
基于OpenAPI构建RAG应用快速入门
本文以Python开发环境为例,介绍如何利用云原生数据仓库 AnalyticDB PostgreSQL 版的OpenAPI快速构建Retrieval Augmentation Generation(RAG)应用。
架构图
RAG架构通过信息检索系统,增加了大语言模型(LLM)的能力,提供了相关的上下文信息,比如特定行业或私有数据文档。RAG架构如下图所示: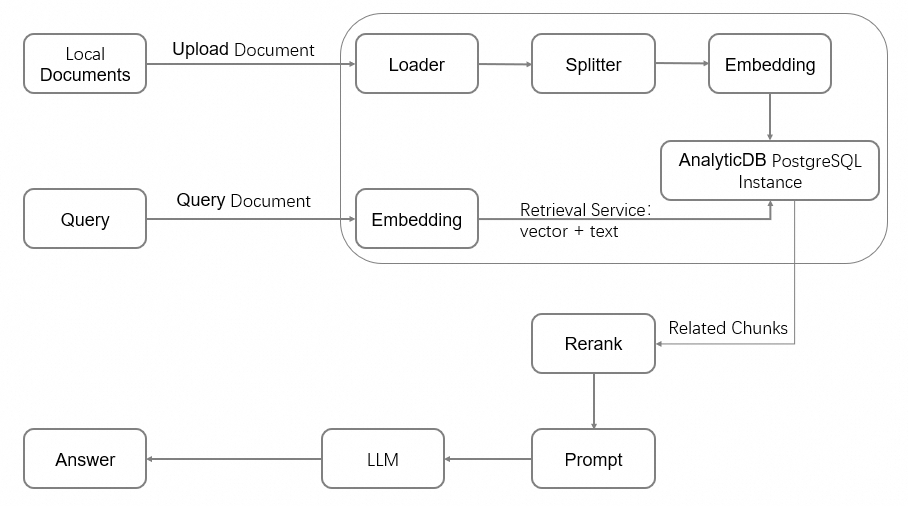
本快速入门基于云原生数据仓库 AnalyticDB PostgreSQL 版的自研向量引擎FastANN,并提供了系列的文档处理能力,通过OpenAPI的方式提供给用户。
其中,OpenAPI封装的AI Service能力为:
多租户管理。
文档处理:Load、Split、Embedding、多模处理。
检索能力:向量检索、全文检索、精排。
准备工作
已注册阿里云账号。若尚未注册,请前往阿里云官网进行注册。
授权服务关联角色。如果您是首次使用AnalyticDB PostgreSQL版,需要在控制台授权创建服务关联角色,操作方式如下:
- 登录云原生数据仓库AnalyticDB PostgreSQL版控制台。
单击页面右上角的新建实例。
在弹出的创建服务关联角色对话框中单击确定。
阿里云账号或RAM用户需要拥有管理AnalyticDB PostgreSQL版的权限(AliyunGPDBFullAccess)。
费用信息
创建实例会产生计算与存储等相关费用,详情请参见产品定价。
免费试用
阿里云提供存储弹性模式实例的免费试用活动,如果您是AnalyticDB PostgreSQL版的新用户,您可以访问阿里云免费试用申请试用资格。如果没有免费试用资格,按照本文操作步骤在控制台创建实例。
使用流程
创建实例
- 登录云原生数据仓库AnalyticDB PostgreSQL版控制台。
单击页面右上角的新建实例,进入实例购买页面。
在实例购买页面,配置核心参数快速完成实例选型,其他参数保持默认即可。如需了解更多参数信息,请参见创建实例。
配置项
说明
本教程示例
商品类型
包年包月:属于预付费,即在新建实例时需要支付费用。适合长期需求,价格比按量付费更实惠,且购买时长越长,折扣越多。
按量付费:属于后付费,即按小时扣费。适合短期需求,用完可立即释放实例,节省费用。
按量付费
地域和可用区
实例所在的地理位置。
购买后无法更换,建议与需要连接的ECS实例创建于同一个地域,以实现内网互通。
华东1(杭州):华东1可用区J
实例资源类型
存储弹性模式:支持独立磁盘扩容,支持在线平滑扩容。
Serverless Pro:只需指定需要的计算资源,无需预留存储资源。
存储弹性模式
引擎版本
推荐选择7.0标准版,以获得更丰富的功能体验。同时支持6.0标准版。
7.0标准版
实例系列
高性能(基础版):适用于大部分业务分析场景。
高可用版:建议企业核心业务采用高可用版本。
高性能(基础版)
向量引擎优化
选择开启。
开启
专有网络(VPC)
选择专有网络VPC的ID。
如需与同地域下的ECS实例内网互连,则需选择与ECS相同的VPC。可选择已有VPC或根据页面提示创建VPC和交换机。
vpc-xxxx
专有网络交换机
选择专有网络下的交换机。如果没有可选的交换机,说明该可用区暂无可用交换机资源。您可以考虑更换至其他可用区,或根据页面提示在当前可用区内创建交换机。
vsw-xxxx
单击立即购买,确认订单信息并单击立即开通。
支付完成后,可单击管理控制台返回实例列表查看新建实例。
说明AnalyticDB PostgreSQL版实例初始化需要一定时间,待实例列表中的实例运行状态显示为运行中,才可进行后续操作。
创建初始账号
AnalyticDB PostgreSQL版提供了两类用户:
高权限用户:初始账号属于高权限用户,具备RDS_SUPERUSER身份,具备数据库的所有操作权限。
普通用户:默认不具备任何权限,需要高权限用户或具有GRANT权限的用户授予单个或多个数据库对象的操作权限。创建方法请参见创建和管理用户。
在左侧导航栏中,单击账号管理。
单击创建初始账号。在创建账号窗口中,填写账号名称并设置密码。然后单击确定。
配置
说明
数据库账号
初始账号的名称,限制如下:
由小写字母,数字和下划线组成。
以小写字母开头,小写字母或数字结尾。
不能以gp开头。
长度为2~16个字符。
新密码、确认密码
初始账号的密码,限制如下:
由大写字母、小写字母、数字、特殊字符其中三种及以上组成。
支持的特殊字符包括
!@#$%^&*()_+-=。长度为8~32个字符。
重要为保障数据安全,建议您定期更换密码。不要使用曾经用过的密码。
准备开发环境
检查Python环境。
本教程基于Python3版本的SDK。请执行以下命令,确认是否已安装Python3.9或以上版本,并安装pip。
如未安装或版本不符合要求,请安装Python。
python -V pip --version安装SDK。
您需要安装
alibabacloud_gpdb20160503和alibabacloud_tea_openapi的SDK,用于身份认证和构建客户端。本教程使用的SDK版本如下。pip install --upgrade alibabacloud_gpdb20160503 alibabacloud_tea_openapi配置环境变量。
将身份认证信息、实例ID等敏感信息配置到环境变量,避免硬编码造成的信息泄露。
Linux&macOS
执行
vim ~/.bashrc命令,打开~/.bashrc文件。macOS系统,请执行
vim ~/.bash_profile。在配置文件中添加以下内容。
