
本文基于一个DolphinScheduler调度任务上云实际项目,介绍如何基于LHM调度迁移工具进行实施,提供一套标准作业程序,降低实施风险。
1 项目背景
X公司是一家快销公司,其大数据任务在Dolphin Scheduler 3.1.9上调度,主要使用的数据源有Hive、Impala、MySQL、ClickHouse。本次需要将其调度任务迁移至DataWorks,并将Hive数据迁移至MaxComute中。调度工作流迁移及其改造基于LHM调度迁移工具完成。该项目体量较大,复杂度较高,存在大量非标准转换需求,以此项目为例旨在向实施人员预警可能存在风险。
2 迁移范围调研与迁移计划制定
2.1 迁移范围盘点
LHM调度迁移工具具有从迁移源端导出、解析工作流的能力:
DolphinScheduler->DataWorks: 导出DolphinScheduler调度任务流
基于解析功能,可生成如下盘点报告:
迁移体量总览
源端调度引擎 | Dolphin Scheduler 3.1.9 |
工作空间数 Project Count | 40+ |
工作流总数 Workflow Total Count | 1500+ |
工作流节点总数 Node Total Count | 15000+ |
文件资源总数 File Resource Total Count | 0 |
UDF总数 UDF Function Total Count | 0 |
节点类型总览
源端任务类型 | Total Count | |
SHELL类 | SHELL | 3000+ |
SQL类 | SQL(HIVE+IMPALA) | 9000+ |
SQL(CLICKHOUSE) | 900+ | |
SQL(MYSQL) | 200+ | |
数据集成类 | SQOOP | 500+ |
逻辑控制类 | SUB_PROCESS | 1200+ |
DEPENDENT | 200+ | |
CONDITIONS | 10+ | |
其他类型节点 | MR | 5+ |
HTTP | 5+ | |
(对于每个工作空间,可生成独立的节点类型统计表)
和各空间的责任人确认,所有空间均需要进行迁移。
2.2 迁移初步方案制定
根据迁移源端与目标端,可初步制定迁移转换方案。调度任务开发具有较强的灵活性,LHM调度迁移工具对标准迁移需求进行了覆盖,然而可能存在一些特殊情况需要人工改造。在制定迁移方案时,需要根据操作文档中列举的转换能力确认LHM工具对迁移工作量的覆盖情况,并整理特殊的、需要人工改造的内容。
迁移链路
源端:Dolphin Scheduler + Hive, Impala, MySQL, ClickHouse
目标端:DataWorks + MaxCompute, MySQL, ClickHouse
节点转换方案
Dolphin Scheduler节点类型 | DataWorks节点类型 |
SHELL | 通用Shell等 |
SQL(HIVE+IMPALA) | MaxCompute SQL |
SQL(CLICKHOUSE) | ClickHouse SQL |
SQL(MYSQL) | MySQL |
SQOOP | DI |
SUB_PROCESS | Sub Process |
DEPENDENT | 虚拟节点 & 血缘依赖 |
CONDITIONS | 双层归并节点 |
MR | MaxCompute MR |
