容器洞察(CloudLens for Container)是云监控 2.0 面向容器场景提供的一站式智能可观测能力,融合了多模态可观测数据(指标、日志、调用链、事件),基于 UModel 建模与 LLM 大模型能力,帮助用户实现容器资源自动关联与智能分析诊断。容器洞察既支持阿里云容器服务(ACK/ACS/ACK One 等)集群接入,也支持用户自建 Kubernetes 或其他云平台 Kubernetes 集群接入。本文主要描述自建 Kubernetes 集群或其他云平台 Kubernetes 集群如何接入云监控 2.0。
适用范围
Kubernetes 集群版本 >= 1.18。
Helm 版本 >= 3.0。
该接入能力目前在灰度阶段,需提交工单加白支持。
操作步骤
准备网络条件
自建 Kubernetes 集群要接入云监控 2.0,需要能够访问阿里云相关服务,网络方式支持走公网和内网,可以在部署 Helm Chart 时选择:
公网配置(默认)
走公网需要保证自建 Kubernetes 集群可以通过互联网访问阿里云相关服务,涉及到阿里云云监控以及日志服务:
内网配置
走内网需要先将自建 Kubernetes 集群的本地网络与云上的某个VPC打通,可以通过阿里云网络相关产品先打通网络,比如高速通道。网络打通后可以按上报地域放开云监控及 SLS 内网域名对应网段。
云监控内网域名:
cms-vpc.[REGION].aliyuncs.com,[REGION]为您选择的阿里云地域。对应网段为100.103.0.0/16,该域名主要用于自动发现集群内的 Promethues Rule 并在云上创建对应的告警规则,不影响数据上报,若您的集群网络无法打通云监控内网网段,可适当降级关闭该功能,否则无法成功完成组件部署。如何关闭详见Q2: 如果集群网络不通阿里云云监控内网网段,导致数据无法接入怎么办?日志服务SLS内网域名,该域名用于可观测数据上报,域名请参考:VPC专用内网域名。
说明如果日志服务内网域名网段存在冲突,可通过私网连接(PrivateLink)访问日志服务。
权限准备
建议为自建 Kubernetes 接入配置的阿里云账号创建一个 RAM 账号并创建AccessKey。并为RAM账号授予权限:可以直接给该RAM 账号赋予 AliyunPrometheusMetricWriteAccess 系统权限策略,也可以自定义权限策略,自定义权限策略参考:
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": [
"log:CreateMachineGroup",
"log:UpdateMachineGroupMachine",
"log:ListMachineGroup",
"log:GetMachineGroup",
"log:UpdateLogtailPipelineConfig",
"log:CreateLogtailPipelineConfig",
"log:GetLogtailPipelineConfig",
"log:GetProject",
"log:GetLogStore",
"log:TagResources",
"log:ListTagResources",
"log:UntagResources",
"log:GetAppliedMachineGroups",
"log:ApplyConfigToGroup",
"log:RemoteWritePrometheus",
"log:RemoteWrite",
"log:QueryMetrics",
"log:QueryPrometheusMetrics",
"log:PostLogStoreLogs",
"log:DeleteLogtailPipelineConfig",
"cms:GetPrometheusInstance",
"cms:SyncAlertRulesByGroup"
],
"Resource": "*"
}
]
}初始化云上资源
登录 阿里云监控 2.0 控制台,进入工作空间管理页面,选择期望接入的工作空间或新建工作空间。
说明新建工作空间信息:
工作空间名称:建议使用有意义的名称,如
k8s-insight。地域:选择与您的 Kubernetes 集群相近的地域,如
cn-hangzhou,参考地域和可用区。描述:可选,描述工作空间的用途。
进入云监控 2.0 接入中心。
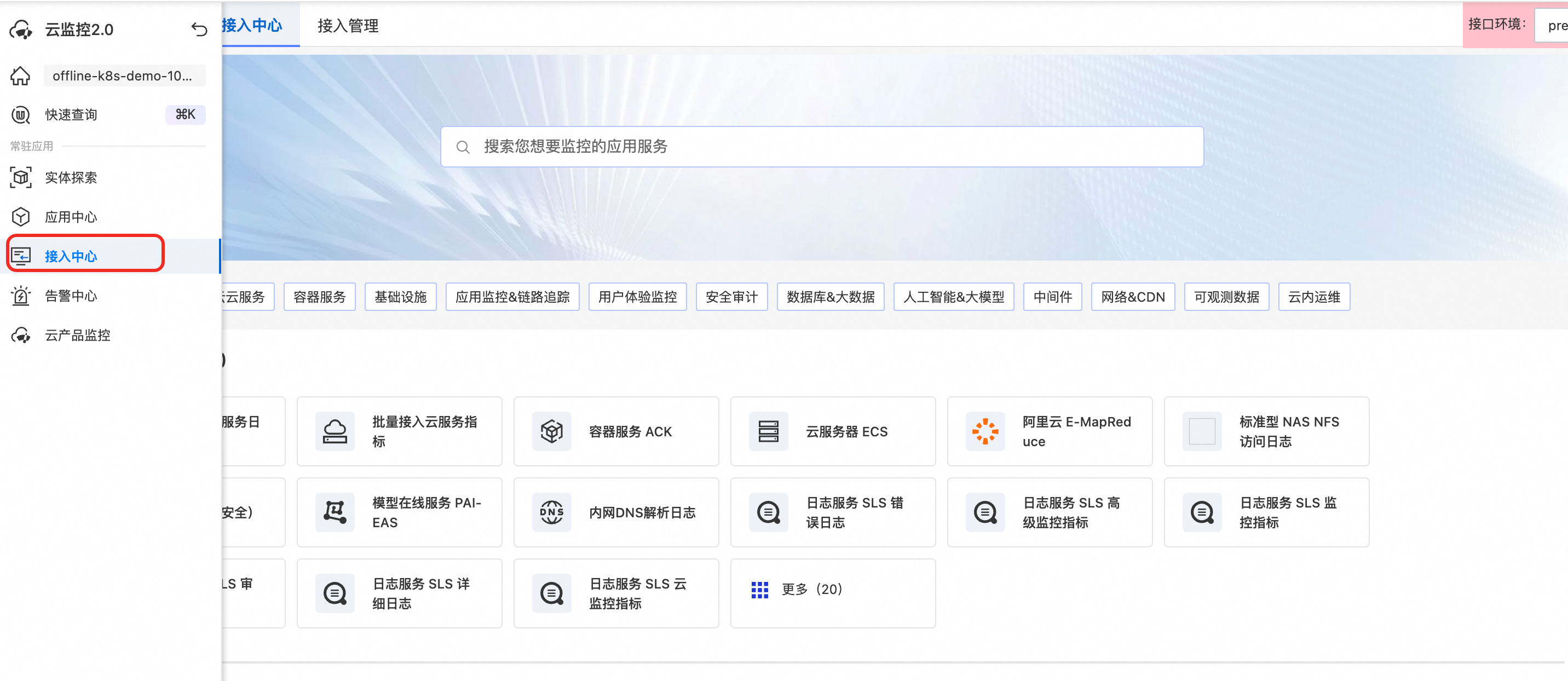
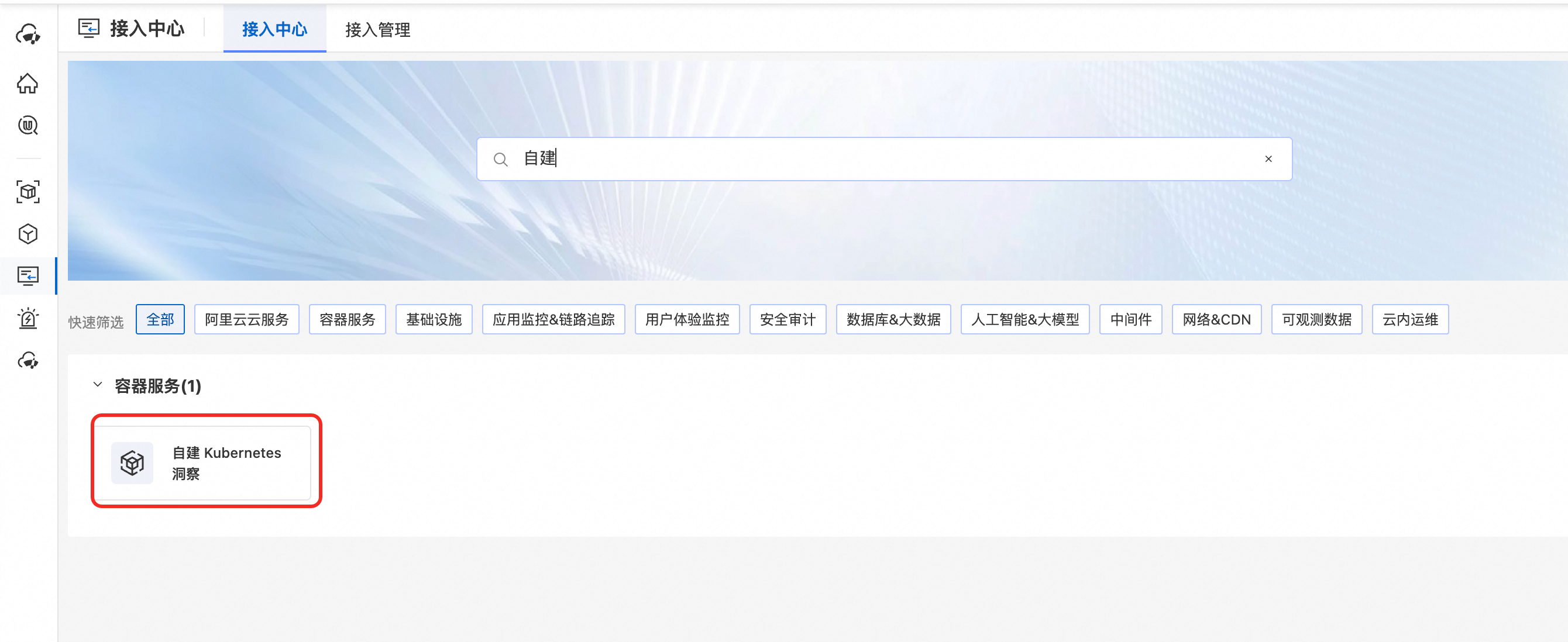
搜索“自建 Kubernetes 接入”项目,按照提示进行接入后单击确定。
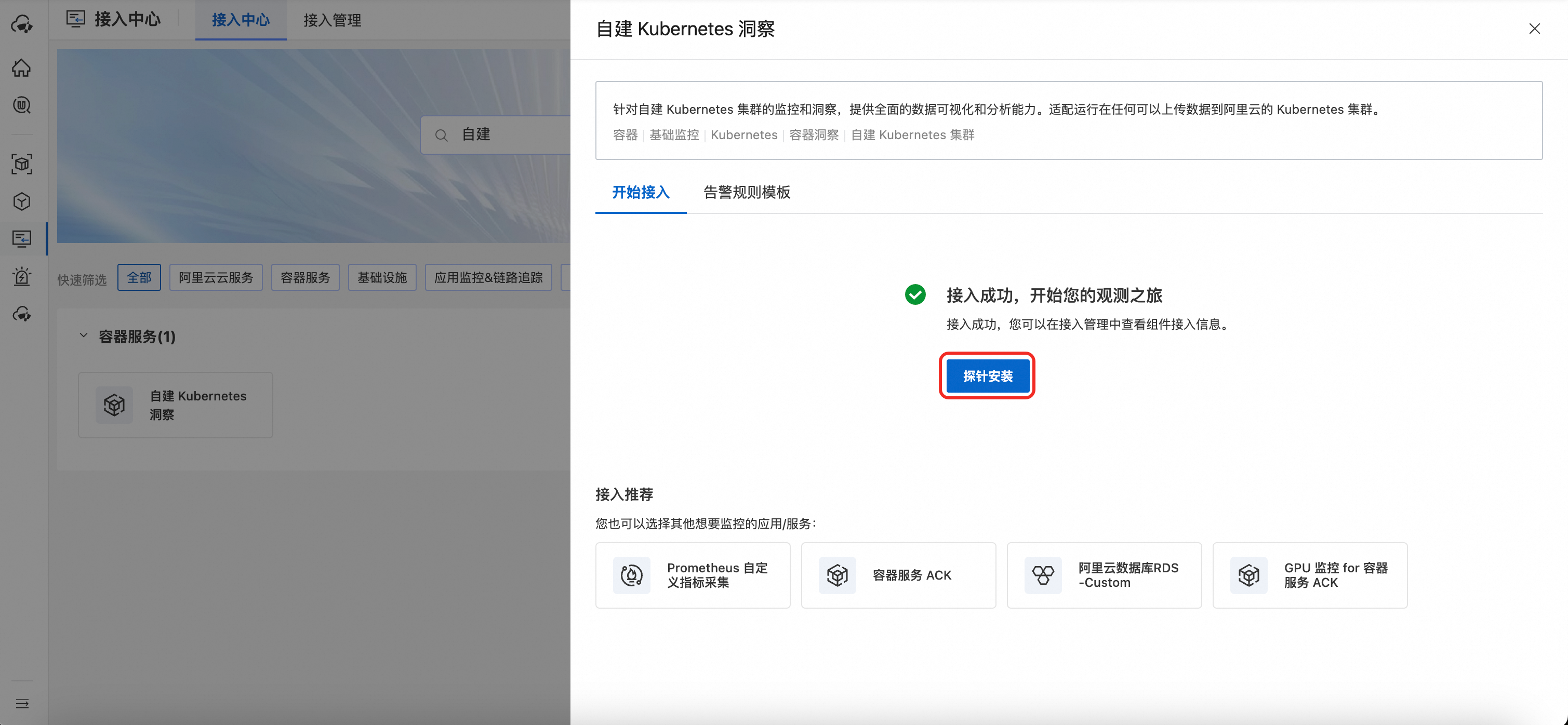
确定后,开始初始化云上资源,单击探针安装为集群部署探针组件。
 说明
说明初始化云上资源,主要是创建对应的 Promethues 实例和SLS 存储,创建后如果没有数据上报不会产生费用。
通过 Helm 方式部署接入组件
云上资源准备就绪后,根据提示在集群中部署 Helm Chart 安装探针进行数据采集及上报。
在输入框中输入 AccessKeyID 及 AccessKeySecret。注意,请确保 AccessKeyID 具有 AliyunPrometheusMetricWrite 对应权限策略,否则,数据上报可能会失败。
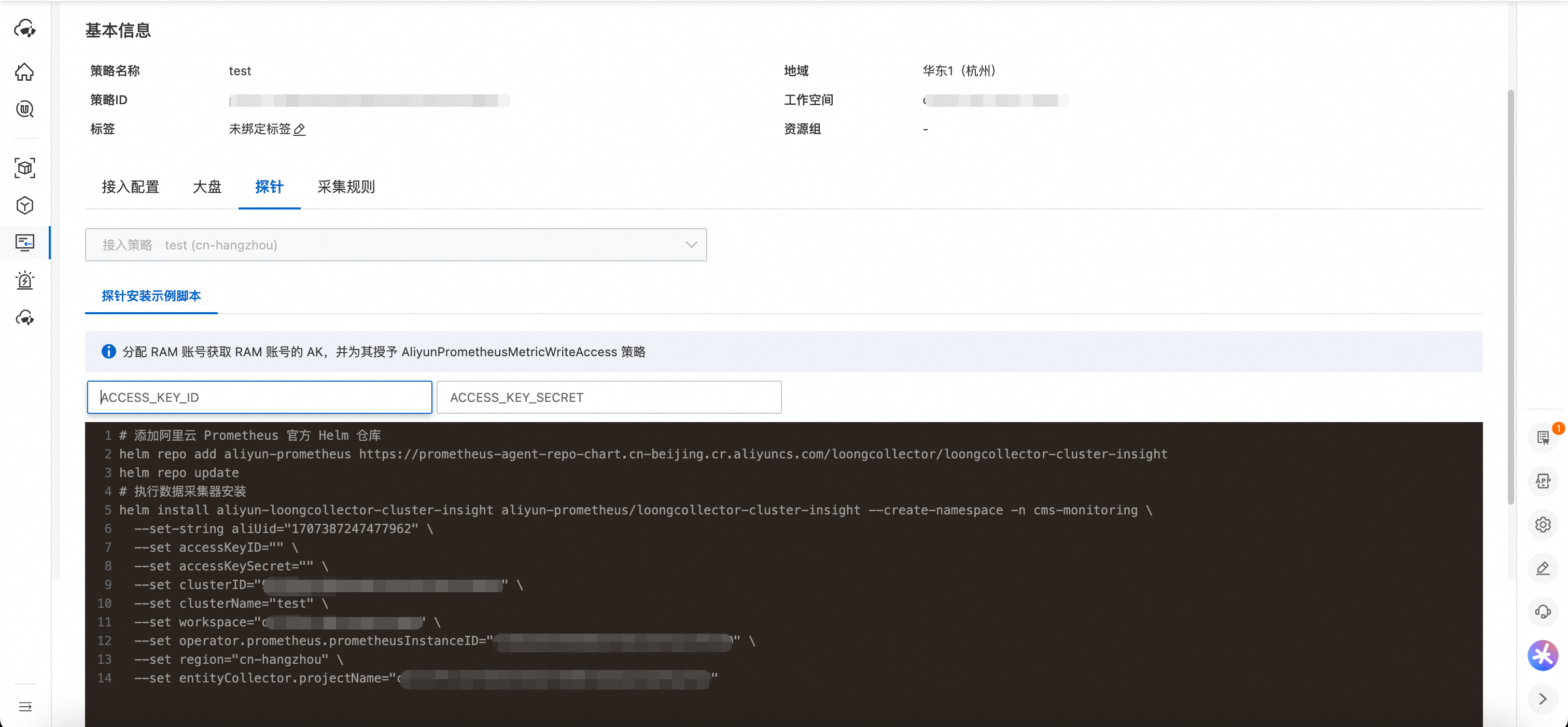
输入复制AccessKeyID 及 AccessKeySecret,探针安装脚本将会自动生成。复制脚本在 Helm 环境中执行。该指令会添加 Helm 仓库及部署 Helm Chart 到自建 Kubernetes 集群。
复制探针安装脚本在您的 Helm 环境中执行即可,默认安装的 Helm Release 名称为
aliyun-prometheus,并且会创建(如果不存在)名为cms-monitoring的 Kubernetes Namespace。说明云监控会为您随机生成一个集群 ID 作为该集群的唯一标识。
验证组件状态
查看安装的工作负载运行状态。若组件均处于 Running 状态,则表明工作负载运行正常。
kubectl get pods -n cms-monitoring在云监控工作空间选择实体探索,观察集群实体是否上报到工作空间。
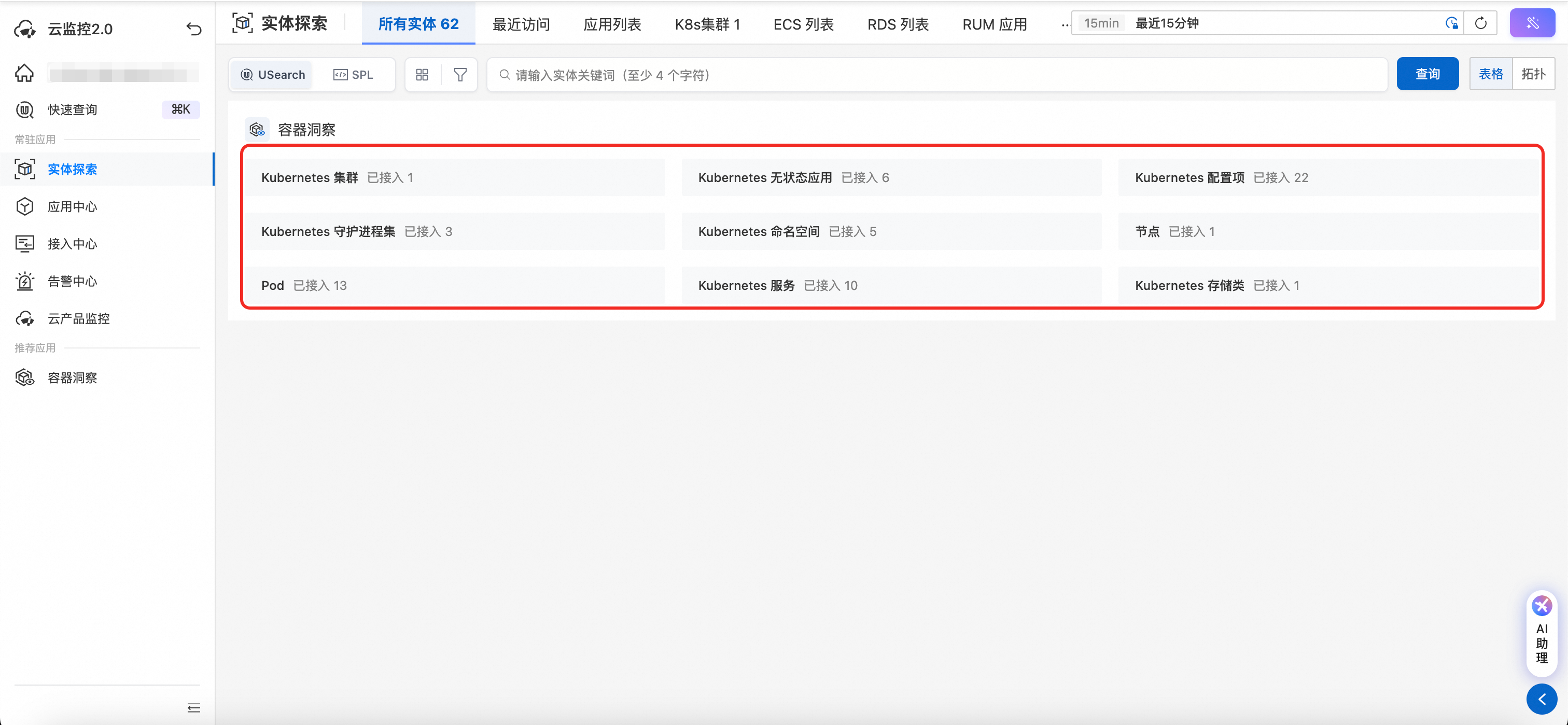
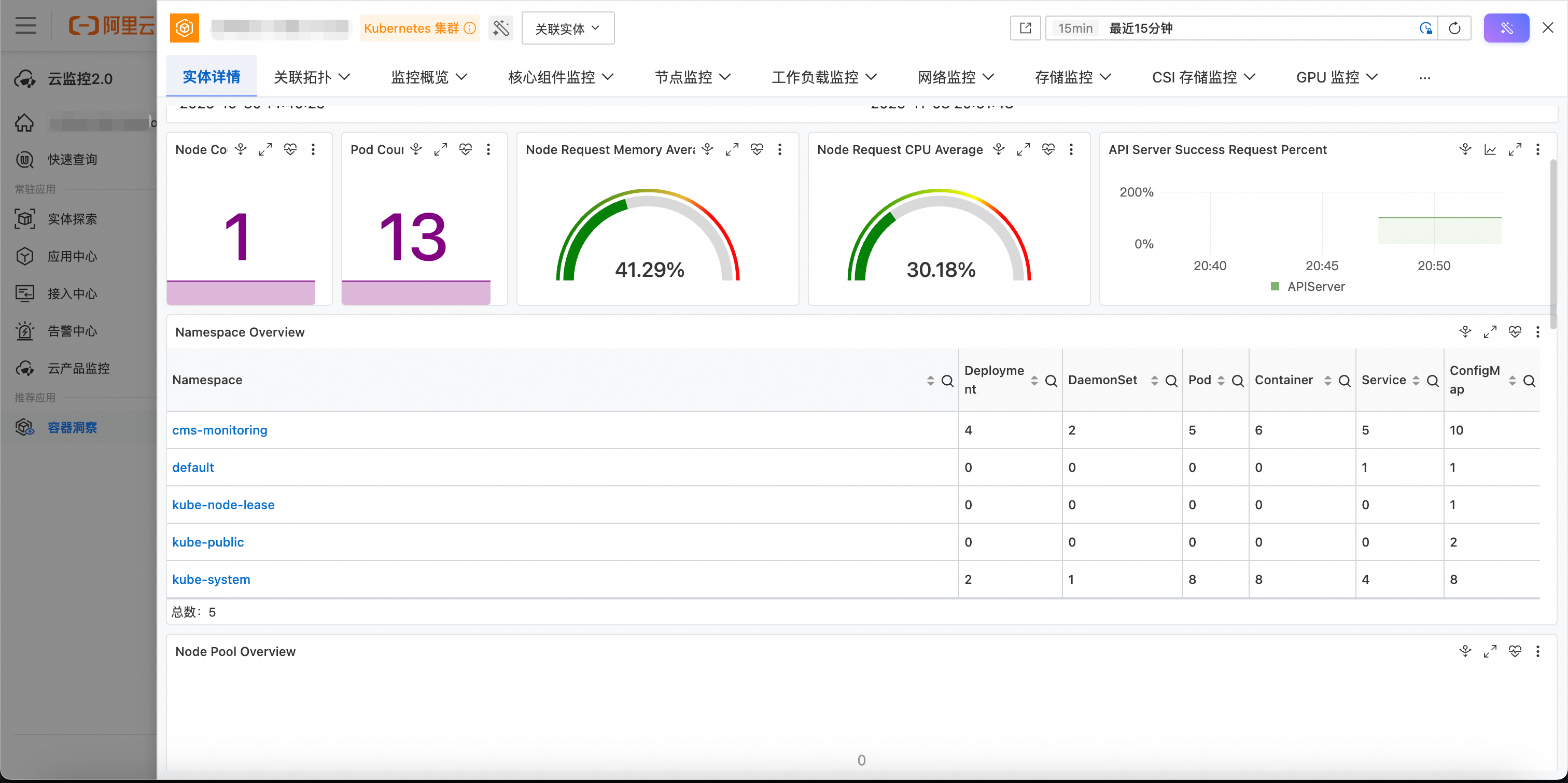
前往容器洞察查看指标数据。
其他操作
卸载组件
当您需要将自建 Kubernetes 从云监控 2.0 中移除时,请按照以下步骤操作。
必须按照顺序执行,否则可能导致资源无法被完全清理。如果您在安装 Helm Chart 时,修改了 Helm Release 名称或命名空间,则需要在卸载时替换为实际值。
步骤 1:删除 ClusterAliyunPipelineConfig 资源(重要)
在卸载 Helm Chart 之前,必须先删除 EntityCollector 创建的 ClusterAliyunPipelineConfig 资源。该资源包含 finalizer,如果直接卸载 Helm Chart,可能会导致该资源无法被删除。
1.1 确认资源名称
首先,确认您的集群ID(CLUSTER_ID),资源名称格式为:custom-kubernetes-{CLUSTER_ID}-entity-collector。例如,如果您的 CLUSTER_ID 是 my-cluster-123,则资源名称为:custom-kubernetes-my-cluster-123-entity-collector。
CLUSTER_ID可以在安装脚本中获取(clusterID 字段),可以访问云监控2.0 对应工作空间,在接入中心 - 接入管理,找到对应接入策略,访问 “探针”即可获取安装脚本。
1.2 删除资源
注意:如果跳过此步骤,直接卸载 Helm Chart,会导致 ClusterAliyunPipelineConfig 资源无法删除,因为 Operator 已被删除,无法处理 finalizer。
kubectl delete clusteraliyunpipelineconfig custom-kubernetes-[CLUSTER_ID]-entity-collector -n cms-monitoring步骤 2:卸载 Helm Chart
执行以下命令卸载 Helm Chart:
helm uninstall aliyun-loongcollector-cluster-insight -n cms-monitoring步骤 3:删除 CRD(可选)
如果您确定不再需要使用自建 Kubernetes 接入,并且其他应用也不会使用这些 CRD,可以删除相关的 CRD 定义。
注意:删除 CRD 会删除该 CRD 类型的所有资源,请确认没有其他应用在使用这些 CRD。
该 Chart 安装的 CRD 包括:
clusteraliyunpipelineconfigs.telemetry.alibabacloud.comaliyunlogconfigs.log.alibabacloud.compodmonitors.monitoring.coreos.comservicemonitors.monitoring.coreos.comprometheusrules.monitoring.coreos.comprobes.monitoring.coreos.com
删除 CRD 命令:
# 删除 ClusterAliyunPipelineConfig CRD
kubectl delete crd clusteraliyunpipelineconfigs.telemetry.alibabacloud.com
# 删除 AliyunLogConfig CRD
kubectl delete crd aliyunlogconfigs.log.alibabacloud.com
# 删除 Prometheus Operator CRDs(如果确认不需要)
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd probes.monitoring.coreos.com更新组件
当 Helm Chart 有更新时,可以按照以下步骤进行更新
获取 Helm Chart 最新版本。
helm repo update helm search repo aliyun-prometheus/loongcollector-cluster-insight获取当前已经安装的 Helm Chart 版本。
helm get all aliyun-loongcollector-cluster-insight -n cms-monitoring | grep "APP_VERSION"如果存在版本更新,可以使用以下指令进行更新,将
TARGET_VERSION替换为需要升级的目标版本。helm upgrade aliyun-loongcollector-cluster-insight aliyun-prometheus/loongcollector-cluster-insight <TARGET_VERSION>
计费说明
接入组件会采集 Kubernetes 实体及指标相关数据,实体数据写入不计费,自建 Kubernetes 集群接入Prometheus 的指标都属于付费自定义指标,将按可观测监控 Prometheus 版计费。
常见问题
Q1: 如果忘记先删除 ClusterAliyunPipelineConfig CR 怎么办?
如果卸载了 Helm Chart 后,但 ClusterAliyunPipelineConfig 资源仍然存在,可以手动删除 finalizer:
# 1. 编辑资源,移除 finalizer
kubectl edit clusteraliyunpipelineconfig custom-kubernetes-[CLUSTER_ID]-entity-collector -n cms-monitoring
# 2. 在编辑器中,删除 finalizers 部分的所有内容,保存并退出
# 删除类似以下的内容:
# finalizers:
# - clusteraliyunpipelineconfig.finalizers.telemetry.alibabacloud.com
# 3. 然后再次尝试删除资源
kubectl delete clusteraliyunpipelineconfig custom-kubernetes-[CLUSTER_ID]-entity-collector -n cms-monitoring
# 4. 验证
kubectl get clusteraliyunpipelineconfig -n cms-monitoringQ2: 如果集群网络不通阿里云云监控内网网段,导致数据无法接入怎么办?
基于 PrometheusRules CR 的告警同步功能要求您的集群打通云监控内网网段。若您的集群无法打通云监控内网网段,可以关闭告警同步功能。
在安装脚本中添加--set operator.enableAlertRule=false即可,如:
# 添加阿里云 Prometheus 官方 Helm 仓库
helm repo add aliyun-prometheus https://prometheus-agent-repo-chart.cn-beijing.cr.aliyuncs.com/loongcollector/loongcollector-cluster-insight
helm repo update
# 执行数据采集器安装
helm install aliyun-loongcollector-cluster-insight aliyun-prometheus/loongcollector-cluster-insight --create-namespace -n cms-monitoring \
--set operator.enableAlertRule=false \ # 加入该配置关闭告警同步
--set-string aliUid="" \
--set accessKeyID="" \
--set accessKeySecret="" \
--set clusterID="" \
--set clusterName="" \
--set workspace="" \
--set operator.prometheus.prometheusInstanceID="" \
--set region="" \
--set entityCollector.projectName=""组件说明
LoongCollector Cluster Insight 组件是一个用于容器洞察的 Helm Chart,它能够收集 Kubernetes 集群的指标和实体信息,并将数据发送到阿里云监控 2.0。
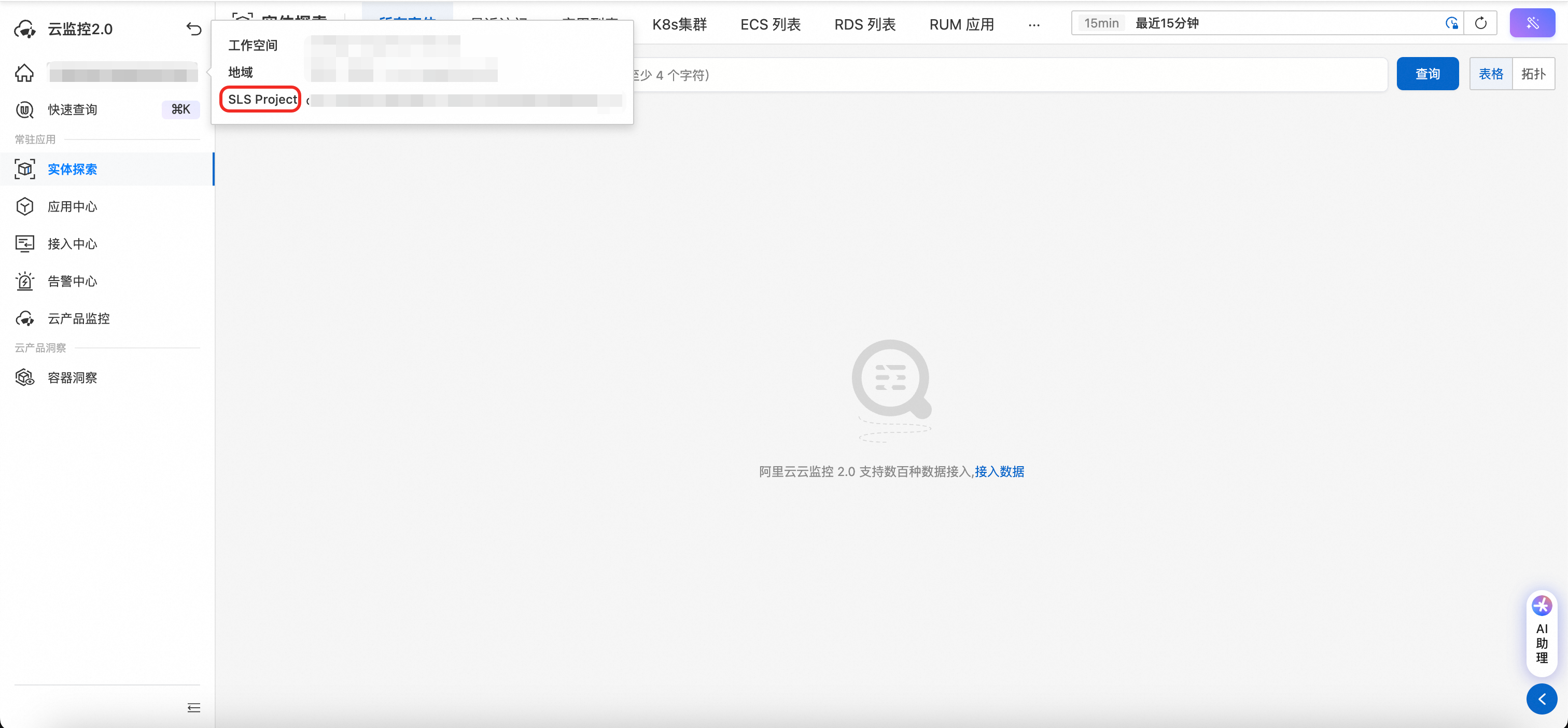
获取工作空间实体库 Project
进入云监控 2.0 工作空间,在左上角展开工作空间详细信息,其中 SLS Project 即为实体库 Project
获取 Helm Repo
helm repo add aliyun-prometheus https://prometheus-agent-repo-chart.cn-beijing.cr.aliyuncs.com/loongcollector/loongcollector-cluster-insight
helm repo update安装 Helm Chart
创建 values.yaml 文件,复制以下内容
aliUid: <ALIYUN_UID>
accessKeyID: <ACCESS_KEY_ID>
accessKeySecret: <ACCESS_KEY_SECRET>
clusterID: <CLUSTER_ID>
clusterName: <CLUSTER_NAME>
workspace: <WORKSPACE>
operator:
prometheus:
prometheusInstanceID: <PROMETHEUS_INSTANCE_ID>
region: <ALIYUN_REGION>
entityCollector:
projectName: <ENTITY_COLLECTOR_PROJECT>使用以下指令安装 Helm Chart
helm install [RELEASE_NAME] aliyun-prometheus/loongcollector-cluster-insight --create-namespace -n [NAMESPACE] -f values.yaml核心组件
LoongCollector
loongcollector-cluster 基于 LoongCollector,是一款面向云原生环境的开源监控数据采集器,旨在为各类基础设施、应用和服务提供统一、高效、可扩展的指标采集能力。
主要特性
多数据源支持:可采集 Kubernetes、Linux 主机、容器运行时、数据库、中间件等多种来源的指标。
PodMonitor / ServiceMonitor 集成:兼容 Prometheus Operator,可直接通过 CRD 管理采集目标。
轻量高效:针对高并发场景进行了优化,减少资源占用,适合边缘节点与核心控制面部署。
灵活配置:支持通过 YAML/ConfigMap 自定义采集规则、标签重写、抓取间隔等参数。
安全传输:支持 HTTP/HTTPS、证书认证及数据压缩,保障采集链路的安全与稳定。
可扩展插件体系:方便开发者接入自定义数据源或处理逻辑。
其他组件
该 Chart 除了核心的 LoongCollector 核心组件提供基础的数据采集能力外,还额外提供了以下组件:
entity-collector: 阿里云监控 2.0 容器洞察的核心组件之一(默认启用)
集群拓扑采集: 自动发现和采集 Kubernetes 集群中的各种资源实体信息
实体关系映射: 构建集群内资源之间的依赖关系和拓扑结构
实时状态同步: 持续监控资源状态变化并实时上报到云监控 2.0
多维度信息整合: 整合节点、Pod、Service、Deployment 等多维度资源信息
node-exporter: 节点指标采集器(默认启用)
作用:采集 Kubernetes 集群中每个节点的系统指标,包括 CPU、内存、磁盘、网络等硬件资源使用情况
部署方式:DaemonSet,确保每个节点都有一个 node-exporter Pod
指标类型:节点级指标(如 node_cpu_seconds_total、node_memory_MemTotal_bytes 等)
kube-state-metrics: Kubernetes 对象状态指标采集器(默认启用)
作用:采集 Kubernetes 集群中各种资源对象的状态指标,如 Pod、Deployment、Service 等的数量和状态
部署方式:Deployment,通常单副本部署
指标类型:Kubernetes 对象指标(如 kube_pod_info、kube_deployment_status_replicas 等)
gpu-exporter: GPU 指标采集器(默认启用)
作用:采集集群中 GPU 卡的使用情况,包括 GPU 利用率、显存使用量、温度等指标
部署方式:DaemonSet,仅在具有 GPU 的节点上运行
指标类型:GPU 相关指标(如 DCGM_FI_DEV_GPU_UTIL、DCGM_FI_DEV_FB_USED 等)
适用场景:使用 GPU 进行机器学习、AI 计算等场景的集群
参数说明
必填参数
以下参数为必填参数,省略将无法正常安装 Helm Chart
配置范围 | Key | 类型 | 说明 | 示例值 |
全局配置 | workspace | string | 云监控 2.0 工作空间名称 | my-workspace |
clusterName | string | 集群名称(自定义) | my-k8s-cluster | |
clusterId | string | 集群标识(自定义) | c1234567890abcdef | |
accessKeyId | string | 阿里云 AccessKey ID | LTAI5txxxxxxxxxxxxx | |
accessKeySecret | string | 阿里云 AccessKey Secret | xxxxxxxxxxxxxxxxxxxxxxxx | |
aliUid | string | 阿里云用户 ID | 1234567890123456 | |
region | string | 工作空间地域 | cn-hangzhou | |
loongcollector-operator 配置 | operator.prometheus.prometheusInstanceID | string | Prometheus 实例 ID | rw-p1234567890abcdef |
entity-collector 配置 | entityCollector.projectName | string | 工作空间对应的实体库 Project 名称 | cms-my-workspace-v9h9awniowbzg |
全局配置(可选)
Key | 类型 | 默认值 | 详情 |
enableDefaultScrapeConfigs | boolean | true | 是否启用默认采集配置 |
scrapeInterval | string | 30s | 全局采集间隔配置 |
cadvisorNodeExporterScrapeInterval | string | 15s | cAdvisor和node-exporter专用采集间隔 |
net | string | Internet | 网络类型,可选值 |
enableDefaultScrapeConfigs | boolean | true | 是否启用默认采集配置 |
scrapeInterval | string | 30s | 全局采集间隔配置 |
entity-collector 配置
可以通过配置entityCollector.enabled=false禁用 entity-collector。注意,禁用 entity-collector 后将无法采集集群实体信息,因此无法体验容器洞察的完整功能,不建议禁用。
Key | 类型 | 默认值 | 详情 |
entityCollector.enabled | boolean | true | 是否启用 entity-collector(建议启用) |
entityCollector.machineGroup | string | custom-kubernetes-{{ .Values.clusterID}}-entity-collector | 机器组名称 |
entityCollector.image.repository | string | registry-cn-hangzhou.ack.aliyuncs.com/acs/loongcollector | |
entityCollector.image.tag | string | v3.1.6.0-96c0f2a-aliyun |
kube-proxy 配置
Key | 类型 | 默认值 | 详情 |
kubeProxy.image.pullPolicy | string | IfNotPresent | |
kubeProxy.image.repository | string | prometheus-agent-repo-registry.cn-beijing.cr.aliyuncs.com/loongcollector/kube-rbac-proxy | |
kubeProxy.image.tag | string | v0.11.0-703dc7e4-aliyun | |
kubeProxy.resources.limits.cpu | string | 20m | CPU限制 |
kubeProxy.resources.limits.memory | string | 128Mi | 内存限制 |
kubeProxy.resources.requests.cpu | string | 10m | CPU请求 |
kubeProxy.resources.requests.memory | string | 32Mi | 内存请求 |
kube-state-metrics 配置
通过配置
kubeStateMetrics.enabled=false可以禁用 kube-state-metrics。注意,禁用kube-state-metrics 后将无法收集 Kubernetes 集群中资源(如 Pod、Deployment、Service 等)的实时状态和元数据。
Key | 类型 | 默认值 | 详情 |
kubeStateMetrics.enabled | boolean | true | 是否启用 kube-state-metrics(建议启用) |
kubeStateMetrics.port | string | 8080 | 指标暴露端口 |
kubeStateMetrics.image.pullPolicy | string | Always | |
kubeStateMetrics.image.repository | string | prometheus-agent-repo-registry.cn-beijing.cr.aliyuncs.com/loongcollector/kube-state-metrics | |
kubeStateMetrics.image.tag | string | v2.3.0-33ccbe6-aliyun | |
kubeStateMetrics.resources.limits.cpu | string | 250m | CPU限制 |
kubeStateMetrics.resources.limits.memory | string | 512Mi | 内存限制 |
kubeStateMetrics.resources.requests.cpu | string | 250m | CPU请求 |
kubeStateMetrics.resources.requests.memory | string | 512Mi | 内存请求 |
kubeStateMetrics.serviceAccountName | string | cms-kube-state-metrics |
gpu-exporter 配置
通过配置
gpuExporter.enabled=false可以禁用 gpu-exporter。注意,禁用 gpu-exporter 后将无法收集 GPU 资源的使用状态(如显存占用、GPU 温度、计算负载等),影响对 GPU 引擎或深度学习任务的性能监控。如果您的集群没有 GPU 节点,可以禁用。
Key | 类型 | 默认值 | 详情 |
gpuExporter.enabled | boolean | true | 是否启用 gpu-exporter |
gpuExporter.port | int | 9445 | 指标暴露端口 |
gpuExporter.image.pullPolicy | string | Always | |
gpuExporter.image.repository | string | registry-cn-hangzhou.ack.aliyuncs.com/acs/gpu-prometheus-exporter | |
gpuExporter.image.tag | string | v3.3.5-1.8.2-2.6.6-3601af6-aliyun | |
gpuExporter.resources.limits.cpu | string | 250m | CPU限制 |
gpuExporter.resources.limits.memory | string | 512Mi | 内存限制 |
gpuExporter.resources.requests.cpu | string | 250m | CPU请求 |
gpuExporter.resources.requests.memory | string | 512Mi | 内存请求 |
node-exporter 配置
可以通过配置
nodeExporter.enabled=false禁用 node-exporter。注意,禁用 node-exporter 后将无法收集主机级别的硬件和操作系统指标(如 CPU 使用率、内存、磁盘 I/O、网络流量等)。
Key | 类型 | 默认值 | 详情 |
nodeExporter.enabled | boolean | true | 是否启用 node-exporter(建议启用) |
nodeExporter.port | int | 19100 | 指标暴露端口 |
nodeExporter.image.pullPolicy | string | IfNotPresent | |
nodeExporter.image.repository | string | prometheus-agent-repo-registry.cn-beijing.cr.aliyuncs.com/loongcollector/node-exporter | |
nodeExporter.image.tag | string | v0.17.0-slim | |
nodeExporter.resources.limits.cpu | string | 1000m | CPU限制 |
nodeExporter.resources.limits.memory | string | 1024Mi | 内存限制 |
nodeExporter.resources.requests.cpu | string | 10m | CPU请求 |
nodeExporter.resources.requests.memory | string | 128Mi | 内存请求 |
nodeExporter.serviceAccountName | string | cms-node-exporter |
loongcollector-operator 配置
Key | 类型 | 默认值 | 详情 |
operator.enableAlertRule | bool | true | 是否启用 PrometheusRules 告警同步 |
operator.service.type | string | ClusterIP | |
operator.service.protocol | string | TCP | |
operator.service.port | int | 8888 | |
operator.webhookService.type | string | ClusterIP | |
operator.webhookService.protocol | string | TCP | |
operator.webhookService.port | int | 9443 | |
operator.admissionRegistration.failurePolicy | string | Ignore | |
operator.admissionRegistration.onlyLabel | boolean | false | |
operator.image.pullPolicy | string | Always | |
operator.image.repository | string | registry-cn-hangzhou.ack.aliyuncs.com/acs/loongcollector-operator | |
operator.image.tag | string | v0.0.1-rc.1 | |
operator.prometheus.metricStore | string | ||
operator.prometheus.project | string | ||
operator.resources.limits.cpu | string | 1 | CPU限制 |
operator.resources.limits.memory | string | 1024Mi | 内存限制 |
operator.resources.requests.cpu | string | 100m | CPU请求 |
operator.resources.requests.memory | string | 128Mi | 内存请求 |
operator.serviceAccountName | string | cms-loongcollector-operator |