在RAM访问控制用户列表页面,单击用户名称,获取RAM用户的AccessKey ID和AccessKey Secret。
在云原生数据仓库AnalyticDB PostgreSQL版控制台查看实例ID和地域ID。
# 用RAM用户的AccessKey ID替换access_key_id export ALIBABA_CLOUD_ACCESS_KEY_ID="access_key_id" # 用RAM用户的AccessKey Secret替换access_key_secret export ALIBABA_CLOUD_ACCESS_KEY_SECRET="access_key_secret" # 用AnalyticDB for PostgreSQL的实例ID替换instance_id,例如gp-bp166cyrtr4p***** export ADBPG_INSTANCE_ID="instance_id" # 用AnalyticDB for PostgreSQL的实例所在地域的地域ID替换instance_region,例如cn-hangzhou export ADBPG_INSTANCE_REGION="instance_region"在vim编辑器中,按下Esc,输入
:wq保存并退出编辑器。执行
source ~/.bashrc命令,使配置文件生效。macOS系统,请执行
source ~/.bash_profile。
Windows
在当前会话中临时设置环境变量,请在CMD中执行以下命令。
# 用RAM用户的AccessKey ID替换access_key_id set ALIBABA_CLOUD_ACCESS_KEY_ID=access_key_id # 用RAM用户的AccessKey Secret替换access_key_secret set ALIBABA_CLOUD_ACCESS_KEY_SECRET=access_key_secret # 用AnalyticDB for PostgreSQL的实例ID替换instance_id,例如gp-bp166cyrtr4p***** set ADBPG_INSTANCE_ID=instance_id # 用AnalyticDB for PostgreSQL的实例所在地域的地域ID替换instance_region,例如cn-hangzhou set ADBPG_INSTANCE_REGION=instance_region
准备数据库环境
准备流程
构建客户端,用于创建向量数据库等操作。
初始化向量数据库。
所有的向量数据都存放在固定的库knowledgebase中,因此每个实例需执行一次初始化。初始化向量数据库的作用:
创建knowledgebase库,并赋予此库的读写权限。
创建中文分词器和全文检索相关功能,此功能为库级别。
创建NameSpace,用于创建文档库。
创建一个文档库(DocumentCollection)用于存储Chunks文本和向量数据。
示例代码
运行前请将account和account_password替换为您实际的数据库账号和密码,其他配置信息可根据实际需求修改。
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_gpdb20160503.client import Client
from alibabacloud_gpdb20160503 import models as gpdb_20160503_models
import os
# --- 从环境变量中获取认证和实例信息 ---
ALIBABA_CLOUD_ACCESS_KEY_ID = os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID']
ALIBABA_CLOUD_ACCESS_KEY_SECRET = os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET']
ADBPG_INSTANCE_ID = os.environ['ADBPG_INSTANCE_ID']
ADBPG_INSTANCE_REGION = os.environ['ADBPG_INSTANCE_REGION']
# 构建并返回一个AnalyticDB for PostgreSQL的API客户端
def get_client():
config = open_api_models.Config(
access_key_id=ALIBABA_CLOUD_ACCESS_KEY_ID,
access_key_secret=ALIBABA_CLOUD_ACCESS_KEY_SECRET
)
config.region_id = ADBPG_INSTANCE_REGION
# https://api.aliyun.com/product/gpdb
if ADBPG_INSTANCE_REGION in ("cn-beijing", "cn-hangzhou", "cn-shanghai", "cn-shenzhen", "cn-hongkong",
"ap-southeast-1"):
config.endpoint = "gpdb.aliyuncs.com"
else:
config.endpoint = f'gpdb.{ADBPG_INSTANCE_REGION}.aliyuncs.com'
return Client(config)
# 初始化向量数据库
def init_vector_database(account, account_password):
