
通过创建Impala数据源能够实现Dataphin读取Impala的业务数据或向Impala写入数据。本文为您介绍如何创建Impala数据源。
背景信息
Impala是用于处理存储在Hadoop集群中大量数据的SQL查询引擎。如果您使用的是Impala,在导出Dataphin数据至Impala,您需要先完成Impala数据源的创建。更多Impala信息,请参见Impala官网。
权限管理
仅支持具备新建数据源权限点的自定义全局角色和超级管理员、数据源管理员、板块架构师、项目管理员角色创建数据源。
使用限制
Dataphin的Impala数据源的数据集成使用JDBC的方式进行集成,因此性能相较于Hive较差,若您集成的表为非Kudu表,您可使用Hive数据源及输入输出组件集成。
仅当连接E-MapReduce 5.x版本的Impala数据源时,才支持使用DLF获取元数据。
操作步骤
在Dataphin首页,单击顶部菜单栏管理中心 > 数据源管理。
在数据源页面,单击+新建数据源。
在新建数据源页面的大数据存储区域,选择Impala。
如果您最近使用过Impala,也可以在最近使用区域选择Impala。同时,您也可以在搜索框中,输入Impala的关键词,快速筛选。
在新建Impala数据源页面中,配置连接数据源参数。
配置数据源的基本信息。
参数
描述
数据源名称
命名规则如下:
只能包含中文、英文字母大小写、数字、下划线(_)或短划线(-)。
长度不能超过64字符。
数据源编码
配置数据源编码后,您可以在Flink_SQL任务中通过
数据源编码.表名称或数据源编码.schema.表名称的格式引用数据源中的表;如果需要根据所处环境自动访问对应环境的数据源,请通过${数据源编码}.table或${数据源编码}.schema.table的变量格式访问。更多信息,请参见Dataphin数据源表开发方式。重要数据源编码配置成功后不支持修改。
数据源编码配置成功后,才能在资产目录和资产清单的对象详情页面进行数据预览。
Flink SQL中,目前仅支持MySQL、Hologres、MaxCompute、Oracle、StarRocks、Hive、SelectDB、GaussDB(DWS)数据源。
版本
选择Impala数据源版本。版本支持:
CDH5:2.11.0
CDH6:3.2.0
CDP7.1.3:3.4.0
E-MapReduce 3.x: 3.4.0
E-MapReduce 5.x: 3.4.0
E-MapReduce 5.x: 4.2.0
数据源描述
对数据源的简单描述。不得超过128个字符。
数据源配置
选择需要配置的数据源:
如果业务数据源区分生产数据源和开发数据源,则选择生产+开发数据源。
如果业务数据源不区分生产数据源和开发数据源,则选择生产数据源。
标签
您可根据标签给数据源进行分类打标,如何创建标签,请参见管理数据源标签。
配置数据源与Dataphin的连接参数。
若您的数据源配置选择生产+开发数据源,则需配置生产+开发数据源的连接信息。如果您的数据源配置为生产数据源,仅需配置生产数据源的连接信息。
说明通常情况下,生产数据源和开发数据源需配置非同一个数据源,以使开发数据源与生产数据源的环境隔离,降低开发数据源对生产数据源的影响。但Dataphin也支持配置成同一个数据源,即相同参数值。
参数
描述
JDBC URL
连接地址的格式为
