
准备工作
创建MaxCompute表
DataHub支持将数据同步到MaxCompute对应的数据表中,同时支持分区表和非分区表,一般情况下推荐用户使用分区表进行数据同步以方便MaxCompute数据处理。
目前DataHub支持将TUPLE和BLOB的数据同步到MaxCompute数据表中。
针对TUPLE类型topic,MaxCompute目标表数据类型需要和DataHub数据类型相匹配,具体的数据类型映射关系如下:
MaxCompute
DataHub
BIGINT
BIGINT
STRING
STRING
BOOLEAN
BOOLEAN
DOUBLE
DOUBLE
DATETIME
TIMESTAMP
DECIMAL
DECIMAL
TINYINT
TINIINT
SMALLINT
SMALLINT
INT
INTEGER
FLOAT
FLOAT
MAP
不支持
ARRAY
不支持
由于目前DataHub并不能完全支持MaxCompute所有的数据类型,请用户尽量根据DataHub数据类型创建MaxCompute表结构。
针对BLOB数据类型,要求MaxCompute表结构仅需要包含一列STRING类型的column即可,DataHub默认会将数据同步到该column中。
DataHub
MaxCompute
BLOB
STRING
同时为了方便数据追踪和问题排查,建议用户在创建MaxCompute表结构时,增加一列
__rowkey__ STRING字段,DataHub会自动将DataHub对应数据的trace信息同步到该列中,以方便后续数据排查。
准备同步任务账号并授权
新建同步MaxCompute任务时,需要用户手动填写访问MaxCompute表的账号信息,请用户确保填入有效的账号信息(一般情况下采用MaxCompute子账号即可)。
需要给该账号授予访问MaxCompute表的响应权限,具体权限包括
CreateInstance、Describe、Alter以及Update权限。用户可以使用DataWorks管控台进行MaxCompute对应表的权限管理,参考配置MaxCompute引擎权限配置MaxCompute引擎权限,也可以选择使用MaxCompute的命令行工具进行授权,参考MaxCompute使用及授权管理。
确认TimestampUnit单位
Connector中TimestampUnit的作用,就是将数据中TIMESTAMP类型的数据(如果有),以TimestampUnit为单位进行转换后写入到下游系统的日期类型(如datetime类型)。
如果TIMESTAMP列写入的是以秒为单位的值,那新建Connector的时候TimestampUnit就选择“SECOND”;如果写入的是以毫秒为单位的值,那就选择“MILLISECOND”;如果写入的是以微秒为单位的值,那就选择“MICROSECOND”。
由于MaxCompute目前的写入标准原因,分区数越多就会导致DataHub同步数据越慢。因此,在创建MaxCompute同步任务时,请尽可能的控制分区数,尤其是USER_DEFINE同步模式。
同一分区的数据越连续越好,不要频繁的分区跳变。
同步模式控制创建分区时,请不要创建过多的分区数。
当MaxCompute项目开启白名单功能时,仅允许白名单内的设备访问项目空间;开启MaxCompute ip白名单后需设置服务白名单才能保证同步服务正常访问,具体设置方式请参考概述
同步模式
Append模式
数据以追加的方式写入目标表中,这种模式适用于数据仅需追加、无需更新的场景。
Upsert模式
Upsert 是 Update + Insert 的组合操作,其核心逻辑是:
如果目标表中存在与当前记录主键相同的记录,则更新该记录;
如果目标表中不存在与当前记录主键相同的记录,则插入该记录。
通过 Upsert 模式,用户可以更灵活地处理数据更新和插入操作,确保目标表中的数据始终保持最新状态。
关于更多 MaxCompute Upsert功能支持文档参考 基本概念
应用场景
数据需要根据主键进行更新:数据可能随时间变化,需要根据主键更新已有记录;
保持目标表中数据的唯一性:需要确保目标表中每条记录的唯一性,避免重复数据;
处理重复数据:需要对海量数据根据某个主键进行去重。
配置说明
Datahub Topic 类型:必须是TUPLE类型的Topic;
Datahub Topic Schema:目前支持以下两种类型
dts同步到datahub的schema类型(以下统称为Dts格式);
用户自主创建的schema,需要选择一列作为操作列,且必须是String类型(以下统称为自定义格式);
Odps 目标表:必须是 Transaction2.0表。
同步规则
1. DTS格式
针对Dts同步Datahub的两种数据格式,Datahub根据Schema中的固定列operation_flag, before_flag, after_flag以下面的规则决定如何将数据同步到 ODPS 目标表中:
operation_flag | before_flag | after_flag | OerationType | 同步目标表 |
I | * | * | UPSERT | 根据主键更新目标表中的记录 |
U | Y | N | DELETE | 根据主键删除目标表中的记录 |
U | N | Y | UPSERT | 根据主键更新目标表中的记录 |
D | * | * | DELETE | 根据主键删除目标表中的记录 |
2. 自定义格式
针对用户自主创建的数据,Datahub将根据用户选择的固定操作列来决定如何将数据同步到ODPS目标表中;
ddddd | OerationType | 同步目标表 |
U | UPSERT | 根据主键更新目标表中的记录 |
D | DELETE | 根据主键删除目标表中的记录 |
创建同步任务
单击DataHub中已创建的Topic,进入Topic详情页。
单击Topic详情页右上角的同步按钮,创建同步任务。
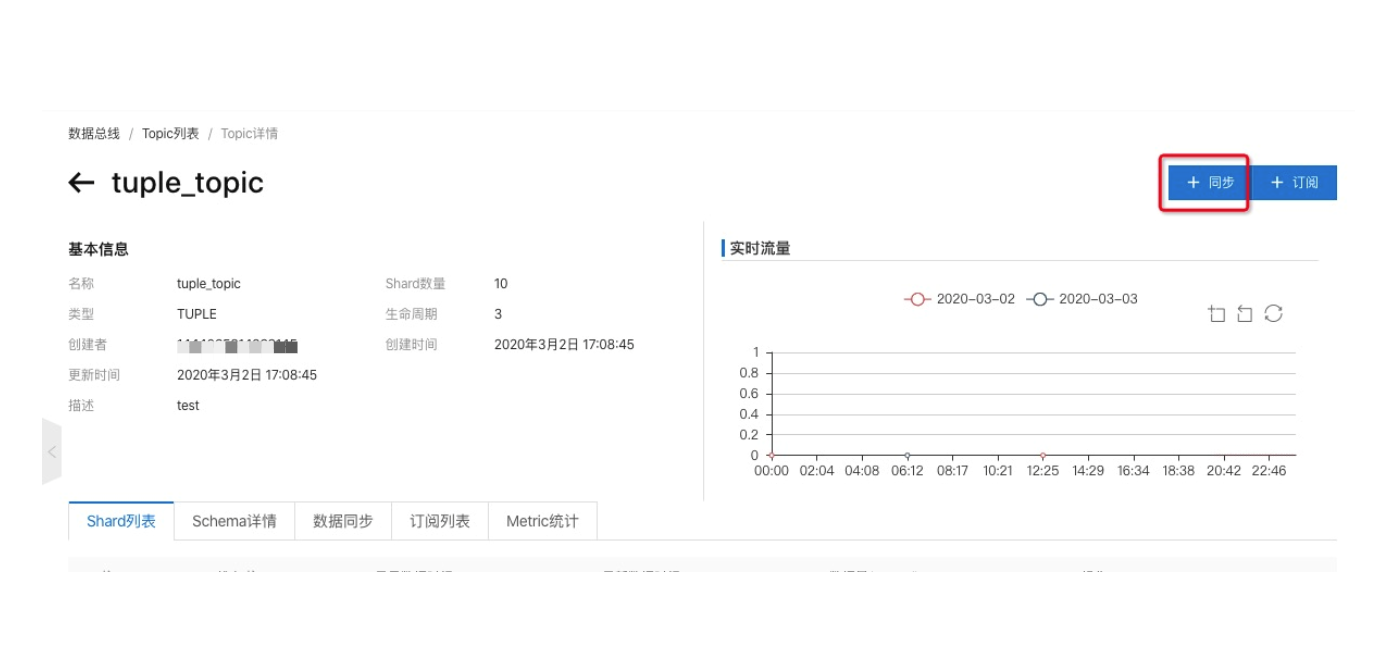
选择MaxCompute类型作业,进入新建Connector页面。
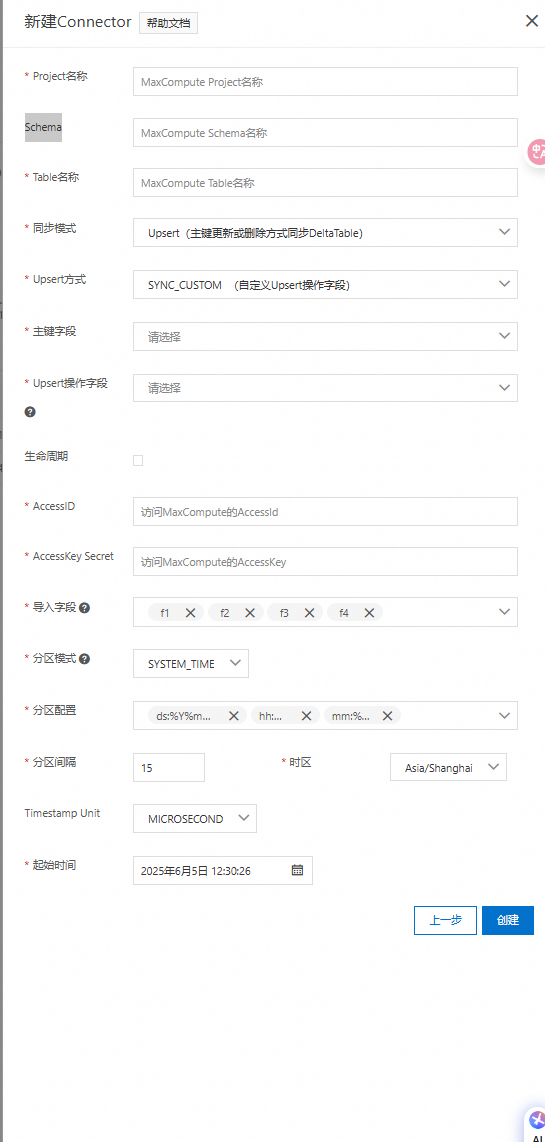
配置项说明:
参数
选项
是否必填
说明
Project名称
/
是
Maxcompute project名称
Schema
/
否
Maxcompute schema名称
说明使用Schema功能需打开Schema语法开发 ,关于打开方式和更多Schema说明信息请参考Schema操作
Table
/
是
Maxcompute Table名称
说明使用Upsert模式同步目标表必须是 Transaction2.0表
同步模式
Append
是
采用追加方式同步到Maxcompute 目标表中
Upsert
主键更新或删除方式同步到Maxcompute DeltaTable
Upsert模式详情参考上文同步模式章节
Upsert方式
SYNC_CUSTOM
选择同步模式为Upsert 该配置项为必填,同步方式为Append则不涉及该配置项
自定义Upsert操作字段
SYNC_NONE
全部以Upsert形式写入目标表
SYNC_DTS
适用于由dts写入DataHub ,启用dts新的附件列规则场景
SYNC_DTS_OLD
适用于由dts写入DataHub,启用dts新的附件列规则场景
主键字段
/
Upsert同步方式下创建下游表时指定的主键列
Upsert操作字段
/
选择SYNC_CUSTOM 方式同步该配置为必选项
选择任意一个String类型的列作为Operation,用于表示当前数据是以Upsert或Delete的形式同步到下游表中
关于Upsert 模式介绍请查看本文Upsert模式介绍章节。
导入字段:DataHub可以根据用户设置将部分column内容同步到MaxCompute表中。
分区模式:分区模式决定了将数据写入到MaxCompute哪个分区中,目前DataHub支持以下分区方式:
分区模式
分区依据
支持Topic类型
说明
USER_DEFINE
Record中的分区列(和MaxCompute的分区字段同名)的value值
TUPLE
(1). DataHub schema中必须包含MaxCompute分区字段 (2). 该列值必须为
UTF8字符串字段值可以为空,表示不分区SYSTEM_TIME
Record写入DataHub的时间
TUPLE / BLOB
(1). 分区配置中设置MaxCompute分区的时间转换Format格式 (2). 设置时区信息
EVENT_TIME
Record中的
event_time(TIMESTAMP)列的value值TUPLE
(1). 分区配置中设置MaxCompute分区的时间转换Format格式 (2). 设置时区信息
META_TIME
Record的属性字段
__dh_meta_time__的value值TUPLE / BLOB
(1). 分区配置中设置MaxCompute分区的时间转换Format格式 (2). 设置时区信息
其中
SYSTEM_TIME、EVENT_TIME和META_TIME均是根据时间Timestamp和时区配置来进行MaxCompute分区的转换过程,单位默认为微秒。分区配置决定了根据时间戳转换MaxCompute分区时的相关配置。目前管控台默认固定的MaxCompute分区格式,分区配置对应为:
分区
时间Format
说明
ds
%Y%m%d
day
hh
%H
hour
mm
%M
minute
分区间隔决定了根据时间戳转换MaxCompute分区时所采用的时间间隔。时间范围是
15分钟 ~ 1440分钟(1天),跳变间隔15分钟。时区信息(TimeZone)时区信息决定了根据时间戳转换MaxCompute分区时所采用的转换时区。
分隔符BLOB数据同步时,可以指定16进制分隔符来决定是否对BLOB数据分割后再同步MaxCompute,比如
0A表示\n(换行符)。Base64编码DataHub BLOB默认存储二进制数据,而MaxCompute对应的同步列为STRING类型,因此管控台创建同步任务时,默认采用base64编码后进行同步,更多定制化需求请参考SDK实现。
