
本文介绍了基于LHM调度迁移工具将Azure Data Factory调度任务流迁移到DataWorks的方案与操作流程,包括三步,Azure Data Factory任务导出、调度任务转换、DataWorks任务导入。
一、环境准备
1.1 运行环境准备
序号 | 项 | 规格 | 数量 | 备注 |
1 | ECS | 4c16g以上 | 1 | 镜像CentOS、AliyunOS均可 |
2 | jdk17 | |||
3 | 运行工具包 |
1.2 网络准备
ECS对应的VPC需要能访问公网
1.3 账号权限准备
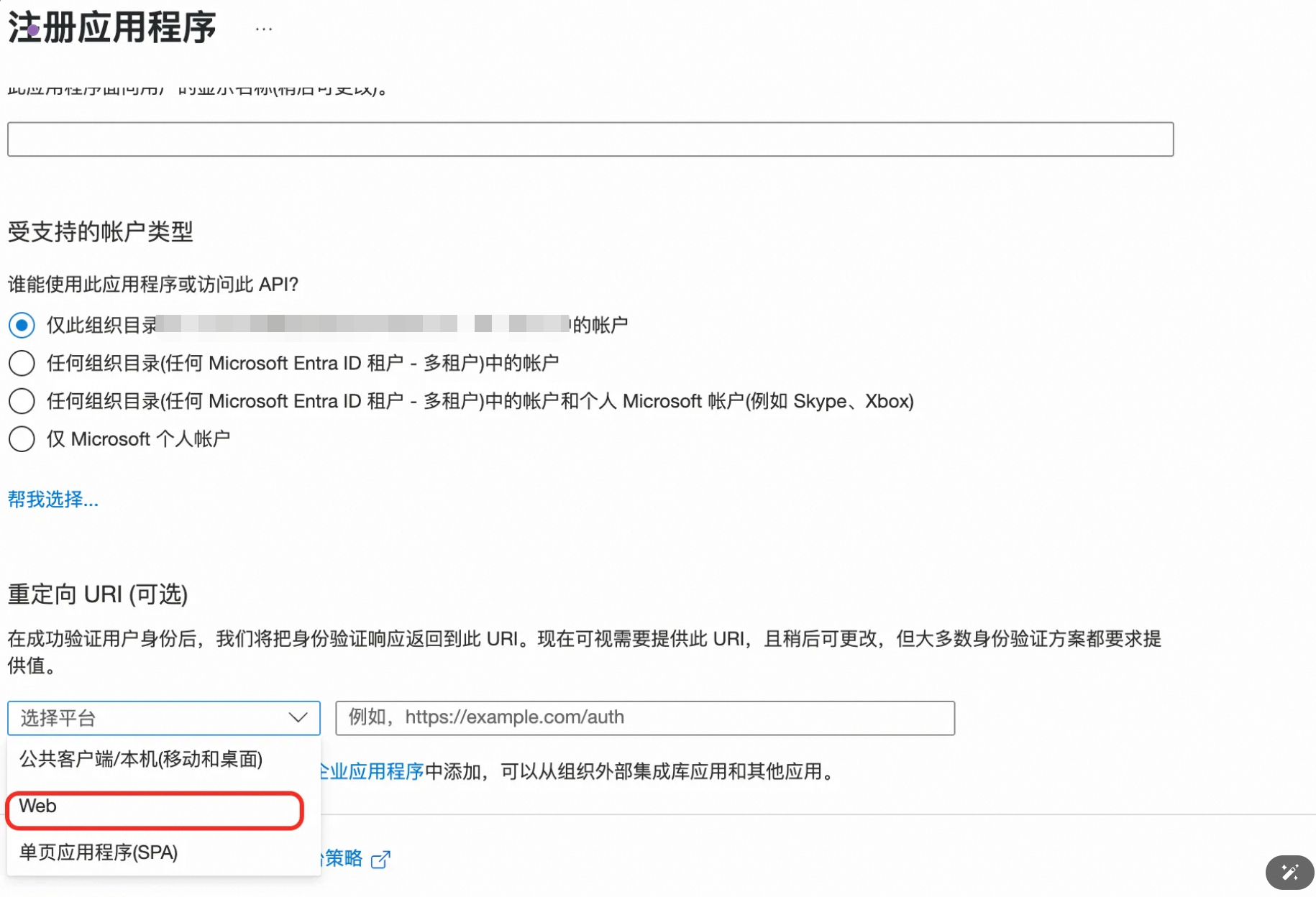
1.3.1 采用服务注册认证的方式
注册应用程序
获取客户端密钥

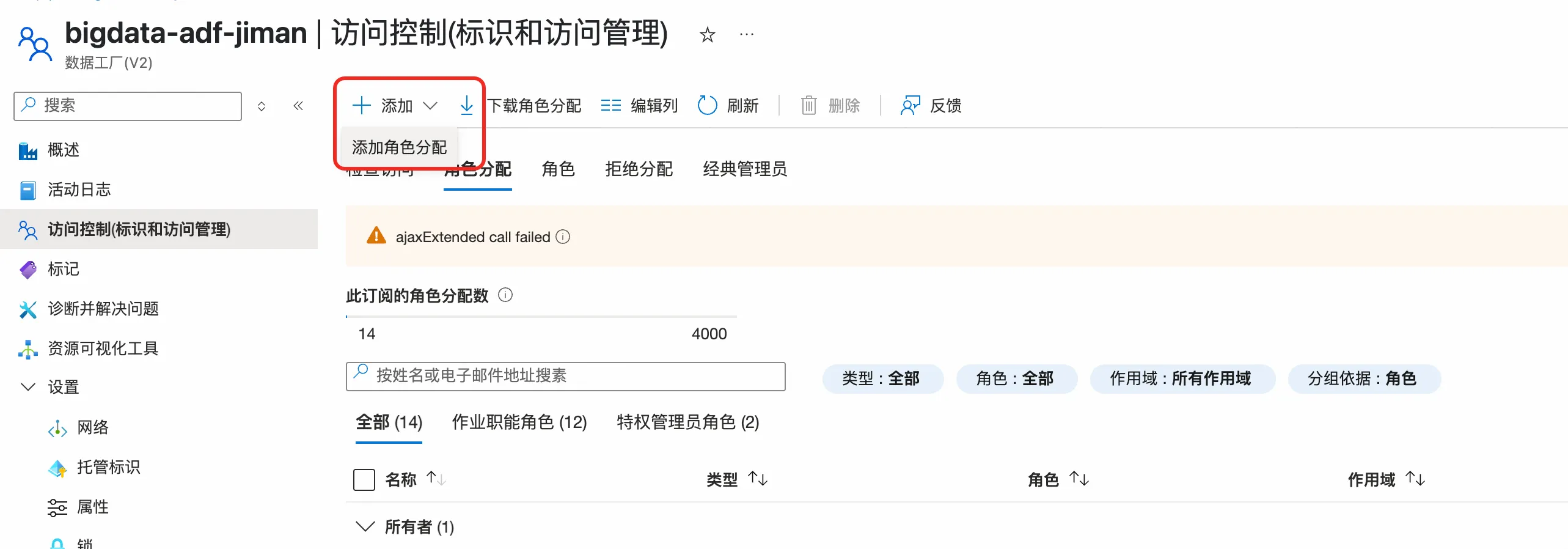
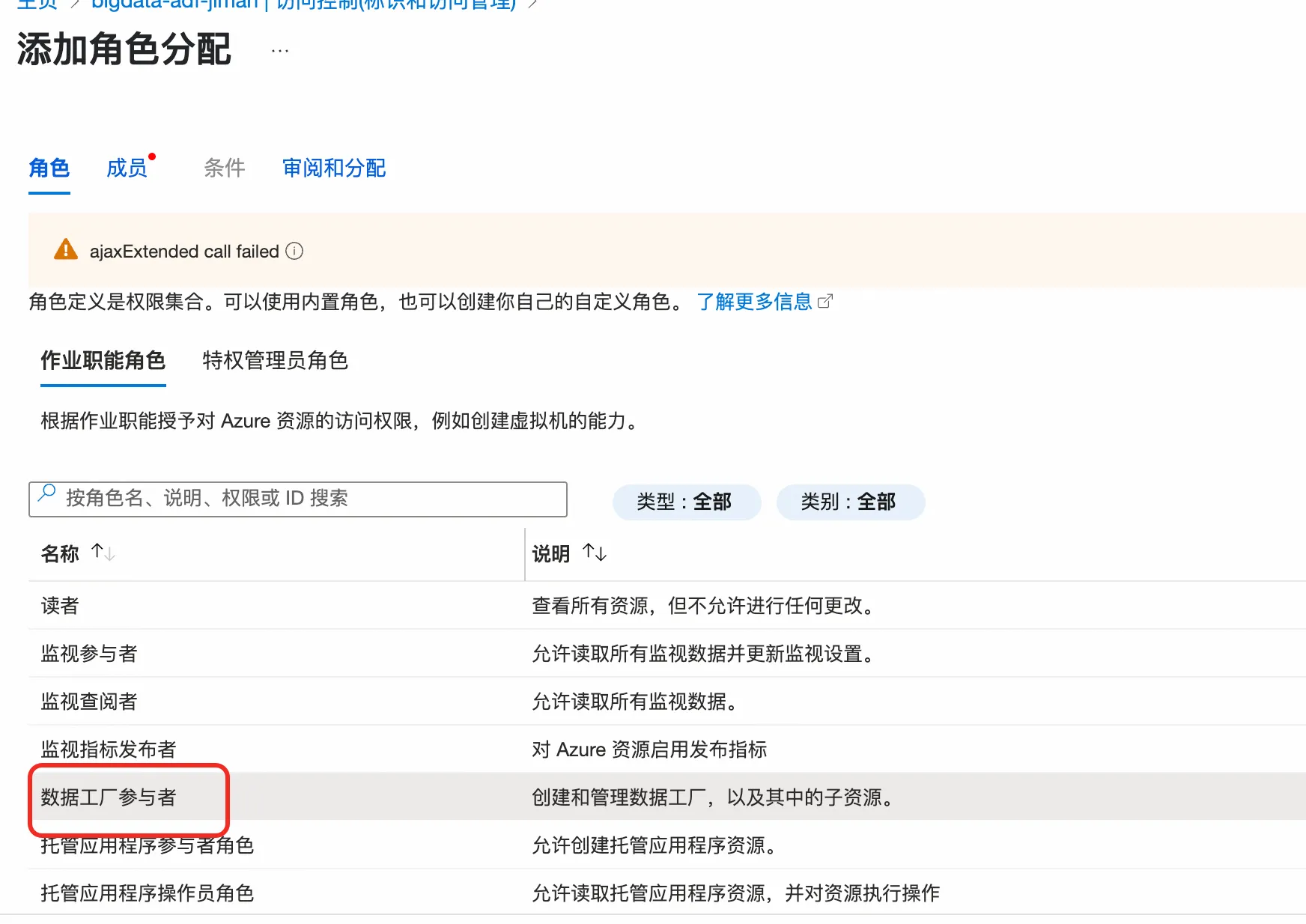
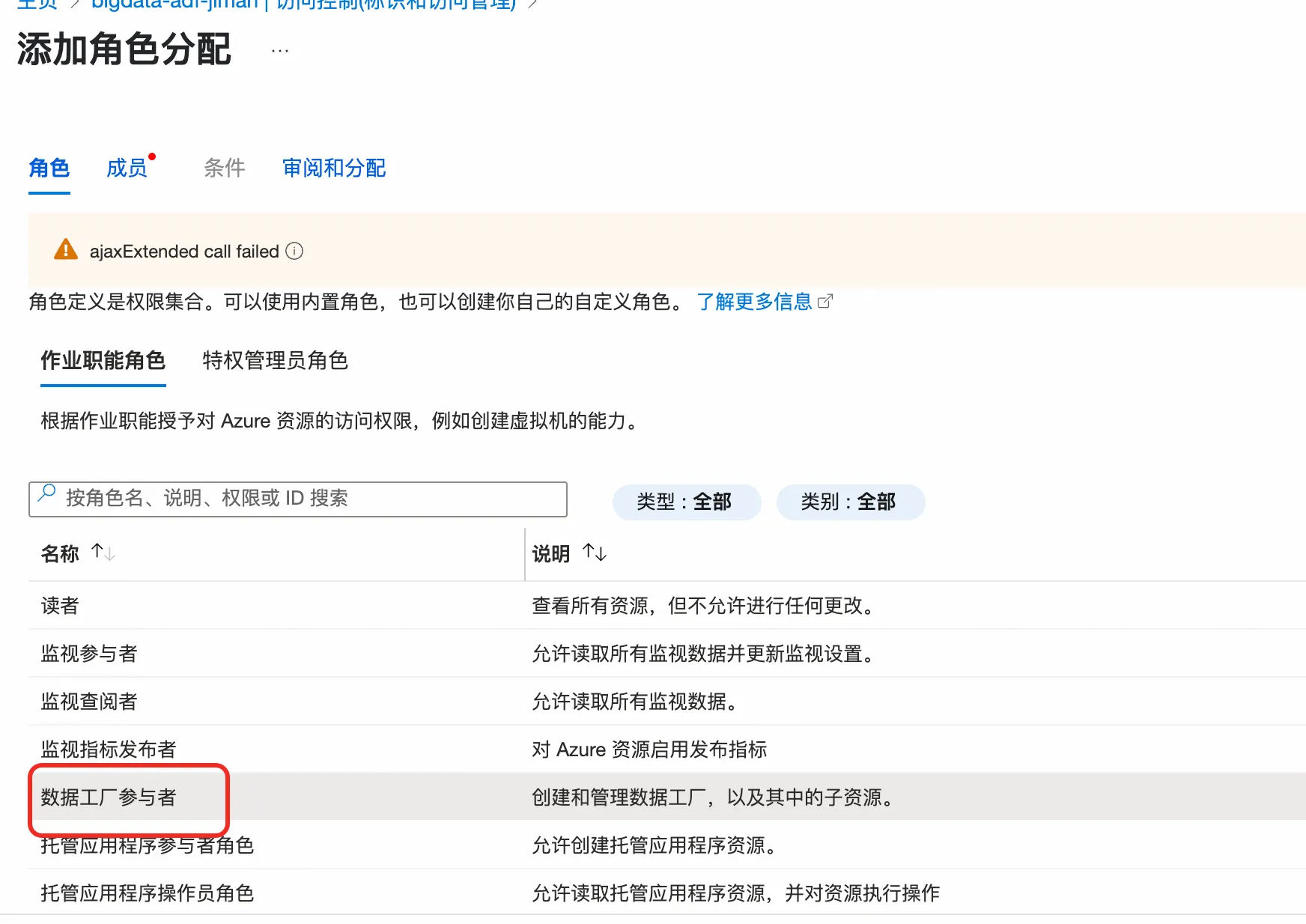
1.3.2 配置Azure Data Factory权限
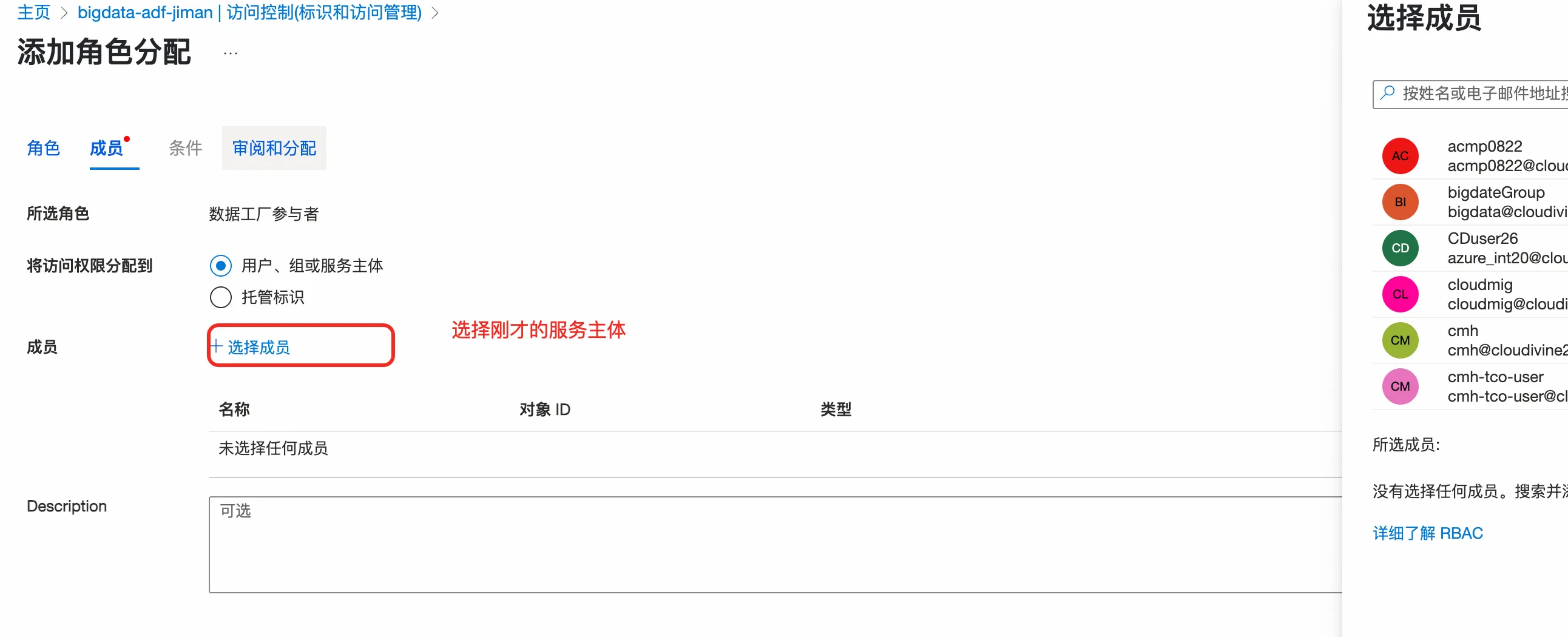
1.3.3. 配置blob权限
非必需,如果要读取节点中blob中存在的文件内容,需要使用ADF服务注册授权同样的方式来对blob进行授权
1.3.4 配置Databricks权限
非必需,主要用来读取Azure Data Factory 中关于Databricks节点具体外置脚本文件
进入dbr工作台
点击用户设置
进入左侧开发者界面
点击生成新令牌
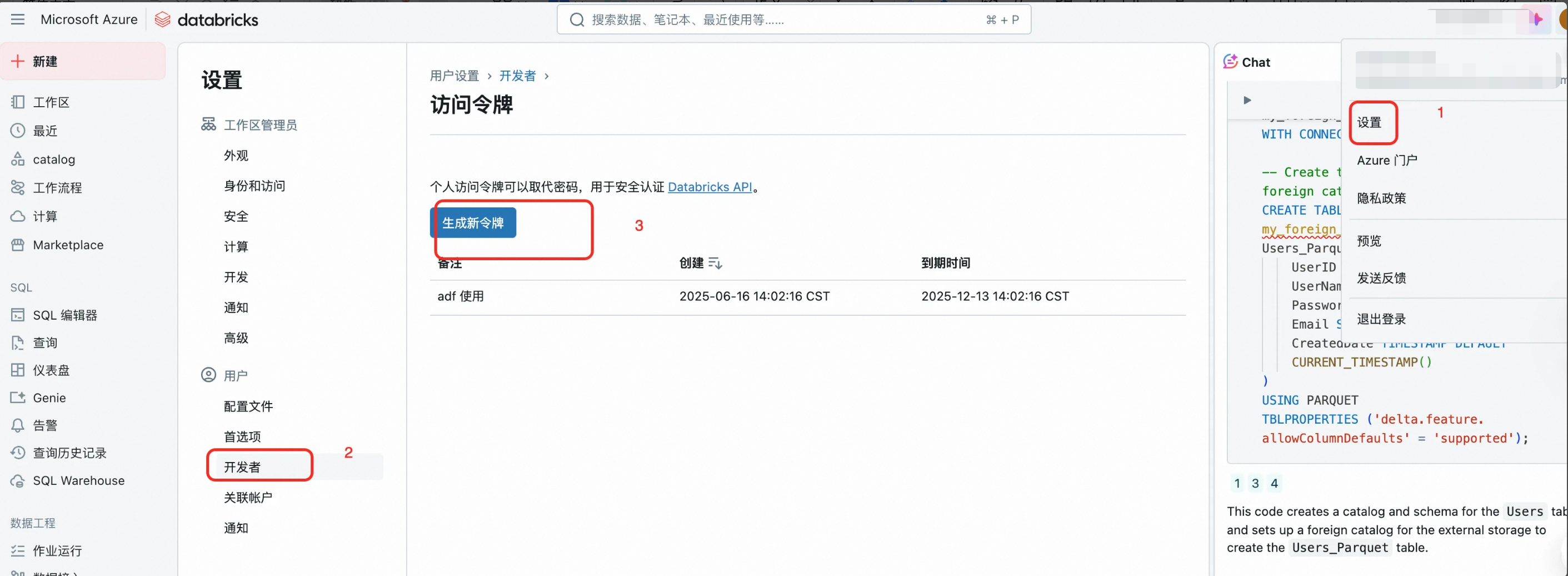
二、AzureDataFactory任务导出
采用SDK方式导出,依赖项如下
<dependency>
<groupId>com.azure.resourcemanager</groupId>
<artifactId>azure-resourcemanager-datafactory</artifactId>
</dependency>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-identity</artifactId>
</dependency>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-storage-blob</artifactId>
</dependency>
<dependency>
<groupId>com.databricks</groupId>
<artifactId>databricks-sdk-java</artifactId>
</dependency>2.1 配置文件
{
"schedule_datasource": {
"name": "name",
"type": "adf",
"properties": {
"isUseProxy": false,
"proxyHost": "proxy.msl.cn",
"proxyPort": "8080",
"AzureCloud": "AZURE_CHINA_CLOUD",
"apiMode": "sdk"
"endpoint": "https://management.azure.com",
"subscriptionId": "xxx",
"factory": "bigdata-adf-jiman",
"project": "bigdata-adf-jiman",
