
本文介绍了基于LHM调度迁移工具将Wedata调度任务流迁移到DataWorks的方案与操作流程,包括三步,Wedata任务导出、调度任务转换、DataWorks任务导入。
一、导出Wedata调度任务流
导出工具通过调用WeData的SDK获取项目空间信息、工作流定义、数据源定义、资源文件等信息。
<dependencies>
<dependency>
<groupId>com.tencentcloudapi</groupId>
<artifactId>tencentcloud-sdk-java-common</artifactId>
<version>3.1.1241</version>
</dependency>
<dependency>
<groupId>com.tencentcloudapi</groupId>
<artifactId>tencentcloud-sdk-java-wedata</artifactId>
<version>3.1.1241</version>
</dependency>
</dependencies>1 前置条件
准备JDK17运行环境,打通运行环境和WeData的网络连接,下载调度迁移工具到本地并解压缩。
网络连接测试方法:验证能否连接WeData Endpoint。
ping wedata.tencentcloudapi.com2 配置连接信息
在工程目录的conf文件夹下创建导出配置文件(JSON格式),如read.json。
使用前请删除json中的注释。
{
"schedule_datasource": {
"name": "YourWedata", // 给你的Wedata数据源起个名称!
"type": "Wedata", // 数据源类型(Wedata)
"properties": {
"region": "ap-guangzhou", // region
"secretId": "***********************", // secretId
"secretKey": "***********************", // secretKey
"projectId": "2100000000000000000", // 空间Id
"projectName": "MyProject" // 空间名称
},
"operaterType": "AUTO"
},
"conf": {
}
}2.1 Region获取方式
见“文档中心>数据开发治理平台 WeData>API 文档>调用方式>请求结构>服务地址”,如广州ap-guangzhou、北京ap-beijing、上海ap-shanghai、成都ap-chengdu。
https://cloud.tencent.com/document/product/1267/76338
2.2 SecretId、SecretKey获取方式
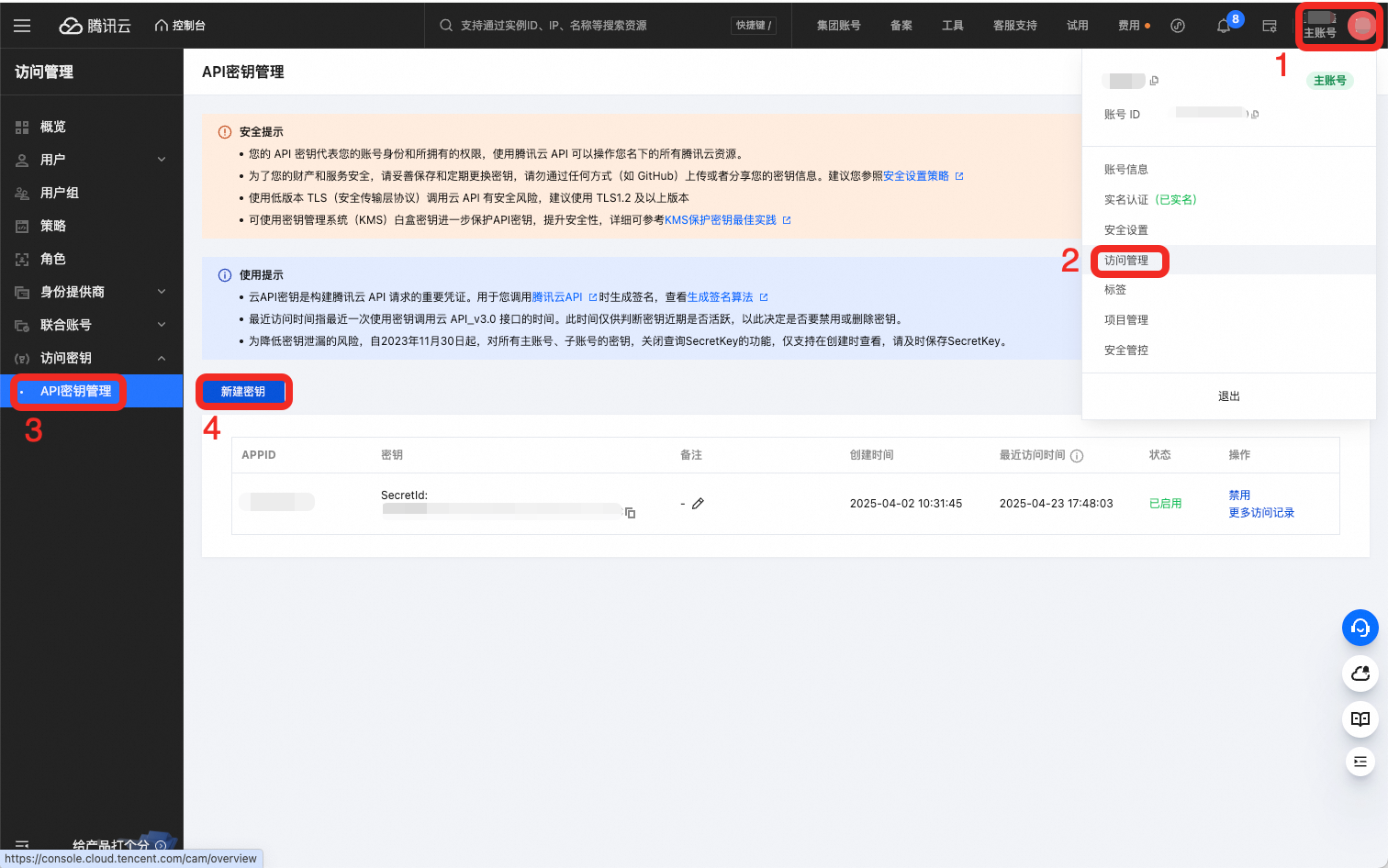
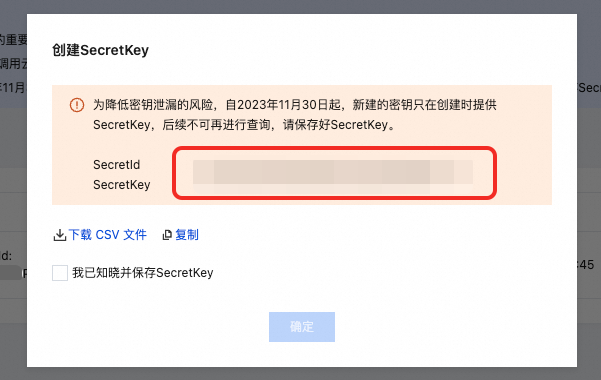
在访问管理-API密钥管理中新建密钥,获取SecretId、SecretKey。注意,账号权限需对。
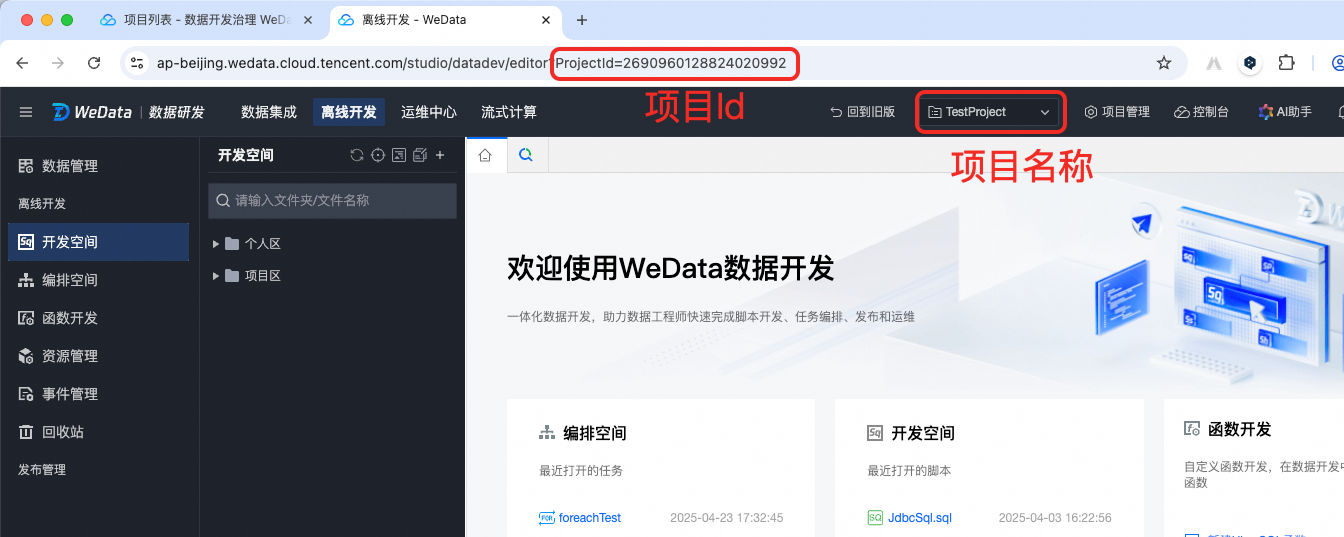
2.3 ProjectId、ProjectName获取方式
项目空间名称可在项目列表页面获取,项目空间ID需在离线开发页面的URL中提取。
3 运行调度探查工具
探查工具通过命令行调用,调用命令如下:
sh ./bin/run.sh read \
-c ./conf/<你的配置文件>.json \
-o ./data/1_ReaderOutput/<源端探查导出包>.zip \
-t wedata-reader其中-c为配置文件路径,-o为ReaderOutput包存储路径,-t为探查插件名称。
例如,当前需要导出WeData的项目A:
sh ./bin/run.sh read \
-c ./conf/projectA_read.json \
-o ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-t wedata-reader探查工具运行中将打印过程信息,请关注运行过程中是否有报错。
4 查看导出结果
打开./data/1_ReaderOutput/下的生成包ReaderOutput.zip,可预览导出结果。
其中,统计报表是对WeData中任务流、节点、资源、函数、数据源基本信息的汇总展示。
而data/project文件夹下是对WeData调度信息数据结构标准化后的结果。
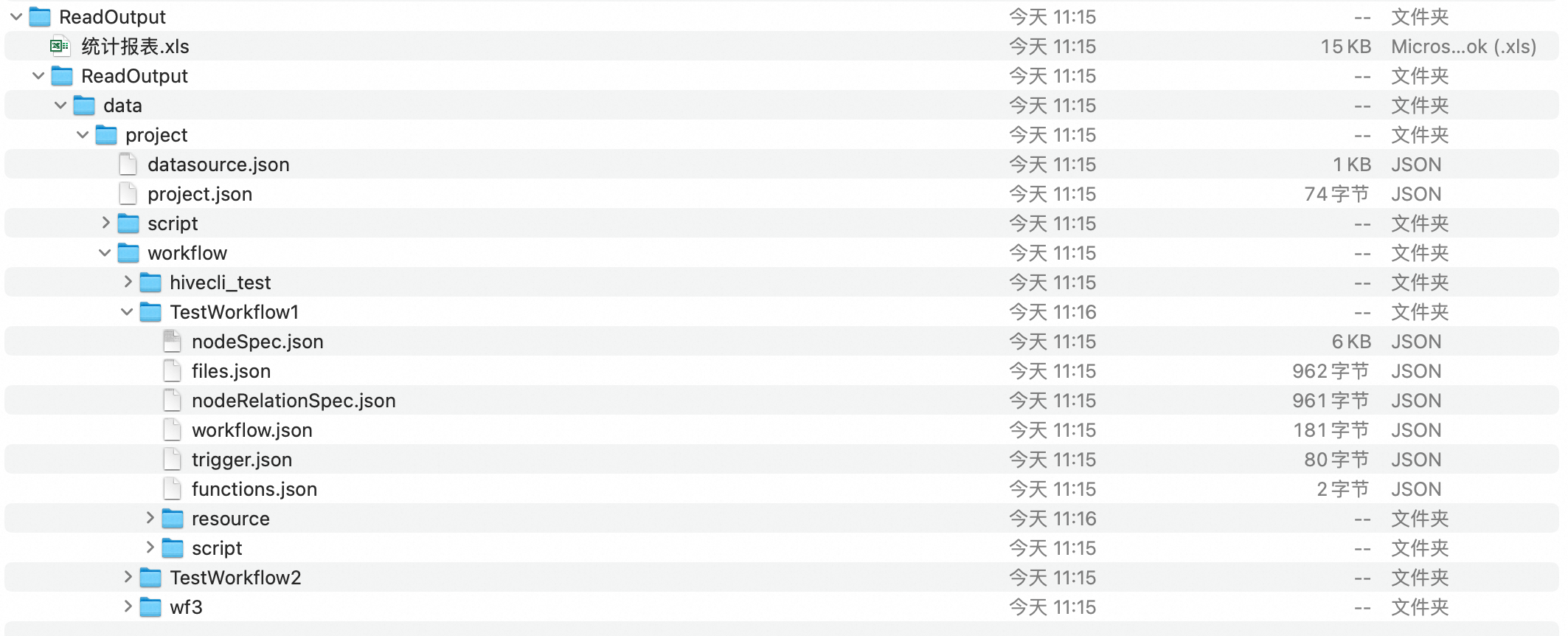
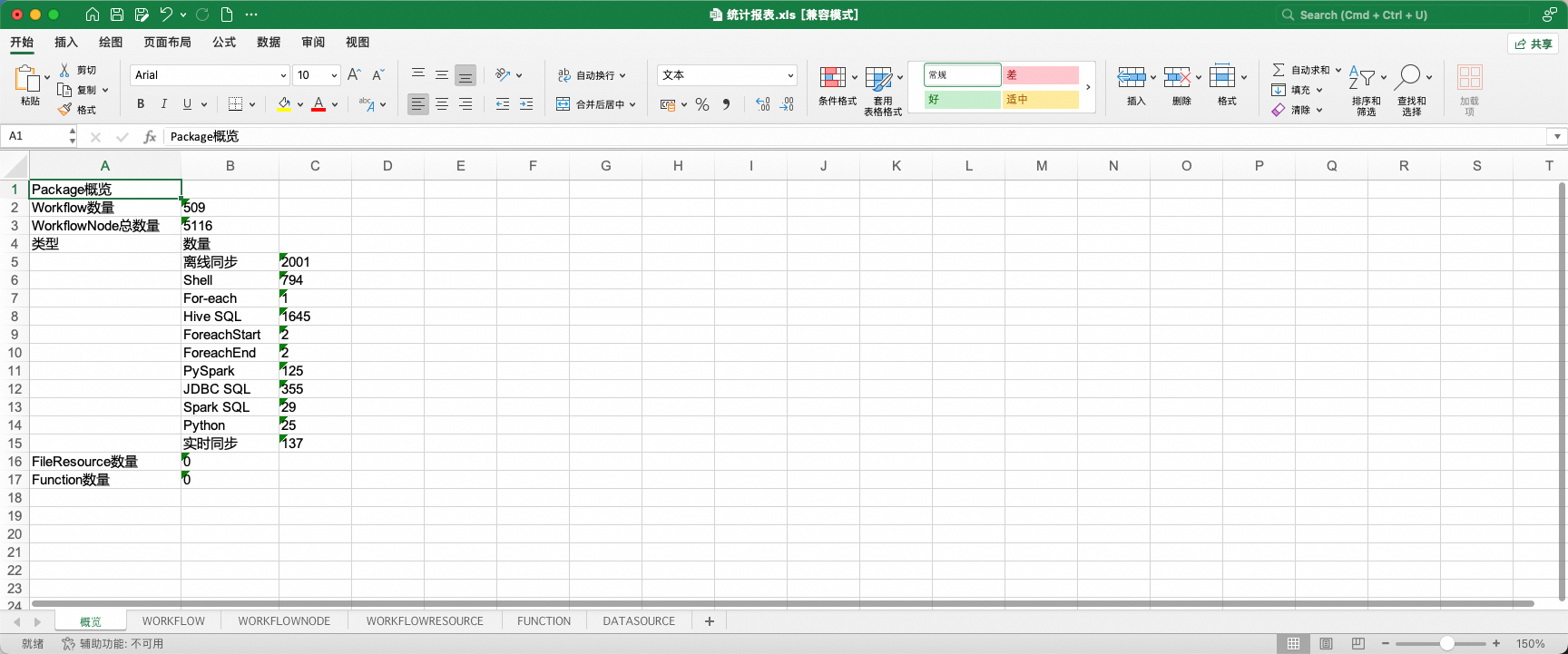
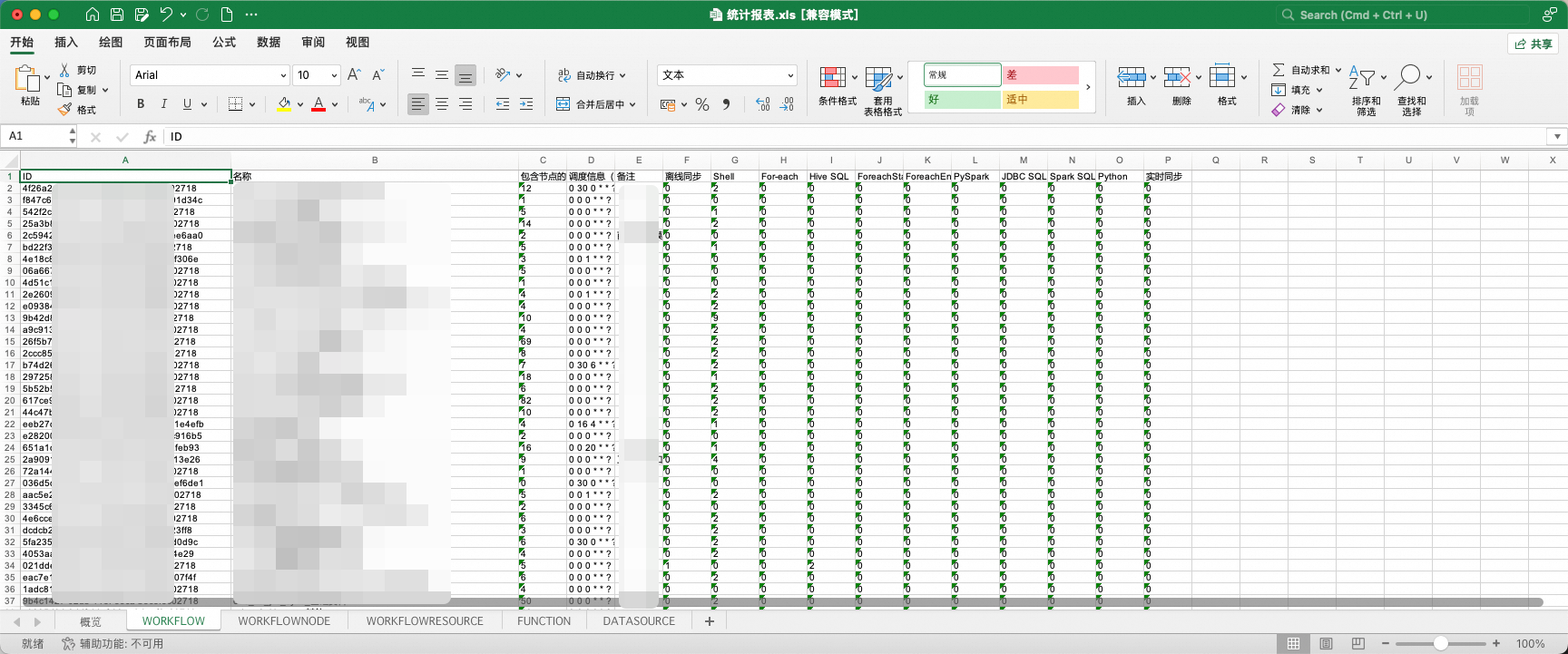
统计报表提供了两项特殊能力:
1、报表中工作流、节点的部分属性被允许更改,允许更改的字段以蓝色字体标识。在下一阶段调度转换中,在初始化阶段,工具将获取表格中的属性变更并使其生效。
2、报表允许通过删除工作流子表中的行,使得在转换时跳过这些工作流(工作流黑名单)。注意!若工作流存在相互依赖关系,相关联的工作流需要同批次转换,不可通过黑名单进行分割。分割会产生异常!
二、Wedata->DataWorks任务流转换
1 前置条件
探查工具运行完成,WeData调度信息被成功导出,ReaderOutput.zip被成功生成。
(可选,推荐)打开探查导出包,查看统计报表,核对待迁移范围是否被导出完全。
2 转换配置项
转换器中提供了丰富的可配置项,以实现对多种目标端计算引擎的适配。
在工程目录的conf文件夹下创建导出配置文件(JSON格式),如tranform.json。
核心配置项包括两项:
1、di.datasource.map用于配置WeData数据源和DataWorks数据源的映射关系(名称、类型)。
2、conf.rule.settings用于配置WeData节点和DataWorks节点的转换规则(节点类型等)。
2.1 转换配置项模板
使用前请删除json中的注释。
{
"name": "wedata-dw-converter",
"self": {
"di.datasource.map": [ // WeData数据源与DataWorks数据源映射规则
{
"srcName": "MyHiveDatasource", // WeData Hive数据源
"srcType": "hive",
"tgtName": "MyMaxComputeDatasource", // DataWorks Maxcompute数据源
"tgtType": "odps"
},
{
"srcName": "MyMysqlDatasource", // WeData Mysql数据源
"srcType": "mysql",
"tgtName": "MyMysqlDatasource", // DataWorks Mysql数据源
"tgtType": "mysql"
}
],
"conf": [
{
"rule": { // 节点转换规则配置(需根据调度转换方案进行配置)
"settings": {
// WeData Shell节点 转换至 DataWorks Shell节点
"workflow.converter.shellNodeType": "DIDE_SHELL",
// WeData Python节点 转换至 DataWorks Python节点
"workflow.converter.pythonNodeType": "PYTHON",
// 如Python节点使用了自定义二方包、或dataworks python版本与所需版本不符,可创建自定义镜像,并配置于此
// DataWorks python节点镜像(可选)
"workflow.converter.pythonImageId": "python_image_0000",
// DataWorks pyodps节点镜像(可选)
"workflow.converter.pyodps2ImageId": "odps_python2_image_0000",
// DataWorks pyodps3节点镜像(可选)
"workflow.converter.pyodps3ImageId": "odps_python3_image_0000",
// WeData HiveSql节点 转换至 DataWorks MaxComputeSql节点
"workflow.converter.hiveSqlNodeType": "ODPS_SQL",
// WeData JDBCSql节点 根据所连接数据源的种类转换至 DataWorks各类数据库的节点
"workflow.converter.jdbcSqlNodeType": {
"doris": "HOLOGRES_SQL",
"oracle": "Oracle",
"mysql": "MYSQL",
"tencent_mysql": "MYSQL"
},
// WeData SparkSql节点 转换至 DataWorks MaxComputeSql节点
"workflow.converter.sparkSqlNodeType": "ODPS_SQL",
// WeData SparkPy节点 转换至 DataWorks MaxComputeSpark节点
"workflow.converter.sparkPyNodeType": "ODPS_SPARK",
// Spark版本号
"workflow.converter.sparkVersion": "3.x"
}
},
"nodes": "all"
}
],
"if.use.migrationx.before": false,
"if.use.default.convert": false,
"if.use.dataworks.newidea": true,
},
"schedule_datasource": {},
"target_schedule_datasource": {}
}2.2 数据源映射表di.datasource.map
数据源映射表di.datasource.map用于配置WeData数据源和DataWorks数据源的映射关系(名称、类型),如源端存在名为MyHiveDatasource的Hive数据源,其数据迁移至名为MyMaxComputeDatasource的MaxCompute数据源,则需进行如下配置。
{
"srcName": "MyHiveDatasource"
"srcType": "hive",
"tgtName": "MyMaxComputeDatasource"
"tgtType": "odps"
}此处,工具当前支持配置的WeData数据源包括:
tencent_mysql, mysql, oracle, doris, hive, dlc, ckafka, kafka, oceanbase, starrocks, postgre, sqlserver
当前支持配置的DataWorks数据源包括:
mysql, oracle, holo(Hologres), odps(MaxCompute), kafka, oceanbase, starrocks, postgre, sqlserver
转换工具将会根据数据源映射规则修改SQL、数据集成等节点与数据源的绑定关系,并完成数据集成配置的映射。
WeData数据集成配置参考:https://cloud.tencent.com.cn/document/product/1267/110747
工具当前数据集成任务配置项映射能力覆盖以下场景:
WeData数据集成读插件 -> DataWorks数据集成读插件:
tencent_mysql -> mysql, mysql -> mysql, oracle-> oracle, doris -> holo, hive -> odps, dlc -> odps, ckafka -> kafka, kafka -> kafka, oceanbase -> oceanbase, starrocks -> starrocks, postgre -> postgre, sqlserver -> sqlserver, ... (More in coming...)