查看同步任务
可以点击对应connector的详情页面查看同步任务的运行状态和点位等信息, 包含同步点位、同步状态以及重启和停止等操作,如下图所示:

同步示例
1. USER_DEFINE同步模式
建立DataHub Topic
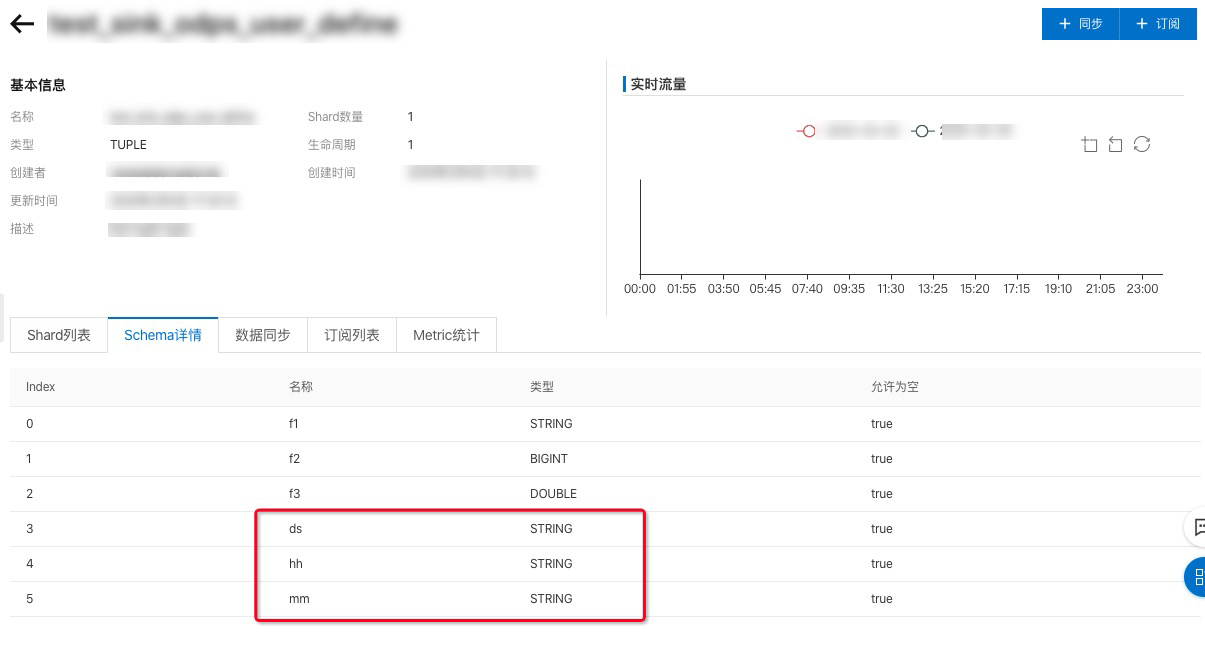
备注: topic schema中必须需要包含MaxCompute分区字段,类型为STRING,如下图所示:
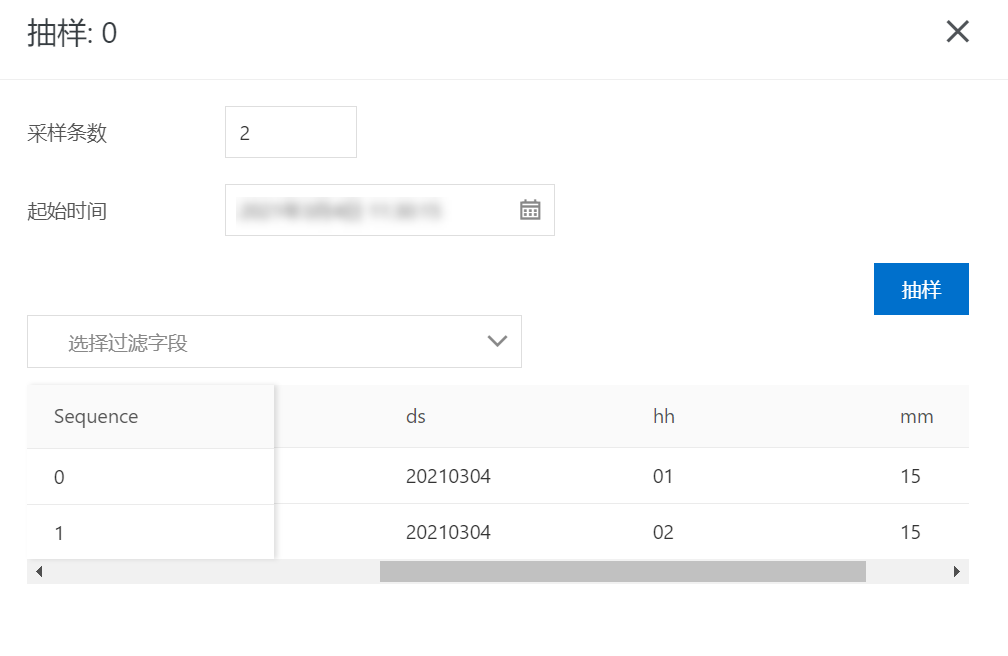
向DataHub Topic写入数据,可以使用datahub-sdk进行数据写入
测试过程中使用SDK写入几条数据,其中[ds,hh,mm]分别为:[20210304,01,15]和[20210304,02,15],数据内容如下所示:
3 建立同步任务
USER_DEFINE分区模式可以通过在同步中设置分区配置字段,如果MaxCompute没有对应的表,可自动创建。
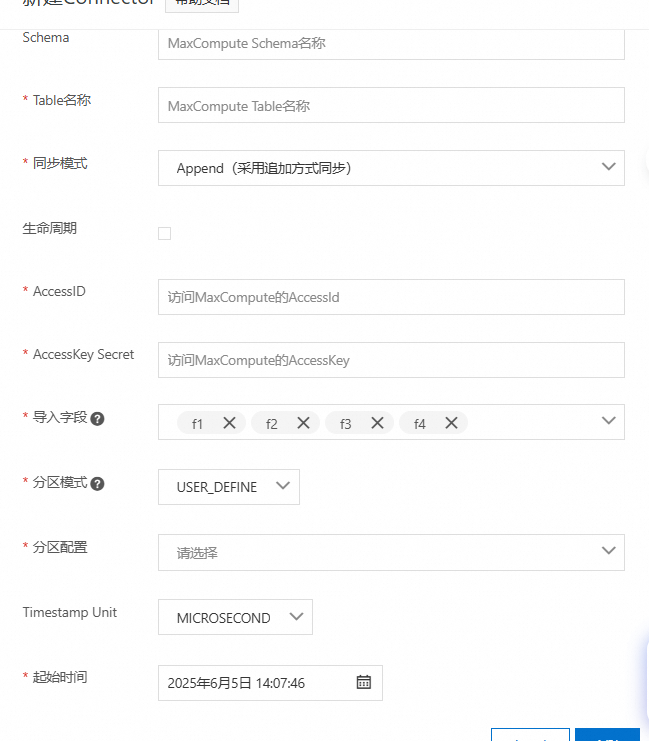
这里导入字段中设置导入f1、f2字段,不同步f3字段。
4 确认同步数据
可以从DataHub管控台查看对应同步任务的同步信息, 查询MaxCompute数据结果,结果如下: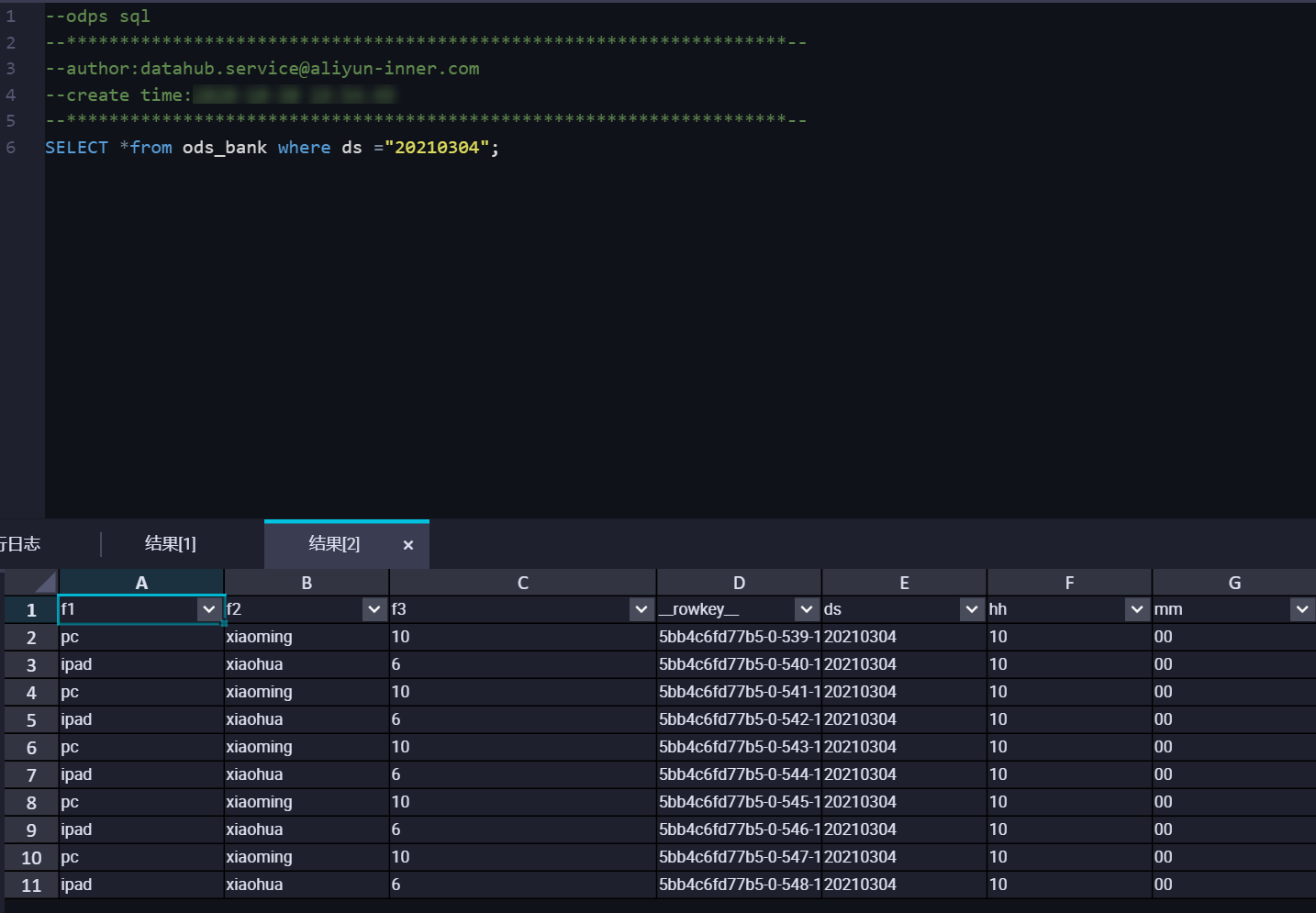 可以看到在USER_DEFINE模式下,DataHub会根据