request = gpdb_20160503_models.InitVectorDatabaseRequest(
region_id=ADBPG_INSTANCE_REGION,
dbinstance_id=ADBPG_INSTANCE_ID,
manager_account=account,
manager_account_password=account_password
)
response = get_client().init_vector_database(request)
print(f"init_vector_database response code: {response.status_code}, body:{response.body}")
# 创建一个命名空间(Namespace)
def create_namespace(account, account_password, namespace, namespace_password):
request = gpdb_20160503_models.CreateNamespaceRequest(
region_id=ADBPG_INSTANCE_REGION,
dbinstance_id=ADBPG_INSTANCE_ID,
manager_account=account,
manager_account_password=account_password,
namespace=namespace,
namespace_password=namespace_password
)
response = get_client().create_namespace(request)
print(f"create_namespace response code: {response.status_code}, body:{response.body}")
# 创建一个文档集合(Document Collection)
def create_document_collection(account,
account_password,
namespace,
collection,
metadata: str = None,
full_text_retrieval_fields: str = None,
parser: str = None,
embedding_model: str = None,
metrics: str = None,
hnsw_m: int = None,
pq_enable: int = None,
external_storage: int = None,):
request = gpdb_20160503_models.CreateDocumentCollectionRequest(
region_id=ADBPG_INSTANCE_REGION,
dbinstance_id=ADBPG_INSTANCE_ID,
manager_account=account,
manager_account_password=account_password,
namespace=namespace,
collection=collection,
metadata=metadata,
full_text_retrieval_fields=full_text_retrieval_fields,
parser=parser,
embedding_model=embedding_model,
metrics=metrics,
hnsw_m=hnsw_m,
pq_enable=pq_enable,
external_storage=external_storage
)
response = get_client().create_document_collection(request)
print(f"create_document_collection response code: {response.status_code}, body:{response.body}")
if __name__ == '__main__':
# AnalyticDB PostgreSQL版实例的数据库初始账号。
account = "testacc"
# 初始账号对应的密码。
account_password = "Test1234"
# 要创建的Namespace名称。
namespace = "ns1"
# Namespace对应的密码,后续数据读写使用此密码。
namespace_password = "ns1password"
# 要创建的文档库名称。
collection = "dc1"
metadata = '{"title":"text", "page":"int"}'
full_text_retrieval_fields = "title"
embedding_model = "m3e-small"
init_vector_database(account, account_password)
create_namespace(account, account_password, namespace, namespace_password)
create_document_collection(account,account_password, namespace, collection,
metadata=metadata, full_text_retrieval_fields=full_text_retrieval_fields,
embedding_model=embedding_model)参数说明
参数 | 说明 |
account | AnalyticDB PostgreSQL版实例的数据库初始账号。 |
account_password | 初始账号对应的密码。 |
namespace | 要创建的Namespace名称。 |
namespace_password | Namespace对应的密码,后续数据读写使用此密码。 |
collection | 要创建的文档库名称。 |
metadata | 自定义map结构的数据元信息,key为字段名,value为字段类型。 |
full_text_retrieval_fields | 自定义的逗号分隔的全文检索字段,字段必须属于metadata的key。 |
parser | 全文检索参数,分词器,默认zh_cn。 |
embedding_model | |
metrics | 向量索引参数,索引算法。 |
hnsw_m | 向量索引参数,HNSW算法中的最大邻居数,范围1~1000。 |
pq_enable | 向量索引参数,索引是否开启PQ(Product quantization)算法加速。 |
external_storage | 向量索引参数,是否使用mmap缓存。 重要 仅6.0版本支持参数external_storage。7.0版本暂不支持。 |
查看表结构
上述代码调用成功后,您可以按照一下步骤登录数据库,查看表结构:
单击目标实例详情页右上角的登录数据库。
在登录实例页面输入数据库账号和数据库密码,单击登录。
登录成功后,您可以看到目标实例的数据库中新增了一个名为“knowledgebase”的数据库,在“knowledgebase”库中创建了一个名为“ns1”的Schema,在对应Schema下,创建了一个名为“dc1”的表,表结构如下。
字段 | 类型 | 字段来源 | 说明 |
id | text | 固定字段 | 主键,表示单条Chunk文本的UUID。 |
vector | real[] | 固定字段 | 向量数据ARRAY,长度对应指定的Embedding模型的维度。 |
doc_name | text | 固定字段 | 文档名称。 |
content | text | 固定字段 | 单条Chunk文本,由文档在Loader和Splitter后得到。 |
loader_metadata | json | 固定字段 | 文档在Loader解析时对应的元数据。 |
to_tsvector | TSVECTOR | 固定字段 | 保存全文检索字段,数据来源为full_text_retrieval_fields指定的字段数据。其中content为默认字段,本调用场景表示会从content和title两个数据源做全文检索。 |
title | text | Metadata定义 | 用户自定义。 |
page | int | Metadata定义 | 用户自定义。 |
文档管理
上传文档。
本文以通过异步方式上传本地文档为例,示例代码如下:
import time import io from typing import Dict, List, Any from alibabacloud_tea_util import models as util_models from alibabacloud_gpdb20160503 import models as gpdb_20160503_models def upload_document_async( namespace, namespace_password, collection, file_name, file_path, metadata: Dict[str, Any] = None, chunk_overlap: int = None, chunk_size: int = None, document_loader_name: str = None, text_splitter_name: str = None, dry_run: bool = None, zh_title_enhance: bool = None, separators: List[str] = None, vl_enhance: bool = None, splitter_model: str = None): with open(file_path, 'rb') as f: file_content_bytes = f.read() request = gpdb_20160503_models.UploadDocumentAsyncAdvanceRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, file_name=file_name, metadata=metadata, chunk_overlap=chunk_overlap, chunk_size=chunk_size, document_loader_name=document_loader_name, file_url_object=io.BytesIO(file_content_bytes), text_splitter_name=text_splitter_name, dry_run=dry_run, zh_title_enhance=zh_title_enhance, separators=separators, vl_enhance=vl_enhance, splitter_model=splitter_model, ) response = get_client().upload_document_async_advance(request, util_models.RuntimeOptions()) print(f"upload_document_async response code: {response.status_code}, body:{response.body}") return response.body.job_id def wait_upload_document_job(namespace, namespace_password, collection, job_id): def job_ready(): request = gpdb_20160503_models.GetUploadDocumentJobRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, job_id=job_id, ) response = get_client().get_upload_document_job(request) print(f"get_upload_document_job response code: {response.status_code}, body:{response.body}") return response.body.job.completed while True: if job_ready(): print("successfully load document") break time.sleep(2) if __name__ == '__main__': job_id = upload_document_async("ns1", "Ns1password", "dc1", "test.pdf", "/root/test.pdf") wait_upload_document_job("ns1", "Ns1password", "dc1", job_id)参数说明
参数
说明
namespace
文档库所在的Namespace名称。
namespace_password
Namespace的密码。
collection
文档要存入的文档库名称。
file_name
文档名称,带有类型后缀。
file_path
本地的文档路径,文件最大200 MB。
metadata
文档的元数据,需要和创建文档库时指定的元数据一致。
chunk_overlap
处理大型数据的切分策略。在分块处理时,连续的块之间重叠的数据量,最大值不能超过chunk_size。
chunk_size
处理大型数据的切分策略,数据拆分成较小的部分时每个块的大小,最大值为2048。
document_loader_name
建议无需指定,会按照文件扩展名自动匹配加载器。自动匹配加载器的详情,请参见文档理解。
text_splitter_name
切分器名称。文档切分详情,请参见文档切分。
dry_run
是否只进行文档理解和切分,不进行向量化和入库。取值说明:
true:只进行文档理解和切分。
false(默认):先进行文档理解和切分,然后进行向量化和入库。
zh_title_enhance
是否开启中文标题加强。取值说明:
true:开启中文标题加强。
false:关闭中文标题加强。
separators
处理大型数据切分策略的分隔符,一般无需指定。
vl_enhance
指定是否开启复杂文档的VL增强内容识别。取值说明:
true:开启文档VL增强内容识别。
false:关闭文档VL增强内容识别。
splitter_model
当document_loader_name指定ADBPGLoader,且text_splitter_name指定LLMSplitter时,可指定切分模型,默认模型使用qwen3-8b。
说明当前支持的切分模型: qwq-plus,qwq-plus-latest,qwen-max,qwen-max-latest,qwen-plus,qwen-plus-latest,qwen-turbo,qwen-turbo-latest,qwen3-235b-a22b,qwen3-32b,qwen3-30b-a3b,qwen3-14b,qwen3-8b,qwen3-4b,qwen3-1.7b,qwen3-0.6b,qwq-32b,qwen2.5-14b-instruct-1m,qwen2.5-7b-instruct-1m,qwen2.5-72b-instruct,qwen2.5-32b-instruct,qwen2.5-14b-instruct,qwen2.5-7b-instruct,qwen2.5-3b-instruct,qwen2.5-1.5b-instruct,qwen2.5-0.5b-instruct。
(可选)其他文档管理操作。
查看文档列表
def list_documents(namespace, namespace_password, collection): request = gpdb_20160503_models.ListDocumentsRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, ) response = get_client().list_documents(request) print(f"list_documents response code: {response.status_code}, body:{response.body}") if __name__ == '__main__': list_documents("ns1", "Ns1password", "dc1")参数说明
参数
说明
namespace
文档库所在的Namespace名称。
namespace_password
Namespace的密码。
collection
文档库名称。
查看文档详情
def describe_document(namespace, namespace_password, collection, file_name): request = gpdb_20160503_models.DescribeDocumentRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, file_name=file_name ) response = get_client().describe_document(request) print(f"describe_document response code: {response.status_code}, body:{response.body}") if __name__ == '__main__': describe_document("ns1", "Ns1password", "dc1", "test.pdf")参数说明
参数
说明
namespace
文档库所在的Namespace名称。
namespace_password
Namespace的密码。
collection
文档库名称。
file_name
文档名称。
返回信息
参数
说明
DocsCount
文档被切分的块数量。
TextSplitter
文档切分器名称。
DocumentLoader
文档Loader名称。
FileExt
文档扩展名。
FileMd5
文档MD5 HASH值。
FileMtime
文档最新上传时间。
FileSize
文件大小,单位为字节。
FileVersion
文档版本,INT类型,代表此文档被上传更新了多少次。
删除文档
def delete_document(namespace, namespace_password, collection, file_name): request = gpdb_20160503_models.DeleteDocumentRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, file_name=file_name ) response = get_client().delete_document(request) print(f"delete_document response code: {response.status_code}, body:{response.body}") if __name__ == '__main__': delete_document("ns1", "Ns1password", "dc1", "test.pdf")参数说明
参数
说明
namespace
文档库所在的Namespace名称。
namespace_password
Namespace的密码。
collection
文档库名称。
file_name
文档名称。
文档检索
本节以使用纯文本检索为例,示例代码如下:
def query_content(namespace, namespace_password, collection, top_k,
content,
filter_str: str = None,
metrics: str = None,
use_full_text_retrieval: bool = None):
request = gpdb_20160503_models.QueryContentRequest(
region_id=ADBPG_INSTANCE_REGION,
dbinstance_id=ADBPG_INSTANCE_ID,
namespace=namespace,
namespace_password=namespace_password,
collection=collection,
content=content,
filter=filter_str,
top_k=top_k,
metrics=metrics,
use_full_text_retrieval=use_full_text_retrieval,
)
response = get_client().query_content(request)
print(f"query_content response code: {response.status_code}, body:{response.body}")
if __name__ == '__main__':
query_content('ns1', 'Ns1password', 'dc1', 10, 'ADBPG是什么?')参数说明
参数 | 说明 |
namespace | 文档库所在的Namespace名称。 |
namespace_password | Namespace的密码。 |
collection | 文档库名称。 |
top_k | 返回相似度最高的检索结果数量。 |
content | 要检索的文本内容。 |
filter_str | 检索前的过滤语句。 |
metrics | 向量距离算法,建议不设置,会按照创建索引时的算法计算。 |
use_full_text_retrieval | 是否使用全文检索,取值说明如下:
|
返回信息
参数 | 说明 |
Id | 切分后的Chunk对应的UUID。 |
FileName | 文档名称。 |
Content | 检索的内容,即切分后的一条Chunk。 |
LoaderMetadata | 在文档上传时产生的Metadata数据。 |
Metadata | 用户自定义的Metadata数据。 |
RetrievalSource | 检索来源,取值说明如下:
|
Score | 按照指定的相似度算法得到的相似度分数。 |
集成LangChain
LangChain是一套基于大语言模型(LLM)构建应用的开源框架,可实现通过一整套接口和工具将模型和外部数据连接。下文将展示如何将AnalyticDB PostgreSQL版的检索能力集成到LangChain中实现一个问答系统。
安装模块。
pip install --upgrade langchain openai tiktoken构建AdbpgRetriever。
from langchain_core.retrievers import BaseRetriever from langchain_core.callbacks import CallbackManagerForRetrieverRun from langchain_core.documents import Document class AdbpgRetriever(BaseRetriever): namespace: str = None namespace_password: str = None collection: str = None top_k: int = None use_full_text_retrieval: bool = None def query_content(self, content) -> List[gpdb_20160503_models.QueryContentResponseBodyMatchesMatchList]: request = gpdb_20160503_models.QueryContentRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=self.namespace, namespace_password=self.namespace_password, collection=self.collection, content=content, top_k=self.top_k, use_full_text_retrieval=self.use_full_text_retrieval, ) response = get_client().query_content(request) return response.body.matches.match_list def _get_relevant_documents( self, query: str, *, run_manager: CallbackManagerForRetrieverRun ) -> List[Document]: match_list = self.query_content(query) return [Document(page_content=i.content) for i in match_list]创建Chain。
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain.schema import StrOutputParser from langchain_core.runnables import RunnablePassthrough OPENAI_API_KEY = "YOUR_OPENAI_API_KEY" os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY template = """Answer the question based only on the following context: {context} Question: {question} """ prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() def format_docs(docs): return "\n\n".join([d.page_content for d in docs]) retriever = AdbpgRetriever(namespace='ns1', namespace_password='Ns1password', collection='dc1', top_k=10, use_full_text_retrieval=True) chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | model | StrOutputParser() )问答。
chain.invoke("AnalyticDB PostgreSQL是什么?") # 回答: # AnalyticDB PostgreSQL是阿里云提供的一种云原生在线分析处理(OLAP)服务,它基于开源的PostgreSQL数据库扩展,提供了高性能、高容量的数据仓库解决方案。 # 它结合了PostgreSQL的灵活性和兼容性以及用于数据分析和报告的高并发和高速查询能力。 # # AnalyticDB PostgreSQL特别适合处理大规模数据集,支持实时分析和决策支持,是企业进行数据挖掘、商业智能(BI)、报告和数据可视化的有力工具。 # 作为一种托管服务,它简化了数据仓库的管理和运维,让用户能够专注于数据分析而不是底层基础设施。 # 主要特点包括: # # 高性能分析 - 使用列式存储和大规模并行处理(MPP)架构来快速查询和分析大量数据。 # 易于扩展 - 根据数据量和查询性能要求,容易横向和纵向扩展资源。 # 兼容 PostgreSQL - 支持PostgreSQL SQL语言和生态系统中的大部分工具,便于现有 PostgreSQL 用户迁移和适应。 # 安全和可靠 - 提供数据备份、恢复和加密等功能,确保数据的安全性和可靠性。 # 云原生集成 - 与阿里云的其他服务如数据集成、数据可视化工具等紧密集成。 # 总之,AnalyticDB PostgreSQL是一个高性能、可扩展的云数据仓库服务,允许企业在云环境中进行复杂的数据分析和报告。
附录
全文检索
为了提高检索的精度,除了向量相似度外,AnalyticDB PostgreSQL版还支持全文检索,并且能和向量相似度检索同时使用达到双路召回效果。
定义全文检索字段。
在使用全文检索前,首先需指定哪些字段用于全文检索的数据源,文档库的接口已经默认使用content字段,您还可以指定其他的Metadata自定义字段。
分词
创建文档库时可以指定Parser字段作为分词器,一般场景下,使用默认的中文zh_ch即可,如果有特殊的分词字符要求,请联系阿里云技术支持。
在插入数据时,分词器会将全文检索指定字段的数据按照分词符切分,保存到to_tsvector中,供后续全文检索使用。
Embedding模型
云原生数据仓库 AnalyticDB PostgreSQL 版支持如下Embedding模型:
embedding_model | 维度 | 说明 |
m3e-small | 512 | 来源于moka-ai/m3e-small,仅支持中文,不支持英文。 |
m3e-base | 768 | 来源于moka-ai/m3e-base,支持中英文。 |
text2vec | 1024 | 来源于GanymedeNil/text2vec-large-chinese,支持中英文。 |
text-embedding-v1 | 1536 | 来源于百炼的通用文本向量,支持中英文。 |
text-embedding-v2 | 1536 | text-embedding-v1的升级版。 |
clip-vit-b-32(多模) | 512 | 开源的多模模型,支持图片。 |
暂不支持使用自定义Embedding模型。
支持更多模型,请参见创建文档库。
向量索引
向量索引支持设置如下参数:
参数 | 说明 |
metrics | 相似度距离度量算法,取值说明如下:
|
hnsw_m | HNSW算法中的最大邻居数。OpenAPI会根据向量维度自动设置不同的值。 |
pq_enable | 是否开启PQ向量降维的功能,取值说明如下:
PQ向量降维依赖于存量的向量样本数据进行训练,如果数据量小于50w时,不建议设置此参数。 |
external_storage | 是否使用mmap构建HNSW索引,取值说明如下:
重要 仅6.0版本支持参数external_storage。7.0版本暂不支持。 |
文档理解
您可以根据文档类型选用合适的loader:
ADBPGLoader:
.pdf、.doc、.docx、.ppt、.pptx、.xls、.xlsx、.xlsm、.csv、.txt、.jpg、.jpeg、.png、.bmp、.gif、.md、.html、.epub、.mobi或.rtf重要指定ADBPGLoader时,前3000页免费,之后需付费,0.005元/页。
UnstructuredHTMLLoader:
.htmlUnstructuredMarkdownLoader:
.mdPyMuPDFLoader:
.pdfPyPDFLoader:
.pdfRapidOCRPDFLoader:
.pdfJSONLoader:
.jsonCSVLoader:
.csvRapidOCRLoader:
.png、.jpg、.jpeg或.bmpUnstructuredFileLoader:
.eml、.msg、.rst、.txt、.xml、.docx、.epub、.odt、.pptx或.tsv
如果未指定document_loader_name,会根据文档名后缀自动决定使用的loader。当一个文档类型有多个loader时,如pdf,可以指定其中任一个。
文档切分
文档切分的效果由chunk_overlap、chunk_size、text_splitter_name、splitter_model几部分决定,其中text_splitter_name取值说明如下:
ChineseRecursiveTextSplitter:继承于RecursiveCharacterTextSplitter,默认以
["\n\n","\n", "。|!|?","\.\s|\!\s|\?\s", ";|;\s", ",|,\s"]作为分隔符,使用正则匹配,中文比 RecursiveCharacterTextSplitter效果更好一些。SpacyTextSplitter:默认以
["\n\n", "\n", " ", ""]作为分隔符。可以支持c++、go、java、js、php、proto、python、rst、ruby、rust、scala、swift、markdown、latex、html、sol、csharp等多种代码语言的切分。RecursiveCharacterTextSplitter:默认分隔符为
\n\n,使用Spacy库的en_core_web_sm模型来分隔,对全英文文档支持较好。MarkdownHeaderTextSplitter:针对markdown类型,使用
[ ("#", "head1"), ("##", "head2"), ("###", "head3"), ("####", "head4") ]来切分。LLMSplitter:使用LLM对文本进行切分。目前该分隔器仅在document_loader_name选用ADBPGLoader时生效。选用该分隔器时,可指定splitter_model,默认模型使用qwen3-8b。