WeData数据集成写插件 -> DataWorks数据集成写插件:
tencent_mysql -> mysql, mysql -> mysql, oracle-> oracle, doris -> holo, hive -> odps, dlc -> odps, ckafka -> kafka, kafka -> kafka, ... (More in coming...)
2.3 节点转换规则conf.rule.settings
工具当前支持转换的WeData节点包括以下类型:
· Shell, HiveSql, JDBCSql, Python, SparkPy, SparkSql
· Foreach, ForeachStart, ForeachEnd, 离线同步
其中可配置DataWorks映射规则的包括以下类型:
· Shell(workflow.converter.shellNodeType):
推荐转换为DIDE_SHELL, EMR_SHELL, VIRTUAL节点等。
· HiveSql(workflow.converter.hiveSqlNodeType):
推荐转换为ODPS_SQL, EMR_HIVE等。
· JDBCSql(workflow.converter.jdbcSqlNodeType):
推荐转换为各类SQL节点、数据库节点等。
· Python(workflow.converter.pythonNodeType):
推荐转换为PYTHON, PYODPS, PYODPS3, EMR_SHELL等。
· SparkPy(workflow.converter.sparkPyNodeType):
推荐转换为ODPS_SPARK, EMR_SPARK等。
· SparkSql(workflow.converter.sparkSqlNodeType):
推荐转换为ODPS_SQL, EMR_SPARK_SQL等。
固定转换规则的节点类型:
· Foreach, ForeachStart, ForeachEnd:
默认转换为DataWorks Foreach节点及其开始结束节点。
· 离线同步: 默认转换为DataWorks数据集成节点
需补充的转换信息:
· Python、PYODPS、PYODPS3节点如需加载自定义镜像,可配置转换规则workflow.converter.pythonImageId、workflow.converter.pyodps2ImageId、workflow.converter.pyodps3ImageId。
· Spark节点需补充Spark版本号,配置workflow.converter.sparkVersion。
DataWorks节点类型可参考此枚举类:
3 运行调度转换工具
转换工具通过命令行调用,调用命令如下:
sh ./bin/run.sh convert \
-c ./conf/<你的配置文件>.json \
-f ./data/1_ReaderOutput/<源端探查导出包>.zip \
-o ./data/2_ConverterOutput/<转换结果输出包>.zip \
-t wedata-dw-converter其中-c为配置文件路径,-f为ReaderOutput包存储路径,-o为ConverterOutput包存储路径,-t为转换插件名称。
例如,当前需要转换的WeData项目A:
sh ./bin/run.sh convert \
-c ./conf/projectA_convert.json \
-f ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-o ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-t wedata-dw-converter转换工具运行中将打印过程信息,请关注运行过程中是否有报错。转换完成后将在命令行中打印转换成功与失败的统计信息。注意,部分节点的转换失败不会影响整体转换流程,如遇少量节点转换失败,可在迁移至DataWorks后进行手动修改。
4 查看转换结果
打开./data/2_ConverterOutput/下的生成包ConverterOutput.zip,可预览导出结果。
其中,统计报表是对转换结果任务流、节点、资源、函数、数据源基本信息的汇总展示。
而data/project文件夹是转换完成的调度迁移包本体。
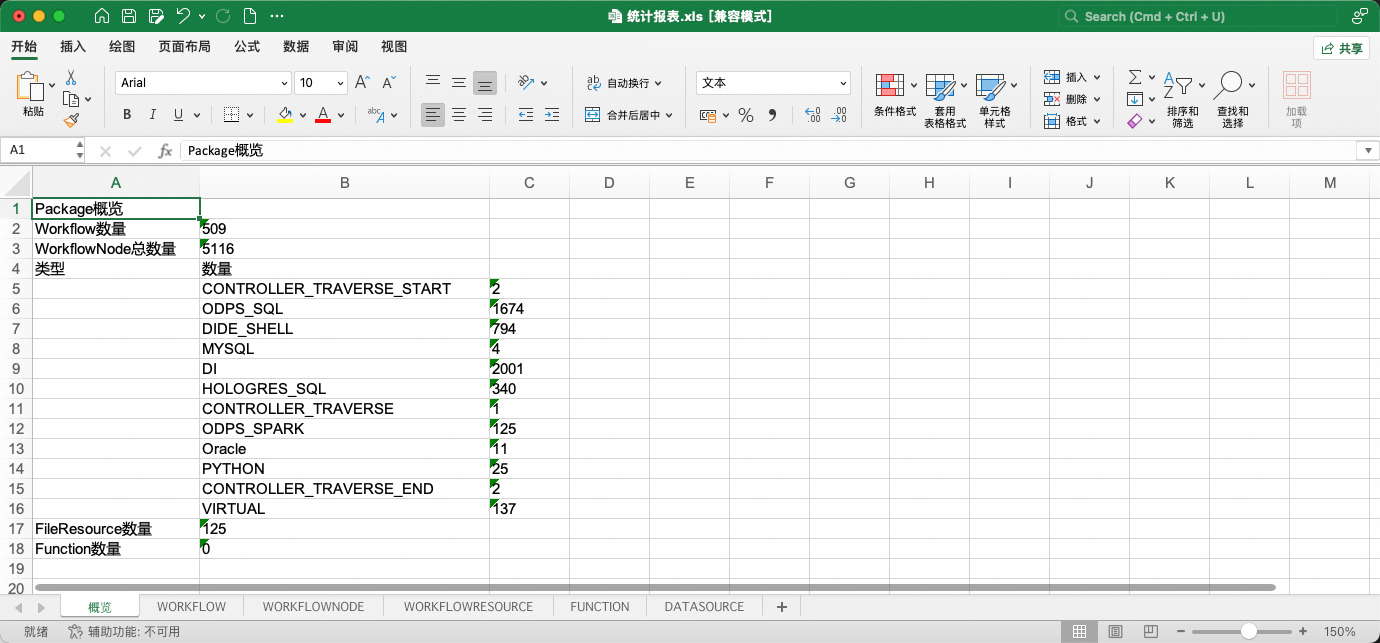
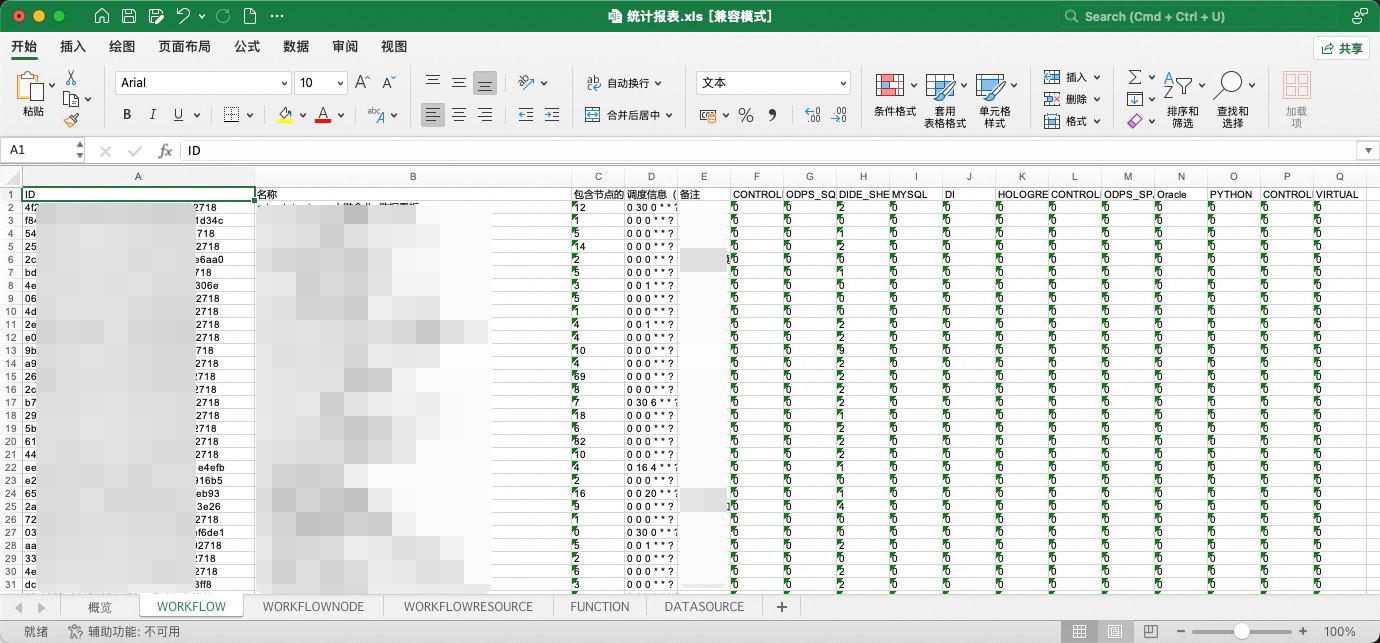
统计报表提供了两项特殊能力:
1、报表中工作流、节点的部分属性被允许更改,允许更改的字段以蓝色字体标识。在下一阶段导入DataWorks时,工具将获取表格中的属性变更并使其生效。
2、报表允许通过删除工作流子表中的行,使得在导入DataWorks时跳过这些工作流(工作流黑名单)。注意!若工作流存在相互依赖关系,相关联的工作流需要同批次导入,不可通过黑名单进行分割。分割会产生异常!
三、导入DataWorks
LHM迁移工具异构转换已将迁移源端的调度元素转换为DataWorks调度格式,工具得以针对不同的迁移场景提供了统一的上传入口,实现任务流导入DataWorks。
导入工具支持多轮刷写,会自动选择创建/更新任务流(OverWrite模式)。
1 前置条件
1.1 转换成功
转换工具运行完成,源端调度信息被成功转换为DataWorks调度信息,ConverterOutput.zip被成功生成。
(可选,推荐)打开转换输出包,查看统计报表,核对待迁移范围是否被转换成功。
1.2 DataWorks侧配置
DataWorks侧需进行以下动作:
1、创建工作空间。
2、创建AK、SK且保证AK、SK对工作空间具有管理员权限。(强烈建议建立与账号有绑定关系的AK、SK,以便在写入遇到问题时进行排查)
3、在工作空间中建立数据源、绑定计算资源、创建资源组。
4、在工作空间中上传文件资源、创建UDF。
1.3 网络连通性检查
验证能否连接DataWorks Endpoint。
服务接入点列表:
ping dataworks.aliyuncs.com2 导入配置项
在工程目录的conf文件夹下创建导出配置文件(JSON格式),如writer.json。
使用前请删除json中的注释。
{
"schedule_datasource": {
"name": "YourDataWorks", //给你的DataWorks数据源起个名字!
