点最小为1,最大为10。
1
VPC ID
无需调整,默认与工作空间的VPC一致。
vpc-uf63vtexqpvl****
交换机
选择目标交换机。
vsw-uf6n9ipl6qgo****
安全组
选择控制工作流的安全组。
sg-bp19mr685pmg4ihc****
OSS Bucket
选择与工作空间所在地域相同的OSS Bucket。
testBucketName
OSS路径
Airflow运行期间日志数据的存储路径。
Airflow
单击确定。
实例创建过程大约需要20分钟,当实例状态为运行中,表示资源已部署完成。

步骤二:构建ETL进行订单数据聚合分析
操作流程
本步骤模拟如下业务场景:

Raw layer:基于订单数据构建分层的Lakehouse。首先,在原始层(Raw layer)生成动态订单原始数据,并将其写入名为
orders_raw的Delta Lake表。Bronze layer:清洗原始数据
orders_raw(包括过滤无效数据、识别有效订单以及规范化日期格式),然后将其写入名为orders_bronze的Delta Lake 表中。Silver layer:聚合加工处理Bronze层的数据,比较各商品类目的销售表现。便于识别每个类目的销售高峰时段,优化营销资源的投放。
操作步骤
本教程提供完整的示例代码,您可以下载示例文件并将其上传至工作空间手动顺序执行。
下载示例文件GenerateOrdersDataInRawLayer.ipynb和ProcessingBronzeAndSilverLayer.ipynb。
GenerateOrdersDataInRawLayer.ipynb:动态生成样例订单明细数据,并写入orders_raw表。其中,batch_start_datetime参数用于定义订单数据同步至数据湖的时间。当通过Airflow调度该Notebook时,batch_start_datetime参数会从Airflow里动态传入并进行覆盖。ProcessingBronzeAndSilverLayer.ipynb:用于创建Bronze层和Silver层的表,然后从Raw层导入数据并进行ETL,完成分层加工。
上传
GenerateOrdersDataInRawLayer.ipynb和ProcessingBronzeAndSilverLayer.ipynb文件至default(默认库)文件夹。进入DMS Notebook,单击左侧导航栏
 按钮,进入资源管理器页面。
按钮,进入资源管理器页面。鼠标悬浮在default(默认库)上右击,然后单击上传文件,选择步骤1下载的示例文件。

执行
GenerateOrdersDataInRawLayer.ipynb和ProcessingBronzeAndSilverLayer.ipynb文件,验证数据加工任务是否能正常运行。打开
GenerateOrdersDataInRawLayer.ipynb文件,将第2个Cell中的Location参数替换为数据实际存储的OSS路径后,单击全部运行,顺序执行该文件。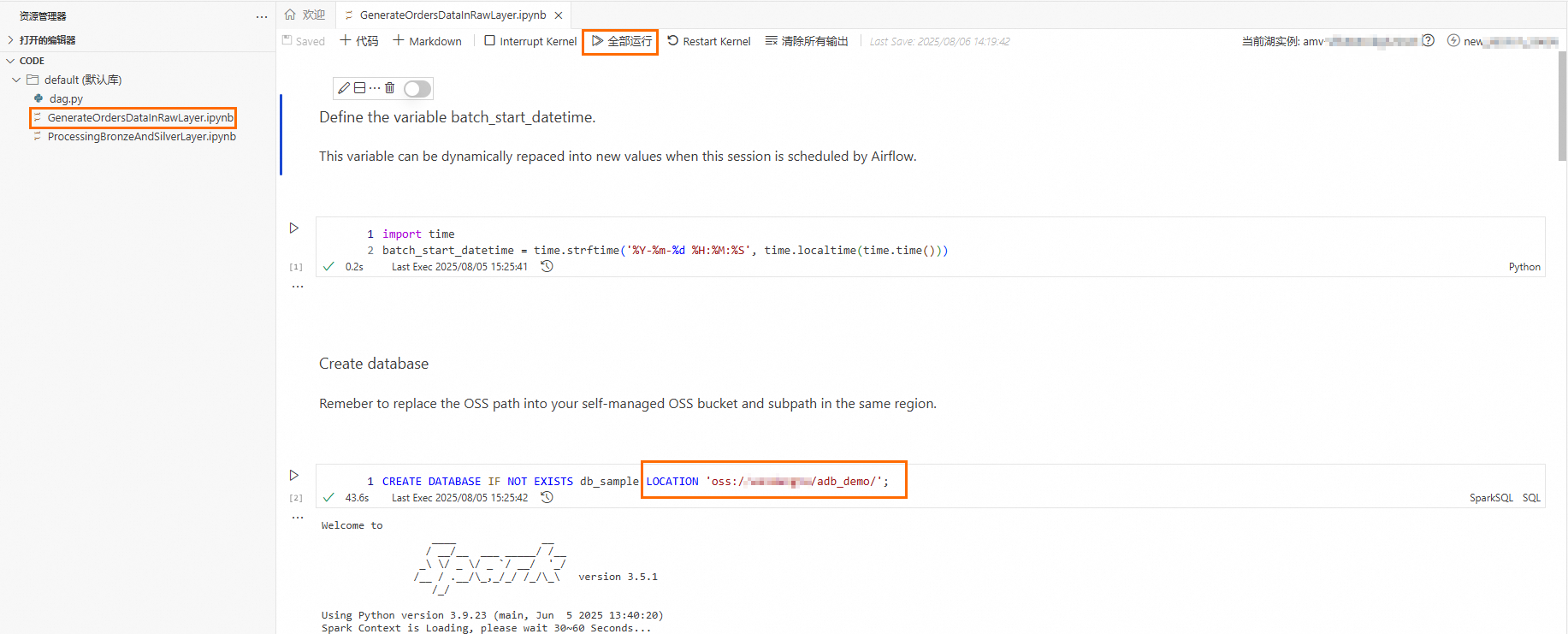
打开
ProcessingBronzeAndSilverLayer.ipynb文件,单击全部执行,顺序执行该文件。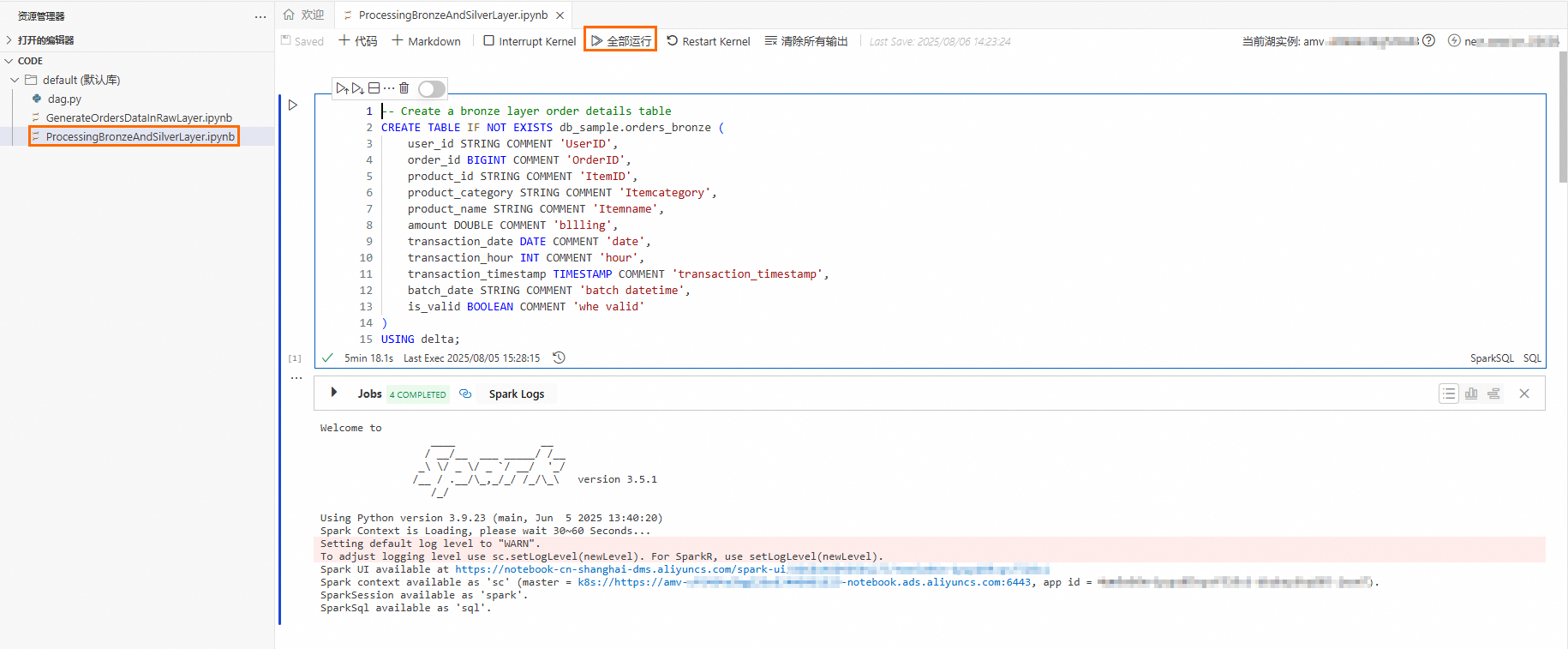
步骤三:定义工作流DAG并发布至Airflow
在资源管理器页面,单击
 按钮,然后单击新建Python文件。
按钮,然后单击新建Python文件。
输入以下代码并替换其中相关配置参数。
from doctest import debug from airflow import DAG from airflow.decorators import task from