本文介绍JVM监控统计的内存指标说明。
Java进程占用内存分布
Java进程在运行期间,内存分布的大致情况如下图所示:
JVM的运行机制比较复杂,此图仅列出了主要的内存分布区域。

ARMS获取JVM内存详情的原理
ARMS应用监控探针通过JDK提供的MemoryMXBean获取JVM运行期间内存详情,受限于MemoryMXBean的运行机制,目前ARMS的JVM内存监控能力还不能覆盖Java进程占用的所有内存区域。更多详情请参见Java官方网站的MemoryMXBean介绍。
堆内存详情
堆(Heap)部分是Java内存中的核心部分,所有对象都在这里分配内存,是垃圾收集的主要区域。根据Java垃圾收集器的不同,ARMS展示的最大允许使用堆内存有可能会略小于用户设置的堆内存上限。例如在ParallelGC垃圾收集器中,设置-XX:+UseParallelGC -Xms4096m -Xmx4096m参数,有可能会产生下图的结果,其中最大允许使用内存为3.8 G,略小于用户设置的4 G。这是因为在这种情况下MemoryMXBean收集的数据并没有包含From Space和To Space区域,导致了细微的偏差。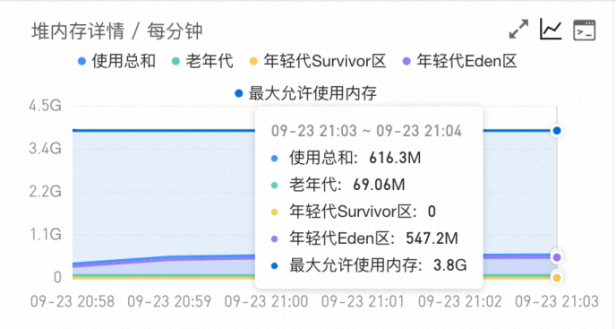
一般情况下,如果使用G1垃圾收集器,ARMS展示的最大允许使用堆内存和用户设置的-Xmx或-XX:MaxRAMPercentage保持一致,而在使用Parallel、ConcMarkSweepGC和Serial垃圾收集器的情况下,存在细微的偏差。
元空间详情
元空间(Meta Space)用于存放类的元数据,包括类的结构信息、方法信息、字段信息等,这一部分的内存占用一般比较稳定。
非堆内存详情
ARMS展示的非堆内存包括元空间(Meta Space)、压缩类空间(Compressed Class Space)和代码缓冲区(Code Cache)三个区域的总和。受限于MemoryMXBean的工作原理,ARMS展示的非堆内存并不直接等同于Heap之外的部分,虚拟机线程栈(VM Thread Stacks)以及JNI本地代码等区域都不包含在ARMS展示的非堆内存中。

元空间(Meta Space):元空间存储类的元信息。JDK 8后,元空间的默认大小和最大大小一般可以通过
-XX:MetaspaceSize=N和-XX:MaxMetaspaceSize=N来指定。压缩类空间(Compressed Class Space):压缩类空间是Java虚拟机的一个特殊区域,用于压缩和存储已加载的类元数据。它通过减小指针的存储空间来降低内存占用,从而减少Java应用程序的内存消耗。压缩类空间可以通过JVM启动参数
-XX:CompressedClassSpaceSize来指定,在JDK 11中,默认的压缩类空间大小为1 GB。代码缓冲区(Code Cache):JVM自身会生成一些Native Code并将其存储在称为Code Cache的内存区域中。JVM生成Native Code的原因有很多,包括动态生成的解释器循环、JNI、即时编译器(JIT)编译Java方法生成的本机代码。其中JIT生成的Native Code占据了Code Cache绝大部分的空间。代码缓冲区可以通过JVM启动参数
-XX:InitialCodeCacheSize和-XX:ReservedCodeCacheSize分别配置其起始大小与最大大小。
直接缓冲区
Java中的直接缓冲区(Direct Buffer)是一种特殊类型的缓冲区,它直接在操作系统的内存中分配空间,而不是在Java虚拟机的堆内存中分配。直接缓冲区的主要特点是可以提供更快的I/O操作,并且可以避免内存复制的开销,因此在处理大量数据时非常高效。大量的I/O操作会增加直接缓冲区内存占用。
堆内存泄露分析
ARMS提供了完善的堆内存泄露定位分析能力,用户可以通过JVM堆内存监控查看是否出现堆内存缓慢增长,如果存在相关堆内存持续增长趋势,可以通过ARMS提供的内存快照或持续剖析功能排查定位堆内内存泄露位置。
堆外内存泄露分析
如果堆内存比较稳定,但应用总体内存在一直增长,未有下降迹象,有可能是堆外内存泄露引起。ARMS目前不提供堆外内存分析能力,可以考虑使用Native Memory Tracking(NMT)工具对堆外内存申请情况进行监测,具体使用说明请参见官方文档。
NMT工具存在一定的使用门槛 ,而且会对应用产生5~10%的性能开销,线上应用使用请先评估影响后再进行。
内存常见问题
为什么ARMS应用监控产品界面上看到的堆、非堆内存总和与通过
top命令看到的RES相差很多?答:ARMS应用监控采集的数据来源来自JMX,并不包含虚拟机线程栈、本地线程栈等部分,以及非JVM内存部分。所以ARMS应用监控展示的JVM内存信息并不等同于通过
top命令看到的RES。为什么ARMS应用监控产品界面上看到的堆、非堆内存总和与在Prometheus、Grafana中看到的内存使用数据相差很多?
答:ARMS应用监控采集的数据来源来自JMX,而Grafana上看到的内存使用率是通过Prometheus Query Language查询的指标,一般取与对应用容器相关的、名字包含container_memory_working_set_bytes的指标,实际上统计的是memcg(进程组)的rss以及active cache的总和。所以两者存在差异。
如果发现有Pod由于OOM Killer导致重启,如何通过ARMS应用监控排查?
答:ARMS应用监控对于堆内存、直接缓冲区的容量规划问题,比较容易排查。但由于ARMS应用监控是从JMX获取内存数据,无法覆盖整个JVM进程的RSS消耗,因此OOM Killer问题需要借助K8s的Prometheus监控生态来排查。另外,特别需要注意以下两个方面:
Pod内是单进程模型吗?
用于排除其他进程内存消耗的干扰。
JVM进程外是否存在泄漏?
例如glibc导致的内存泄漏。