"type": "DataWorks",
"properties": {
"endpoint": "dataworks.cn-hangzhou.aliyuncs.com", // 服务接入点
"project_id": "YourProjectId", // 工作空间ID
"project_name": "YourProject", // 工作空间名称
"ak": "************", // AK
"sk": "************", // SK
},
"operaterType": "MANUAL"
},
"conf": {
"di.resource.group.identifier": "Serverless_res_group_***_***", // 调度资源组
"resource.group.identifier": "Serverless_res_group_***_***", // 数据集成资源组
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls", // DataWorks节点类型表的路径
"qps.limit": 5 // 向DataWorks发送API请求的QPS上限
}
}2.1 服务接入点
根据DataWorks所在Region选择服务接入点,参考文档:
2.2 工作空间ID与名称
打开DataWorks控制台,打开工作空间详情页,从右侧基本信息中获取工作空间ID与名称。
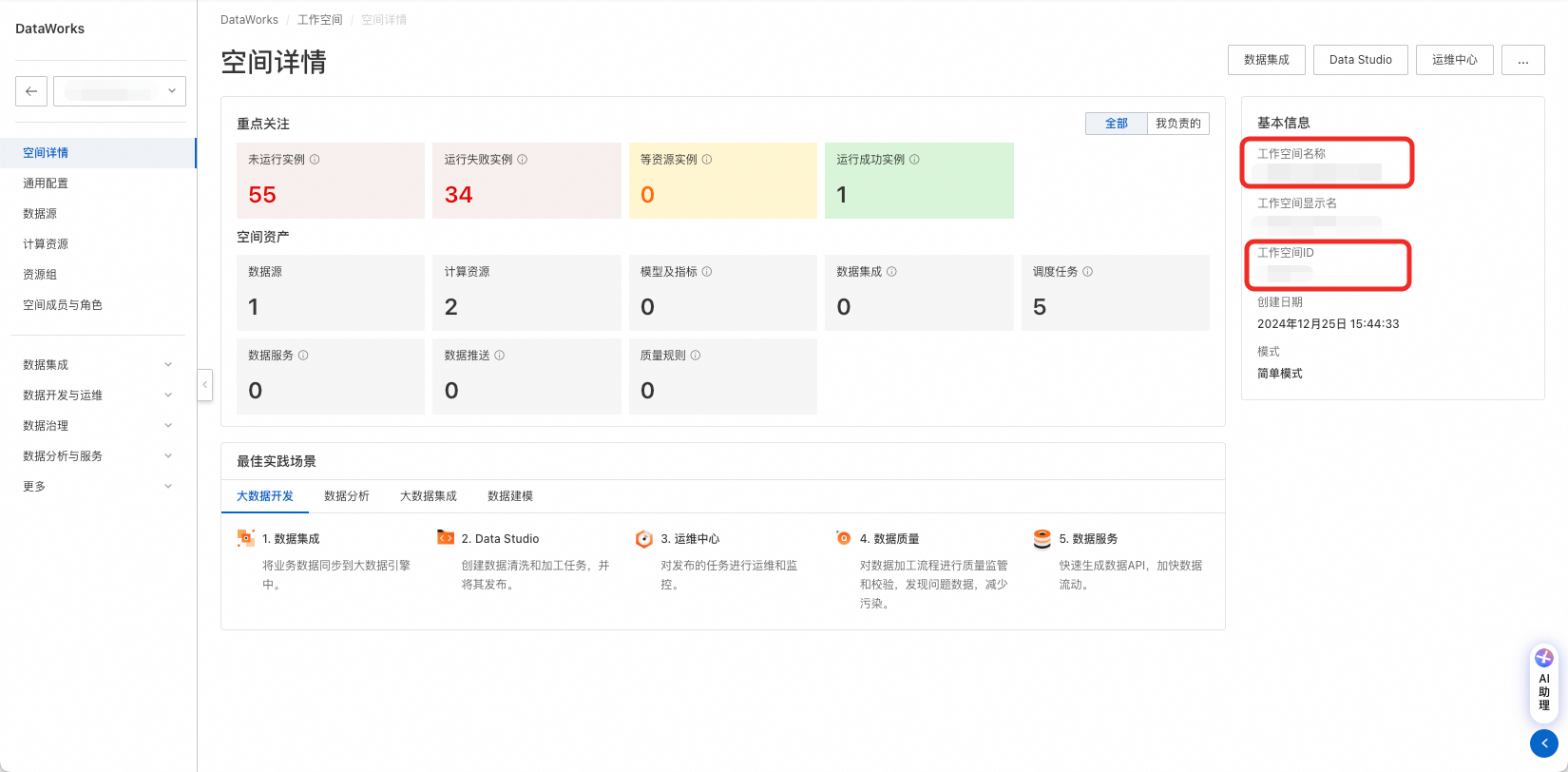
2.3 创建AK、SK并授权
在用户页创建AK、SK,要求对目标DataWorks工作空间拥有管理员读写权限。
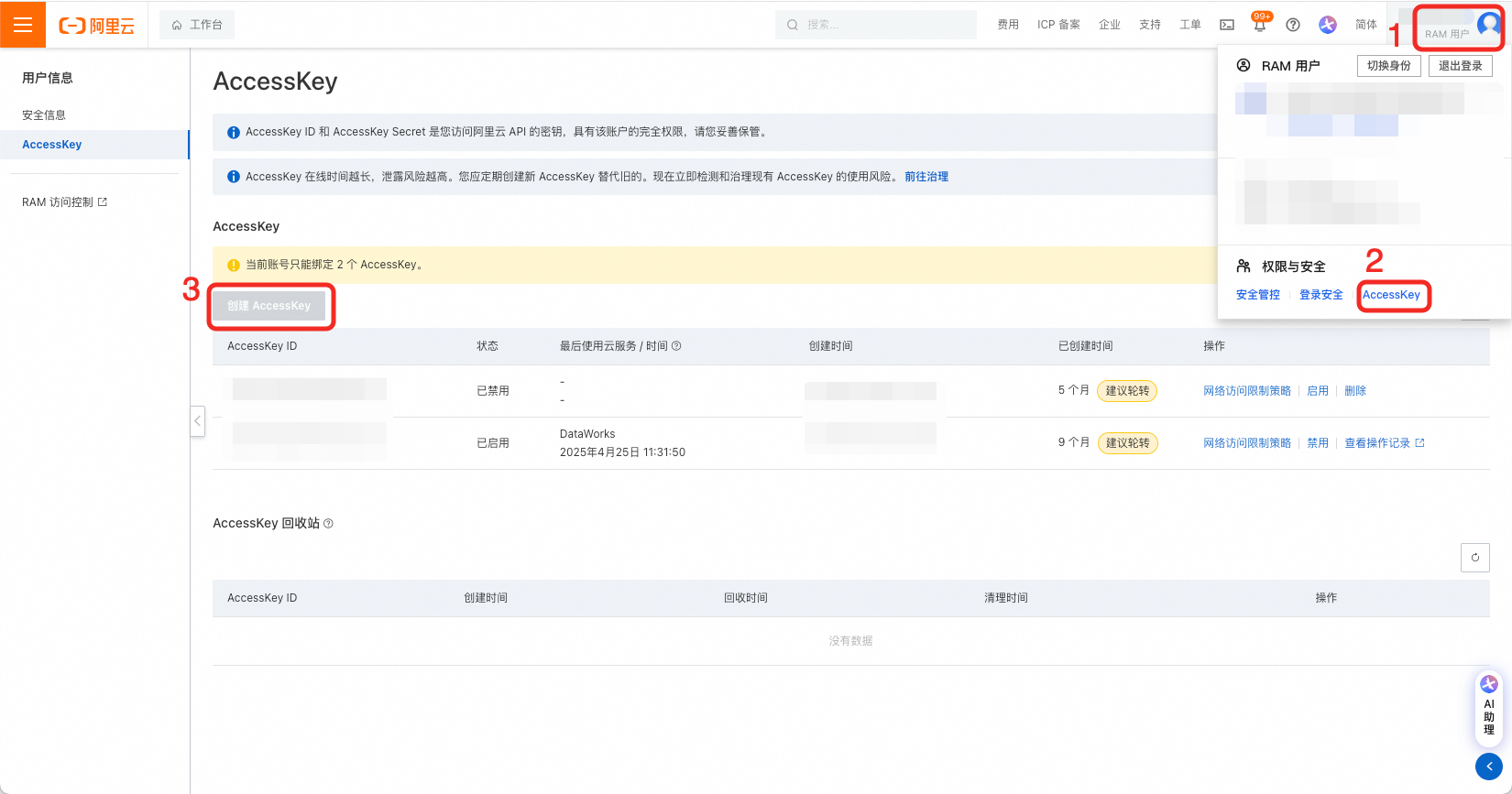
