
AnalyticDB PostgreSQL稀疏向量使用指南
当您需要高效存储大部分元素为零的向量时,创建稀疏向量表比稠密向量表能节省大量的存储空间。本文介绍云原生数据仓库AnalyticDB PostgreSQL版向量数据库如何使用稀疏向量,包括创建稀疏向量表、构建稀疏向量索引、执行稀疏向量检索,以及执行稀疏向量和稠密向量的混合查询等。
背景简介
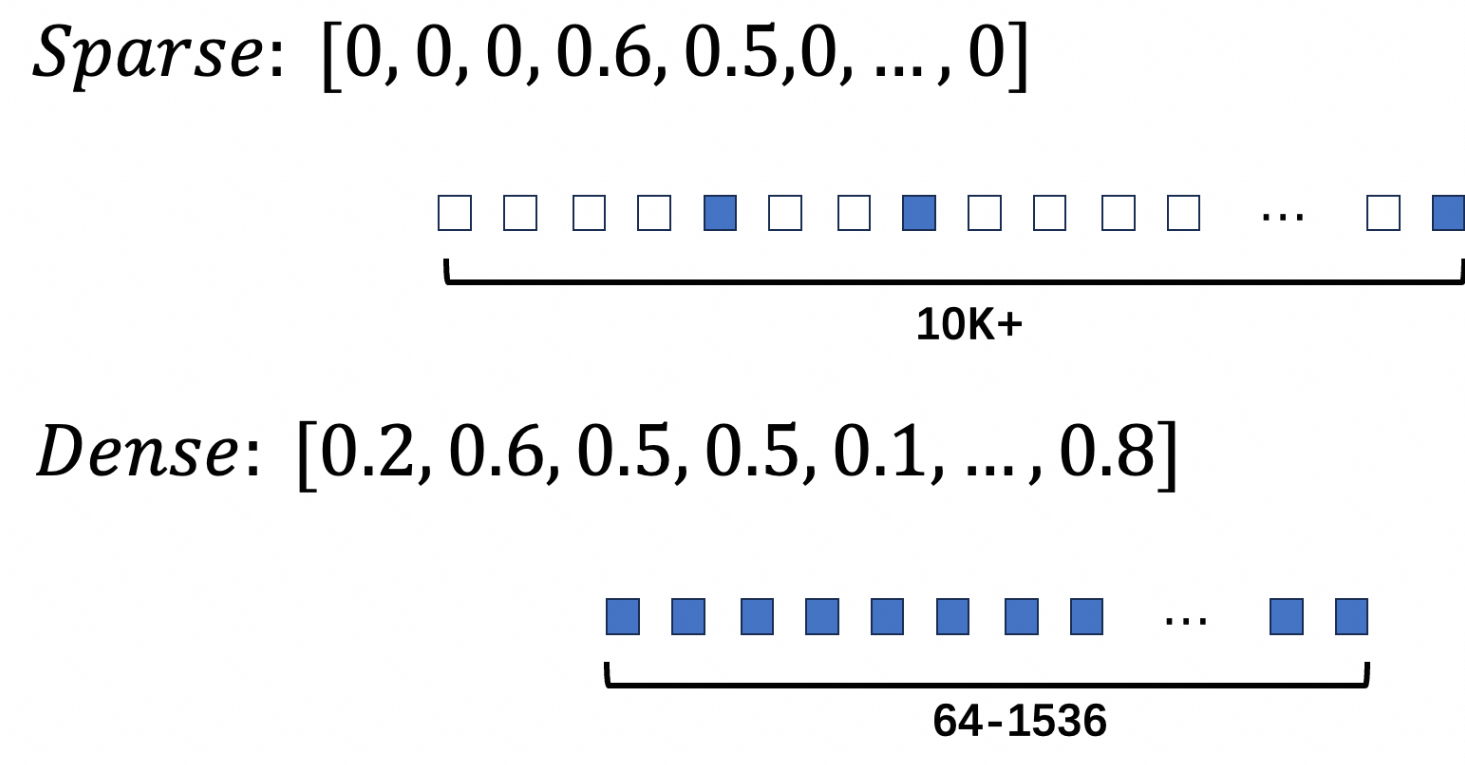
在向量数据库中,向量通常分为稠密向量(Dense)和稀疏向量(Sparse)。稀疏向量是一种大部分元素都是零的数据结构,通常有数万个维度,但只有少数维度有实际值。这种数据结构特别适用于表示文本、图像等类型的数据。在关键词检索中,一个稀疏向量就表示一个文档,其维度对应字典中的关键词,值表示关键词的重要性。如果使用BM25算法生成稀疏向量,维度的值包含关键词匹配数量、词频和其他文本相关性因素。与普通数组或列表相比,稀疏向量能够高效存储和操作高维数据,显著减少存储空间和计算资源的消耗。这种数据结构在机器学习和自然语言处理中非常有用,适用于处理稀疏特征的场景。
稠密向量和稀疏向量的区别如下图所示:
前提条件
已创建云原生数据仓库AnalyticDB PostgreSQL版v6.6.2.3及以上版本实例。具体操作,请参见创建实例。
已开启向量检索引擎功能,请参见开启或关闭向量检索引擎优化。
使用稀疏向量
创建稀疏向量表
语法
CREATE TABLE <SparseVectorTable>
(
id int PRIMARY KEY,
description text,
...,
sparse_vector svector(MAX_DIM),
)DISTRIBUTED BY(id);参数说明:
SparseVectorTable:向量表名称。
sparse_vector:稀疏向量列,为svector类型。
MAX_DIM:稀疏向量的最大维度(非有值维度数量)。
使用示例
创建一个名为svector_test的稀疏向量表,具体示例如下:
-- 创建一个带稀疏向量字段的表
CREATE TABLE <svector_test>(
id bigint,
type int,
tag varchar(10),
document text,
sparse_features svector(250000)
) DISTRIBUTED BY (id);
-- 设置稀疏向量列为Plain模式
ALTER TABLE <svector_test> ALTER COLUMN sparse_features SET storage plain;Plain模式:在PostgreSQL中 ,存储机制对于大对象、大字段或无法容纳在常规数据页内的数据采用了一种名为Toast的策略。这种策略允许数据的高效存储和访问。当字段使用Plain策略存储时,数据被存储为非压缩和非分裂的一整块,数据必须完全适应单个数据项,不会溢出到Toast表中。Plain模式通常用于需要避免Toast处理开销的小数据字段,或者可以被高效存储的数据类型,例如整数或小文本字段。
创建稀疏向量索引
语法
稀疏向量的索引仅支持内积距离度量,不支持PQ量化和MMAP模式。语法规则如下:
CREATE INDEX <idx_sparse_vector>
ON MyTable USING vector_index (sparse_vector_column);
WITH (DISTANCEMEASURE=IP,
HNSW_M=$M,
HNSW_EF_CONSTRUCTION=$EF_CONSTURCTION);参数说明:
idx_sparse_vector:向量索引名称。
DISTANCEMEASURE:取值为IP,否则会出现参数报错。
HNSW_M和HNSW_EF_CONSTRUCTION:参考创建向量索引。
使用示例
以使用示例中的svector_test稀疏向量表为例,创建稀疏向量索引,具体示例如下:
-- 根据混合查询的结构化字段为其创建btree索引,如果结构化字段为数组类型,也可以添加gin索引
CREATE INDEX svector_test(type);
CREATE INDEX svector_test(tag);
-- 为稀疏向量列创建一个HNSW索引
CREATE INDEX ON svector_test USING ANN(sparse_features) WITH(DISTANCEMEASURE=IP,HNSW_M=64,pq_enable=0,external_storage=0);稀疏向量数据的表示
在云原生数据仓库AnalyticDB PostgreSQL版中,通过使用svector类型可以表示稀疏向量。svector类型支持以JSON格式的字符串输入,需要包含indices字段和values字段,分别表示下标数组(非负整数)和对应的值数组(浮点数)。一个20维的稀疏向量可以作如下数据表示:
