配置Lindorm(计算引擎)输出组件,可以将外部数据库中读取的数据写入到Lindorm(计算引擎),或从大数据平台对接的存储系统中将数据复制推送至Lindorm(计算引擎),进行数据整合和再加工。本文为您介绍如何配置Lindorm(计算引擎)输出组件。
前提条件
已创建Lindorm(计算引擎)数据源。具体操作,请参见创建Lindorm(计算引擎)数据源。
进行Lindorm(计算引擎)输出组件属性配置的账号,需具备该数据源的同步写权限。如果没有权限,则需要申请数据源权限。具体操作,请参见申请数据源权限。
操作步骤
在Dataphin首页顶部菜单栏,选择研发 > 数据集成。
在集成页面顶部菜单栏选择项目(Dev-Prod模式需要选择环境)。
在左侧导航栏中单击离线集成,在离线集成列表中单击需要开发的离线管道,打开该离线管道的配置页面。
单击页面右上角的组件库,打开组件库面板。
在组件库面板左侧导航栏中需选择输出,在右侧的输出组件列表中找到Lindorm(计算引擎)组件,并拖动该组件至画布。
单击并拖动目标上游组件的
 图标,将其连接至当前Lindorm(计算引擎)输出组件上。
图标,将其连接至当前Lindorm(计算引擎)输出组件上。单击Lindorm(计算引擎)输出组件卡片中的
 图标,打开Lindorm(计算引擎)输出配置对话框。
图标,打开Lindorm(计算引擎)输出配置对话框。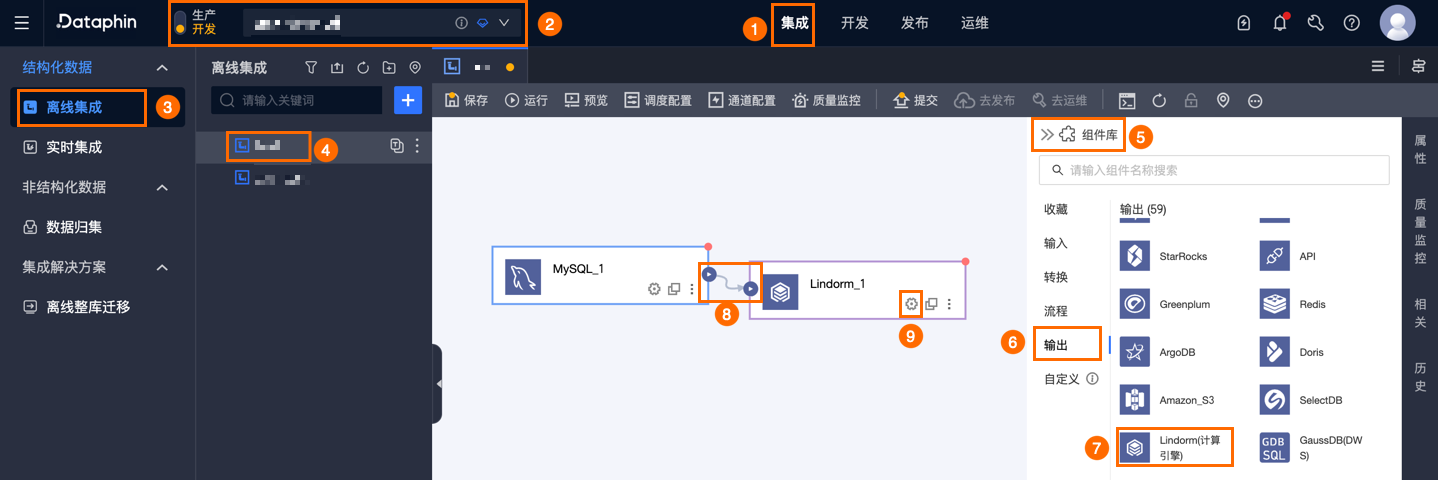
在Lindorm(计算引擎)输出配置对话框中,配置参数。
参数
描述
基本设置
步骤名称
Lindorm(计算引擎)输出组件的名称。Dataphin自动生成步骤名称,您也可以根据业务场景修改。命名规则如下:
只能包含中文、字母、下划线(_)、数字。
不能超过64个字符。
数据源
在数据源下拉列表中,为您展示当前Dataphin中所有的Lindorm(计算引擎)类型数据源,包括您是否拥有同步写权限的数据源。 单击
 图标,可复制当前数据源名称。
图标,可复制当前数据源名称。对于没有同步写权限的数据源,您可以单击数据源后的申请,申请数据源的同步写权限。具体操作,请参见申请数据源权限。
如果您还没有Lindorm(计算引擎)类型的数据源,单击新建,创建数据源。具体操作,请参见创建Lindorm(计算引擎)数据源。
表
选择输出数据的目标表。 单击
 图标,可复制当前所选表的表名称。重要
图标,可复制当前所选表的表名称。重要表Schema发生变更时需要重新配置管道任务。
文件编码
支持UTF-8和GBK。
加载策略
支持追加数据和覆盖所有数据。
追加数据:直接向目标表追加写入数据。
覆盖所有数据:先删除目标表或配置分区下的所有数据,再写入新数据。
压缩格式
非必填项,如果文件有压缩,请选择对应的压缩格式,以便Dataphin进行解压处理,包括zlib、hadoop-snappy、lz4、none。ORC表默认zlib压缩格式,其他格式表无默认格式。
性能配置
输出表格式为ORC且字段较多的场景下,内存足够时可尝试调大该配置以提高写入性能,内存不足时可尝试调小该配置以减少GC时间提高写入性能。默认
{"hive.exec.orc.default.buffer.size":16384},单位字节,建议不要配置超过262144个字节(256k)。分区
非iceberg存储格式的分区表,必须配置固定的要写入的静态分区,例如,
hh=xx,mm=xx;iceberg存储格式的分区表,支持写入动态分区,即分区可不配置,但是字段映射要映射分区字段,如果此处配置了静态分区,则写入分区以此为准。准备语句
数据导入前对数据库执行的SQL脚本。
结束语句
数据导入后对数据库执行的SQL脚本。
字段映射
输入字段
根据上游的输出,为您展示输入字段。
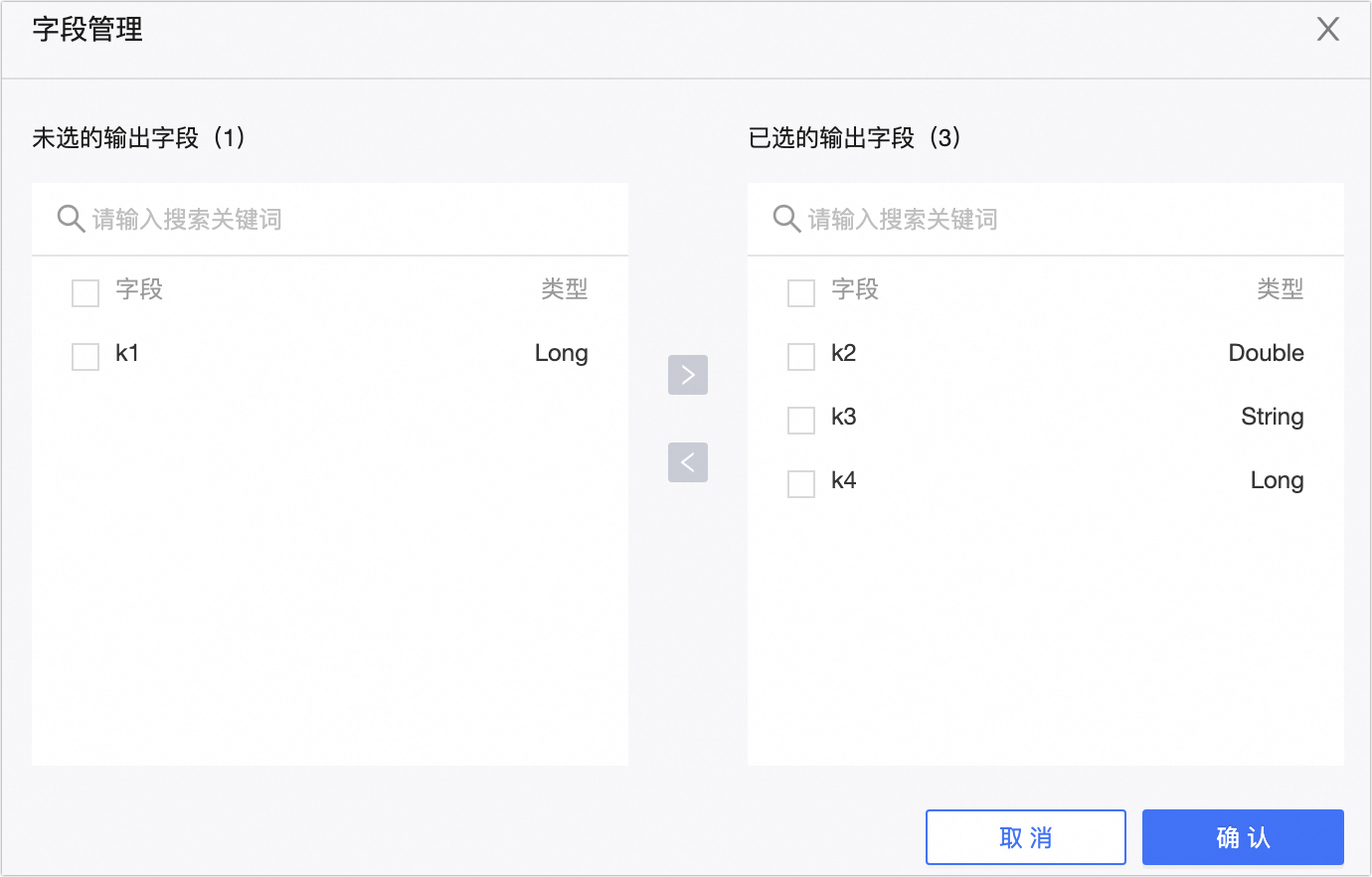
输出字段
为您展示输出字段。单击字段管理选择输出字段。

单击
图标,将已选的输入字段移入未选的输入字段。单击
图标,将未选的输入字段移入已选的输入字段。
映射关系
映射关系用于将源表的输入字段和目标表的输出字段进行映射。映射关系包括同名映射和同行映射。适用场景说明如下:
同名映射:对字段名称相同的字段进行映射。
同行映射:源表和目标表的字段名称不一致,但字段对应行的数据需要映射。只映射同行的字段。
单击确认,完成Lindorm(计算引擎)输出组件的属性配置。