您可以通过托管模型构建AI应用的核心底座,由 云原生应用开发平台 CAP基于函数计算封装模型体验,提供Serverless GPU运行时服务。
什么是模型服务
模型服务能力是一项全面托管的模型服务,通过Serverless GPU计算,托管开源与微调模型实现统一的模型构建,为您提供构建生成式AI应用所需的一系列模型能力。
模型服务底层依赖函数计算的GPU作为底层算力,您可以无需关心底层基础设施的管理,只需专注于AI应用的开发,一键拉取大模型,并自动生成开发所需的调用API。
使用模型服务,您可以轻松试验和评估适合您的大模型,通过微调(SFT)和检索增强生成(RAG)等技术利用您的数据对大模型进行私人定制,构建仅服务于您的专属大模型。
模型服务来源
ModelScope
从ModelScope官网拉取模型。
对象存储 OSS
从您创建的OSS Bucket中获取存放的模型。
自定义模型镜像
选择您托管到容器镜像服务 ACR中的镜像模型。
模型服务将自动从对应来源拉取模型并部署,不同的来源下载速率不一致,可关注部署日志来观测下载速率。以Qwen7B为例,通常下载时间为分钟级。
模型执行框架
目前模型支持ModelScope Library作为底层模型执行框架,请确保自定义模型来源可被ModelScope Library执行并部署。更多信息,请参见Library介绍。
前提条件
已创建项目,具体操作,请参见管理项目。
创建模型服务
使用控制台模板列表中的模板创建项目时,部分模板默认会创建模型服务,您也可以手动添加模型服务。
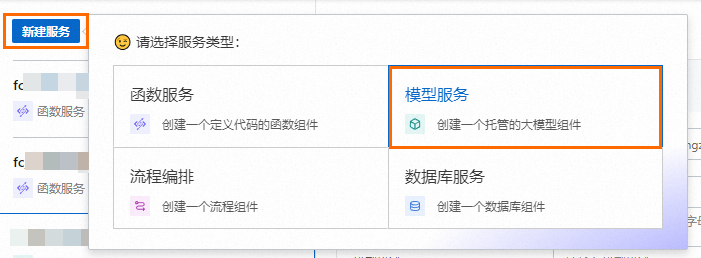
登录云原生应用开发平台 CAP控制台,单击目标项目,在项目详情页面,单击左上角的新建服务,选择模型服务类型并单击跳转至创建服务页面。
