
本文基于一个小众调度引擎到DataWorks的实际迁移项目,介绍了LHM定制调度迁移链路的最佳实践流程。
一站式湖仓大数据迁移平台(Lake House Migration,LHM)提供了多种调度平台间的工作流迁移的能力,已覆盖多种主流大数据调度到DataWorks的迁移。对于小众调度引擎迁移到DataWorks、开源二开调度引擎迁移到DataWorks的需求,LHM提供了定制调度迁移链路的模式——开发自定义插件。
本文档基于一个小众调度引擎——A引擎到DataWorks的实际迁移项目,介绍了从制定迁移方案到插件化开发的全套实施流程,减少调度转换中的遗漏点、风险点,助力用户平稳上云。
1 准备:制定迁移方案
1.1 探查:了解迁移源端调度引擎的特性、确定迁移范围
为制定具体的迁移方案,首先我们要对迁移源端的特性进行探明与梳理。
大数据调度平台的元素通常包括:项目、任务流、任务、文件资源、UDF、触发器、参数,元素间存在层级关系和引用关系。
1.1.1 调度元素层次结构梳理
首先以某小众引擎->DataWorks为例,说明梳理元素间层级关系和引用关系的必要性。
DataWorks新版数据开发中,元素有如下关系:
.
└── 工作空间
├── 工作流
│ ├── 节点
│ │ ├── 任务脚本
│ │ ├── 调度配置-调度参数(任务级参数)
│ │ └── 资源引用、UDF引用
│ ├── 调度配置-时间属性(触发器)
│ └── 调度配置-调度参数(工作流级参数)
├── 资源(文件资源)
└── 函数(UDF)某调度引擎中,元素有如下关系:
.
└── 项目
├── 开发空间
│ └── 任务脚本
└── 编排空间
└── 工作流
├── 任务
│ ├── 脚本引用
│ ├── 任务级参数
│ ├── 定时(触发器)
│ └── 资源引用、UDF引用
│── 工作流级别参数
├── 资源
└── UDF由于调度结构的差异,调度元素之间无法直接映射迁移。例如,样例中的引擎节点脚本单独存储,节点对脚本有引用关系;而在DataWorks中,对于大部分类型的节点,脚本被直接存储于节点中。样例中的引擎需要对每个节点设置触发器,而DataWorks在工作流上设计了触发器,这种结构性差异需要通过改造处理。此外,在此迁移场景中,资源、UDF也要做层级上的处理。
因此,在定制迁移时,了解源端调度引擎元素层次结构、梳理源端引擎与DataWorks在调度元素层次上的结构差异是首要的工作。
梳理方式有两种,一是直接通过源端调度引擎前端展示的功能梳理调度元素层级结构;二是利用源端调度引擎的导出功能,在导出包中梳理调度元素层级结构。
1.1.2 调度元素属性梳理
不同调度引擎中各调度元素的属性是各异的,在迁移时应尽量平迁相同功能的元素及其属性,加以适当的异构改造。接下来介绍需要重点关注的调度元素属性。
a. 任务类型及其主要属性
指调度引擎提供的任务类型及其功能。梳理任务类型和任务主要属性是制定调度转换规则、开发迁移工具中节点转换的基础。
b. 任务血缘属性
任务血缘可能存在多种情况:
节点-节点血缘(node-node lineage)
· 同工作流内节点血缘。
· 同工作空间内、跨工作流节点血缘。
· 跨工作空间节点血缘。
节点-工作流血缘(node-workflow lineage)
· 同项目内节点-工作流血缘。