稀疏向量数据示例
[0, 0, 1.1, 0, 0, 0, 2.2, 0, 0, 3.3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]稀疏向量数据表示
{"indices":[2, 6, 9], "values":[1.1, 2.2, 3.3]}参数说明:
indices:[2, 6, 9]表示稀疏向量中非0值的维度为第2,6,9维。
values:[1.1, 2.2, 3.3]表示对应的三个非0维度的取值为1.1,2.2,3.3。
在云原生数据仓库AnalyticDB PostgreSQL版数据库中,使用svector可以将字符串转换为稀疏向量类型,SQL语句如下所示:
postgres=# SELECT '{"indices":[2, 6, 9], "values":[1.1, 2.2, 3.3]}'::svector;
svector
--------------------------------------------
{"indices":[2,6,9],"values":[1.1,2.2,3.3]}
(1 ROW)稀疏向量数据的导入
稀疏向量的数据导入支持INSERT和COPY语法,以使用示例中的svector_test稀疏向量表为例,介绍INSERT的使用方法,具体示例如下:
-- 插入稀疏向量
INSERT INTO svector_test VALUES (1, 1, 'a', 'xxx', '{"indices":[2, 6, 9], "values":[1.1, 2.2, 3.3]}'::svector);
INSERT INTO svector_test VALUES (2, 2, 'b', 'xxx', '{"indices":[50, 100, 200], "values":[2.1, 3.2, 4.3]}'::svector);
INSERT INTO svector_test VALUES (3, 3, 'b', 'xxx', '{"indices":[150, 60, 90], "values":[5, 1e3, 1e-3]}'::svector);稀疏向量的检索
稀疏向量检索分为精确检索和近似检索。
精确检索:完全按照相似度距离排序的暴力检索。该方式需要比较每一个向量,因此检索速度慢,但是召回率可以达到100%。该方法适用于对实时性要求不高,但对精确度要求高的场景。
近似检索:通过优化算法快速找到近似的结果。虽然精确度有所降低,但检索速度快。该方法适用于对实时性要求较高,但对精确度要求不严格的场景。
语法
对于稀疏向量表来说,稀疏向量检索只支持内积距离度量的检索方式。精确检索和近似检索的语法如下。
精确检索
SELECT id, inner_product(<sparse_vector>, '{"indices":[1,2,..], "values":[1.1,2.2...]}'::svector)
AS score FROM <SparseVectorTable> ORDER BY negative_inner_product(<sparse_vector>,
'{"indices":[1,2,..], "values":[1.1,2.2...]}'::svector) LIMIT <topk>;参数说明:
sparse_vector:向量列名称。
SparseVectorTable:向量表名称。
topk:需要检索的结果集topk。
近似检索
SELECT id, inner_product(<sparse_vector>, '{"indices":[1,2,..], "values":[1.1,2.2...]}'::svector)
AS score FROM <SparseVectorTable> ORDER BY <sparse_vector>
'{"indices":[1,2,..], "values":[1.1,2.2...]}'::svector LIMIT <topk>;参数说明:
sparse_vector:向量列名称。
SparseVectorTable:向量表名称。
topk:需要检索的结果集topk。
使用示例
以使用示例中的svector_test稀疏向量表为例,使用稀疏向量检索的示例如下:
稀疏向量检索
SELECT id, sparse_features,
'{"indices":[2,60,50], "values":[2,0.01, 0.02]}' <#> sparse_features AS score
FROM svector_test
ORDER BY score
LIMIT 3;检索结果
id | sparse_features | score
--------+-------------------------------------------------+---------------------
