阿里云容器计算服务ACS支持AHPA(Advanced Horizontal Pod Autoscaler)弹性能力。AHPA可以根据Prometheus的历史数据进行学习和分析,提前预测未来的资源需求,并据此动态调整Pod副本数量,确保在业务高峰到来之前完成资源的扩容和预热操作,从而提高系统的响应速度和稳定性。同时,当预测到业务低谷时,也会适时缩容以节省资源成本。
背景信息
AHPA Controller通过接入阿里云的Prometheus可观测监控,获取并处理应用的历史指标数据,这些数据可以成为弹性预测伸缩决策的基础。利用机器学习算法,AHPA Controller可以预测未来24小时内所需的Pod实例数量,特别适用于处理周期性负载变化的场景。通过结合主动预测和被动预测策略,AHPA Controller能够及时调整Pod实例数量,确保资源提前预热,以应对即将到来的流量高峰。这种方式不仅提升了应用的响应速度和整体性能,还帮助用户在保持服务稳定性的同时,有效管理资源成本。更多关于AHPA的信息,请参见AHPA概述。
前提条件
已创建ACS集群。具体操作,请参见创建ACS集群。
已开启Prometheus监控。关于开启Prometheus监控的具体操作,请参见使用阿里云Prometheus监控ACS集群状态。
步骤一:安装AHPA Controller
登录容器计算服务控制台,在左侧导航栏选择集群。
在集群页面,单击目标集群ID,然后在左侧导航栏,选择运维管理 > 组件管理。
在组件管理页面,其他分类中定位到AHPA Controller组件,然后在组件卡片上单击安装,按照页面提示完成组件的安装。
步骤二:配置Prometheus数据源并接入AHPA
登录ARMS控制台。
在左侧导航栏选择,进入可观测监控 Prometheus 版的实例列表页面。
在实例列表页面顶部,选择Prometheus实例所在的地域,单击目标实例名称(与ACS集群同名,实例类型为通用),在左侧导航栏单击设置。在HTTP API地址(Grafana 读取地址)区域记录以下配置项的值。
如果开启了Token,则需要设置访问Token。
查看并记录内网地址(Prometheus URL)。

在ACS集群中设置Prometheus查询地址。
使用以下内容,创建application-intelligence.yaml。
prometheusUrl:ARMS Prometheus访问地址。token:Prometheus的访问Token。
apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-hangzhou-intranet.arms.aliyuncs.com:9443/api/v1/prometheus/da9d7dece901db4c9fc7f5b9c40****/158120454317****/cc6df477a982145d986e3f79c985a****/cn-hangzhou" token: "eyJhxxxxx"说明如需查看AHPA对应的Prometheus监控大盘,您还需要在此ConfigMap中配置以下字段:
prometheus_writer_url:设置Remote Write内网地址。prometheus_writer_ak: 设置阿里云账号的AccessKeyID。prometheus_writer_sk:设置阿里云账号的AccessKeySecret。
执行以下命令,部署application-intelligence。
kubectl apply -f application-intelligence.yaml
接入AHPA。
登录ARMS控制台。
在左侧导航栏选择,进入可观测监控 Prometheus 版的实例列表页面。
在顶部导航栏单击接入其他组件,进入接入中心。然后在搜索框中搜索AHPA,单击AHPA卡片。
接入AHPA组件。
在ACK AHPA页面,选择容器服务集群 > 选择集群,在下拉框中选择要接入组件的集群。
根据以下内容,填写配置信息。单击确定。
配置项
说明
Exporter名称
当前AHPA监控唯一名称。
metrics采集间隔(秒)
监控数据采集时间间隔。
等待接入状态检查步骤完成,单击接入管理。接入完成。
步骤三:部署测试服务
测试服务包括fib-deployment、fib-svc和用于模拟请求峰谷服务fib-loader,同时部署一个HPA资源用于与AHPA进行结果对比。
使用以下内容,创建demo.yaml。
执行以下命令,部署测试服务。
kubectl apply -f demo.yaml
步骤四:声明方式创建AHPA资源
您可以通过提交AdvancedHorizontalPodAutoscaler资源配置弹性策略,具体操作如下。
使用以下内容,创建ahpa-demo.yaml。
apiVersion: autoscaling.alibabacloud.com/v1beta1 kind: AdvancedHorizontalPodAutoscaler metadata: name: ahpa-demo spec: scaleStrategy: observer metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 40 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: fib-deployment maxReplicas: 100 minReplicas: 2 stabilizationWindowSeconds: 300 prediction: quantile: 95 scaleUpForward: 180 instanceBounds: - startTime: "2021-12-16 00:00:00" endTime: "2031-12-16 00:00:00" bounds: - cron: "* 0-8 ? * MON-FRI" maxReplicas: 15 minReplicas: 4 - cron: "* 9-15 ? * MON-FRI" maxReplicas: 15 minReplicas: 10 - cron: "* 16-23 ? * MON-FRI" maxReplicas: 20 minReplicas: 15部分参数说明如下:
参数
是否必选
说明
scaleTargetRef
是
指定目标Deployment。
metrics
是
用于配置弹性Metrics,当前支持CPU、GPU、Memory、QPS、RT等指标。
target
是
目前阈值,例如
averageUtilization: 40表示CPU使用目标阈值为40%。scaleStrategy
否
用于设置弹性伸缩模式。默认值为
observer。auto:由AHPA负责扩缩容。observer:只观察,但不进行真正的伸缩动作。您可以通过这种方式观察AHPA的工作是否符合预期。scalingUpOnly:只扩容不缩容。proactive:只生效主动预测。reactive:只生效被动预测。
maxReplicas
是
最大扩容实例数。
minReplicas
是
最小缩容实例数。
stabilizationWindowSeconds
否
缩容冷却时间,默认300秒。
prediction.quantile
是
预测分位数,业务指标实际值低于设定目标值的概率越大表示越保守。取值范围为0~1,支持两位小数,默认值为0.99。推荐取值范围为0.90~0.99。
prediction. scaleUpForward
是
Pod达到Ready状态所需要的时间(冷启动时间)。
instanceBounds
否
扩缩容时间段实例数边界。
startTime:表示开始时间。
