
离线整库迁移可用于将本地数据中心或在ECS上自建的数据库同步数据至大数据计算服务,包括MaxCompute、Hive、TDH Inceptor等数据源。本文为您介绍如何新建并配置整库迁移任务。
前提条件
已完成所需迁移的数据源创建。整库迁移支持MySQL、Microsoft SQL Server、Oracle、OceanBase等来源端的数据迁移。具体支持的数据源,请参见整库迁移支持的数据源。
功能介绍
离线整库迁移是一个提升用户效率、降低用户使用成本快捷工具。相对于离线单条管道,离线整库迁移可以批量配置离线管道,一次性完成数据库内多张数据表的同步文件的配置。
操作步骤
在Dataphin首页,在顶部菜单栏选择研发 > 数据集成。
在顶部菜单栏,选择目标项目。
在左侧导航栏,选择整库迁移 > 离线整库迁移。
在离线整库迁移页面,配置相关参数。参数及其配置说明如下表。
配置基本信息。
整库迁移文件夹名称:允许最长字符256个,不支持竖线(|)、正斜线(/)、反斜线(\)、半角冒号(:)、半角问号(?)、尖括号(<>)、星号(*)和半角引号(")。
配置数据源信息。
同步来源
参数
描述
数据源类型
选择同步来源的数据源类型。支持的数据源与数据源创建说明,请参见整库迁移支持的数据源。
Oracle数据源
Schema:支持跨Schema选表,请选择表所在的Schema,如不指定则默认为数据源中配置的Schema。
文件编码:若选择Oracle数据源,需选择Oracle的编码方式。支持UTF-8、GBK、ISO-8859-1。
Microsoft SQL Server、PostgreSQL、Amazon Redshift、Amazon RDS for PostgreSQL、Amazon RDS for MySQL、Amazon RDS for SQL Server、Amazon RDS for Oracle、Amazon RDS for DB2、PolarDB-X2.0数据源
Schema:支持跨Schema选表,请选择表所在的Schema,如不指定则默认为数据源中配置的Schema。
DolphinDB数据源
库:选择表所在的库,若不填写则使用数据源注册时填写的库。
Hive数据源
若选择Hive数据源,需要配置以下配置项。
文件编码:支持UTF-8、GBK。
Orc表压缩格式:支持zlib、hadoop-snappy、lz4、none。
Text表压缩格式:支持gzip、bzip2、lzo、lzo_deflate、hadoop_snappy、framing-snappy、zip、zlib。
Parquet表压缩格式:支持hadoop_snappy、gzip、lzo。
字段分隔符:将使用填写的分隔符写入目标表。如不填写,将默认为
\u0001。
时区
请根据数据库配置的时区选择相应的时区。数据集成在中国地区默认时区为
GMT+8,该时区不支持夏令时,如果数据库配置时区支持夏令时,如Asia/Shanghai时区,则当同步的时间数据处于夏令时的时间段,建议选择Asia/Shanghai等时区,否则同步的数据与数据库中的数据相差1小时。支持的时区包括:GMT+1、GMT+2、GMT+3、GMT+5:30、GMT+8、GMT+9、GMT+10、GMT-5、GMT-6、GMT-8、Africa/Cairo、America/Chicago、America/Denver、America/Los_Angeles、America/New York、America/Sao Paulo、Asia/Bangkok、Asia/Dubai、Asia/Kolkata、Asia/Shanghai、Asia/Tokyo、Atlantic/Azores、Australia/Sydney、Europe/Berlin、Europe/London、Europe/Moscow、Europe/Paris、Pacific/Auckland、Pacific/Honolulu。
数据源
选择来源数据源。若无所需数据源,您也可以单击新建数据源进行创建。
批量读取条数
来源数据源为Oracle、Microsoft SQL Server、OceanBase、IBM DB2、PostgreSQL、Amazon Redshift、Amazon RDS for PostgreSQL、Amazon RDS for MySQL、Amazon RDS for SQL Server、Amazon RDS for Oracle、Amazon RDS for DB2、DolphinDB时,支持配置批量读取条件,即一次性读取数据的条数,默认为1024条。
同步目标
参数
描述
数据源类型
选择目标数据源类型。支持的数据源与数据源创建说明,请参见整库迁移支持的数据源。
说明同步至AnalyticDB for PostgreSQL数据源,系统每日会为目标表创建一个日期分区。
若有其他分区需要,可以在生成管道后,单击单条管道修改分区相关的准备语句。
数据源
选择目标数据源。若无所需数据源,您也可以单击新建数据源进行创建。支持的数据源与数据源创建说明,请参见整库迁移支持的数据源。
TDH Inceptor、ArgoDB目标数据源类型。
需要配置存储格式。
TDH Inceptor:支持PARQUET、ORC、TEXTFILE存储格式。
ArgoDB:支持PARQUET、ORC、TEXTFILE、HOLODESK存储格式。
Hive目标数据源类型。
数据湖表格式选择为Hudi、Iceberg或不选择时,所需配置的配置项不同。
说明仅当所选数据源或当前项目计算源启用了数据湖表格式,并选择了Iceberg或Hudi时,此处的数据湖表格式方可选择Iceberg或Hudi。
数据湖表格式选择为不选择(即Hive)
是否外部表:单击开关来选择是否为外部表,默认为关闭。
存储格式:支持PARQUET、ORC、TEXTFILE存储格式。
文件编码:Hive的存储格式为ORC,支持配置文件编码。包括UTF-8和GBK。
压缩格式:
ORC存储格式:支持zlib、hadoop-snappy、none。
PARQUET存储格式:支持gzip、hadoop-snappy。
TEXTFILE存储格式:gzip、bzip2、lzo、lzo_deflate、hadoop-snappy、zlib。
性能配置:Hive的存储格式为ORC,支持配置性能配置。输出表格式为ORC且字段较多的场景下,内存足够时可尝试调大该配置提高写入性能,内存不足时可尝试调小该配置减少GC时间提高写入性能。默认
{"hive.exec.orc.default.buffer.size":16384},单位字节(Byte),建议不要配置超过262144字节(256k)。字段分隔符:TEXTFILE存储格式可以配置字段分隔符。系统将使用填写的分隔符写入目标表,如不填写。默认为
\u0001。字段分隔符处理:TEXTFILE存储格式可以配置字段分隔符处理。如数据中存在默认或自行配置的字段分隔符,可选择处理策略,防止数据写入错误。包括保留、去除、替换为。
行分隔符处理:TEXTFILE存储格式可以配置行分隔符处理。如数据中存在换行符(
\r\n、\n),可选择处理策略,防止数据写入错误。包括保留、去除、替换为。开发数据源Location:Dev-Prod模式项目可以指定开发数据源建表语句中表存储的Location。例如,
hdfs://path_to_your_extemal_table。生产数据源Location:Dev-Prod模式项目可以指定生产数据源建表语句中表存储的Location。例如,
