
通过PAI DSW开发Spark应用
交互式建模(DSW)是PAI产品的云端机器学习开发IDE,支持多种语言及开发环境。您可以在DSW实例中连接云原生数据仓库 AnalyticDB MySQL 版集群,并通过其集成的Notebook、Terminal等开发环境编写PySpark脚本,提交Spark作业。本文为您介绍通过DSW实例提交Spark作业的具体操作步骤。
前提条件
AnalyticDB for MySQL集群的产品系列为企业版、基础版或湖仓版。
已在AnalyticDB for MySQL集群中创建Job型资源组,并在该资源组中配置Spark参数
spark.adb.version=3.2。已创建AnalyticDB for MySQL集群的数据库账号。
如果是通过阿里云账号访问,只需创建高权限账号。
如果是通过RAM用户访问,需要创建高权限账号和普通账号并且将RAM用户绑定到普通账号上。
已授权AnalyticDB for MySQL扮演AliyunADBSparkProcessingDataRole角色来访问其他云资源。
AnalyticDB for MySQL集群已配置Spark应用的日志存储地址。
说明登录云原生数据仓库AnalyticDB MySQL控制台,在页面,单击日志配置,选择默认路径或自定义存储路径。自定义存储路径时不能将日志保存在OSS的根目录下,请确保该路径中至少包含一层文件夹。
步骤一:创建并配置PAI DSW实例
开通PAI并创建工作空间。具体操作,请参见开通PAI和创建及管理工作空间。
PAI需要与AnalyticDB for MySQL位于同一地域。
创建DSW实例。
您可以选择如下两种方法创建DSW实例。
在控制台直接创建DSW示例。具体操作,请参见创建DSW实例。
您需将镜像选择为镜像地址,并手动填入AnalyticDB for MySQL Spark的Livy镜像地址
registry.cn-hangzhou.aliyuncs.com/adb-public-image/adb-spark-public-image:livy.0.5.pre。对于对其他参数配置没有要求,您可根据自己的业务需求配置。在教程中点击在DSW中打开,选择符合要求的DSW实例或创建新的DSW实例。具体操作,请参见创建DSW实例。
在创建DSW页面,镜像地址和DSW实例规格已预先填写,您仅需要填写实例名称并单击确定,即可创建DSW实例。
访问DSW实例。具体操作,请参见控制台访问。
单击顶部菜单栏Terminal,执行以下语句,启动Apache Livy代理。
cd /root/proxy python app.py --db <ClusterID> --rg <Resource Group Name> --e <URL> -i <AK> -k <SK> -t <STS> &参数说明:
参数
是否必填
说明
ClusterID
是
AnalyticDB for MySQL集群ID。
Resource Group Name
是
AnalyticDB for MySQL集群Job型资源组名称。
URL
是
AnalyticDB for MySQL集群的服务接入点。
如何查看AnalyticDB for MySQL集群的服务接入点,请参见服务接入点。
AK、SK
条件必填
阿里云账号或者具备AnalyticDB for MySQL访问权限的RAM用户的AccessKey ID和AccessKey Secret。
如何获取AccessKey ID和AccessKey Secret,请参见账号与权限。
说明仅使用阿里云主账号或RAM用户时需要填写AK和SK。
STS
条件必填
RAM角色的临时身份凭证,即安全令牌(STS Token)。
有权限的RAM用户可以使用自己的访问密钥调用AssumeRole - 获取扮演角色的临时身份凭证接口,以获取某个RAM角色的STS Token,从而使用STS Token访问阿里云资源。
说明仅使用RAM角色时需要填写STS。
返回如下两行信息则表明启动成功:
2024-11-15 11:04:52,125-ADB-INFO: ADB Client Init 2024-11-15 11:04:52,125-ADB-INFO: Aliyun ADB Proxy is ready查看是否有进程监听5000端口。
执行步骤4操作成功后可以执行
netstat -anlp | grep 5000语句查看是否有进程监听5000端口。
步骤二:PySpark开发
访问DSW实例。具体操作,请参见控制台访问。
单击顶部导航栏的Notebook,进入Notebook页面。
单击顶部菜单栏。在弹出的Select Kernel对话框中选择Python 3 (ipykernel),并单击Select。
依次执行下列语句,安装并加载sparkmagic。
!pip install sparkmagic %load_ext sparkmagic.magics执行
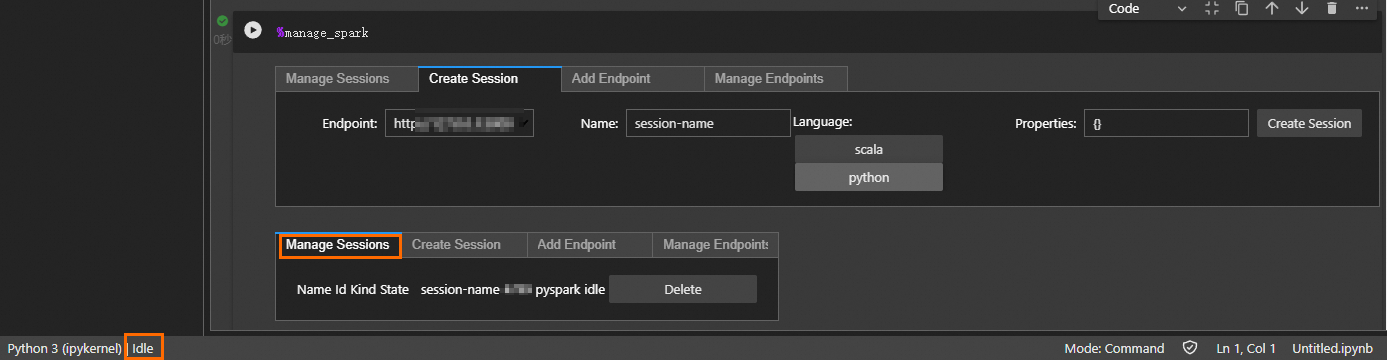
%manage_spark语句。执行后,弹出Create Session页签。
在弹出的Create Session页签中,选择Language为Python,然后单击Create Session。
重要Create Session仅需单击一次,请勿重复点击。
单击Create Session后,Notebook页面底部状态会显示为Busy,当状态变为Idle并且在Manage Session页签下看到Session ID时,表明Session已创建成功。
运行PySpark脚本。
运行PySpark脚本时,必须在业务代码前添加
%%spark命令指定使用远端Spark。%%spark db_sql = """ CREATE DATABASE IF NOT exists test_db comment 'demo db' location 'oss://testBucketName/test' WITH dbproperties(k1='v1', k2='v2') """ tb_sql = """ CREATE TABLE IF NOT exists test_db.test_tbl(id int, name string, age int) using parquet location 'oss://testBucketName/test/test_tbl/' tblproperties ('parquet.compress'='SNAPPY'); """ insert_sql = """ INSERT INTO test_db.test_tbl VALUES(1, 'adb', 10); """ select_sql = """ SELECT * FROM test_db.test_tbl; """ spark.sql(db_sql).show() spark.sql(tb_sql).show() spark.sql(insert_sql).show() spark.sql(select_sql).show()