airflow.models.param import Param from airflow.operators.bash import BashOperator from airflow.operators.empty import EmptyOperator from datetime import datetime, timedelta from airflow.providers.alibaba_dms.cloud.operators.dms_notebook import DMSNotebookOperator import time # 定义DAG参数 default_args = { # 任务所有者 'owner': 'user', # 任务失败后重试的次数 'retries': 1, # 任务重试前的等待时间 'retry_delay': timedelta(minutes=5) } # 定义DAG参数 with DAG( # 定义DAG ID,全局唯一 dag_id="RefreshTheRawBronze****", default_args=default_args, # 定义DAG的描述 description="Trigger this DAG every three hours and dynalically refresh the raw/bronze/silver layers", # 定义DAG的调度频率,每3小时调度一次 schedule_interval='0 0/3 * * *', # refresh every three hours # 定义DAG首次调度的时间 start_date=datetime(2025, 7, 28), # 是否在DAG启动时追溯执行错过的任务 catchup=False ) as dag: notebook_node_raw_layer = DMSNotebookOperator( # 定义Task ID,全局唯一 task_id = 'GenerateOrdersData****', # Notebook会话名称,此处填写为准备在工作中创建的会话名称 session_name='Spark****', # GenerateOrdersDataInRawLayer.ipynb文件路径,默认为/Workspace/code/default/<file_name> file_path='/Workspace/code/default/GenerateOrdersDataInRawLayer.ipynb', run_params={'batch_start_datetime': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) }, debug=True, dag=dag ) notebook_node_bronze_silver_layer = DMSNotebookOperator( # 定义Task ID,全局唯一 task_id = 'ProcessingBronzeAnd****', # Notebook会话名称,此处填写为准备在工作中创建的会话名称 session_name='Spark****', # GenerateOrdersDataInRawLayer.ipynb文件路径,默认为/Workspace/code/default/<file_name> file_path='/Workspace/code/default/ProcessingBronzeAndSilverLayer.ipynb', run_params={}, debug=True, dag=dag ) # 定义DAG的执行顺序 notebook_node_raw_layer >> notebook_node_bronze_silver_layer if __name__ == "__main__": dag.test( run_conf={} )说明更多关于DAG和DMS Notebok Operator的自定义参数的内容,请参见DAG、Best Practices和参数说明。
将工作流DAG发布至Airflow。
在页面左侧导航栏,单击
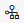 按钮,进入Airflow页面。
按钮,进入Airflow页面。单击步骤一创建的Airflow实例,在顶部导航栏单击DAGs,查看工作流DAG是否存在。
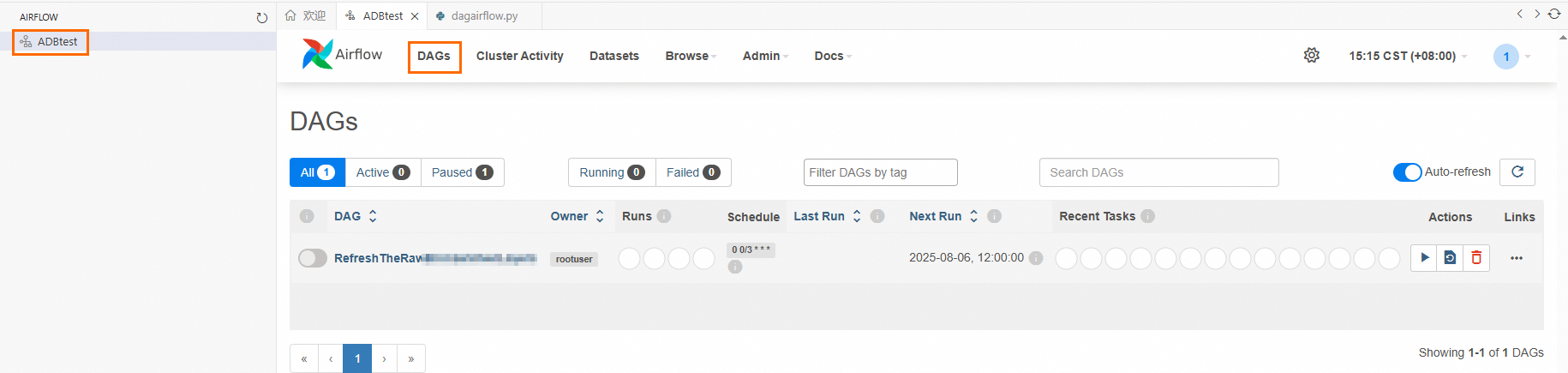
单击DAG名称,单击
 按钮,刷新工作流内容。
按钮,刷新工作流内容。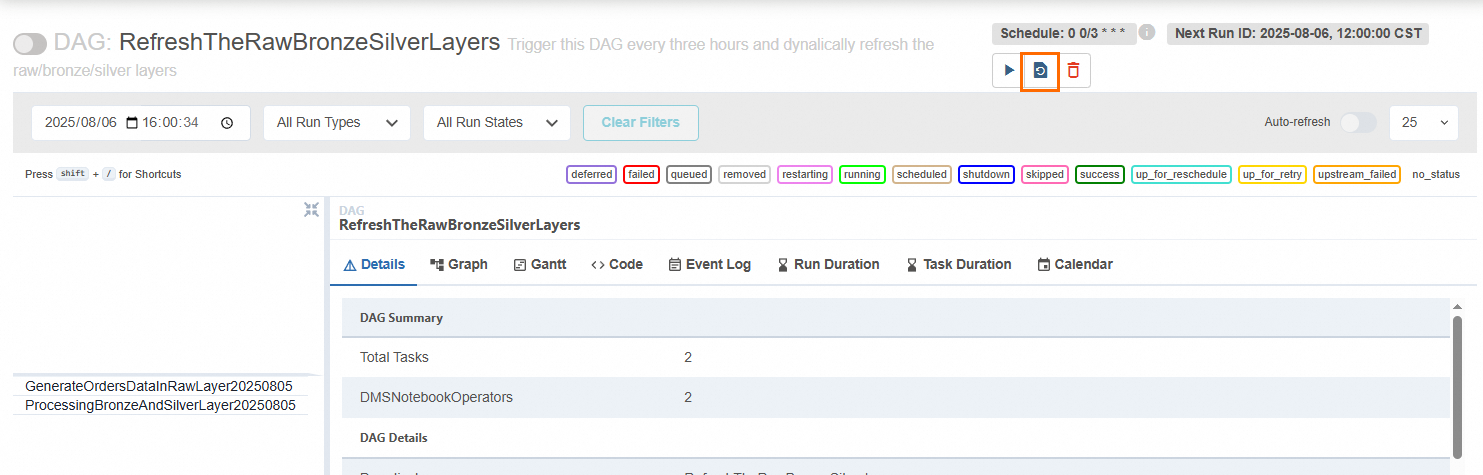
单击Code页签,检查DAG的内容与步骤2中定义的DAG内容是否一致、以及左侧Task列表与步骤2中定义的Operator节点是否一致。
若一致,则表明DAG已发布成功;若不一致,请修改步骤2中的相关参数,然后单击
 按钮刷新工作流。
按钮刷新工作流。
步骤四:执行DAG并开启自动调度
DAG内容检查无误后,单击
 按钮,手动执行DAG。
按钮,手动执行DAG。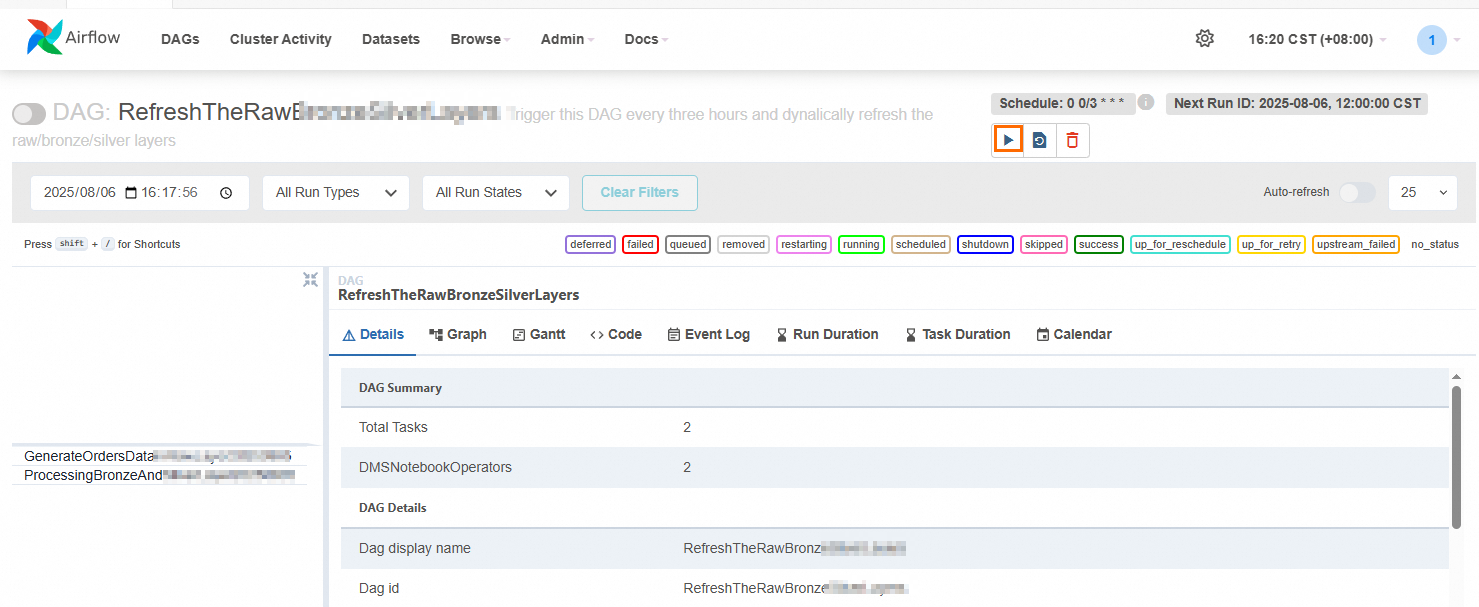
单击Task列表右侧的
 按钮,查看DAG执行详细信息。
按钮,查看DAG执行详细信息。单击Details,可以查看Task任务的ID、执行状态、开始执行、结束时间等信息。
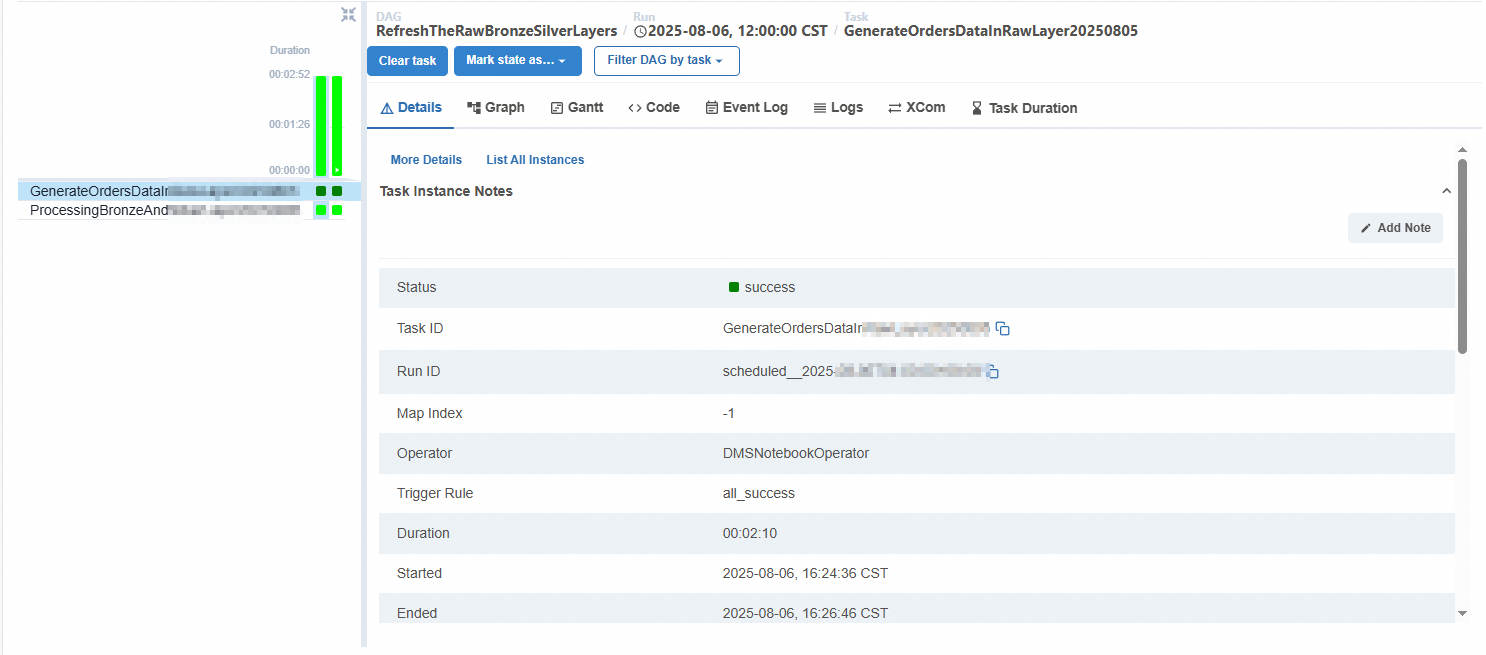
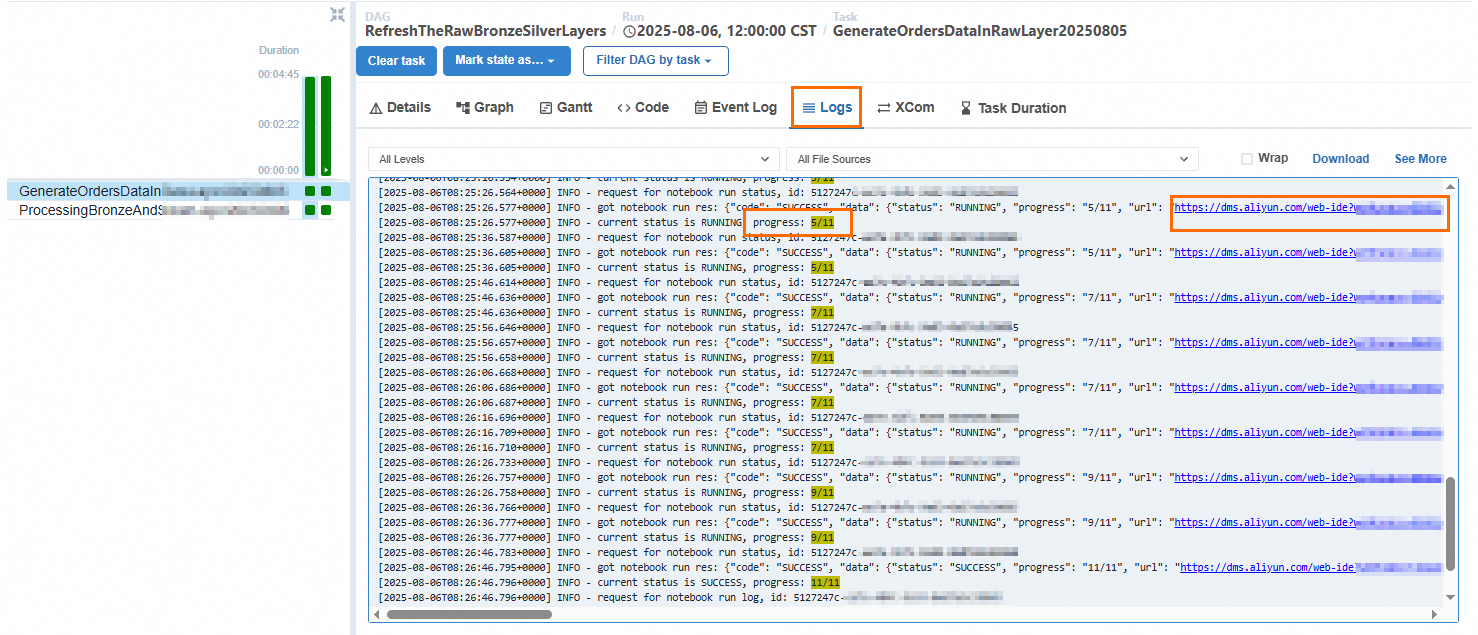
单击Logs页签,可以查看Cell的执行进度,单击url后,可以查看对应Cell执行后的输出结果,从而判断整个DAG调度后的最终结果是否符合预期。
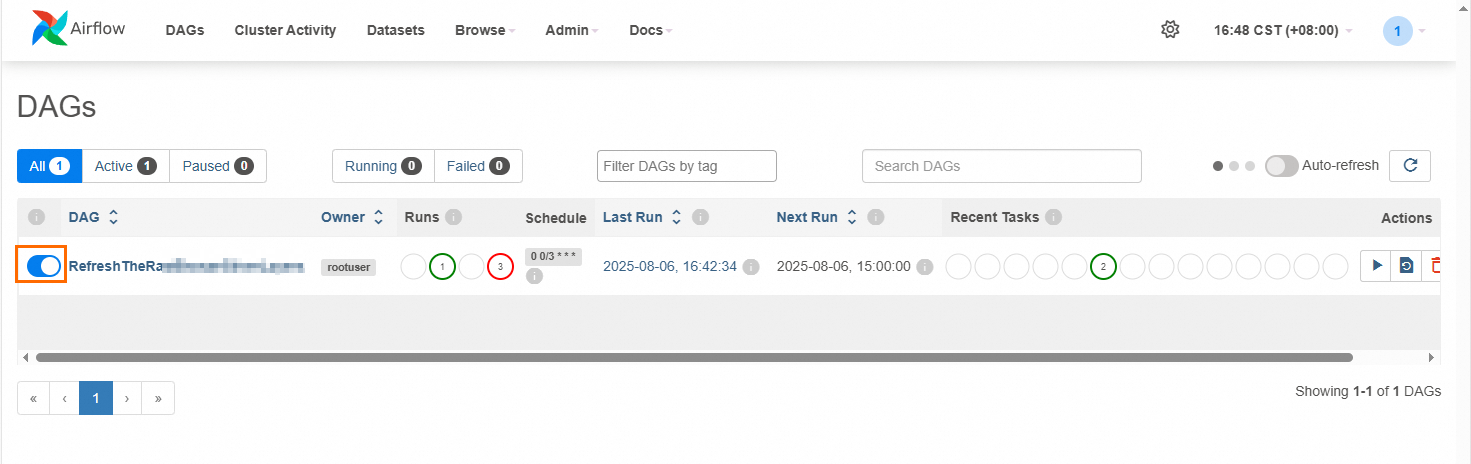
在顶部导航栏单击DAGs,可以查看DAG执行成功或失败的次数(Runs列),以及处于成功、失败或排队状态下的任务数量(Recent Tasks列)。
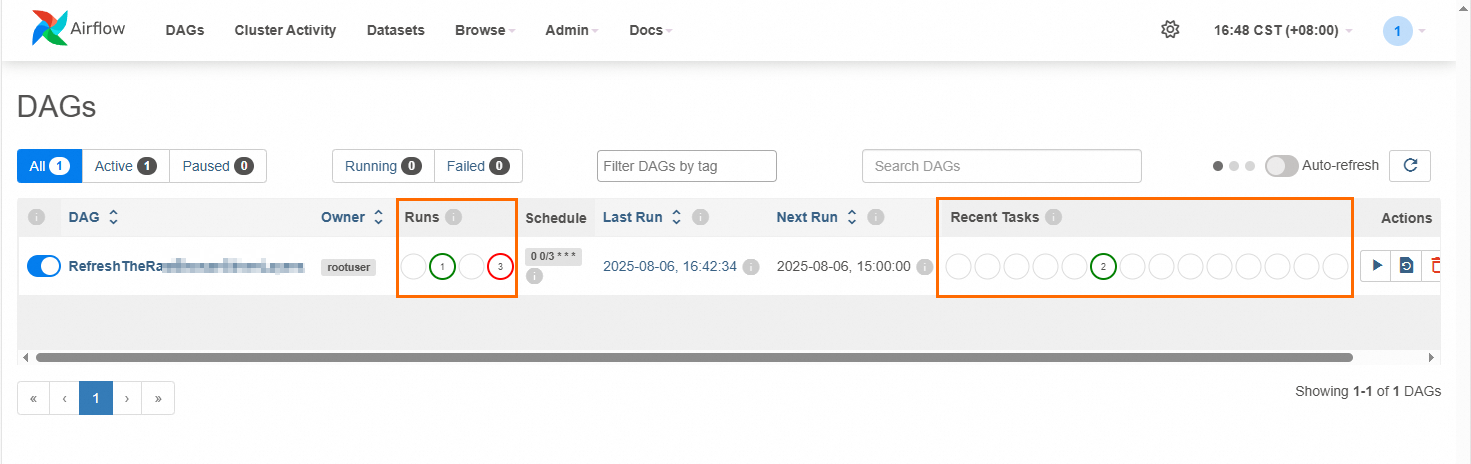
开启自动调度。
执行完成后,在顶部导航栏单击DAGs,查看DAG的调度按钮是否开启,若按钮置灰,请手动开启。若为开启状态,则DAG后续会按照设置的调度频率定时执行。