hdfs://path_to_your_extemal_table。说明Basic模式项目仅需要填写一个数据源Location。
数据湖表格式选择为Hudi
执行引擎:若所选数据源已开启Spark,则执行引擎支持选择Spark或Hive;若所选数据源未开启Spark,则仅支持选择Hive。
Hudi表类型:可选择MOR(merge on read)或COW(copy on write),默认为MOR(merge on read)。
扩展属性:输入Hudi官方支持的配置属性,格式为
k=v。
数据湖表格式选择为Iceberg
执行引擎:若所选数据源已配置Spark,则展示并默认选择Spark;若未配置,则仅展示并选择Hive。
是否外部表:单击开关来选择是否为外部表,默认为关闭。
存储格式:支持PARQUET、ORC、TEXTFILE存储格式。
文件编码:Hive的存储格式为ORC,支持配置文件编码。包括UTF-8和GBK。
压缩格式:
ORC存储格式:支持zlib、hadoop-snappy、none。
PARQUET存储格式:支持gzip、hadoop-snappy。
TEXTFILE存储格式:gzip、bzip2、lzo、lzo_deflate、hadoop-snappy、zlib。
性能配置:Hive的存储格式为ORC,支持配置性能配置。输出表格式为ORC且字段较多的场景下,内存足够时可尝试调大该配置提高写入性能,内存不足时可尝试调小该配置减少GC时间提高写入性能。默认
{"hive.exec.orc.default.buffer.size":16384},单位字节(Byte),建议不要配置超过262144字节(256k)。字段分隔符:TEXTFILE存储格式可以配置字段分隔符。系统将使用填写的分隔符写入目标表,如不填写。默认为
\u0001。字段分隔符处理:TEXTFILE存储格式可以配置字段分隔符处理。如数据中存在默认或自行配置的字段分隔符,可选择处理策略,防止数据写入错误。包括保留、去除、替换为。
行分隔符处理:TEXTFILE存储格式可以配置行分隔符处理。如数据中存在换行符(
\r\n、\n),可选择处理策略,防止数据写入错误。包括保留、去除、替换为。开发数据源Location:Dev-Prod模式项目可以指定开发数据源建表语句中表存储的Location。例如,
hdfs://path_to_your_extemal_table。生产数据源Location:Dev-Prod模式项目可以指定生产数据源建表语句中表存储的Location。例如,
hdfs://path_to_your_extemal_table。说明Basic模式项目仅需要填写一个数据源Location。
数据湖表格式选择为Paimon时
执行引擎:当前仅支持Spark。
Paimon表类型:可选择MOR(merge on read)、COW(copy on write)或MOW(merge on write),默认为MOR(merge on read)。
扩展属性:输入Hudi官方支持的配置属性,格式为
k=v。
AnalyticDB for PostgreSQL、GaussDB(DWS)目标数据源类型。
需要配置以下配置项。
重要冲突解决策略仅在AnalyticDB for PostgreSQL内核版本高于4.3时的Copy模式下有效,内核低于4.3或不明版本时请谨慎选择,避免造成任务失败。
冲突解决策略:copy加载策略支持设置冲突解决策略,包括冲突时报错和冲突时覆盖。
Schema:支持跨Schema选表,请选择表所在的Schema,如不指定则默认为数据源中配置的schema。
Lindorm目标数据源类型。
需要配置以下配置项。
存储格式:支持PARQUET、ORC、TEXTFILE、ICEBERG存储格式。
压缩格式:不同存储格式支持不同压缩格式。
ORC存储格式:支持zlib、hadoop-snappy、lz4、none。
PARQUET存储格式:支持gzip、hadoop-snappy。
TEXTFILE存储格式:支持gzip、gzip2、lzo、lzo_deflate、hadoop-snappy、zlib。
开发数据源Location:Dev-Prod模式项目可指定开发环境建表语句中表存储的根路径Location,如:
/user/hive/warehouse/xxx.db。生产数据源Location:Dev-Prod模式项目可指定生产环境建表语句中表存储的根路径Location,如:
/user/hive/warehouse/xxx.db。
MaxCompute数据源
MaxCompute表类型:可选择普通表或Delta表。
Databricks数据源
Schema:支持跨Schema选表,请选择表所在的Schema,如不指定则默认为数据源中配置的schema。
加载策略
Hive(数据湖表格式选择为Hudi或Paimon时)、TDH Inceptor、ArgoDB、StarRocks、Oracle、MaxCompute、Lindorm(计算引擎)目标数据源的加载策略支持覆盖数据、追加数据和更新数据。
覆盖数据:如果同步的数据存在,先删除已有数据,再写入新增数据。
追加数据:如果同步的数据存在,不进行覆盖,新增数据进行追加同步。
更新数据:按照主键进行更新,若主键不存在则插入新增数据。
说明若MaxCompute表类型选择为普通表,则加载策略可选择追加数据或覆盖数据;若MaxCompute表类型选择为Delta表,则加载策略可选择更新数据或覆盖数据。
Hive(数据湖表格式选择为不选择时)目标数据源的加载策略支持仅覆盖集成任务写入的数据、追加数据和覆盖所有数据。
AnalyticDB for PostgreSQL、GaussDB(DWS)目标数据源的加载策略支持insert和copy。
insert:数据逐条同步。适用于数据量较小的情况,可以提高同步数据的准确性和完整性。
copy:数据通过文件形式同步。适用于数据量较大的情况,可以提高同步速度。
批量写入数据量
Hive(数据湖表格式选择为Hudi时)、AnalyticDB for PostgreSQL和StarRocks目标数据源支持配置批量写入数据量,即一次性写入的数据量大小,可同时设置批量写入条数,写入时按两个配置中先达到上限的量写入。
批量写入条数
Hive(数据湖表格式选择为Hudi时)、AnalyticDB for PostgreSQL和StarRocks目标数据源支持配置批量写入条数,即一次性写入数据的条数。
配置数据同步。
同步来源非FTP。
选中来源表后,将生成对应的目标表,名称默认与来源表名一致。若有名称转换配置,则为转换后的名称。
说明若来源端数据源选择为外部数据源,且未配置采集任务(即获取不到元数据),则数据同步中元数据信息为空,可前往元数据中心配置采集任务。

区块
说明
①操作区
已勾选、未勾选:可以根据已勾选和未勾选筛选来源表。
搜索来源表:支持通过表名称搜索当前来源表,大小写敏感。
高级搜索:页面最多展示10000张表,高级搜索功能支持在数据库所有表中批量查找与搜索表名。单击高级搜索,在高级搜索对话框中,配置高级搜索参数。
配置搜索方式。
支持精确输入表名和模糊搜索方式搜索来源。
精确输入表名:需要在搜索内容中批量输入表名。表名分隔符为配置的分隔符,默认为
\n,可以自行定义。模糊搜索:需要在搜索内容中填写表名关键字。系统将根据表名关键字进行模糊搜索。
输入搜索内容。
搜索方式不同,输入的搜索内容不同。
精确输入表名:可以批量输入表名查找表,输入内容请使用配置的分隔符分隔表名。
模糊搜索:可以输入表名称的关键字进行搜索。
搜索结果。
配置搜索方式和搜索内容后单击搜索将为您展示搜索结果。在搜索结果表内选择需要操作的表,并选择操作类型,包括批量选中或批量取消选中。单击确定,来源表将根据操作类型选中或取消选中。
自动删除数据源中同名表:选中后Dataphin会先自动删除数据源中已经存在的,且与整库生成同名的表,再重新自动创建表。
重要如为项目数据源,则会同时删除生产与开发环境中的同名表,请谨慎操作。
名称转化配置:非必选,名称转换配置可将您来源表的表名、字段名进行替换或过滤数据后进行同步。
单击名称转换配置。
在名称转换配置页面,配置转换规则。
表名转换规则:单击新建规则,在规则项中填写来源表待替换字符串和目标表替换字符串。如:需将表名
datawork替换为dataphin,则待替换字符串为work,替换字符串为phin。表名前缀:在表名前缀输入框中填写目标库表的表名前缀。同步时将自动生成目标库表的前缀,如:表名前缀填写
pre_,表名为dataphin,则生成的目标库表名为pre_dataphin。表名后缀:在表后前缀输入框中填写目标库表的表名后缀。同步时将自动生成目标库表的后缀,如:表名后缀填写
_prod,表名为dataphin,则生成的目标库表名为pre_dataphin_prod。字段名称规则:单击新增规则,在规则项中填写来源字段替换字符串和目标字段替换字符串。如:需要将字段名
datawork替换为dataphin,则待替换字符为work,替换的字符为phin。
配置完成后单击确定,对应目标库表将展示转换后的目标库表名。
说明替换字符及表名前后缀中的英文字符将自动转换为小写。
校验表名:校验目标数据库中是否存在当前的目标表名。
②来源表
在来源表列表中选择需同步的来源表。
③对应目标库表
选择来源表后,生成对应目标库表,名称默认与源表名一致。若有名称转换配置,则为转换后的名称。
说明目标表名仅支持英文字母、数字及下划线。如来源表名含有其他字符,请配置表名转换规则。
④管道统计
当前已选择的管道数。
同步来源为FTP。
请先单击下载Excel模板并按照模板指引填写模板后上传模板文件。请严格按照模板文件的格式填写,否则会导致文件解析失败。
说明可上传单个.xlsx文件或单个压缩包(可以包含一个或多个.xlsx文件),压缩格式仅支持zip类型。文件需小于50M。
文档上传完成后,单击解析文件。
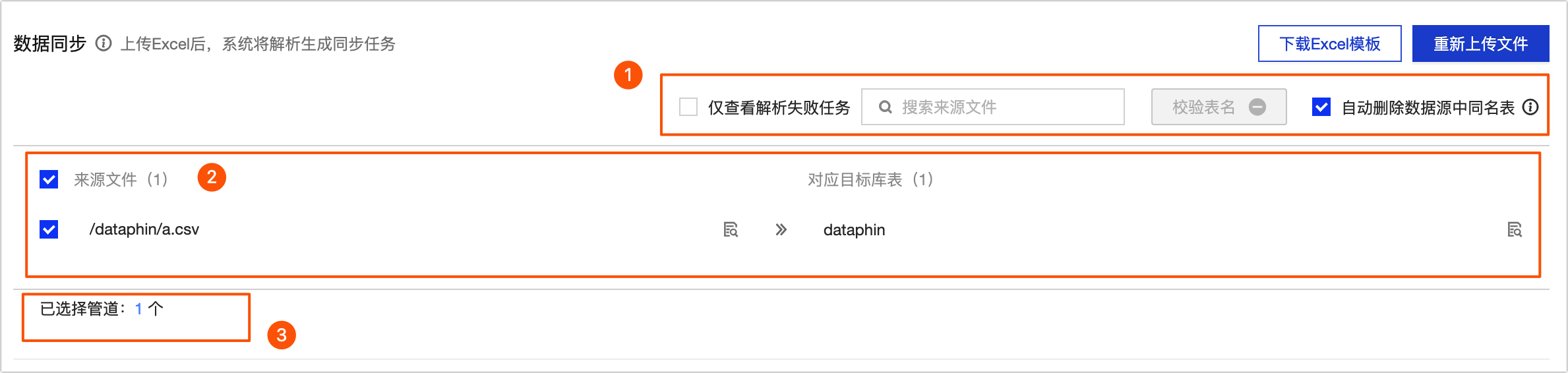
参数
描述
①操作区
搜索来源文件:支持通过文件名称搜索当前来源文件。
仅查看解析失败任务:列表将仅展示解析失败的任务。
自动删除数据源中同名表:选中后会先自动删除数据源中已存在的与整库生成的目标表同名的表,再重新自动创建。
重要如为项目数据源,则会同时删除生产与开发环境中的同名表,请谨慎操作。
校验表名:校验目标数据库中是否存在当前的目标表名。
②来源文件与对应目标表
来源文件:在来源文件列表中选择需同步的来源文件。
对应目标表:解析文件后,将根据模板文件生成对应目标库表。
③管道统计
当前已选择的管道数。
任务名配置
生成方式,即离线整库迁移任务名的生成方式,可选择系统默认或自定义规则。
参数
描述
生成方式
系统默认
按照系统默认的命名方式生成任务名。
自定义规则
重要在配置自定义任务名规则前,请先完成同步来源数据源和同步目标数据源的选择,否则无法配置自定义任务名规则。
默认规则:已选择同步来源和同步目标的数据源,且任务名配置的生成方式选择自定义规则后,系统会在任务名命名规则文本框中生成一个默认规则。任务名默认规则为
${来源数据源类型}2${目标数据源类型}_${source_table_name}。例如当前整库迁移任务来源数据源类型为MySQL,目标数据源类型为Oracle,来源表中第一个表名为
source_table_name1,则默认任务名命名规则为MySQL2Oracle_${source_table_name},任务名预览为MySQL2Oracle_source_table_name1。说明此处的默认规则不等同于系统默认的生成方式。
自定义规则:在左侧任务名命名规则文本框内输入命名规则,可删除已有的默认规则,或在默认规则的基础上做修改。
名称不支持竖线(|)、正斜线(/)、反斜线(\)、半角冒号(:)、半角问号(?)、尖括号(<>)、星号(*)和半角引号("),长度不超过256个字符,支持单击右侧可添加元数据列表中的有效元数据名进行复制。
说明命名规则中添加元数据后,任务名预览中元数据的取值都取自于来源表列表中第一张表的信息。
设置同步方式和数据过滤。
参数
描述
同步方式
选择同步方式。同步方式设置包括每日同步、单次同步、每日同步+单次同步。
每日同步:系统将生成每日调度的集成管道周期任务,通常用于同步每日的增量或全量数据。
单次同步:系统将生成集成管道手动任务,通常用于同步历史全量数据。
每日同步+单次同步:系统将同时生成每日调度的周期任务和手动任务,通常用于单次全量后每日增量或全量的数据同步场景。
说明来源库为FTP时,不支持每日同步+单次同步。
目标表创建为
选择创建的目标表类型。包括分区表和非分区表。不同的同步方式目标表创建规则如下:
每日同步:选择分区表,目标表将创建为分区表,默认写入
ds=${bizdate}的分区;选择非分区表,目标表将创建为非分区表。单次同步:选择分区表,目标表将创建为分区表,需要配置单次同步写入分区参数,支持常量或分区参数。例如,常量
20230330、分区参数ds=${bizdate};选择非分区表,目标表将创建为非分区表。每日同步+单次同步:默认为分区表,不支持选择。需要配置单次同步写入分区参数,支持常量或分区参数。例如,常量
20230330、分区参数ds=${bizdate}。说明目前仅支持将单次同步的数据写入对应目标表的一个指定分区内。如需将全量历史数据写入对应的不同分区,可在单次同步后使用SQL任务处理写入目标表相应分区,或者选择每日同步增量数据,然后进行补数据操作补全历史分区。
数据过滤
来源库非HIve、MaxCompute

每日同步过滤条件:同步方式包含每日同步时,可以配置每日同步时的过滤条件。如配置了
ds=${bizdate},任务运行时会抽取来源库中ds=${bizdate}的所有数据写入指定的目标表分区。单次同步过滤条件:同步方式包含单次同步时,可以配置单次同步过滤条件。如配置了
ds=<${bizdate},任务运行时会抽取来源库中ds=<${bizdate}的所有数据写入指定的目标表(分区)。
来源库为Hive、MaxCompute
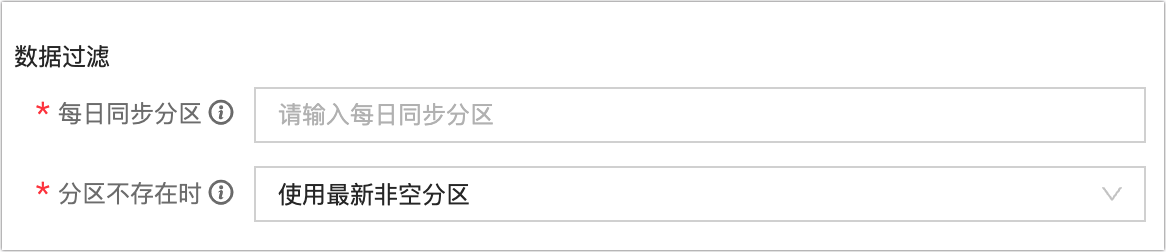
每日同步分区:来源库为Hive、MaxCompute时,必须在此指定分区表每日读取的分区。支持读取单分区,可填写
ds=${bizdate};或多分区,如填写/*query*/ds>=20230101 and ds<=20230107。单次同步分区:来源库为Hive、MaxCompute且同步方式包含单次同步时,必须在此指定分区表单次读取的分区。支持读取单分区,可填写
ds=${bizdate};或多分区,可填写/*query*/ds>=20230101 and ds<=20230107。分区不存在时:可选择以下策略处理当指定分区不存在时的场景:
置任务失败:终止该任务并置失败。
置任务成功:任务正常运行成功,无写入的数据。
使用最新非空分区:来源库为MaxCompute时,支持使用该表当前的最新非空分区(max_pt)作为需同步的分区,如该表不存在任何有数据的分区,则任务报错并置失败。Hive来源库不支持配置。
说明来源库为FTP时,不支持数据过滤配置。
参数配置
来源库为FTP时,支持在来源文件路径中使用参数。
调度运行配置
参数
描述
调度配置
选择调度配置。调度配置包括同时调度和分批调度。
同时调度:指每日零点(调度时区的零点)同时执行源库所选择表的同步任务。
分批调度:指将源库所选择的表按批次的方式逐批执行同步任务。支持0~23小时周期和最大142条同步数量。例如,如需同步100张表,设置了每隔2小时同步10张表则需要20个小时才能完成一个同步周期任务的启动。一个同步间隔周期不能超过24小时。
运行超时
同步任务运行时,若单次运行总时长超过设置阈值仍未完成,会自动终止并置为失败。支持选择系统配置或自定义。
系统配置:使用系统默认配置的超时时间。更多信息,请参见运行配置。
自定义:自定义超时时间。支持输入0-168之间的数字(不包括0),保留2位小数。
失败自动重跑
该任务实例、补数据实例运行失败,会按照配置决定是否自动重跑。重跑次数支持输入[0,10]之间的整数,重跑间隔支持输入[1,60]之间的整数。
上游依赖
单击添加依赖,可添加物理节点或逻辑表节点作为该节点的上游依赖。如不配置,则默认配置租户的虚拟根节点作为上游依赖,您也可手动添加一个虚拟节点作为该节点的依赖对象。适用于需统一补数据等场景。
资源配置
调度资源组:整库迁移集成任务调度运行时需要消耗调度资源。整库迁移集成任务为独享资源任务,您可指定每个整库迁移集成任务生成的实例可使用的调度资源组,实例调度时会占用指定资源组的资源配额,如果指定的资源组可用资源不足,则会进入等待调度资源状态。不同资源组之间的资源相互隔离互不影响,以保证调度稳定性。
设置调度资源组仅支持选择应用场景为任务日常调度且与当前任务所属项目有关联关系的资源组。具体操作,请参见资源组配置。
说明Basic项目支持配置调度资源组,Dev-Prod项目支持配置开发任务调度资源组和生产任务调度资源组。
如果选择了项目默认资源组,将根据项目默认资源组的配置修改自动更新。
生产/开发环境任务调度均默认使用项目默认调度资源组,支持修改为当前任务所在项目绑定可使用的其他资源组(包括注册调度集群的资源组)。
完成参数的配置后,单击生成管道,完成离线整库迁移管道的创建。
在运行结果区域,可查看管道任务的运行结果,包括来源表、目标表、同步方式、任务状态及备注信息。

管道生成后,在离线集成目录下将生成本次离线整库迁移任务的文件夹,文件夹中包含对应的离线管道任务,您可以对生成的离线管道任务进行配置并发布。详情请参见配置离线管道任务属性。
若部分表创建失败或后续有需要新增的表,可针对创建失败或新增的表进行手动创建离线管道任务或离线脚本任务,再将其移动至离线整库迁移的文件夹中。操作如下:
单击目标离线整库迁移文件夹后的
 按钮。选择新建离线管道或离线脚本。
按钮。选择新建离线管道或离线脚本。在创建离线管道或创建离线脚本对话框中完成相关配置项后,单击确定。相关配置项及其说明请参见通过单条管道创建集成任务、通过脚本模式创建集成任务。
说明创建完成后的离线管道任务和离线脚本任务将位于当前离线整库迁移的文件夹中。
不支持将文件夹移入或移出离线整库迁移的文件夹中。
离线集成目录中需要移动的离线管道任务和离线脚本任务,可通过单击其名称后的
 按钮,选择移动,在移动文件的对话框中选择目录来完成移动。支持移动至离线整库迁移文件夹中。
按钮,选择移动,在移动文件的对话框中选择目录来完成移动。支持移动至离线整库迁移文件夹中。若删除整库迁移的文件夹,将同时删除该文件夹下包含的所有任务,包括离线管道任务和离线脚本任务。
后续步骤
完成离线整库迁移任务的创建和发布后,您可以在运维中心查看并运维集成任务,保证任务的正常运行。更多信息,请参见运维中心。