
本文介绍如何在阿里云容器服务ACK中使用KServe部署生产可用的DeepSeek模型推理服务。
背景介绍
DeepSeek-R1模型
KServe
Arena
前提条件
已创建包含GPU的Kubernetes集群。具体操作,请参见为集群添加GPU节点池。
已通过kubectl连接到集群。具体操作,请参见通过kubectl连接集群。
已安装ack-kserve️组件。具体操作,请参见安装ack-kserve️组件。
已安装Arena客户端。具体操作,请参见配置Arena客户端。
GPU实例规格和成本预估
在推理阶段主要占用显存的是模型参数,可以通过以下公式计算。
以一个默认精度为FP16的7B模型为例,模型参数量为:7B(即70亿),精度数据类型字节数为:默认精度16位浮点数 / 8位每字节 = 2字节。
除了加载模型占用的显存之外,还需要考虑运算时所需的KV Cache大小和GPU使用率,通常会预留一部分buffer,因此推荐使用24GiB显存的GPU实例ecs.gn7i-c8g1.2xlarge或ecs.gn7i-c16g1.4xlarge。更多内容,请参见推荐实例规格表。关于GPU实例规格和计费的详情,请参见GPU计算型实例规格族和GPU云服务器计费。
模型部署
步骤一:准备DeepSeek-R1-Distill-Qwen-7B模型文件
执行以下命令从ModelScope下载DeepSeek-R1-Distill-Qwen-7B模型。
说明请确认是否已安装git-lfs插件,如未安装可执行
yum install git-lfs或者apt-get install git-lfs安装。更多的安装方式,请参见安装git-lfs。git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B.git cd DeepSeek-R1-Distill-Qwen-7B/ git lfs pull在OSS中创建目录,将模型上传至OSS。
说明关于ossutil工具的安装和使用方法,请参见安装ossutil。
ossutil mkdir oss://<your-bucket-name>/models/DeepSeek-R1-Distill-Qwen-7B ossutil cp -r ./DeepSeek-R1-Distill-Qwen-7B oss://<your-bucket-name>/models/DeepSeek-R1-Distill-Qwen-7B创建PV和PVC。为目标集群配置名为
llm-model的存储卷PV和存储声明PVC。具体操作,请参见使用ossfs 1.0静态存储卷。控制台操作示例
以下为示例PV的基本配置信息:
配置项
说明
存储卷类型
OSS
名称
llm-model
访问证书
配置用于访问OSS的AccessKey ID和AccessKey Secret。
Bucket ID
选择上一步所创建的OSS Bucket。
OSS Path
选择模型所在的路径,如
/models/DeepSeek-R1-Distill-Qwen-7B。以下为示例PVC的基本配置信息:
配置项
说明
存储声明类型
OSS
名称
llm-model
分配模式
选择已有存储卷。
已有存储卷
单击选择已有存储卷链接,选择已创建的存储卷PV。
kubectl操作示例
以下为示例YAML:
apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: <your-oss-ak> # 配置用于访问OSS的AccessKey ID akSecret: <your-oss-sk> # 配置用于访问OSS的AccessKey Secret --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: <your-bucket-name> # bucket名称 url: <your-bucket-endpoint> # Endpoint信息,如oss-cn-hangzhou-internal.aliyuncs.com otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: <your-model-path> # 本示例中为/models/DeepSeek-R1-Distill-Qwen-7B/ --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-model
步骤二:部署推理服务
执行下列命令,启动名称为deepseek的推理服务。
arena serve kserve \ --name=deepseek \ --image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.6.6 \ --gpus=1 \ --cpu=4 \ --memory=12Gi \ --data=llm-model:/models/DeepSeek-R1-Distill-Qwen-7B \ "vllm serve /models/DeepSeek-R1-Distill-Qwen-7B --port 8080 --trust-remote-code --served-model-name deepseek-r1 --max-model-len 32768 --gpu-memory-utilization 0.95 --enforce-eager"参数解释如下表所示:
参数
是否必选
说明
--name
是
提交的推理服务名称,全局唯一。
--image
是
推理服务的镜像地址。
--gpus
否
推理服务需要使用的GPU卡数。默认值为0。
--cpu
否
推理服务需要使用的CPU数量。
--memory
否
推理服务需要使用的内存数量。
--data
否
服务的模型地址,本文指定模型为上一步创建的存储卷
llm-model,挂载到容器中的/models/目录下。预期输出:
inferenceservice.serving.kserve.io/deepseek created INFO[0003] The Job deepseek has been submitted successfully INFO[0003] You can run `arena serve get deepseek --type kserve -n default` to check the job status
步骤三:验证推理服务
执行下列命令,查看KServe推理服务的部署情况。
arena serve get deepseek预期输出:
Name: deepseek Namespace: default Type: KServe Version: 1 Desired: 1 Available: 1 Age: 3m Address: http://deepseek-default.example.com Port: :80 GPU: 1 Instances: NAME STATUS AGE READY RESTARTS GPU NODE ---- ------ --- ----- -------- --- ---- deepseek-predictor-7cd4d568fd-fznfg Running 3m 1/1 0 1 cn-beijing.172.16.1.77输出结果表明,KServe推理服务部署成功。