endTime:表示结束时间。
instanceBounds.bounds.cron
否
用于配置定时任务,Cron表达式表示一个时间集合,使用5个空格分隔的字段表示,例如
- cron: "* 0-8 ? * MON-FRI"表示每月星期一到星期五晚上12点到早上8点执行任务。Cron表达式的字段解释如下。更多信息,请参见Cron表达式。
字段名
是否必须
允许的值
允许的特定字符
分(Minutes)
是
0~59
* / , -
时(Hours)
是
0~23
* / , -
日(Day of Month)
是
1~31
* / , – ?
月(Month)
是
1~12或JAN~DEC
* / , -
星期(Day of Week)
否
0~6或SUN~SAT
* / , – ?
说明月(Month)和星期(Day of Week)字段的值不区分大小写,例如
SUN、Sun和sun效果一致。若星期(Day of Week)字段未配置,默认为
*。特定字符说明:
*:表示所有可能的值。/:表示指定数值的增量。,:表示列出枚举值。-:表示范围。?:表示不指定值。
执行以下命令,创建AHPA弹性策略。
kubectl apply -f ahpa-demo.yaml
步骤五:查看预测结果
在接入管理页面单击容器环境页签下的集群名称,组件类型选择ACK AHPA,单击大盘页签,然后单击ahpa-dashboard,您可以查看其监控大盘的详情数据。
Prometheus监控提供的AHPA大盘数据包括CPU使用率、Pod数、预测Pod数等。
CPU使用率&实际POD数大盘展示了当前工作负载(Deployment)的CPU平均利用率以及Pod数量。
CPU实际使用量与预测使用量表示当前工作负载中Pod的CPU使用总量与预测给出的使用量。如果预测给出的使用量大于实际使用量,则表明预测的CPU容量充足。
在Pod趋势区域,您可以查看实际Pod数、推荐Pod数以及主动预测的Pod数。
实际Pod数:当前运行中的Pod数量。
推荐Pod数:AHPA推荐扩缩容Pod数。综合主动预测、被动预测以及边界区间给出的最终Pod数。
主动预测:是基于历史数据,识别出周期性,然后预测出来的Pod数。
由于预测需要历史7天的数据,上述示例部署完成之后,需要运行7天才可以看到预测结果。如果已有线上的应用可以直接在AHPA大盘中选择该应用对应的deployment即可。
本文以弹性伸缩模式配置为observer模式(观察者模式)为例,与使用HPA策略(可作为应用运行实际所需的资源量进行参考)进行对比,观察AHPA预测结果是否符合预期。
下图为AHPA Prometheus大盘的预测示例。
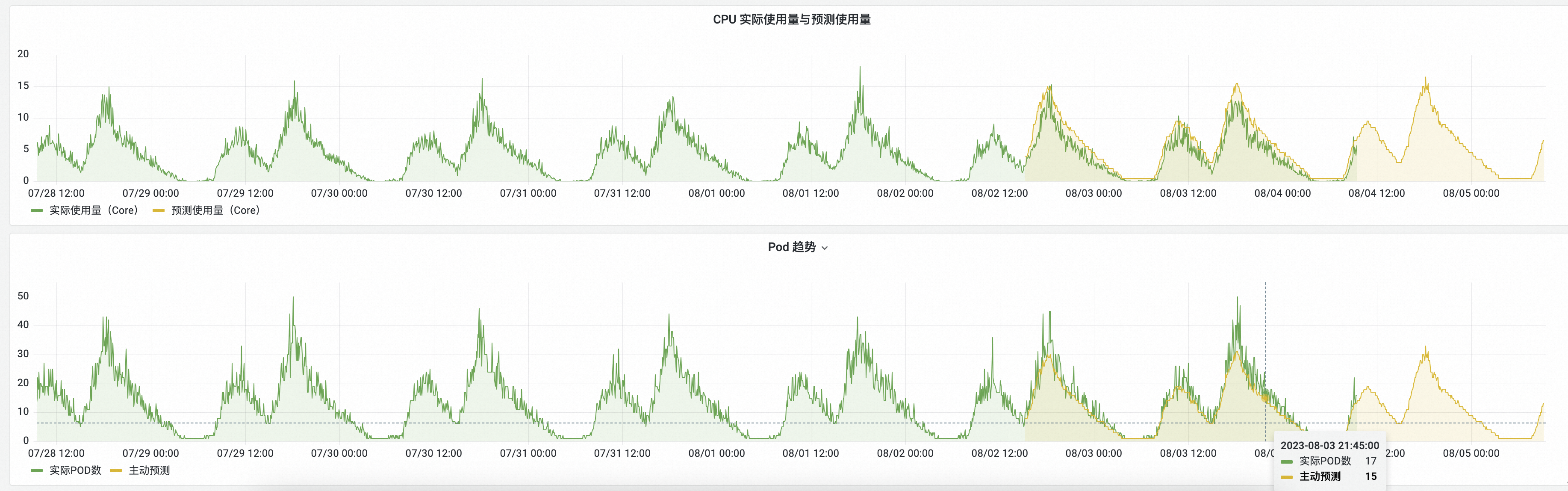
其中:
CPU实际使用量与预测使用量:绿色表示HPA实际的CPU使用量,黄色表示AHPA预测出来的CPU使用量。
黄色曲线大于绿色,表明预测的CPU容量充足。
黄色曲线提前于绿色,表明提前准备好了所需资源。
Pod趋势:绿色表示使用HPA实际的扩缩容Pod数,黄色表示AHPA预测出来的扩缩容Pod数。
黄色曲线小于绿色,表明预测的Pod数量更少。
黄色曲线比绿色更为平滑,表明通过AHPA扩缩容波动更平缓,提升业务稳定性。
通过预测结果表明,弹性预测趋势符合预期。若经过观察后,符合预期,您可以将scaleStrategy设置为auto,由AHPA负责扩缩容。
AHPA关键指标说明
指标名 | 说明 |
ahpa_proactive_pods | 主动预测Pod数。 |
ahpa_reactive_pods | 被动预测Pod数。 |
ahpa_requested_pods | 推荐Pod数。 |
ahpa_max_pods | 最大Pod数。 |
ahpa_min_pods | 最小Pod数。 |
ahpa_target_metric | 目标阈值。 |