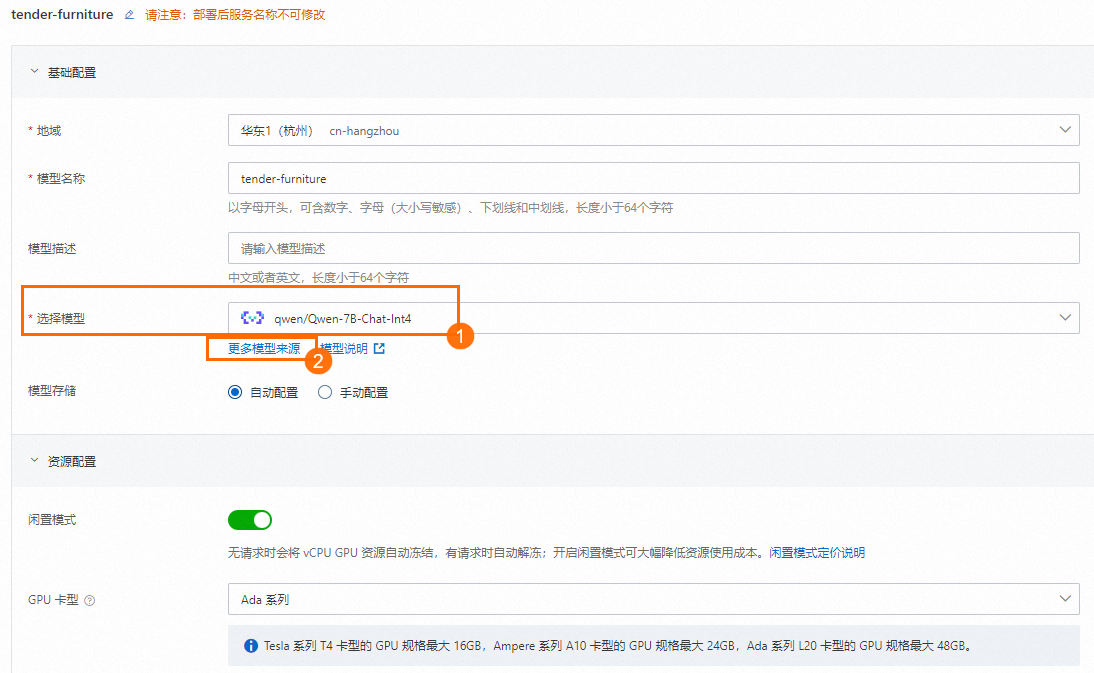
在创建服务页面,选择开源模型(图示中①)以及所需的资源信息,然后单击预览&部署。如果没有特殊需求,其他配置项保持默认值即可。
您也可以单击更多模型来源(图示中②),手动添加模型,详见步骤3。
(可选)单击更多模型来源,在选择模型对话框手动添加模型。
ModelScope
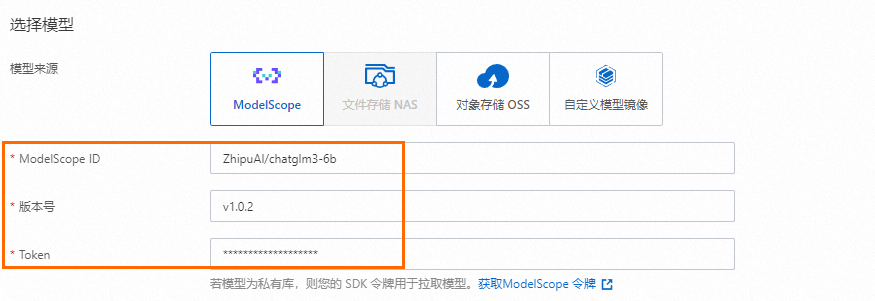
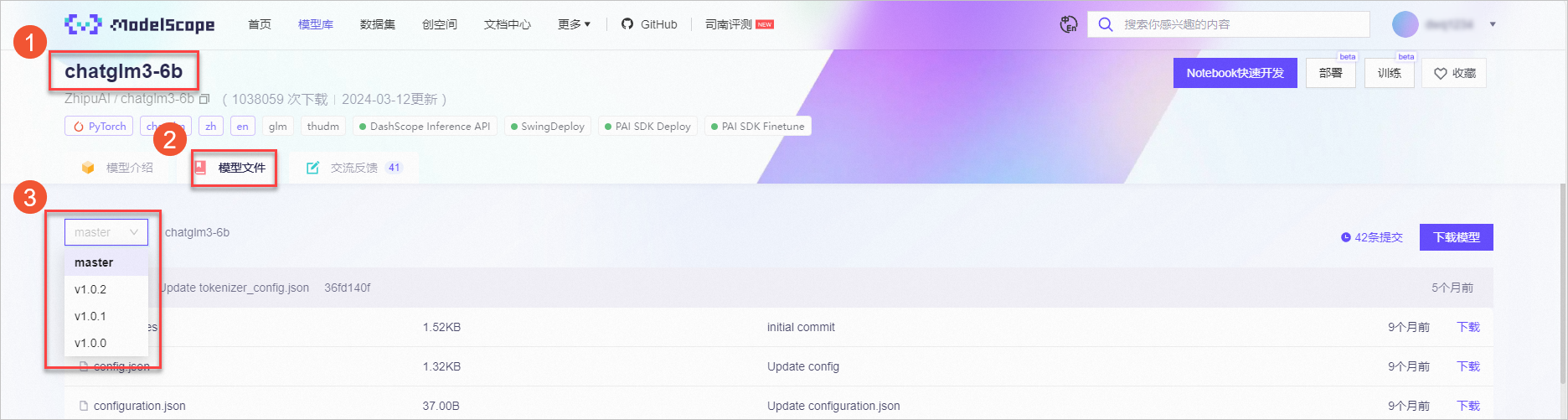
支持从ModelScope官网获取模型ID,版本号。
Token为ModelScope令牌。
对象存储 OSS
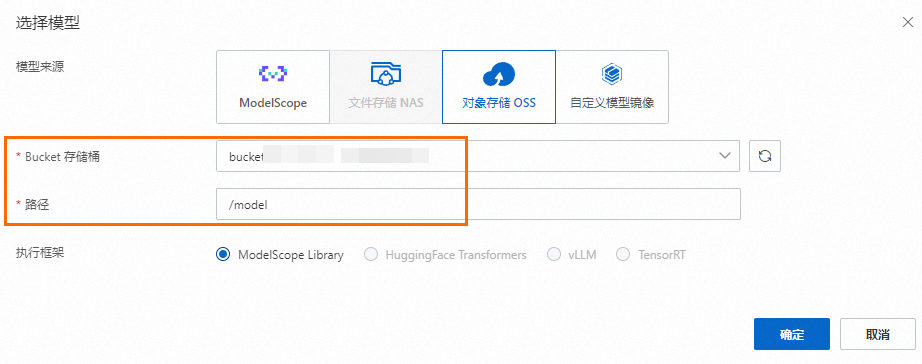
如图所示,需选择您的Bucket,并填写模型存储路径。
自定义模型镜像

如图所示,选择您托管在容器镜像服务 ACR中的模型镜像。
