
本文介绍Connector生态集成的计费说明、产品功能、使用限制以及基本概念等信息。
背景信息
企业在向数字化转型的过程中,往往会遇到诸多挑战。例如,缺少统一的信息集成途径;数据格式类型多样,给传输和集成带来不便;缺少分享数据和后端服务的便捷服务;缺少云上云下跨网络的安全信息通道。Connector生态集成是一个全栈式的消息与数据集成平台,可显著简化您与其他产品集成的流程,并支持云上云下、跨区域集成,帮助您实现数字化转型。
Connector生态集成为消息产品提供的低代码,全栈事件流(EventStreaming)服务平台,聚焦消息集成、数据连接、数据处理、服务集成等场景。提供可视化UI界面来便捷地创建集成任务,支持可视化设计与编排。提供跨地域、跨实例、跨应用的跨端连接能力。显著降低消息领域的集成与开发成本。
前提条件
Connector底层基于事件总线和函数计算实现,在使用Connector之前,请确保已开通以下服务。
开通目标服务。例如,创建流出目标端为Tablestore的Sink Connector,请先开通表格存储(Tablestore)服务。
说明若目标服务为日志服务,可不开通函数计算服务。
计费说明
事件总线目前处于公测中,免费使用。
函数计算的计费说明,请参见计费概述。
权限策略
阿里云账号:在控制台创建Connector时,控制台会弹出详细授权策略,按照控制台提示确认授权即可。
RAM用户:RAM用户至少要求阿里云账号授权以下策略:
AliyunKafkaFullAccess:管理云消息队列 Kafka 版的权限。
AliyunFCFullAccess:管理函数计算的权限。
AliyunEventBridgeFullAccess:管理事件总线的权限。
目标服务的管理权限。
除上述必要权限外,如需使用扩展能力需额外授权。例如:
如需通过VPC网络访问目标服务,需要被授予AliyunVPCFullAccess权限策略来管理VPC资源。
如需查看函数计算FC(Function Compute)运行日志等信息,需要被授予AliyunLogFullAccess权限策略来管理日志服务。
产品功能
集成丰富的数据源
Connector生态集成旨在打通阿里云公有云、跨云、混合云场景下的数据连接。支持云上多款产品的日志接入、支持用户自建场景的数据源接入、支持跨云场景的数据源接入等。目前已打通日志、数据库、消息中间件等多种场景的数据接入。
数据清洗/数据流出
Connector生态集成提供了强大的、界面化的数据ETL(Extract-Transform-Load)配置能力,方便快捷地对完成上报、进入到消息队列的数据进行清洗、格式化、数据格式转换等操作。并支持将完成ETL处理的数据转储到下游。
Serverless自定义处理
Connector生态集成基于Serverless平台的优势,依托函数计算FC的用户自编码能力,支持用户基于Serverless Function函数计算平台自定义地完成业务逻辑的编写,完成自定义的数据处理分发功能。
使用限制
使用Connector生态集成功能时的限制项如下表所示。
限制项 | 说明 |
任务数 | 单地域总任务数(包括消息流入和消息流出)不超过20个,如果您需要提升创建Connector的任务数,请提交工单申请。 |
任务名称 | 必须以字母或数字开头,剩余部分可以包含字母、数字、短划线(-)。不超过127个字符,超出长度自动截断。 |
事件模式匹配 | 在字符串表达式(stringExpression)模式下,每个字段最多包含5个MAP结构(expression)。 |
事件内容转换 |
|
极端情况任务数据丢失 | 具体信息,请参见重试和死信。 |
概念介绍—消息流入(Source)
消息流入是消息的数据集成组件。消息流入能够在多种数据源(消息、Log日志、关系型数据和非关系型数据等)之间进行灵活、快速、无侵入式的数据集成。可以实现跨机房、跨数据中心、跨云的数据集成方案,并能自助实施、运维、监控集成数据。主要能力是将各类数据流入至云消息队列 Kafka 版,并且可靠地管理来自不同源头的数据源,同时对来源数据进行筛选和过滤。
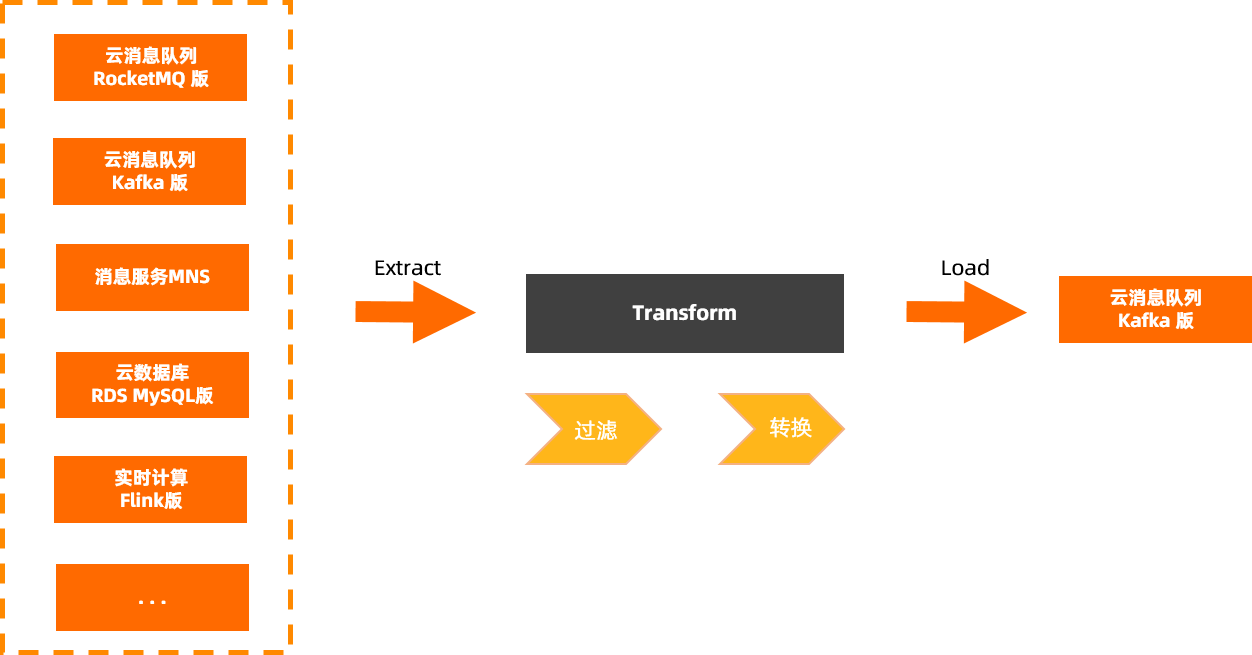
概念介绍—消息流出(Sink)
消息流出的主要能力是将云消息队列 Kafka 版的数据流出到各类数据目标,Connector生态集成模块对云消息队列 Kafka 版的消息进行可靠分发,同时在分发时对消息数据进行清洗和过滤。
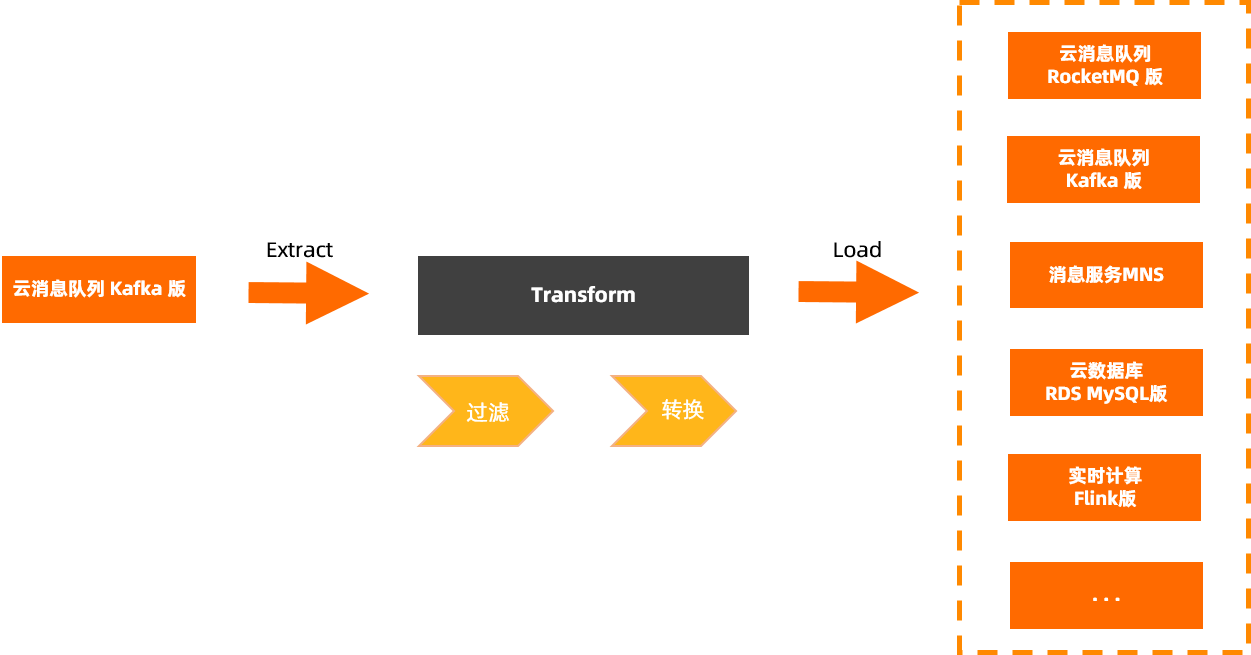
概念介绍—数据处理(Transform)
数据处理是Connector生态集成的重要功能组件,可以在配置消息流入或消息流出任务的同时选择性配置数据处理能力。依托事件总线EventBridge强大的自研数据处理及灵活的函数计算自定义能力,提供7种匹配模式(指定值匹配、前缀匹配、后缀匹配、除外匹配、数值匹配、数组匹配、复杂组合逻辑匹配)、5种规则转换器(完整事件、部分事件、常量、模板转换器、函数计算模板转换器),可快速实现消息的转换、处理和分析能力。
概念介绍—任务(Task)
任务是运行Connector生态集成的资源实体,也是具体实现。通常情况下,一条任务由源、目标及其配置的过滤规则和转换规则构成。任务的底层资源即事件总线EventBridge的事件流(EventStreaming)功能。
任务包括资源配置和数据处理两部分,资源配置是任务的源及目标的配置信息,是任务的重要组成部分。数据处理请参见概念介绍—数据处理(Transform)。
任务一旦创建完成,消息流入或者流出的资源类型会置为不可修改状态。
版本说明
云消息队列 Kafka 版的Connector共有两个版本,若您的阿里云账号未创建过旧版Connector,那么控制台仅展示新版入口;若已创建过旧版Connector任务,控制台会同时展示新版和旧版入口,建议您使用新版Connector。
新旧版本消息流入Connector即Source Connector能力相同,此处对消息流出Connector即Sink Connector能力差异做以下说明。
差异项 | 新版Sink Connector(推荐) | 旧版Sink Connector |
底层依赖能力 | 底层依赖事件总线EventBridge和函数计算FC(Function Compute)构建。 说明 SLS Sink Connector仅依赖事件总线EventBridge。 | 底层能力未统一,主要包含三大类:
创建的Connector具体属于哪一类需查看对应的Connector文档。 |
消息过滤 | 支持多种消息过滤模式,过滤无用消息,提升处理效率。详细信息,请参见事件模式。 | 不支持。 |
死信队列 | 支持消息服务MNS和云消息队列 RocketMQ 版等服务做死信队列。 | 支持云消息队列 Kafka 版做死信队列。 |
重试策略 | 统一支持。 | 部分支持。 |
依赖Kafka资源 | 不额外依赖。 | 系统自动或手动创建任务位点Topic、任务配置Topic、任务状态Topic、死信队列Topic、异常数据Topic等资源。 |
跨账号传输 | 暂不支持。如有需求请提交工单申请。 | 支持。 |
消费线程并发数 | 可自定义配置32以内的消费线程并发数。 | 仅支持配置以下选项:1、2、3、6、12。 |
消费组 | 可新建或复用已有资源。 | 仅支持新建消费组。 |