
本文介绍如何将自建ClickHouse迁移到云数据库 ClickHouse 企业版集群,以及云数据库 ClickHouse 企业版集群之间迁移操作。Remote函数在SELECT和INSERT查询中用于允许访问自建ClickHouse服务器,这使得迁移表只需要编写一个带有嵌套SELECT的INSERT INTO查询即可。
将自建ClickHouse迁移到云数据库 ClickHouse 企业版,以及云数据库 ClickHouse 企业版集群之间迁移操作的示意图如下:
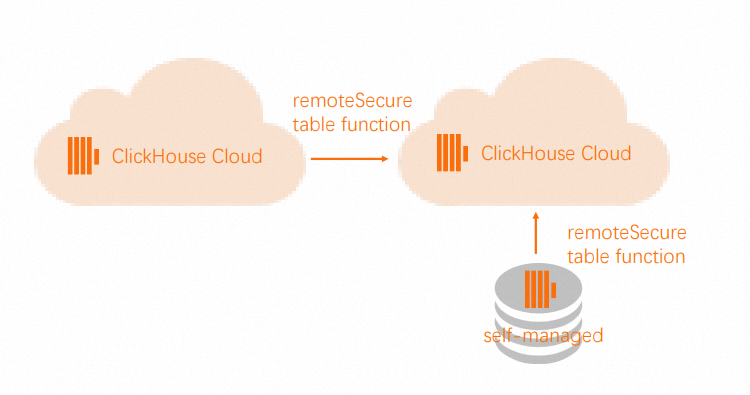
从自建ClickHouse向企业版迁移
在云数据库 ClickHouse 企业版中,无论您的源表是否存在分片或副本,您只需创建对应的目标表即可(在该表中,您可以省略Engine参数,因为系统将自动使用SharedMergeTree表引擎)。云数据库 ClickHouse 企业版集群会自动处理垂直和水平扩展,您无需担心复制和分片的具体实现方式。
在本示例中,自建ClickHouse以下称为源集群,云数据库 ClickHouse 企业版集群以下称为目标集群。
操作概述
从自建ClickHouse向云数据库 ClickHouse 企业版集群迁移的流程如下。
在源集群中添加一个只读用户。
在目标集群上复制源表结构。
如果源集群支持从外部网络访问时,您可以将源集群数据读取至目标集群;如果源集群不支持从外部网络访问时,您可以将源集群数据推送至目标集群。
(可选)在目标集群上将源集群的IP地址删除。
从源集群中删除只读用户。
操作步骤
在源集群上执行以下操作(源表中已有数据):
增加一个只读用户到表db.table中。
CREATE USER exporter IDENTIFIED WITH SHA256_PASSWORD BY 'password-here' SETTINGS readonly = 1;GRANT SELECT ON db.table TO exporter;复制源表结构。
SELECT create_table_query FROM system.tables WHERE database = 'db' and table = 'table'
在目标集群上执行以下操作。
创建数据库。
CREATE DATABASE db使用源数据表的
CREATE TABLE语句来创建目标数据表。说明在运行
CREATE TABLE语句时,将ENGINE更改为SharedMergeTree,但是不能包含任何参数,因为云数据库 ClickHouse 企业版集群始终会复制表并提供正确的参数。ORDER BY、PRIMARY KEY、PARTITION BY、SAMPLE BY、TTL和SETTINGS子句定义了表的结构和元数据信息,请保留这些子句,以确保表在目标云数据库 ClickHouse 企业版集群中正确地创建。CREATE TABLE db.table ...使用
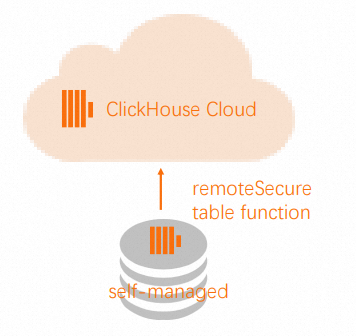
Remote函数读取数据或推送数据。说明如果源ClickHouse服务器不可从外部网络访问,您可以选择将数据推送而不是读取,因为
Remote函数适用于选择和插入操作。在目标集群中使用
Remote函数从源集群的源表中读取数据。
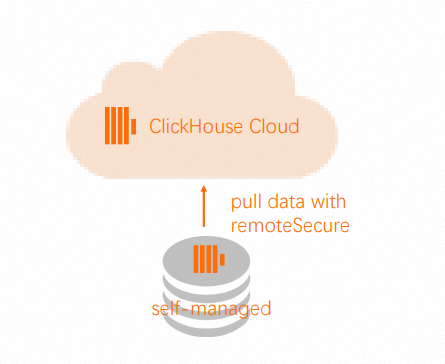
