本文介绍如何创建使用AnalyticDB Sink Connector,您可通过AnalyticDB Sink Connector将数据从云消息队列 Kafka 版实例的数据源Topic导出至AnalyticDB的表中。
前提条件
详细步骤,请参见创建前提。
步骤一:创建目标服务资源
创建云原生数据仓库 AnalyticDB MySQL 版资源或云原生数据仓库AnalyticDB PostgreSQL版资源。
云原生数据仓库 AnalyticDB MySQL 版:在云原生数据仓库 AnalyticDB MySQL 版控制台创建集群、数据库账号,连接集群并创建数据库。更多信息,请参见创建集群、创建数据库账号、连接集群和创建数据库。
云原生数据仓库AnalyticDB PostgreSQL版:在云原生数据仓库AnalyticDB PostgreSQL版控制台创建实例、数据库账号和登录数据库。更多信息,请参见创建实例、创建数据库账号和客户端连接。
本文以AnalyticDB PostgreSQL版为例,创建数据库名为abd_sink_database和数据表名为abd_sink_table的资源。
步骤二:创建AnalyticDB Sink Connector并启动
登录云消息队列 Kafka 版控制台,在概览页面的资源分布区域,选择地域。
在左侧导航栏,选择。
在消息流出(Sink)页面,单击创建任务。
在消息流出创建面板,配置以下参数,单击确定。
在基础信息区域,设置任务名称,将流出类型选择为云原生数据仓库AnalyticDB。
在资源配置区域,设置以下参数。
表 1. 源(云消息队列 Kafka 版) 参数
说明
示例
地域
源Kafka实例所在的地域。
华东1(杭州)
kafka实例
数据源所在的Kafka实例ID。
alikafka_post-cn-9hdsbdhd****
Topic
数据源所在的Kafka实例Topic。
guide-sink-topic
Group ID
数据源所在的Kafka实例中的Group ID。
快速创建:自动创建以GID_EVENTBRIDGE_xxx命名的Group ID。
使用已有:选择已创建的Group,请选择独立的Group ID,不要和已有的业务混用,以免影响已有的消息收发。
使用已有
并发配额(消费者数)
消费Topic数据的并发线程数,线程和Topic分区的对应关系如下:
Topic分区数=并发消费数:一个线程消费一个Topic分区。建议使用。
Topic分区数>并发消费数:多个并发消费会均摊所有分区消费。
Topic分区数<并发消费数:一个线程消费一个Topic分区,多出的消费数无效。
2
消费位点
最新位点:从最新位点开始消费。
最早位点:从最初位点开始消费。
最新位点
网络配置
有跨境传输数据需求时选择自建公网,其他情况可选择默认网络。
默认网络
表 1. 目标(云原生数据仓库AnalyticDB) 参数
说明
示例
实例类型
选择已创建的实例的类型,本文以AnalyticDB PostgreSQL版为例。