· 跨项目节点-工作流血缘。
任务流-任务流血缘(workflow-workflow lineage)
· 同项目内工作流血缘。
· 跨项目工作流血缘。
DataWorks血缘使用任务节点输出名进行挂载,DataWorks新版数据开发对以上血缘类型均已支持。
c. 数据源与脚本转换
大数据迁移项目通常包含数据迁移和调度迁移两部分。在迁移/上云方案中,用户可能会更换数据源。例如,用户原本使用Hive,迁移后选型MaxCompute。数据源的迁移影响数据集成任务、数据开发任务的内容,调度迁移中需要相应进行转换的内容包括:
数据集成任务的读写插件配置。
SQL语句语法。
SQL语句中的库表名称。
因此梳理源端调度引擎中创建的数据源信息以及数据源与节点的绑定关系是必要的。
A引擎中存在若干个MySQL、Postgres数据源和Hive数据源,Hive数据源计划迁移为MaxCompute数据源。相应的,数据集成任务需要对MaxCompute数据源进行操作,hiveSql需要转换为ODPS_SQL,hiveSql中的库表名需要更改为MaxCompute中的库表名称。
除数据源相关的数据集成、数据开发代码外,迁移前后运行环境的改变可能会导致部分脚本无法直接执行,例如Shell、Python、Java等节点的脚本代码,需要项目上关注。
此外,部分调度引擎提供了若干可直接使用的变量,如DataWorks的时间表达式“$[yyyymmdd]”。在更换调度引擎后,源端调度引擎提供的变量需要进行转换处理。
亦有部分调度引擎对任务中的字段进行了加密/编码,在迁移中需要对属性进行解码。如DataArts在CDMJob中对部分where字段进行了编码。
d. 调度引擎规则特性差异
各调度引擎对于调度元素及其属性具有不同的约束规则,迁移时需要注意上传任务流需满足目标端约束。
例如,调度引擎中是否对调度元素的id、名称或其他属性有唯一性要求。在DataWorks中,Workflow的名称要求在同一目录下唯一、任务的输出名要求在工作空间中唯一、各元素ID唯一。而部分调度引擎无相同的强约束,因此存在改造需求。
需要提醒的是,将源端多项目迁移到目标端单一项目时,项目的合并也可能会导致出现重名的调度元素。在这种情况下,即便源端存在单空间内名称唯一性要求,也可能会导致重名。
1.1.3 调度迁移梳理清单
调度引擎中调度元素、属性与结构的高度复杂性,使得在进行梳理转换工作时,很容易出现遗漏。我们整理了一份“任务迁移前期梳理清单”,为调度迁移前期调研工作提供标准动作模板,减少调度转换中的风险。

1.2 规划:调度迁移异构转换方案确定
调度迁移异构转换方案基于探查结果制定,源于项目组对源端调度、目标端调度特性的全面了解,尤其需要重视源端与目标端的差异。接下来,我们将A引擎->DataWorks的迁移制定方案。
a. 引擎:
A引擎 + CDH -> DataWorks + MaxCompute
b. Project:
情况
· A引擎无Project概念,Workflow并列存在;DataWorks需要在工作空间中管理任务流。
· 用户希望在迁移的同时完成数仓分层治理。
方案
· 要求用户提供ODS、EDW层任务流清单。
· 基于数仓分层清单,将任务流分写到两个DataWorks工作空间。
· 注意创建跨工作空间的任务血缘依赖(DataWorks支持)。
