
Amazon RDS for PostgreSQL输出组件用于向Amazon RDS for PostgreSQL数据源写入数据。同步其他数据源的数据至Amazon RDS for PostgreSQL数据源的场景中,完成源数据的信息配置后,需要配置Amazon RDS for PostgreSQL输出组件的目标数据源。本文为您介绍如何配置Amazon RDS for PostgreSQL输出组件。
前提条件
已创建Amazon RDS for PostgreSQL数据源。更多信息,请参见创建Amazon RDS for PostgreSQL数据源。
进行Amazon RDS for PostgreSQL输出组件属性配置的账号,需具备该数据源的同步写权限。如果没有权限,则需要申请数据源权限,更多信息,请参见申请、续期和交还数据源权限。
操作步骤
在Dataphin首页顶部菜单栏,选择研发 > 数据集成。
在集成页面顶部菜单栏选择项目(Dev-Prod模式需要选择环境)。
在左侧导航栏中单击离线集成,在离线集成列表中单击需要开发的离线管道,打开该离线管道的配置页面。
单击页面右上角的组件库,打开组件库面板。
在组件库面板左侧导航栏中需选择输出,在右侧的输出组件列表中找到Amazon RDS for PostgreSQL组件,并拖动该组件至画布。
单击并拖动目标输入组件的
 图标,将其连接至当前Amazon RDS for PostgreSQL输出组件上。
图标,将其连接至当前Amazon RDS for PostgreSQL输出组件上。单击Amazon RDS for PostgreSQL输出组件卡片中的
 图标,打开Amazon RDS for PostgreSQL输出配置对话框。
图标,打开Amazon RDS for PostgreSQL输出配置对话框。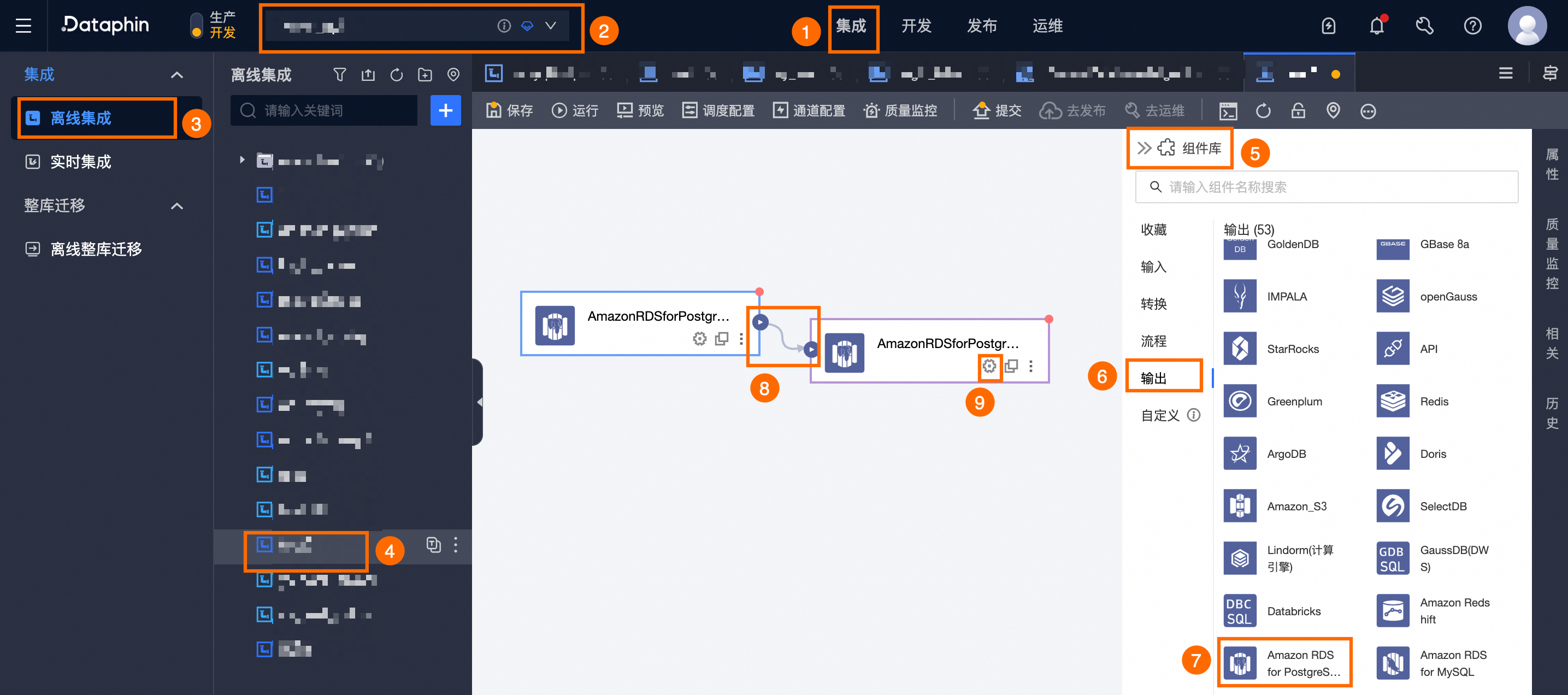
在Amazon RDS for PostgreSQL输出配置对话框中,配置以下参数。
参数
描述
基本设置
步骤名称
即Amazon RDS for PostgreSQL输出组件的名称。Dataphin自动生成步骤名称,您也可以根据业务场景修改。命名规则如下:
只能包含中文、字母、下划线(_)、数字。
长度不超过64个字符。
数据源
在数据源下拉列表中,展示所有Amazon RDS for PostgreSQL类型的数据源,包括您已拥有同步写权限的数据源和没有同步写权限的数据源。单击
 图标,可复制当前数据源名称。
图标,可复制当前数据源名称。对于没有同步写权限的数据源,您可以单击数据源后的申请,申请数据源的同步写权限。具体操作,请参见申请数据源权限。
如果您还没有Amazon RDS for PostgreSQL类型的数据源,单击
 新建图标,创建数据源。具体操作,请参见创建Amazon RDS for PostgreSQL数据源。
新建图标,创建数据源。具体操作,请参见创建Amazon RDS for PostgreSQL数据源。
Schema(非必选)
支持跨Schema选表,请选择表所在的Schema,如不指定则默认为数据源中配置的Schema。
表
选择输出数据的目标表。 可输入表名关键字进行搜索,或输入准确表名后单击精准查找。选择表后,系统将自动进行表状态检测。单击
 图标,可复制当前所选表的表名称。
图标,可复制当前所选表的表名称。如果Amazon RDS for PostgreSQL数据源中没有数据同步的目标表,则您可以通过一键建表的功能,简单快速的生成目标表。详细操作步骤如下:
单击一键建表。Dataphin会自动为您匹配创建目标表的代码,包括目标表名称(默认为来源表名)、字段类型(基于Dataphin字段做了初步的转换)等信息。
您可以根据业务情况修改创建目标表的SQL脚本后,单击新建。
目标表新建成功后,Dataphin自动将新建的目标表作为输出数据的目标表。一键生成目标表用于为开发环境、生产环境创建数据同步的目标表。Dataphin默认为您选中生产环境建表,如果生产环境已经有同名且结构相同的数据表,则您无需勾选生产环境建表。
说明如果开发环境或生产环境存在同名的表,单击新建后,Dataphin会报已存在该表的错误。
没有匹配项时,也支持根据手动输入的表名进行集成。
加载策略
选择数据写入目标表的策略。加载策略包括:
追加数据(insert into):当主键/约束冲突时,会提示脏数据错误。
主键冲突时更新(on conflict do update set):当主键/约束冲突时,会在已存在的记录上更新映射字段的数据。
同步写入
主键更新语法非原子操作,若写入数据存在主键重复,则需开启同步写入,否则使用并行写入,同步写入性能低于并行写入。
说明仅当加载策略选择主键冲突时更新时,支持配置此项。
批量写入数据量(非必填)
一次性写入的数据量大小,可同时设置批量写入条数,写入时系统将按两个配置中先达到上限的量进行写入,默认32M。
批量写入条数(非必填)
默认2048条。数据同步写入时,采用攒批写入策略,其中设定的参数包括批量写入条数和批量写入数据量。
当读取到的数据量累积至设定的任一上限(即达到批量写入的数据量或条数限制)时,系统将认为已攒满一批数据,并立即将这批数据一次性写入目标端。
建议设置批量写入的数据量为32MB,对于批量插入的条数上限,可以根据单条记录的实际大小灵活调整,通常设定为一个较大值以充分利用批次写入的优势。例如,若单条记录大小约为1KB,可将批量插入字节大小设为16MB,同时考虑到这一条件,将批量插入条数设定为大于16MB除以单条记录大小1KB的结果(即大于16384条),这里假设设置为20000条。如此配置后,系统将会依据批量插入的字节大小来触发批次写入操作,每当累积的数据量达到16MB时,就会执行一次写入动作。
准备语句(非必填)
数据导入前对数据库执行的SQL脚本。
比如为了满足服务的持续可用性,当前步骤写数据执行前先创建目标表Target_A,执行写入到目标表Target_A,当前步骤写数据执行完成后,对数据库中持续提供服务的表Service_B重命名成Temp_C,然后将表Target_A重命名为Service_B,最后删除Temp_C。
结束语句(非必填)
数据导入后对数据库执行的SQL脚本。
字段映射
输入字段
根据上游的输出,为您展示输入字段。
输出字段
为您展示输出字段。支持进行以下操作:
字段管理:单击字段管理选择输出字段。
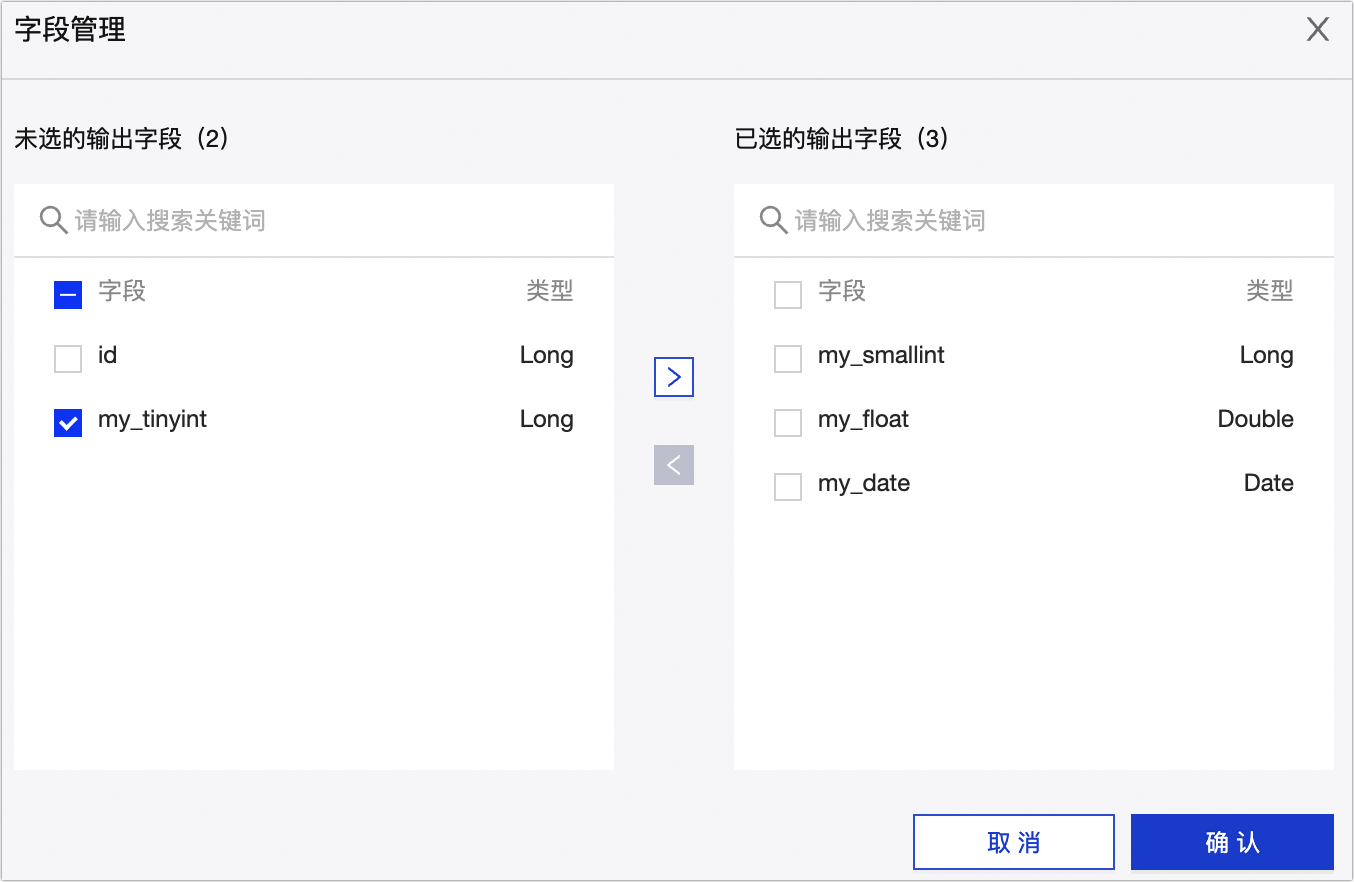
单击
 图标,将已选的输入字段移入未选的输入字段。
图标,将已选的输入字段移入未选的输入字段。单击
 图标,将未选的输入字段移入已选的输入字段。
图标,将未选的输入字段移入已选的输入字段。
批量添加:单击批量添加,支持JSON、TEXT格式、DDL格式批量配置。
以JSON格式批量配置,例如:
// 示例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]说明name表示引入的字段名称,type表示引入后的字段类型。例如,
"name":"user_id","type":"String"表示把字段名为user_id的字段引入,设置字段类型为String。以TEXT格式批量配置,例如:
// 示例: user_id,String user_name,String行分隔符用于分隔每个字段的信息,默认为换行符(\n),可支持换行符(\n)、半角分号(;)、半角句号(.)。
列分隔符用于分隔字段名与字段类型,默认为半角逗号(,)。
以DDL格式批量配置,例如:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
新建输出字段:单击+新建输出字段,根据页面提示填写字段并选择类型。当前行完成配置后,单击
 图标保存。
图标保存。
映射关系
根据上游的输入和目标表的字段,可以手动选择字段映射。快速映射包括同行映射和同名映射。
同名映射:对字段名称相同的字段进行映射。
同行映射:源表和目标表的字段名称不一致,但字段对应行的数据需要映射。只映射同行的字段。
单击确认,完成Amazon RDS for PostgreSQL输出组件的属性配置。