
阿里云计算巢提供了Qwen3系列模型的一键部署方案,最快5分钟即可私有部署Qwen3系列模型,如Qwen3-235B、Qwen3-32B模型等。您无需关心模型部署运行的标准环境与底层云资源编排,仅需填写几个参数即可享受企业专属模型的推理体验。本文为您介绍如何通过计算巢一键部署Qwen3系列模型。
什么是Qwen3
模型列表是千问系列最新推出的超大规模语言模型,基于万亿参数级架构构建,深度融合多模态数据与强化学习技术。其具备卓越的自然语言理解与生成能力,支持中英双语及多种编程语言交互,可高效完成文本创作、逻辑推理、代码生成等复杂任务。
计费说明
计算巢平台不收取平台使用费,只收取服务部署时使用的阿里云云资源的费用。本示例部署费用包含:
所选GPU云服务器的实例规格
块存储
公网带宽
RAM账号所需权限
部署服务实例时需要对部分阿里云资源进行访问和创建操作。因此您的账号需要包含如下资源的权限。若您使用RAM用户创建服务实例,需要在创建服务实例前为RAM用户添加相应资源权限。
权限策略名称 | 备注 |
AliyunECSFullAccess | 管理云服务器服务(ECS)的权限 |
AliyunVPCFullAccess | 管理专有网络(VPC)的权限 |
AliyunROSFullAccess | 管理资源编排服务(ROS)的权限 |
AliyunComputeNestUserFullAccess | 管理计算巢服务(ComputeNest)的用户侧权限 |
操作步骤
单击LLM推理服务-ECS版进入实例创建页面。
在创建服务实例界面,配置服务实例信息。本节仅展示关键参数,其他参数按需填写。
参数
说明
选择模板
请选择单机版。
模型系列
请选择Qwen。
模型名称
目前支持Qwen3-235B-A22B,Qwen3-32B,Qwen3-8B。本节以Qwen3-32B为例。
实例类型
本节以ecs.gn7i-8x.16xlarge为例。若部署Qwen3-235B-A22B模型,需要ecs.ebmgn8v.48xlarge实例规格,如需使用请提交工单申请。
选择是否开始公网访问
可根据需求选择是否开启公网,如果您需要进行性能测试,请开启公网访问。

单击下一步:确认订单。确认服务实例信息与价格预览,单击立即创建。
说明由于模型不同,创建所需的时间也不同,请您耐心等待。
测试服务实例。
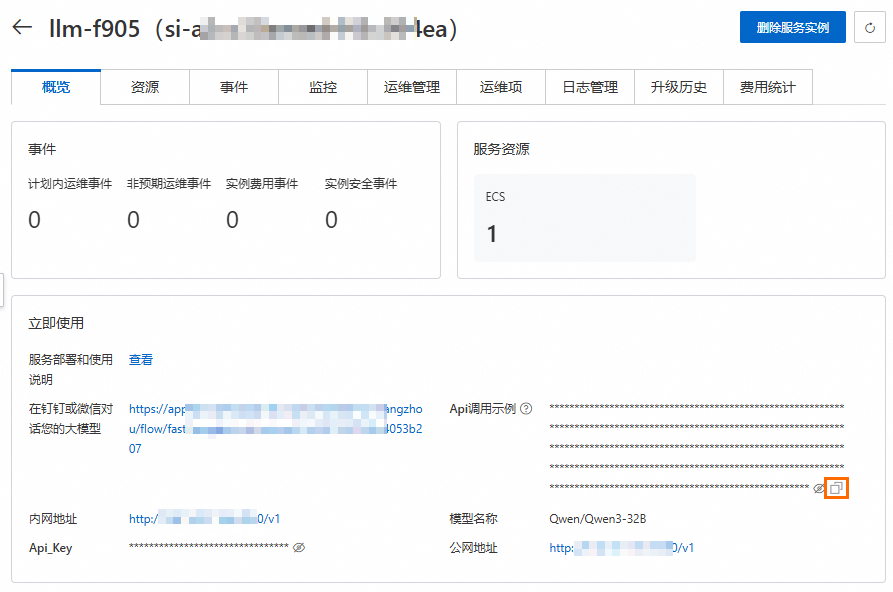
访问计算巢-服务实例页面,单击您创建的服务实例。
在概览页签的立即使用区域中,复制API调用示例。
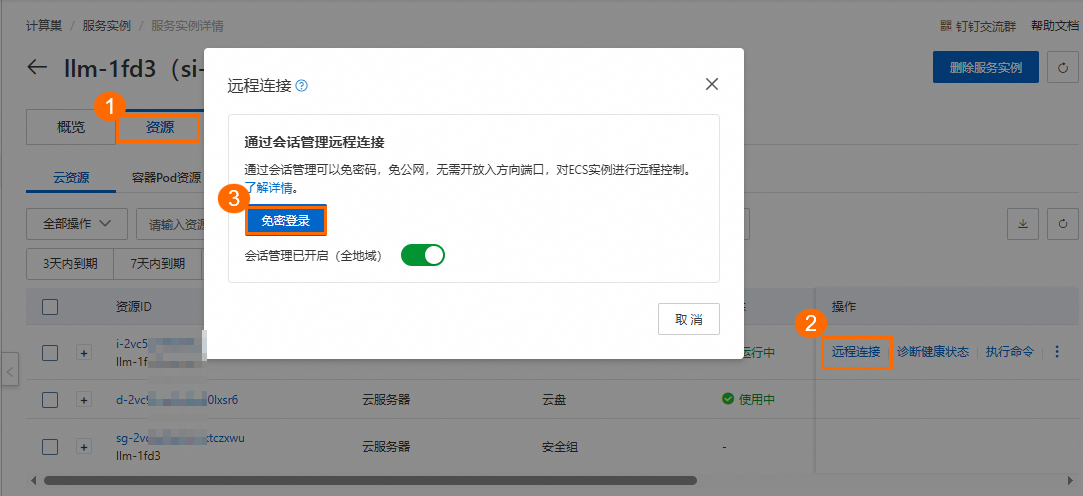
在资源页签中,单击ECS实例的远程连接。在弹窗中单击免密登录,登录ECS实例。
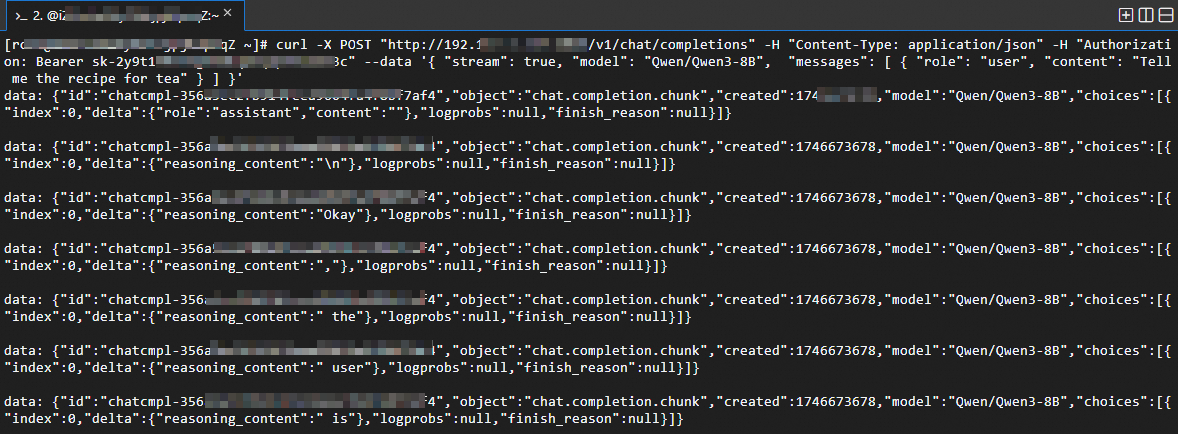
粘贴API调用示例,并按Enter键即可。
默认为流式返回,如下图所示。
 说明
说明若不希望流式输出,可将API调用示例中的
stream修改为false,若您提问内容较为复杂,非流式输出的时间可能会较长,请您耐心等待。
其他操作
查询模型部署参数
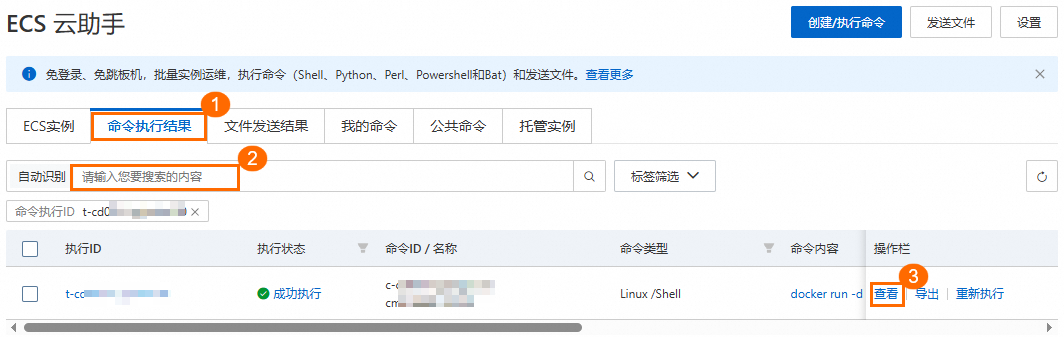
在日志管理页签中,找到资源类型为ALIYUN::ECS::RunCommand,复制并单击关联ID,进入ECS 云助手控制台。
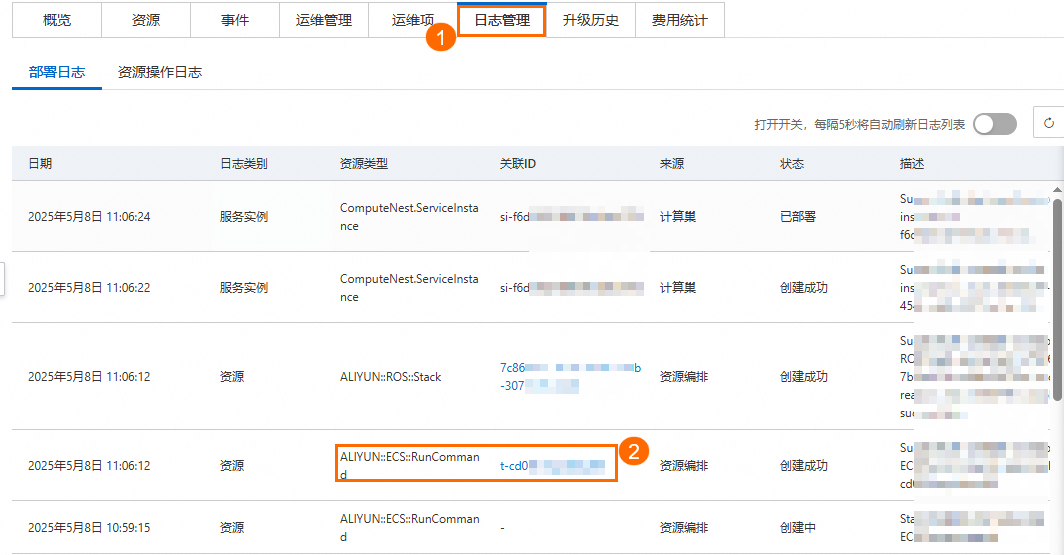
在ECS 云助手控制台的命令执行结果页签中,粘贴关联ID并搜索。

单击操作栏中的查看,在执行信息页签的命令内容中,您可找到模型部署参数。
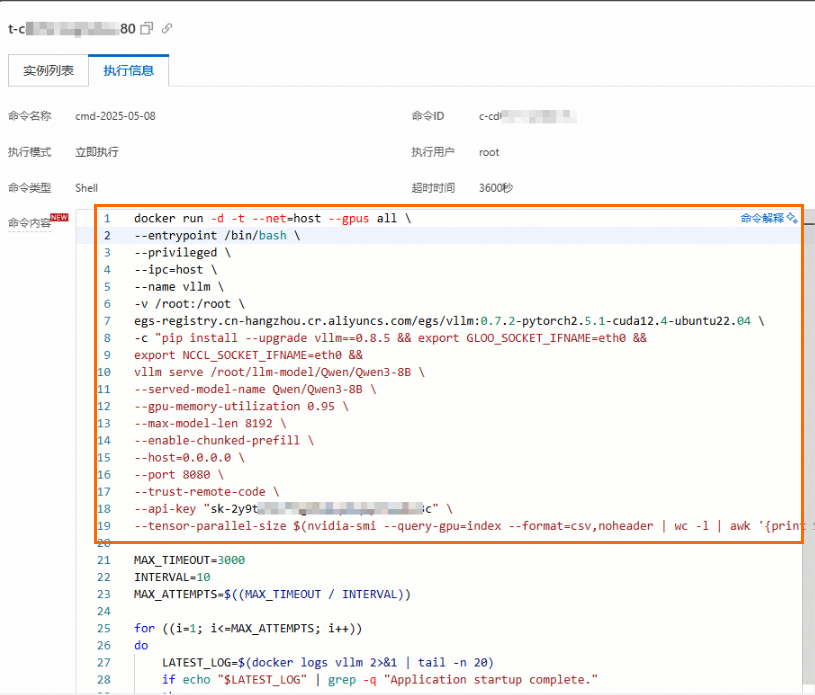
自定义参数部署模型
如果您有使用自定义模型部署参数的需求,可以在部署服务实例后,按照如下操作步骤进行修改并重新部署。
在资源页签中,单击ECS实例的远程连接。在弹窗中单击免密登录,进入ECS实例。
执行下面的命令,停止模型服务。
警告停止服务会导致业务中断,建议您在非业务高峰期时执行该操作。
sudo docker stop vllm sudo docker rm vllm获取模型部署命令,根据需求修改并在命令行中执行。
下方分别是vllm与sglang部署的参考脚本,您可参考注释修改实际执行的脚本。
说明重新部署大约需要10分钟,请您耐心等待。
vllm部署
