
创建Nova向量索引
Nova是AnalyticDB PostgreSQL 7.0版新一代的向量检索引擎,旨在提供极致的查询性能和更高的性价比。它分为磁盘型(Novad)和内存型(Novam)两种模式,前者具有高性价比,后者则面向极致性能场景。本文为您介绍Nova索引的选型及创建操作。
优势
与传统的HNSW索引相比,Nova索引具备以下核心优势:
查询性能提升:向量查询速度更快。
内存效率优化:引入了Novad磁盘型索引,降低内存占用,提供更高的性价比。
写入吞吐量增加:数据写入与索引构建过程解耦,提升向量数据的写入效率。
前提条件
内核版本为7.4.2.0及以上的AnalyticDB for PostgreSQL7.0版实例。
容量评估与索引选型
Nova索引分为磁盘型(Novad)和内存型(Novam)两种模式:
磁盘型(Novad):基于图+分区混合索引实现,HNSW常驻内存、IVF存储于磁盘,磁盘IO友好,索引规模远超内存时性能稳定。对内存依赖小于Novam,Novad的索引构建性能大大优于Novam,且索引磁盘占用远小于Novam。适用于大规模低成本检索的使用场景, 在百亿、千亿数据量级下有显著的成本优势。
内存型(Novam):基于图索引实现,内存容量越大,性能越优,内存不足时自动访问磁盘。在内存充足的情况下,同等规格的Novam查询性能优于Novad。适用于实时推荐等高性能场景。
Nova索引后台有定期优化任务,无业务负载时也可能占用资源。
不同向量维度和向量数下的资源规格建议如下(仅列举部分场景,可通过增加资源支持更大数据量):
Novad
向量维度 | 向量数 | 建议总计算资源 |
128 | <320M | 8c |
256 | <160M | |
512 | <80M | |
768 | <50M | |
1024 | <40M | |
1536 | <26M | |
2048 | <20M | |
128 | <640M | 16c |
256 | <320M | |
512 | <160M | |
768 | <100M | |
1024 | <80M | |
1536 | <60M | |
2048 | <40M | |
128 | <1.28B | 32c |
256 | <640M | |
512 | <320M | |
768 | <200M | |
1024 | <160M | |
1536 | <120M | |
2048 | <80M | |
128 | <5.12B | 128c |
256 | <2.56B | |
512 | <1.28B | |
768 | <800M | |
1024 | <640M | |
1536 | <480M | |
2048 | <320M | |
128 | <200B | 4096c |
256 | <100B | |
512 | <50B | |
768 | <33B | |
1024 | <25B | |
1536 | <16B | |
2048 | <12B | |
128 | <1.6T | 32768c |
256 | <800B | |
512 | <400B | |
768 | <260B | |
1024 | <200B | |
1536 | <130B | |
2048 | <100B |
Novam
向量维度 | 向量数 | 建议总计算资源 |
128 | <32M | 8C |
256 | <16M | |
512 | <8M | |
768 | <5M | |
1024 | <4M | |
1536 | <2.6M | |
2048 | <2M | |
128 | <64M | 16C |
256 | <32M | |
512 | <16M | |
768 | <10M | |
1024 | <8M | |
1536 | <5M | |
2048 | <4M | |
128 | <128M | 32C |
256 | <64M | |
512 | <32M | |
768 | <20M | |
1024 | <16M | |
1536 | <10M | |
2048 | <8M |
语法
CREATE INDEX [INDEX_NAME]
ON [SCHEMA_NAME].[TABLE_NAME]
USING ANN(COLUMN_NAME)
WITH (DIM=<DIMENSION>,
ALGORITHM=<ALGORITHM>,
DISTANCEMEASURE=<MEASURE>,
...);参数说明:
INDEX_NAME:索引名。
SCHEMA_NAME:模式(命名空间)名。
TABLE_NAME:表名。
COLUMN_NAME:向量索引列名。
其他向量索引参数:
参数名
含义
默认值
取值范围
dim
向量维度。
无(必填)
[1, 8192]
algorithm
索引算法:
novam: 不带量化压缩的图索引。
novad: 带rabitq量化的分区索引。
hnswflat: 不带量化压缩的hnsw索引。
hnswflat
(novam, novad, hnswflat)
distancemeasure
支持的相似度距离度量算法:
L2:使用欧氏距离(平方)函数构建索引,通常适用于图片相似度检索场景。计算公式:
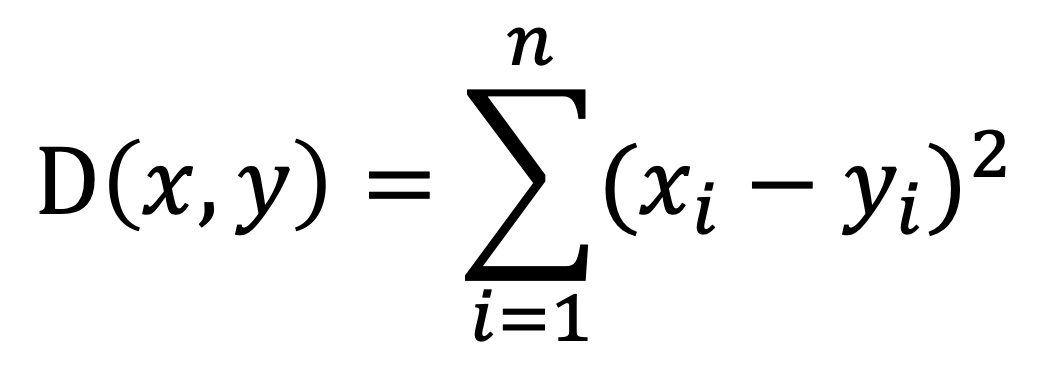
IP:使用反内积距离函数构建索引,通常适用于向量归一化之后替代余弦相似度。计算公式:

COSINE:使用余弦距离函数构建索引,通常适用于文本相似度检索场景。计算公式:
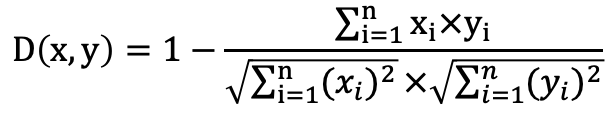
l2
(L2, IP, COSINE)
max_delta_vecs
最大写入攒批向量数。
1048576
[1024, 1073741824]
hnsw_m
Novam中邻居数,通常情况下,越大图质量越好,构建时间越长。
16
[10, 1000]
hnsw_ef_construction
Novam构建时搜索候选集大小,越大图质量越好,构建时间越长。
64
[40, 4000]
base_slice_log2_size
Novam文件分片大小的log2对数。
24
[10, 30]
nlist
Novad列表数。
1024
[2, 1073741824]
accel_m
Novad加速层邻居数。
16
[8, 1024]
accel_efc
Novad加速层构建候选集大小。
128
[1, 32768]
rabitq_bits
rabitq压缩比特数。
1
[1, 8]
max_cluster_vecs
Novad单文件中心点最大向量数。
65536
[1, 10000000]
示例
创建示例表。
CREATE TABLE chunks ( id SERIAL PRIMARY KEY, chunk VARCHAR(1024), intime TIMESTAMP, url VARCHAR(1024), feature REAL[] ) DISTRIBUTED BY (id);对向量列创建Nova索引。
创建余弦相似度度量的Novad向量索引。
CREATE INDEX idx_feature_novad_cosine ON chunks USING ann(feature) WITH ( dim=1536, algorithm=novad, distancemeasure=cosine, nlist=4096, rabitq_bits=1 );创建欧氏距离度量的Novam向量索引。
CREATE INDEX idx_feature_novam_l2 ON chunks USING ann(feature) WITH ( dim=1536, algorithm=novam, distancemeasure=l2, hnsw_m=32, hnsw_ef_construction=200 );