3 | {"indices":[60,90,150],"values":[1000,0.001,5]} | -10
1 | {"indices":[2,6,9],"values":[1.1,2.2,3.3]} | -2.20000004768372
2 | {"indices":[50,100,200],"values":[2.1,3.2,4.3]} | -0.0419999957084656
(3 ROWS)稀疏向量的向量检索召回率,可以通过fastann.sparse_hnsw_max_scan_points和fastann.sparse_hnsw_ef_search进行调节。具体内容,请参见相关参考。
稠密向量与稀疏向量的混合查询
创建一个同时包含稀疏向量和稠密向量的数据表HYBRID_SEARCH_TEST,并以此为基础介绍如何实现稠密向量和稀疏向量的混合查询,具体建表SQL语句示例如下:
-- 创建混合查询的数据表
CREATE TABLE IF NOT EXISTS HYBRID_SEARCH_TEST (
id integer PRIMARY key,
corpus text,
filter integer,
dense_vector float4[],
sparse_vector svector(250003)
) distributed BY (id);
-- 设置向量列为Plain模式
ALTER TABLE hybrid_search_test ALTER COLUMN dense_vector SET storage plain;
ALTER TABLE hybrid_search_test ALTER COLUMN sparse_vector SET storage plain;创建索引的SQL语句示例如下:
-- 创建结构化索引
CREATE INDEX ON hybrid_search_test(FILTER);
-- 创建稠密向量索引
CREATE INDEX ON hybrid_search_test USING ANN(dense_vector) WITH(DISTANCEMEASURE=IP, DIM=1024, HNSW_M=64, HNSW_EF_CONSTRUCTION=600, EXTERNAL_STORAGE=1);
-- 创建稀疏向量索引
CREATE INDEX ON hybrid_search_test USING ANN(sparse_vector) WITH(DISTANCEMEASURE=IP, HNSW_M=64, HNSW_EF_CONSTRUCTION=600);稠密向量查询、稀疏向量查询以及混合查询的SQL语句示例如下:
-- 向量检索 + filter
SELECT id, corpus FROM hybrid_search_test WHERE FILTER IN (0, 100, 200, 300, 400, 500, 600, 700, 800, 900) ORDER BY dense_vector <#> ARRAY[1,2,3,...,1024]::float4[] LIMIT 100;
-- sparse检索 + filter
SELECT id, corpus FROM hybrid_search_test WHERE FILTER IN (0, 100, 200, 300, 400, 500, 600, 700, 800, 900) ORDER BY sparse_vector <#> '{"indices":[1,2,..], "values":[1.1,2.2...]}'::svector LIMIT 100;
-- 混合检索 + filter
WITH combined AS (
(SELECT id, corpus, inner_product_distance(dense_vector, ARRAY[1,2,3,...,1024]::float4[]) AS dist1, sparse_vector <#> '{"indices":[1,2,..], "values":[1.1,2.2...]}'::svector AS dist2 FROM hybrid_search_test WHERE FILTER IN (0, 100, 200, 300, 400, 500, 600, 700, 800, 900) ORDER BY dist2 LIMIT 100)
UNION ALL
(SELECT id, corpus, inner_product(sparse_vector, '{"indices":[1,2,..], "values":[1.1,2.2...]}'::svector) AS dist1, dense_vector <#> ARRAY[1,2,3,...,1024]::float4[] AS dist2 FROM hybrid_search_test WHERE FILTER IN (0, 100, 200, 300, 400, 500, 600, 700, 800, 900) ORDER BY dist2 LIMIT 100 )