"resourceGroupName": "biadata",
"tenantId": "xxx",
"clientId": "xxx",
"clientSecretValue": "xxxx",
"dbr_endpoint": "https://adb-xxxxx.16.azuredatabricks.net",
"dbr_token": "xxxxx",
"pipelineNameWhite": "dbr-demo"
},
"operaterType": "AUTO"
}
}2.2 配置项说明
序号 | 参数名 | 是否必填 | 样例值 | 备注 |
1 | isUseProxy | 否 | false | 当使用代理模式来访问Azure时必需 |
2 | proxyHost | 否 | proxy.msl.cn | 当使用代理模式来访问Azure时必需 |
3 | proxyPort | 否 | 8080 | 当使用代理模式来访问Azure时必需 |
4 | AzureCloud | 否 | AZURE_CHINA_CLOUD | 可选项如下: 分别对应不同的区域,默认为AZURE_CHINA_CLOUD
|
5 | endpoint | 否 | https://portal.azure.com | 跟AzureCloud绑定,可不填 |
6 | subscriptionId | 是 | xxxxx | 订阅ID,可以在adf对应的主页概览获取 |
7 | resourceGroupName | 是 | xxxxx | 资源组名字,可以在adf对应的主页概览获取 |
8 | factory | 是 | bigdata-adf-jiman | 主要用来做标识 |
9 | project | 否 | bigdata-adf-jiman | 和factory保持一致即可 |
10 | tenantId | 是 | xxxxx | 在服务注册步骤中可以获取到 |
11 | clientId | 是 | xxxxx | 在服务注册步骤中可以获取到 |
12 | clientSecretValue | 是 | xxxxx | 在服务注册步骤中可以获取到 |
13 | dbr_endpoint | 否 | xxxxx | 在databricks首页获取 |
14 | dbr_token | 否 | xxxxx | 在databricks首页获取 |
15 | pipelineNameWhite | 否 | dbr-demo | 白名单,多个pipeline名称用,分割 |
2.3 执行导出命令
mkdir result
sh ./bin/run.sh read \
-c ./conf/<你的配置文件>.json \
-o ./data/1_ReaderOutput/<源端探查导出包>.zip \
-t adf-reader命令参数说明
序号 | 参数名 | 是否必填 | 样例参数值 | 备注 |
1 | -c | 是 | ./conf/<你的配置文件>.json | 配置文件路径 |
2 | -o | 是 | ./data/1_ReaderOutput/<源端探查导出包>.zip | 输出路径 |
3 | -t | 是 | adf-reader | 插件类型(固定值) |
完整命令样例
mkdir result
sh ./bin/run.sh read -c ./conf/read.json -f ./result/temp.zip -o ./result/read_out.zip -t adf-reader2.4 查看导出结果