执行以下命令,使用获取到的Nginx Ingress网关地址访问推理服务。
# 获取Nginx ingress的IP地址。 NGINX_INGRESS_IP=$(kubectl -n kube-system get svc nginx-ingress-lb -ojsonpath='{.status.loadBalancer.ingress[0].ip}') # 获取Inference Service的Hostname。 SERVICE_HOSTNAME=$(kubectl get inferenceservice deepseek -o jsonpath='{.status.url}' | cut -d "/" -f 3) # 发送请求访问推理服务。 curl -H "Host: $SERVICE_HOSTNAME" -H "Content-Type: application/json" http://$NGINX_INGRESS_IP:80/v1/chat/completions -d '{"model": "deepseek-r1", "messages": [{"role": "user", "content": "Say this is a test!"}], "max_tokens": 512, "temperature": 0.7, "top_p": 0.9, "seed": 10}'预期输出:
{"id":"chatcmpl-0fe3044126252c994d470e84807d4a0a","object":"chat.completion","created":1738828016,"model":"deepseek-r1","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\n\n</think>\n\nIt seems like you're testing or sharing some information. How can I assist you further? If you have any questions or need help with something, feel free to ask!","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":9,"total_tokens":48,"completion_tokens":39,"prompt_tokens_details":null},"prompt_logprobs":null}
可观测性
在生产环境中LLM推理服务的可观测性是至关重要的,可以有效提前发现和定位故障。vLLM框架提供了许多LLM推理指标,具体指标请参见Metrics文档。KServe也提供了一些指标来帮助您监控模型服务的性能和健康状况。我们在Arena工具中集成了这些能力,您只需要在提交应用时增加--enable-prometheus=true参数即可。
arena serve kserve \
--name=deepseek \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.6.6 \
--gpus=1 \
--cpu=4 \
--memory=12Gi \
--enable-prometheus=true \
--data=llm-model:/models/DeepSeek-R1-Distill-Qwen-7B \
"vllm serve /models/DeepSeek-R1-Distill-Qwen-7B --port 8080 --trust-remote-code --served-model-name deepseek-r1 --max-model-len 32768 --gpu-memory-utilization 0.95 --enforce-eager"您可以通过Grafana大盘来观测基于vLLM部署的LLM推理服务。首先将vLLM的Grafana JSON model导入到Grafana,然后创建LLM推理服务的可观测大盘。导入的JSON model请参见vLLM官方网站。具体导入操作,请参见如何导出和导入Grafana仪表盘。配置后Dashboard大盘如下图所示:
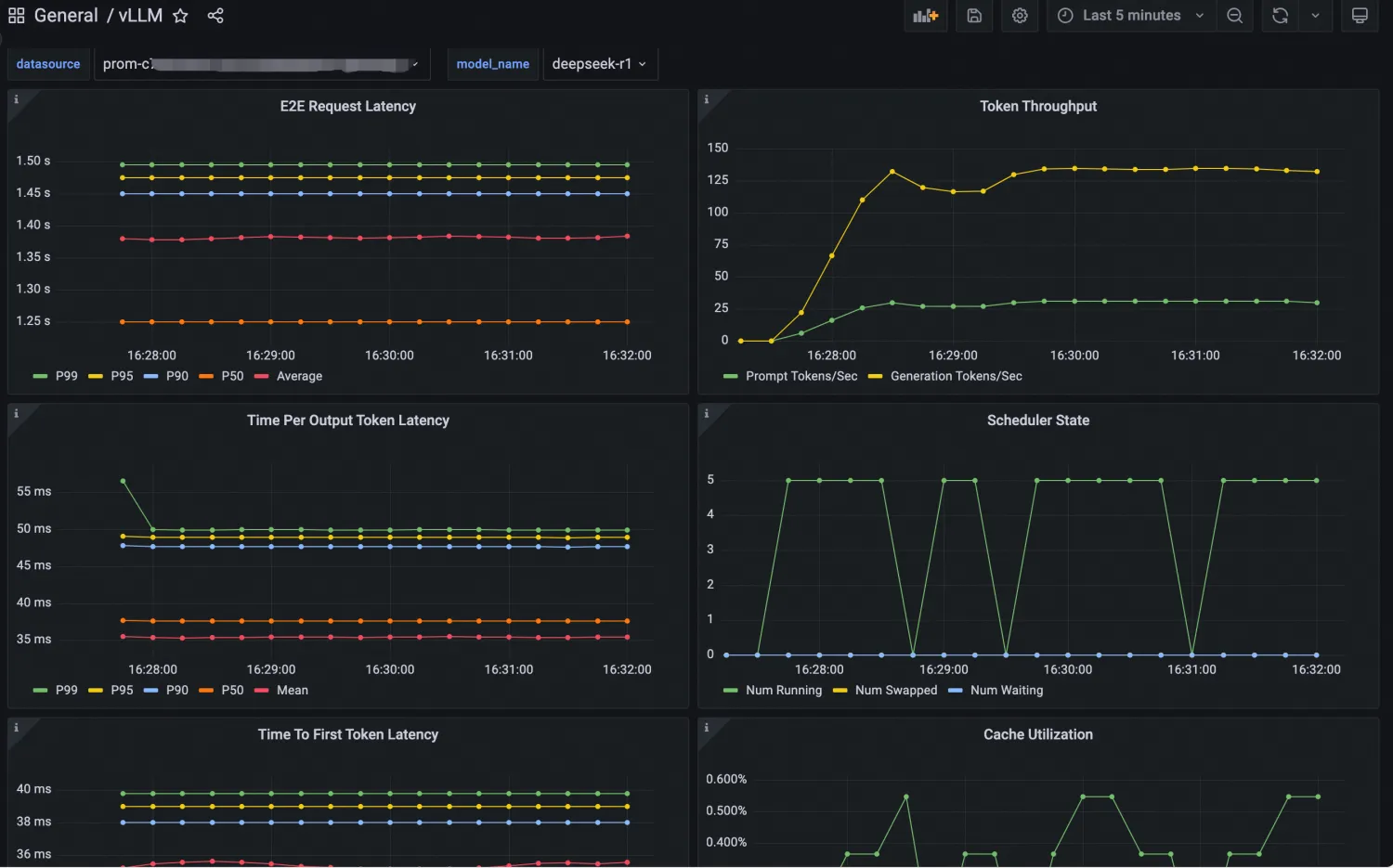