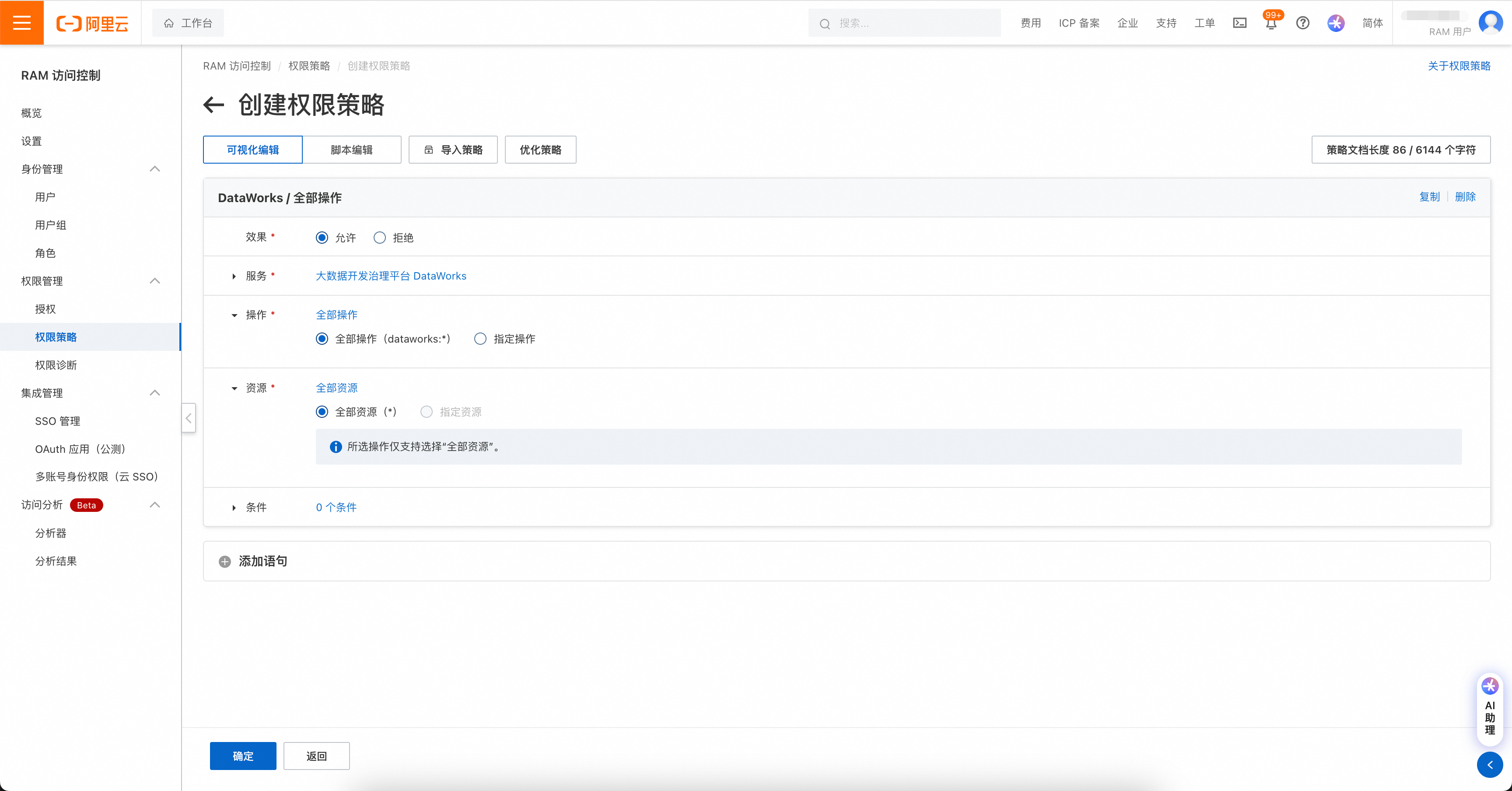
权限管理包括两处,如果账号是RAM账号,则需先对RAM账号进行DataWorks操作授权。
权限策略页面:https://ram.console.aliyun.com/policies
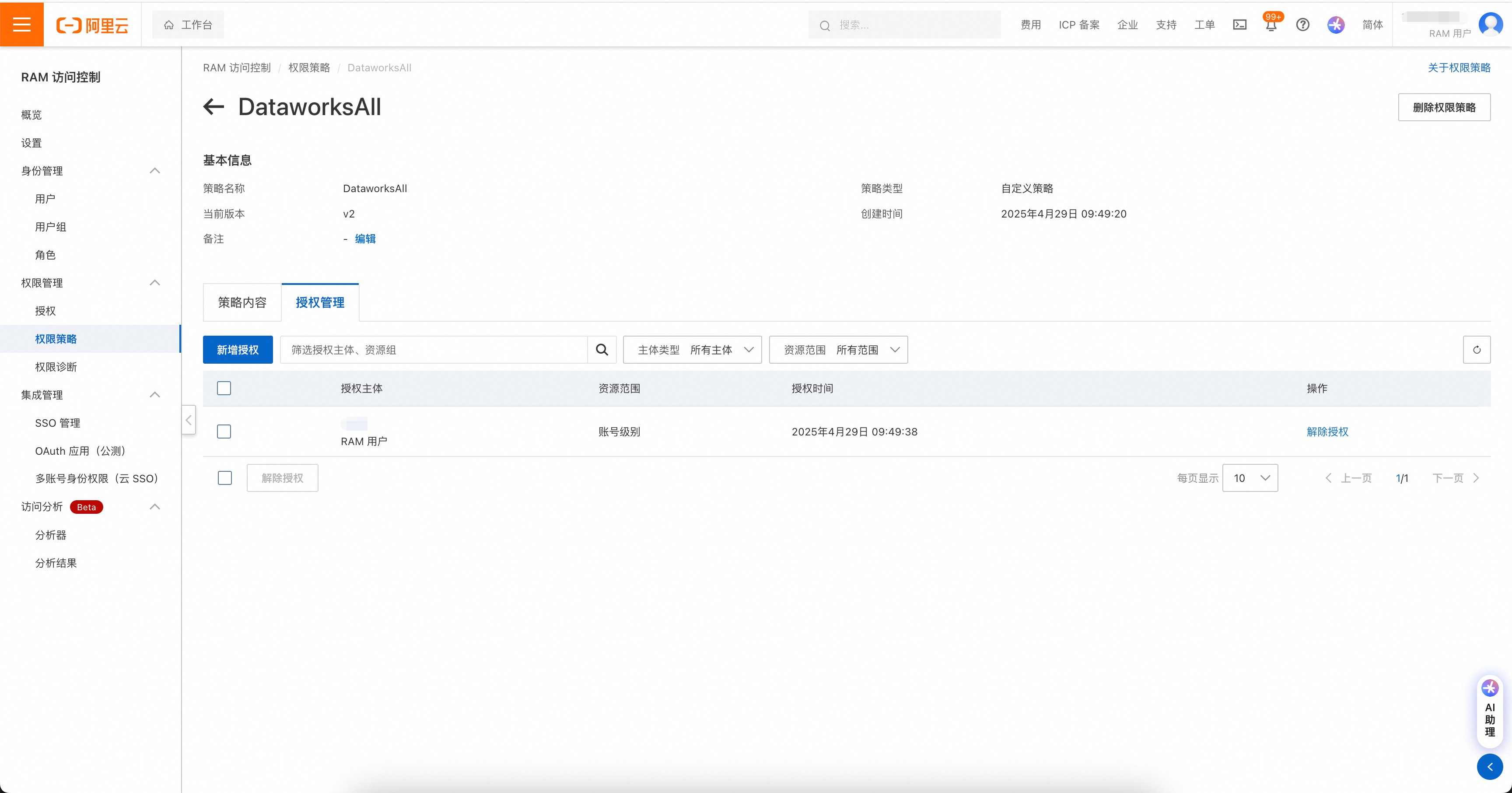
然后在DataWorks工作空间中,将工作空间权限赋给账号。
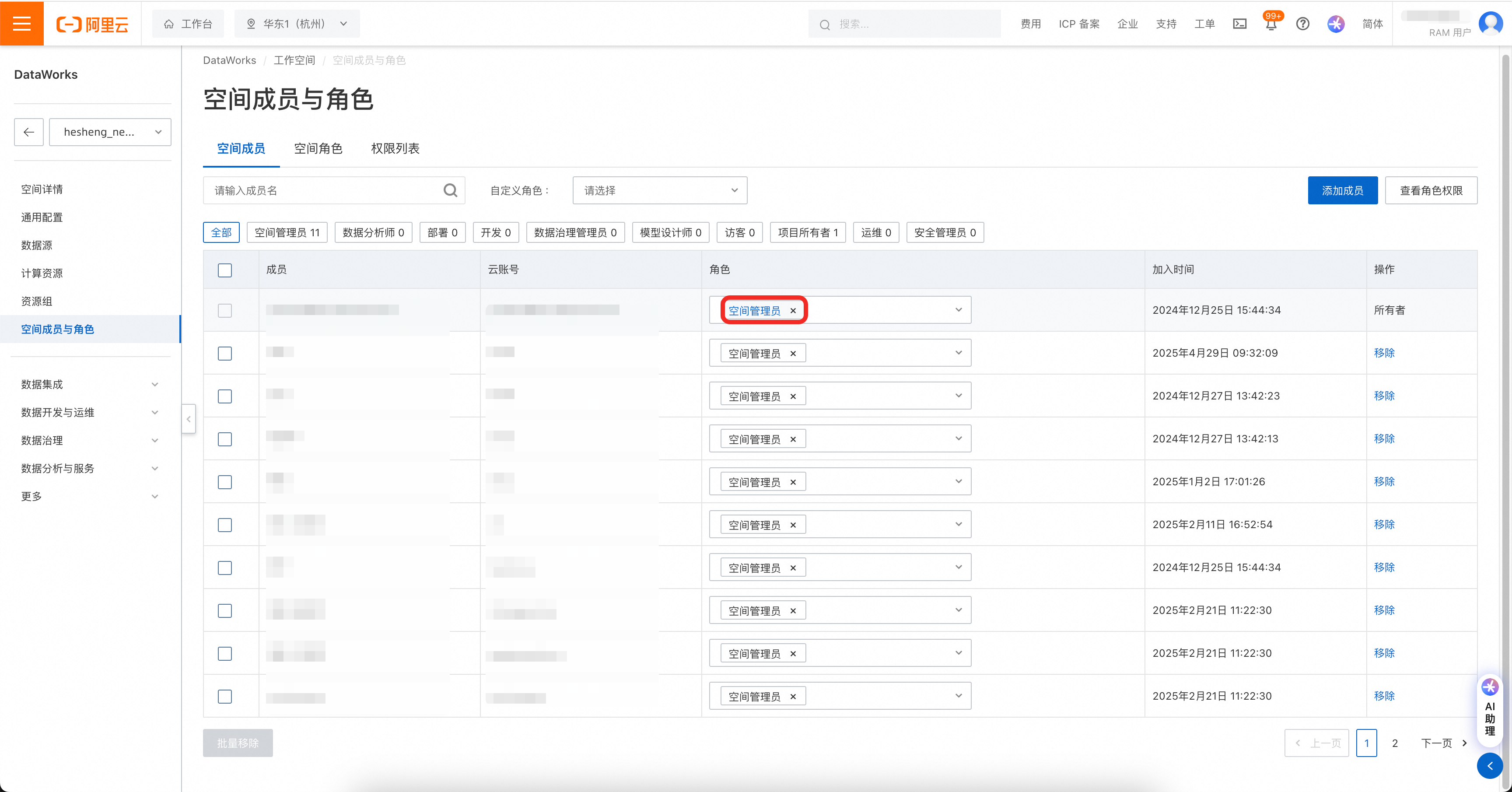
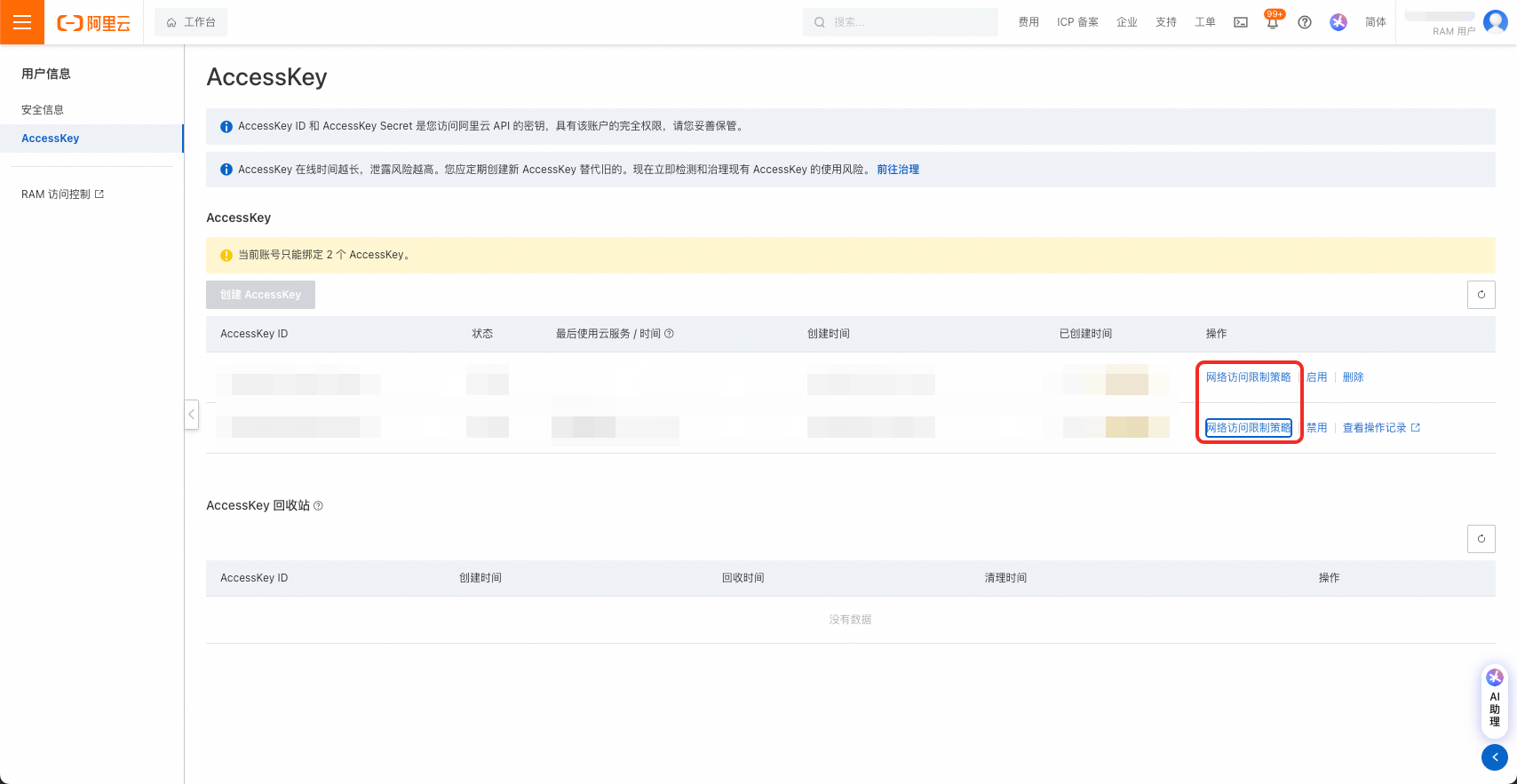
注意!AccessKey可设置网络访问限制策略,请务必保证迁移工具所在机器的IP被允许访问。
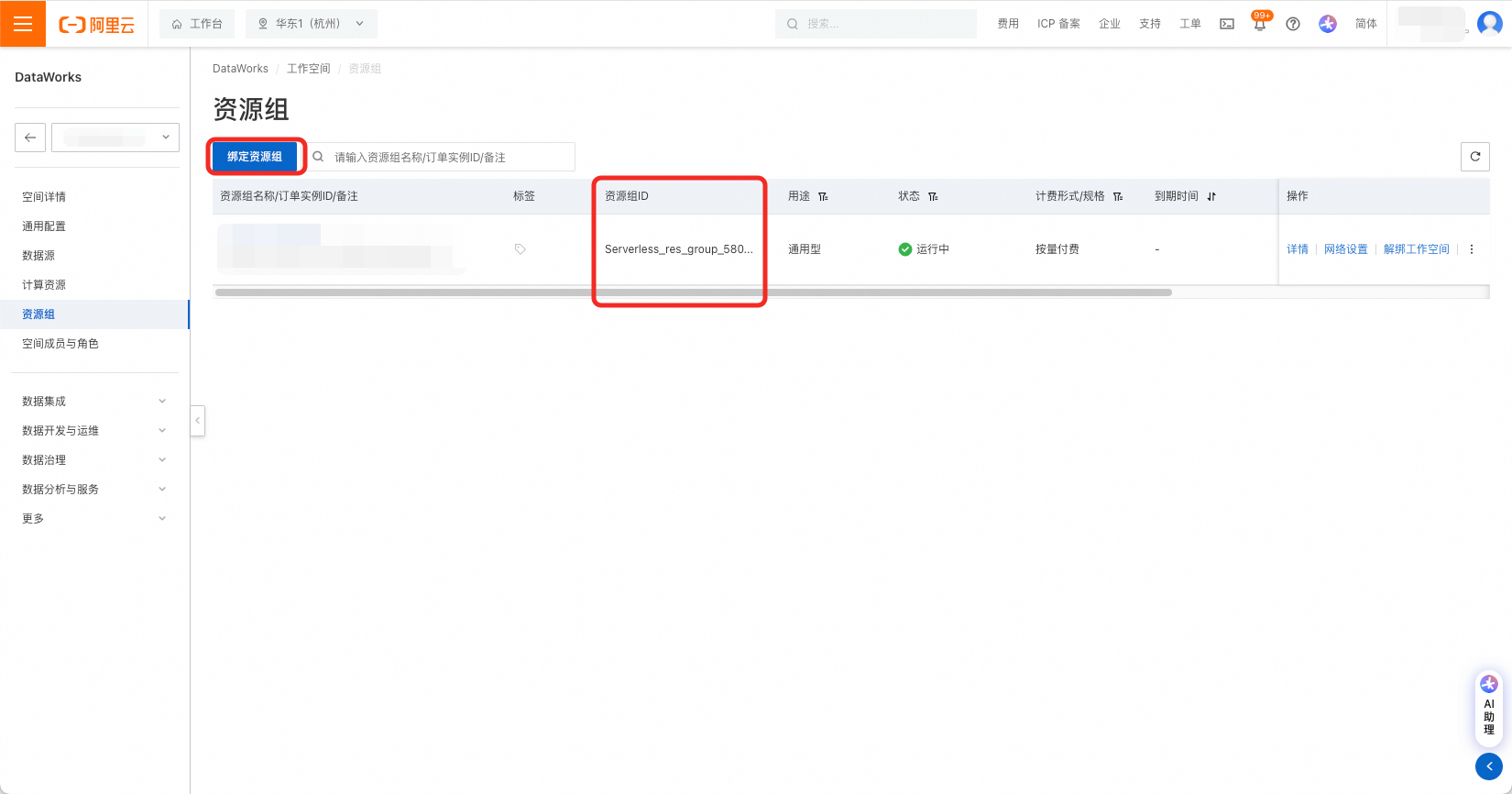
2.4 资源组
由DataWorks工作空间详情页左侧菜单栏进入资源组页面,绑定资源组,并获取资源组ID。
通用资源组可用于节点调度,也可用于数据集成。配置项中调度资源组resource.group.identifier和数据集成资源组di.resource.group.identifier可以配置为同一通用资源组。
2.5 QPS设置
工具通过调用DataWorks的API进行导入操作。不同DataWorks版本中的读、写OpenAPI分别有相应的QPS限制和每日调用次数限制,详见链接:使用限制。
DataWorks基础版、标准版、专业版建议填写"qps.limit": 5,企业版建议填写"qps.limit": 20。
注意,请尽可能避免多个导入工具同时运行。
2.6 DataWorks节点类型ID设置
在DataWorks中,部分节点类型在不同Region中被分配了不同的TypeId。具体TypeID以DataWorks数据开发实际界面为准。存在此特性的节点类型以数据库节点为主:数据库节点。
