
Hive输出组件用于向Hive数据源写入数据。同步其他数据源的数据至Hive数据源的场景中,完成源数据源的信息配置后,需要配置Hive输出组件写入数据的目标数据源。本文为您介绍如何配置Hive输出组件。
使用限制
Hive输出组件支持写入文件格式为orc、parquet、text、Hudi(Hudi格式仅支持Cloudera Data Platform7.x的Hive计算源或数据源)、Iceberg(Iceberg格式仅支持E-MapReduce5.x的Hive计算源或数据源)、Paimon(Paimon格式仅支持E-MapReduce5.x的Hive计算源或数据源)的Hive数据表。不支持ORC格式的事务表、Kudu表集成。
Kudu表数据集成请使用Impala输出组件。更多信息,请参见配置Impala输出组件。
前提条件
操作步骤
在Dataphin首页顶部菜单栏,选择研发 > 数据集成。
在集成页面顶部菜单栏选择项目(Dev-Prod模式需要选择环境)。
在左侧导航栏中单击离线集成,在离线集成列表中单击需要开发的离线管道,打开该离线管道的配置页面。
单击页面右上角的组件库,打开组件库面板。
在组件库面板左侧导航栏中需选择输出,在右侧的输出组件列表中找到Hive组件,并拖动该组件至画布。
单击并拖动目标输入、转换或流程组件的
 图标,将其连接至当前Hive输出组件上。
图标,将其连接至当前Hive输出组件上。单击Hive输出组件卡片中的
 图标,打开Hive输出配置对话框。
图标,打开Hive输出配置对话框。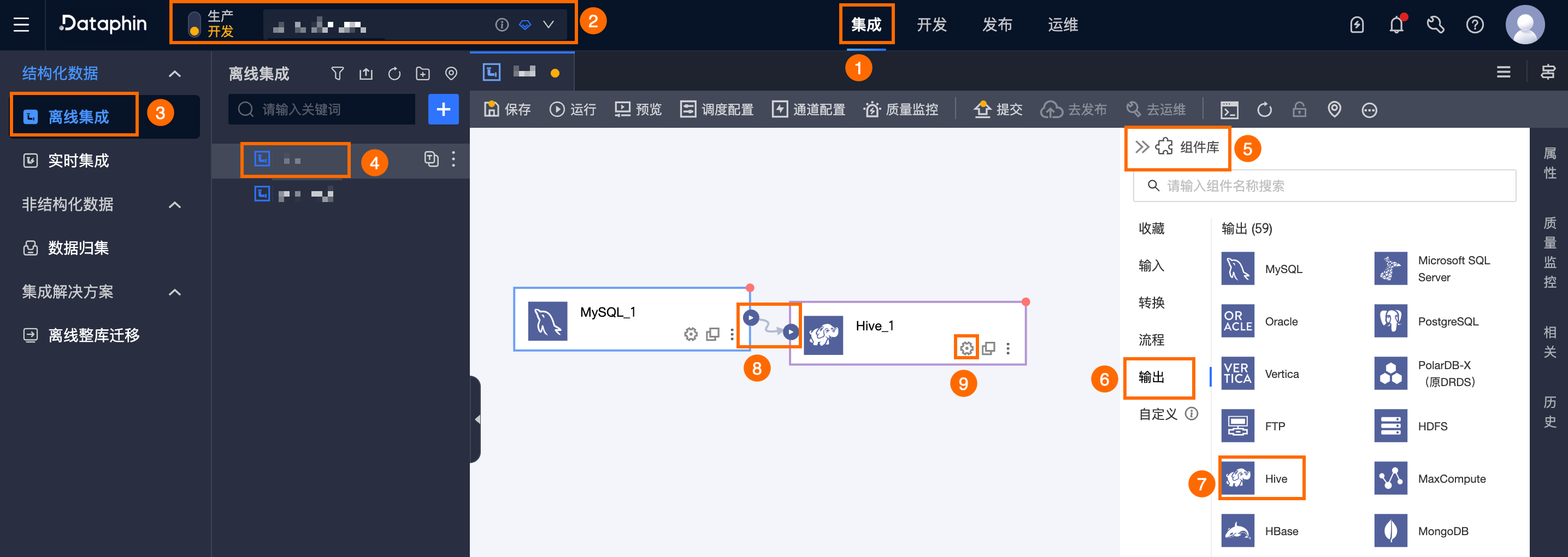
在Hive输出配置对话框,配置参数。
Hive表与Hudi表所需配置的参数不同。
输出目标表选择为Hive表
参数
描述
基本设置
步骤名称
即Hive输出组件的名称。Dataphin自动生成步骤名称,您也可以根据业务场景修改。命名规则如下:
只能包含中文、字母、下划线(_)、数字。
不能超过64个字符。
数据源
在数据源下拉列表中,展示所有Hive类型的数据源,包括您已拥有同步写权限的数据源和没有同步写权限的数据源。单击
 图标,可复制当前数据源名称。
图标,可复制当前数据源名称。表
选择输出数据的目标表(Hive表)。 可输入表名关键字进行搜索,或输入准确表名后单击精准查找。选择表后,系统将自动进行表状态检测。单击
 图标,可复制当前所选表的表名称。
图标,可复制当前所选表的表名称。如果Hive数据源中没有数据同步的目标表,则您可以通过一键建表的功能,简单快速的生成目标表。详细操作步骤如下:
单击一键建表。Dataphin会自动为您匹配创建目标表的代码,包括目标表名称(默认为来源表名)、字段类型(基于Dataphin字段做了初步的转换)等信息。
数据湖表格式选择为不选择或Iceberg。
说明仅当所选数据源或当前项目所使用的计算源开启数据湖表格式,且选择为Iceberg时,此处支持选择Iceberg。
执行引擎选择为Hive或Spark。
说明仅当数据湖表格式选择为Iceberg时,支持选择执行引擎。若所选数据源已配置Spark,则展示并默认选择Spark;若未配置,则仅展示并选择Hive。
DDL根据所选的数据湖表格式以及执行引擎自动生成,您可在此基础上进行修改,完成后单击新建。目标表新建成功后,Dataphin自动将新建的目标表作为输出数据的目标表。
说明如果开发环境存在同名的表,Dataphin会报已存在该表的错误。
没有匹配项时,也支持根据手动输入的表名进行集成。
生产表缺失策略
生产表不存在时的处理策略,可选择不处理或自动创建,默认为自动创建。若选择不处理,则任务发布时不进行生产表创建;若选择自动创建,则任务发布时在目标环境创建同名表。
不处理:若目标表不存在,则提交时会提示目标表不存在,但仍可正常发布。此时,用户需自行在生产环境创建目标表,才可执行任务。
自动创建:需编辑建表语句,默认填充所选表的建表语句,用户可进行调整。建表语句中的表名使用占位符
${table_name},且仅支持填写该占位符,实际执行时将替换为真实表名。若目标表不存在,则先按照建表语句进行建表,若建表失败,则发布时检查结果为失败,您可根据错误提示修改建表语句,修改完成后再次进行发布。若目标表已存在,则不执行建表。
说明仅Dev-Prod模式项目中支持配置此项。
文件编码
选择文件存储在Hive的编码方式。文件编码包括UTF-8和GBK。
加载策略
向目标数据源(Hive数据源)写入数据时,数据写入表中的策略。加载策略包括覆盖所有数据、追加数据、仅覆盖集成任务写入的数据,适用场景说明如下:
覆盖所有数据:会先删除目标表或分区下的所有数据,再新增以表名开头的数据文件。
追加数据:直接向目标表追加写入数据。
仅覆盖集成任务写入的数据:会先删除目标表或分区下以表名开头的数据文件(通过SQL等其他方式写入的数据不会被删除)。
NULL值替换(非必填)
仅支持
textfile数据存储格式的来源表。填写需要替换为NULL的字符串。例如,填写\N时,系统会将\N字符串替换为NULL。字段分隔符(非必填)
仅支持
textfile数据存储格式的来源表。填写字段之间分隔符。如果您没有填写,则系统默认为使用\u0001作为分隔符。压缩格式(非必填)
选择文件的压缩格式。根据Hive中数据存储格式不同,支持选择压缩格式不同:
数据存储格式为orc:支持选择的压缩格式包括zlib、snappy。
数据存储格式为parquet:支持选择的压缩格式包括snappy、gzip。
数据存储格式为textfile:支持选择的压缩格式包括gzip、bzip2、 lzo、lzo_deflate、hadoop-snappy和zlib。
字段分隔符处理(非必填)
仅支持
textfile数据存储格式的输出表。数据中存在默认或自行配置的字段分隔符时,可以配置字段分隔符处理策略,防止数据写入错误。可以选择保留、去除或替换为。行分隔符处理(非必填)
仅支持
textfile数据存储格式的输出表。数据中存在默认或自行配置的字段分隔符时,可以配置行分隔符号处理策略,默认以\n作为行分隔符,如数据中存在换行符\r、\n,可选择处理策略,防止数据写入错误。可以选择保留、去除或替换为。Hadoop参数配置(非必填)
用于调整写入参数,针对不同的表类型可以填写不同的参数,多个参数间用英文逗号隔开(,),格式为
{"key1":"value1", "key2":"value2"}。例如:输出表格式为orc且字段较多的场景下可根据内存大小来调整{"hive.exec.orc.default.buffer.size"}参数,内存足够时可尝试调大该配置提高写入性能,内存不足时可尝试调小该配置减少GC时间提高写入性能,默认为16384Byte(16KB),建议不超过262144Byte(256KB)。分区
如果所选的目标表是分区表,那么需要填写分区信息。例如,
state_date=20190101,也支持参数的方式以便每天增量写入数据。例如,state_date=${bizdate}。准备语句(非必填)
数据导入前对数据库执行的SQL脚本。
比如为了满足服务的持续可用性,当前步骤写数据执行前先创建目标表Target_A,执行写入到目标表Target_A,当前步骤写数据执行完成后,对数据库中持续提供服务的表Service_B重命名成Temp_C,然后将表Target_A重命名为Service_B,最后删除Temp_C。
结束语句(非必填)
数据导入后对数据库执行的SQL脚本。
字段映射
输入字段
根据上游组件的输出,为您展示输入字段。
输出字段
输出字段区域展示了已选中表的所有字段。
重要为了保证数据写入Hive时数据不会出错,输出字段必须和输入组件的字段全部映射。
映射关系
根据上游的输入和目标表的字段,可以手动选择字段映射。映射关系包括同行映射和同名映射。
同名映射:对字段名称相同的字段进行映射。
同行映射:源表和目标表的字段名称不一致,但字段对应行的数据需要映射。只映射同行的字段。
输出目标表选择为Hudi表
参数
描述
基本设置
步骤名称
即Hive输出组件的名称。Dataphin自动生成步骤名称,您也可以根据业务场景修改。命名规则如下:
只能包含中文、字母、下划线(_)、数字。
不能超过64个字符。
数据源
在数据源下拉列表中,展示所有Hive类型的数据源,包括您已拥有同步写权限的数据源和没有同步写权限的数据源。单击
 图标,可复制当前数据源名称。
图标,可复制当前数据源名称。表
选择输出数据的目标表(Hudi表)。 可输入表名关键字进行搜索,或输入准确表名后单击精准查找。选择表后,系统将自动进行表状态检测。单击
图标,可复制当前所选表的表名称。如果Hive数据源中没有数据同步的目标表,则您可以通过一键建表的功能,简单快速地生成目标表。详细操作步骤如下:
单击一键建表。Dataphin会自动为您匹配创建目标表的代码,包括目标表名称(默认为来源表名)、字段类型(基于Dataphin字段做了初步的转换)等信息。
数据湖表格式选择为Hudi。
Hudi表类型:可选择MOR(merge on read)或COW(copy on write),默认为MOR(merge on read)。
主键字段(非必填):输入主键字段,多个字段间使用半角逗号(,)分隔。
扩展属性(非必填):输入Hudi官方支持的配置属性,格式为
k=v。说明如果开发环境存在同名的表,单击新建后,Dataphin会报已存在该表的错误。
没有匹配项时,也支持根据手动输入的表名进行集成。
执行引擎选择为Hive或Spark。
说明仅当数据湖表格式选择为Hudi时,支持选择执行引擎。执行引擎默认为Hive,若所选数据源已开启Spark,则支持选择Spark。
DDL根据所选的数据湖表格式以及执行引擎自动生成,您可在此基础上进行修改,完成后单击新建。
生产表缺失策略
生产表不存在时的处理策略,可选择不处理或自动创建,默认为自动创建。若选择不处理,则任务发布时不进行生产表创建;若选择自动创建,则任务发布时在目标环境创建同名表。
不处理:若目标表不存在,则提交时会提示目标表不存在,但仍可正常发布。此时,用户需自行在生产环境创建目标表,才可执行任务。
自动创建:需编辑建表语句,默认填充所选表的建表语句,用户可进行调整。建表语句中的表名使用占位符
${table_name},且仅支持填写该占位符,实际执行时将替换为真实表名。若目标表不存在,则先按照建表语句进行建表,若建表失败,则发布时检查结果为失败,您可根据错误提示修改建表语句,修改完成后再次进行发布。若目标表已存在,则不执行建表。
说明仅Dev-Prod模式项目中支持配置此项。
分区
如果所选的目标表是分区表,那么需要填写分区信息。例如,
state_date=20190101,也支持参数的方式以便每天增量写入数据。例如,state_date=${bizdate}。加载策略
向目标数据源(Hive数据源)写入数据时,数据写入表中的策略,包括覆盖数据、追加数据、更新数据。
覆盖数据:使用新增数据覆盖已有数据。
追加数据:直接向目标表追加写入数据。
更新数据:按主键更新,不存在时则插入数据。
说明通过SQL等其他方式写入的数据不会被删除。
BulkInsert
适用于大数据量的批量快速同步场景,通常用于初始数据的导入。
说明仅当加载策略选择为追加策略或覆盖策略时,支持配置此项,且默认为开启。
分批写入
通过分批的方式将数据写入目标表,开启后还需配置分批比例。
分批比例
占JVM总内存比例,默认为0.2,可填写0.01~0.50之间的两位小数。
Hadoop参数配置(非必填)
用于调整写入参数,针对不同的表类型可以填写不同的参数,多个参数间用英文逗号隔开(,),格式为
{"key1":"value1", "key2":"value2"}。可使用{"hoodie.parquet.compression.codec":"snappy"}参数将压缩格式调整为snappy。字段映射
输入字段
根据上游组件的输出,为您展示输入字段。
输出字段
输出字段区域展示了已选中表的所有字段。
说明Hudi表无需映射所有字段。
映射关系
根据上游的输入和目标表的字段,可以手动选择字段映射。映射关系包括同行映射和同名映射。
同名映射:对字段名称相同的字段进行映射。
同行映射:源表和目标表的字段名称不一致,但字段对应行的数据需要映射。只映射同行的字段。
输出目标表为Paimon表
参数
描述
基本设置
步骤名称
即Hive输出组件的名称。Dataphin自动生成步骤名称,您也可以根据业务场景修改。命名规则如下:
只能包含中文、字母、下划线(_)、数字。
不能超过64个字符。
数据源
在数据源下拉列表中,展示所有Hive类型的数据源,包括您已拥有同步写权限的数据源和没有同步写权限的数据源。单击
图标,可复制当前数据源名称。表
选择输出数据的目标表(Paimon表)。 可输入表名关键字进行搜索,或输入准确表名后单击精准查找。选择表后,系统将自动进行表状态检测。单击
图标,可复制当前所选表的表名称。如果Hive数据源中没有数据同步的目标表,则您可以通过一键建表的功能,简单快速的生成目标表。详细操作步骤如下:
单击一键建表。Dataphin会自动为您匹配创建目标表的代码,包括目标表名称(默认为来源表名)、字段类型(基于Dataphin字段做了初步的转换)等信息。
数据湖表格式选择为不选择、Iceberg或Paimon。
说明仅当所选数据源或当前项目所使用的计算源开启数据湖表格式,且选择为Iceberg时,此处支持选择Iceberg。
执行引擎选择为Hive或Spark。
说明仅当数据湖表格式选择为Iceberg或Paimon时,支持选择执行引擎。若所选数据源已配置Spark,则展示并默认选择Spark;若未配置,则仅展示并选择Hive。
Paimon表类型可选择MOR(merge on read)、COW(copy on write)或MOW(merge on write),默认选择MOR。
说明仅当数据湖表格式选择为Paimon时,支持配置Paimon表类型。
DDL根据所选的数据湖表格式以及执行引擎自动生成,您可在此基础上进行修改,完成后单击新建。目标表新建成功后,Dataphin自动将新建的目标表作为输出数据的目标表。
说明如果开发环境存在同名的表,单击新建后,Dataphin会报已存在该表的错误。
没有匹配项时,也支持根据手动输入的表名进行集成。
生产表缺失策略
生产表不存在时的处理策略,可选择不处理或自动创建,默认为自动创建。若选择不处理,则任务发布时不进行生产表创建;若选择自动创建,则任务发布时在目标环境创建同名表。
不处理:若目标表不存在,则提交时会提示目标表不存在,但仍可正常发布。此时,用户需自行在生产环境创建目标表,才可执行任务。
自动创建:需编辑建表语句,默认填充所选表的建表语句,用户可进行调整。建表语句中的表名使用占位符
${table_name},且仅支持填写该占位符,实际执行时将替换为真实表名。若目标表不存在,则先按照建表语句进行建表,若建表失败,则发布时检查结果为失败,您可根据错误提示修改建表语句,修改完成后再次进行发布。若目标表已存在,则不执行建表。
说明仅Dev-Prod模式项目中支持配置此项。
加载策略
向目标数据源(Hive数据源)写入数据时,数据写入表中的策略。加载策略包括追加数据、覆盖数据、更新数据,适用场景说明如下:
追加数据:直接向目标表追加写入数据。
覆盖数据:使用新增数据覆盖已有数据。
更新数据:按主键更新,不存在则插入。
NULL值替换(非必填)
仅支持
textfile数据存储格式的来源表。填写需要替换为NULL的字符串。例如,填写\N时,系统会将\N字符串替换为NULL。字段分隔符(非必填)
仅支持
textfile数据存储格式的来源表。填写字段之间分隔符。如果您没有填写,则系统默认为使用\u0001作为分隔符。字段分隔符处理(非必填)
仅支持
textfile数据存储格式的输出表。数据中存在默认或自行配置的字段分隔符时,可以配置字段分隔符处理策略,防止数据写入错误。可以选择保留、去除或替换为。行分隔符处理(非必填)
仅支持
textfile数据存储格式的输出表。数据中存在默认或自行配置的字段分隔符时,可以配置行分隔符号处理策略,默认以\n作为行分隔符,如数据中存在换行符\r、\n,可选择处理策略,防止数据写入错误。可以选择保留、去除或替换为。Hadoop参数配置(非必填)
用于调整写入参数,针对不同的表类型可以填写不同的参数,多个参数间用英文逗号隔开(,),格式为
{"key1":"value1", "key2":"value2"}。例如:输出表格式为orc且字段较多的场景下可根据内存大小来调整{"hive.exec.orc.default.buffer.size"}参数,内存足够时可尝试调大该配置提高写入性能,内存不足时可尝试调小该配置减少GC时间提高写入性能,默认为16384Byte(16KB),建议不超过262144Byte(256KB)。分区
如果所选的目标表是分区表,那么需要填写分区信息。例如,
state_date=20190101,也支持参数的方式以便每天增量写入数据。例如,state_date=${bizdate}。字段映射
输入字段
根据上游组件的输出,为您展示输入字段。
输出字段
输出字段区域展示了已选中表的所有字段。
重要为了保证数据写入Hive时数据不会出错,输出字段必须和输入组件的字段全部映射。
映射关系
根据上游的输入和目标表的字段,可以手动选择字段映射。映射关系包括同行映射和同名映射。
同名映射:对字段名称相同的字段进行映射。
同行映射:源表和目标表的字段名称不一致,但字段对应行的数据需要映射。只映射同行的字段。
单击确认,完成Hive输出组件的属性配置。