导入Grafana大盘操作步骤
导入大盘
登录ARMS控制台。
在左侧导航栏,单击接入管理。
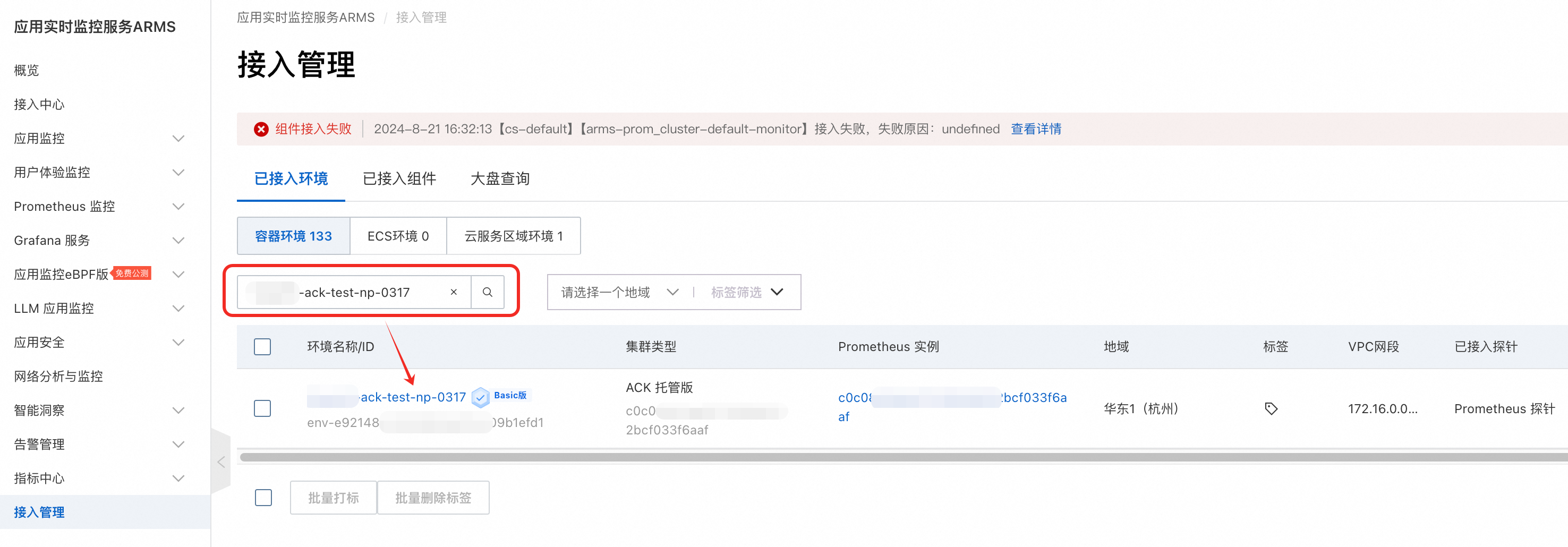
在已接入环境页签中选择容器环境,通过ACK集群名称搜索环境,然后点击进入目标环境。
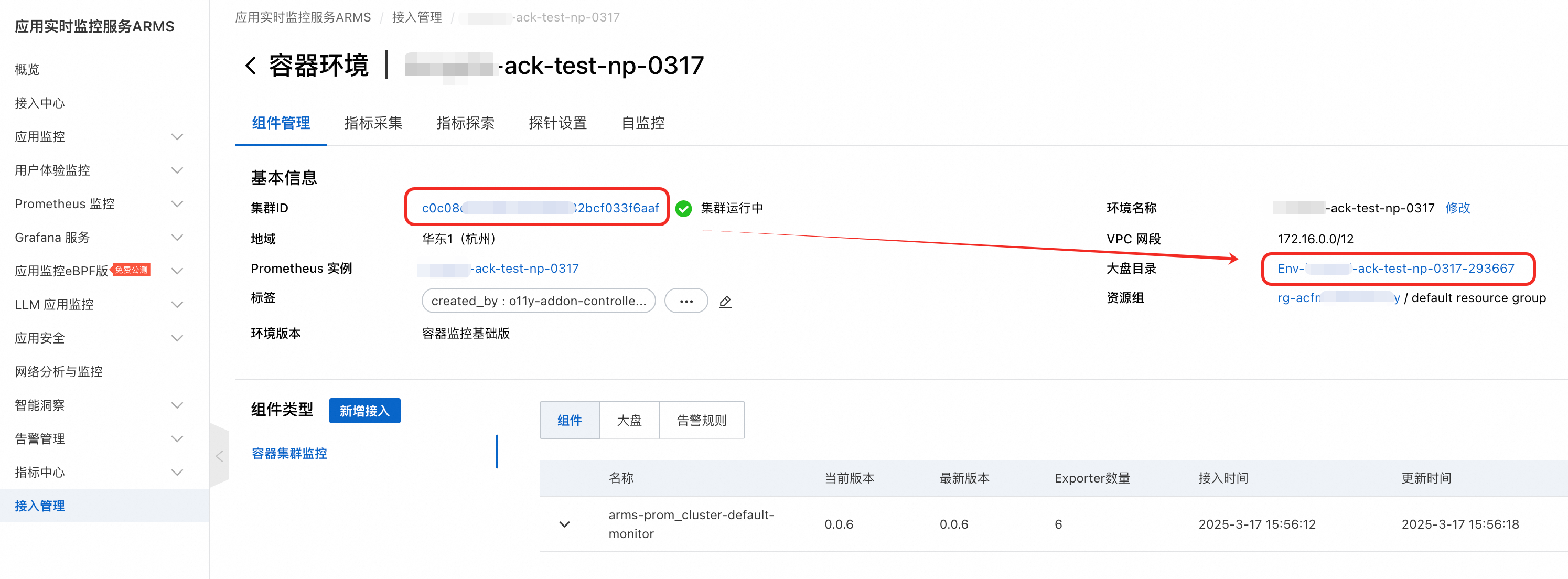
在组件管理页签中,复制并保存集群ID,点击进入大盘目录。
在Dashboards页签右侧,点击Import按钮。
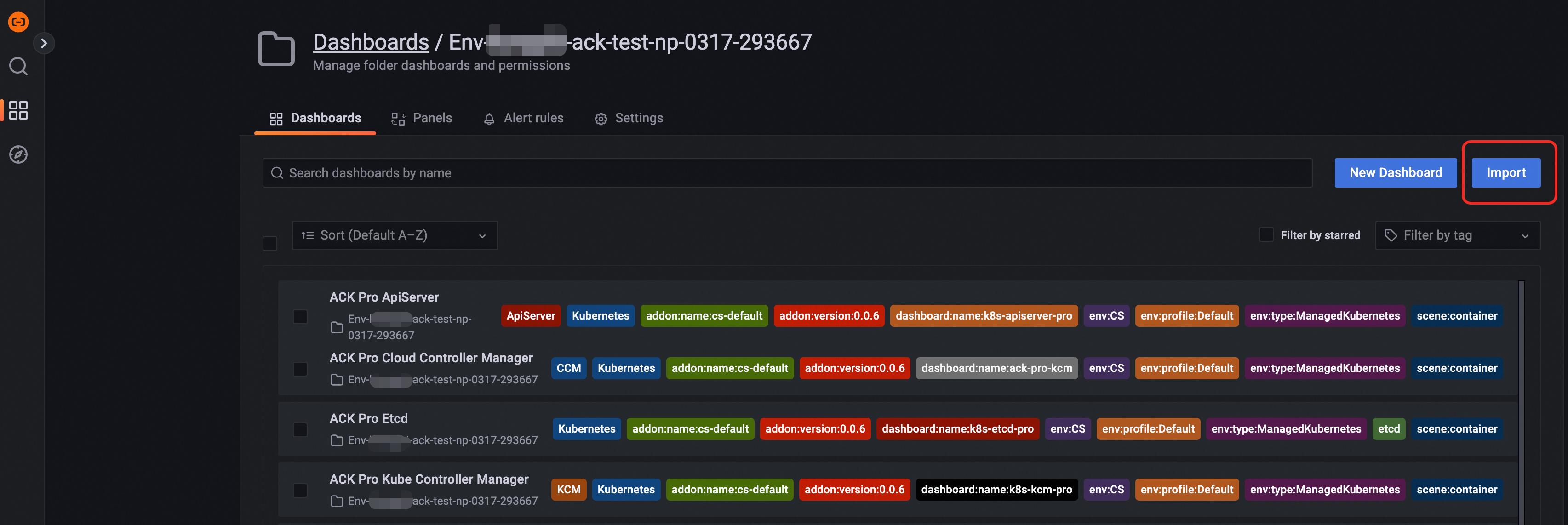
复制grafana.json文件内容,粘贴到Import via panel json区域,然后点击Load按钮。
说明您也可以通过上传JSON文件的方式导入大盘。
保持默认设置,点击Import,即可完成LLM推理服务可观测大盘的导入。
大盘数据验证
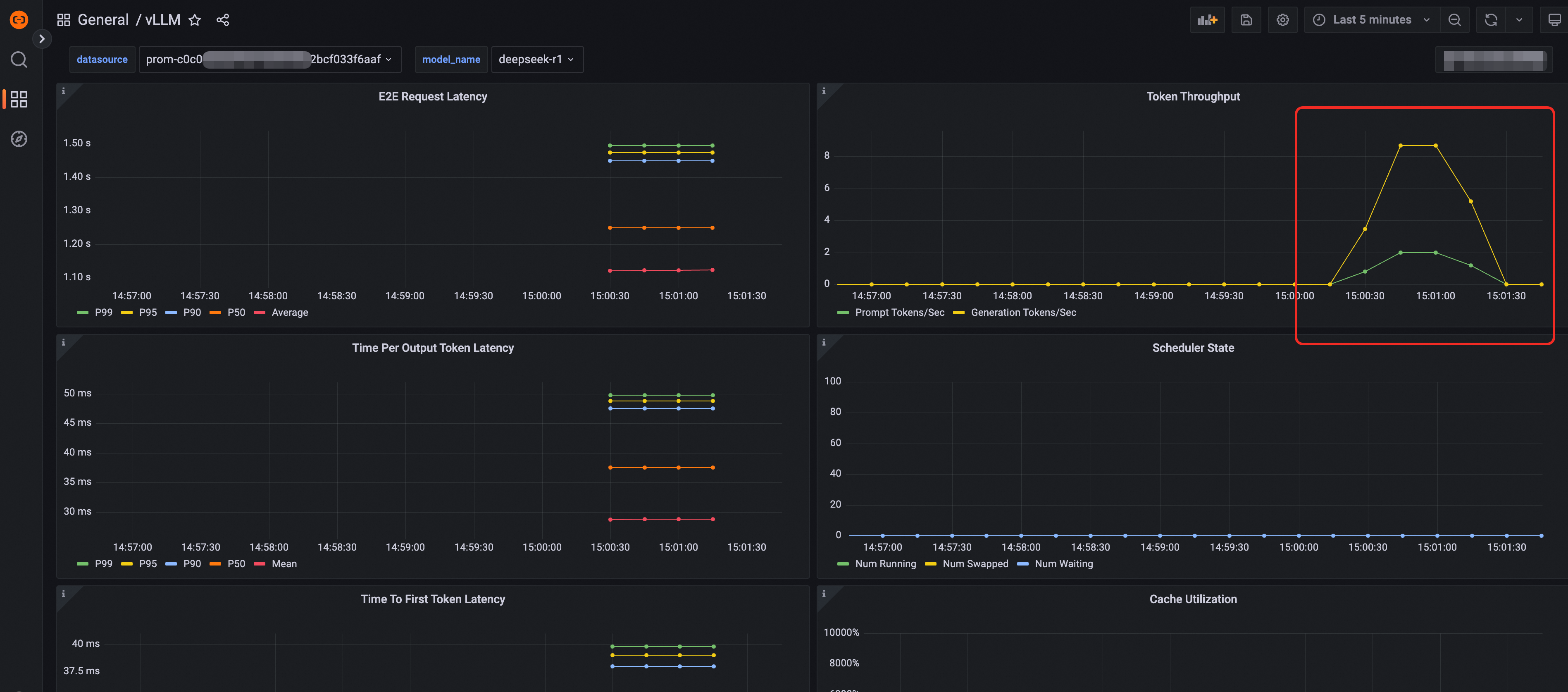
弹性扩缩容
在部署与管理KServe模型服务时,可能会遇到动态负载波动。KServe通过Kubernetes的HPA技术和ACK的ack-alibaba-cloud-metrics-adapter组件,支持根据CPU、内存、GPU使用率及自定义性能指标,自动调整模型服务Pod的数量,确保服务稳定高效。详细内容,请参见为服务配置弹性扩缩容。
模型加速
随着技术的发展,AI应用的模型数据越来越大,但是通过存储服务(如OSS、NAS等)拉取这些大文件时可能会出现长时间的延迟和冷启动问题。您可以利用Fluid显著提升模型加载速度,从而优化推理服务的性能,特别是对于基于KServe的推理服务而言。详细内容,请参见使用Fluid实现模型加速。
灰度发布
在生产环境中应用发布更新是最为常见的操作,为了保证业务平稳、降低变更风险,灰度发布必不可少。ACK支持多种灰度发布策略,如根据流量百分比灰度,根据请求Header灰度等。详细内容,请参见实现推理服务的灰度发布。
GPU共享推理
DeepSeek-R1-Distill-Qwen-7B模型仅需14 GB显存,如果您使用更高规格的GPU机型,可以考虑使用GPU共享推理技术,提升GPU使用率。GPU共享技术可以将一个GPU进行切分,多个推理服务共享一个GPU,从而提升GPU使用率。详细内容,请参见部署GPU共享推理服务。