如:MySQL节点在杭州Region的NodeTypeId为1000039、在深圳Region的NodeTypeId为1000041。
为适应上述DataWorks不同Region的差异特性,工具提供了一种可配置的方式,允许用户配置工具所使用的节点TypeId表。
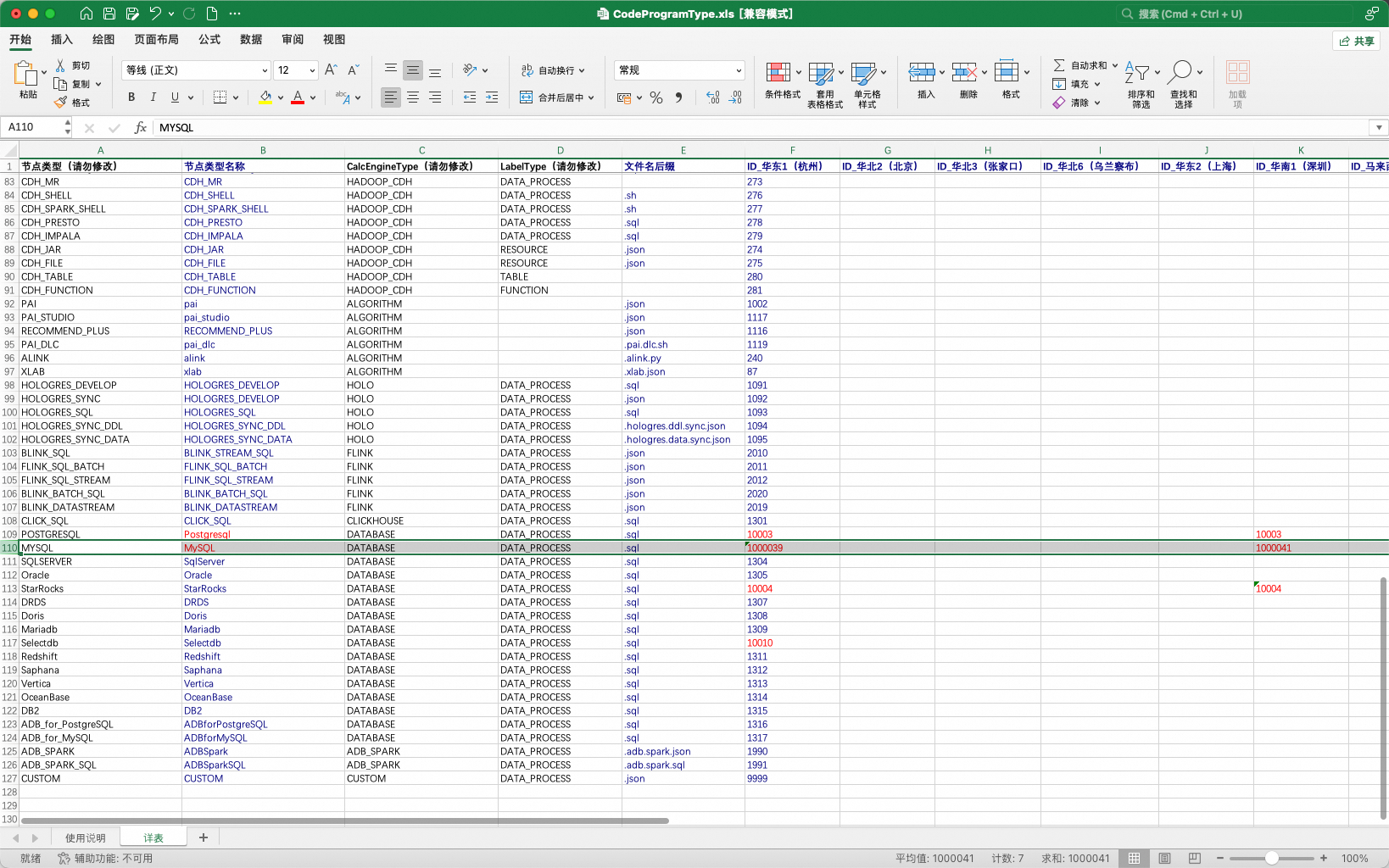
表格通过导入工具的配置项引入:
"conf": {
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls" // DataWorks节点类型表的路径
}从DataWorks数据开发界面上获取节点类型Id的方法:在界面上新建一个工作流,并在工作流中新建一个节点,在点击保存后查看工作流的Spec。
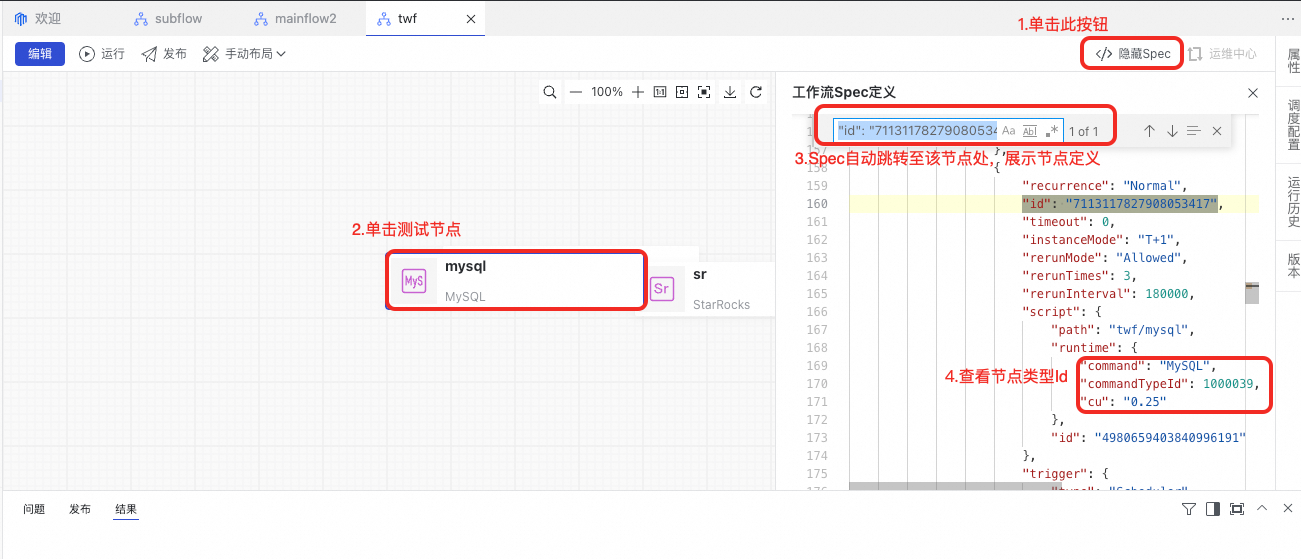
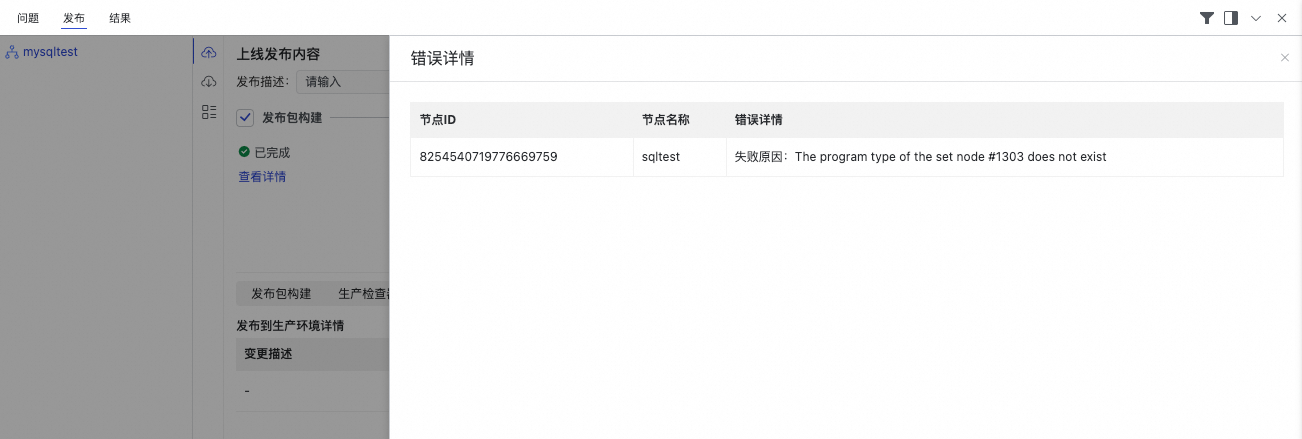
若节点类型配置错误,在任务流发布时将提示以下错误。
3 运行DataWorks导入工具
转换工具通过命令行调用,调用命令如下:
sh ./bin/run.sh write \
-c ./conf/<你的配置文件>.json \
-f ./data/2_ConverterOutput/<转换结果输出包>.zip \
-o ./data/4_WriterOutput/<导入结果存储包>.zip \
-t dw-newide-writer其中-c为配置文件路径,-f为ConverterOutput包存储路径,-o为WriterOutput包存储路径,-t为提交插件名称。
例如,当前需要导入DataWorks的项目A:
sh ./bin/run.sh write \
-c ./conf/projectA_write.json \
-f ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-o ./data/4_WriterOutput/projectA_WriterOutput.zip \
-t dw-newide-writer导入工具运行中将打印过程信息,请关注运行过程中是否有报错。导入完成后将在命令行中打印导入成功与失败的统计信息。注意,部分节点的导入失败不会影响整体导入流程,如遇少量节点导入失败,可在DataWorks中进行手动修改。
4 查看导入结果
导入完成后,可在DataWorks中查看导入结果。导入过程中亦可查看工作流逐个导入的过程,如发现问题需要终止导入,可运行jps命令找到BwmClientApp,并使用kill -9终止导入。
5 Q&A
5.1 源端持续在进行开发,这些增量与变更如何提交到DataWorks?
迁移工具为OverWrite模式,重新运行导出、转换、导入可实现将源端增量提交到DataWorks的能力。请注意,工具将根据全路径匹配任务流以选择创建任务流/更新任务流。如需进行变更迁移,请勿移动任务流。
5.2 源端持续在进行开发,同时进行DataWorks上任务流改造与治理,增量迁移时是否会覆盖DataWorks上的变更?
是的,迁移工具为OverWrite模式,建议您在完成迁移后再在DataWorks上进行后续改造。或者采用分批迁移的方式,已迁移等任务流再确认不再刷写后开始DataWorks改造,不同批次之间互相不会影响。
5.3 整个包导入耗时太长,能否只导入一部分
可以,可手动裁剪待导入包来实现部分导入:将data/project/workflow文件夹下需要导入的任务流保留、其他任务流删除,重新压缩回压缩包,再运行导入工具。注意,存在相互依赖的任务流需要捆绑导入,否则任务流间的节点血缘将会丢失。