打开./data/1_ReaderOutput/下的生成包ReaderOutput.zip,可预览导出结果。其中,统计报表是任务流、节点、资源、函数、数据源基本信息的汇总展示,而data/project文件夹下是对调度信息数据结构标准化后的结果。

统计报表提供了两项特殊能力:
1、报表中工作流、节点的部分属性被允许更改,允许更改的字段以蓝色字体标识。在下一阶段导入DataWorks时,工具将获取表格中的属性变更并使其生效。
2、报表允许通过删除工作流子表中的行,使得在导入DataWorks时跳过这些工作流(工作流黑名单)。注意!若工作流存在相互依赖关系,相关联的工作流需要同批次导入,不可通过黑名单进行分割。分割会产生异常!
三、调度任务转换
3.1 配置文件
{
"conf": {
"locale": "zh_CN"
},
"self": {
"if.use.default.convert": false,
"if.use.migrationx.before": false,
"if.use.dataworks.newidea": true,
"filter.rule": []
},
"schedule_datasource": {
"name": "adf",
"type": "Adf"
},
"target_schedule_datasource": {
"name": "name",
"type": "DataWorks"
}
}3.2 配置项说明
目前默认即可
序号 | 参数名 | 是否必填 | 样例值 | 备注 |
1 | filter.rule | 否 | [ { "type": "black", "element": "node", "field": "name", "value": "DataXNode" } ] | 过滤规则,可不填。 type标识黑白名单,可选项: BLACK| WHITE element标识筛选元素类型,支持workflow和node,可选项:NODE| WORKFLOW field标识按照名称或者按照id来筛选,可选项:ID|NAME value标识具体的值,多个可用,分割 |
schedule_datasource.name标识数据源,对应的是所有workflow的根目录
3.3 节点内置转换映射逻辑
3.3.1 常规节点映射逻辑
ADF节点类型 | DW节点类型 | 备注 |
Copy | DI | 目前仅有原始的json脚本,di具体的内容跟数据源类型相关,需要拿到所有di相关的数据源类型才能想办法转换 |
Delete | DIDE_SHELL | 拼接了删除文件路径的shell |
SqlServerStoredProcedure | ODPS-SQL | 默认为odps节点,如果判断逻辑是sqlserver,则节点类型为Sql Server |
DatabricksSparkJar | ODSP-SPARK | 用已经有的参数转换了odps spark节点,可能存在遗漏 |
DatabricksSparkPython | ODSP-SPARK | 用已经有的参数转换了odps spark节点,可能存在遗漏 |
DatabricksNotebook | NOTEBOOK | scala相关的cell未做处理 |
SynapseNotebook | NOTEBOOK | scala相关的cell未做处理 |
SparkJob | ODSP-SPARK | 暂时转为虚拟节点 |
AppendVariable | CONTROLLER_ASSIGNMENT | 赋值节点 |
ExecutePipeline | SUB_PROCESS | |
Script | ODPS_SQL | |
Wait | DIDE_SHELL | |
WebActivity | DIDE_SHELL | |
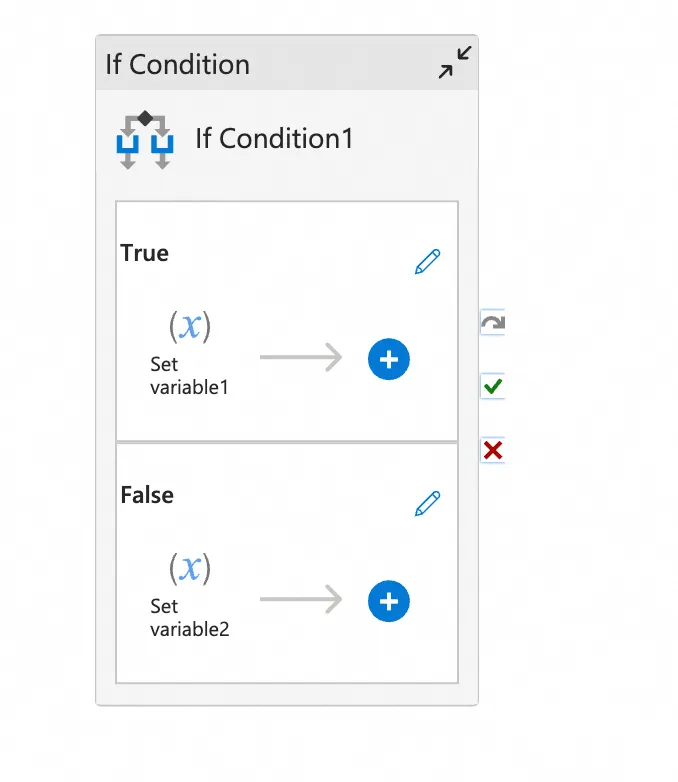
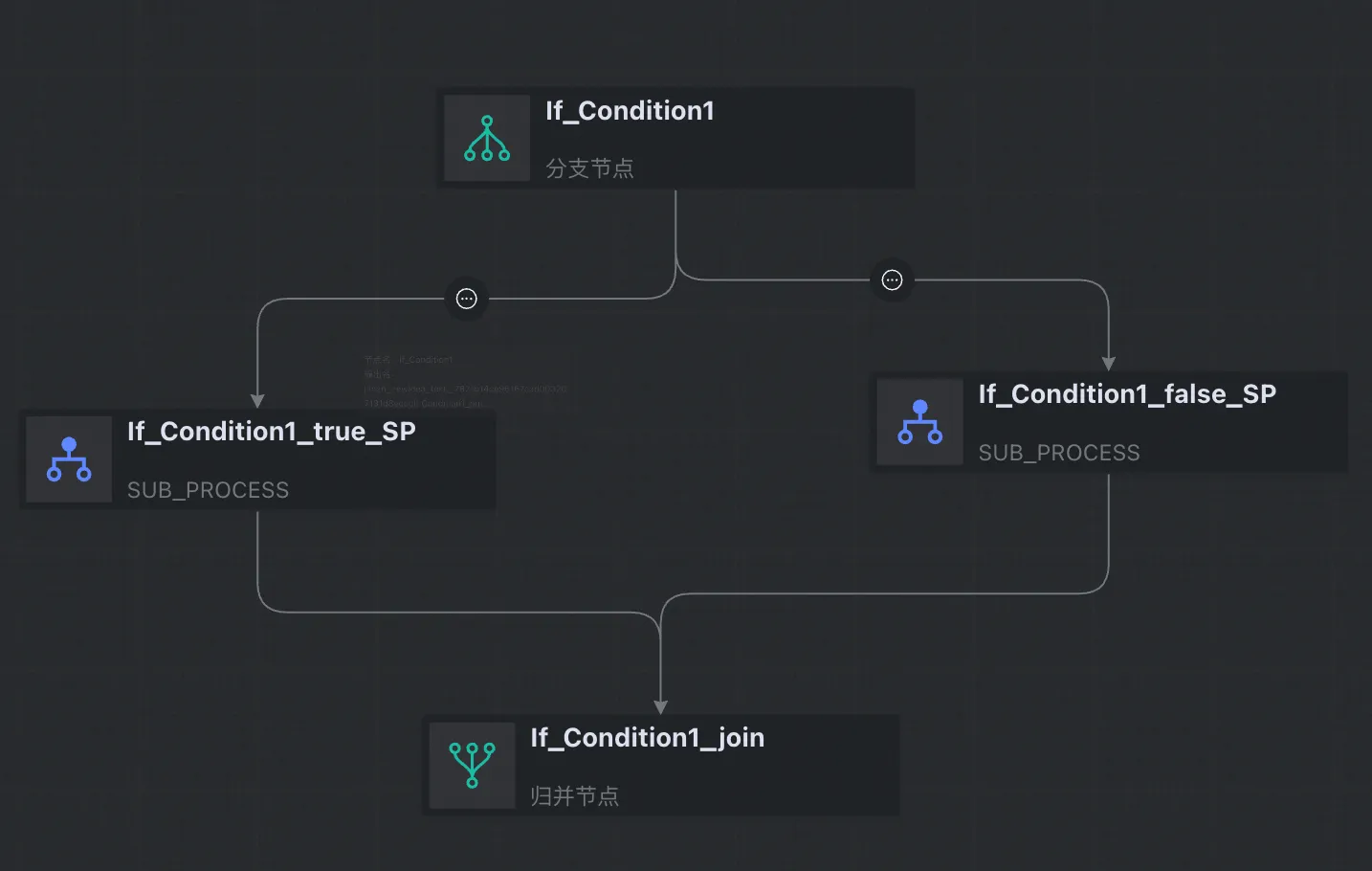
IfCondition | CONTROLLER_BRANCH | 转为分支+subprocess+归并 |
FOREACH | CONTROLLER_TRAVERSE | Foreach |
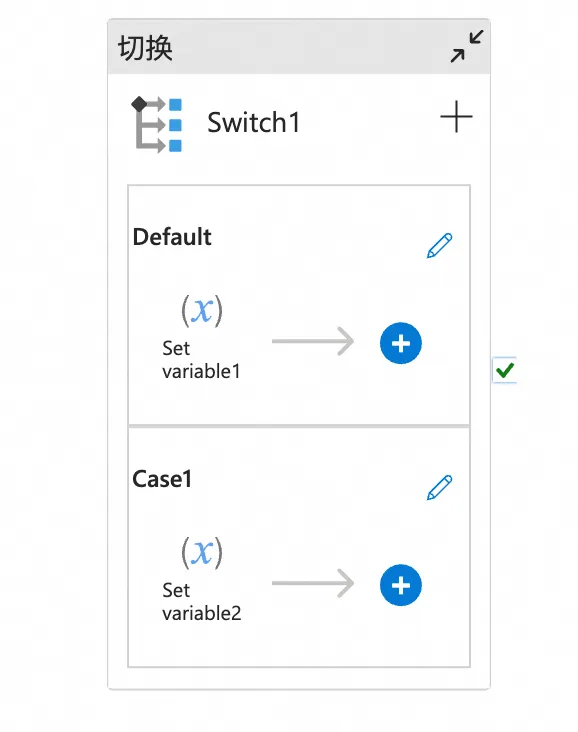
Switch | CONTROLLER_BRANCH | 转为分支+subprocess+归并 |
Until | CONTROLLER_CYCLE | do-while节点 |
Lookup | CONTROLLER_ASSIGNMENT | |
Filter | CONTROLLER_ASSIGNMENT | |
GetMeta | CONTROLLER_ASSIGNMENT | |
SetVariable | CONTROLLER_ASSIGNMENT | |
HDInsightHive | ODPS-SQL | |
HDInsightSpark | ODPS_Spark | |
HDInsightMapReduce | ODPS_MR | |
其他 | VIRTUAL |
备注:目前资源文件需要手工上传
3.3.2 逻辑节点映射逻辑
ifcondition
foreach
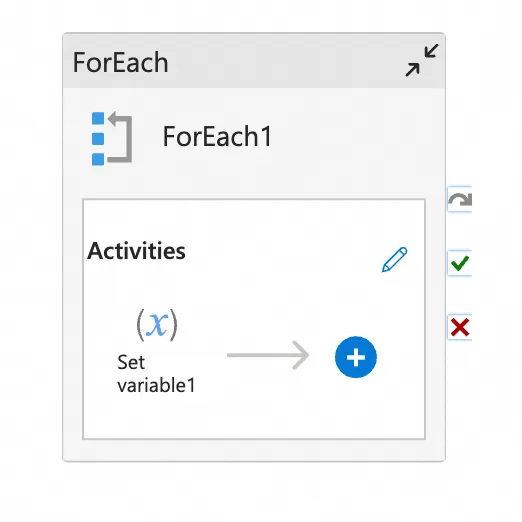
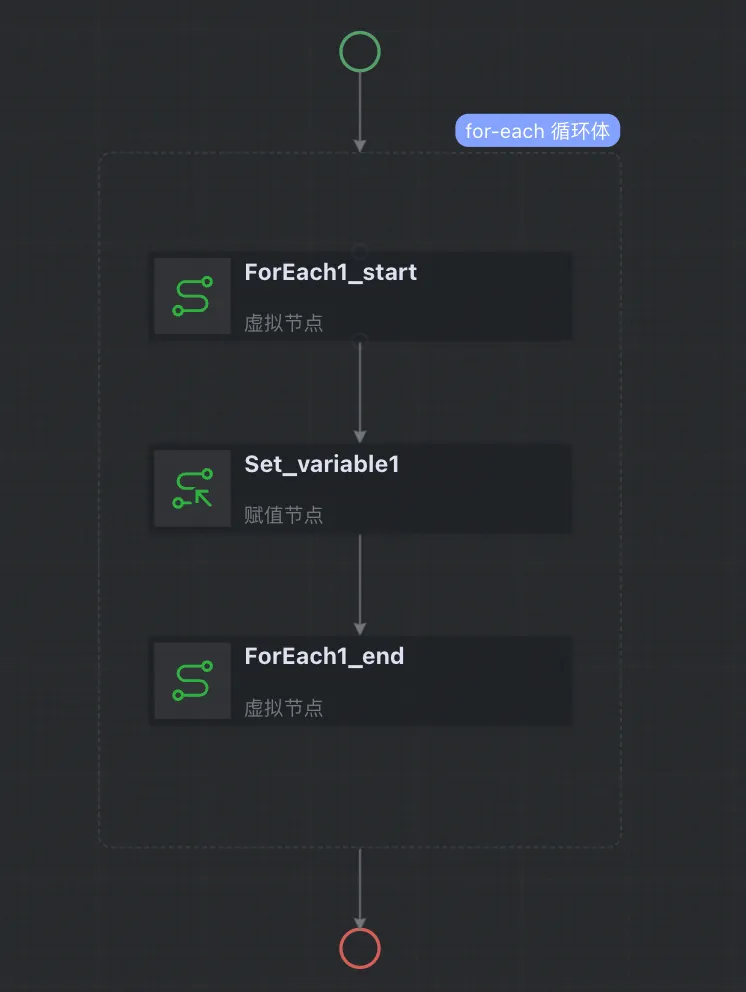
switch
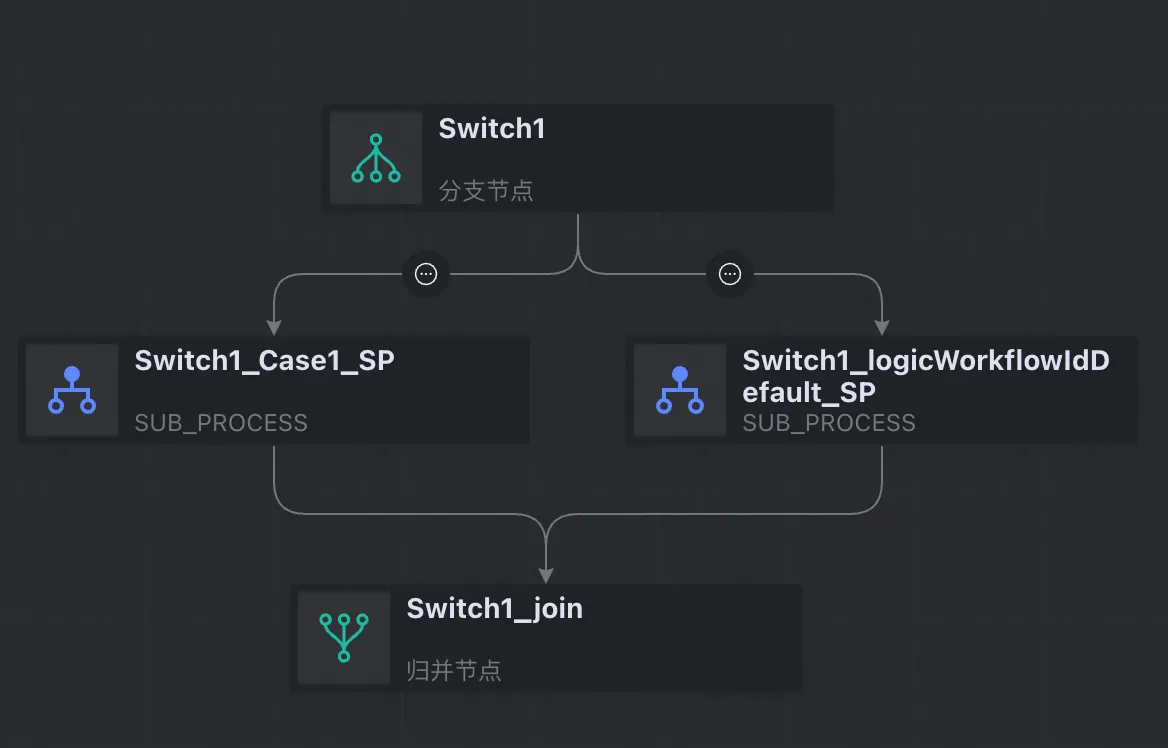
3.3.3 执行转换命令
sh ./bin/run.sh convert \
-c ./conf/<你的配置文件>.json \
-f ./data/1_ReaderOutput/<源端探查导出包>.zip \
-o ./data/2_ConverterOutput/<转换结果输出包>.zip \
-t wedata-dw-converter序号 | 参数名 | 是否必填 | 样例参数值 | 备注 |
1 | -c | 是 | ./conf/<你的配置文件>.json | 配置文件路径 |
2 | -f | 是 | ./data/1_ReaderOutput/<源端探查导出包>.zip | 探查导出包 |
3 | -o | 是 | ./result/convert_out.zip | 输出包路径 |
4 | -t | 是 | adf-dw-converter | 插件类型(固定值) |
3.3.4 查看转换结果
打开./data/2_ConverterOutput/下的生成包ConverterOutput.zip,可预览导出结果。
其中,统计报表是对转换结果任务流、节点、资源、函数、数据源基本信息的汇总展示。
而data/project文件夹是转换完成的调度迁移包本体。

统计报表提供了两项特殊能力:
1、报表中工作流、节点的部分属性被允许更改,允许更改的字段以蓝色字体标识。在下一阶段导入DataWorks时,工具将获取表格中的属性变更并使其生效。
2、报表允许通过删除工作流子表中的行,使得在导入DataWorks时跳过这些工作流(工作流黑名单)。注意!若工作流存在相互依赖关系,相关联的工作流需要同批次导入,不可通过黑名单进行分割。分割会产生异常!
四、Dataworks任务导入
LHM迁移工具异构转换已将迁移源端的调度元素转换为DataWorks调度格式,工具得以针对不同的迁移场景提供了统一的上传入口,实现任务流导入DataWorks。
导入工具支持多轮刷写,会自动选择创建/更新任务流(OverWrite模式)。
1 前置条件
1.1 转换成功
转换工具运行完成,源端调度信息被成功转换为DataWorks调度信息,ConverterOutput.zip被成功生成。
(可选,推荐)打开转换输出包,查看统计报表,核对待迁移范围是否被转换成功。
1.2 DataWorks侧配置
DataWorks侧需进行以下动作:
1、创建工作空间。
2、创建AK、SK且保证AK、SK对工作空间具有管理员权限。(强烈建议建立与账号有绑定关系的AK、SK,以便在写入遇到问题时进行排查)
3、在工作空间中建立数据源、绑定计算资源、创建资源组。
4、在工作空间中上传文件资源、创建UDF。
1.3 网络连通性检查
验证能否连接DataWorks Endpoint。
服务接入点列表:
ping dataworks.aliyuncs.com2 导入配置项
在工程目录的conf文件夹下创建导出配置文件(JSON格式),如writer.json。
使用前请删除json中的注释。
{
"schedule_datasource": {
"name": "YourDataWorks", //给你的DataWorks数据源起个名字!
"type": "DataWorks",
"properties": {
"endpoint": "dataworks.cn-hangzhou.aliyuncs.com", // 服务接入点
"project_id": "YourProjectId", // 工作空间ID
"project_name": "YourProject", // 工作空间名称
"ak": "************", // AK
"sk": "************", // SK
},
"operaterType": "MANUAL"
},
"conf": {
"di.resource.group.identifier": "Serverless_res_group_***_***", // 调度资源组
"resource.group.identifier": "Serverless_res_group_***_***", // 数据集成资源组
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls", // DataWorks节点类型表的路径
"qps.limit": 5 // 向DataWorks发送API请求的QPS上限
}
}2.1 服务接入点
根据DataWorks所在Region选择服务接入点,参考文档:
2.2 工作空间ID与名称
打开DataWorks控制台,打开工作空间详情页,从右侧基本信息中获取工作空间ID与名称。
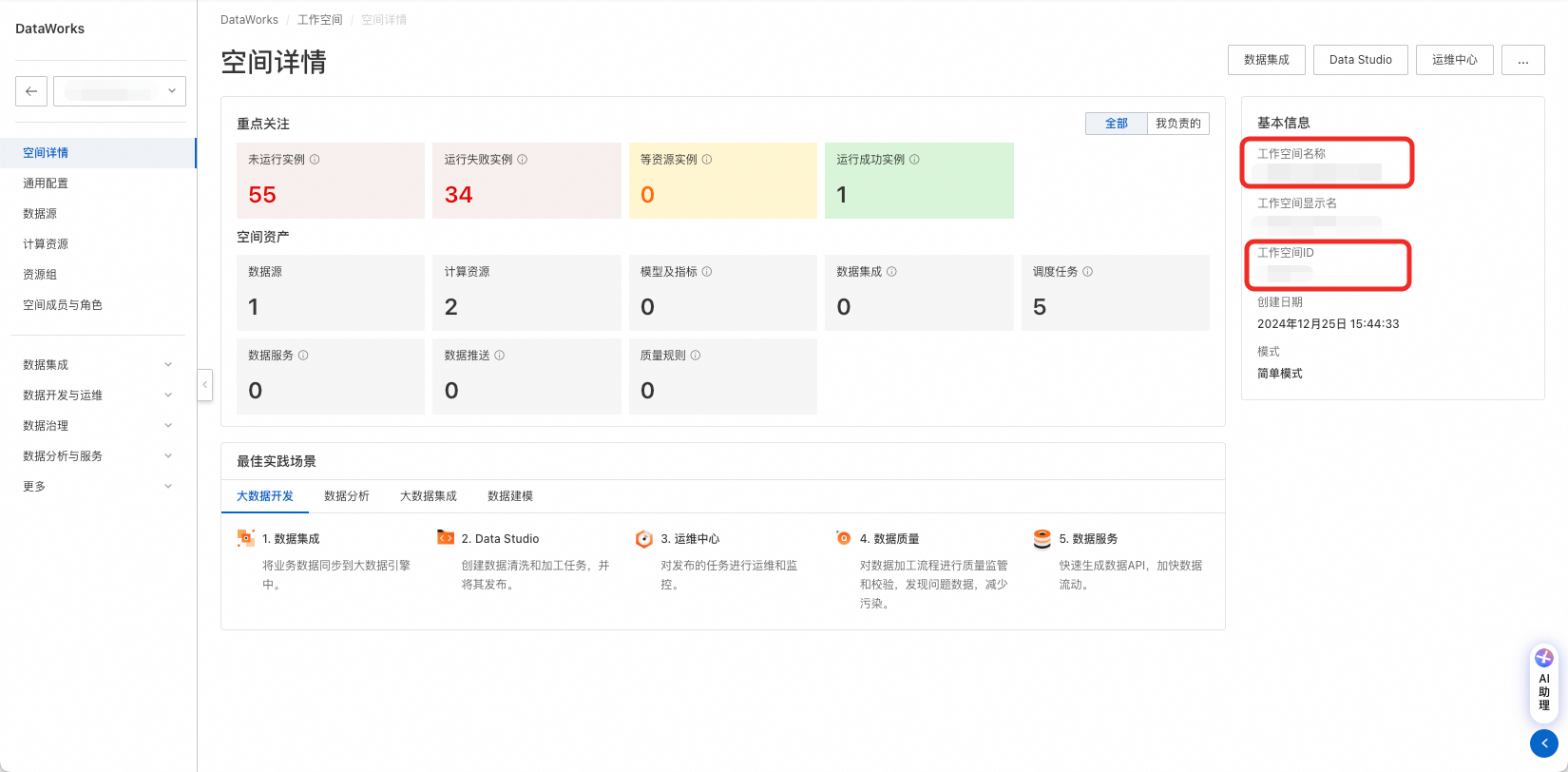
2.3 创建AK、SK并授权
在用户页创建AK、SK,要求对目标DataWorks工作空间拥有管理员读写权限。
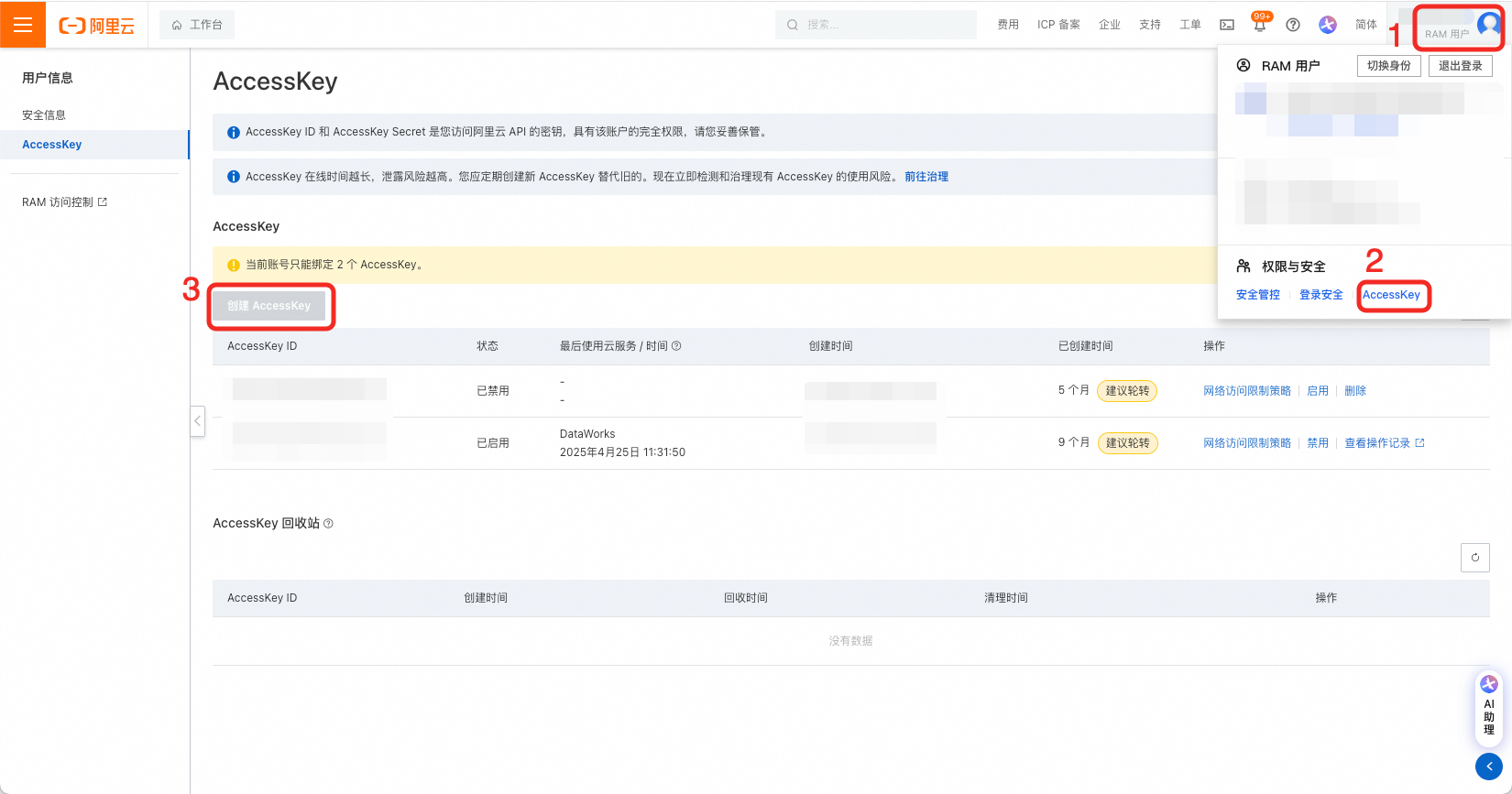
权限管理包括两处,如果账号是RAM账号,则需先对RAM账号进行DataWorks操作授权。
权限策略页面:https://ram.console.aliyun.com/policies
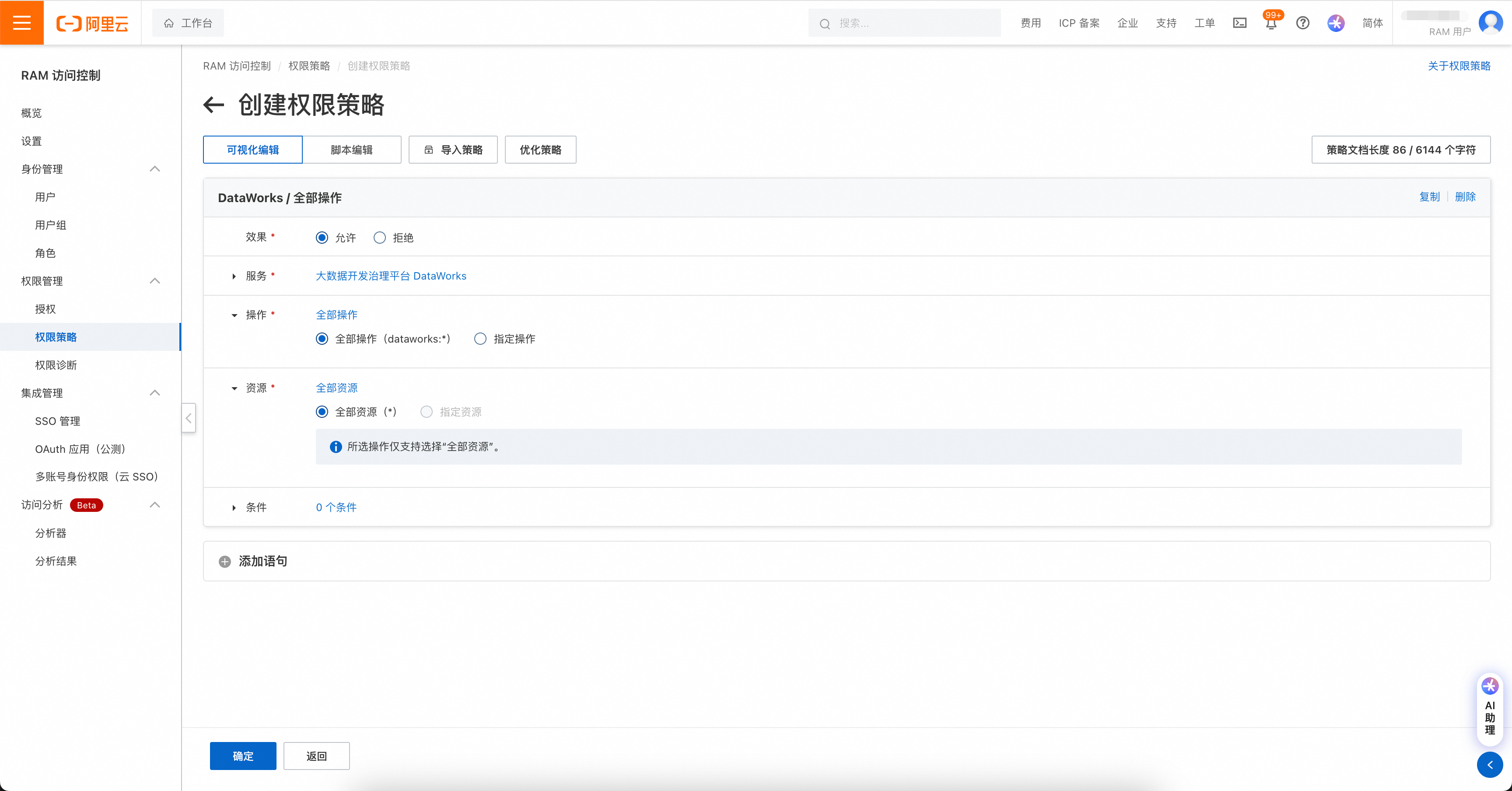
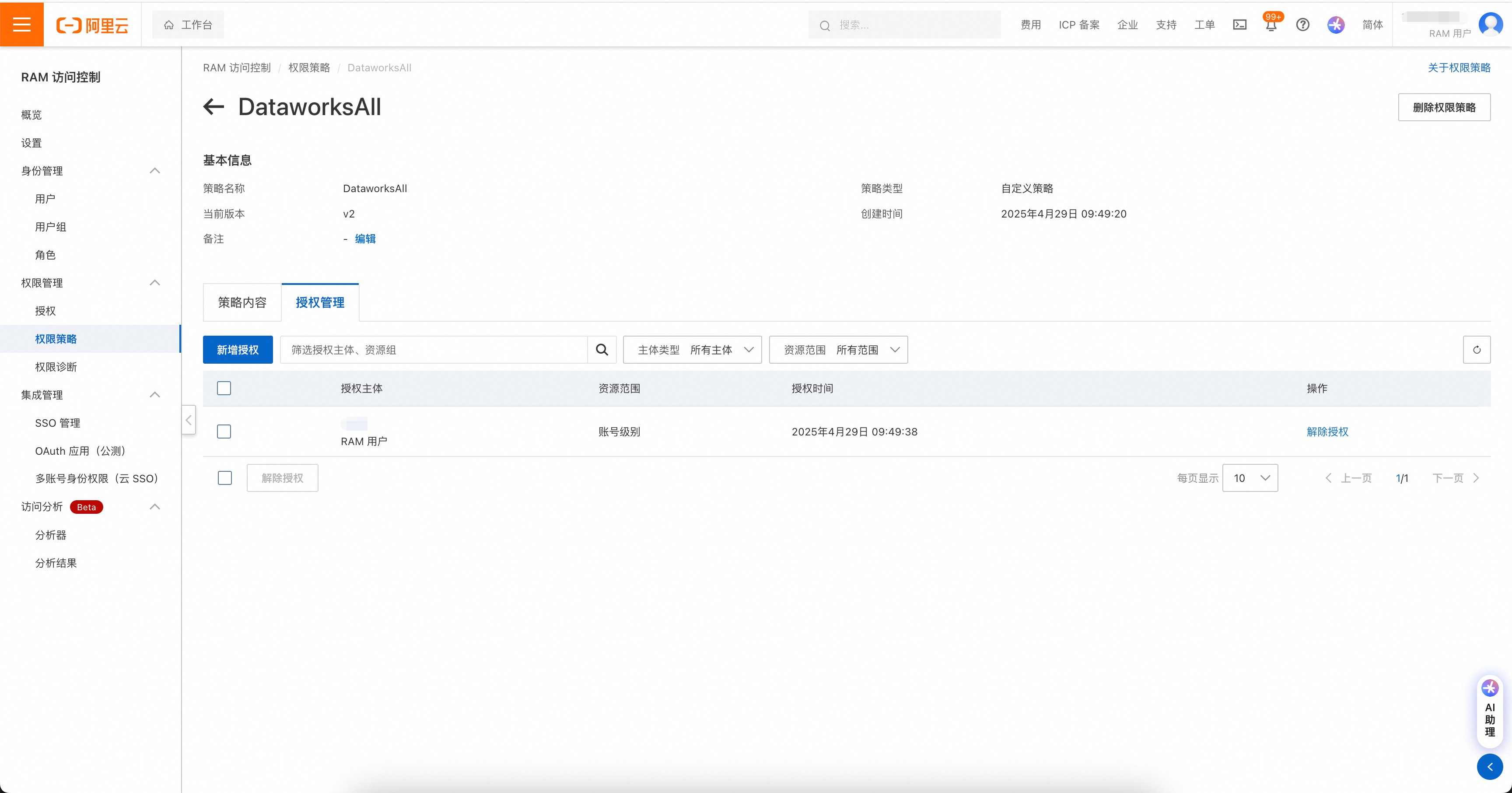
然后在DataWorks工作空间中,将工作空间权限赋给账号。
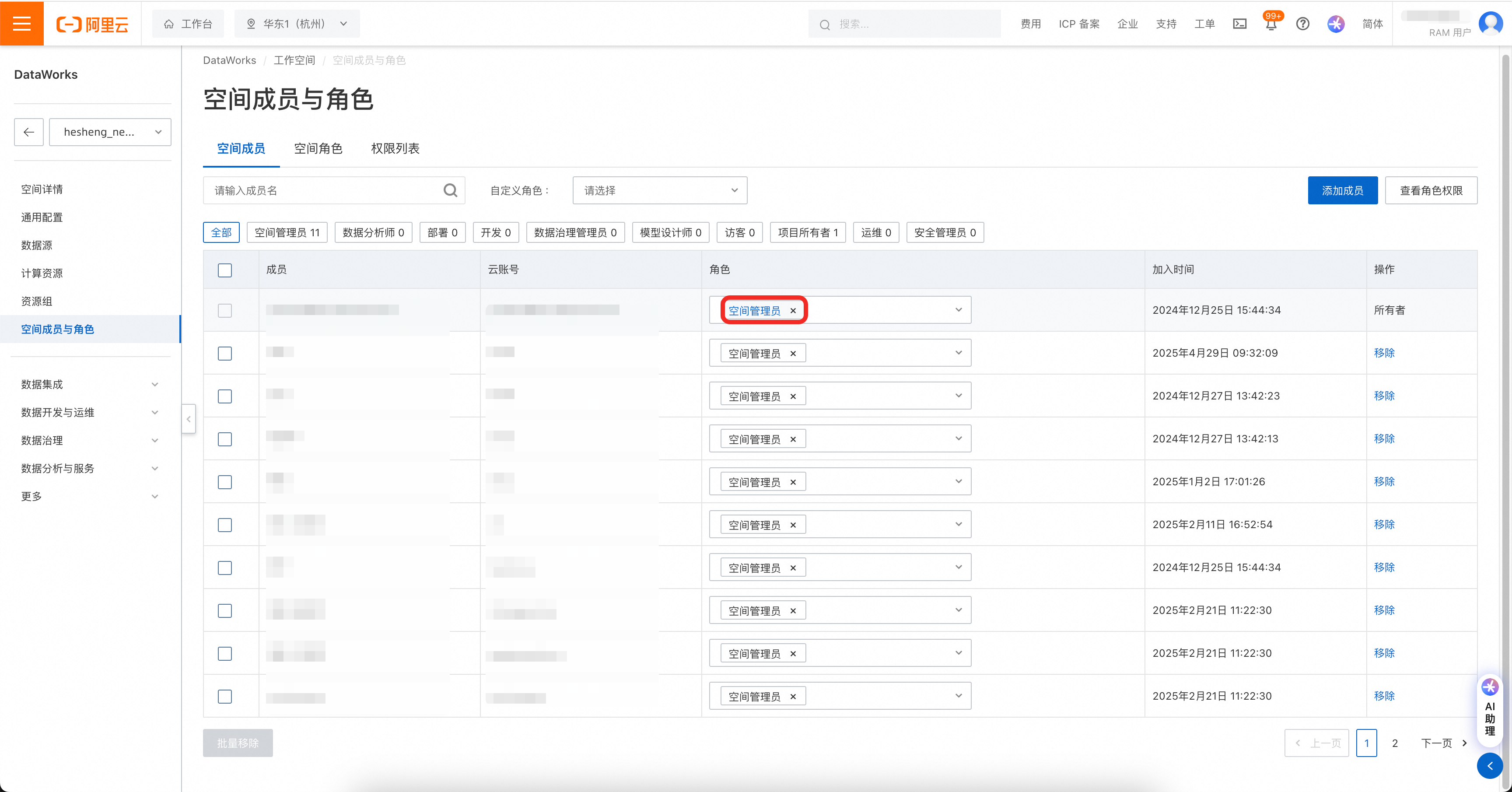
注意!AccessKey可设置网络访问限制策略,请务必保证迁移工具所在机器的IP被允许访问。
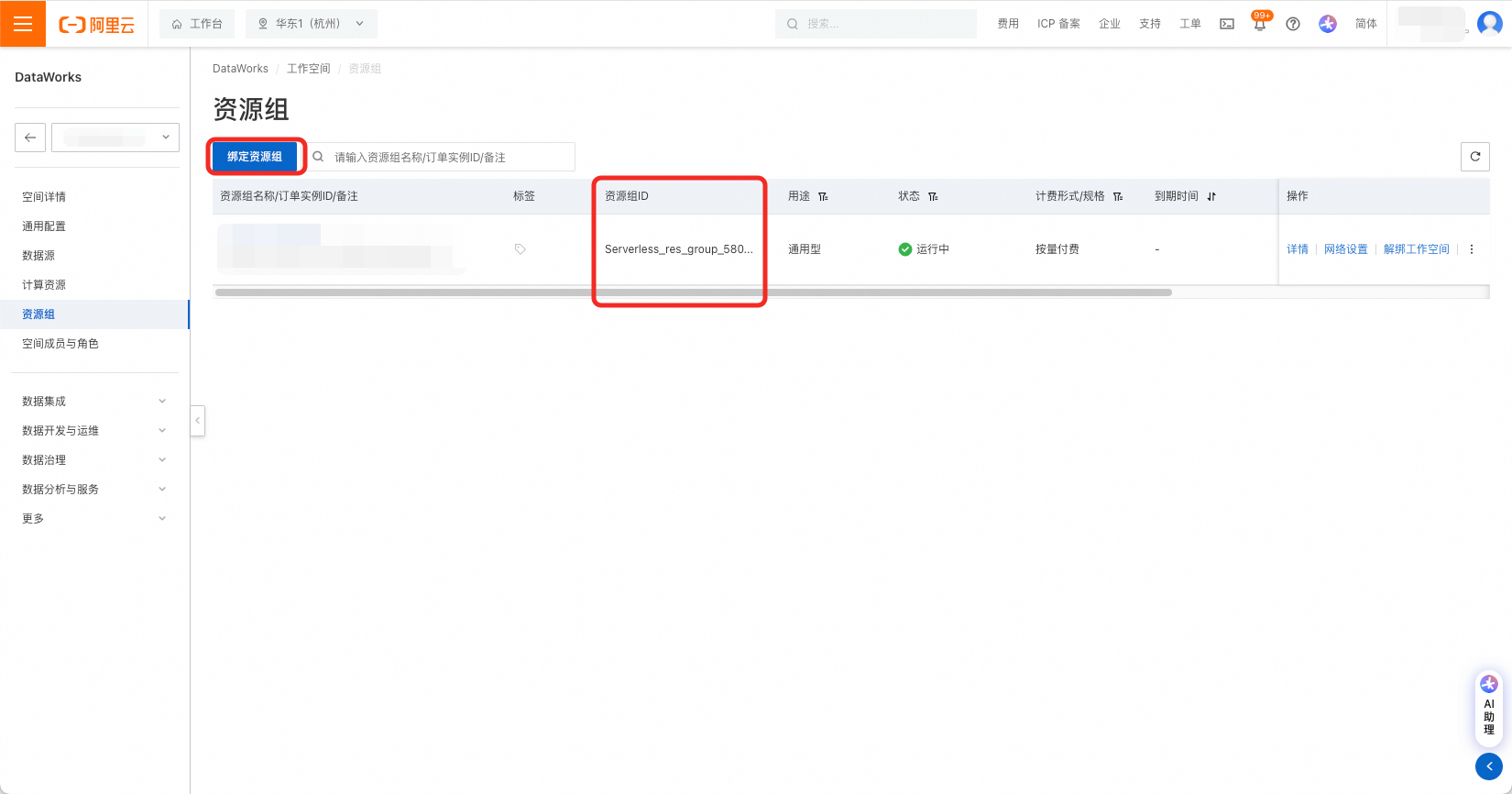
2.4 资源组
由DataWorks工作空间详情页左侧菜单栏进入资源组页面,绑定资源组,并获取资源组ID。
通用资源组可用于节点调度,也可用于数据集成。配置项中调度资源组resource.group.identifier和数据集成资源组di.resource.group.identifier可以配置为同一通用资源组。