sudo docker run -d -t --net=host \ --gpus all \ # 允许容器访问所有可用的GPU设备 --entrypoint /bin/bash \ --privileged \ --ipc=host \ --name vllm \ # 给容器指定一个易于识别的名字vllm -v /root:/root \ 将宿主机的/root目录挂载到容器内的/root,实现数据共享 egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.7.2-pytorch2.5.1-cuda12.4-ubuntu22.04 \ -c "pip install --upgrade vllm==0.8.2 && # 可自定义版本,如 pip install vllm==0.7.1 export GLOO_SOCKET_IFNAME=eth0 && # 采用vpc进行网络通信所需环境变量,勿删改 export NCCL_SOCKET_IFNAME=eth0 && # 采用vpc进行网络通信所需环境变量,勿删改 vllm serve /root/llm-model/${ModelName} \ # 使用服务启动模型 --served-model-name ${ModelName} \ # 指定服务中使用的模型名称 --gpu-memory-utilization 0.98 \ # Gpu占用率,过高可能导致其他进程触发OOM。取值范围:0~1 --max-model-len ${MaxModelLen} \ # 模型最大长度,取值范围与模型本身有关。 --enable-chunked-prefill \ --host=0.0.0.0 \ --port 8080 \ --trust-remote-code \ --api-key "${VLLM_API_KEY}" \ # 可选,设置API密钥,如不需要可去掉。 --tensor-parallel-size $(nvidia-smi --query-gpu=index --format=csv,noheader | wc -l | awk '{print $1}')" # 使用GPU数量,默认使用全部GPU。sglang部署
#下载包含sglang的公开镜像 sudo docker pull egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.7.2-sglang0.4.3.post2-pytorch2.5-cuda12.4-20250224 sudo docker run -d -t --net=host \ --gpus all \ # 允许容器访问所有可用的GPU设备 --entrypoint /bin/bash \ --privileged \ --ipc=host \ --name llm-server \ -v /root:/root \ egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.7.2-sglang0.4.3.post2-pytorch2.5-cuda12.4-20250224 \ -c "pip install sglang==0.4.3 && # 可自定义版本 export GLOO_SOCKET_IFNAME=eth0 && # 采用vpc进行网络通信所需环境变量,勿删改 export NCCL_SOCKET_IFNAME=eth0 && # 采用vpc进行网络通信所需环境变量,勿删改 python3 -m sglang.launch_server \ --model-path /root/llm-model/${ModelName} \ # 使用服务启动模型 --served-model-name ${ModelName} \ # 指定服务中使用的模型名称 --tp $(nvidia-smi --query-gpu=index --format=csv,noheader | wc -l | awk '{print $1}')" \ # 使用GPU数量,默认使用全部GPU。 --trust-remote-code \ --host 0.0.0.0 \ --port 8080 \ --mem-fraction-static 0.9 # Gpu占用率,过高可能导致其他进程触发OOM。取值范围:0~1执行成功,如下如所示。
执行下面的命令,查看模型服务是否运行。执行若结果如下图所示,则模型服务重新部署成功。
sudo docker ps sudo docker logs vllm
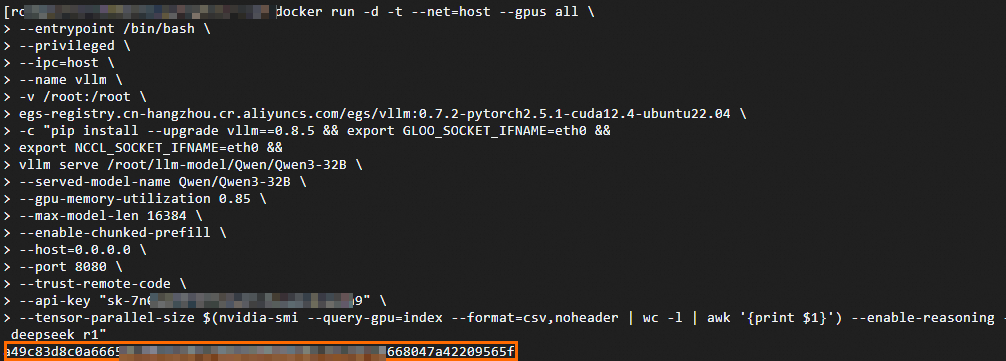

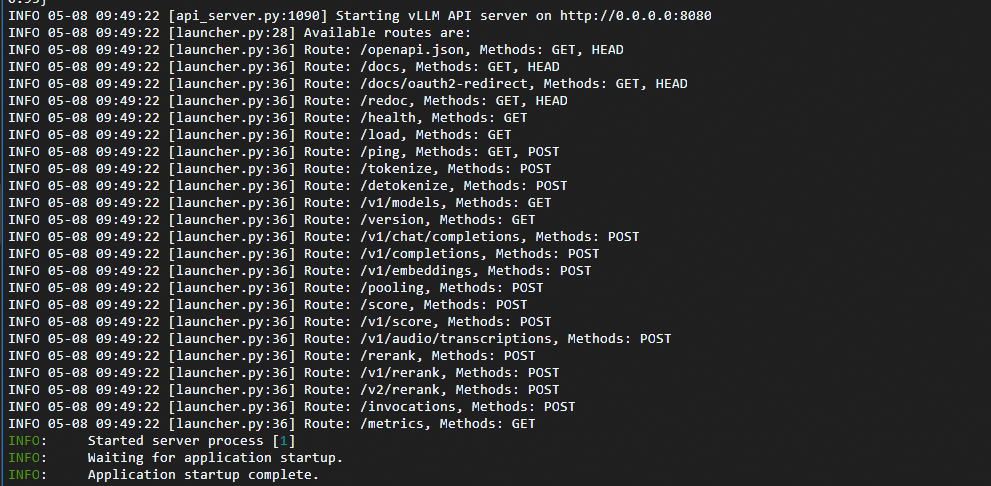
性能测试参考
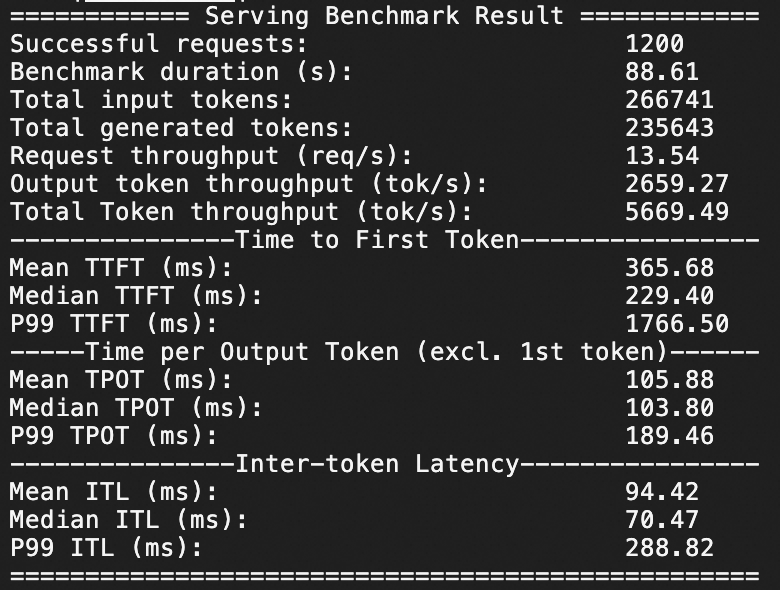
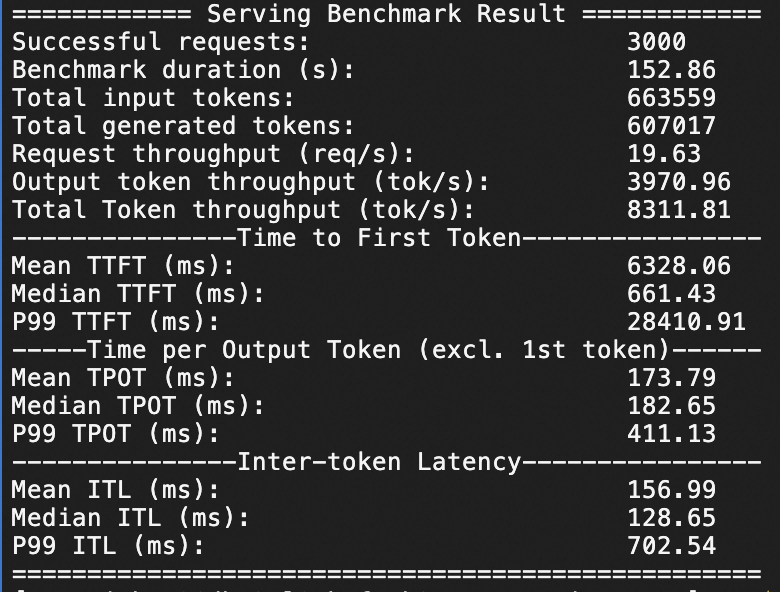
Qwen3-235B-A22B压测
本针对Qwen3-235B-A22B在ecs.ebmgn8v.48xlarge实例规格下,分别测试QPS为20、50情况下模型服务的推理响应性能,压测持续时间均为1分钟。
QPS为20,1分钟1200个问答请求。
QPS为50,1分钟3000个问答请求。
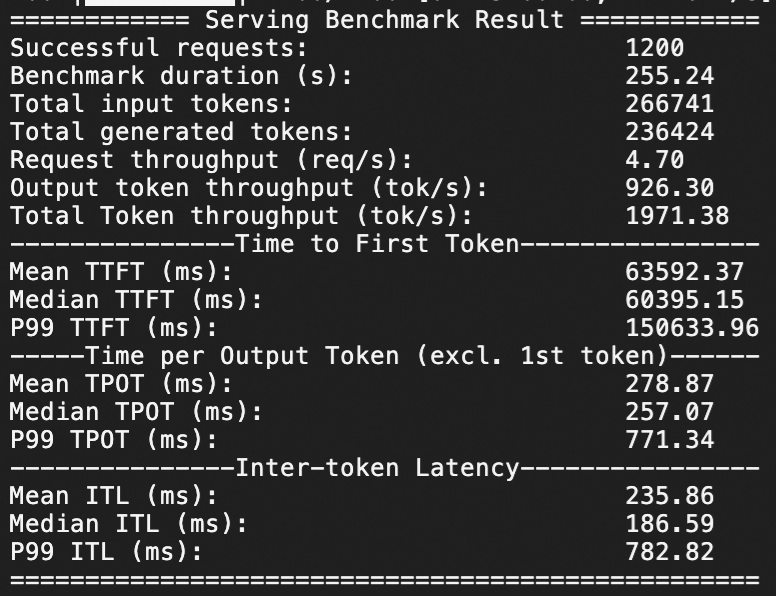
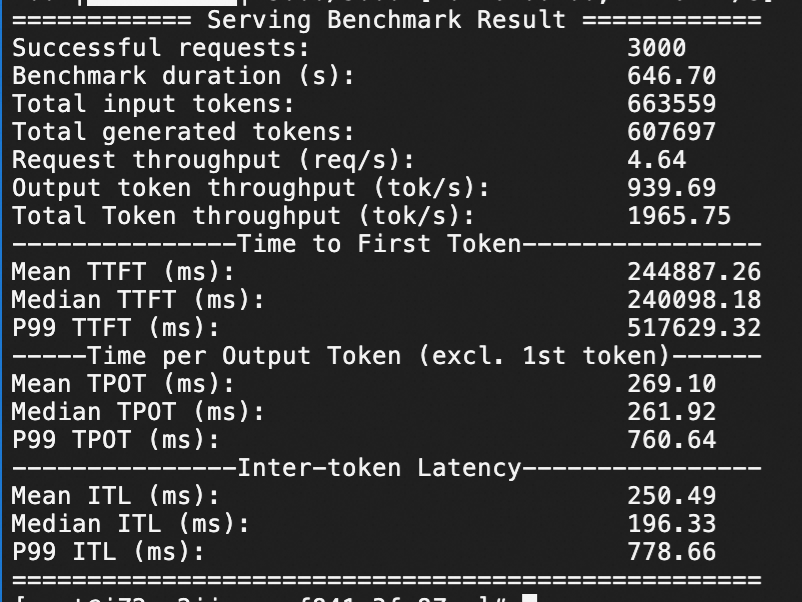
Qwen3-32B压测
针对Qwen3-32B在ecs.gn7i-8x.16xlarge实例规格下,分别测试QPS为20、50情况下模型服务的推理响应性能,压测持续时间均为1分钟。
QPS为20,1分钟1200个问答请求。
QPS为50,1分钟3000个问答请求。
若希望了解压测过程,请参见压测过程说明。