INSERT INTO db.table SELECT * FROM remote('source-hostname:9000', db, table, 'exporter', 'password-here')在源集群中使用
Remote函数将数据推送到目标集群中。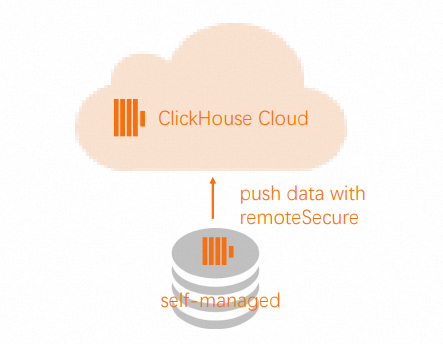 说明
说明为了使
Remote函数能够连接到您的云数据库 ClickHouse 企业版集群上,您需要将源集群的IP地址添加到目标集群的白名单中。具体操作,请参见设置白名单。INSERT INTO FUNCTION remote('target-hostname:9000', 'db.table', 'default', 'PASS') SELECT * FROM db.table
在云数据库 ClickHouse 企业版之间进行迁移
在云数据库 ClickHouse 企业版集群之间迁移数据的使用场景如下。
从还原的备份中迁移数据。
从开发服务复制数据到预发服务(或从预发到生产)。
本示例中有两个云数据库 ClickHouse 企业版集群,以下称为源集群和目标集群。
操作概述
在云数据库 ClickHouse 企业版之间迁移的流程如下:
确定一个云数据库 ClickHouse 企业版集群作为源集群,另一个作为目标集群。
在源集群上添加一个只读用户。
在目标集群上复制源表结构。
暂时允许源集群的IP访问。
从源集群到目标集群复制数据。
在目标集群上重新建立IP访问列表。
从源服务中删除只读用户。
操作步骤
在源集群执行以下操作。
增加一个只读用户表db.table中。
CREATE USER exporter IDENTIFIED WITH SHA256_PASSWORD BY 'password-here' SETTINGS readonly = 1;GRANT SELECT ON db.table TO exporter;复制源表结构。
SELECT create_table_query FROM system.tables WHERE database = 'db' and table = 'table'
在目标集群复制表结构。
创建数据库。
CREATE DATABASE db使用源集群的
CREATE TABLE语句,在目标数据库上创建表。CREATE TABLE db.table ...
在目标集群上创建表,使用来自源集群的
SELECT CREATE_TABLE_QUERY...的输出。允许源集群上的远程操作。
为了从源集群到目的集群地读取数据,源集群和目标集群必须允许互相连接。请执行以下操作。
将源集群的IP地址添加到目标集群的白名单中。
将目标集群的IP地址添加到源集群的白名单中。
说明您可以通过
SELECT * FROM system.clusters;查看云数据库 ClickHouse 企业版集群的IP地址。修改白名单的具体操作,详情请参见设置白名单。把数据从源集群复制到目标集群。
使用
Remote函数从源集群中读取数据。连接到目标集群,在目标集群上运行以下命令验证数据。INSERT INTO db.table SELECT * FROM remote('source-hostname:9000', db, table, 'exporter', 'password-here')在源集群上恢复访问列表。
如果您之前导出了访问列表,那么您可以使用Share重新导入它,否则请重新添加条目到访问列表中。
删除只读的exporter用户。
DROP USER exporter删除源集群和目标集群的访问IP地址。具体操作,请参见设置白名单。