在弹出的服务资源预览对话框,确认信息后单击确认部署。
访问模型服务
模型服务创建成功后,您可以在服务详情页面,单击API 地址跳转至API调用示例页面,单击测试进行相关模型试用。
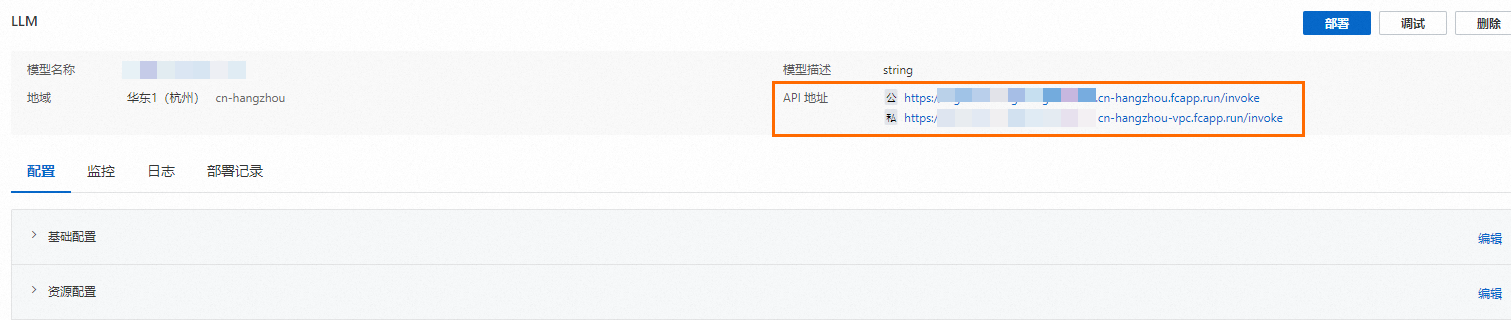
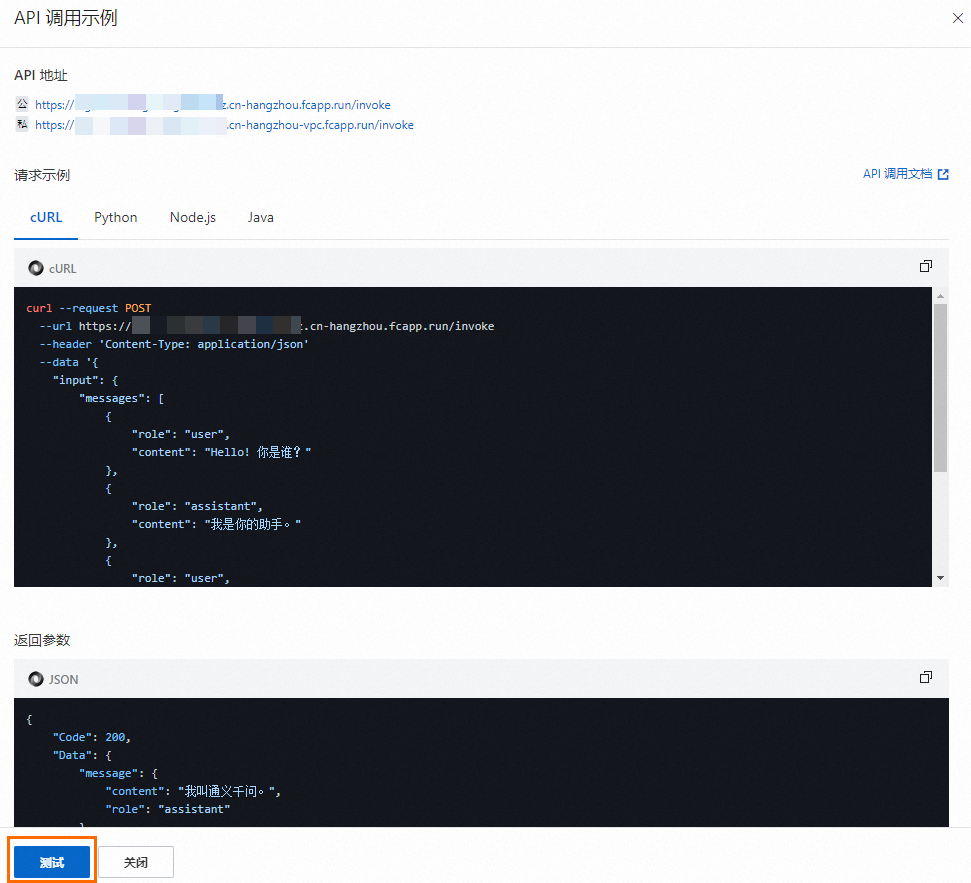
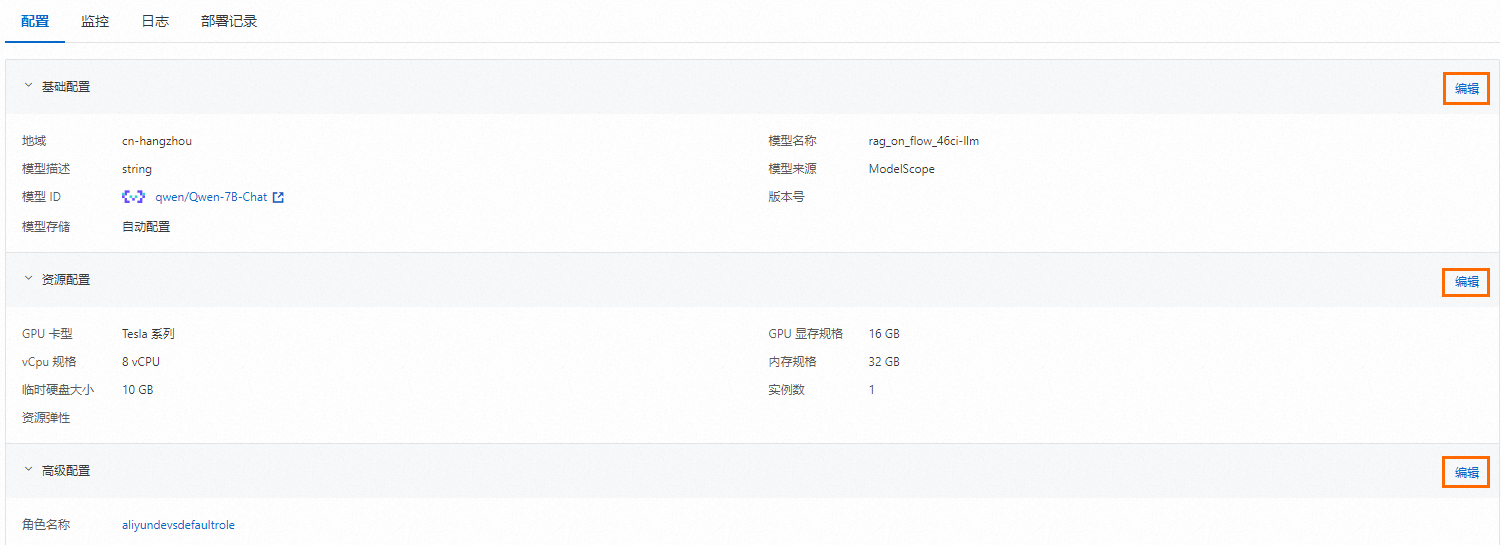
更新模型服务
服务部署成功后,您可以在已部署模型详情页面编辑基础配置的模型信息,也可以编辑底层资源配置信息。如下图所示,依次单击编辑修改配置并保存。
删除服务
选中要删除的服务,点击删除。进入删除服务确认弹窗。

勾选我已知晓:删除该项目及选中的服务将立刻中断其所服务的线上业务,并且不可恢复,同时将彻底删除其所依赖的云产品资源,然后单击确定删除。