
数据清洗
数据清洗功能提供常见的消息处理模板,包括内容分割、动态路由、内容富化和内容映射等。您可以直接利用模板处理消息,也可以根据业务情况在模板基础上修改代码。
背景信息
消息数据清洗任务提供基本的算子能力,底层逻辑使用函数计算。支持进行数据清洗的产品包含云消息队列 RocketMQ 版、云消息队列 Kafka 版、云消息队列 MQTT 版、云消息队列 RabbitMQ 版消息服务。数据清洗任务创建完成后,您可以登录函数计算控制台,进行代码自定义及相应函数配置的修改。
算子 | 算子能力说明 |
内容分割 | 根据正则表达式对消息内容进行分割,将分割后的消息逐条发送至目标。 |
动态路由 | 根据正则表达式匹配消息内容,将匹配成功的消息路由至对应目标,将匹配不成功的消息路由至默认目标。 |
内容富化 | 根据富化源对消息内容进行富化。如果消息原始内容包含AccountID,处理时根据AccountID查询数据库,获得客户地域后填至源消息体中,并发送至目标服务。 |
内容映射 | 根据正则表达式对消息内容进行映射处理。例如,屏蔽消息中敏感字段或将消息大小缩减至最小标准。 |
本文以云消息队列 Kafka 版为例介绍如何使用数据清洗。
创建数据清洗任务
在云消息队列Kafka版控制台的,选择地域,单击创建任务。
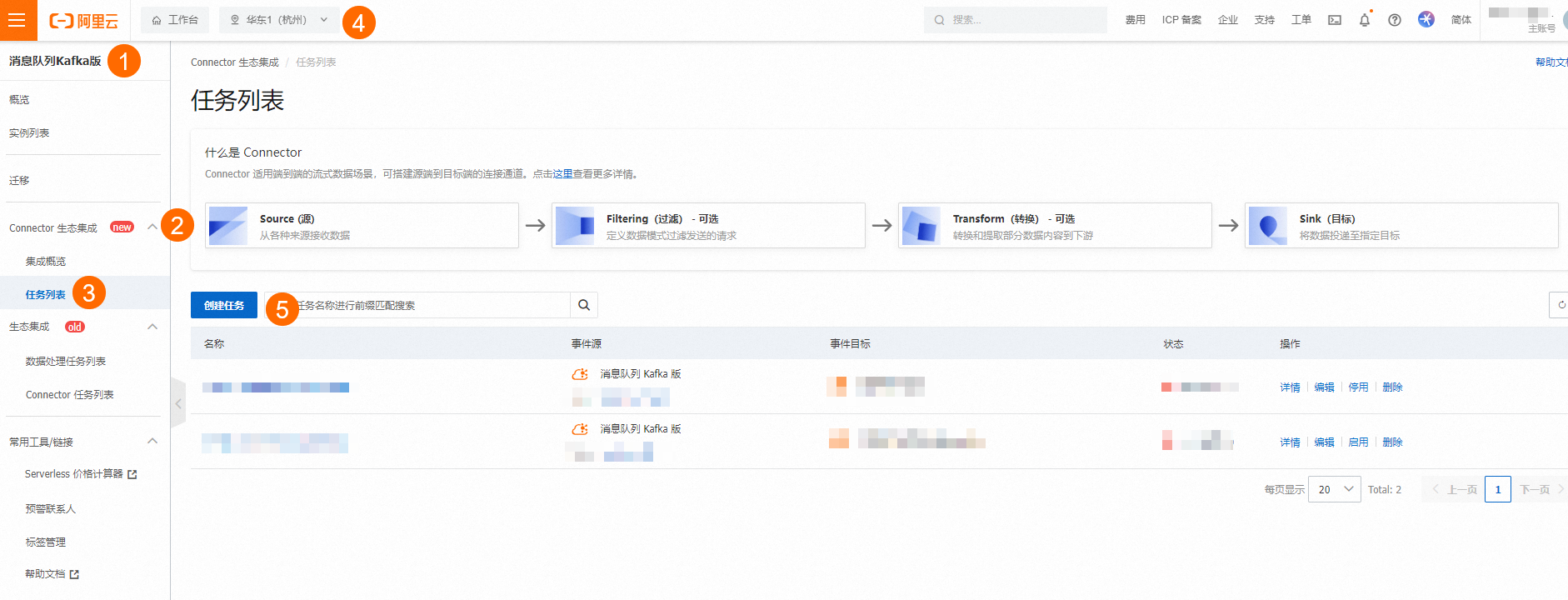
在弹出的创建任务页面填写任务名称,页签,选择数据提供方,选择配置项,单击下一步。具体请参见资源配置。
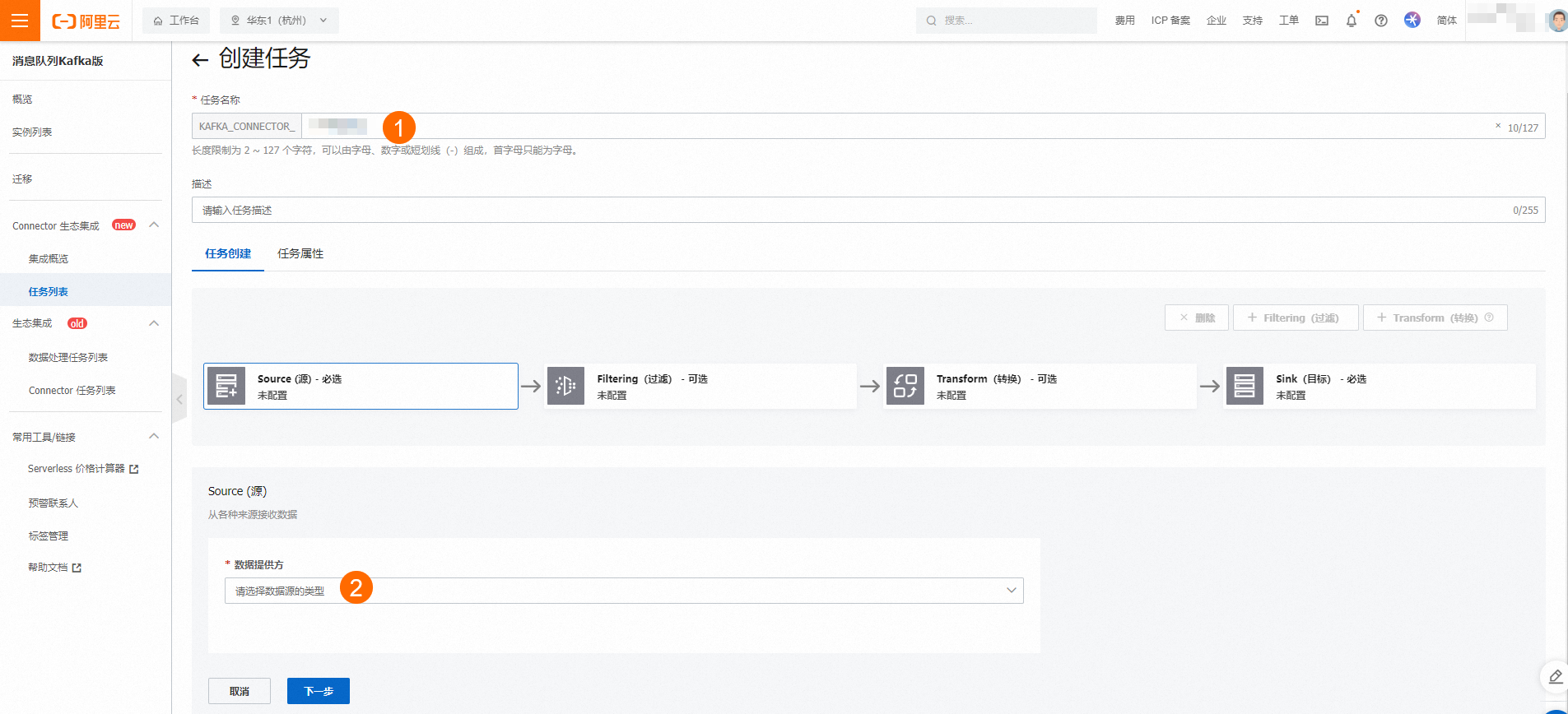
在Filtering(过滤)页签中填写模式内容,单击下一步。具体请参见消息过滤。
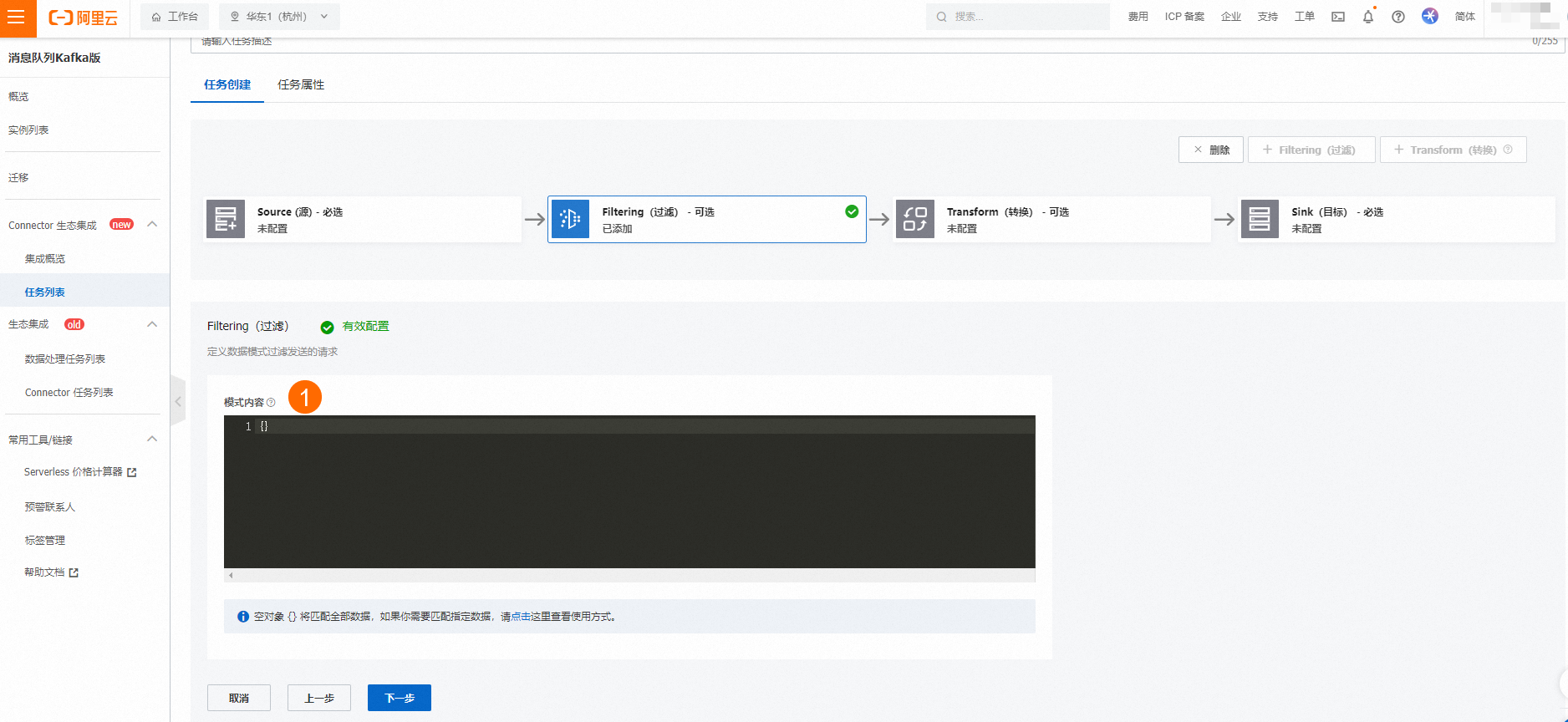
在Transform(转换)页签中选择阿里云服务为函数计算,在新建函数模板中,函数默认带出,函数模板可自行选择,单击下一步。具体请参见函数模板使用示例。
在Sink(目标)页签中选择服务类型,填写配置信息,单击保存。
创建完成后,您可以在左侧导航栏的任务列表查看。
资源配置
配置项 | 说明 |
Source (源) | |
数据提供方 | 选择数据流出的服务类型 |
地域 | 本文选择华东1(杭州)。 |
Kafka实例 | 选择生产消息的Kafka实例。 |
Topic | 选择源实例的Topic。 |
Group ID |
本文选择快速创建。 |
消费位点 | 本文选择最新位点。 |
网络配置 |
|
数据格式 | 默认为Text。 |
批量推送条数 | 一次调用函数发送的最大批量消息条数,当积压的消息数量到达设定值时才会发送请求,取值范围为 [1, 10000]。例如 1。 |
批量推送间隔(单位:秒) | 调用函数的间隔时间,系统每到间隔时间点会将消息聚合后发给函数计算,取值范围为 [0,15],单位秒。0秒表示无等待时间,直接投递。例如 3。 |