MySQL版
PostgreSQL版
PostgreSQL版
AnalyticDB实例ID
选择已创建的实例ID。
gp-bp10uo5n536wd****
数据库名
选择创建的数据库。
abd_sink_database
表名
选择创建的数据表。
abd_sink_table
数据库用户名
输入设置的用户名。
user
数据库密码
输入设置的密码。
******
网络配置
专有网络:通过专有网络VPC将Kafka消息投递到AnalyticDB。
公网:通过公网将Kafka消息投递到AnalyticDB。
公网
VPC
选择VPC ID。仅当网络配置为专有网络时需配置此参数。
vpc-bp17fapfdj0dwzjkd****
交换机
选择vSwitch ID。仅当网络配置为专有网络时需配置此参数。
vsw-bp1gbjhj53hdjdkg****
安全组
选择安全组。仅当网络配置为专有网络时需配置此参数。
test_group
批量推送
批量推送可帮您批量聚合多个事件,当批量推送条数和批量推送间隔两个条件达到任意一个时即会触发批量推送。例如:您设置的推送条数为100条,间隔时间为15 s,在10 s内消息条数已达到100条,那么该次推送则不会等待15 s后再推送。
开启:开启批量推送功能。
关闭:关闭批量推送功能。默认每次仅投递给FC一条消息。
关闭
批量推送条数
一次调用函数发送的最大批量消息条数,当积压的消息数量到达设定值时才会发送请求。取值范围为[1,10000]。仅当批量推送参数设置为开启时需要配置此参数。
100
批量推送间隔
调用函数的间隔时间,系统每到间隔时间点会将消息聚合后发给函数计算。取值范围为[0,15],单位:秒。取值为0表示没有等待时间,直接投递。仅当批量推送参数设置为开启时需要配置此参数。
10
完成上述配置后,在消息流出(Sink)页面,找到刚创建的AnalyticDB Sink Connector任务,单击其右侧操作列的启动。当状态栏由启动中变为运行中时,Connector创建成功。
步骤三:测试AnalyticDB Sink Connector
在消息流出(Sink)页面,在AnalyticDB Sink Connector任务的事件源列单击源Topic。
在Topic详情页面,单击体验发送消息。
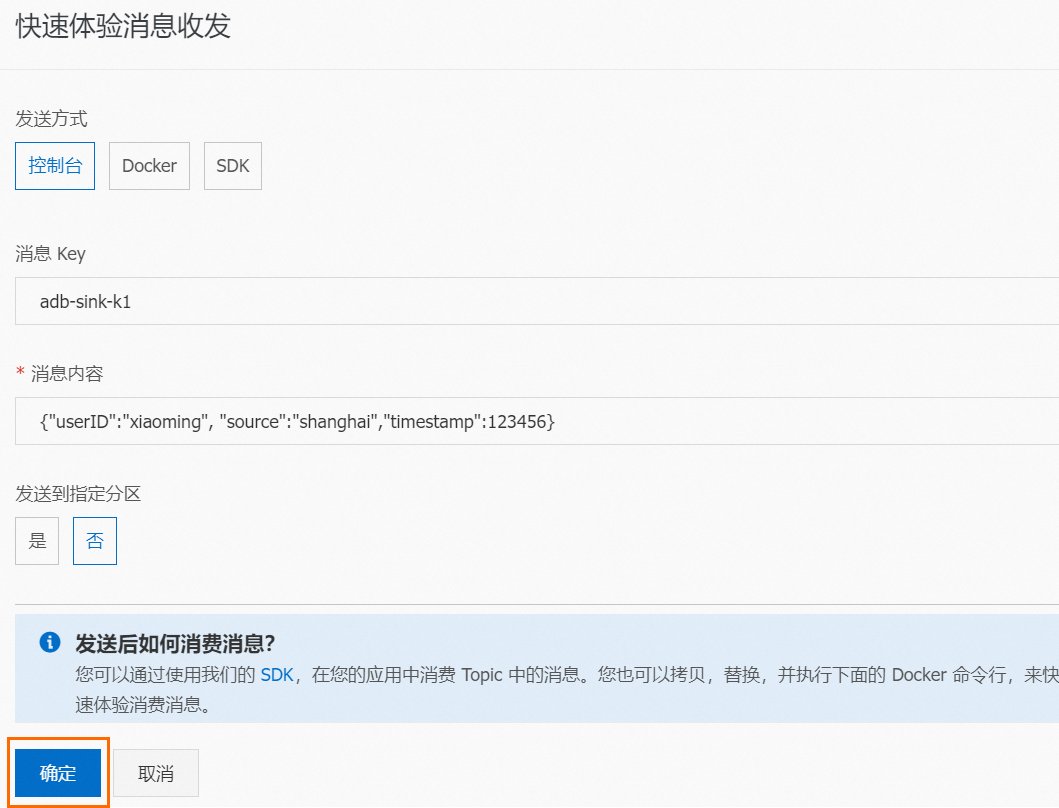
在快速体验消息收发面板,按照下图配置消息内容,然后单击确定。
说明此处的消息内容为JSON格式,JSON中需包含已创建的数据表的所有列,系统会将JSON中同名字段对应的值写入到数据表对应的列中。
在消息流出(Sink)页面,在AnalyticDB Sink Connector任务的事件目标列单击目标实例。
在实例基本信息页面,单击右上角的登录数据库。
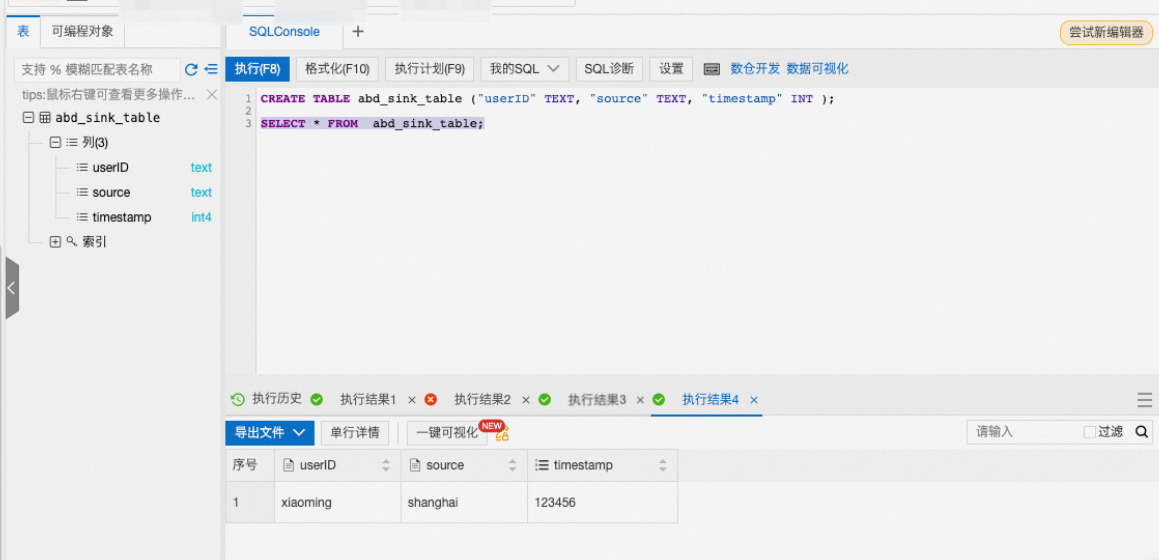
在DMS数据管理服务页面,执行以下语句,查询表中全量数据。
SELECT * FROM abd_sink_table;查询结果如下所示: