
由于自建ClickHouse面临高稳定性风险、运维管理难(集群扩展性差、版本更新困难)以及容灾能力弱等原因,越来越多的客户希望将自建的ClickHouse集群升级为云PaaS服务。本文为您介绍,自建ClickHouse如何迁移至云数据库ClickHouse社区兼容版集群。
前提条件
目标集群:
自建集群:
已具有数据库账号和密码。
账号权限需具备库表读权限、SYSTEM命令执行权限。
目标集群与自建集群网络互通。
如果自建集群和目标集群位于同一个VPC下,您还需要将目标集群所有节点的IP地址以及其交换机 ID的IPv4网段,添加到自建集群的白名单中。
云数据库ClickHouse中如何添加白名单,请参见设置白名单。
自建集群如何添加白名单,请参见自身产品文档。
如何查看云数据库ClickHouse集群的所有节点的IP地址,请通过
SELECT * FROM system.clusters;查看。如何获取云数据库ClickHouse交换机 ID的IPv4网段,请参见以下步骤:
在云数据库ClickHouse控制台找到目标集群的集群信息页面,在网络信息处获取交换机 ID。
在交换机列表,根据交换机 ID,搜索找到目标交换机,查看IPv4网段。
当自建集群和云集群位于不同VPC,或自建集群位于本地IDC或其他云厂商时,请先解决网络问题。具体操作,请参见如何解决目标集群与数据源网络互通问题?。
迁移验证
在您正式开始迁移数据前,强烈建议您创建一个测试环境,以验证业务的兼容性、性能以及迁移是否能够顺利完成。在迁移验证完成后,再在生产环境中进行数据迁移。这一步骤至关重要,它可以帮助您提前识别并解决潜在问题,确保迁移过程顺利,并且避免对生产环境造成不必要的影响。
创建迁移任务,进行数据迁移。具体步骤,请参见本文。
上云兼容性和性能瓶颈分析以及是否能完成迁移,请参见ClickHouse自建上云兼容性和性能瓶颈分析与解决。
选择方案
迁移方案 | 优点 | 缺点 | 适用场景 |
可视化操作,无需手动迁移元数据。 | 只能进行整集群数据的全量和增量迁移,无法仅迁移指定的部分库表或部分历史数据。 | 整个集群数据迁移。 | |
可自主控制迁移哪些库表数据。 | 操作繁杂,需要手动迁移元数据。 |
|
操作步骤
控制台迁移
使用限制
目标集群版本需大于等于21.8。
注意事项
迁移过程中
目标集群进行迁移的库表会暂停合并(Merge),但自建集群不会。
说明迁移数据时间过长,将导致目标集群的元数据积累过多。建议迁移任务的持续时长不超过5天。
目标集群必须使用default集群。如果您自建集群的命名使用了其他名字,则会自动将分布式表中的cluster定义转化为default。
迁移内容
支持迁移的内容:
库、数据字典、物化视图。
只支持迁移SQL创建的数据字典,不支持通过XML创建的数据字典。
确认方法:
SELECT * FROM system.dictionaries WHERE (database = '') OR isNull(database);,如果SQL存在返回结果,代表有XML创建的数据字典。数据字典访问外部服务时,请确保外部服务可用且为集群开放白名单;数据字典的数据源为当前ClickHouse的内表数据时,如果定义中
HOST参数配置的是IP地址,迁移后可能会因IP变更而导致访问失败,需重新确认当前ClickHouse的HOST并手动创建数据字典。
表结构:除了Kafka和RabbitMQ引擎表以外的所有表结构。
数据:增量迁移MergeTree族表的数据。
不支持迁移的内容:
Kafka和RabbitMQ引擎表的表以及数据。
非MergeTree类型表(例如外表、Log表等)的数据。
重要以上不支持的内容,在迁移过程中,您需根据操作步骤,手动处理。
迁移数据量:
冷数据:冷存数据的迁移速度相对较慢,建议您尽量清理自建集群中的冷存数据,以确保其总量不超过1TB。否则,迁移时间过长可能会导致迁移失败。
热数据:热数据如果超过10TB,迁移任务失败率比较高,不建议您使用此方案进行迁移。
如果数据不满足上述条件,迁移方案可选择手动迁移。
集群影响
自建集群:
读取自建集群过程中,自建集群的CPU和内存会升高。
不允许其进行DDL操作。
目标集群:
写入数据过程中,目标集群的CPU和内存升高。
不允许进行DDL操作。
迁移的库表不允许进行DDL操作,不需要迁移的库表没有此限制。
迁移中的库表停止merge,不需要迁移的库表不会停止merge。
迁移任务开始前会重启,结束后也会重启一次。
迁移结束后,集群会持续一段时间高频merge操作,这会导致IO使用率上升,从而引起业务请求的延迟增加。建议您提前规划以应对业务请求延迟的潜在影响。具体merge操作时间,您需自己计算。如何计算,请参见计算迁移结束后的merge时间。
操作步骤
步骤一:自建集群检查并开启使用系统表system。
在数据迁移之前,您需根据自建集群是否已启用system.part_log和system.query_log,对config.xml文件进行修改配置,以实现增量迁移。
未启用system.part_log和system.query_log
如果您未启用system.part_log和system.query_log,您需在config.xml文件中增加以下内容。
system.part_log
<part_log>
<database>system</database>
<table>part_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>system.query_log
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>已启用system.part_log和system.query_log
您需根据下述内容,检查config.xml中
system.part_log和system.query_log的配置,如果存在不一致之处,需将其修改为以下配置,否则可能会导致迁移失败或迁移速度缓慢。system.part_log
<part_log> <database>system</database> <table>part_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </part_log>system.query_log
<query_log> <database>system</database> <table>query_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </query_log>修改配置后,您还需执行语句
drop table system.part_log和drop table system.query_log,在业务表插入数据后,会重新触发创建system.part_log和system.query_log。
步骤二:配置目标集群兼容自建集群版本。
配置目标集群兼容自建集群,尽量减少上云后,业务上的修改。
获取目标集群与自建集群的版本号并对比二者是否相同。
登录目标集群与自建集群,分别执行下述语句,获取二者的版本号。如何登录云数据库ClickHouse,请参见连接数据库。
SELECT version();如果对比结果不同,您需登录目标集群,通过修改compatibility参数与自建集群的版本号保持一致。使二者功能尽可能保持一致。示例如下。
SET GLOBAL compatibility = '22.8';
步骤三:(可选)目标集群开启使用MaterializedMySQL引擎。
如果自建集群中有引擎为MaterializedMySQL的表,您需执行下述语句,开启MaterializedMySQL引擎的使用。
SET GLOBAL allow_experimental_database_materialized_mysql = 1;ClickHouse社区已不再维护MaterializedMySQL引擎,建议您上云后,使用DTS同步MySQL数据。
针对MaterializedMySQL引擎社区不再维护问题,DTS将MySQL数据同步至云数据库ClickHouse时,其使用ReplacingMergeTree表代替了MaterializedMySQL表。更多详情,请参见MaterializedMySQL兼容性。
如何使用DTS迁移MySQL数据至云数据库ClickHouse,请参见下述文档。
步骤四:创建迁移任务
在集群列表页面,选择社区版实例列表,单击目标集群ID。
在左侧导航栏,单击。
在迁移任务页面,单击创建迁移任务。
配置源实例与目标实例。
配置以下信息,单击测试连接以进行下一步。
说明测试连接成功后,进入下一个步骤。如果测试连接失败,请根据提示,重新配置源实例和目标实例。
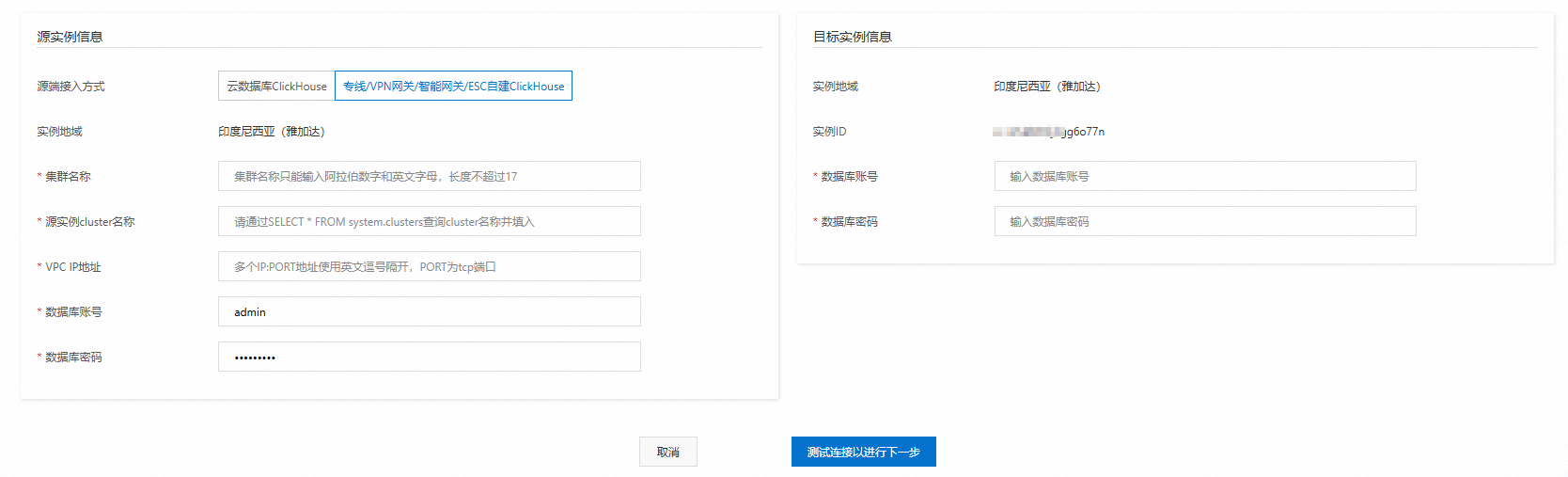
源集群配置项
配置项
说明
示例
源端接入方式
固定选择专线/VPN网关/智能网关/ECS自建ClickHouse。
专线/VPN网关/智能网关/ECS自建ClickHouse
集群名称
源集群的名称。
仅由阿拉伯数字和小写英文字母组成。
source
源实例cluster名称
您需通过
SELECT * FROM system.clusters;获取源实例cluster名称。default
VPC IP地址
集群每个shard的IP和PORT(即shard的TCP地址),并使用英文逗号隔开。
重要不能使用云ClickHouse的VPC域名地址或者SLB地址。
格式:
IP:PORT,IP:PORT,......根据自建上云的使用场景不同,集群IP和PORT的获取方法不同。
阿里云ClickHouse实例的跨账户、跨地域迁移
您可以使用以下SQL获取自建集群的IP和PORT。
SELECT shard_num, replica_num, host_address as ip, port FROM system.clusters WHERE cluster = 'default' and replica_num = 1;其中replica_num=1表示选择第一个副本集,您也可以选择其他副本集或者自行挑选每个shard的一个副本组成。
非阿里云ClickHouse实例迁移
如果IP不便映射到阿里云,您可以使用以下SQL获取自建集群的IP和PORT。
SELECT shard_num, replica_num, host_address as ip, port FROM system.clusters WHERE cluster = '<cluster_name>' and replica_num = 1;参数说明如下。
cluster_name:目标集群的名字。
replica_num=1表示选择第一个副本集,也可以选择其他副本集或者自行挑选每个shard一个副本组成。
如果IP和端口发生了转换后映射到阿里云,则需要根据网络打通情况配置对应的IP和PORT。
192.168.0.5:9000,192.168.0.6:9000
数据库账号
源集群数据库账号。
test
数据库密码
源集群数据库账号密码。
test******
目标集群配置项
配置项
说明
示例
数据库账号
目标集群数据库账号。
test
数据库密码
目标群数据库账号密码。
test******
确认迁移内容。
仔细阅读页面中数据迁移的包含内容提示信息,单击下一步:预检测并启动同步。
后台迁移链路预检测并启动任务。
后台会对目标集群和自建集群进行实例状态检测、存储空间检测和本地表和分布式表检测。
检测成功:
检测成功后的界面如下图所示。
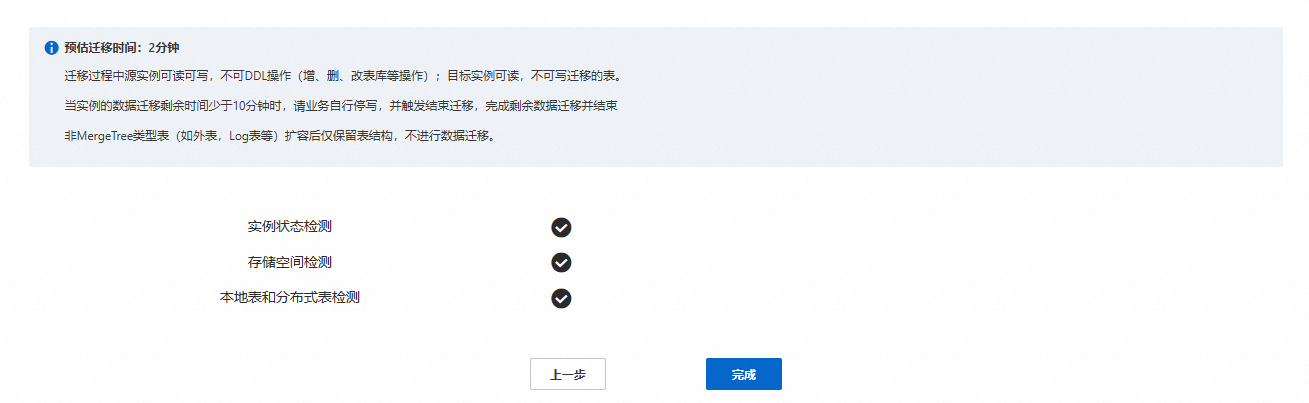
仔细阅读页面迁移过程中对实例的影响提示内容。
单击完成。
重要单击完成后,任务创建完成且启动,任务状态为运行中,您可在任务列表查看任务。
完成任务创建后,您还需监控迁移任务,在迁移完成的最后阶段,主动停写自建集群,进行剩余库表结构迁移。如何监控迁移任务,请参见监控迁移任务并停写自建集群。
检测失败:您需要按照提示信息进行操作,重新进行数据迁移。检测内容及要求如下。检测报错信息以及解决方案,请参见迁移检查中报错信息查询及解决方案。
检测项目
检测要求
实例状态检测
迁移发起时,自建集群和目标集群不能有正在运行的管控任务(包含扩容,升降配等)。如果当前自建集群和目标集群有管控任务正在运行,则不能发起迁移任务。
存储空间检测
迁移进行前,进行存储空间校验。保证目标集群的存储空间大于等于自建集群的已使用空间的1.2倍。
本地表和分布式表检测
如果自建集群存在本地表没有创建分布式表或者分布式表不唯一,则校验失败。请删除多余的分布式表或创建唯一分布式表。
步骤五:评估迁移是否可以完成
如果源集群的写入速度小于 20MB/s,您可跳过此步骤。
如果源集群的写入速度大于 20MB/s,由于目标集群理论上单节点写入速度也大于 20MB/s。为了确保目标集群的写入速度能够赶上源集群的写入速度,从而顺利完成迁移,您需要检查目标集群的真实写入速度,以评估迁移的可行性。具体操作如下:
步骤六:监控迁移任务并预估何时停写自建集群
在社区版实例列表,单击目标集群ID。
在左侧导航栏,单击。
在实例迁移列表页面,您可进行以下操作:
查看迁移任务的状态以及运行阶段信息。
重要您需重点监控目标任务的运行阶段信息,根据运行阶段信息列中预计剩余时间,按照步骤七,主动停写自建集群并处理Kafka和RabbitMQ引擎表。
单击操作列的查看详情进入任务详情页面,查看任务详情。任务详情包含以下内容。
说明如果迁移任务结束,即状态为已完成、已取消,则控制台上查看详情中的内容会被清空,您可在目标集群通过以下SQL查看迁移的表结构列表。
SELECT `database`, `name`, `engine_full` FROM `system`.`tables` WHERE `database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema');所有已迁移的表结构以及其是否迁移成功的状态。
所有迁移了的数据库结构及其是否迁移成功的状态。
所有库表迁移失败的报错信息。
迁移任务的各个状态及其对应的功能如下。
任务状态
功能描述
运行中
准备迁移的环境和资源中。
初始化
初始化迁移任务中。
配置迁移
迁移集群的配置。
库表结构迁移
迁移所有库,以及MergeTree族表和Distributed表。
数据迁移
增量迁移MergeTree族表的数据。
其他库表结构迁移
迁移物化视图和非MergeTree族表的表结构。
检查数据
检查目标集群已完成的表数据量和自建集群的表数据量是否一致,如果不一致,任务可能无法完成,建议重新进行迁移。
后置配置
迁移完成后的目标集群的系统配置,例如清理迁移现场、开启源实例写入等。
已完成
迁移任务已完成。
已取消
迁移任务已取消。
步骤七:停写自建集群并处理Kafka和RabbitMQ引擎表
业务切流前需要确保自建实例无新数据产生,进而保证迁移后数据的完整性。故需停止业务写入,并删除Kafka和RabbitMQ表。具体操作如下:
登录自建集群,通过以下语句,查询需要处理的表。
SELECT * FROM system.tables WHERE engine IN ('RabbitMQ', 'Kafka');查看目标表的建表语句。
SHOW CREATE TABLE <aim_table_name>;登录目标集群,执行上一步获取的建表语句。如何登录目标集群,请参见通过DMS连接ClickHouse。
登录自建集群,删除已经迁移了的Kafka和RabbitMQ引擎表。
重要删除Kafka时,需同时删除引用Kafka表的物化视图,否则会导致物化视图迁移无法完成,最终导致迁移无法完成。
步骤八:完成迁移任务
完成任务操作代表在您主动停写自建集群后,此任务完成剩余数据迁移,并进行数据量检查,迁移剩余的库表结构。已完成迁移的内容,您可通过查看任务详情获取。
如果检查不通过,迁移任务会一直处于数据量检查阶段。建议您取消迁移,重新创建迁移任务。如何取消迁移任务,请参见其他操作。
长时间的迁移数据会导致目标集群的元数据过多,进而会影响迁移的速度。建议您在迁移任务创建后的5天内完成此操作。
在集群列表页面,选择社区版实例列表,单击目标集群ID。
在左侧导航栏,单击。
在目标迁移任务的操作列,单击完成迁移。
在完成迁移对话框,单击确定。
步骤九:迁移非MergeTree类型表的业务数据
迁移任务中,非MergeTree类型的表(例如外表、Log表等)仅支持迁移表结构。迁移任务完成后,目标集群此类表只有表结构,没有具体的业务数据。具体业务数据迁移您需自主迁移。操作如下:
登录自建集群,通过以下语句,查看需要迁移数据的非MergeTree类型的表。
SELECT `database` AS database_name, `name` AS table_name, `engine` FROM `system`.`tables` WHERE (`engine` NOT LIKE '%MergeTree%') AND (`engine` != 'Distributed') AND (`engine` != 'MaterializedView') AND (`engine` NOT IN ('Kafka', 'RabbitMQ')) AND (`database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema')) AND (`database` NOT IN ( SELECT `name` FROM `system`.`databases` WHERE `engine` IN ('MySQL', 'MaterializedMySQL', 'MaterializeMySQL', 'Lazy', 'PostgreSQL', 'MaterializedPostgreSQL', 'SQLite') ))登录目标集群,通过
remote函数进行迁移表数据。具体操作,请参见通过remote函数进行数据迁移。
其他操作
迁移任务完成相关操作后,任务的迁移状态会变成已完成,但务列表不会立即更新,建议您,通过间隔刷新查看任务状态。
操作 | 功能含义 | 影响 | 使用场景 |
取消迁移 | 强制取消任务,跳过数据量检查,不迁移剩余的库表结构。 |
| 迁移任务影响了自建集群,希望尽快结束迁移,开启写入。 |
停止迁移 | 立刻停止迁移数据,跳过数据量检查,迁移剩余的库表结构。 | 目标集群重启。 | 期望迁移一部分数据后测试,但是不想停写自建集群。 |
停止迁移
在集群列表页面,选择社区版实例列表,单击目标集群ID。
在左侧导航栏,单击。
在目标迁移任务的操作列,单击停止迁移。
在停止迁移对话框,单击确定。
取消迁移
在集群列表页面,选择社区版实例列表,单击目标集群ID。
在左侧导航栏,单击。
在目标迁移任务的操作列,单击取消迁移。
在取消迁移对话框,单击确定。
手动迁移
方法一:使用BACKUP与RESTORE命令迁移
具体操作,请参见使用BACKUP和RESTORE命令实现数据备份恢复。
方法二:使用 INSERT FROM SELECT语句迁移
步骤一:元数据(建表的DDL)的迁移
ClickHouse元数据的迁移,主要指进行建表DDL迁移。
如需安装clickhouse-client工具,请安装与目标实例云数据库ClickHouse版本一致的clickhouse-client工具。下载链接,请参见clickhouse-client。
查看自建集群的database列表。
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="SHOW databases" > database.list参数说明:
参数
描述
old host
自建集群的地址。
old port
自建集群的端口。
old user name
登录自建集群的账号,拥有DML读写和设置权限,允许DDL权限。
old password
上述账号对应的密码。
说明system是系统数据库,不需要迁移,可以直接过滤掉。
查看自建集群的table列表。
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="SHOW tables from <database_name>" > table.list参数说明:
参数
描述
database_name
数据库名称
您也可以通过系统表直接查询所有database和table名称。
SELECT DISTINCT database, name FROM system.tables WHERE database != 'system';说明查询到的表名中,如果有以.inner.开头的表,则它们是物化视图的内部表示,不需要迁移,可以直接过滤掉。
导出自建集群中指定数据库下所有表的建表DDL。
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="SELECT concat(create_table_query, ';') FROM system.tables WHERE database='<database_name>' FORMAT TabSeparatedRaw" > tables.sql将建表DDL导入到目标实例云数据库ClickHouse。
说明您需要在建表DDL导入之前,在云数据库ClickHouse中创建表所在数据库。
clickhouse-client --host="<new host>" --port="<new port>" --user="<new user name>" --password="<new password>" -d '<database_name>' --multiquery < tables.sql参数说明:
参数
描述
new host
目标实例云数据库ClickHouse的地址。
new port
目标实例云数据库ClickHouse的端口。
new user name
登录目标实例云数据库ClickHouse的账号,拥有DML读写和设置权限,允许DDL权限。
new password
上述账号对应的密码。
步骤二:数据迁移
通过remote函数进行数据迁移
在目标实例云数据库ClickHouse中,通过如下SQL进行数据迁移。
INSERT INTO <new_database>.<new_table> SELECT * FROM remote('<old_endpoint>', <old_database>.<old_table>, '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0, max_result_rows = 0;说明20.8版本优先使用remoteRaw函数进行数据迁移,如果失败可以申请小版本升级。
INSERT INTO <new_database>.<new_table> SELECT * FROM remoteRaw('<old_endpoint>', <old_database>.<old_table>, '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0, max_result_rows = 0;参数说明:
重要通过partition_id对数据过滤后,可以减少资源占用,建议您选用此参数。
参数
描述
new_database
目标云数据库ClickHouse实例中的数据库名。
new_table
目标实例云数据库ClickHouse中的表名。
old_endpoint
源实例的endpoint。
自建ClickHouse
endpoint格式:
源实例节点的IP:port。重要此处port为TCP port。
云数据库ClickHouse
源实例的endpoint为VPC内网endpoint,不是公网endpoint。
重要以下端口3306和9000是固定值。
社区版实例:
endpoint格式:
VPC内网地址:3306。示例:
cc-2zeqhh5v7y6q*****.clickhouse.ads.aliyuncs.com:3306
企业版实例:
endpoint格式:
VPC内网地址:9000。示例:
cc-bp1anv7jo84ta*****clickhouse.clickhouseserver.rds.aliyuncs.com:9000
old_database
自建集群的数据库名。
old_table
自建集群的表名。
username
自建集群的账号。
password
自建集群的密码。
max_execution_time
查询的最大执行时间。设置为0表示没有时间限制。
max_bytes_to_read
查询在读取源数据时能读取的最大字节数。设置为0表示没有限制。
log_query_threads
是否记录查询执行的线程信息。设置为0表示不记录线程信息。
max_result_rows
查询结果的最大行数。设置为0表示没有限制。
_partition_id
数据分区ID。
通过文件导出导入方式进行数据迁移
通过文件,将数据从自建集群数据库导出到目标实例云数据库ClickHouse中。
通过CSV文件导出导入
将数据从自建集群数据库导出为CSV格式文件。
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="select * from <database_name>.<table_name> FORMAT CSV" > table.csv导入CSV文件到目标实例云数据库ClickHouse。
clickhouse-client --host="<new host>" --port="<new port>" --user="<new user name>" --password="<new password>" --query="insert into <database_name>.<table_name> FORMAT CSV" < table.csv
通过Linux pipe管道进行流式导出导入
clickhouse-client --host="<old host>" --port="<old port>" --user="<user name>" --password="<password>" --query="select * from <database_name>.<table_name> FORMAT CSV" | clickhouse-client --host="<new host>" --port="<new port>" --user="<user name>" --password="<password>" --query="INSERT INTO <database_name>.<table_name> FORMAT CSV"
迁移检查中报错信息查询及解决方案
检查报错信息 | 含义 | 解决方案 |
Missing unique distributed table or sharding_key not set. | 自建集群的本地表缺失唯一分布式表。 | 迁移前,自建集群的本地表需要创建对应的分布式表。 |
The corresponding distribution table is not unique. | 自建集群的本地表对应的分布式表存在多个。 | 自建集群删除多余的分布式表,保留其中一个。 |
MergeTree table on multiple replica cluster. | 自建集群为多副本集群,但是存在非Replicated表,数据在副本之间不一致,不支持迁移。 | |
Data reserved table on destination cluster. | 需要迁移的表在目标集群存在数据。 | 删除目标集群对应的表。 |
Columns of distributed table and local table conflict | 自建集群的分布式表和本地表的列不一致。 | 自建集群重建分布式表,和本地表保持一致。 |
Storage is not enough. | 目标集群存储空间不足。 | 升配目标集群磁盘空间,满足目标集群总空间大于1.2倍的自建集群使用空间。如何升配,请参见社区兼容版集群垂直变配和水平扩缩容。 |
Missing system table. | 自建集群系统表缺失。 | 修改自建集群配置config.xml,创建必须的系统表。如何配置,请参见步骤一:自建集群检查并开启使用系统表system。 |
The table is incomplete across different nodes. | 该表在部分节点缺失。 | 需要在不同分片创建同名的表。针对物化视图inner表,建议重命名inner表,然后重建物化视图,指向重命名后的inner表。具体操作,请参见物化视图inner表在不同分片不一致。 |
计算迁移结束后的merge时间
迁移结束后,目标集群会持续一段时间的高频merge操作,这会导致IO使用率上升,从而引起业务请求的延迟增加。如果您的业务对读写数据延迟敏感,建议您升配实例规格和磁盘PL等级,缩短merge引发IO使用率高的时间。如何升配,请参见社区兼容版集群垂直变配和水平扩缩容。
迁移结束后的merge时间具体计算公式如下:
单副本和双副本集群都可使用以下公式计算。
预计高频merge操作总时间 =
MAX(热存数据merge时间,冷存数据merge时间)热存数据merge时间 =
单节点热数据量 * 2 / MIN(实例规格带宽, 磁盘带宽*n)冷存数据merge时间 =
(冷数据量/节点数) / MIN(实例规格带宽, OSS读带宽) + (冷数据量/节点数) / MIN(实例规格带宽, OSS写带宽)
参数说明如下。
单节点热数据量:您可通过查看集群监控信息查看磁盘使用量-单节点统计行的数据。
实例规格带宽
说明实例规格带宽数据并非绝对。如果云数据库ClickHouse后台使用了不同的机型,该参数将会有所不同。此处的数据为最低带宽,以供参考。
规格
带宽 (MB/s)
标准型8核32GB
250
标准型16核64GB
375
标准型24核96GB
500
标准型32核128GB
625
标准型64核256GB
1250
标准型80核384GB
2000
标准型104核384GB
2000
磁盘带宽:请参见ESSD云盘性能级别表格中单盘最大吞吐量(MB/s)行的数据。
n:表示单节点磁盘数量,您可通过
SELECT count() FROM system.disks WHERE type = 'local';获取。冷数据量:您可通过查看集群监控信息查看冷存使用量行的数据。
节点数:集群的节点数量,您可通过
SELECT count() FROM system.clusters WHERE cluster = 'default' and replica_num=1;获取。OSS读带宽:请参见OSS带宽表格中内外网总下载带宽列的数据。
OSS写带宽:请参见OSS带宽表格中内外网总上传带宽列的数据。
常见问题
Q:如何处理报错:“Too many partitions for single INSERT block (more than 100)”?
A:单个INSERT操作中超过了max_partitions_per_insert_block(最大分区插入块,默认值为100)。ClickHouse每次写入都会生成一个data part(数据部分),一个分区可能包含一个或多个data part,如果单个INSERT操作中插入了太多分区的数据,那会造成ClickHouse内部有大量的data part,这会给合并和查询造成很大的负担。为了防止出现大量的data part,ClickHouse内部做了限制。
解决方案:请执行以下操作,调整分区数或者max_partitions_per_insert_block参数。
调整表结构,调整分区方式,或避免单次插入的不同分区数超过限制。
避免单次插入的不同分区数超过限制,可根据数据量适当修改max_partitions_per_insert_block参数,放大单个插入的不同分区数限制,修改语法如下:
SET GLOBAL ON cluster DEFAULT max_partitions_per_insert_block = XXX;说明ClickHouse社区推荐默认值为100,分区数不要设置得过大,否则可能对性能产生影响。在批量导入数据后可以将值修改为默认值。
Q:为什么目标实例云数据库ClickHouse连接自建数据库ClickHouse连接失败?
A:可能是您的自建数据库ClickHouse设置了防火墙或白名单等操作。您需在自建数据库ClickHouse的白名单中添加云数据库ClickHouse的交换机 ID的IPv4网段。如何获取云数据库ClickHouse的交换机 ID的IPv4网段,请参见查看IPv4网段。
Q:扩缩容和迁移多副本实例时,为什么不允许存在非Replicated表?如果存在,如何解决?
A:原因及解决方案如下:
原因分析:多副本实例需要使用Replicated表才能实现数据在副本间同步,否则多副本将失去意义。迁移工具随机选择其中一个副本作为数据源将数据迁移到目标实例。
如果存在非Replicated表,导致不同副本之间数据无法同步,数据处于单副本状态。迁移工具只会迁移其中一个副本的数据,进而导致数据缺失。如下图所示,副本0(r0)的MergeTree表存在1、2、3数据;副本1(r1)的MergeTree表存在4、5数据。迁移到目标实例后,只剩下1、2、3数据。

解决方案:如果源实例非Replicated表可以删除,建议优先选择删除表。否则,需要将源实例的非Replicated表替换为Replicated表。具体操作如下:
登录源实例。
创建Replicated表,除了引擎以外,表结构必须与要替换的非Replicated表保持一致。
手动将非Replicated表的数据迁移到新建的Replicated表。迁移语句如下。
重要每个副本都需迁移,即r0和r1都需要执行。
语句中节点IP可通过
SELECT * FROM system.clusters;获取。INSERT INTO <目标库>.<新建的Replicated表> SELECT * FROM remote('<节点IP>:3003', '<源库>', '<要替换的非Replicated表>', '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0;将非Replicated表和Replicated表互换名字
EXCHANGE TABLES <源库>.<要替换的非Replicated表> AND <目标库>.<新建的Replicated表> ON CLUSTER default;