HTTP | 通用Shell节点 & Curl命令 |
工作流转换包括三部分:
节点转换;
血缘转换;
配置项转换。
节点转换包括三部分:
节点类型转换;
配置项转换;
脚本转换(内容转换)。
将转换方案与LHM调度迁移工具转换能力(见DolphinScheduler->DataWorks任务流转换)相比对,我们可以盘点工具能力覆盖情况:
工作流DAG转换已支持,含节点、血缘;
工作流配置项转换已支持,如定时参数;
节点类型映射均已支持;
节点代码转换部分支持,如SQL转换、Sqoop转DI、HTTP转Shell;
节点配置项转换部分支持。
人工改造点:
存在大量Shell节点,且脚本的开发风格较为奔放,需要分类改造为不同的DataWorks节点或进行适配。工具提供的是Shell节点转通用Shell节点的能力,不足以应对该需求,因此需要人工改造。
Hive、Impala数据源迁移至MaxCompute,然而在Dolphin Scheduler中未区分Hive数据源与Impala数据源,需要人工将Hive SQL与Impala SQL分类,再传递给SQL转换。
MR节点使用了Jar包资源,需要进行人工改造。
节点使用了Dolphin Scheduler内置变量,需要人工梳理内置变量的映射规则,并结合工具所提供的变量批量替换能力进行改造。
通常Shell脚本、Python脚本、Spark Jar具有高度灵活性,工具难以完全覆盖其转换,需要项目实施人员重点关注。
此外,各调度引擎提供了特有的内置调度变量,其构造方式(类似于语法)存在差异,调用方式(例如是否需要在节点变量中先声明后使用?还是可以直接在节点代码中使用?)也存在差异。以工具去覆盖每一种内置变量的转换是工程浩大的,因此工具为用户提供了标准的变量替换能力,用户可自行梳理其使用到的内置变量映射规则,半自助地完成转换。
2.3 POC验证
调度迁移具有高度复杂性,强烈建议在正式实施前,构建完备的最小测试用例(迁移测试用工作流)并进行迁移验证。测试用例应包含所有待迁移的节点类型及其使用方式。
此外,项目实施应制定合理的时间计划,预留校验时间与改造时间,减少实施风险。
3 调度迁移工具实施流程
LHM调度迁移(多轮迁移)主流程如图所示,目前工具已完成大部分环节的自动化/半自动化覆盖。在纯标准迁移场景中,工具能实现全流程自动化覆盖;当存在特殊改造需求时,工具也能提供半自动化能力,辅助用户完成转换。以X公司的上云项目为例,主要经历了以下步骤:
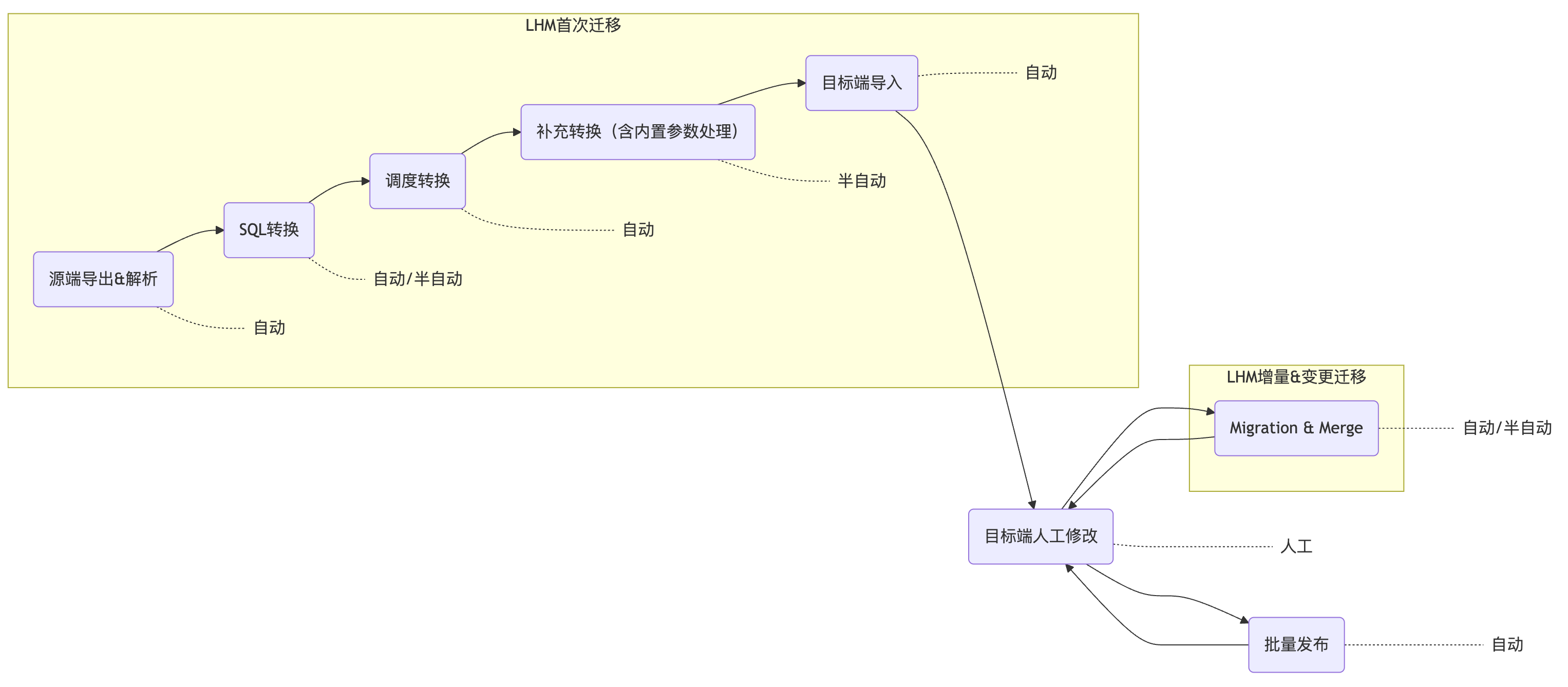
3.1 迁移源端调度工作流导出与解析
LHM调度迁移工具Reader模块通过调用Dolphin Scheduler的API获取项目空间信息、工作流定义、数据源定义、资源文件等信息。操作详见:导出DolphinScheduler调度任务流。
3.2 SQL转换
由于Hive/Impala迁移至MaxCompute,节点上的HiveSQL、ImpalaSQL需要转换为MaxComputeSQL。操作详见:如何在调度迁移中转换SQL语法。
SQL转换可以在调度转换前进行,亦可在调度转换后进行,我们建议在前。这是由于工具会将SQL脚本会按节点类型及数据源类型分类放置,如果存在A类SQL节点、B类SQL节点均转换为C类SQL节点的情况,在调度转换后两类SQL会掺杂在一起,难以进行A->C、B->C的分类转换;而在转换前,A与B能清晰区分。
此外,在本项目中,由于Dolphin Scheduler上Hive数据源与Impala数据源未作区分,SQL转换前需要实施人员对HiveSQL、ImpalaSQL进行分类。分类方式通常有两种,其一是通过SQL节点绑定的数据源作区分,人工梳理哪些数据源为Hive数据源、哪些为Impala数据源,然后批量地将关联脚本分类;其二是识别HiveSQL、ImpalaSQL语法特征,基于脚本本身做分类。该项目中采用的是第二种方式,并结合大模型完成了分类。
3.3 调度转换
使用LHM调度迁移工具Converter模块完成Dolphin Scheduler到DataWorks的转换,包含工作流、节点、部分脚本(如Sqoop转DI)、调度属性、血缘依赖的转换。Converter提供了标准的异构调度转换能力,覆盖了大部分转换工作量。操作详见:DolphinScheduler->DataWorks任务流转换。
3.4 补充转换
在LHM标准调度转换完成后,用户可以对调度数据包进行进一步修改以实现一些特殊转换需求。特殊转换需求包含两部分:一是标准迁移转换工具难以完全覆盖的特殊转换需求,二是因用户对迁移目标端的治理需求。
LHM提供了一些灵活开放的能力,让用户可以快速、自由地修改调度属性:使用调度迁移中的概览报表补充修改调度属性。
LHM调度标准包也允许用户自由修改,包结构可参考:规范:LHM调度迁移标准包数据结构。
在本项目中,实施人员基于上述能力对调度变量进行了改造,并对部分Shell脚本进行了适配性处理。
3.5 目标端导入
使用LHM调度迁移工具Writer模块将转换完成的工作流导入到DataWorks中。操作详见:导入DataWorks。
3.6 目标端人工修改
在前期调研中发现,迁移源端存在大量Shell节点,且脚本的开发风格较为奔放,需要分类改造为不同的DataWorks节点或进行适配。工具提供的是Shell节点转通用Shell节点的能力,不足以应对该需求。
在利用LHM调度迁移工具完成首轮迁移后,实施人员在DataWorks中对复杂的Shell节点进行了重构。
LHM也提供了针对DataWorks的批量治理工具,以辅助实施人员完成修改:使用本工具进行DataWorks批量治理。
3.7 增量迁移&变更迁移(Merge操作)
由于大数据集群迁移是一个持续性过程,时间周期根据规模与复杂度可能从数周至数月不等,因此一边进行迁移一边源端持续性开发、一边迁移一边目标端进行集群适配性改造是比较常见的。通常需要多轮迁移来同步源端的变更(含增量),同时将有选择的保留在目标端的一些改造调整。LHM调度迁移工具针对该场景提供了源端、目标端的Merge能力,实现丝滑的增量迁移、变更迁移,操作详见:多轮迁移中如何融合迁移源端与目标端的变更。
3.8 目标端批量发布
工具提供了对DataWorks周期任务流批量发布的能力,会自动解析任务流依赖、引用关系,按拓扑顺序依次发布。在迁移完成后,可使用此能力完成工作流的批量发布,操作详见:使用本工具对DataWorks周期工作流批量发布。
4 校验与割接
迁移完成后,应进行充分的双跑校验,以保障迁移效果。校验符合预期时可进行割接。
可使用LHM提供的实用工具辅助校验与修复:例如,利用LHM DataWorks批量治理工具将任务批量设置为空跑状态,或是将任务所绑定的数据源批量切换为测试数据源/生产数据源。(详见使用本工具进行DataWorks批量治理)。
5 项目复盘
项目复盘动作,回顾风险、评估效率与收益。