jdbc:impala//host:port/dbname。例如,jdbc:impala//192.168.*.1:5433/dataphin。Kerberos
Kerberos是一种基于对称密钥技术的身份认证协议:
Hadoop集群有Kerberos认证,则需要开启Kerberos。
Hadoop集群没有Kerberos认证,则无需开启Kerberos。
Krb5文件/KDC Server、Keytab File、Principal
开启Kerberos后,需要配置参数如下:
Krb5文件/KDC Server:需要上传包含Kerberos认证域名的Krb5文件、配置KDC服务器地址,辅助完成Kerberos认证。
说明支持配置多个KDC Server服务地址,使用英文逗号
,分割。Keytab File:上传登录Krb5文件域名或KDC服务器地址的账号和密码的文件。
Principal:配置Keytab File文件对应的Kerberos认证用户名。
用户名、密码
如果您没有开启Kerberos,则需要配置访问Impala实例的用户名和密码。
配置数据源元数据库参数。
元数据获取方式:支持元数据库、HMS、DLF三种源数据获取方式。获取方式不同,所需配置信息不同。
元数据库获取方式
参数
说明
数据库类型
请根据集群中使用的元数据库类型,选择对应的数据库类型。Dataphin支持选择MySQL、PostgreSQL。MySQL数据库类型支持MySQL 5.1.43、MYSQL 5.6/5.7和MySQL 8版本。
JDBC URL
填写目标数据库的JDBC连接地址。连接地址格式为
jdbc:mysql://host:port/dbname。用户名、密码
填写登录元数据库的用户名和密码。
HMS获取方式
参数
说明
hive-site.xml
上传Hive的hive-site.xml配置文件。
DLF获取方式
说明仅当连接E-MapReduce 5.x版本的Impala数据源时,才支持使用DLF获取元数据。
参数
说明
Endpoint(非必填)
填写集群在DLF数据中心所在地域的Endpoint,若未填写则使用hive-site.xml中的配置项。Endpoint如何获取,请参见DLF Region和Endpoint对照表。
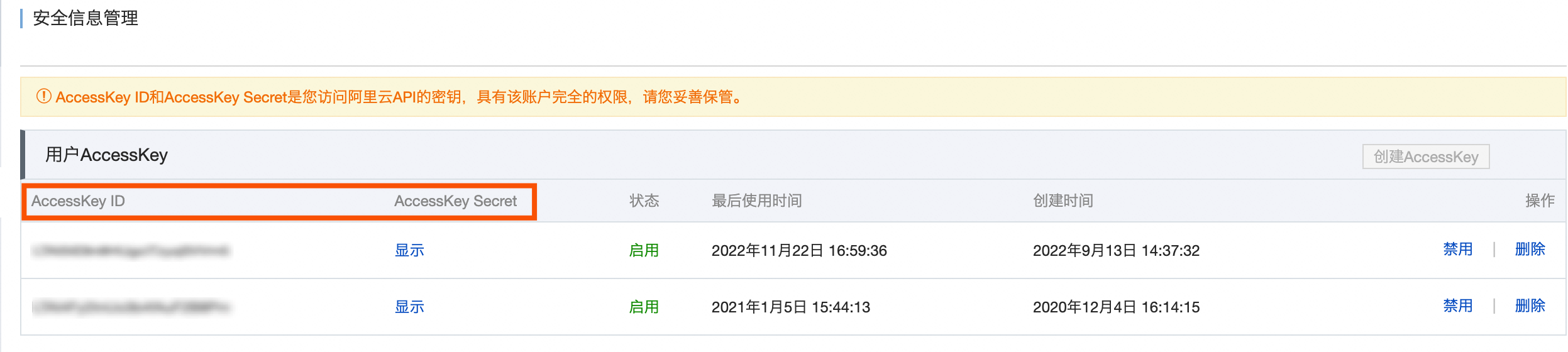
AccessKey ID、AccessKey Secret
填写集群所在账号的AccessKey ID和AccessKey Secret。
您可在用户信息管理页面,获取账号的AccessKey ID和AccessKey Secret。
hive-site.xml
上传Hive的hive-site.xml配置文件。
配置数据源与Dataphin的高级设置。
参数
描述
连接重试次数
数据库连接超时,将自动重试连接直到完成设定的重试次数。若达到最大重试次数仍未连接成功,则连接失败。
说明默认重试次数为1次,支持配置0~10之间参数。
连接重试次数将默认应用于离线集成任务与全域质量(需开通资产质量功能模块),离线集成任务中支持单独配置任务级别的重试次数。
选择默认资源组,该资源组用于运行与当前数据源相关任务,包括数据库SQL、离线整库迁移、数据预览等。
进行测试连接或直接单击确定进行保存,完成Impala数据源的创建。
单击测试连接,系统将测试数据源是否可以和Dataphin进行正常的连通。若直接单击确定,系统将自动对所有已选中的集群进行测试连接,但即使所选中的集群均连接失败,数据源依然可以正常创建。