可以看到在USER_DEFINE模式下,DataHub会根据MaxCompute分组字段所对应的value将DataHub中的数据同步到对应的分区中。
2. SYSTEM_TIME同步模式
建立DataHub Topic
备注:由于分区是根据写入DataHub时间来计算的,因此topic schema只需包含数据字段,不需要包含分区字段,如下图所示:
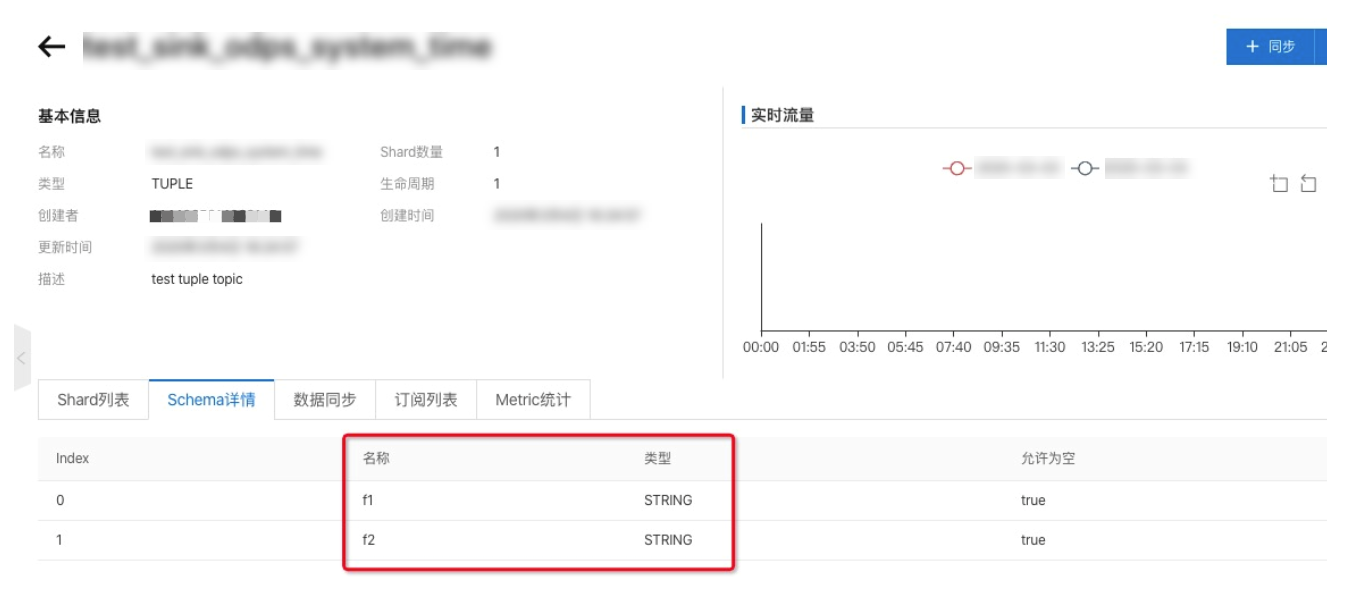
向DataHub Topic写入数据,可以使用datahub-sdk进行数据写入。
测试过程中使用SDK写入几条数据,DataHub目前对应的写入时间为
2021-03-04 14:02:45,数据内容如下所示:
建立同步任务
请注意分区配置需要和MaxCompute表分区一致。
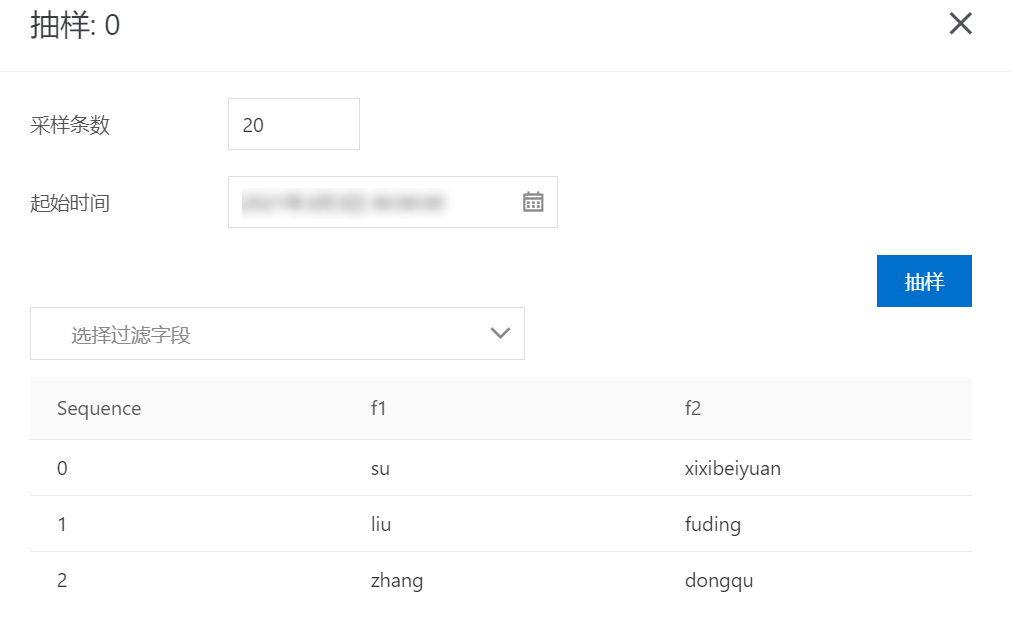
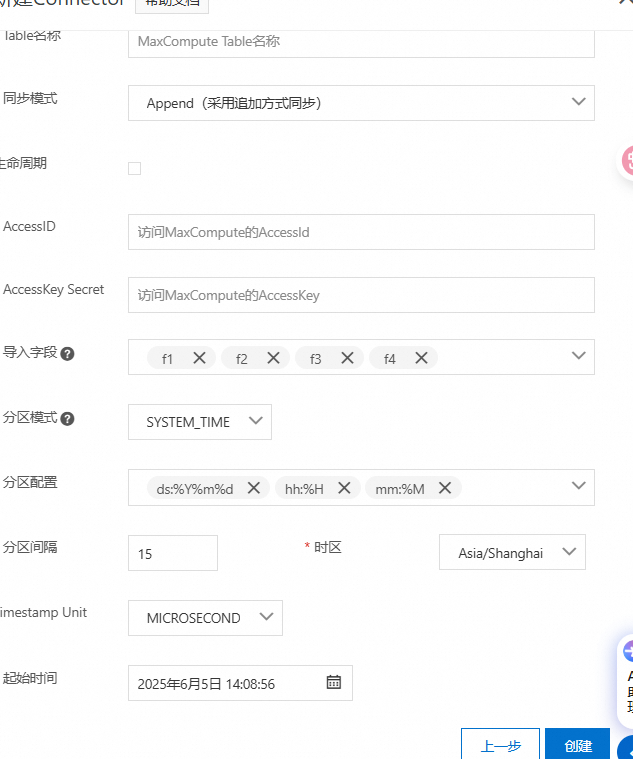
4 确认同步数据
可以从DataHub管控台查看对应同步任务的同步信息,如DoneTime, 查询MaxCompute数据结果,结果如下: 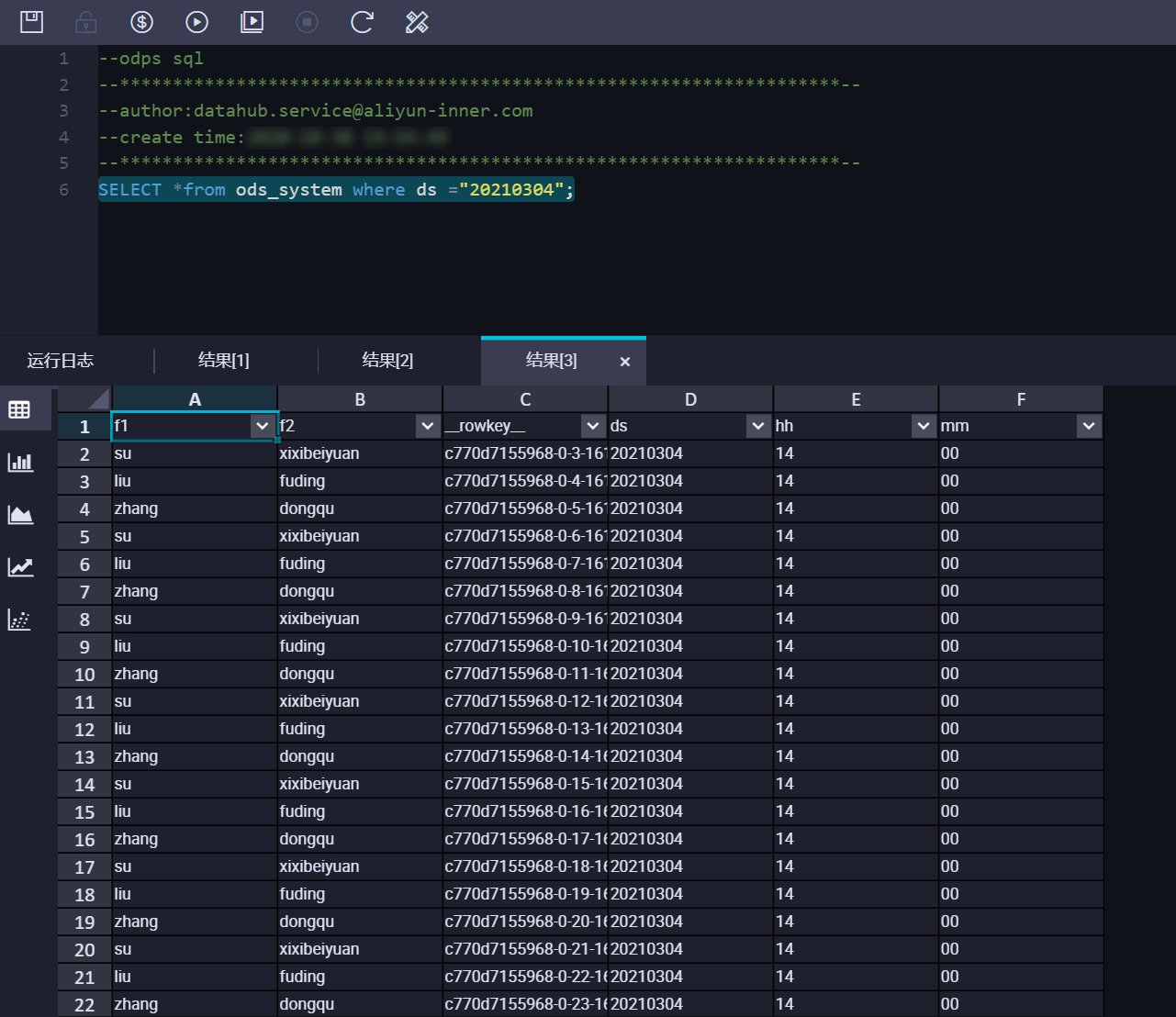 可以看到在SYSTEM_TIME模式下,DataHub会根据
可以看到在SYSTEM_TIME模式下,DataHub会根据数据写入DataHub的时间将DataHub中的数据同步到对应的分区中。
常见问题
同步到MaxCompute timestamp字段时间变为1970-01-19
原因:DataHub同步MaxCompute默认时间戳单位为微秒,用户写入时间戳为毫秒解决方案:写入DataHub时间戳以微秒方式写入。