
在使用容器计算服务 ACS(Container Compute Service)算力时,您无需深入了解底层硬件,也无需涉及GPU节点管理和配置即可开箱即用。ACS部署简单、支持按量付费,非常适合用于LLM推理任务,可以有效降低推理成本。DeepSeek-R1是一个参数量较大的模型,部分单机GPU无法支持完全加载或高效运行,因此我们推荐使用双容器实例部署方案以及多容器实例分布式推理部署方案,能够更好地支持大规模模型的推理、吞吐量提升和性能保障。本文介绍如何使用ACS算力部署生产可用的满血版DeepSeek分布式推理服务。
背景介绍
DeepSeek-R1模型
vLLM
容器计算服务ACS
LeaderWorkerSet(以下简称LWS)
Fluid
方案介绍
模型切分
DeepSeek-R1模型共有671B参数,单张GPU显存最大一般只有96GB,无法加载全部模型,因此需要将模型切分。本文基于双GPU容器实例分布式部署,采用模型并行(PP=2)和数据并行(TP=8)的切分方式,模型切分示意图如下。
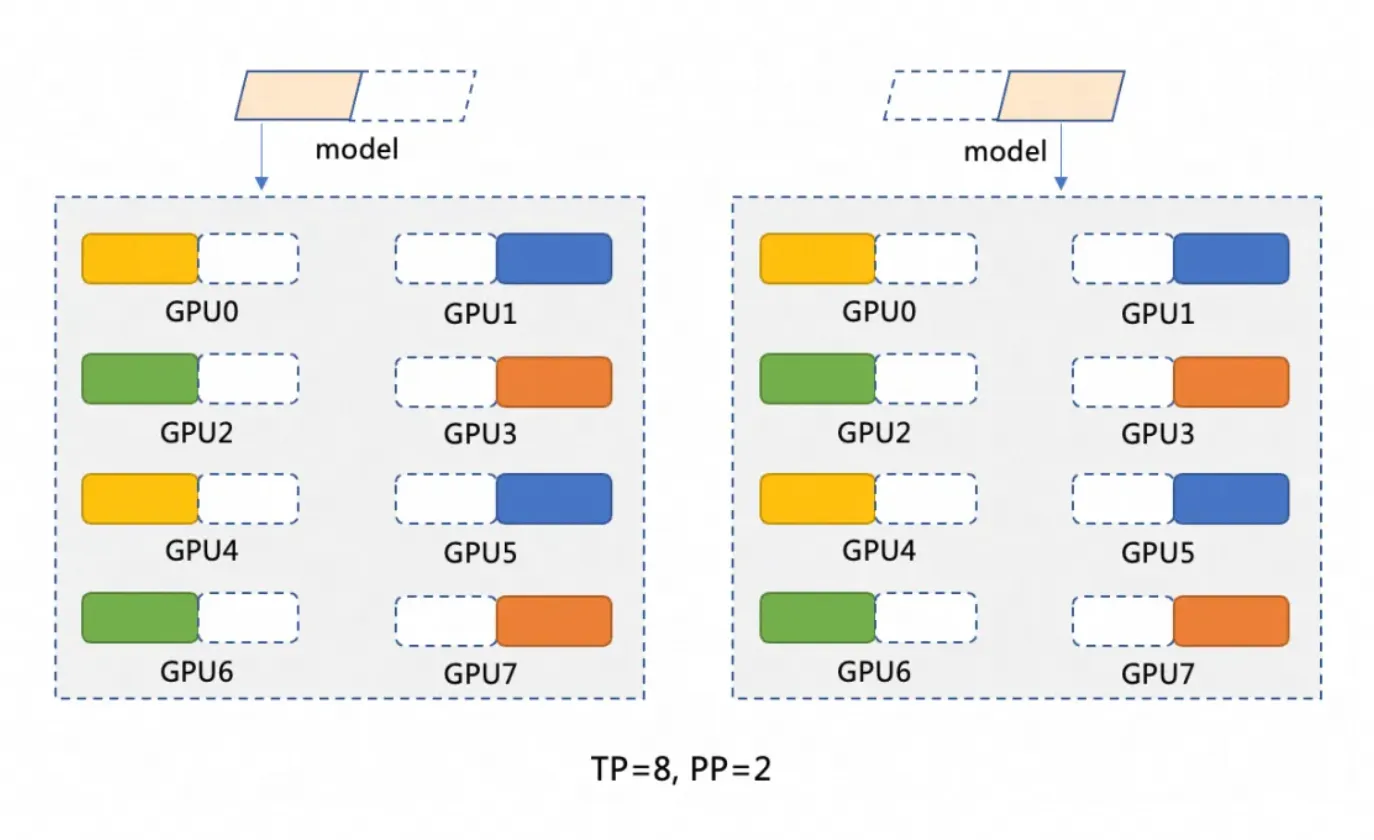
模型并行(PP=2)将模型切分为两个阶段,每个阶段运行在一个GPU容器实例上。例如有一个模型M,我们可以将其切分为M1和M2,M1在第一个GPU容器实例上处理输入,完成后将中间结果传递给M2,M2在第二个GPU容器实例上进行后续操作。
数据并行(TP=8)在模型的每个阶段内(例如M1和M2),将计算操作分配到8个GPU上进行。比如在M1阶段,当输入数据传入时,这些数据将被分割为8份,并分别在8个GPU上同时处理。每个GPU处理一小部分数据,计算获取的结果然后合并。
分布式部署架构
本方案使用ACS快速部署分布式DeepSeek满血版推理服务,选择vLLM + Ray的方式分布式部署DeepSeek-R1模型。同时通过社区LWS来管理DeepSeek在分布式中的Leader-Worker部署模式,通过Fluid在ACS集群中提供分布式缓存提高模型的加载速度。vLLM分别部署在两个ACS GPU Pod实例中,每个Pod有8张GPU卡。每个Pod作为一个Ray Group可以提高吞吐量和并发,每个Ray Group由Ray head和Ray worker组成,可以将模型进行拆分处理。需要注意的是,不同的分布式部署架构会影响YAML中tensor-parallel-size和LWS_GROUP_SIZE等变量的取值。

前提条件
已创建ACS集群,配置的地域和可用区支持GPU资源。具体操作,请参见创建ACS集群。
已使用kubectl连接Kubernetes集群。具体操作,请参见获取集群kubeconfig并通过kubectl工具连接集群。
GPU实例规格和成本预估
ACS GPU双实例或多实例部署中的单个实例推荐使用96 GiB显存的资源配置:GPU:8卡(单卡96G显存), CPU:64 vCPU,Memory:512 GiB。您可以参考规格推荐表和GPU计算类型卡型规格来选择合适的实例规格。关于如何计算ACS GPU实例产生的费用,请参见计费说明。
在使用ACS GPU实例时,实例规格同样遵循ACS Pod规格规整逻辑。
ACS Pod默认提供30 GiB的免费的临时存储空间(EphemeralStorage),本文中使用的推理镜像
registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/vllm:v0.7.2占用约9.5 GiB。如果该存储空间大小无法满足您的需求,您可以自定义增加临时存储空间大小。详细操作,请参见增加临时存储空间大小。
操作步骤
步骤一:准备DeepSeek-R1模型文件
大语言模型因其庞大的参数量,需要占用大量的磁盘空间来存储模型文件,建议您创建NAS存储卷或OSS存储卷来持久化存储模型文件,本文推荐使用OSS。
模型文件下载和上传比较慢,您可以通过提交工单快速将模型文件复制到您的OSS Bucket。
执行以下命令,从ModelScope下载DeepSeek-R1模型。
说明请确认是否已安装git-lfs插件,如未安装可执行
yum install git-lfs或者apt-get install git-lfs安装。更多的安装方式,请参见安装git-lfs。git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1.git cd DeepSeek-R1/ git lfs pull在OSS中创建目录,将模型上传至OSS。
说明关于ossutil工具的安装和使用方法,请参见安装ossutil。
ossutil mkdir oss://<your-bucket-name>/models/DeepSeek-R1 ossutil cp -r ./DeepSeek-R1 oss://<your-bucket-name>/models/DeepSeek-R1将模型存储到OSS后,有两种方式加载模型。
直接使用PVC&PV挂载模型:适用于一些较小的模型,对于Pod启动、加载模型速度没有过多要求的应用。
控制台操作示例
以下为示例PV的基本配置信息:
配置项
说明
存储卷类型
OSS
名称
llm-model
访问证书
配置用于访问OSS的AccessKey ID和AccessKey Secret。
Bucket ID
选择上一步所创建的OSS Bucket。
OSS Path
选择模型所在的路径,如/models/DeepSeek-R1
以下为示例PVC的基本配置信息:
配置项
说明
存储声明类型
OSS
名称
llm-model
分配模式
选择已有存储卷。
已有存储卷
单击选择已有存储卷链接,选择已创建的存储卷PV。
kubectl操作示例
以下为示例YAML:
apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: <your-oss-ak> # 配置用于访问OSS的AccessKey ID akSecret: <your-oss-sk> # 配置用于访问OSS的AccessKey Secret --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: <your-bucket-name> # bucket名称 url: <your-bucket-endpoint> # Endpoint信息,如oss-cn-hangzhou-internal.aliyuncs.com otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: <your-model-path> # 本示例中为/models/DeepSeek-R1/ --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-model使用Fluid加速模型加载:适用于一些较大的模型,对于Pod启动、加载模型速度有要求的应用。详细操作,请参见使用Fluid实现数据加速访问。
在ACS应用市场通过Helm安装ack-fluid组件,组件版本需要1.0.11-*及以上。详细操作,请参见使用Helm创建应用。
ACS Pod开启特权模式。可以通过提交工单进行开启。
创建一个用来访问OSS的Secret。
apiVersion: v1 kind: Secret metadata: name: mysecret stringData: fs.oss.accessKeyId: xxx fs.oss.accessKeySecret: xxx其中,
fs.oss.accessKeyId和fs.oss.accessKeySecret是用来访问上述OSS的AccessKey ID和AccessKey Secret。创建Dataset和JindoRuntime。
apiVersion: data.fluid.io/v1alpha1 kind: Dataset metadata: name: deepseek spec: mounts: - mountPoint: oss://<your-bucket-name> # 请按实际情况修改<your-bucket-name> options: fs.oss.endpoint: <your-bucket-endpoint> # 请按实际情况修改<your-bucket-endpoint> name: deepseek path: "/" encryptOptions: - name: fs.oss.accessKeyId valueFrom: secretKeyRef: name: mysecret key: fs.oss.accessKeyId - name: fs.oss.accessKeySecret valueFrom: secretKeyRef: name: mysecret key: fs.oss.accessKeySecret --- apiVersion: data.fluid.io/v1alpha1 kind: JindoRuntime metadata: name: deepseek spec: replicas: 16 # 可以按需调整 master: podMetadata: labels: alibabacloud.com/compute-class: performance alibabacloud.com/compute-qos: default worker: podMetadata: labels: alibabacloud.com/compute-class: performance alibabacloud.com/compute-qos: default annotations: kubernetes.io/resource-type: serverless resources: requests: cpu: 16 memory: 128Gi limits: cpu: 16 memory: 128Gi tieredstore: levels: - mediumtype: MEM path: /dev/shm volumeType: emptyDir ## 按需调整 quota: 128Gi high: "0.99" low: "0.95"创建完成后可以通过
kubectl get pod | grep jindo命令检查Pod是否为Running状态。预期输出:deepseek-jindofs-master-0 1/1 Running 0 3m29s deepseek-jindofs-worker-0 1/1 Running 0 2m52s deepseek-jindofs-worker-1 1/1 Running 0 2m52s ...通过创建DataLoad缓存模型。
apiVersion: data.fluid.io/v1alpha1 kind: DataLoad metadata: name: deepseek spec: dataset: name: deepseek namespace: default loadMetadata: true通过以下命令检查缓存状态。
kubectl get dataload预期输出:
NAME DATASET PHASE AGE DURATION deepseek deepseek Executing 4m30s Unfinished当前的
PHASE为Executing状态,说明正在执行中。等待约20分钟后再次执行命令,如果状态改为Complete,说明已经缓存成功。您可以使用kubectl logs $(kubectl get pods --selector=job-name=deepseek-loader-job -o jsonpath='{.items[0].metadata.name}') | grep progress命令获取Job名称并查看日志获取执行进度。通过以下命令检查Dataset资源。
kubectl get datasets预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE deepseek 1.25TiB 1.25TiB 2.00TiB 100.0% Bound 21h
步骤二:基于ACS GPU算力部署模型
在ACS应用市场通过Helm安装lws组件。详细操作,请参见使用Helm创建应用。
使用LeaderWorkerSet部署模型。
说明请将YAML中的
alibabacloud.com/gpu-model-series: <example-model>替换为ACS支持的GPU具体型号。目前支持的GPU型号列表请咨询PDSA或提交工单。与TCP/IP相比,高性能网络RDMA实现了零拷贝和内核旁路等特性,避免了数据拷贝和频繁的上下文切换,从而实现了更低的延迟、更高的吞吐量和更低的CPU占用。ACS支持在YAML中配置标签
alibabacloud.com/hpn-type: "rdma"来使用RDMA,支持RDMA的GPU型号请咨询PDSA或提交工单。如果使用Fluid加载模型,需要修改两处PVC的
claimName为Fluid Dataset名称。不同的分布式部署架构会影响YAML中
tensor-parallel-size和LWS_GROUP_SIZE等变量的取值。
标准部署示例
apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: deepseek-r1-671b-fp8-distrubution spec: replicas: 1 leaderWorkerTemplate: size: 2 #leader和worker的总数量 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: leader alibabacloud.com/compute-class: gpu #指定GPU类型 alibabacloud.com/compute-qos: default #指定acs qos等级 alibabacloud.com/gpu-model-series: <example-model> ##指定GPU型号 spec: volumes: - name: llm-model persistentVolumeClaim: ## 如果使用fluid,此处应填写 fluid dataset 名字,比如:deepseek claimName: llm-model - name: shm emptyDir: medium: Memory sizeLimit: 32Gi containers: - name: deepseek-r1-671b-leader image: registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/vllm:v0.7.2 env: - name: NCCL_SOCKET_IFNAME #指定网卡 value: eth0 command: - sh - -c - "/vllm-workspace/ray_init.sh leader --ray_cluster_size=$(LWS_GROUP_SIZE);vllm serve /models/DeepSeek-R1/ --port 8000 --trust-remote-code --served-model-name ds --max-model-len 2048 --gpu-memory-utilization 0.95 --tensor-parallel-size 8 --pipeline-parallel-size 2 --enforce-eager" #tensor-parallel-size设置为leader和worker各个pod的总卡数 resources: limits: nvidia.com/gpu: "8" cpu: "64" memory: 512G requests: nvidia.com/gpu: "8" cpu: "64" memory: 512G ports: - containerPort: 8000 volumeMounts: - mountPath: /models/DeepSeek-R1 name: llm-model - mountPath: /dev/shm name: shm workerTemplate: metadata: labels: alibabacloud.com/compute-class: gpu #指定GPU类型 alibabacloud.com/compute-qos: default #指定acs qos等级 alibabacloud.com/gpu-model-series: <example-model> ##指定GPU型号 spec: volumes: - name: llm-model persistentVolumeClaim: ## 如果使用fluid,此处应填写 fluid dataset 名字,比如:deepseek claimName: llm-model - name: shm emptyDir: medium: Memory sizeLimit: 32Gi containers: - name: deepseek-r1-671b-worker image: registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/vllm:v0.7.2 env: - name: NCCL_SOCKET_IFNAME #指定网卡 value: eth0 command: - sh - -c - "/vllm-workspace/ray_init.sh worker --ray_address=$(LWS_LEADER_ADDRESS)" resources: limits: nvidia.com/gpu: "8" cpu: "64" memory: 512G requests: nvidia.com/gpu: "8" cpu: "64" memory: 512G ports: - containerPort: 8000 volumeMounts: - mountPath: /models/DeepSeek-R1 name: llm-model - mountPath: /dev/shm name: shm使用RDMA加速示例
如果使用开源基础镜像(如vLLM等),需要在YAML中增加以下env参数:
Name
Value
NCCL_SOCKET_IFNAME
eth0
NCCL_IB_TC
136
NCCL_IB_SL
5
NCCL_IB_GID_INDEX
3
NCCL_DEBUG
INFO
NCCL_IB_HCA
mlx5
NCCL_NET_PLUGIN
none
apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: deepseek-r1-671b-fp8-distrubution spec: replicas: 1 leaderWorkerTemplate: size: 2 #leader和worker的总数量 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: leader alibabacloud.com/compute-class: gpu #指定GPU类型 alibabacloud.com/compute-qos: default #指定acs qos等级 alibabacloud.com/gpu-model-series: <example-model> ##指定GPU型号 # 指定让应用运行在高性能网络RDMA中,支持RDMA的GPU型号请提交工单咨询 alibabacloud.com/hpn-type: "rdma" spec: volumes: - name: llm-model persistentVolumeClaim: ## 如果使用fluid,此处应填写 fluid dataset 名字,比如:deepseek claimName: llm-model - name: shm emptyDir: medium: Memory sizeLimit: 32Gi containers: - name: deepseek-r1-671b-leader image: registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/vllm:v0.7.2 env: - name: NCCL_SOCKET_IFNAME #指定网卡 value: eth0 - name: NCCL_IB_TC value: "136" - name: NCCL_IB_SL value: "5" - name: NCCL_IB_GID_INDEX value: "3" - name: NCCL_DEBUG value: "INFO" - name: NCCL_IB_HCA value: "mlx5" - name: NCCL_NET_PLUGIN value: "none" command: - sh - -c - "/vllm-workspace/ray_init.sh leader --ray_cluster_size=$(LWS_GROUP_SIZE);vllm serve /models/DeepSeek-R1/ --port 8000 --trust-remote-code --served-model-name ds --max-model-len 2048 --gpu-memory-utilization 0.95 --tensor-parallel-size 8 --pipeline-parallel-size 2 --enforce-eager" #tensor-parallel-size设置为leader和worker各个pod的总卡数 resources: limits: nvidia.com/gpu: "8" cpu: "64" memory: 512G requests: nvidia.com/gpu: "8" cpu: "64" memory: 512G ports: - containerPort: 8000 volumeMounts: - mountPath: /models/DeepSeek-R1 name: llm-model - mountPath: /dev/shm name: shm workerTemplate: metadata: labels: alibabacloud.com/compute-class: gpu #指定GPU类型 alibabacloud.com/compute-qos: default #指定acs qos等级 alibabacloud.com/gpu-model-series: <example-model> ##指定GPU型号 # 指定让应用运行在高性能网络RDMA中,支持RDMA的GPU型号请提交工单咨询 alibabacloud.com/hpn-type: "rdma" spec: volumes: - name: llm-model persistentVolumeClaim: ## 如果使用fluid,此处应填写 fluid dataset 名字,比如:deepseek claimName: llm-model - name: shm emptyDir: medium: Memory sizeLimit: 32Gi containers: - name: deepseek-r1-671b-worker image: registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/vllm:v0.7.2 env: - name: NCCL_SOCKET_IFNAME #指定网卡 value: eth0 - name: NCCL_IB_TC value: "136" - name: NCCL_IB_SL value: "5" - name: NCCL_IB_GID_INDEX value: "3" - name: NCCL_DEBUG value: "INFO" - name: NCCL_IB_HCA value: "mlx5" - name: NCCL_NET_PLUGIN value: "none" command: - sh - -c - "/vllm-workspace/ray_init.sh worker --ray_address=$(LWS_LEADER_ADDRESS)" resources: limits: nvidia.com/gpu: "8" cpu: "64" memory: 512G requests: nvidia.com/gpu: "8" cpu: "64" memory: 512G ports: - containerPort: 8000 volumeMounts: - mountPath: /models/DeepSeek-R1 name: llm-model - mountPath: /dev/shm name: shm通过Service暴露推理服务。
apiVersion: v1 kind: Service metadata: name: ds-leader spec: ports: - name: http port: 8000 protocol: TCP targetPort: 8000 selector: leaderworkerset.sigs.k8s.io/name: deepseek-r1-671b-fp8-distrubution role: leader type: ClusterIP
步骤三:验证推理服务
使用
kubectl port-forward在推理服务与本地环境间建立端口转发。说明请注意
kubectl port-forward建立的端口转发不具备生产级别的可靠性、安全性和扩展性,因此仅适用于开发和调试目的,不适合在生产环境使用。更多关于Kubernetes集群内生产可用的网络方案的信息,请参见Ingress管理。kubectl port-forward svc/ds-leader 8000:8000预期输出:
Forwarding from 127.0.0.1:8000 -> 8000 Forwarding from [::1]:8000 -> 8000发送模型推理请求。
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "ds", "messages": [ { "role": "system", "content": "你是个友善的AI助手。" }, { "role": "user", "content": "介绍一下深度学习。" } ], "max_tokens": 1024, "temperature": 0.7, "top_p": 0.9, "seed": 10 }'预期输出:
{"id":"chatcmpl-4bc78b66e2a4439f8362bd434a60be57","object":"chat.completion","created":1739501401,"model":"ds","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"嗯,用户让我介绍一下深度学习,我得仔细想想怎么回答才好。首先,我得明确深度学习的基本定义,它是机器学习的一个分支,对吧?然后要跟传统的机器学习方法对比,说明深度学习的优势在哪里,比如自动特征提取之类的。可能需要提到神经网络,尤其是深度神经网络的结构,比如多层隐藏层。\n\n接下来应该讲一下深度学习的核心组件吧,比如激活函数、损失函数、优化器这些。可能用户对这些术语不熟悉,所以需要简单解释一下每个部分的作用。比如ReLU作为激活函数,Adam作为优化器,交叉熵损失函数这些例子。\n\n然后应用领域,计算机视觉、自然语言处理这些应该都是比较常见的,可能需要举几个实际的例子,比如图像识别、机器翻译,用户可能更容易理解。另外行业应用,像医疗、金融这些,用户可能会感兴趣这些实际的应用场景。\n\n还要提到流行的框架,比如TensorFlow、PyTorch,这些框架的使用让深度学习更易于实现。还有就是硬件加速比如GPU的重要性,说明为什么深度学习现在发展得这么快。\n\n另外,可能得讨论一下深度学习的挑战和限制,比如数据依赖、计算资源需求高、可解释性差这些,这样用户能全面了解优缺点。可能还需要提到一些未来的发展方向,比如高效训练算法、可解释性研究这些。\n\n用户的需求可能是想了解深度学习的基本概念,可能有一些技术背景,但不太深入。他们可能想快速掌握关键点和应用,所以回答需要结构清晰,重点突出,不用太深入技术细节,但也不能太简略。需要平衡专业性和易懂性。\n\n要避免使用太多术语,或者在用术语时稍作解释,比如“神经网络”、“卷积神经网络”等。可能用户是学生或者刚入行的从业者,需要用平实的语言让他们理解。同时要举一些例子帮助他们联系实际应用,这样更容易记忆。\n\n还要注意深度学习和机器学习的关系,需要明确区分两者的不同,说明深度学习属于机器学习,但层次更深,处理更复杂的问题。可能还要提到反向传播算法,作为训练的关键技术之一。\n\n最后做一个总结,强调深度学习的影响和潜力,未来的发展方向,这样能让用户有一个全面的认识。检查一下有没有遗漏的重要点,比如常见的模型结构如CNN、RNN这些,可能也需要简要提及,以展示多样性。\n\n有时候用户可能对原理感兴趣,但在这里保持简洁比较重要,重点是概述而非深入的技术细节。确保回答的逻辑流畅,从定义开始,到核心组件,应用,框架,挑战,未来方向,这样的结构比较合理。\n</think>\n\n深度学习是机器学习的一个分支,旨在通过构建多层的神经网络(称为“深度”网络)来模拟人脑的学习机制。它通过从大量数据中自动学习复杂的特征和模式,广泛应用于图像识别、语音处理、自然语言处理等领域。\n\n### 核心概念\n1. **人工神经网络(ANN)**:\n - 由输入层、多个隐藏层和输出层组成,每层包含多个神经元。\n - 通过模拟神经元的激活和传递实现信息处理。\n\n2. **特征自动提取**:\n - 传统机器学习依赖人工设计特征,而深度学习通过多层网络自动提取数据的抽象特征(如从像素到物体的边缘、形状等)。\n\n3. **关键组成部分**:\n - **激活函数**(如ReLU、Sigmoid):引入非线性,增强模型表达能力。\n - **损失函数**(如交叉熵、均方误差):衡量预测值与真实值的差距。\n - **优化器**(如SGD、Adam):通过反向传播优化网络参数,最小化损失。\n\n---\n\n### 典型模型\n- **卷积神经网络(CNN)**: \n 专为图像设计,通过卷积核提取空间特征。经典模型如ResNet、VGG。\n- **循环神经网络(RNN)**: \n 处理序列数据(文本、语音),引入记忆机制,改进版如LSTM、GRU。\n- **Transformer**: \n 基于自注意力机制,大幅提升自然语言处理性能(如BERT、GPT系列)。\n\n---\n\n### 应用场景\n- **计算机视觉**:人脸识别、医学影像分析(如肺部CT病灶检测)。\n- **自然语言处理**:智能客服、文档摘要生成、翻译(如DeepL)。\n- **语音技术**:语音助手(如Siri)、实时字幕生成。\n- **强化学习**:游戏AI(AlphaGo)、机器人控制。\n\n---\n\n### 优势与挑战\n- **优势**:\n - 自动学习复杂特征,减少人工干预。\n - 在大数据和高算力下表现远超传统方法。\n- **挑战**:\n - 依赖海量标注数据(例如需数万张标注医学图像)。\n - 模型训练成本高(如GPT-3训练费用超千万美元)。\n - “黑箱”特性导致可解释性差,在医疗等高风险领域应用受限。\n\n---\n\n### 工具与趋势\n- **主流框架**:TensorFlow(工业部署友好)、PyTorch(研究首选)。\n- **研究方向**:\n - 轻量化模型(如MobileNet用于移动端)。\n - 自监督学习(减少对标注数据的依赖)。\n - 可解释性增强(如可视化模型决策依据)。\n\n深度学习正推动人工智能的边界,从生成式AI(如Stable Diffusion生成图像)到自动驾驶,持续改变技术生态。其未来发展可能在降低计算成本、提升效率及可解释性方面取得突破。","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":17,"total_tokens":1131,"completion_tokens":1114,"prompt_tokens_details":null},"prompt_logprobs":null}
相关文档
阿里云容器计算服务 ACS(Container Compute Service)已经集成到容器服务 Kubernetes 版,您可以通过ACK托管集群Pro版快速使用ACS提供的容器算力。关于ACK使用ACS GPU算力的详细内容,请参见ACK使用ACS GPU算力示例。
基于ACK部署DeepSeek的相关内容,请参见:
关于DeepSeek R1/V3模型的详细介绍,请参见: