
通过创建MaxCompute数据源能够实现Dataphin读取MaxCompute的业务数据或向MaxCompute写入数据。本文为您介绍如何创建MaxCompute数据源。
背景信息
MaxCompute即阿里云大数据计算服务,适用于数据分析场景的企业级SaaS(Software as a Service)模式云数据仓库,以Serverless架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您可以经济并高效地分析处理海量数据。
使用限制
MaxCompute数据源不支持接入MaxCompute的外部项目。详情请参见MaxCompute项目概述。
权限说明
仅超级管理员、数据源管理员、板块架构师、项目管理员和具备新建数据源权限点的自定义全局角色,支持创建数据源。
操作步骤
在Dataphin首页,单击顶部菜单栏管理中心 > 数据源管理。
在数据源页面,单击+新建数据源。
在新建数据源页面的大数据存储区域,选择MaxCompute。
如果您最近使用过MaxCompute,也可以在最近使用区域选择MaxCompute。同时,您也可以在搜索框中,输入MaxCompute的关键词,快速搜索。
在新建MaxCompute数据源页面中,配置连接数据源参数。
配置数据源的基本信息。
参数
说明
数据源名称
填写数据源名称。命名规则如下:
只能包含中文、英文字母大小写、数字、下划线(_)或短划线(-)。
长度不能超过64个字符。
数据源编码
配置数据源编码后,您可以在Flink_SQL任务或使用Dataphin JDBC客户端中,通过
数据源编码.表名称或数据源编码.schema.表名称的格式直接访问Dataphin数据源表,实现快捷消费;如果需要根据任务执行环境自动切换数据源,请通过${数据源编码}.table或${数据源编码}.schema.table的变量格式访问。更多信息,请参见Dataphin数据源表开发方式。重要数据源编码配置成功后不支持修改。
数据源编码配置成功后,才能在资产目录和资产清单的对象详情页面进行数据预览。
Flink SQL中,目前仅支持MySQL、Hologres、MaxCompute、Oracle、StarRocks、Hive、SelectDB、GaussDB(DWS)数据源。
数据源描述
填写对数据源的简单描述。不得超过128个字符。
数据源配置
选择需要配置的数据源:
如果业务数据源区分生产数据源和开发数据源,则选择生产+开发数据源。
如果业务数据源不区分生产数据源和开发数据源,则选择生产数据源。
标签
您可以根据标签给数据源进行分类打标,如何创建标签,请参见管理数据源标签。
配置数据源与Dataphin的连接参数。
若您的数据源配置选择生产+开发数据源,则需配置生产+开发数据源的连接信息。如果您的数据源配置为生产数据源,仅需配置生产数据源的连接信息。
说明通常情况下,生产数据源和开发数据源需配置为非同一个数据源,以实现开发数据源与生产数据源的环境隔离,降低开发数据源对生产数据源的影响。但Dataphin也支持配置成同一个数据源,即相同参数值。
参数
说明
Endpoint
MaxCompute的Endpoint,请根据您的网络环境和连接方式选择对应的Endpoint。
如何获取Endpoint,请参见Endpoint。
Access ID、Access Key
MaxCompute数据源所在账号的AccessKey ID和AccessKey Secret。
如何获取,请参见获取AccessKey。
说明仅当认证方式选择为AccessKey认证时,支持配置此项。
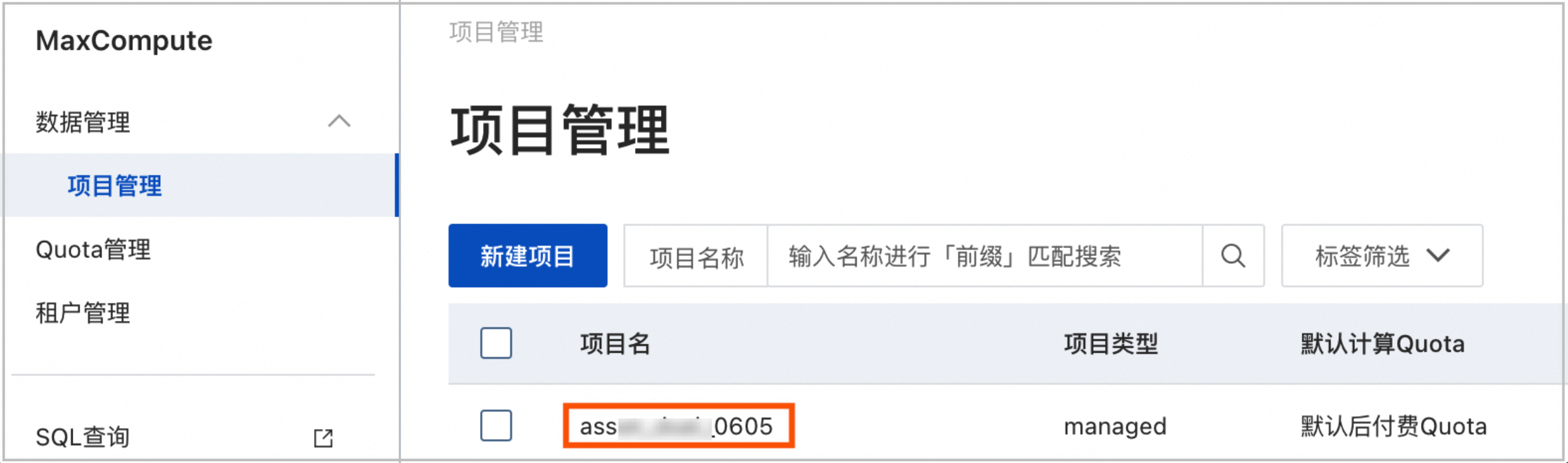
Project Name
此处为MaxCompute项目名称,非DataWorks工作空间名称。
您可以登录MaxCompute控制台,左上角切换地域后,即可在项目管理页签查看到具体的MaxCompute项目名。
选择默认资源组,该资源组用于运行与当前数据源相关任务,包括数据库SQL、离线整库迁移、数据预览等。
进行测试连接或直接单击确定进行保存,完成MaxCompute数据源的创建。
单击测试连接,系统将测试数据源是否可以和Dataphin进行正常的连通。若直接单击确定,系统将自动对所有已选中的集群进行测试连接,但即使所选中的集群均连接失败,数据源依然可以正常创建。