c. Workflow:
情况
· A引擎和DataWorks都有任务流的设计。
· A引擎任务流ID满足唯一性条件、而名称存在重复情况;而DataWorks不允许同一路径下任务流重名。
方案
· A引擎任务流->DataWorks任务流一一映射。
· 转换中将A引擎任务流的ID拼接到其名称之后,使任务流名称满足唯一性。
d. Node:
节点类型映射
A引擎节点类型 | 说明 | 数量 | DataWorks目标类型 |
******** | 依赖节点 | ******** | Virtual + 跨工作流/项目空间的节点血缘 |
******** | 分支并发节点 | ******** | Virtual + 节点血缘 |
******** | RDBMS->HDFS/HIVE | ******** | DI |
******** | HDFS/HIVE->RDBMS | ******** | DI |
******** | HIVESQL(脚本外置) | ******** | ODPS_SQL |
其中Depend节点改造方法为:
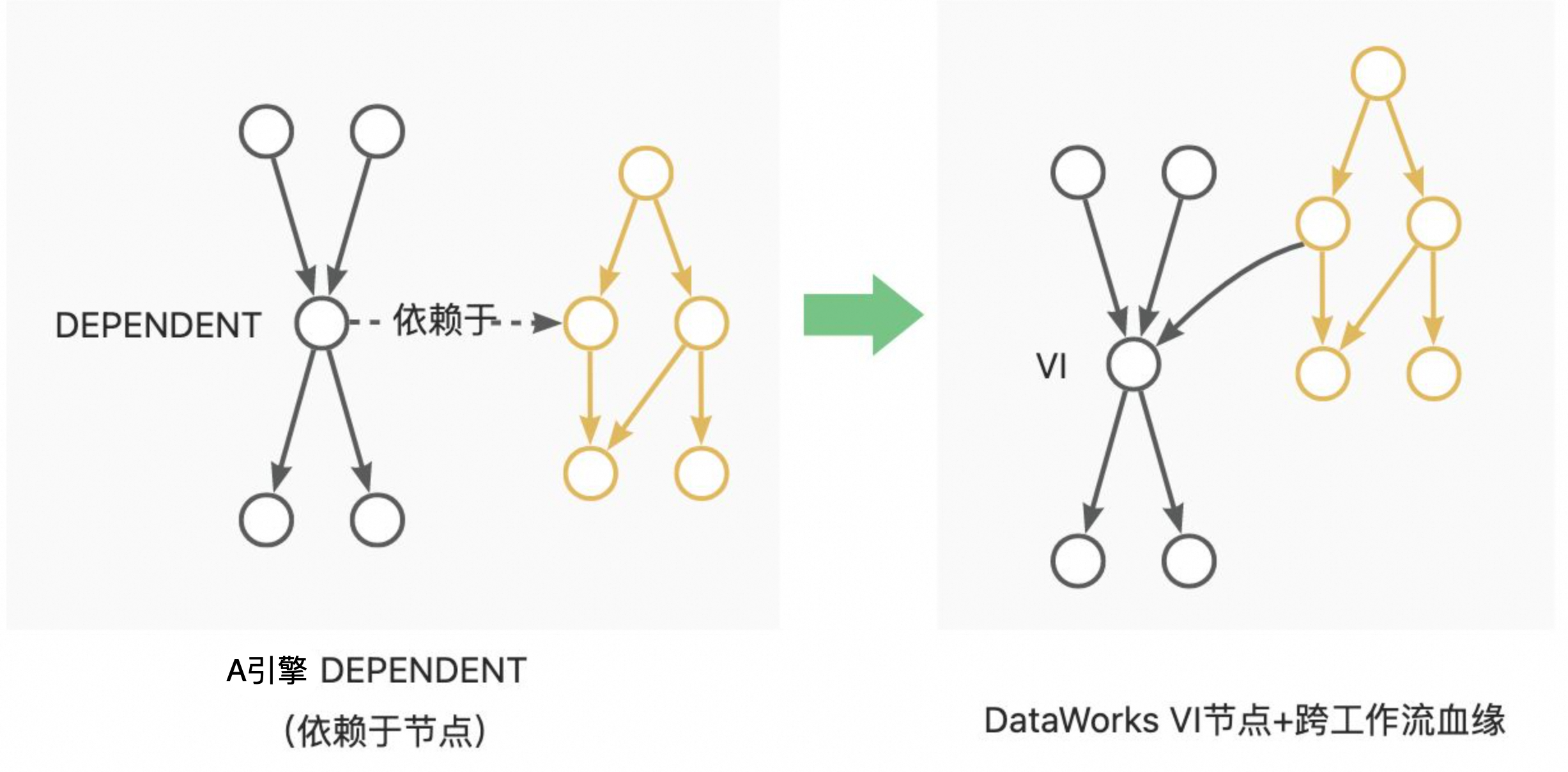
A引擎的节点脚本存储于单独的文件中。节点通过指定脚本的ID,对脚本文件进行应用。在迁移中需要将脚本读取并放置于节点中。
需要注意的是,在调度异构转换中补充目标端特有的属性也是迁移必不可少的工作之一。DataWorks中存在资源组的设计,创建数据集成任务时必须添加资源组、Cu等信息。
e. 脚本与变量改造
情况
· 源端HIVE上云后迁移至MaxCompute。
· A调度引擎提供内置时间表达式${yesterday};DataWorks中使用${bizdata}表示前一天。
方案
· 脚本转换:将A引擎的HiveSql脚本转换为OdpsSql脚本。
· 脚本转换:将A引擎数据集成节点中对Hive数据源的读写配置,改造为DI节点对MaxCompute数据源的读写配置脚本。
· 脚本中数据源库表名映射:将Hive数据源库表名修改为MaxCompute数据源库表名。
· 变量映射:将节点变量中、脚本中的${yesterday}修改为${bizdate}。
f. Trigger定时触发器
情况
· A引擎支持对Workflow设置定时,不支持对Node设置定时;新版DataWorks支持对Worflow定时,而不支持对Node设置。
g. 资源与函数
情况
· A引擎调度中资源函数以脚本文件为主,无UDF与Jar包资源。
方案
· 在转换时将脚本文件读取并放置于任务中。
以上是针对A引擎 -> DataWorks + MaxCompute迁移需求设计的调度异构转换迁移方案。本项目共计5k+节点,迁移体量大,且转换规则复杂,人工迁移费工费时易出错,开发自动化转换工具显然更合适。
2 开发:基于LHM迁移框架的自定义调度转换插件开发
从零开始开发一套调度迁移工具是具有挑战的,需要对源端、目标端的调度特性、数据结构了如指掌。
基于成熟的调度迁移工具框架开发具有以下优势:
为调度迁移能力开发提供GuideLine,有条理地完成调度迁移的读、转、写三步动作,提高开发质量。
可复用工具内的现有迁移能力,减少开发工作量。
可利用成熟工具的配套设施,优化迁移体验。
那么,哪里有功能成熟、框架开放的调度迁移工具可以使用呢?