) SELECT DISTINCT first_value(id) OVER (PARTITION BY id) AS id, first_value(corpus) OVER (PARTITION BY id) AS corpus, MAX(dist1 - dist2) OVER (PARTITION BY id) AS dist FROM combined ORDER BY dist DESC LIMIT 100;相关参考
稀疏向量检索相关的内核参数
稀疏向量检索相关的内核参数 | 功能说明 | 默认值 | 取值范围 |
fastann.sparse_hnsw_max_scan_points | 在HNSW索引中进行稀疏向量检索时,最大扫描点个数,用于提前结束检索,可用于召回率测试。 | 8000 | [1, 8000000] |
fastann.sparse_hnsw_ef_search | 在HNSW索引中进行稀疏向量检索时,检索候选集大小,可用于召回率测试。 | 400 | [10, 10000] |
上述内核参数可以在会话级别设置生效。
稀疏向量支持的向量函数
函数作用 | 向量函数 | 返回值类型 | 含义 | 支持的数据类型 |
l2_distance | double_precision | 欧氏距离(开方值),通常用于衡量两个稀疏向量的大小,表示两个稀疏向量的距离。 | svector | |
计算 | inner_product | double precision | 内积距离,在向量归一化之后等于余弦相似度,通常用于在向量归一化之后替代余弦相似度。 | svector |
dp_distance | double precision | 点积距离,和内积距离完全一致。 | svector | |
cosine_similarity | double precision | 余弦相似度,取值范围:[-1, 1],通常用于衡量两个稀疏向量在方向上的相似性,而不关心两个稀疏向量的实际长度。 | svector | |
svector_add | svector | 两个稀疏向量的加法。 | svector | |
svector_sub | svector | 两个稀疏向量的减法。 | svector | |
svector_mul | svector | 两个稀疏向量的乘法。 | svector | |
svector_norm | double precision | 计算单个稀疏向量的模长。 | svector | |
svector_angle | double precision | 计算两个稀疏向量的夹角。 | svector | |
排序 | l2_squared_distance | double precision | 欧氏距离(平方值),由于比欧氏距离(开方值)少了开方的计算,因此主要用于对欧氏距离(开方值)的排序逻辑,以减少计算量。 | svector |
negative_inner_product | double precision | 反内积距离,为内积距离取反后的结果,主要用于对内积距离的排序逻辑,以保证排序结果按内积距离从大到小排序。 | svector | |
cosine_distance | double precision | 余弦距离,取值范围:[0, 2],主要用于对余弦相似度的排序逻辑,以保证排序结果按余弦相似度从大到小排序。 | svector |
向量函数的使用示例
-- 欧氏距离
SELECT l2_distance('{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector, '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector);
-- 内积距离
SELECT inner_product('{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector, '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector);
-- 余弦相似度
SELECT l2_distance('{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector, '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector);
-- 向量加法
SELECT svector_add('{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector, '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector);
-- 向量减法
SELECT svector_sub('{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector, '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector);
-- 向量乘法
SELECT svector_mul('{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector, '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector);
-- 欧氏平方距离
SELECT l2_squared_distance('{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector, '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector);
-- 反内积距离
SELECT negative_inner_product('{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector, '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector);
-- 余弦距离
SELECT cosine_distance('{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector, '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector);稀疏向量支持的向量操作符
操作符 | 计算含义 | 排序含义 | 支持的数据类型 |
<-> | 获取欧氏距离(平方),结果等同于l2_squared_distance。 | 无 | svector |
<#> | 获取反内积,结果等同于negative_inner_product | 按点积距离从大到小排序。 | svector |
<#> | 获取余弦距离,结果等同于cosine_distance。 | 无 | svector |
+ | 两个稀疏向量的加法。 | 无 | svector |
- | 两个稀疏向量的减法。 | 无 | svector |
* | 两个稀疏向量的乘法。 | 无 | svector |
向量操作符示例
-- 欧氏平方距离
SELECT '{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector <-> '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector AS score;
-- 反内积距离
SELECT '{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector <#> '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector AS score;
-- 余弦距离
SELECT '{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector <=> '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector AS score;
-- 加法
SELECT '{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector + '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector AS value;
-- 减法
SELECT '{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector + '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector AS value;
-- 乘法
SELECT '{"indices":[1,2,3,4,5,6], "values":[1,2,3,4,5,6]}'::svector * '{"indices":[1,2,3,4,5,6], "values":[2,3,4,5,6,7]}'::svector AS value;