
数据膨胀诊断
AnalyticDB PostgreSQL版提供的智能诊断数据膨胀功能,可以定期自动诊断数据库内的所有表,并生成诊断信息表。您可以通过诊断信息表,查看表的膨胀情况并获得相应的处理建议(如执行VACUUM或VACUUM FULL操作)。
注意事项
智能诊断数据膨胀功能仅支持存储弹性模式实例,且内核版本须满足以下条件:
AnalyticDB PostgreSQL 6.0版实例为v6.3.10.0及以上。
AnalyticDB PostgreSQL 7.0版实例为v7.0.4.0及以上。
智能诊断数据膨胀功能在后台启动是以库为维度进行诊断,但不包括系统库(postgres、template0、template1、adbpgadmin和aurora 5个系统库),建议您将业务数据放在新建库中,不要将数据放在上述5个系统库中,否则无法诊断数据。
智能诊断数据膨胀功能在用户库中会扫描每张表(不包括临时表和unlogged表),但为了兼顾扫描的速度和诊断的意义,默认情况下,数据量小于1 GB的表会被过滤。如需调整该阈值,请参见设置数据量阈值。
智能诊断功能会定期自动诊断实例的每个用户库,定期启动的时间是每隔一个小时,且在整点启动。例如,5点启动自动诊断功能后,下个启动点时间是6点整。
为何会数据膨胀
数据膨胀是对表中未使用空间量和死亡元组占用空间量的度量。AnalyticDB PostgreSQL版数据库使用PostgreSQL多版本并发控制(MVCC)来管理并发事务,底层表的储存数据被划分成固定大小的Page,默认Page大小为32 KB。每个Page包含Header(数据头)、Item pointer array(指向内部数据的指针数组)、Unused space(未使用空间量)和Tuples(数据元组)。
INSERT数据时,会从Page的未使用空间中分配新的Tuple。如果当前Page的未使用空间不足时,会分配新的Page来存放写入的数据。
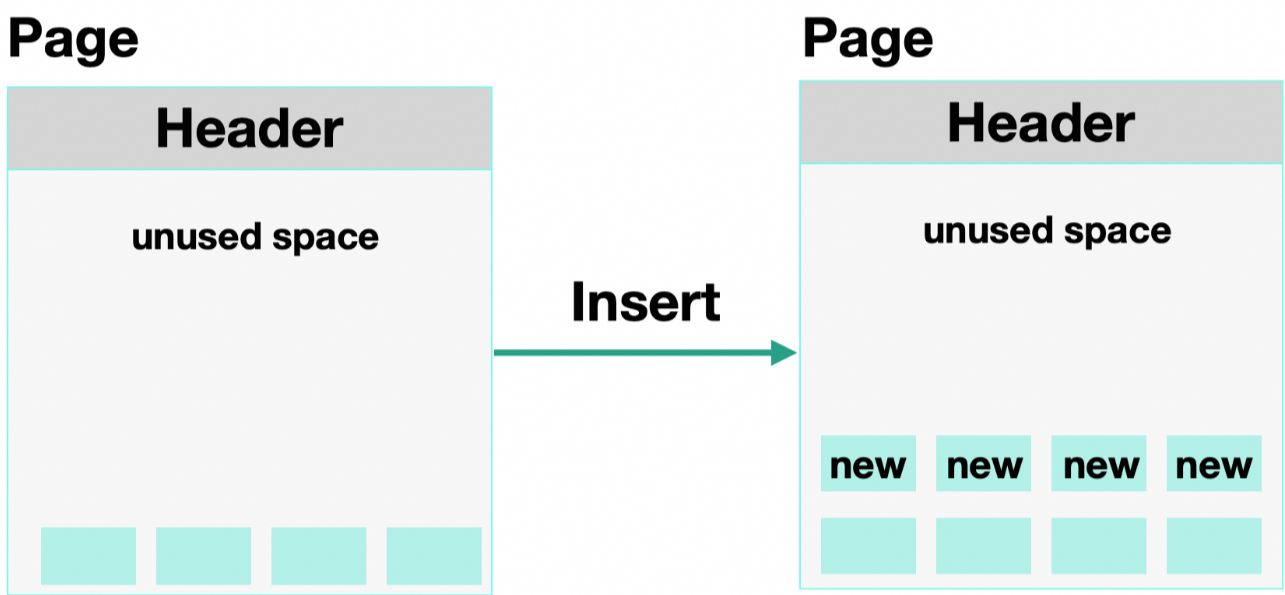
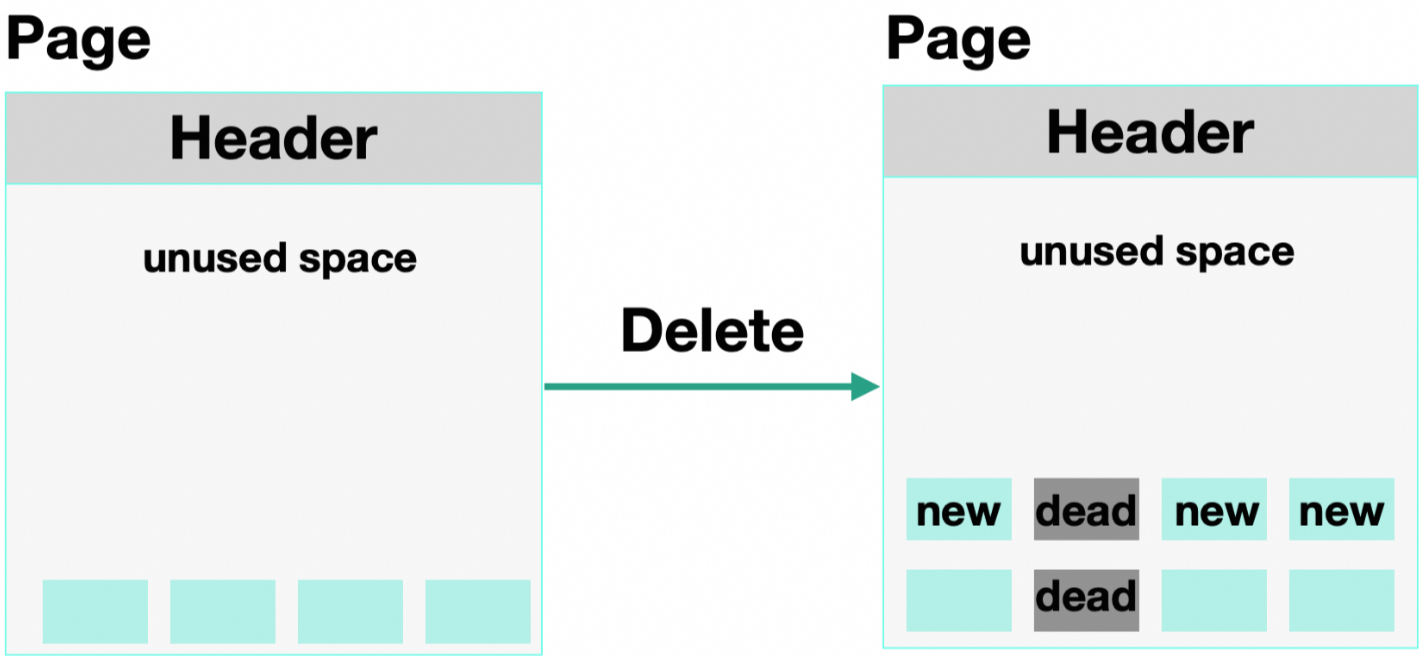
DELETE数据时,数据不会从Page内部真正删除,只是标记成死亡元组(Dead Tuple)。这些死亡元组依然占据着空间,会导致数据膨胀。
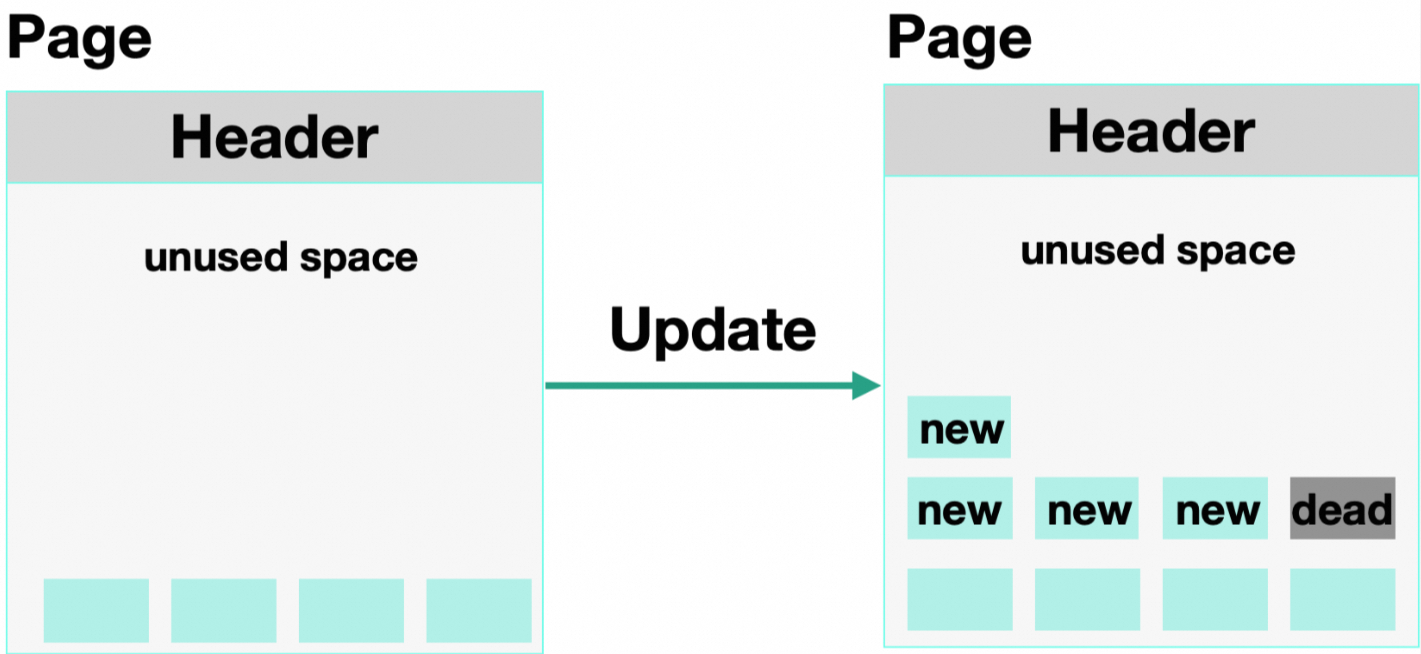
UPDATE数据时,由于多版本并发控制机制,数据不会在原地更新,而是将原来的Tuple标记成Dead Tuple,再插入New Tuple来达到数据更新的目的。因此,UPDATE操作也会造成数据表膨胀。
查看数据膨胀
智能诊断功能的诊断信息存储在adbpg_toolkit.diag_bloat_tables表中。
诊断信息表
diag_bloat_tables中的数据是按照ORDER BY bloat_coeff desc, real_size DESC排序的,即膨胀率越大的表越靠前。如果两个表的膨胀率相同时,数据量大的表更靠前。诊断信息表内部原理是基于PostgreSQL的Statistic Collector进程的统计信息来进行诊断的,Statistic Collector在PostgreSQL Server发生Crash时统计信息会重置(极小概率发生)。如果您发现诊断信息出现偏差时,可以通过ANALYZE命令来重新采集统计信息。具体操作,请参见使用ANALYZE收集统计信息。
您可以通过以下两种方式查看诊断信息。
控制台查看诊断信息。具体操作,请参见数据膨胀、倾斜与索引统计。
执行SQL语句查看诊断信息。SQL语句如下:
SELECT * FROM adbpg_toolkit.diag_bloat_tables;表
diag_bloat_tables各个字段的详细说明如下:字段
类型
说明
schema_name
name (63-byte type for storing system identifiers)
表所在的Schema的名称。
table_name
name
表名。
storage_type
text
表的存储类型,例如堆表或AO表。
expect_size
bigint
表预期没有膨胀的大小,单位为字节(Byte)。
real_size
bigint
表真正的大小,单位为字节(Byte)。
bloat_size
bigint
表膨胀的大小,单位为字节(Byte)。
bloat_coeff
bigint
表的膨胀率,取值范围为0~100,单位为%。
suggest_action
text
诊断该表建议采取的动作,取值如下:
空(不需要操作)
VACUUM
VACUUM FULL
last_vacuum
timestamp with time zone
最后一次手动清理表的时间(不计算VACUUM FULL)。
diagnose_time
timestamp with time zone
诊断信息生成的时间。
您也可以添加过滤条件,查看指定Schema或指定表的数据膨胀情况,查询语句如下:
查看指定Schema下所有表的数据膨胀情况:
SELECT * FROM adbpg_toolkit.diag_bloat_tables WHERE schema_name = '<Schema名称>';查看指定表的数据膨胀情况:
SELECT * FROM adbpg_toolkit.diag_bloat_tables WHERE table_name = '<Table名称>';
手动触发数据膨胀诊断
智能诊断功能默认在每个整点启动。如果您对某张表执行了VACUUM或VACUUM FULL操作,需要立即查看操作后的效果,需要手动触发一次数据膨胀诊断。手动触发数据膨胀诊断的语句如下:
SELECT adbpg_toolkit.diagnose_bloat_tables();设置数据量阈值
默认情况下,智能诊断功能会过滤小于1 GB的表,如需调整过滤的表的阈值大小,可以通过如下语句进行设置:
ALTER DATABASE <数据库名称> SET adb_diagnose_table_threshold_size to <表的数据量,单位为字节>;例如,您需要诊断500 MB以上的表,示例语句如下:
ALTER DATABASE diagnose SET adb_diagnose_table_threshold_size to 536870912;消除数据膨胀
随着对表不断进行INSERT、DELETE或UPDATE操作,会积累大量Dead Tuple,占据大部分本可以用来存放数据的空间,使得Page中未使用空间减小,导致更多的Page被分配出来。当Page被扫描时,这些大量的Dead Tuple也会被扫描,从而增加了IO时间开销。数据膨胀会带来以下副作用:
导致表的存储空间变大,浪费存储空间。
扫描IO开销增加,导致查询性能下降。
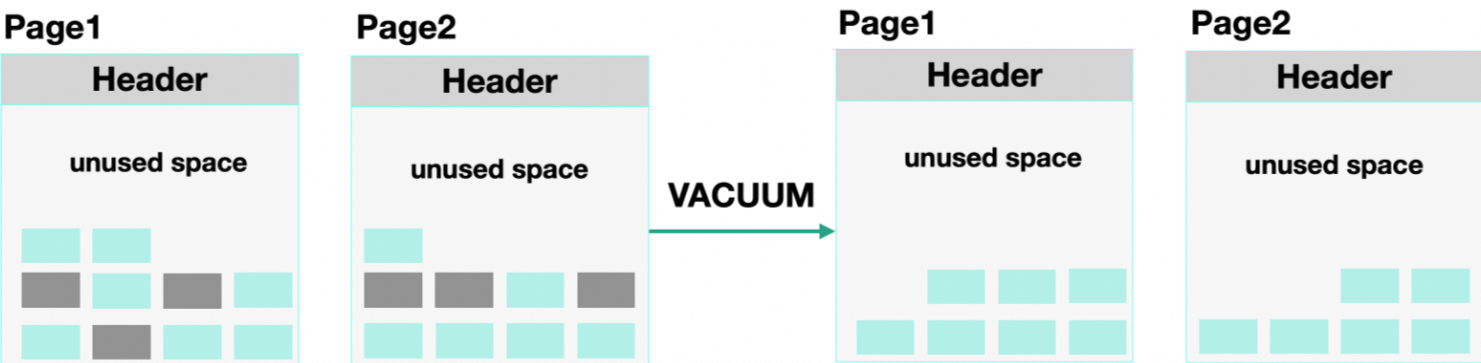
可通过VACUUM或VACUUM FULL命令消除数据膨胀。
执行VACUUM命令删除Dead Tuple来增加New Tuple可用的未使用空间量。
该方式的优缺点如下:
优点:VACUUM相较于VACUUM FULL,在表的锁粒度上更轻。VACUUM FULL需要ACCESS EXCLUSIVE锁模式,该模式会阻塞其他任何对该表的类型操作。例如,执行VACUUM FULL时,SELECT操作也会被阻塞,即VACUUM FULL操作没结束前,该表无法使用。
缺点:VACUUM不会跨Page来整理表的存储空间,无法减小磁盘上表的大小。
执行VACUUM FULL命令删除Dead Tuple来增加New Tuple可用的未使用空间量,同时跨Page来重新组织该表的储存。
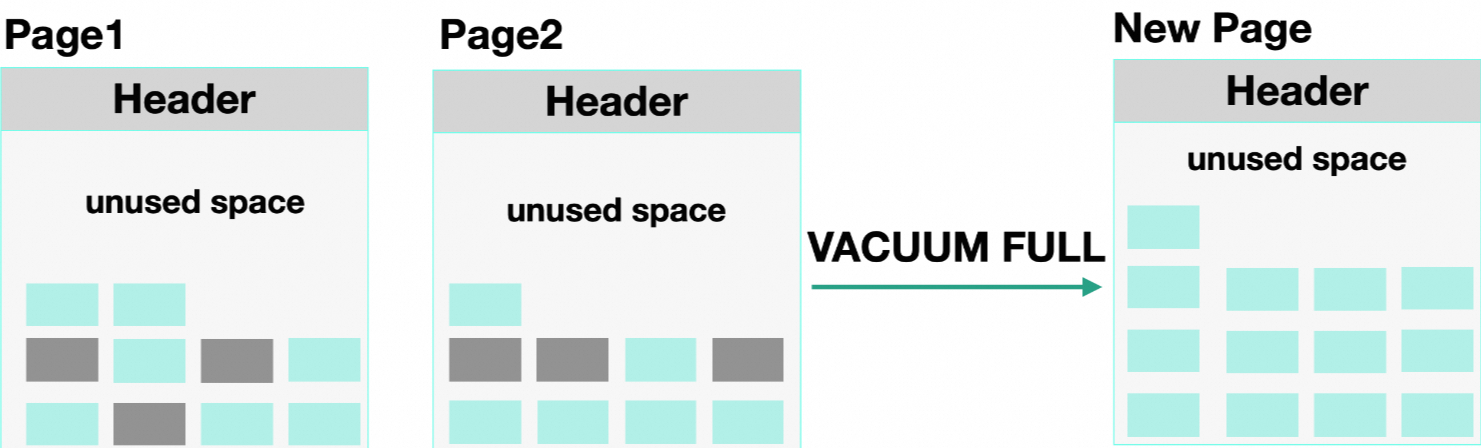
该方式的优缺点如下:
优点:重新整理表数据,让表变成更紧凑,能减小之前由于Dead Tuple造成的表磁盘大小膨胀,可以减小磁盘上表的大小。
缺点:重新整理表的Page储存时,需要ACCESS EXCLUSIVE锁模式。该模式是排他模式,意味着其他任何对该表的操作都会被阻塞。同时由于该命令需要重新整理储存的Page,所以它需要额外的储存空间来储存整理完的数据。