2.5 QPS设置
工具通过调用DataWorks的API进行导入操作。不同DataWorks版本中的读、写OpenAPI分别有相应的QPS限制和每日调用次数限制,详见链接:使用限制。
DataWorks基础版、标准版、专业版建议填写"qps.limit": 5,企业版建议填写"qps.limit": 20。
注意,请尽可能避免多个导入工具同时运行。
2.6 DataWorks节点类型ID设置
在DataWorks中,部分节点类型在不同Region中被分配了不同的TypeId。具体TypeID以DataWorks数据开发实际界面为准。存在此特性的节点类型以数据库节点为主:数据库节点。
如:MySQL节点在杭州Region的NodeTypeId为1000039、在深圳Region的NodeTypeId为1000041。
为适应上述DataWorks不同Region的差异特性,工具提供了一种可配置的方式,允许用户配置工具所使用的节点TypeId表。
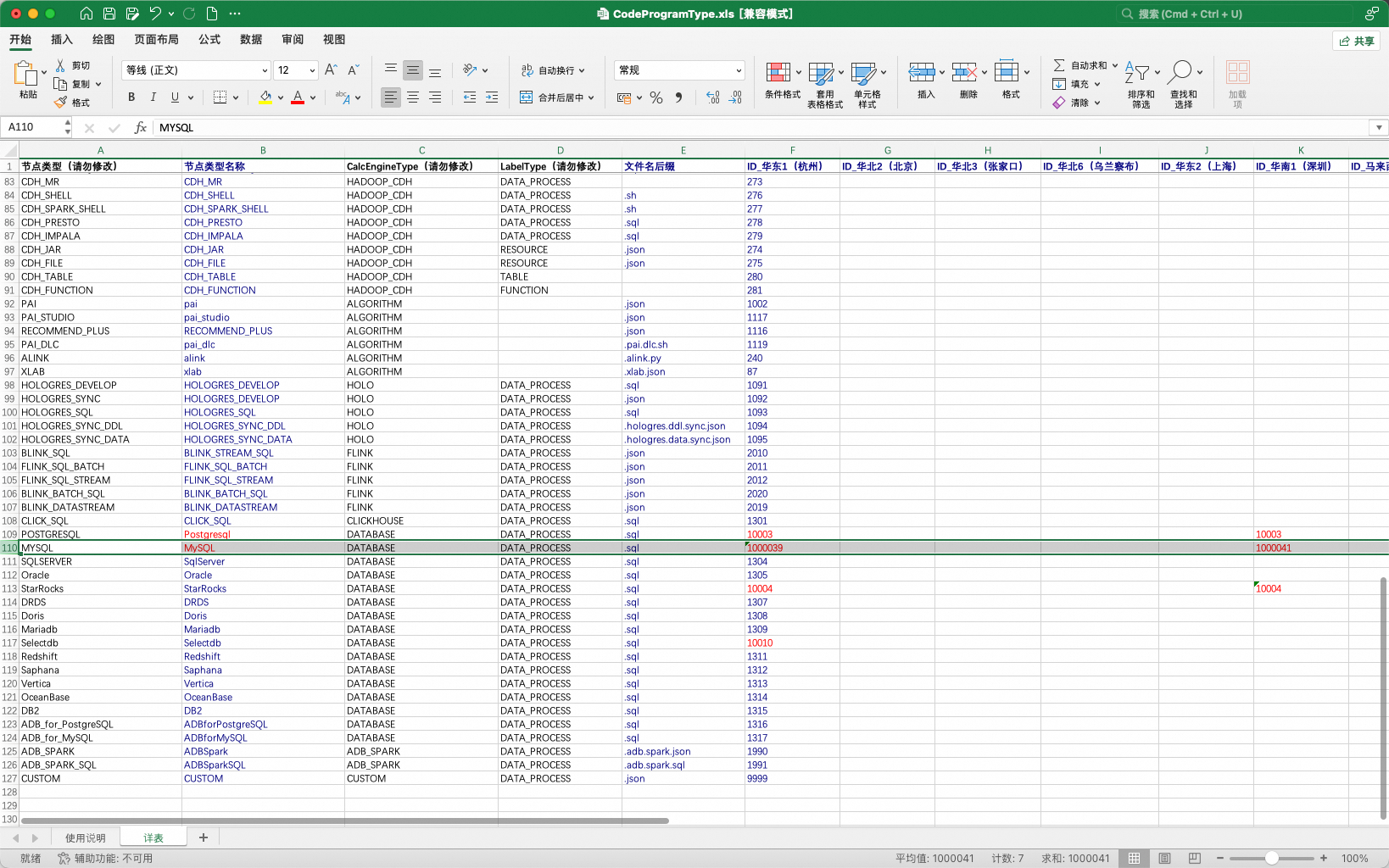
表格通过导入工具的配置项引入:
"conf": {
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls" // DataWorks节点类型表的路径
}从DataWorks数据开发界面上获取节点类型Id的方法:在界面上新建一个工作流,并在工作流中新建一个节点,在点击保存后查看工作流的Spec。
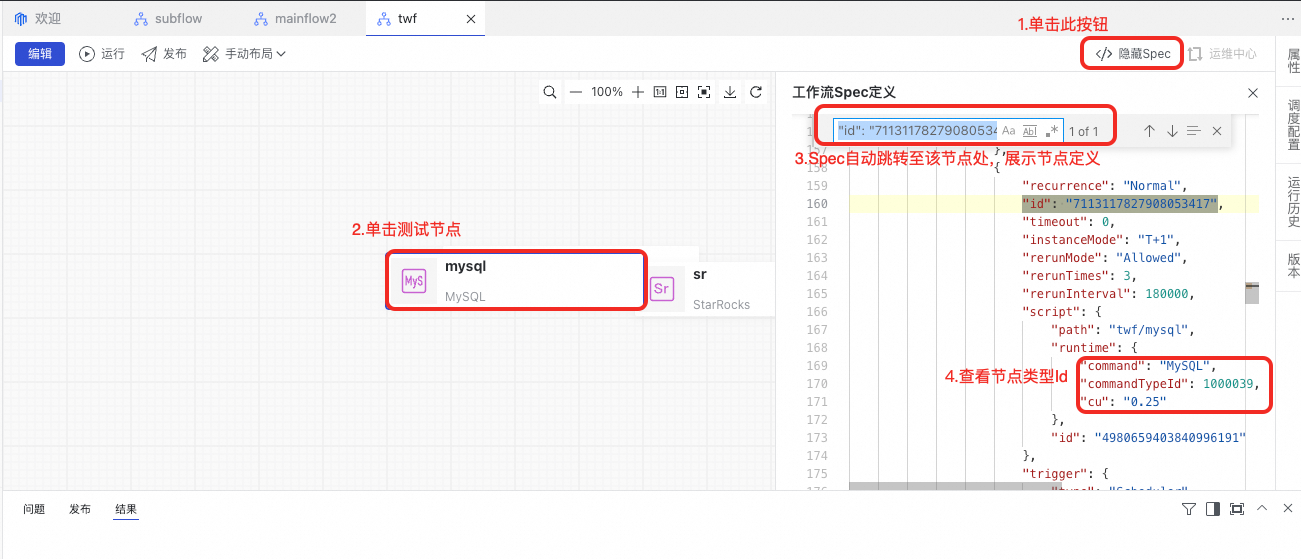
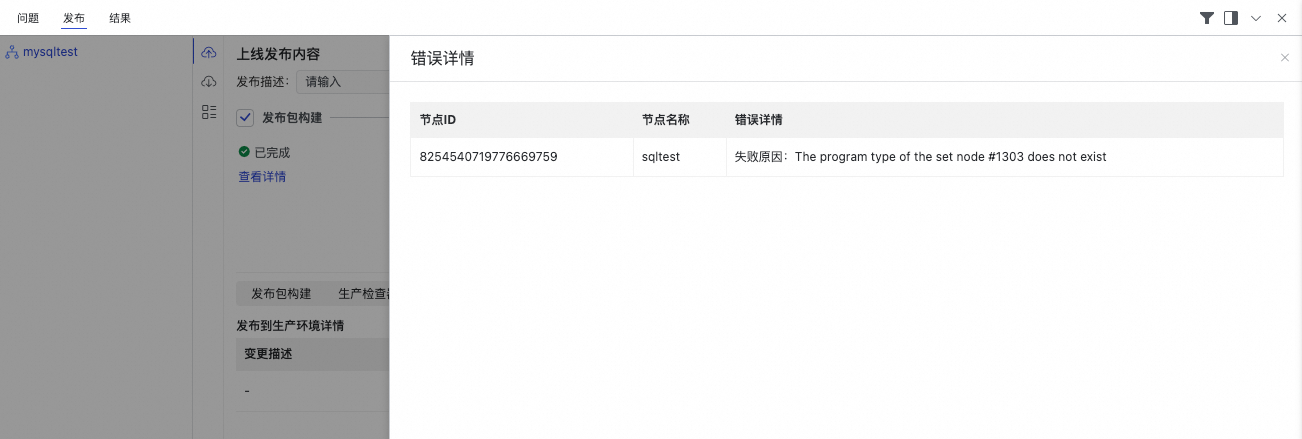
若节点类型配置错误,在任务流发布时将提示以下错误。
3 运行DataWorks导入工具
转换工具通过命令行调用,调用命令如下:
sh ./bin/run.sh write \
-c ./conf/<你的配置文件>.json \
-f ./data/2_ConverterOutput/<转换结果输出包>.zip \
-o ./data/4_WriterOutput/<导入结果存储包>.zip \
-t dw-newide-writer其中-c为配置文件路径,-f为ConverterOutput包存储路径,-o为WriterOutput包存储路径,-t为提交插件名称。
例如,当前需要导入DataWorks的项目A:
sh ./bin/run.sh write \
-c ./conf/projectA_write.json \
-f ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-o ./data/4_WriterOutput/projectA_WriterOutput.zip \
-t dw-newide-writer导入工具运行中将打印过程信息,请关注运行过程中是否有报错。导入完成后将在命令行中打印导入成功与失败的统计信息。注意,部分节点的导入失败不会影响整体导入流程,如遇少量节点导入失败,可在DataWorks中进行手动修改。
4 查看导入结果
导入完成后,可在DataWorks中查看导入结果。导入过程中亦可查看工作流逐个导入的过程,如发现问题需要终止导入,可运行jps命令找到BwmClientApp,并使用kill -9终止导入。
5 Q&A
5.1 源端持续在进行开发,这些增量与变更如何提交到DataWorks?
迁移工具为OverWrite模式,重新运行导出、转换、导入可实现将源端增量提交到DataWorks的能力。请注意,工具将根据全路径匹配任务流以选择创建任务流/更新任务流。如需进行变更迁移,请勿移动任务流。
5.2 源端持续在进行开发,同时进行DataWorks上任务流改造与治理,增量迁移时是否会覆盖DataWorks上的变更?
是的,迁移工具为OverWrite模式,建议您在完成迁移后再在DataWorks上进行后续改造。或者采用分批迁移的方式,已迁移等任务流再确认不再刷写后开始DataWorks改造,不同批次之间互相不会影响。
5.3 整个包导入耗时太长,能否只导入一部分
可以,可手动裁剪待导入包来实现部分导入:将data/project/workflow文件夹下需要导入的任务流保留、其他任务流删除,重新压缩回压缩包,再运行导入工具。注意,存在相互依赖的任务流需要捆绑导入,否则任务流间的节点血缘将会丢失。