
为LLM(Large Language Model)应用安装Python探针后,ARMS即可开始监控LLM应用,您可以在Token分析页面了解LLM应用中的Token使用情况。
在大模型应用中,Token 是文本处理的基本单位,用于表示模型输入和输出的最小语义单元。Token 可以是一个单词、一个子词(subword)或一个字符,具体取决于模型的分词方式(Tokenizer)。
前提条件
已为LLM应用安装探针,具体操作,请参见LLM 大语言模型应用接入 ARMS。
查看LLM应用Token分析
登录ARMS控制台,在左侧导航栏选择。
在应用列表页面顶部选择目标地域,然后单击目标应用名称。
在上方导航栏单击Token分析。
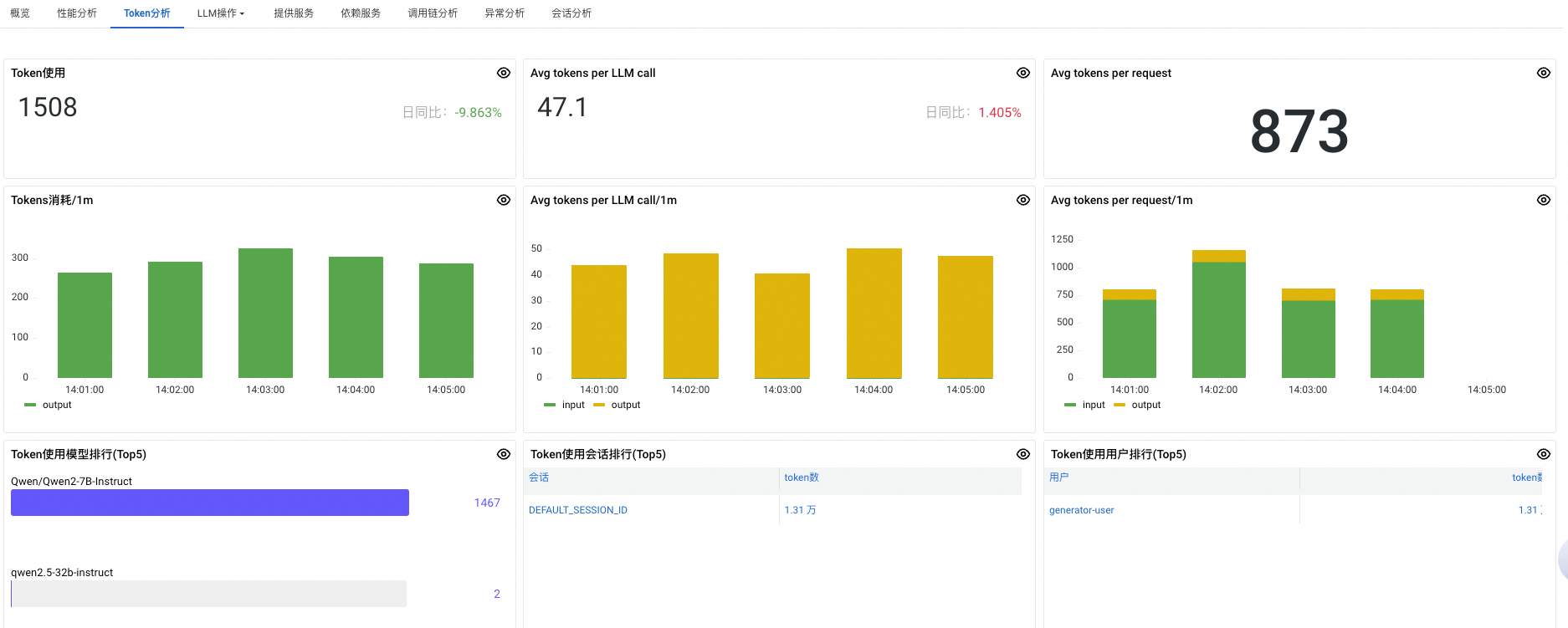
面板
说明
Token使用
指定时间段内所有模型调用消耗的 Token 总量。
Avg tokens per LLM call
每次模型调用(LLM Call)平均消耗的 Token 数量。
Avg tokens per request
每个用户请求(Request)平均消耗的 Token 数量。
Tokens消耗/1m
每分钟内所有模型调用消耗的 Token 总量。
Avg tokens per LLM call/1m
每分钟内每次模型调用平均消耗的 Token 数量。
Avg tokens per request/1m
每分钟内每个用户请求平均消耗的 Token 数量。
Token使用模型排行(Top5)
按 Token 消耗总量从高到低排序,展示 Token 使用最多的前5个模型。
Token使用会话排行(Top5)
按 Token 消耗总量从高到低排序,展示 Token 使用最多的前5个会话(Session)。
Token使用用户排行(Top5)
按 Token 消耗总量从高到低排序,展示 Token 使用最多的前5个用户。
相关文档
该文章对您有帮助吗?