
本文为您介绍如何在AI助手中配置并使用语音和图片的识别功能,帮助您更高效地处理音视觉内容。
前提条件
已经创建AI助手并完成web页面集成。具体操作,请参见创建AI助手。
开启图片识别
进入AppFlow-AI助手页面。选择目标AI助手,在AI助手详情页的集成页签中,单击web页面集成。
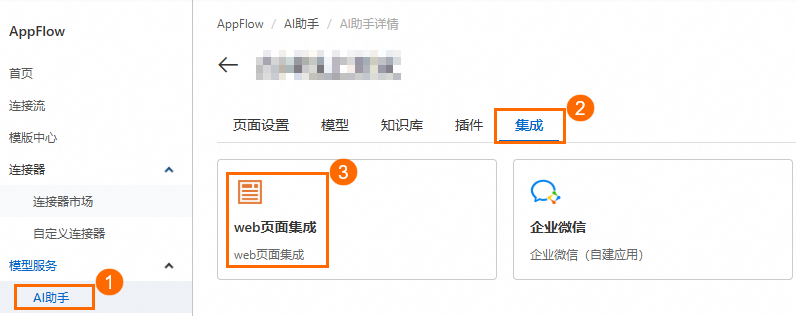
单击需要配置的集成ID/名称,在消息设置区域中勾选是否支持图片选项,然后单击提交以保存设置。

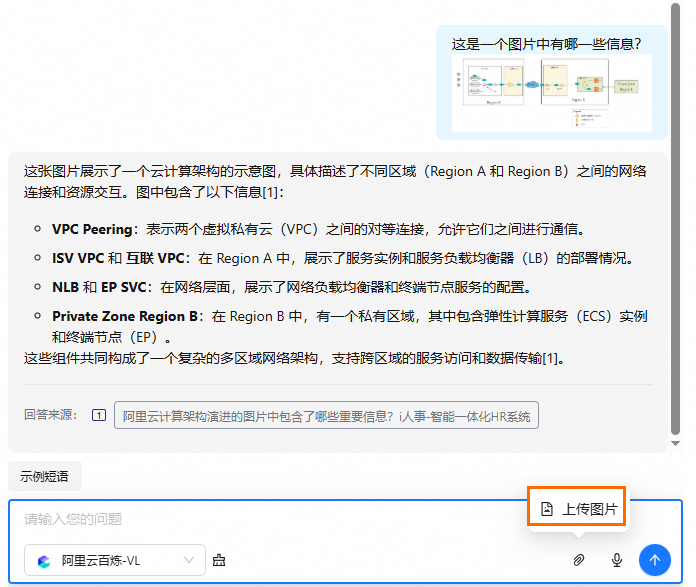
测试图片识别功能。
本节以访问独立部署页面为例,单击上传图片,上传完成后在对话框中输入问题。
开启语音识别
步骤一:创建阿里云智能语音交互语音识别项目
进入阿里云智能语音交互首页并开通服务。
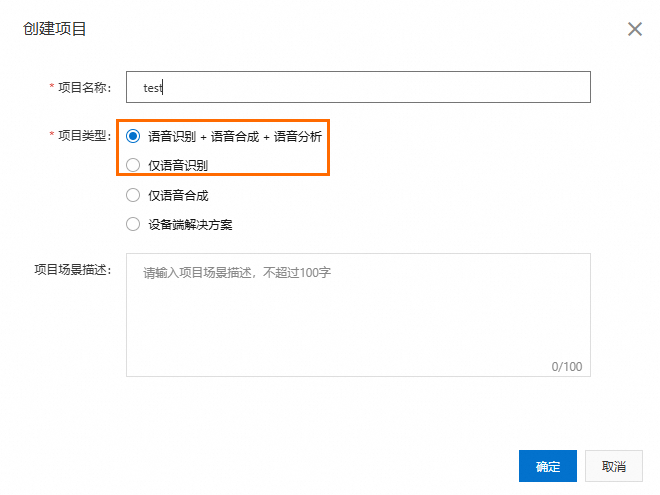
进入阿里云智能语音交互-全部项目,单击创建项目。
在对话框中填写项目名称,项目类型选择为语音识别+语音合成+语音分析或仅语音识别,单击确定。
在跳转的项目详情页面,单击复制保存appkey,同时可修改语音识别模型的配置信息以满足不同需求。具体操作,请参见管理项目。

步骤二:在AppFlow中配置阿里云智能语音交互
进入AppFlow-AI助手页面,选择目标AI助手。
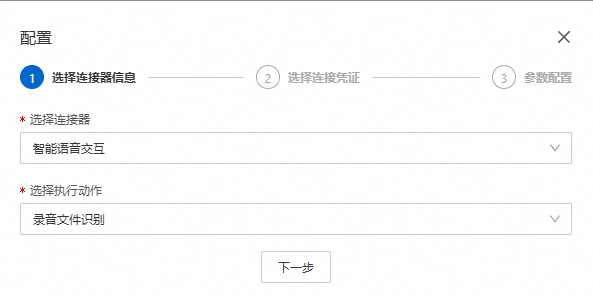
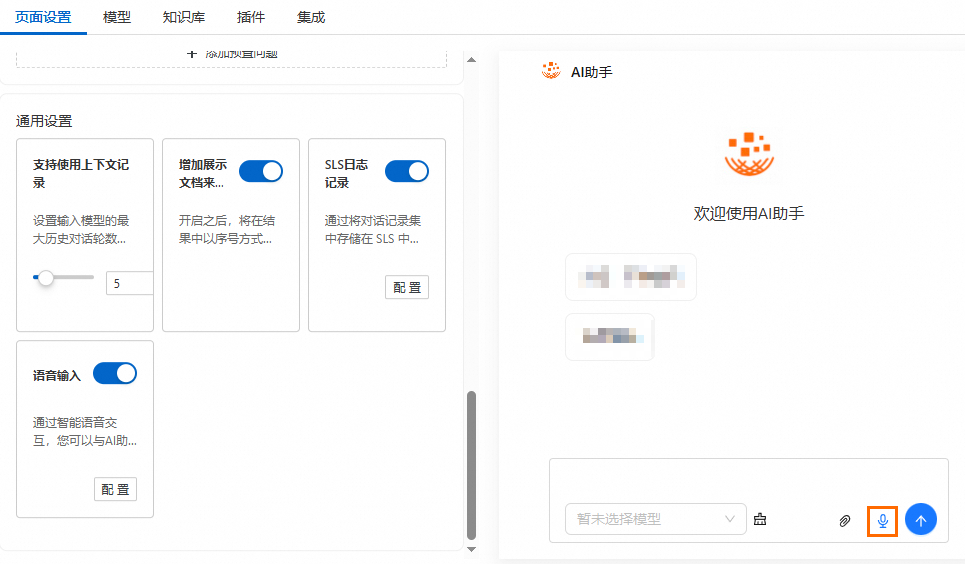
在AI助手详情的通用设置区域下,开启语音输入并单击配置。
在对话框中选择连接器为智能语音交互,选择执行动作为录音文件识别,单击下一步。
设置智能语音交互凭证。
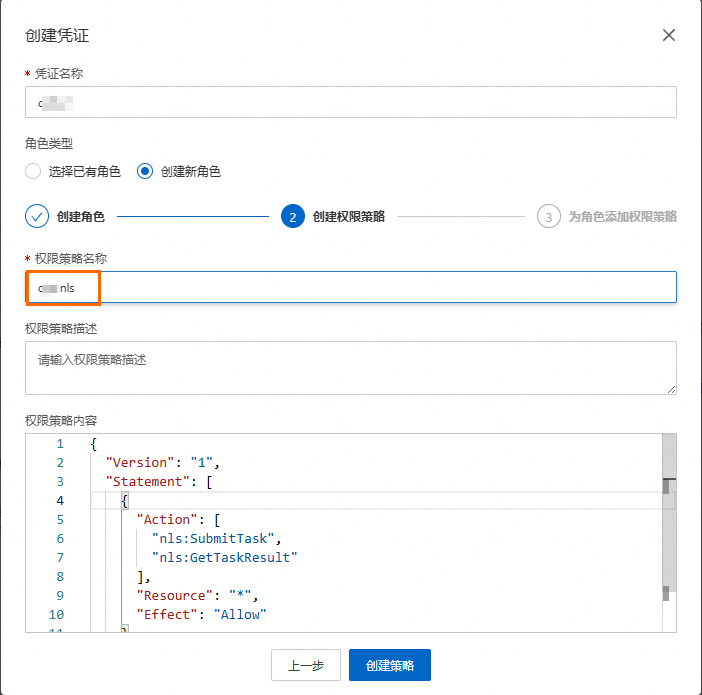
单击添加新凭证,输入凭证名称将角色类型选择创建新角色,输入角色名称并单击创建角色。

设置权限策略名称,单击创建策略。
说明该策略针对阿里云智能语音交互服务(NLS) ,允许角色调用相关API来提交任务和获取任务结果。
单击授权。
选择新创建的链接凭证,单击下一步。
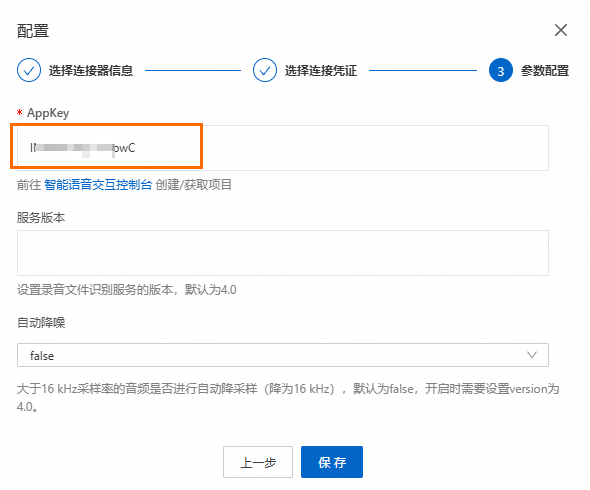
在参数配置中将步骤一中保存的appkey,填入AppKey并单击保存。
此时在页面设置右侧的预览页面中,可看到已经支持语音输入。
步骤三:在web页面集成中开启语音支持
进入AppFlow-AI助手页面。在AI助手详情的集成页签中,单击web页面集成。
单击需要配置的集成ID/名称,在消息设置区域中勾选是否支持语音选项,然后单击提交以保存设置。

测试语音交互功能。
本节以访问独立部署页面为例,单击对话框中的话筒图标进行语音输入。