一站式湖仓大数据迁移平台(Lake House Migration,LHM)提供了N2N调度迁移的能力,自动化完成源端调度引擎探查、异构调度转换与目标端调度引擎写入。对于主流调度引擎的迁移,LHM调度迁移工具提供了成熟的读转写能力,无需开发、一键迁移。而针对非标、中大体量调度迁移场景的项目提供了“自定义插件”的方案:允许项目组在框架内自行开发读、转、写能力,并以插件形式加载到LHM调度迁移框架中使用。
A引擎 -> DataWorks + MaxCompute调度迁移中,项目组基于LHM调度迁移框架完成了Reader、Converter插件的快速开发。
LHM调度迁移工具为该项目产生的实际收益如下:
有成熟的开发文档指导开发Reader、Converter插件,同时可申请LHM调度迁移团队提供的开发指导服务。
可直接使用LHM内置的DataWorks Writer插件完成目标端提交。
可联动调用SQL转换能力,完成HiveSql到OdpsSql的转换。
可使用LHM管控能力组织、管理调度迁移链路。
可使用LHM报表能力,可视化查看源端探查报表、异构转换报表、目标端提交报表。
3 实施:基于LHM迁移工具的调度迁移实施
在插件开发完成后,可在LHM调度迁移工具建立调度迁移链路,完成调度迁移全流程。基于LHM调度迁移工具,该项目5k+调度任务的迁移实际迁移实施仅用时1小时。
4 复盘:充分的调研与自动化工具的使用是保障高效迁移的关键
本文系统性地介绍了小众调度引擎迁移至DataWorks的方法。
非标场景调度迁移的关键挑战有二:
可能在没有任何资料的情况下,要求对未知调度引擎进行全面了解,并完整梳理迁移中需要异构转换的内容。
从零开始开发调度迁移工具存在技术难度与工作量,且难以控制开发质量。
本文以A引擎 + CDH -> DataWorks + MaxCompute迁移项目为例,提供了一份将小众调度引擎迁移至DataWorks的解决方案:
首先介绍了如何有条理地梳理调度引擎特性,提供了一份“调度迁移梳理清单”;
然后基于对源端、目标端特性差异的全面了解,针对性的制定了调度迁移异构转换方案;
为保障开发质量、减少开发工作量,选择了LHM调度迁移框架,开发Reader、Converter插件。
基于LHM工具快速完成调度迁移实施。
实施效果如下:
若项目采用人工迁移方法,预计需要:
人工迁移所需人天评估(100任务/人天):52人天
基于LHM工具的调度迁移实施,项目实际成本投入:
自定义Reader、Writer插件开发:15人天
工具实施(含工具部署、试运行验证、正式实施):5人天
提效比例:(52-15-5)/(52)*100% = 61.54%
即,基于该方案,项目实施减少了61.54%的人天投入,大大降低实施成本。
回顾整个过程,由于项目组在POC阶段就进行了有条理且充分的调研,并在正式实施前基于LHM调度工具完成了高效的开发,大大规避了调度迁移实施风险、提高实施效率。