
Kafka输出组件可以将外部数据库中读取数据写入到Kafka,或从大数据平台对接的存储系统中将数据复制推送至Kafka,进行数据整合和再加工。本文为您介绍如何配置Kafka输出组件。
前提条件
已创建Kafka数据源。具体操作,请参见创建Kafka数据源。
进行Kafka输出组件属性配置的账号,需具备该数据源的同步读权限。如果没有权限,则需要申请数据源权限。具体操作,请参见申请数据源权限。
操作步骤
在Dataphin首页顶部菜单栏,选择研发 > 数据集成。
在集成页面顶部菜单栏选择项目(Dev-Prod模式需要选择环境)。
在左侧导航栏中单击离线集成,在离线集成列表中单击需要开发的离线管道,打开该离线管道的配置页面。
单击页面右上角的组件库,打开组件库面板。
在组件库面板左侧导航栏中需选择输出,在右侧的输出组件列表中找到KAFKA组件,并拖动该组件至画布。
单击并拖动目标输入、转换或流程组件的
 图标,将其连接至当前KAFKA输出组件上。
图标,将其连接至当前KAFKA输出组件上。单击Kafka输出组件卡片中的
 图标,打开KAFKA输出配置对话框。
图标,打开KAFKA输出配置对话框。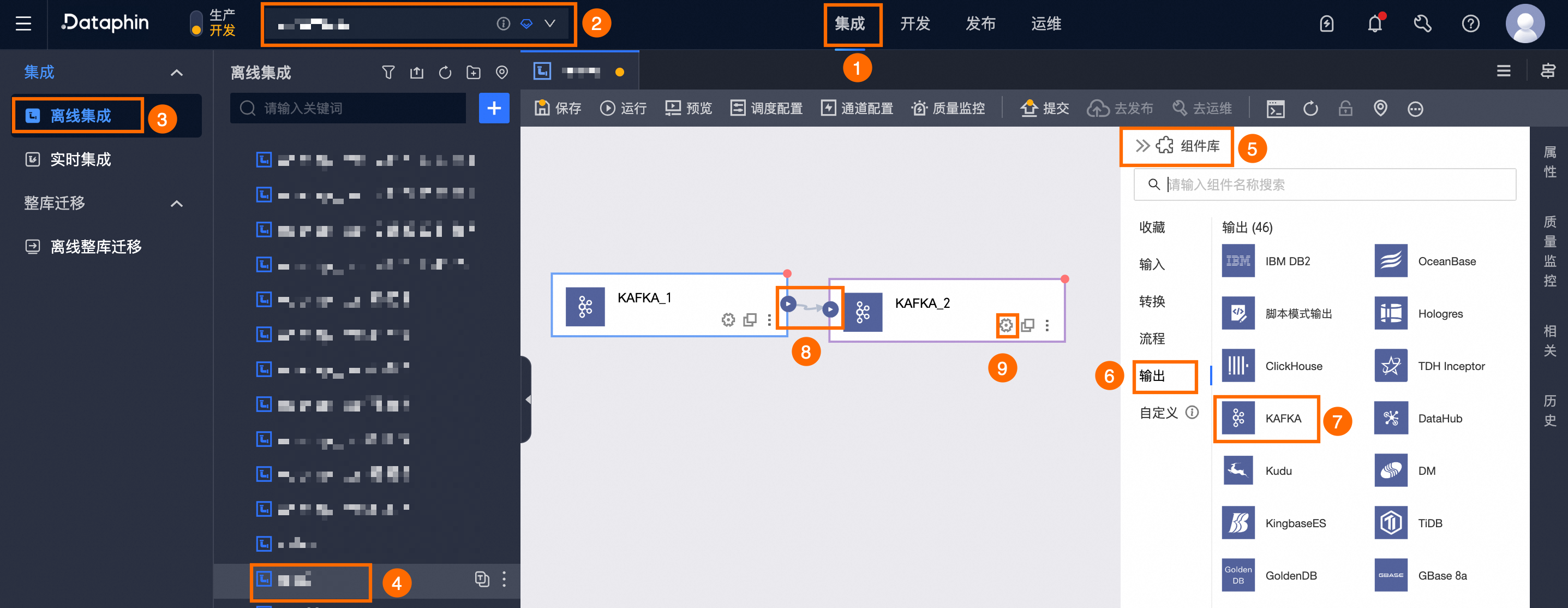
在KAFKA输出配置对话框,按照下表配置参数。
参数
描述
基本设置
步骤名称
即Kafka输出组件的名称。Dataphin自动生成步骤名称,您也可以根据业务场景修改。命名规则如下:
只能包含中文、字母、下划线(_)、数字。
不能超过64个字符。
数据源
在数据源下拉列表中,展示所有Kafka类型的数据源,包括您已拥有同步写权限的数据源和没有同步写权限的数据源。单击
 图标,可复制当前数据源名称。
图标,可复制当前数据源名称。对于没有同步写权限的数据源,您可以单击数据源后的申请,申请数据源的同步写权限。具体操作,请参见申请、续期和交还数据源权限。
如果您还没有Kafka类型的数据源,单击新建数据源,创建数据源。具体操作,请参见创建Kafka数据源。
主题
根据实际场景,选择需要的Topic。没有匹配项时,也支持根据手动输入的Topic名进行集成。 单击
 图标,可复制当前所选Topic的名称。
图标,可复制当前所选Topic的名称。如果Kafka数据源中没有所需的Topic,您可以通过一键建Topic的功能,简单快速的生成Topic。详细操作步骤如下:
单击一键建Topic,在一键建Topic对话框中配置以下参数。
Topic名称:输入Topic名称,支持所有字符。
分区数:输入大于等于1的整数,默认分区数为1。
副本数:输入大于等于1的整数,默认副本数为2。
Topic参数(非必填):输入Topic创建参数,格式为
key=value,多个参数间需换行分隔。生产环境建Topic:选中后,将同时在生产环境中新建Topic。如果生产环境已经有同名的Topic,则您无需选中生产环境建Topic。
单击新建。
键取值列
填写键取值列。
如果选择多列,会将配置的所有列序号的值用逗号连接作为写入Kafka记录的Key。
如果不选择,写入Kafka记录Key为null,数据轮流写入topic的各个分区中。
写入模式
该配置项决定将数据源端读取记录的所有列拼接作为写入Kafka记录Value的格式,可选值为text和json,默认值为text。
text:将所有列按照分隔符配置项指定分隔符拼接。
json:将所有列按照目标表字段名称拼接为JSON字符串。
说明如果配置了valueIndex,该配置项无效。
例如源端记录有三列,值为a、b和c:
当写入模式配置为text、分隔符配置为#时,写入Kafka的记录Value为字符串a#b#c。
当写入模式配置为JSON、目标表字段配置为["col1","col2","col3"]时,写入Kafka的记录Value为字符串{"col1":"a","col2":"b","col3":"c"}。
值分隔符
Value分隔符配置。
当写入模式为json时,不支持Value分隔符配置。
当写入模式为text时,支持配置单个或者多个字符作为分隔符,支持以\u0001格式配置unicode字符,支持\t、\n等转义字符。默认为\t(水平制表符),支持Value分隔符配置。
键类型和值类型
选择Kafka的Key和Value的类型。
当键取值列不选择或选择多列时,Key类型和Value类型可选项包含BYTEARRAY、STRING和KAFKA AVRO(数据源配置了schema.registry时可选择)。
当键取值列选择一列时,Key类型和Value类型可选项包含BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG、SHORT、STRING和KAFKA AVRO(数据源配置了schema.registry时可选择)。
高级配置
按需进行配置,支持以下参数:
keyfieldDelimiter:键分隔符,Kafka的键取值列为多列时的连接字符,默认为空。
valueIndex:配置Kafka Writer中作为Value的列,例如valueIndex=[0,1,2,3] ,[ ]内的数字代表输入组件的字段的seqnumber
写入模式为text时,默认将所有列拼起来作为Value,使用分隔符配置的分隔符进行分割,值类型只能选择BYTEARRAY或STRING。
写入模式为JSON时,以键值对写入JSON。
partition=0:指定写入Kafka topic指定分区的编号,是一个大于等于0的整数,默认为0。
nullKeyFormat=null:key指定的源端列值为null时,替换为该配置项指定的字符串,如果不配置不做替换。
nullValueFormat=null:当源端列值为null时,组装写入kafka记录Value时替换为该配置项指定的字符串,如果不配置不做替换。
acks=all:初始化Kafka Producer时的acks配置,决定写入成功的确认方式。值为0不进行写入成功确认,值为1确认主副本写入成功,值为all确认所有副本写入成功。默认acks=all。
keySchema: 如topic配置了schema.regisrty, 请输入key schema。默认为空。
valueSchema: 如topic配置了schema.regisrty, 请输入value schema。默认为空。
字段映射
输入字段
为您展示上游组件的输出字段。
输出字段
为您展示输出字段。 Dataphin支持通过批量添加和新建输出字段的方式配置输出字段:
批量添加:单击批量添加,支持JSON、TEXT格式批量配置。
以JSON格式批量配置,例如:
// 示例: [{"name": "user_id","type": "String"}, {"name": "user_name","type": "String"}]说明name表示引入的字段名称,type表示引入后的字段类型。 例如:
"name":"user_id","type":"String"表示把字段名为user_id的字段引入,设置字段类型为String。以TEXT格式批量配置,例如:
// 示例: user_id,String user_name,String行分隔符用于分隔每个字段的信息,默认为换行符(\n),可支持换行符(\n)、分号(;)、点(.)。
列分隔符用于分隔字段名与字段类型,默认英文逗号(,)。
新建输出字段。
单击+新建输出字段,根据页面提示填写字段及选择类型。
复制上游字段。
单击复制上游字段,系统将根据上游的字段名自动生成输出字段。
管理输出字段。
同时您也可以对已添加的字段执行如下操作:
单击操作列下的
 图标,编辑已有的字段。
图标,编辑已有的字段。单击操作列下的
 图标,删除已有的字段。
图标,删除已有的字段。
映射关系
映射关系用于将源表的输入字段和目标表的输出字段映射起来,便于后续进行数据同步。映射关系包括同名映射和同行映射。适用场景说明如下:
同名映射:对字段名称相同的字段进行映射。
同行映射:源表和目标表的字段名称不一致,但字段对应行的数据需要映射。只映射同行的字段。
单击确认,完成Kafka输出组件配置。